
融合多粒度语义特征的中文情感分析方法
2023-11-29 04:20:52任菊香刘忠宝
华东师范大学学报(自然科学版) 2023年6期
任菊香,刘忠宝
(1.山西工程科技职业大学 信息工程学院,山西 晋中 030619;2.北京语言大学 信息科学学院,北京 100083;3.泉州信息工程学院 软件学院,福建 泉州 362000)
0 引 言
近年来,中文情感分析受到研究人员的广泛关注并取得了长足进步,但现有研究存在语义理解能力弱和情感特征表达不充分等问题.中英文语言的差异性,使得英文文本情感分析取得的研究成果无法直接迁移到中文文本,极大地增加了中文情感分析的研究难度.鉴于此,本文针对中文文本的特殊性以及情感分析的实际需求,在字、词特征的基础上,引入部首特征和情感词性特征,利用双向长短期记忆网络(bidirectional long short-term Memory,BLSTM)、注意力机制(attention mechanism)、循环卷积神经网络(recurrent convolutional neural network,RCNN)等模型,提出了融合字、词、部首、词性等多粒度语义特征的中文文本情感分析方法.
本文研究的创新点主要体现在3 个方面: 一是针对中文文本的特殊性以及情感分析的实际需求,围绕大数据环境下中文情感分析问题展开研究,选题具有一定的新意;二是研究融合了情报学、语言学、信息科学、人工智能等学科的诸多前沿理论和方法,采用多学科交叉的模式来分析问题、解决问题,在研究方法和手段上具有一定的创新性;三是深度融合字、词、部首、词性等多粒度语义特征,提出了中文文本情感分析方法,进一步丰富了中文情感分析的理论体系和方法体系.具体而言,本文主要的学术贡献: 一是针对中文文本的特殊性,利用汉字部首助力中文文本语义理解;二是深度融合字、词、部首、词性等多粒度语义特征,进一步提升了中文情感分析性能.
1 相关研究
现有研究主要沿着两条技术路线展开: 传统方法和深度学习方法.传统方法利用情感词典或机器学习模型进行情感分析: 基于情感词典的方法能够准确反映文本的非结构化特征,易于分析和理解,但随着大量新词的出现,情感词典覆盖范围有限,无法解决词形、词性变化问题;基于机器学习的方法比起构建情感词典具有一定优势,但该方法需要事先给定大量特征,效率较为低下,且机器学习模型无法学习文本数据的深层次语义特征.鉴于深度学习模型在特征提取和语义表征方面的优势,研究人员开始关注该模型并将其引入文本情感分析.目前,基于深度学习模型的文本情感分析主要从字、词和词性等不同粒度角度开展研究.
基于字粒度的文本情感分析,以字为基本单元构造字向量,通过深度学习模型提取字向量的深层次语义特征进行文本情感分析.刘文秀等[1]为解决文本情感分析对分词的依赖性和词的歧义性问题,提出了一种基于变换器的双向编码器表征技术(bidirectional encoder representations from transformer,BERT)[2]和BLSTM 的文本情感分析模型,该模型将BERT 预训练的字向量替代传统方法的词向量,然后利用BLSTM 模型进行特征提取,进而实现情感识别;与长短期记忆网络(long short-term memory,LSTM)、文本卷积神经网络(text convolutional neural network,TextCNN)和BERT-LSTM 等模型的对比实验表明,该模型情感分析性能优良,其F1值最高提升了6.78%.徐凯旋[3]等融合BERT 模型和TextCNN 模型,提出了BERT-TextCNN 混合模型,该模型利用BERT 模型获取具有句子全局特征的字向量,然后将其输入TextCNN 模型抽取局部特征.
