
基于EEMD与GWO-SVM的石化机组轴承故障诊断
2023-11-28 05:38:08朱俊杰张清华朱冠华苏乃权
自动化与仪表 2023年11期
朱俊杰,张清华,朱冠华,苏乃权
(1.吉林化工学院 信息与控制工程学院,吉林 132022;2.广东石油化工学院 广东省石化装备故障诊断重点实验室,茂名 525000)
随着石化工业的快速发展,石化机组装置日益趋于大型化、复杂化。由于石化机组工况复杂,长期运行在高温、高速、重载等环境条件下,其中石化机组轴承作为关键的机械零部件一旦出现故障,若不能及时诊断将会引发重大的经济损失和安全事故[1-2]。
在轴承故障诊断技术发展的过程中,基于振动信号的诊断方法是目前比较有效的检测方法[3]。经验模态分解(empirical mode decomposition,EMD)方法在处理旋转机械故障信号方面得到了广泛地应用,但是存在模态混叠以及端点效应问题,它无法准确揭示信号特性信息[4]。为了缓解EMD 中出现的问题,提出了集合经验模态分解(EEMD)。文献[5]利用EEMD 将流速信号分解为一系列的本征模态函数,通过小波阈值降噪构造了非线性阈值函数,有效地降低超声水表受到的噪声干扰;文献[6]采用EEMD 结合快速峭度图的故障诊断方法,从含有强烈背景噪声的信号中成功提取出减速器齿轮箱的早期微弱故障特征。
支持向量机(support vector machines,SVM)作为一种基于统计学的分类模型方法能很好地解决小样本下的模式识别问题,在故障诊断领域被广泛应用。但其性能容易受到惩罚因子c 与核函数参数g 的选择影响[7]。为此针对SVM 参数选择与智能优化算法相结合,提高其故障分类准确率。文献[8]通过构建信息熵和合成峭度优化的变分模态分解(variational mode decomposition,VMD),利用粒子群(particle swarm optimization,PSO)优化参数对轴承进行故障诊断,解决变分模态分解参数人为确定的问题,并能够实现轴承故障的精确诊断;文献[9]利用EMD 对压力信号和振动信号进行筛选,通过计算其能量值构造特征向量,最后对比不同优化算法得出遗传算法(genetic algorithm,GA)优化后SVM在小样本、非线性、高维模式识别问题的优势。
本文采用EEMD 分解构建特征矩阵,利用GWO算法构建GWO-SVM 故障诊断模型,最后将本文方法与未优化的SVM 和传统优化算法的SVM 模型进行对比,验证了所提方法的有效性和优越性。
1 基本原理
1.1 EEMD 算法
石化机组发生故障时,会产生大量的非线性、非平稳信号。集合经验模态分解通过引入噪声来协助分析的方法以及平均值的思想很好地解决了模态混叠的问题[10]。EEMD 方法本质是一种叠加高斯白噪声的多次经验模式分解,利用白噪声频谱均匀分布的特性,对待分析信号中加入白噪声,在不同时间尺度的信号可以自动分离到与其适应的参考尺度上去。噪声经过多次的平均计算后会相互抵消,从而有效抑制了模态混叠的产生[11]。EEMD 分解步骤如下:
步骤1将正态分布的白噪声加到原始信号上,得到新的信号:
式中:xi(t)为第i 次得到的新信号;x(t)为原始信号;ni(t)为第i 次加入的白噪声序列。
步骤2将加入白噪声的新信号进行EMD 分解,得到各IMF 分量:
