
基于迁移元学习的调制识别算法
2023-11-27 02:13庞伊琼许华张悦朱华丽彭翔
兵工学报 2023年10期
庞伊琼, 许华, 张悦, 朱华丽, 彭翔
(空军工程大学 信息与导航学院, 陕西 西安 710077)
0 引言
通信信号调制样式识别是介于信号检测与解调之间的关键步骤,在信息侦察、电子对抗、电磁频谱监测等领域都有着重大的研究意义。传统通信信号调制识别通过对目标信号进行特征分析与提取,并以此为依据设计特定的分类器实现对信号的分类[1-3]。随着现代通信技术的迅猛发展,传统方法已无法适应复杂电磁环境下的调制识别任务,这促进了以深度学习为基础的新一代调制识别技术的发展。O’Shea等[4-5]首次采用深度学习技术解决调制识别问题,提出通过卷积神经网络(CNN)直接学习信号IQ序列样本,完成对11类调制信号的识别任务。Kumar等[6]采用ResNet-50和Incepction V2网络提取信号星座密度矩阵图特征,并通过与前置噪声滤波网络结合实现对低信噪比数字调制信号的准确识别。Liu等[7]将双向长短时记忆(LSTM)网络与CNN级联,在信噪比超过4 dB时对11类调制信号的识别率可达到90%。文献[8]采用特征降维的方式控制CNN的运算开销,对比传统CNN,在降低94.44%计算量的同时实现了86.5%的识别准确率,该算法有效提升了CNN网络在调制识别领域的应用价值。
虽然基于深度学习的调制识别方法取得了显著的识别效果,但深度学习方法的成功往往都需要至少数千个带标签训练样本,训练样本量不足会导致网络出现过拟合问题。然而随着实际应用的不断扩展,通信信号环境所能提供的带标签信号样本很难满足以上基于深度学习的调制识别方法的要求。
针对深度学习方法所需训练样本过多的问题,迁移学习[9]将从源域中学到的知识迁移到对相关目标域的学习过程中,有效降低了在目标域训练深度神经网络对样本量的需求。在信号调制识别领域迁移学习技术已经有了广泛应用,如文献[10-12]采用迁移学习技术对网络模型进行预训练,在目标数据集样本量明显减少的情况下保证了算法的识别准确率。但迁移学习要实现较好的识别性能仍需至少几百个目标域信号样本,针对仅有几个带标签信号样本的调制识别任务无法直接采用迁移学习技术,元学习[13-14]可采用基于任务的训练方式来解决仅有几个带标签训练样本的信号识别问题。元学习的目标是训练得到一个具有强泛化性能的基网络,该网络通过从训练任务中积累的元知识指导对新任务的学习,仅需极少量数据就可使网络快速收敛。模型无关元学习(MAML)[15]在元训练过程中通过大量不同任务所产生的误差的梯度信息学习基网络的最优初始化参数。在元测试时采用学习到的最优网络参数来初始化基网络参数,只需少量训练数据对网络进行微调就可快速适应新任务。但MAML算法的基网络通常只能采用浅层神经网络,若直接采用较深的神经网络将会大幅提升网络的训练难度,限制了网络识别性能的进一步提升。