基于词粒度的文本情感分析,以词为基本单元构造词向量,通过深度学习模型提取词向量的深层次语义特征进行文本情感分析.张海涛等[4]基于卷积神经网络(convolutional neural network,CNN)构建微博舆情情感识别模型,微博话题数据集上的实验结果表明,该模型相较于传统方法具有一定的优势,能够实现高效的微博舆情情感分析;曹宇等[5]提出了一种基于双向门控循环单元(bidirectional gate recurrent unit,BGRU)模型的中文文本情感分析方法,该方法相较于BLSTM 模型,其模型结构更为简单,训练速度更快,ChnSentiCorp 语料集上的实验结果表明,该模型的F1值达到了90.61%.为解决财经微博文本中网民情感状态转移的时序分析问题,吴鹏等[6]提出了基于认知情感评价模型和LSTM 模型的财经微博文本情感识别模型,海量微博数据集上的实验结果表明,该模型的准确率达到89.45%,远高于支持向量机(support vector machine,SVM)和半监督递归自编码器(semi-supervised recursive auto encoder,SS-RAE);胡任远等[7]提出了多层协同卷积神经网络模型(multi-level convolutional neural network,MCNN),并与BERT 模型相结合,提出了 BERT-MCNN 混合模型.缪亚林等[8]提出的融合CNN 与BGRU 模型的文本情感识别模型,豆瓣影视评论数据集上的实验结果表明,该模型较于相同复杂度的CNN-BLSTM 模型,其分类准确率和训练速度分别提高了2.52%和41.43%.
一些研究人员注意到字、词在情感分析中的作用,提出了融合字粒度与词粒度的情感分析方法,例如,李平等[9]提出的双通道卷积神经网络(dual channel convolutional neural network,DCCNN)模型,该模型采用不同通道进行卷积运算,其中一个通道为字向量,另一个为词向量,通过不同尺寸的卷积核,提取句子特征,实验结果表明,该模型的正确率和F1值相较于传统方法有了显著提升,均达到95%以上;张柳等[10]利用多尺度卷积核,构建基于字、词向量的多尺度卷积神经网络CNN 模型,并将其应用于微博评论情感识别;陈欣等[11]针对深度学习模型无法充分获取文本语义特征的问题,在融合字、词向量的基础上,分别利用CNN 模型和BLSTM 模型进行情感正负分类和主客观分类研究.
基于词性粒度的文本情感分析,以中文词语的词性作为主要特征进行文本情感分析.赵富等[12]针对现有研究提取文本特征能力不足的问题,提出了一种融合词性的双注意力机制BLSTM 模型,实验结果表明,与未融合词性的模型相比,该模型在4 类语料集上情感识别的准确率分别提高了1.35%、1.25%、0.93%和1.5%.王义等[13]利用CNN 模型的多个通道,分别对词向量、词向量与词性融合的词性对向量以及字向量进行卷积运算,建立了细粒度的多通道CNN 模型;实验结果表明,与CNN 模型相比,该模型的准确率和F1值上均有显著提升.
对相关研究进行梳理可以发现,研究人员围绕字、词、词性等多粒度特征进行的情感分析研究,取得了一系列研究成果.随着研究的深入,也面临一些重要挑战: 首先,中文文本情感分析研究大多借鉴英文文本情感分析方法,忽略了中文(象形文字)与英文(拉丁文字)的本质区别;其次,一些研究虽然认识到字特征、词特征、词性特征对于情感分析的重要性,试图将字特征、词特征、词性特征进行融合,但融合方式太过粗糙,严重影响了文本的语义理解能力;最后,除字特征、词特征、词性等特征外,能否引入更多特征实现更为高效的情感分析尚未深入探讨.这些问题是本文尝试解决的主要问题.
2 研究方法
中文情感分析具有2 个显著特点: 一是汉字是组成中文文本的基本单元,每个汉字的部首蕴含了丰富的语义信息;二是词语的词性,特别是动词、形容词、副词等,其包含了丰富的情感信息.因此,与之前的研究工作不同,本文引入深度学习模型,利用字、词、部首、词性等多粒度语义特征对中文文本进行全面建模,充分挖掘蕴含其中的潜在语义信息和情感信息,以期进一步提高中文情感分析性能.
