
基于层级自适应微调的长文本分类算法研究
2023-11-30 04:55:18郑坚王俊鑫陈奕林林灵鑫侯子豪
无线互联科技 2023年18期
关键词:注意力机制
郑坚 王俊鑫 陈奕林 林灵鑫 侯子豪
作者简介:郑坚燚(1997— ),男,广东汕头人,工程师,硕士;研究方向:自然语言处理。
摘要:随着算力的提升,文本分类算法已进入深度学习时代。文章以深度学习下的自适应微调长文本分类模型为基础,针对其策略网络存在决策能力不足与离散噪声这一问题,结合现有分层模型展开研究,提出融合层编码的层级自适应微调长文本分类模型,力求推进模型在长文本分类任务上的性能。首先,文章重构策略网络,将策略网络迁移至模型内部,消除离散噪声,提高决策精度。其次,考虑预训练模型的层级特征差异,文章提出层编码,为策略网络提供层位置信息,提高策略网络对特征的层位置感知。文章基于Yelp-2013、IMDB、Reuters 3个国际数据集,利用对比实验、烧蚀实验验证模型性能。实验表明,文章提出的长文本分类模型相较于基线模型在3个数据集上的性能更优。
关键词:长文本分类;预训练模型;注意力机制;循環神经网络
中图分类号:TP391.1 文献标志码:A
0 引言
随着 5G 技术的发展,长文本数据量剧增。长文本数据在社会信息传播中扮演了重要的角色,高效的长文本分类算法能提高数据管理系统对长文本数据的管理效率。良好的数据管理系统不仅能提高企业对长文本数据的管理水平,还能提高信息调配速率并优化用户体验。随着算力的提升,深度学习下的长文本分类算法研究也在不断推进。
当前,深度学习下的长文本分类算法研究可分为基于非预训练模型的浅层模型与基于预训练模型的深层模型。浅层模型基于Long Short Term Memory(LSTM)等时序模型搭建,如tree-LSTM、缓存 LSTM等[1-3]。该类模型具有计算量低、易于实现等优点,但在长文本分类任务中仍存在梯度爆炸的问题。相较于前者,深层模型利用预训练模型对文本块进行特征抽取,由此建模上下文,在长文本分类任务下的性能有较大的提升,如:Hierarchical BERT with An Aadaptive Fine-tuning Strategy(HAdaBERT)等[4]。但是,深层模型下的自适应微调模型仍存在问题,如:策略网络决策能力不足、离散噪声等。
1 模型设计与原理
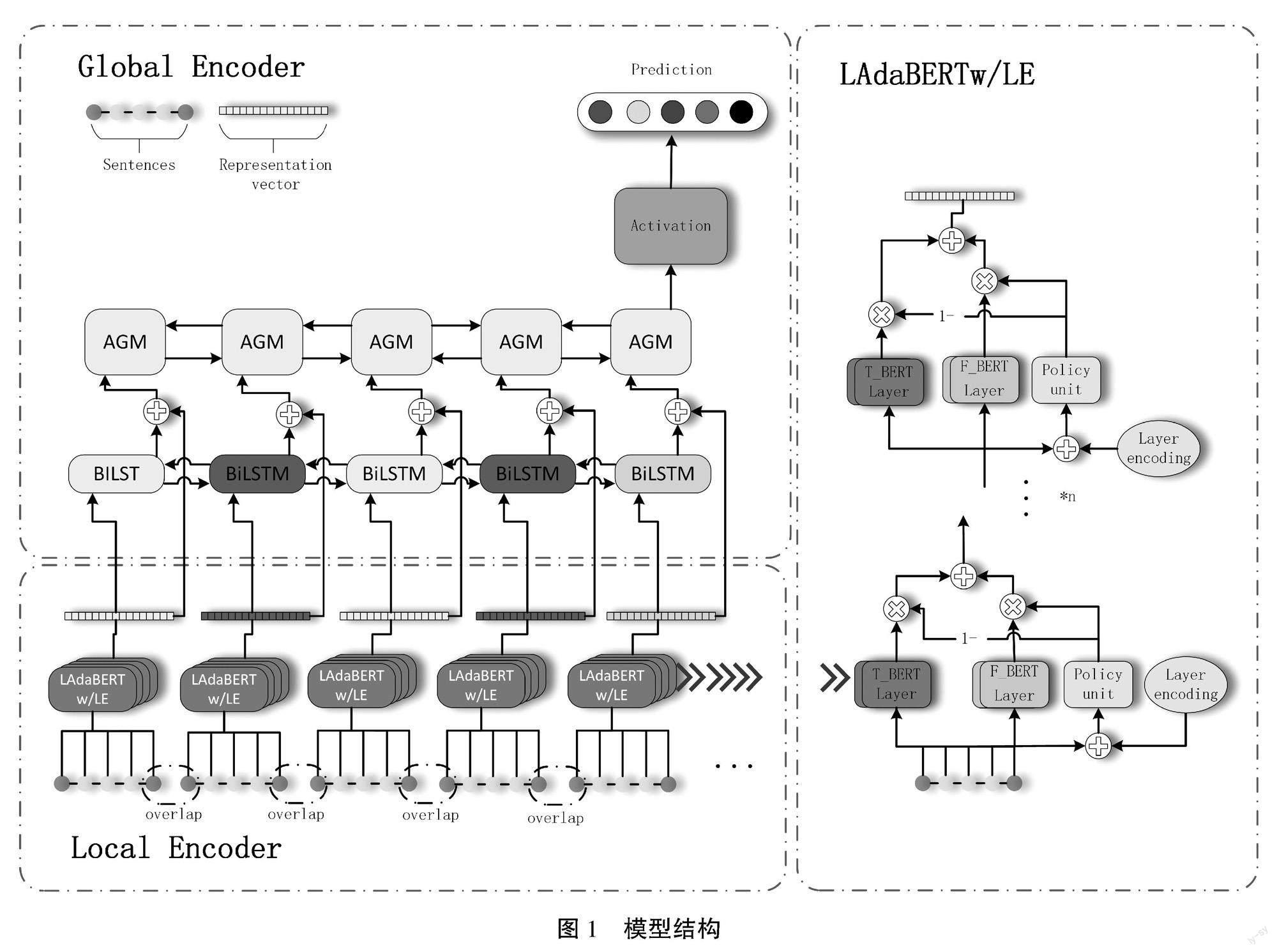
针对自适应微调模型所存在的问题,本文提出一种融合层编码的层级自适应微调长文本分类模型,模型结构如图1所示。该模型由Local Encoder(局部编码器)与Global Encoder(全局编码器)组成。其中,局部编码器由融合层编码的层级自适应微调BERT(Layer Aadaptive Fine-tuning BERT with Layer Encoding,LAdaBERT/LE)组成,局部编码器对文本块进行特征提取,形成具有上下文特征的文本块特征。全局编码器由BiLSTM(Bi-directional Long Short Term Memory)、AGM(Attention-based Gated Memory Network)、输出层组成,全局编码器对文本块特征进行融合,形成长文本特征后投入输出层完成长文本分类任务[4]。