本文提出一种基于迁移元学习的调制识别算法。为采用深度残差神经网络作为MAML算法的基网络,针对所用信号样本独立同分布的数据特性,本文算法根据迁移学习思想首先在整个训练集上对基网络进行预训练,在元学习阶段中只保留基网络特征提取部分,并通过设置两个可学习的神经元参数ψ1和ψ2对其预训练所得网络参数θ1进行缩放与偏移操作,即ψ1θ1+ψ2,从而实现网络的迁移。元训练过程中将ψ1、ψ2以及基网络分类部分的网络初始参数θ2作为元知识,通过最小化识别任务中测试数据产生的损失来优化ψ1、ψ2以及θ2,提高网络对新类信号数据的泛化性能。元测试过程中将元训练得到的ψ1、ψ2以及最优初始化参数θ2用于解决新类信号的识别任务,只需通过少量训练数据对基网络分类部分网络参数进行微调,就能对新任务中待测信号的调制样式实现准确识别。
1 模型无关元学习算法
1.1 元学习基本思想
人类在学习新事物时可以运用之前学习过程中已经掌握的一些技能,如认识猫的儿童更容易理解老虎这个概念,可通过学习一张老虎图片就快速认出老虎。受此启发提出元学习的概念,元学习通过对以往任务的学习积累元知识来指导对新任务的学习,根据元知识的不同,可将元学习方法分为基于度量的元学习算法[16-19]、基于优化策略的元学习算法[20]、基于最优初始化参数的元学习算法[15]。元学习的实现分为元训练与元测试两个过程,且都是基于任务进行的,本文算法主要针对仅有几个带标签训练样本的调制识别问题,则元训练与元测试过程中的任务都为信号识别任务,且每个任务包含少量训练信号样本与待测信号样本。在元训练过程中通过学习训练任务积累元知识,元知识可用于提高基网络的泛化性能,实现对元测试阶段新类信号的信号识别任务的快速学习。
元训练与元测试过程中采样的识别任务中的训练数据若包含C类信号,且每类信号拥有K个信号样本,则将该识别任务称为C-wayK-shot任务。为使网络在元测试阶段对仅有少量训练样本的新类信号识别任务实现较高的识别准确率,需要大量训练任务帮助网络积累元知识,训练任务通常从一个包含大量信号样本的数据集Dbase中采样得来,假设Dbase由NC类信号组成(不包含测试任务中所含有的信号类别),采样一个C-wayK-shot任务时首先从这NC类信号中随机选取C类信号(C≤NC),然后从每类信号样本中随机采样K+Nq个样本,将这K+Nq个信号样本中的K个样本作为该任务的训练数据,Nq个样本作为该任务的测试数据,通过该方式多次采样本文所需的训练任务集。
1.2 MAML算法
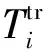
(1)

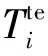
(2)

MAML算法的训练过程分为外循环与内循环,在内循环中寻找针对每个任务的最优参数θ′i,在外循环中通过基网络在最优参数下的测试损失更新基网络的初始参数θ。算法训练伪代码如图1所示。
根据文献[13]的研究结论可知,MAML算法通过这种特殊的训练方式为网络寻找到一个尽可能适应所有任务的初始化参数,使得网络参数在面对新任务时能够被更快、更容易地微调,提升网络快速学习新任务的能力。当训练结束后,面对未经训练的新类信号,只需微调一小部分网络参数就可使网络快速学习到可用于区分新类信号的关键特征。

输入:任务分布集p(T);学习率:β、γ过程:1.使用随机值θ初始化基网络f参数2.while not done do3. 从p(T)中抽取一批任务,即Ti~p(T)4. for all Ti do5. 计算Ti的训练损失:LTtri(fθ)6. 通过梯度下降得针对任务Ti的最优参数:θ′i=θ-βΔθLTtri(fθ)7. end8. 更新初始化参数:θ←θ-γΔθ∑Ti~p(T)LTtei(fθ′i)9.end输出:基网络f的最优初始化参数θ
