
计及生产行为约束的工业用户时序调节潜力分析方法
2023-11-29 02:03张俊芳
南京理工大学学报 2023年5期
刘 晗,肖 飞,崔 勇,耿 建,张俊芳,柳 伟
(1.南京理工大学 自动化学院,江苏 南京 210094;2. 国网上海市电力公司,上海 200122; 3. 中国电力科学研究院有限公司(南京),江苏 南京 210094)
“十四五”期间,随着我国对风电、光伏等新能源的持续大规模应用,给电力系统稳定调控带来严峻挑战,此外电力系统面临高比例新能源和高比例电力电子设备接入的“双高”问题,给电网平衡带来新的挑战[1-3]。工业企业作为我国能源消耗大户,在用电方面更是占据主导地位,在当前国家新一轮电力改革的背景下,工业用户负荷因具有灵活性、经济性等特征成为优化改革的主要对象,可有效提高系统运行效率与稳定。因此,对工业用户负荷进行时序调节以及对其潜力分析尤为重要,而工业负荷由于特征数据复杂且庞大,给工业负荷的分析工作带来不小的挑战,分析方法的选择对潜力分析的结果有着举足轻重的影响。
目前,对于工业负荷相关分析已有足够深入的研究。为了充分利用工业负荷本身属性,发挥其潜能,有必要深入挖掘负荷数据,提炼出更准确的工业用户用电特性[4],建立负荷调控潜力指标。文献[5-7]通过分析可调节负荷多元需求响应模型调控和调峰、调频市场的技术差异,为工业用户负荷调控评估能力构建了四维度评估指标体系,制定了可调节负荷调控能力标准,并验证了可行性。文献[8]针对工业用户提出了一种新的调控潜力分析方法,将调控能力分为长短期,以此分析工业用户的可调节潜力。文献[9]通过工业用户在多个时间度量下的用电特征,构建多时间尺度潜力评估体系,实现对调控潜力的评估量化。随着数据量的不断增多,常规的分析方法往往不能满足需求,因此机器学习常常被用于工业负荷的潜力评估。文献[10]通过需求侧调控需求,量化工业负荷数据,并分为不同小组,按小组构建调控潜力评估体系,分析优化结果。文献[11]提出行空间聚类分析方法并构建区域能力评价模型,寻找热点区域,进而挖掘潜力。文献[12]提出优化SAX和带权负荷指标的AP聚类算法,对负荷进行聚类分析,并基于聚类结果对各类用户的需求响应潜力进行分析。此外还有利用神经网络进行潜力分析,为工业负荷提供了新的方向[13,14]。
综上所述,本文结合聚类方法和神经网络的优点,提出一种基于数据模型双驱动的工业负荷可调节潜力评估方法。与以往组合预测方法不同,该方法融合了多层聚类模型,优化聚类效果,提高预测精度,并以某地实际数据验证该方法的有效性。
1 工业用户时序调节潜力模型
1.1 工业用户时序调节潜力影响因素分析
分析工业用户用电方式及用电行为影响可准确判断工业用户用电特性。本文在文献[15]所提出的工业用户用电行为构成的基础上,从用户行为维度和用户成本维度出发,将工业用户时序调节潜力影响因素分为两大类:用户行为影响因素和用户成本影响因素[16]。
1.2 工业用户时序可调节潜力指标体系
工业用户可调节潜力指标体系就是综合考虑用户行为影响因素和用户成本影响因素所构建的,它代表了工业负荷的调控价值。
1.2.1 工业用户行为特征指标
(1)订单需求
订单需求是表示用户基本生产行为的指标,用来表征用户生产周期及时间变化。该指标的表达式为
(1)
式中:C1该订单用电量需求;Pday为用户每天的用电量;ai为生产系数;T为生产周期。
(2)最大负荷小时利用数
最大负荷利用小时数是指用户年用电量与年最大负荷的比值。不同类型的工业负荷,其最大负荷利用小时数也不同,具体数值可见表1。