1.1 局部编码器
本文以自适应微调模型为基础,由于该模型的输入长度限制为512词,待分类的长文本被分割为多个文本块。为了建立文本块之间的联系,同一个长文本中的上一个文本块的尾句取出,设置为下一个文本块的首句。若当前文本块长度超出文本块阈值,则当前句将被保存,作为下一文本块的首句。
1.1.1 LAdaBERT/LE
当长文本被分割为文本块后被分别投入LAdaBERT/LE中提取文本块特征。该模型由多层重复单元组成,其结构如图1中右侧所示。其中,每层单元由动态BERT单元、静态BERT单元、策略网络组成。单层单元的计算公式如下:
LayerOuti=Wai×pi+Wfi×(1-pi)(1)
其中,LayerOuti为第i层输出,Wai为当前层动态BERT单元输出,Wfi为当前层静态BERT单元输出,pi为当前层策略权重。经过多层单元计算,获得最终的输出Vi,即第i个文本块特征。
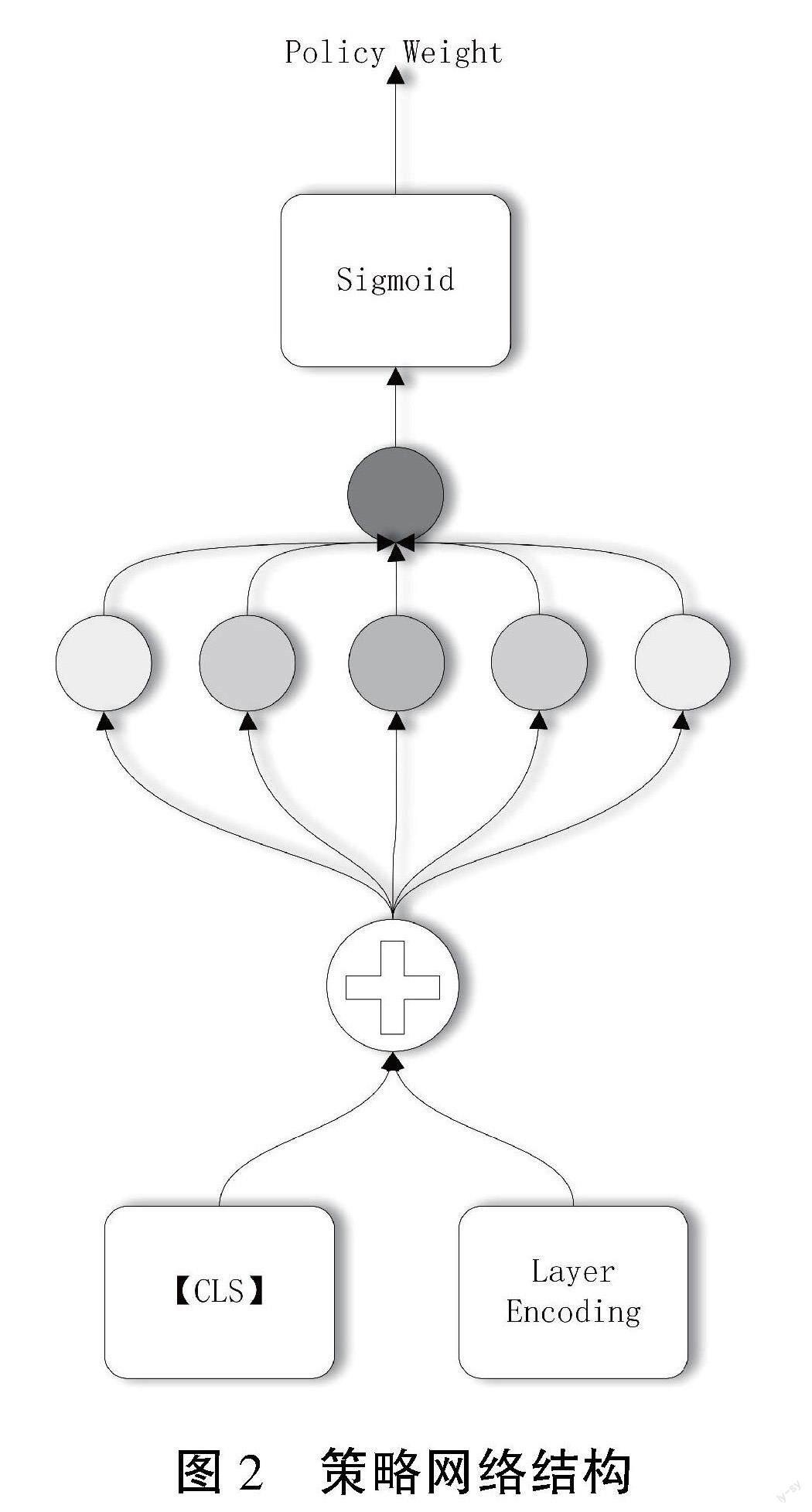
1.1.2 策略网络
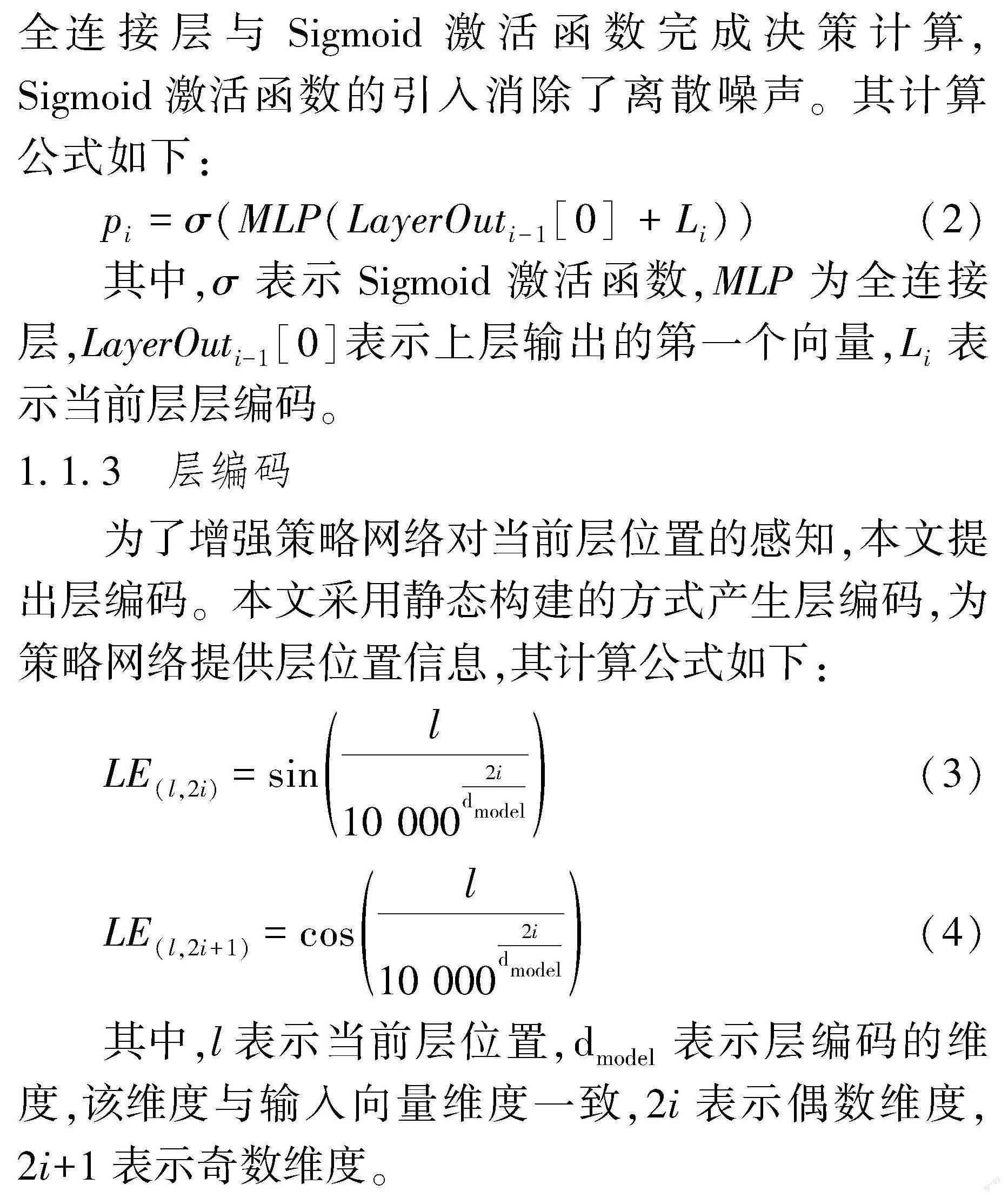
策略权重pi由策略网络产生,其结构如图2所示。本文将策略网络迁移到模型内部,相比外部策略网络,内部策略网络更贴近决策层与决策信息,降低了决策难度。因此,在本文中,策略网络利用多层全连接层与Sigmoid激活函数完成决策计算,Sigmoid激活函数的引入消除了离散噪声。其计算公式如下:
pi=σ(MLP(LayerOuti-1[0]+Li))(2)
其中,σ表示Sigmoid激活函数,MLP为全连接层,LayerOuti-1[0]表示上层输出的第一个向量,Li表示当前层层编码。
1.1.3 层编码
为了增强策略网络对当前层位置的感知,本文提出层编码。本文采用静态构建的方式产生层编码,为策略网络提供层位置信息,其计算公式如下:
LE(l,2i)=sinl10 0002idmodel(3)
LE(l,2i+1)=cosl10 0002idmodel(4)
其中,l表示当前层位置,dmodel表示层编码的维度,该维度与输入向量维度一致,2i表示偶数维度,2i+1表示奇数维度。
1.2 全局编码器
文本块经LAdaBERT/LE处理后,归属于同个长文本的文本块特征被按顺序收集,由此构建每个长文本的文本块特征合集VCi,文本块特征合集经全局编码器处理后形成长文本特征,该特征被投入分类层完成分类。
1.2.1 双向交互网络
在全局编码器中,文本块特征集合首先被投入BiLSTM层进行特征交互,经残差连接后产生中间特征Hi,其计算公式如下:
Hi=BiLSTM(VCi)+VCi(5)