MAML算法仅在传统端到端网络的输出后增加了由测试集生成的损失函数,其设计结构具备很好的通用性与性能提升潜能。由于算法采用的基网络仅需负责反向传播以及输出预测结果,在训练过程中不需要增加额外参数,相比其他类型的元学习算法,MAML算法自适应能力更强,更适用于解决极少量样本条件下的调制识别问题。
2 基于迁移元学习的调制识别算法
针对仅有几个有标签信号样本的调制识别问题,本文在MAML算法的基础上做了进一步的改进,如图2所示,本文算法的实现过程分为迁移预训练阶段和元学习阶段。首先通过整个训练集预训练网络模型,在元学习阶段冻结网络参数且只保留特征提取部分,并通过设置缩放偏移参数[ψ1,ψ2]将其迁移至小样本识别任务的学习过程中,在元训练过程中采用MAML算法的双层循环训练策略,将[ψ1,ψ2]以及新分类器的初始化参数θ2作为可学习的元知识进行优化训练,使得在元测试时基网络可快速适应新的小样本识别任务。

图2 算法流程图Fig.2 Algorithm flow chart
2.1 算法实现过程
如图2所示,在迁移预训练阶段,本文通过训练集内的所有信号样本优化网络模型参数,首先随机初始化特征提取部分和分类器部分的网络参数θ1和θ2,并通过梯度下降对[θ1;θ2]进行优化训练,即
(3)
式中:α表示学习率;D表示训练集;LD([θ1;θ2])表示训练集识别损失,可表示为
(4)
x表示信号样本,y表示x对应的信号标签,本文中l(f[θ1;θ2](x),y)为交叉熵损失函数。
通过训练集内所有信号样本预训练得到网络模型f[θ1;θ2],元学习过程基于多个信号识别任务进行,由于训练集与信号识别任务内待识别的信号类别数不相等,如本文中预训练得到的是10类别(10-way)信号分类器,而元学习过程中需要5类别(5-way)信号分类器,因此在后续的元学习过程中将只保留网络模型的特征提取部分。在元学习阶段冻结特征提取部分网络参数θ1,并针对信号识别任务设置新的分类器。本文算法所用训练集与测试集内包含的调制信号样本来自同一信号数据集,所有信号样本均服从同一分布,样本间具备较高的相关性。根据迁移学习思想[7],预训练所得特征提取网络不仅可以提取训练集内信号样本特征,还可有效实现对测试集内信号样本的特征提取,但由于预训练网络是在整个训练集上进行的,难以快速适应只有几个带标签信号样本的识别任务。因此本文算法在元学习阶段通过设置可学习的缩放偏移参数[ψ1,ψ2]实现对特征提取部分网络参数θ1的迁移,具体地,假定网络参数的权值和偏差分别为W、b,则当输入为x时,网络输出可表示为
f[W;b;ψ{1;2}](x)=(W⊙ψ1)x+(b+ψ2)
(5)
在元训练前随机设置分类器的初始参数θ2,ψ1和ψ2的初始值分别设置为1和0,在内循环过程中针对小样本识别任务T,通过Ttr训练优化当前基网络分类器部分的参数,则针对T的最优网络参数为
(6)
不同于式(3),此处θ2表示新分类器的网络初始化参数,外循环过程中通过得到的f[θ1;θ′2]网络测试Tte,并由产生的识别损失优化更新[ψ1,ψ2]以及基网络分类器的初始化参数θ2,即