表1 各典型工业用户最大负荷利用小时数
(3)节能效益
节能成本指标表示工业用户需求响应所节约的电费,其公式为
C3=Eavoid*Mf+Epinc*Mp+Eginc*Mg
(2)
式中:C3为年所节约用电量;Eavoid表示峰时段削减的用电量;Mf表示峰时段的电价;Epinc表示平时段削减的用电量;Mp表示平时段的电价;Eginc表示谷时段削减的用电量;Mg表示谷时段的电价。
1.2.2 工业用户成本特征指标
(1)维修成本
维修成本是指工业用户需要对生产设备进行维修时的负荷特征。通过检修行为特征来衡量对工业负荷的检修能力和检修时的负荷变化特征。该指标的表达式如下
(3)
式中:C4为用户周期内维持成本;Ppeak为用户周期内用电高峰时段的最大峰值负荷;Psl为用户的安全生产保障负荷;Drest为用户连续厂休日最大天数;Dall为一个周期内总天数;M为用户生产成本。
(2)新增电能成本
新增电能成本用于衡量每日用户负荷变化剧烈程度和电网调峰能力,该值越大说明用户负荷变化越剧烈,同时也能体现电网调峰能力越强。该指标的表达式如下
(4)

(3)时间成本
时间成本用于衡量用户用电时间百分比,数值越大说明用户用电舒适度越高。该指标的表达式如下
(5)
式中:C6为企业生产周期T的时间成本。
2 工业用户时序调节潜力分析方法
本文提出一种基于多层反馈聚类模型和VMD-TCN的综合性方法来分析工业用户的潜力,具体流程图如图1所示。

图1 工业用户时序调节潜力分析流程图
2.1 基于三次样插值法的数据预处理
由于在采样中可能会导致采集的时间序列数据存在缺失值,因此要对工业负荷展开研究首先需要寻找出缺失数据并对其进行填补,以便展开后续的研究。
按照负荷功率曲线,定位到数据缺失点,并综合比较缺失值前后几天同时刻的负荷数据,通过构造三次样条插值拟合函数fa(x),对缺失数据点进行补全,得到完整数据。填充值公式可表示为
D(tm)=fa(tm)
(6)
式中:tm为负荷数据缺失时间点;D(tm)为tm点填充值。
2.2 基于多层反馈聚合模型的工业负荷聚类研究
单一的聚类模型受数据的影响较为严重,适应能力较弱,因此本文提出基于K-means和DNN的多层反馈聚类模型,旨在通过神经网络强大的自适应学习能力以及非线性映射能力,从负荷特性和可调节潜力特性两方面对用户进行综合聚类,为后续潜力分析奠定基础[18]。
2.2.1 基于一次聚类的工业用户负荷特性提取
K-means算法作为处理大量负荷数据的首选算法,具有多种优点,因此本文采用K-means算法对工业用户进行一次聚类[19]。流程图如图2所示。

图2 K-means算法流程图
最佳聚类数x轮廓系数[20]确定。轮廓系数公式如下
(7)
式中:A,B表示样本点的内聚度。轮廓系数S的取值范围为[-1,1],轮廓系数越大聚类效果越好。
2.2.2 基于二次聚类的工业用户潜力特征融合
二次聚类的输入为考虑用户行为影响因素和用户成本影响因素的指标数据。由于指标数据复杂且繁多,因此需要对其进行降维。本文采用主成分分析法(Principal component analysis,PCA)对工业负荷历史数据进行降维[21]。
在提取指标数据主成分时,需要根据贡献率选取前k个主成分,并将贡献率靠前的主成分作为输入进行二次聚类。贡献率表达式为

(8)
降维之后,对一次聚类输出结果进行二次聚类,本文采用自组织竞争神经网络(Self-organizing competitive neural network,SOM)[22]方法,步骤如下:
(1)归一化处理。将贡献率最高的主成分与竞争层中的权向量进行归一化处理,得到X*和Wj(j=1,2,…,m)。

(9)
(3)输出与调整。获胜的神经元可以调整权向量,获胜神经元输出为1,其余输出为0。
(10)
式中:μ表示学习速率,逐渐减小。
完成一个循环之后继续重复(1)~(3),直到学习速率μ=0,并输出最终结果。
2.2.3 基于K-means和DNN的多层反馈聚类模型
一次聚类结果代表了工业用户本身的负荷信息,二次聚类结果代表了工业用户的可调节潜力信息,二次结果通过反馈机制修正一次结果,在修正一次聚类误差的同时可以将工业用户的可调节潜力信息与原始负荷信息融合,从而得到具有可调节潜力考虑多重因素的处理数据,为后续分析调节潜力奠定基础。
基于此,本文提出基于K-means和DNN的多层反馈聚类模型,如图3所示。首先,利用K-means算法对工业用户进行聚类分析,判断不同负荷特性的用户。其次,针对同种负荷类型的用户,利用PCA对其进行降维,并作为输入进入SOM中得到二次聚类结果。最后,将二次聚类结果作为输入,利用DNN训练,修正一次聚类结果,最终得到综合考虑工业用户综合特性和多种影响因素的聚类结果。