本文整体研究框架如图1 所示,由数据输入层、向量表示层、特征提取层和结果输出层等4 部分组成: 数据输入层将中文文本转换为字、字级部首、词、词级部首以及词性文本等5 类输入数据;向量表示层利用向量表示模型对输入数据进行向量化表示,得到特征向量;特征提取层利用双向长短期记忆网络、注意力机制、循环卷积神经网络等模型,从5 类特征向量中提取深层次语义特征;结果输出层对特征提取层得到的语义特征进行融合,通过全连接层和分类函数,得到情感识别结果.

图1 研究框架Fig.1 Research framework
2.1 数据输入层
数据输入层的主要作用是对中文文本进行预处理并生成输入数据.中文文本的特点是: 首先,字与词都能表达文本语义;其次,部首是汉字的固有属性,也是语义信息的重要载体;最后,词性因其包含情感信息,故在情感分析中发挥重要作用.基于上述分析,本文将中文文本转换为字、字级部首、词、词级部首和词性文本等五类输入数据.为了便于理解,本文以“比预想的好很多”文本为例,给出如图2 所示的文本转换过程.
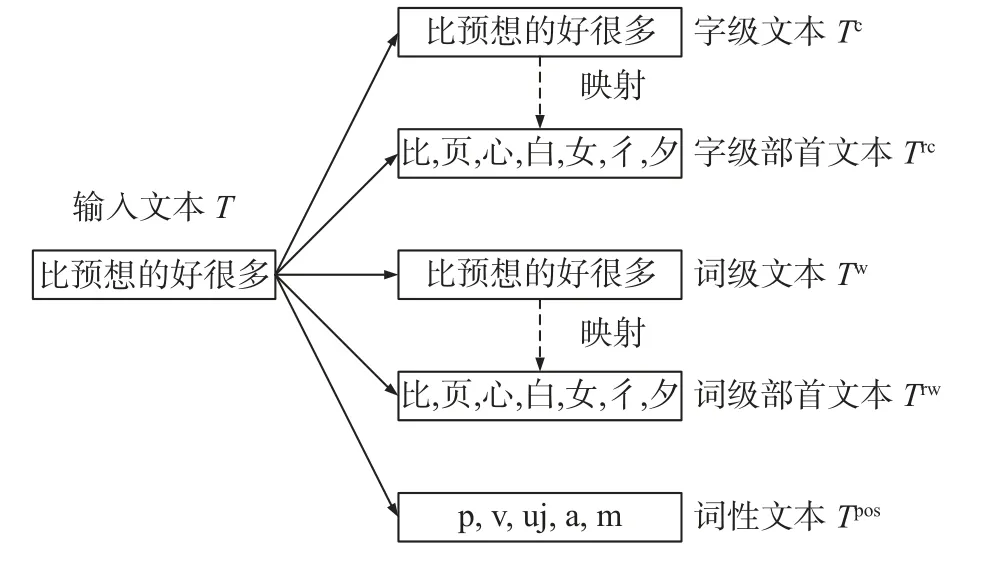
图2 文本转换过程实例Fig.2 Example of text transformation process
在图2 中,对于输入文本T,它有n个字组成,即Tc={c1,c2,···,cn},其中Tc表示字级文本,ci(i1,2,···,n)表示组成输入文本T的字;利用jieba 分词工具将输入文本T切分为m个词,即Tw={w1,w2,···,wm},其中Tw表示词级文本,wi(i1,2,···,m)表示组成输入文本T的词;根据新华字典的部首映射关系,分别得到字级文本Tc和词级文本Tw的字级部首文本Trc和词级部首文本Trw,即Trc={cr,1,cr,2,···,cr,n},其中cr,i(i1,2,···,n)表示字级部首,Trw={wr,1,wr,2,···,wr,n},其中wr,i(i1,2,···,n)表示词级部首;利用jieba 词性分析工具将词级文本Tw转换为词性文本Tpos,即Tpos={pos1,pos2,···,posm},其中posi(i1,2,···,m)表示词对应的词性.标识符号与词性的对应关系如表1 所示.由上述分析可知,字级文本Tc与字级部首文本Trc规模相当,词级文本Tw、词级部首文本Trw、词性文本Tpos规模相当,即|Tc|=|Trc|,|Tw| =|Trw| =|Tpos|. 这里|·|表示文本规模.