式中:ci,j(t)为第i 次加入白噪声分解得到的第j 个IMF;ri,j(t)为残余函数;J 为IMF 的数量。
步骤3重复M 次步骤1 和步骤2,得到一系列每次分解的IMF 分量:
步骤4将每次得到对应的IMF 分量进行平均处理得到最终的EEMD 分解结果:
式中:ci,j(t)为EEMD 分解的第j 个IMF,i=1,2,…,M,j=1,2,…,J。
1.2 样本熵
样本熵是一种时间序列复杂度表征参数,是衡量时间序列的复杂性和维数变化时序列产生新模式概率的大小,产生新模式的概率越大,序列的复杂性程度越高,熵值就越大[12]。设长度为N 的时间序列X={x(1),x(2),…,x(N)},其样本熵的计算步骤如下:
步骤1将时间序列X 构造成m 维矢量,即
步骤2定义X(i)与X(j)间的距离d[X(i),X(j)],为两者对应元素中差值最大的一个,即:
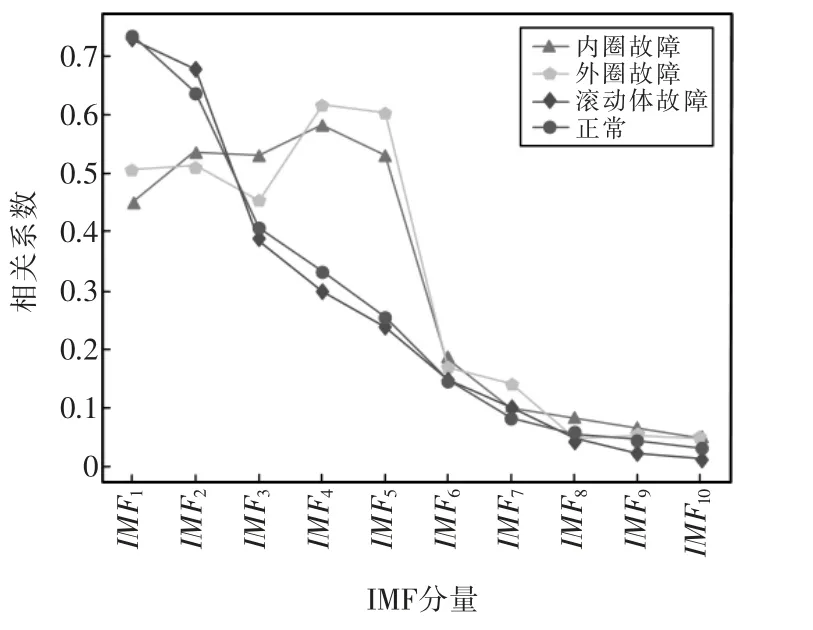
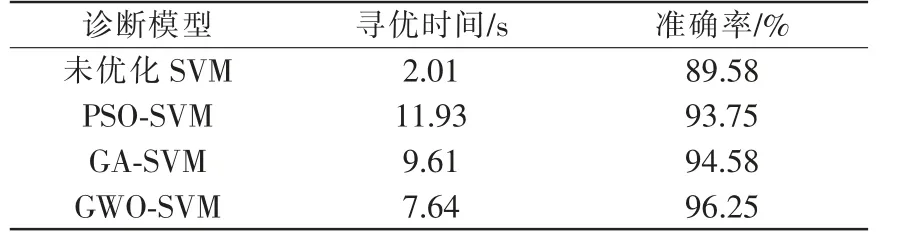
步骤3给定阈值r>0,统计d[X(i),X(j)] 计算其平均值,即: 步骤4令m=m+1,重复步骤1、步骤2 和步骤3,得: 当时间序列X(i)的长度N 为有限值时,样本熵为 灰狼优化算法为文献[13]通过自然界中灰狼群体等级制度以及狩猎行为提出了一种新的群体智能优化算法。GWO 算法具有收敛性能强、参数少等特点,能够实现目标参数的优化问题。由于其独特的自适应收敛因子和信息反馈,可以实现局部搜索和全局搜索之间的平衡,在问题的准确性和收敛速度方面有良好地表现[14]。 灰狼优化算法中狼群根据社会等级依次记为头狼α、β 狼、δ 狼和ω 狼。将α 作为最优解个体的适应度最优,次优解β,最佳解决方案δ,剩下候选解为ω。狩猎过程由α、β、δ 进行,ω 围绕α、β、δ 来更新位置,进行跟踪围剿。GWO 算法步骤如下: 步骤1包围猎物 灰狼位置和灰狼与猎物间的距离为 系数向量为 式中:t 为迭代次数;Xp为猎物的位置向量;X 为灰狼的位置向量;a 为收敛因子;r1和r2为随机向量,模取[0-1]之间的随机数。 步骤2追捕狩猎 在狩猎过程中猎物实际位置未知,α、β 和δ 狼通过识别猎物位置带领ω 狼对猎物进行包围。灰狼个体跟踪猎物位置的数学模型描述如下: 式中:X 和D 分别为α、β 和δ 当前位置和α、β、δ 与其他ω 间的距离。 狼群中ω 个体向α、β 和δ 前进的步长和方向为 ω 最终位置为 GWO-SVM 模型流程如图1 所示,GWO 算法优化SVM 模型相关参数步骤如下: 图1 GWO-SVM 模型流程Fig.1 Flow chart of GWO-SVM model 步骤1设置狼群数量,最大迭代次数,SVM 惩罚因子c 与核函数参数g 的范围; 步骤2随机产生初始灰狼种群; 步骤3根据初始设置范围参数的c 和g,通过SVM 对训练集进行训练得到准确率作为灰狼的适应度; 步骤4计算灰狼个体的适应度值,根据最好的适应度值将灰狼分为α、β、δ 狼群,更新灰狼中每个个体的位置和适应度; 步骤5若达到最大迭代次数,寻优结束,输出最优的参数c 和g,获得最优SVM 模型;否则跳转步骤4 继续寻找参数。 