
改进YOLOv5s的细胞培养板分类识别方法研究
2023-11-28 11:41王卫军贺利乐
机械设计与制造 2023年11期
王 坛,王卫军,贺利乐,徐 征
(1.西安建筑科技大学机电工程学院,陕西 西安 710055;2.广州中国科学院先进技术研究所,广东 广州 511458)
1 引言
合成生物学是一门交叉学科,融合了生物学、化学、计算机科学、物理学等多个学科。合成生物海量性的试错实验远远超过人工承受的范围,目前我国只有少部分的自动化工作流程,与国外相比还存在较大差距。实现生物实验室自动化已成为生物现代化的发展趋势,而实现细胞培养板的分类识别,是自动化流程的关键环节。
传统分类识别方法通过固定尺寸的窗口遍历图像,进行感兴趣区域搜索,然后使用HOG[1]、SIFT[2]等方法对窗口内的图像进行特征提取,最后使用SVM[3]、Adaboost[4]等分类器对提取的特征进行分类。近年来,随着卷积神经网络的快速发展,基于卷积神经网络的分类识别算法不断涌现,较传统算法在准确性和鲁棒性上有所提升。目前基于卷积神经网络的分类识别算法主要分为两类:(1)以R-CNN[5]、Fast-RCNN[6]、为代表的基于候选区域的检测算法;(2)以SSD[7]、YOLO[8]为代表的端对端检测算法。
针对生物实验室中细胞培养板分类识别的问题,提出一种基于YOLOv5s的细胞培养板分类识别方法(YOLOv5s-tiny)。首先通过多尺度Retinex颜色恢复算法对输入端图像进行预处理;在考虑实验场景的基础上对小目标的检测进行剪枝,优化算法中的损失函数及非极大值抑制算法,并加入CBAM注意力机制以提高网络性能;最后,通过实验验证这里方法的有效性。
2 图像预处理
针对实验环境下光照不均,造成采集的图像出现过暗和模糊的问题,分别通过单尺度Retinex算法、多尺度Retinex算法和颜色恢复算法MSRCR对实验环境下采集的图像进行预处理,并通过图像质量评价指标对各算法的处理结果进行对比分析。
2.1 Retinex理论
文献[9]于20世纪60年代提出Retinex理论,其基本内容是物体被观察的颜色由物体对光线反射能力和周围的光照强度决定的。Retinex理论将图像分解为环境光和物体表面对环境光反射的乘积,Retinex光照反射模型,如图1所示。计算过程,如式(1)所示。

图1 Retinex光照反射模型Fig.1 Retinex Light Reflection Model
式中:S(x,y)—观测图像;I(x,y)—环境光的亮度分量;R(x,y)—带有图像信息的反射分量。
2.2 图像增强效果
采用单尺度Retinex 算法(SSR),多尺度Retinex 算法(MSR)和颜色恢复算法(MSRCR)对实验环境下的图像进行增强,选取了亮度不足的昏暗场景进行对比分析。三种算法在灯光亮度不足的实验场景下的图像增强结果,如图2所示。

原始图像,如图2(a)所示。可以看出实验环境亮度不足,图像显示效果差,图像不清晰,无法清楚地分辨培养板和背景。经过单尺度处理后的图像,如图2(b)所示。图像亮度稍许提高,清晰度提高,但色彩失真严重。经过多尺度算法处理后的图像,如图2(c)所示。图像亮度得到明显提升,整体对比度增强,但依然存在色彩失真问题。经过颜色恢复算法处理后的图像,如图2(d)所示。MRCSR有效的改善了图像颜色失真问题,墙壁上的文字能够轻松识别,培养板轮廓清晰可见,可以明显区分出培养板和背景,图像成像效果得到提升。
2.3 图像质量评价
引入平均信息熵、结构相似度和峰值信噪比作为图像质量评价指标,原始图像和经过三种图像增强算法处理后图像的信息熵、结构相似度和峰值信噪比参数,如表1所示。