(7)
(8)

2.2 网络结构
本文网络模型的特征提取部分和分类器分别由卷积层和全连接层构成,其中特征提取部分采样深层残差网络ResNet,ResNet由多级残差块组成,每个残差块包含3层3×1卷积,通过1×1卷积使得输入输出的格式一致,实现跳层连接,最后再级联一个2×1的最大池化层,残差结构可避免网络过深导致的梯度消失问题。如图4所示,图4(a)为n级残差块结构,图4(b)为ResNet网络整体结构。网络分类器部分采用一层全连接网络。

输入:任务分布p(T)以及对应训练集D;学习率:α、β、γ过程:1.随机初始化基网络f特征提取器部分和分类器的网络参数θ1和θ22.for (x,y) in D do3. 计算损失:LD([θ1;θ2])=1|D|∑(x,y)∈Dl(f[θ1;θ2](x),y)4. 更新网络参数θ和θ:[θ1;θ2]←[θ1;θ2]-αΔLD([θ1;θ2])5.end6.初始化ψ1值为1,ψ2值为07.根据识别任务设置新分类器并随机初始化对应参数θ8.while not done do9. 从p(T)中抽取一批任务,即Ti~p(T)10. for all Ti do11. 计算Ti的训练损失:LTtr(f[θ1;θ2],ψ{1,2})12. 计算针对任务Ti的最优参数: θ′2=θ2-βΔθ2LTtr(f[θ1;θ2],ψ{1,2})13. end14. 更新分类器初始化参数θ2: θ2←θ2-γΔθ2∑T~p(T)LTte(f[θ1;θ′2],ψ{1,2})15. 更新[ψ1,ψ2]:ψi←ψi-γΔψi∑T~p(T)LTte(f[θ1;θ′2],ψ{1,2})16.end输出:最优初始化参数θ2、[ψ1,ψ2]
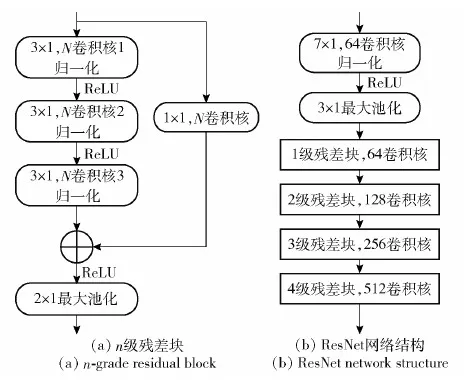
图4 ResNet特征提取网络Fig.4 ResNet feature extraction network
本文算法设置了两个可学习的参数[ψ1,ψ2],其结构随着特征提取网络参数结构的变化而不同,如图5所示当特征提取网络权重参数格式为C×Nk×k1×k2,则对应放缩系数ψ1和平移系数ψ2格式分别为C×Nk×1×1和1×Nk×1×1。相对于一般MAML算法,本文算法在元学习阶段只需更新参数[ψ1,ψ2],减少了网络所需训练的参数量,降低了算法在小样本条件下采用深度神经网络时的训练难度。
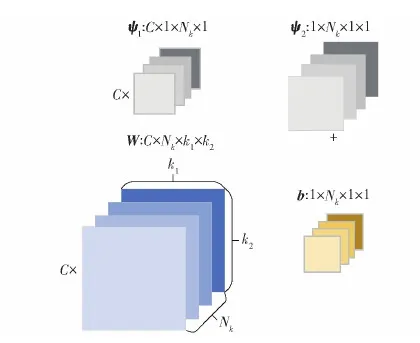
图5 参数格式Fig.5 Parametric format
3 仿真实验
3.1 实验数据集与实验参数设置
RadioML2018.01是Deepsig提出的调制识别公开数据集,数据集内信号样本通过从模拟的真实通信环境中采样得来,随机采样下的所有信号样本独立同分布[5]。该数据集包含24类调制信号,本节实验选取信噪比从-10 dB到20 dB的调制信号,信噪比分布间隔为2 dB,通过从每类信号的每个信噪比点的样本中采样1 000个样本构成本节仿真实验所需数据集,信号数据格式为[1 024,2],表示序列长度为1 024的I、Q路分量。实验中将数据集内不同类调制信号划分为训练集、验证集以及测试集,3个数据集内所包含信号调制样本不相交,各个数据集的具体调制样式如表1所示。在元学习过程中通过从这些数据集中随机采样出大量不同的C-wayK-shot识别任务来实现本文算法。