表1 标识符号与词性的对应关系表Tab.1 Relationship between the identifiers and part-of-speech of words
2.2 向量表示层
向量表示层利用Word2Vec 词嵌入方法,对5 类输入数据{Tc,Trc,Tw,Trw,Tpos}进行训练,得到相应的向量化表示:Ec={ec,1,ec,2,· ··,ec,n}表示字向量集合,其中ec,i(i1,2,···,n)表示字向量;Erc={erc,1,erc,2,· ··,erc,n}表示字级部首向量集合,其中erc,i(i1,2,···,n)表示字级部首向量;Ew={ew,1,ew,2,· ··,ew,m}表示词向量集合,其中ew,j(j1,2,···,m)表示词向量;Erw={erw,1,erw,2,···,erw,m}表示词级部首向量集合,其中erw,j(j1,2,···,m)表示词级部首向量;Epos={epos,1,epos,2,···,epos,m}表示词性向量集合,其中epos,j(j1,2,···,m)表示词性向量.
具体而言,上述输入数据向量化表示均利用Word2Vec 系列方法中的Skip-gram 模型和层次化softmax 策略来实现.这里以词向量为例介绍Skip-gram 模型的工作原理.Skip-gram 模型通过中心词来预测上下文背景词的概率.具体而言,该模型将每个词语都表示为中心词的词向量和背景词的词向量,以此来计算中心词和待预测背景词之间的条件概率.相应计算公式为
式(1)中:wc表示中心词;wo表示背景词;vc表示中心词的词向量;vo表示背景词的词向量;N表示词典大小;i表示单词在词典中的索引.
2.3 特征提取层
特征提取层利用BLSTM 模型、注意力机制、RCNN 模型对5 类特征向量进行深层次语义提取.基本思路: 利用BLSTM 模型与注意力机制,将部首向量分别与字向量、词向量进行特征融合,得到字与字级部首的融合特征以及词与词级部首的融合特征;利用RCNN 模型对词性向量进行特征提取,得到词性特征.工作原理及工作流程如下.
(1)字、词、部首是中文文本的固有属性,不会随具体下游任务的改变而改变,具有鲜明的序列化特征.BLSTM 模型具有串联的网络结构,非常适合处理序列化数据.因此,本文选用BLSTM 模型处理字特征、词特征和部首特征.BLSTM 模型通过拼接具有正向和反向的LSTM 模型的特征向量,实现了上下文语义特征的有效利用.LSTM 模型工作原理对应的公式为
式(2)中:xt为时刻t的输入向量;it、ft、ot分别表示当前时刻的输入门、遗忘门和输出门;Wi、Wf、Wo分别表示输入门、遗忘门和输出门的权重矩阵;bi、bf、bo分别表示输入门、遗忘门和输出门的偏置向量;ct表示当前时刻的记忆单元;t-1 表示当前时刻t的后一时刻;Wc、bc分别表示当前信息的权重矩阵和偏置向量;sigmoid(·)和tanh(·)为激活函数;ht为当前时刻的输出向量;⊙为哈达玛积;×表示矩阵乘法.
BLSTM 模型工作原理对应的公式为
式(3)中:xt为t时刻的输入向量;分别表示正向和反向LSTM 模型得到的特征向量;yt为当前时刻tBLSTM 模型得到的特征向量;t+1 表示当前时刻t的前一时刻.