表1 图像评价指标参数Tab.1 Image Evaluation Index Parameters
由表中的平均信息熵可知,经过MRCSR算法处理后比SSR算法提高了0.1%,比MSR算法提高了10%。经过MRCSR算法处理后,图像携带的信息量变大,物体轮廓细节更加清楚。由表中的结构相似度得出,经过MRCSR算法处理后的图像光照分量高于其他算法,图像亮度得到明显提高。分析表中的峰值信噪比可知,经MRCSR算法处理后比SSR算法提高了118%,比MSR算法提高了61%,图像失真程度小,成像效果好。
3 改进的YOLOv5s-tiny算法
3.1 YOLO v5s基本思想
YOLOv5s 是由Ultralytics 公司开发的一种可以预测对象类别和边界框的端对端神经网络。同等尺寸下,较其他网络,检测效果好,速度快且稳定性高。
YOLOv5s 主要分为输入端、Backbone、Neck 和Prediction 四部分,其网络结构,如图3所示。YOLOv5s较上一代YOLO 算法有较多创新,其中输入端的创新包括Mosaic数据增强、自适应锚定框计算、自适应图片缩放;Backbone的创新为Focus切片操作及CSPDarknet53网络,解决了卷积神经网络中网络优化的梯度信息重复问题;Neck 的创新为在主干网络后加入SPP 模块和FPN+PAN结构,提高了特征提取的能力;还加入了CSP结构,加强了网络特征融合的能力;输出端采用非极大值抑制算法,对遮挡目标的识别有所改进。
YOLOv5s的输出端采用和YOLOv3相同的预测头。输入图片经过卷积层分别得到(19×19),(38×38),(76×76)三个不同尺寸的特征图,为了更好的提取特征,通过上采样将(38×38)的特征图与(19×19)的特征图进行融合,将(76×76)的特征图与(38×38)的特征图进行融合,构成了YOLOv5s的预测框架,分别负责大、中、小物体的预测。
3.2 YOLOv5s-tiny的网络结构
YOLOv5s预测的三个特征层尺寸由浅到深分别是(76×76),(38×38),(19×19)对应不同尺寸的锚定框,因此实现了多尺度检测。因实验环境下,对小目标的检测场景极少出现,故省略(76×76)的特征层检测,以轻量化网络结构。YOLOv5s-tiny 网络结构,如图4所示。

图4 YOLOv5s-tiny网络结构Fig.4 The Network Structure of YOLOv5s-Tiny
3.2.1 深度可分离卷积
文章采用深度可分离卷积代替主干网络中的普通卷积使网络模型轻量化,该模块分为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两个过程,如图5所示。该模型的提出是为了减少参数量提高运算效率。不同于普通卷积,深度卷积对通道数为M的输入层的每个通道独立进行卷积运算,然后逐点卷积使用1×1×M的卷积核对上一步生成的特征图在深度方向进行组合,输出M个新的特征图。
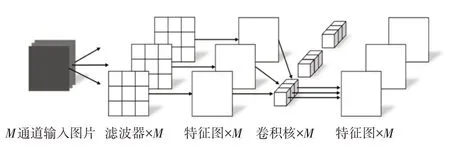
图5 深度可分离卷积Fig.5 Depth Separable Convolution