图3 基于K-means和DNN的多层反馈聚类模型图
2.3 基于VMD-TCN的工业用户时序调节潜力分析
针对输入数据结构复杂、存在噪声、端点效应和虚假分量等问题,本文利用基于VMD-TCN算法的方法来分析工业用户的潜力。
将已聚合的数据代入到工业用户时序调节潜力模型中初步求得潜力数据,再进行基于VMD-TCN的潜力分析,主要分为三个部分。首先,通过VMD分解,得到不同频次的子模态,然后再将各个模态输入TCN网络输出各模态预测结果,将预测结果叠加输出负荷潜力上下限,最后进行一系列误差分析。
2.3.1 基于VMD算法的数据分解
采用交替方向乘子法(ADMM)解决变分问题,从中找到增加的拉格朗日L的鞍点,以解决原始最小化问题。由于VMD分解的优势,其子序列IMF分量个数h可以被人为设定,当选择到合适的分量个数,VMD分解出的各分量比一些传统分解技术(如WD小波分解,EMD经验模态分解)的分解结果更为清晰。采用中心频率法确定h值。
2.3.2 基于TCN网络的模态分析
基于TCN的工业负荷分析模型的整体架构如图4所示,主要分为输入部分、TCN网络残差模块部分和输出部分。


图4 基于TCN的负荷分析模型架构
3 算例分析
本文以某大型地区电网数据为例,对工业负荷的时序可调节潜力进行实例分析与验证。本文分别建立反向传播神经网络(BPNN)、变分模态分解法组合长短期记忆神经网络(VMD-LSTM)以及VMD-TCN共三种组合预测模型,并进行对比分析。
3.1 数据预处理
由于信号传输中断,传感器装置失灵等原因会导致采集到的数据出现随机性缺失,如图5所示为某个用户在一段时间内的负荷缺失情况,在经过数据填充预处理后,使用采样间隔为15 min的量测电表数据,该典型用户经三次样条插值处理后的情况如图6所示。

图5 某典型用户负荷缺失情况

图6 经三次样条插值后的某典型用户负荷情况
3.2 多层反馈聚类模型分析
针对经预处理以后的某地实测工业负荷数据,本文首先采用K-means算法对负荷进行一次聚类,其次根据轮廓系数确定一次聚类的最佳聚类数k=3,如图7所示。

图7 基于轮廓系数的一次聚类结果
最终可以得到三类不同特性的工业用户群,如图8所示。从图可以看出,每类用户相对于聚类中心的距离各不相同,子类3距离聚类中心的距离较近且各自距离中心的距离较为均匀,说明用户特性具有一定规律,可调节潜力较强;而子类1距离聚类中心的距离较远,说明用户随机性较强,可调节潜力较差。

图8 基于SOM的二次聚类结果
基于上述分析得到的三种不同特性的用户群体,因指标对其影响的不同,每一类用户的可调节潜力可能存在差异,因此还需分析各类用户的可调节潜力。
3.3 工业用户时序调节潜力分析
在实际应用中,可调节能力强的工业用户往往参与调节,因此基于上文分析出的可调节潜力能力,本节将采用子类3进行可调节潜力的分析。
3.3.1 基于VMD算法的负荷时间序列分解
由表2可知,当潜力上限模态分解数hup为5时,hup=4的中心频率为2 681.062和hup=5的中心频率4 274.791量级相同,因此潜力上限模态分解数hup取4。同样地,潜力下限模态分解数hdown为5时,hdown=4的中心频率和hdown=5的中心频率量级相同,因此潜力下限模态分解数hdown取4。