本文提出用灰狼算法来优化支持向量机模型,通过EEMD 分解和样本熵对轴承故障特征进行提取,经过GWO-SVM 模型对轴承进行故障分类。本文故障诊断流程如图2 所示,步骤如下: 图2 故障诊断流程Fig.2 Flow chart of fault diagnosis 步骤1采集轴承4 种不同状态的振动信号进行EEMD 分解,得到对应的IMF 分量; 步骤2计算各IMF 分量与原始信号的相关系数,根据相关性强度筛选相关系数重要的IMF 分量并计算其样本熵,构造特征向量; 步骤3分别对轴承4 种不同状态进行标签处理,由得到的样本熵将数据集划分为训练集和测试集; 步骤4将训练集输入GWO-SVM 模型,得到最优参数c 和g,最后再将测试集输入优化好的GWO-SVM 模型进行验证,得到故障诊断结果。 为了验证本文所提方法的有效性,采用的数据集为石化机组实验平台,平台主要由多级离心式空气压缩机组、振动加速度传感器、固定架、数据采集器等组成,如图3 所示。实验过程选取采集器EMT490采集正常状态下的无故障振动加速度时域信号,然后更换故障件轴承:滚珠缺失、轴承外圈磨损、轴承内圈磨损进行信号采集。其中电机转速1000 r/min,电机额定功率11 kW,采集频率为1024 Hz。 图3 石化机组故障诊断实验平台Fig.3 Experimental platform for fault diagnosis of petrochemical units 在石化机组故障诊断实验平台上分别采集外圈故障、内圈故障、滚动体故障和正常状态4 种状态下的轴承振动信号。每种状态分别随机采集150组样本数据,4 种状态共600 组样本数据,每组样本数据点为1024。将600 组样本按照6∶4 的比例随机划分,其中训练集样本360 组,测试集样本240 组。 利用EEMD 对以上轴承4 种不同状态的原始信号进行分解,得到每种状态下10 组IMF 分量。由于相关系数能够体现2 组信号相关性大小的参量,相关系数越大,则2 组信号越相似,反之亦然。为得到更多有效特征信息,通过计算各IMF 分量的相关系数,提取原始振动信号重要特征,去除相关的虚假分量。IMF 分量相关系数计算公式如下: 式中:xi为原始振动信号;yi为IMF 分量;N 为振动信号长度;xˉ和yˉ为对应信号平均值。4 种故障类型各IMF 分量的相关系数如图4 所示。 图4 4 种故障状态相关系数Fig.4 Correlation coefficients of 4 fault states 以下取值范围为相关性强度:相关系数0.8~1.0极强相关;0.4~0.6 中等强度相关;0.2~0.4 弱相关;0.0~0.2 极弱相关或无相关。选取相关系数大于0.2相关性较强的IMF 分量,保留前5 个IMF 分量,分别求出4 种故障类型样本熵特征向量;同时,分别对轴承4 种不同状态进行标签处理。以每种状态下的一个样本为例,其样本熵特征向量如表1 所示。 表1 样本熵特征向量Tab.1 Sample entropy feature vectors 在GWO-SVM 模型中,设置狼群数量为20,最大迭代次数为100;PSO-SVM 模型中,设置c1=1.2,c2=1.2,种群数量为20,最终迭代次数为100;GASVM 模型中,设置种群数量为20,最终迭代次数为100;其中SVM 参数惩罚因子c 的寻优范围为[0.1,100],核函数参数g 寻优范围为[0.1,100]。