图6 LDIoU计算原理Fig.6 The Calculation Principle of LDIoU
假设输入的特征图尺寸为HInput×WInput×M,普通卷积核尺寸为Hc×Wc×M,输出的特征图尺寸为HOutput×WOutput×N,逐通道卷积核尺寸为HD×WD×M,普通卷积的参数量为Hc×Wc×M×N,深度可分离卷积的参数量为HD×WD×M+1×1×M×N。若按照YOLOv5s 的参数,采用深度可分离卷积的参数量较普通卷积减少了87%。
3.2.2 损失函数
目标检测中常用交互比(IoU)作为评价预测检测框和真实检测框的重合程度。IoU的计算过程,如式(2)所示。一般IoU越接近1,说明检测结果越准确。由于IoU对目标物体的尺度、重叠率不敏感,所以YOLOv5s中使用广义交互比(GIoU)作为边界框的损失函数,GIoU的计算过程,如式(3)所示。GIoU虽然解决了IoU在预测框和真实框不重叠时梯度消失的问题,但仍存在收敛速度慢的缺点。
式中:Bgt=(xgt,ygt,wgt,hgt)—真实框的坐标和大小;
B=(x,y,w,h)—预测框的坐标和大小。
式中:C—覆盖预测框和真实框的最小框。
针对以上算法的不足,这里采用基于距离交互比的损失函数(LDIoU)作为YOLOv5s-tiny的损失函数,定义为:
式中:b—预测框;bgt—真实框的中心点;ρ—两个中心点之间的欧式距离;c—覆盖预测框和真实框的最小闭合框的对角线距离。
相较于GIoU损失函数,LDIoU计算时加入了边界框的重叠区域和中心点距离因素,不仅直接最小化预测框和真实框之间的距离,提高了收敛速度;而且在两框处于水平方向和垂直方向时,加快了损失回归。
3.2.3 非极大值抑制
非极大值抑制算法(NMS)广泛应用于目标检测的后处理过程中,其原理是找出检测分数最高的检测框,其他与被选中的检测框重叠区域大于阈值的框被剔除,将这一过程不停迭代,从而找到最佳的目标检测位置。由于IoU大于阈值的检测框被直接剔除,会出现两框重叠率较高时被剔除得分较小框的问题。因此,文献[10]提出了软化非极大值抑制算法(Soft_NMS),通过降低与最高得分框重叠的相邻检测框的置信度,解决了NMS直接剔除检测框的问题。NMS计算过程,如式(5)所示。
式中:si—当前检测框的得分;M—当前最高得分的检测框;bi—待检测框;Nt—IoU的阈值。
Soft_NMS高斯加权算法计算过程,如式(6)所示。bi和M的IoU越大,bi的得分si就下降的越厉害。
式中:σ—权重系数;
D—最终检测框的集合。
通过在不断修改权重系数对数据集进行测试,经过实验研究,Soft_NMS 高斯加权算法在权重系数为(0.4~0.6)的变化范围内,表现了优秀的性能,与NMS算法相比,使用Soft_NMS高斯加权算法作为后处理的平均精确度提升了2.2%。经分析对比,在包含重叠目标的培养板数据集上,Soft_NMS 高斯加权算法的预测框更加准确。
3.2.4 注意力机制
注意力机制(Attention Mechanism)是在计算机处理能力有限的情况下,解决信息过载问题的一种技术手段,其核心目的是从众多信息中提取出对当前任务更关键的信息。在图像识别中通过生成掩码(Mask)的方式,对其进行评价打分,从而提高图像信息处理的效率和准确性。使用集成了通道注意力机制和空间注意力机制的卷积块注意力模块(CBAM),通过对YOLOv5s卷积特征图中培养板的特征分配高权重,对背景分配低权重,从而使准确率得到提升,解决了局部遮挡情况下容易漏检的问题。CBAM 模块,如图7(a)所示。通道注意力机制和空间注意力机制,如图7(b)、图7(c)所示。给定一个中间层的特征图F作为输入,其维度是C×H×W,CBAM依次生成一个维数为C×1×1的通道注意力权重Mc和一个维数为1×H×W的空间注意力权重,将通道注意力权重Mc乘以特征图F得到F',再计算F'的空间注意力特征图,最后两者逐元素相乘得到注意力权重F'',计算结果,如式(7)所示。