表2 不同k对应的中心频率
运用VMD算法对计算出来的潜力上下限数据进行分解,如图9所示,选取了2 500个数据点的分解结果。

图9 VMD分解结果
3.3.2 基于TCN算法的潜力分析
对每个模态分别进行TCN建模,并将每个模态所得到的结果进行求和重构,即可得到子类3某一天的时序可调节潜力的上下限。如图10所示。由图可知此工业用户在凌晨0点到6点时处于电价优惠区,可下调潜力明显较小,而此时可上调潜力明显较大;在7点到17点处于用电高峰区,可上调潜力小于可下调潜力;在晚高峰18点到20点时的可上调潜力和可下调潜力都较小,符合实际生产和用电需求。
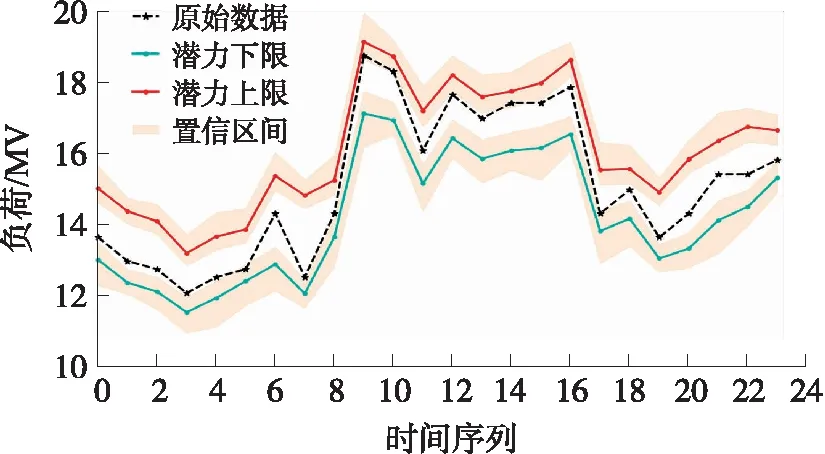
图10 TCN潜力分析结果
3.3.3 模型分析结果对比
为了验证本文所提算法的准确性,建立了BPNN和VMD-LSTM两种模型来对用户的可调潜力进行分析,并采用平均绝对误差百分比(MAPE)、均方根误差(RMSE)和R-Square决定系数(R2系数)作为评价指标对分析结果进行比较。对比结果见表3。

表3 不同方法下的分析质量对比
由表3可以看出本文所提的潜力分析模型表现最佳。VMD-TCN模型MAPE误差仅为0.017 5,RMSE误差仅为0.492 6,R2系数为0.972 4,较表现相对较优的VMD-LSTM模型的预测误差下降了近50%,本文所提的潜力分析模型达到了一个新的预测精度,完全验证了该模型框架的能力。
4 结论
本文从工业用户负荷调节潜力的角度出发,提出一种基于多层反馈聚类模型和VMD-TCN算法相融合的调节潜力分析方法,对聚类效果和预测精度有明显改善。并以某地实际数据为例,验证本文所提分类方法的性能优越性。算例结果表明:
(1)采用基于K-means和DNN算法的多层反馈聚类模型,基于K-means的一次聚类和基于DNN的二次聚类相互影响相互促进,改善了单一聚类模型寻类不佳的问题,提高了聚类效果,同时充分考虑了工业用户本身特性和成本特性对用户可调节潜力的改进能力。
(2)采用基于VMD-TCN的潜力分析算法,将负荷时间序列分解为不同中心频率的子模态,能够有效降低模型的复杂度。以多层聚类结果为基础,对不同模态分别建模后输入TCN网络可以有效提高模型精度,又能结合时效性问题,从而提升模型整体性能。与BPNN、VMD-LSTM神经网络对比,所提方法对用户潜力分析的误差更小,可为模型的整体精度提供可靠数据保证,从而提高准确性和效率。
(3)在多场景下对于不同用户具有适用性,可以有效分析用户在满足自身生产需求下参与新型电力系统削峰填谷,具有一定的工程应用前景。
猜你喜欢
知识经济·中国直销(2018年1期)2018-01-31
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国卫生(2016年7期)2016-11-13
儿童故事画报(2016年4期)2016-06-24
儿童故事画报(2016年4期)2016-06-24
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
电子设计工程(2015年6期)2015-02-27
计算物理(2014年2期)2014-03-11