具体工作流程: 首先,将BLSTM 模型的初始状态置为0;然后,将字向量集合Ec和词向量集合Ew分别输入BLSTM 模型,得到字特征向量集合yc、词特征向量集合yw,以及BLSTM 模型存放的状态值和yc={yc,1,,yc,2,· ··,yc,n},其中yc,i(i1,2,···,n)表示字特征向量;yw={yw,1,yw,2,···,yw,m},其中yw,j(j1,2,···,m)表示词特征向量.工作流程对应的公式为
(2)注意力机制能够对文本的某些关键特征赋予较高权重,以降低冗余信息的干扰并提高关键特征对情感分析结果的贡献度.文本的情感极性通常由某些关键词或短语决定.注意力机制通过学习文本上下文语义,自动感知有助于判别情感倾向的关键特征,并基于此融合不同特征.在实现方面,注意力机制通过点积方式实现字特征向量集合yc、字级部首向量集合Erc,以及词特征向量集合yw、词级部首向量集合Erw的融合,进而得到融合后的字级向量(i1,2,···,n),以及融合后的词级向量(j1,2,···,m).具体实现对应的公式是
其中AAtt表示注意力机制.
(3)将字级向量erc,i(i1,2,···,n)与词级向量erw,j(j1,2,···,m)作为输入向量,分别输入初始化的BLSTM 模型,并将之前BLSTM 模型存放的状态值、传递给当前BLSTM 模型作为初始状态,得到输出字–部首特征向量集合yrc以及词–部首特征向量集合yrw,且yrc={yrc,1,,yrc,2,···,yrc,n},其中yrc,i(i1,2,···,n)表示字–部首特征向量;yrw={yrw,1,yrw,2,· ··,yrw,m},其中yrw,j(j1,2,···,m)表示词–部首特征向量.其工作流程相应公式为
(4)利用基于多层感知机方式实现的注意力机制分别对yrc和yrw进行特征融合,得到输出向量Vc和Vw.计算过程是
式(7)中:α表示注意力机制;M表示经过多层感知机后的权重矩阵;W和b分别为待训练的权重矩阵和偏置向量;tanh 为激活函数;uc和uw为随机初始化的上下文向量.
(5)词语的词性包含了丰富的情感倾向,是情感分析任务关注的重要特征之一.文本情感分析需要模型具备两大能力: 一是能够较好地提取文本的序列特征,二是能够准确地提取文本中的动词、形容词等词性特征.BLSTM 模型只能提取文本的序列特征,无法提取词性特征.因此,该模型无法用于词性特征提取.RCNN 模型能够利用RNN 模型中的串行结构学习文本的上下文依赖关系,也能够利用CNN 模型中的池化结构保留并捕捉关键词的词性特征.因此,本文选用该模型提取词性特征.具体而言,首先,将词性向量集合Epos输入BLSTM 模型,得到词性特征向量集合Ypos,其中Ypos{ypos,1,ypos,2,···,ypos,m};然后,利用拼接方式融合词性向量集合Epos与词性特征向量集合Ypos,通过最大池化(max-pooling)操作得到最终的输出向量Vpos. 其工作流程相应公式是
2.4 结果输出层
结果输出层负责生成情感识别结果.具体流程: 首先,对输出向量Vc、Vw、Vpos进行特征融合,得到融合后的特征向量Vy;然后,将融合后的特征向量Vy输入全连接(fully connected,FC)神经网络,得到Oy;接着,利用softmax 函数进行归一化处理,得到概率输出P;最后,选择概率最大的值作为情感识别结果y.其工作流程相应公式是
3 实验分析
3.1 实验所用的数据集
实验采用的数据集是NLPCC(natural language processing and Chinese computing)数据集[14],该数据集共有44 875 个样本,其情感标签有喜好、悲伤、厌恶、愤怒、高兴和其他等6 种.该数据集的清洗及预处理流程如下.
(1)文本过滤.研究对象是中文文本,故需去掉非中文数据.
(2)数据清洗.去除数据集中非文本数据类型,如控制符、表情符号、HTML(hyper text markup language)标签、URL(uniform resource locator)等.
(3)对数字和英文字母归一化处理.将全角字符全部转换为半角字符.
(4)对标点符号归一化处理.将数据集中的标点符号统一转化为中文标点符号.
(5)大小写转换.将数据集中的大写字母转化为小写字母.
(6)繁简转换.利用Python 工具包OpenCC 将数据集中的繁体字转换为简体字.
(7)人工合并数据集中多余的空格.
实验中将NLPCC 数据集划分为训练集、验证集和测试集,其比例为6∶2∶2.