本节实验采用Python软件开发平台下的Pytorch神经网络架构搭建网络模型,实验在Windows 7系统、32 GB内存、配备NVDIA P4000显卡的服务器上进行。
在预训练阶段通过SGD算法优化网络参数,初始学习率设置为0.01,训练迭代100个epoch,每经过20个Epoch,学习率减小为原来的50%,选取验证识别率最高的模型用于元学习阶段。元训练阶段采用Adam优化算法,内循环和外循环学习率分别设置为0.001和0.000 1,选取验证识别率最高的模型作为最终训练模型。在元测试阶段,通过和采样训练任务一样的方式从测试集中采样600个测试识别任务来测试网络模型的识别准确率,将所有测试任务识别准确率的平均值用于表征算法最终的识别性能。在每个识别任务中,每类信号选取15个信号样本作为测试样本。
3.2 迁移元学习算法性能分析
3.2.1 不同样本量下算法性能分析
迁移元学习算法可解决极少量带标签信号样本条件下的调制识别问题,为验证算法的识别性能,在不同样本量条件下进行仿真实验,同时为证明迁移元学习算法的性能优势,实验还选取了 3种不同的调制识别算法,分别为CNN[4]、迁移学习(TL)[11]和数据增强(DA)[21],对所有算法在不同样本量下的性能差异进行对比分析。迁移元学习算法特征提取网络设置为ResNet网络,为保证实验结果的可靠性,根据实验单一变量原则,所有对比算法所用数据集均为表1所示的测试集,通过采样该数据集中部分信号样本训练3种对比算法的网络参数,将其余样本用于测试算法识别性能。本文迁移元学习算法采用表1中数据集进行仿真实验。当测试信号信噪比为20 dB时,不同算法识别准确率随每类信号训练样本量的变化情况如图6所示。
分析图6中变化曲线可知:本文算法要达到最好的识别性能所需的样本量只有20个,远远少于其他对比算法所需的样本量;当待测信号的训练样本量只有几个时,本文迁移元学习算法的识别性能明显优于对比算法,如当每类信号训练样本量为20时,对比基于CNN、TL、DA的3种调制识别方法,本文算法的识别准确率分别提高了79.66%、72.42%、78.05%。
图7分别展示了本文算法针对5-way 5-shot和5-way 1-shot测试任务以及3种对比算法的识别准确率随信噪比的变化曲线,图7(a)中CNN、TL、DA 3种对比算法所用每类训练信号样本量N=50,图7(b)中N=100。从图7中可以看出,当对比算法的训练样本量N为50个时,相对于其他对比算法,本文算法针对5-way 1-shot和5-way 5-shot测试任务均取得了最优的识别效果;当N=100个时,本文算法在测试信号信噪比大于0 dB时针对5-way 5-shot任务的识别性能依然优于其他对比算法。图6和图7中实验结果表明,本文迁移元学习算法在待测信号只有几个训练样本时仍能取得较高的识别准确率,在所用样本量远远少于其他对比算法时。本文迁移元学习算法可以实现更优的识别性能,主要原因在于本文算法采用元学习策略优化网络模型,即在训练阶段通过学习大量不同的小样本识别任务来优化模型网络参数。通过这种跨任务的训练方式,使得网络模型具备了“学会学习”的能力,可以实现对新任务的快速适应。不同于元学习策略,对比算法则是直接学习信号样本与对应标签之间的映射关系,训练完成的网络能够直接识别新的待测信号样本的调制样式,然而网络模型要掌握这种能力需要学习大量不同的信号样本,当训练样本量不足时会导致识别性能的下降。从实验结果中可以看出,本文算法即使在每类信号带标签样本量只有1个时也能保持较高的识别准确率,相对于3种对比算法,本文算法有很大的性能优势。