其中,BiLSTM表示BiLSTM层。在长文本中,并非所有特征具有同等重要性。本文引入AGM网络,该网络通过注意力机制,计算中间特征的重要性并进行交互,由此产生长文本特征o。其计算公式如下:
o=AGM(Hi)(6)
其中,AGM表示AGM网络。长文本特征向量o自此构建完成。
1.2.2 输出层
与其他分类模型输出层一致,本文采用全连接层与Softmax激活函数组合为输出层,输出层利用长文本特征计算并输出样本在各个类别上的概率,其计算公式如下:
ycn^=Softmax(MLP(on))(7)
其中, ycn^表示第n个样本在c个类别上各自的预测概率,Softmax表示Softmax激活函数。本文针对长文本数据下的多分类与多标签分类进行研究,因此采用交叉熵损失函数,其计算公式如下:
=-∑Ni=1(yi)×log( ycn^)(8)
其中,yi为真实标签,(.)为独热编码。
2 数据集介绍
本文针对长文本分类任务,在 Yelp-2013、IMDB(Internet Movie Database)、Reuters 3个国际公开数据集上进行实验。其中,数据集的样本量分别为78 966、135 669、10 789,类别数分别为5、10、90,Yelp-2013与IMDB数据集为多分类任务,评价指标为准确率,Reuters数据集为多标签分类任务,评价指标为F1分数。
3 实验参数设置与分析
3.1 实验参数设置
本文所采用的实验平台为单卡单机平台,操作系统为Windows 10 专业版,处理器为Intel(R)Core(TM)i7-10700 CPU @2.90 GHz,运算加速器为 RTX3090(24G),采用的编程语言为Python3.10,深度学习框架为Pytorch1.10.2,CUDA版本为11.7.1。对于Yelp-2013、IMDB、Reuters数据集,训练epoch分别设置为50、50、100,学习率分别设置为6e-5、1e-5、1.2e-4,文本块阈值分别设置为160、160、360。
3.2 实验结果分析
本文采用对比实验与烧蚀实验验证模型的有效性。实验结果如表2所示。其中,TACC表示测试集准确率,DACC表示验证集准确率,TF1表示测试集F1分数,DF1表示验证集F1分数。
3.2.1 对比实验
表2展示了多个模型在不同数据集上的表现情况,相较于基线模型,本文所提出的长文本分类模型在各个数据集上的表现最优,充分展示了该模型在长文本分类任务上的优秀性能。
3.2.2 燒蚀实验
本文采用烧蚀实验验证内部策略网络与层编码的有效性,实验结果如表2所示。其中,LAdaBERT表示删除层编码后的模型,HAdaBERT表示采用外部策略网络并去除层编码的模型。由实验结果可知,当模型采用内部策略网络时,模型性能有所提升,这表明内部策略网络相较于外部策略网络的决策能力更高,进一步提升了模型在长文本分类任务上的性能。当模型采用内部决策网络并引入层编码后,模型性能进一步提升,这表明层编码所带来的层位置信息提高了策略网络的决策能力,进而提升了模型的长文本分类性能。