3.2 实验设置
(1)实验环境: 操作系统为Window10;内存大小为16 GB;编程语言采用Python3.7.0;深度学习框架采用PyTorch1.7.1;训练优化器为Adam;词向量工具采用Gensim4.1.2;GPU 为NVIDIA GeForce GTX 1660Ti.
(2)参数设置如表2 所示.其中,epoch 为迭代次数,表示训练时需要遍历多少次训练集;batch_size为批处理数量,表示每次训练输入模型的样本数量;learning_rate 表示模型的学习率;dropout 表示丢弃率,用来避免“过拟合”,以提升模型的泛化能力;hidden_dim 表示隐藏层的神经元数目.

表2 实验参数Tab.2 Experimental parameters
3.3 评价指标
采用精确率(precision,P)、召回率(recall,R)、调和平均值(F1-score,F1)来衡量情感识别效果,其计算分别公式为
式(10)中:NTP表示被正确分类的正例样本(真正例(true positive,TP))的数量;NFP表示被错误分类的正例样本(假正例(false positive,FP))的数量,NFN表示给错误分类的负例样本(假负例(false negative,FN))的数量;P表示模型预测正确的正例样本占预测为正例的样本的比例,R表示模型预测正确的正例样本中占实际为正例的样本的比例.
3.4 实验结果与分析
3.4.1 实验模型
为了验证本文所提方法的有效性,引入多个主流模型进行对比实验.对比模型如下.
(1)FastText[15]对文本的词向量进行平均池化,实现文本的向量化表示,并基于此进行情感识别.
(2)BLSTM[16]是双向LSTM,为RNN 的变种,利用BLSTM(Ec)和BLSTM(Ew)分别对字文本和词文本进行情感识别,即同时将字向量集合Ec和词向量集合Ew作为输入.
(3)CNN[4]通过卷积层对词向量进行卷积运算,进而得到特征向量,并基于此进行情感识别.
借鉴文献[17]提出的多通道双向长短期记忆网络,结合本文研究对象,本文提出了Two BLSTMs 和Four BLSTMs,分别对字、词文本以及字文本、字级部首文本、词文本、词级部首文本建模.
(4)Two BLSTMs 使用2 个BLSTM 分别对字文本和词文本进行建模,将二者的输出向量进行拼接并进行情感识别.
(5)Four BLSTMs 使用4 个BLSTM 分别对字文本、字级部首文本、词文本、词级部首文本进行建模,将4 个通道经BLSTM 的输出向量进行拼接并进行情感识别.
(6)BLSTM_Att[18]使用双向LSTM,并引入注意力机制赋予特征不同的关注度.利用BLSTM_Att(Ec)和BLSTM_Att(Ew)模型分别对字文本和词文本进行情感识别,即同时将字向量集合Ec和词向量集合Ew作为输入.
借鉴文献[17]提出的多通道双向长短期记忆网络以及文献[18]提出的BLSTM_Att 模型,结合本文研究对象,本文提出了Two BLSTM_Atts 和Four BLSTM_Atts,分别对字、词文本以及字文本、字级部首文本、词文本、词级部首文本建模.
(7)Two BLSTM_Atts 使用2 个BLSTM-Att 分别对字文本和词文本进行建模,将二者的输出向量进行拼接并进行情感识别.
(8)Four BLSTM_Atts 使用4 个BLSTM-Att 分别对字文本、字级部首文本、词文本、词级部首文本进行建模,然后将4 个通道上的BLSTM-Att 的输出向量进行拼接并进行情感识别.
(9)Cross BLSTM_Atts 在本文所提方法的基础上去除词性特征.
(10)BERT-BLSTM[1]利用BERT 模型构造字向量,然后利用BLSTM 进行特征提取,进而实现情感识别.
(11)RCNN-BLSTM_Atts 为本文所提方法.
3.4.2 结果与分析
各模型在数据集NLPCC 上的实验结果如表3 所示.