将训练集按照上述步骤求出其样本熵构造特征向量矩阵,分别输入上述模型中。 最后将测试集输入未优化的SVM 模型以及训练优化好的PSO-SVM 模型、GA-SVM 模型和GWO-SVM模型进行对比实验。诊断结果如图5、图6、图7 和图8 所示,4 种模型测试诊断结果对比如表2 所示。 表2 4 种模型的故障诊断结果Tab.2 Fault diagnosis results of 4 models 图5 未优化SVM 诊断结果Fig.5 Unoptimized SVM diagnosis results 图6 PSO-SVM 诊断结果Fig.6 PSO-SVM diagnosis results 图7 GA-SVM 诊断结果Fig.7 GA-SVM diagnosis results 图8 GWO-SVM 诊断结果Fig.8 GWO-SVM diagnosis results 从表2 中4 种模型测试诊断结果可以看出,经过优化算法得到的故障诊断结果GWO-SVM 模型的分类效果最好,最终准确率为96.25%,相比未优化SVM、PSO-SVM 和GA-SVM 模型的准确率分别提高了6.67%、2.5%和1.67%;在寻优时间上,虽然未优化SVM 用时最短,但分类效果太差。GWO-SVM模型所需时间相比PSO-SVM 模型缩短了4.29 s,比GA-SVM 模型缩短了1.97 s。说明了SVM 通过GWO优化算法能很大程度提升故障诊断识别的准确率,同时与传统的PSO 和GA 优化算法相比其寻优时间和准确率上效果更好。 本文通过对实际的石化机组原始信号进行EEMD分解,利用相关系数筛选IMF 分量计算其样本熵构建特征向量,解决了分解过程混叠模态的问题,剔除了部分噪声分量,保留了故障特征的有效信息。最后通过实验对比分析,采用GWO-SVM 模型对石化机组轴承进行故障诊断,识别准确率得到有效提升。与传统优化算法存在寻优速度慢、容易陷入局部最优值等问题相比,所提方法有效减少了运行时间。2 GWO-SVM 模型
2.1 GWO 算法
2.2 GWO-SVM 参数优化

3 故障诊断流程

4 实验分析
4.1 数据集

4.2 特征提取

4.3 结果分析




5 结语
猜你喜欢
基层中医药(2021年12期)2021-06-05 06:56:26
智族GQ(2019年9期)2019-10-28 08:16:21
小太阳画报(2019年1期)2019-06-11 10:29:48
数学大王·低年级(2018年5期)2018-11-01 10:34:06
英美文学研究论丛(2018年1期)2018-08-16 03:00:06
纺织科学研究(2017年6期)2017-07-03 12:14:15
快乐语文(2016年15期)2016-11-07 09:46:31
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
读写算(中)(2015年6期)2015-02-27 08:47:14
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