4 结语
为了优化自适应微调模型在长文本分类任务上的性能,本文采用内部策略网络与层编码提高决策网络决策能力,提出融合层编码的层级自适应微调长文本分类算法。实验表明,该模型在长文本分类任务上具有良好的分类性能。
参考文献
[1]HOCHREITER S,SCHMIDHUBER J.Long short-term memory[J].Neural computation,1997(8):1735-1780.
[2]TAI K S,SOCHER R,MANNING C D.Improved semantic representations from tree-structured long short-term memory networks:Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing[C].Stroudsburg,PA:ACL,2015.
[3]XU J,CHEN D,QIU X,et al.Cached long short-term memory neural networks for document-level sentiment classification:Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing[C].Stroudsburg,PA:ACL,2016.
[4]KONG J,WANG J,ZHANG X.Hierarchical BERT with an adaptive fine-tuning strategy for document classification[J].Knowledge-Based Systems,2022(238):107872.
(編辑 王永超编辑)
Research on long text classification algorithm based on hierarchical adaptive fine-tuning
Zheng Jianyi1, Wang Junxin2, Chen Yilin3, Lin Lingxin4, Hou Zihao5
(Guangdong University of Technology, Guangzhou 510000, China)
Abstract: With the improvement of computational power, text classification algorithms have entered the era of deep learning. This article is based on an adaptive fine-tuning long text classification model under deep learning and focuses on the issues of insufficient decision-making ability and discrete noise in its policy network. By combining existing hierarchical models, a hierarchical adaptive fine-tuning long text classification model with fusion layer encoding is proposed, aiming to advance the performance of the model in long text classification tasks. Firstly, this article reconstructs the policy network by transferring it internally within the model, eliminating discrete noise and improving decision accuracy. Secondly, considering the hierarchical feature differences of pre-trained models, this article introduces layer encoding to provide layer position information to the policy network, enhancing the decision networks perception of feature layer positions. Based on the Yelp-2013, IMDB, and Reuters international datasets, this article validates the models performance through comparative experiments and ablative experiments. The results demonstrate that the proposed long text classification model outperforms the baseline model on all three datasets.
Key words: long text classification; pre-training model; attention mechanism; recurrent neural network
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
无线互联科技(2019年9期)2019-07-29 00:41:36
无线互联科技(2019年9期)2019-07-29 00:41:36
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