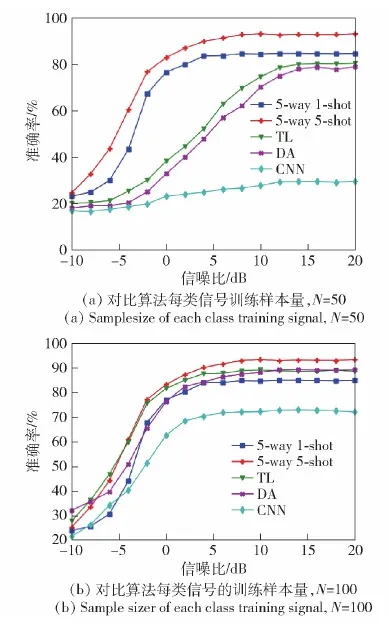
图7 不同算法识别性能变化曲线Fig.7 Variation curves of recognition performances of different algorithms
3.2.2 算法对比消融实验
为进一步提高网络模型在带标签信号样本量只有几个时的识别准确率,在MAML算法的基础上,本文迁移元学习算法增添了迁移预训练过程,并在元学习过程中设置可训练更新的缩放偏移参数[ψ1,ψ2]。为验证这些改进的有效性,本节在表1的数据集上进行消融实验,当测试信号信噪比为20 dB时,针对5类调制信号识别任务(5-way)的实验测试结果如表2所示,其中ConvNet表示5层的卷积神经网络,且经过迁移预训练的网络在元学习阶段将冻结特征提取部分的网络参数。
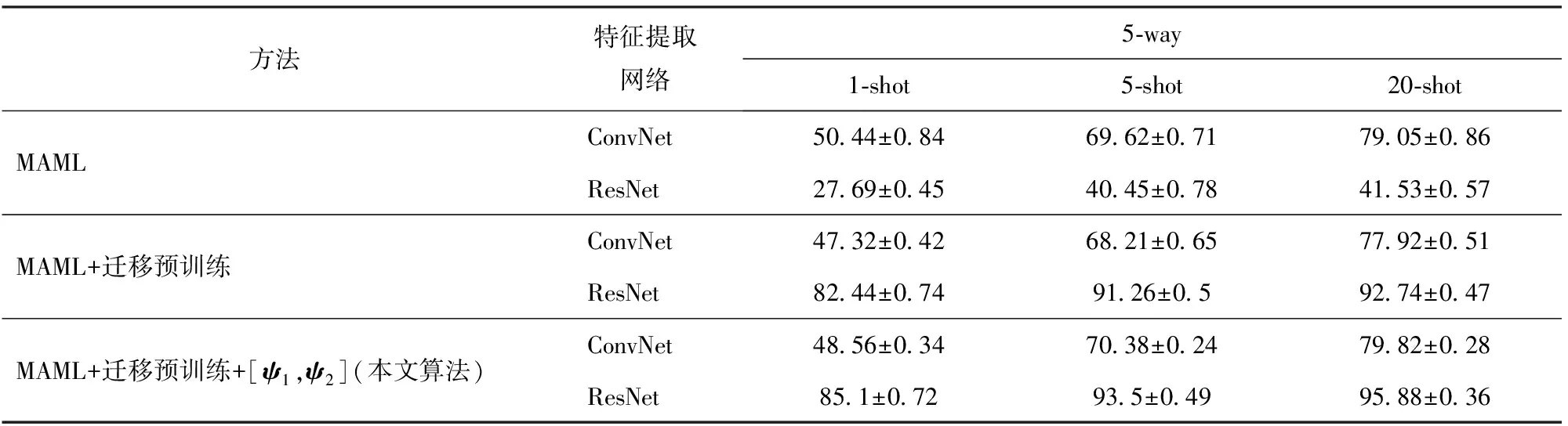
表2 对比消融实验结果Table 2 Comparison of ablation results %
从表2中可以看出,本文针对MAML算法的改进都进一步提高了网络的识别准确率。分析表2中的数据可知,当MAML算法采用层数更深的ResNet作为特征提取网络时,网络的识别准确率反而下降了。这是因为MAML算法针对每个识别任务都只有极少量的训练样本(见图8),当采用较深的特征提取网络,如果直接更新整个网络参数,则难以训练网络收敛,整个元训练过程中网络的识别精度和损失都在剧烈波动,网络无法实现一个较为稳定的学习效果,导致网络的识别性能显著下降。
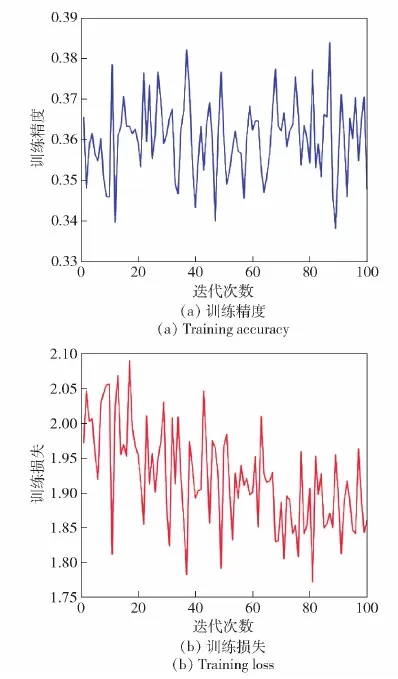
图8 采用ResNet时MAML算法训练损失与训练精度Fig.8 Training loss and accuracy of MAML algorithm with ResNet
通过迁移预训练过程进一步提升了ResNet网络对同一分布信号样本的特征提取能力,缓解了ResNet网络在元学习阶段的学习压力,元学习过程中冻结特征提取部分的网络参数,这极大地减少了网络所需学习更新的网络参数,降低了网络训练的难度(见图9)。迁移元学习算法在使用更深的ResNet特征提取网络时,网络经过60次训练迭代就能使网络收敛到最优的状态。同时在元学习阶段冻结特征提取部分网络参数还能使训练过程更注重对分类部分网络参数的学习,强化了分类网络对提取到信号特征的敏感度。但从表2数据中还可以看出,当ConvNet作为特征提取网络时,通过迁移预训练操作没有提高算法的信号识别准确率。主要原因在于ConvNet网络层数较浅,特征提取能力有限,无法提取到信号样本间细致的特征差异。由于ConvNet网络特征提取能力存在局限性,使得迁移预训练操作无法有效提升采用ConvNet作为特征提取网络时的算法识别性能。采用另一方面设置可学习的缩放偏移参数[ψ1,ψ2]迁移特征提取部分的网络参数,通过元训练得到最优的[ψ1,ψ2]可帮助特征提取网络在元测试阶段尽快适应新类信号的识别任务,进一步提升网络的识别性能。