图7 CBAM模块Fig.7 Convolution Block Attention Module
式中:⊗—对应元素一一相乘。
通道注意力机制首先通过最大池化和平均池化操作,对特征图F的每个通道在空间维度上进行压缩,生成两个通道注意力向量然后分别将其输入到一个由隐藏层组成的共享多层感知器(MLP)中,并生成两个维数为C×1×1的注意力向量;将上述两个向量相加,通过sigmoid激活函数,最后生成一个维数为C×1×1的通道注意力向量Mc,计算公式,如式(8)所示。
式中:σ—sigmoid激活函数;W0—MLP第一层的权重;W1—MLP的第二层的权重;AvgPool—平均池化;MaxPool—最大池化。
空间注意力机制将特征图F通过最大池化和平均池化操作,得到两个维数相同的特征图,然后将二者串行拼接成一个新的特征图,再将其输入(7×7)的卷积层中,得到一个与原特征图维数相同的空间注意力权重矩阵,然后回乘到原特征图上,计算公式,如式(9)所示。
4 实验分析
4.1 实验数据集
细胞培养板数据集均在实验室环境下采集,使用Intel Realsense D435i深度相机作为采集设备,通过改变机械臂的不同姿态,分别在不同角度下拍摄培养板图像,拍摄时的背景为实验室货架背景,能反映真实的使用环境。最终采集的图像970张,像素大小为(1280×720),包含4种不同规格的培养板。
培养板数据集按照COCO数据集格式制作,将970张图像按照7:2:1的比例,随机分成训练集、验证集和测试集,其中训练集679张图像,验证集194张图像,测试集97张图像。通过labelimg软件对培养板数据集进行边界框标注,训练集图片共标注2369个培养板,验证集共标注216个培养板。
4.2 实验环境及参数设置
为验证改进后网络的可行性和有效性,与YOLOv5s网络模型进行实验对比。在CPU为Inte(lR)Xeon(R)Sliver 4110,显卡为NVIDIA GTX 2080Ti,内存为64G 的工作站上进行训练测试,软件环境为Anaconda 4.8.3,CUDA 10.2,CUDNN 7.5,编译语言为Python 3.7,深度学习框架为pytorch 1.5.1。训练网络输入图像尺寸为(608×608),冲量系数为0.937,batch_size 为16,学习率为10-4,epoch为300。
这里采用Kmeas++聚类算法对实验数据集重新设计锚框,Kmeans++算法改进了初始聚类中心的选取方式。在权衡计算量和检测召回率后,选取8个尺寸的锚框,均匀分布在大中两种尺度上,每种尺度预测4个边界框。重复Kmeans++聚类实验10次,取10次实验中平均IoU最高值对应的锚框尺寸,8个锚框的尺寸分别为(175×120)、(160×156)、(185×173)、(278×291)、(245×168)、(224×218)、(259×242)、(389×407)。
4.3 评价指标
这里采用精确率(Precision)、召回率(Recall)、平均精确率(mAP)、权重(Weight)、耗时(Time)作为评价指标[11]。精确率评估正确分类样本数量占预测样本数量的比例;召回率评估正确分类样本数量占真实样本数量的比例;平均精确度评估多类别目标的平均检测精度;权重评估网络模型的大小;耗时评估网络运算的速度。精确率和召回率的计算过程,如式(10)、式(11)所示。
式中:TP—正确将正类判定为正类的数量;
FP—错误将负类判定为正类的数量;
FN—错误将正类判定为负类的数量。
4.4 实验结果
YOLOv5s算法和YOLOv5s-tiny算法在培养板数据集上的检测能力,如表2所示。由表2可知,相比于YOLOv5s算法,文章提出的YOLOv5s-tiny 算法召回率、精确度和mAP 分别提升了1.4%、4.5%和2.6%;网络权重较YOLOv5s减小约20%;检测的平均耗时较YOLOv5s增加约22%。
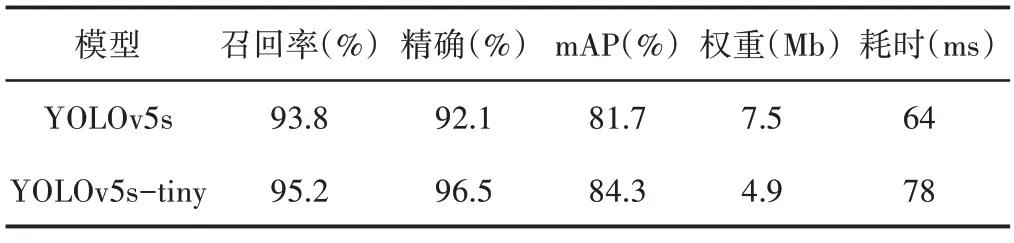
表2 图像评价指标参数Tab.2 Image Evaluation Index Parameters
分别使用式(3)、式(4)的损失函数训练YOLOv5s-tiny 网络模型,获得训练的Loss 曲线,如图8 所示。可以看出,采用GIoU_Loss训练的模型收敛区间为(0.038~0.13),在270次epoch之后收敛,而采用DIoU_Loss训练的模型损失收敛区间明显小于GIoU_Loss,为(0.018~0.1292),在60次epoch之前的收敛速度高于GIoU_Loss。

图8 损失函数曲线Fig.8 Loss Curve
YOLOv5s 和YOLOv5s-tiny 算法在培养板数据集上测试的部分检测结果,如图10所示。YOLOv5s在检测时出现了培养板误检和漏检的问题。如图9(a)显示box1被多个预测框标记,box2置信度为0.64,box3 置信度为0.81;图9(b)显示box2 未被检出,box3置信度为0.82,box4置信度为0.78;图9(c)显示三个目标全被检出,置信度分别为0.865、0.85及0.87;图9(d)显示三个目标全被检出,置信度分别为0.71、0.83及0.81。可以看出,针对生物实验室中细胞培养板的分类识别问题,YOLOv5s-tiny 改善了误检和漏检问题,预测框置信度得到了提升,验证了算法的可行性和有效性。

图9 YOLOv5s和YOLOv5-tiny部分检测结果Fig.9 Partial Test Results of YOLOv5s and YOLOv5-Tiny
5 结语
针对生物实验室中细胞培养板分类识别问题,提出一种改进YOLOv5s的细胞培养板分类识别方法。该方法首先对小目标检测层进行剪枝操作,然后对输入层图像进行图像增强,使用深度可分离卷积代替普通卷积,优化损失函数和非极大值抑制,最后引入注意力机制,提高识别的准确性。通过实验表明,比较YOLOv5s算法,改进后的方法在精确率和平均精确度方面分别提升了4.5%和2.6%,权重文件减小了20%,方法可行有效,为生物实验室自动化提供了理论支持。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
核科学与工程(2021年4期)2022-01-12
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
计算机应用(2018年5期)2018-07-25
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
轴承(2015年2期)2015-07-25
电视技术(2014年19期)2014-03-11