表3 实验结果Tab.3 Experimental results
由表3 值可以看出,FastText 的F1值最低,仅为70.15%,其主要原因是该模型对词向量进行平均池化造成了语义丢失.BLSTM(Ec)、BLSTM(Ew)、Two BLSTMs、Four BLSTMs 的F1值分别为75.16%、79.35%、80.80%和81.19%,而BLSTM_Att(Ec)、BLSTM_Att(Ew)、Two BLSTM_Atts、Four BLSTM_Atts 的F1值分别是77.39%、80.62%、81.03%和81.23%,即引入注意力机制的模型,F1值分别提升了2.23%、1.27%、0.23%和0.04%.这表明注意力机制对于中文情感分析具有重要作用.
BLSTM(Ew)模型的F1值为79.35%,CNN 模型的F1值为79.80%,CNN 模型的F1值与BLSTM(Ew)基本相当,仅提高了0.45%.分析发现,这两类模型均是利用词特征的单通道模型,区别在于CNN 模型的池化结构能够捕捉到丰富的文本语义特征,BLSTM 模型的串行结构能够学习到上下文的长期依赖关系.
Two BLSTMs 和Two BLSTM_Atts 同时利用字特征和词特征的双通道模型,相较于只利用字或词向量的单一模型BLSTM(Ec)、BLSTM(Ew)、BLSTM_Att(Ec)、BLSTM_Att(Ew),其F1值均有一定提升.其中,Two BLSTM_Atts 的F1值相较于BLSTM(Ec)提高了5.87%.这表明同时利用字、词特征,有助于提高中文情感分析性能.
Four BLSTMs 和Four BLSTM_Atts 的F1值相较于Two BLSTMs 和Two BLSTM_Atts 均有一定提升,表明部首特征对于中文情感分析具有一定作用.
此外,Cross BLSTM_Att 的F1值相较于Four BLSTM_Atts 提高了1.52%,相较于Four BLSTMs 提高了1.56%.对比这3 类模型可以发现,Four BLSTMs 和Four BLSTM_Atts 模型只将特征向量通过简单拼接进行特征融合,在特征提取过程中,字、词与部首特征均未进行任何信息交互;反观Cross BLSTM_Atts 模型,其通过BLSTM 模型提取字、词特征,并利用点积注意力机制与字级部首向量和词级部首向量进行信息交互与融合,使得融合后的特征向量能从字、词、部首的深层次语义特征中感知情感倾向.
BERT-BLSTM 的F1值为83.14%,识别效果优于Cross BLSTM_Atts 模型,其主要原因是:BERT 模型可以动态地表示文本向量,并能根据情感分析任务对其语义表征能力进行微调,生成更为准确的语义特征,因此其情感识别性能更优.
本文所提模型的F1值达到了84.80%,超过了所有的对比模型: 相较于Cross BLSTM_Att 提升了2.05%;相较于BERT-BLSTM 提升了1.66%.这表明,词性特征对于情感分析至关重要.RCNN 模型既能对词性文本序列进行双向建模,又能通过池化操作从词性文本筛选出对情感表达具有显著作用的词性特征.通过与字–部首特征、词–部首特征进行特征融合,可得到更优的情感分析结果.
4 结 论
本研究基于中文文本的特殊性以及情感分析的实际需求,充分利用部首特征和情感词性特征,深度融合BLSTM 模型、注意力机制、RCNN 模型,提出了一种融合字、词、部首、词性等多粒度特征的中文文本情感分析方法,并在数据集NLPCC 上进行了对比实验.结果表明,本文方法的F1值较之其他模型均有一定的提升.本文研究尚存在一些不足,例如,未对中文文本的情感进行更细粒度的分析,没有探究计算效率提升路径与策略等.此外,如何更好地捕捉不同粒度特征之间的关联和交互也是未来研究的重点.
猜你喜欢
小学生学习指导·低年级(2024年8期)2024-12-31 00:00:00
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
小学生学习指导(低年级)(2021年3期)2021-07-21 03:02:26
开放教育研究(2020年2期)2020-03-31 01:54:14
作文周刊·小学二年级版(2019年12期)2019-04-26 12:37:56
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