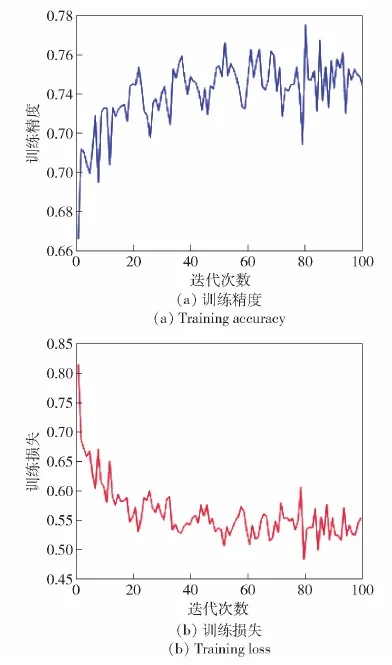
图9 迁移元学习算法训练损失与训练精度Fig.9 Training loss and accuracy of transfer meta-learning algorithm
3.2.3 不同元学习算法性能对比
为进一步验证迁移元学习算法的性能优势,本节另外选取5类元学习算法进行对比实验,包括原型网络(PN)[16]、关系网络(RN)[17]、匹配网络(MN)[18]、孪生网络(SN)[19]、Meta-learner LSTM[20],将这些元学习算法用于解决本文所提的只有几个带标签信号样本时的调制识别问题,所有算法都在表3所示数据集上进行仿真实验,当测试信号信噪比为20 dB时,以上算法在5-way 5-shot和5-way 1-shot识别任务上的测试结果如表3所示,从表3数据中可以看出,相对于其他算法,本文算法取得了更好的识别效果。
本文算法具有明显的性能优势,在5-way 5-shot和5-way 1-shot识别任务中都取得了最优的识别效果。在对比的5类元学习算法中,PN、RN、MN、SN都属于基于度量的元学习算法,该类算法通过多个训练任务学习一个合适的特征度量空间,当面对新类信号的识别任务时,不需要更新网络参数,只需将带标签信号样本与待测信号样本映射到经训练所得的特征度量空间中,通过某种距离度量函数计算样本间的距离,寻找最近邻的类别确定识别结果。

表3 不同元学习算法的性能对比Table 3 Performance comparison of different meta-learning algorithms %
由于样本量的限制,基于度量的元学习算法很难学习到一个高效率的特征度量空间,对比本文迁移元学习算法,当ResNet作为算法特征提取网络时,这4类基于度量的元学习算法在5-way 5-shot识别任务上测试识别准确率分别降低了8.61%、7.98%、18.48%、26.18%。
Meta-learner LSTM算法通过训练一个LSTM元网络来学习基网络参数的更新规则,当面对新类信号的识别任务时,在LSTM元网络指导下可以对网络参数进行更准确地更新,以快速适应新任务,但该算法中基网络训练损失和元网络参数的梯度都依赖于元网络的参数,算法计算复杂度较高。当ResNet作为基网络时,本文算法在5-way 5-shot识别任务上的识别准确率相对于Meta-learner LSTM算法提升了21.14%。本文算法通过迁移预训练操作降低了训练ResNet的难度,并通过引入可学习的偏移缩放参数将预训练所得的ResNet网络参数迁移至元学习过程中,使得ResNet网络能够更快地适应小样本识别任务,进一步提高了网络的识别性能,算法识别准确率在5-way 1-shot识别任务上也远高于其他元学习算法。
4 结论
本文通过迁移预训练的方式降低MAML算法采用较深的特征提取网络时的训练难度,提升网络对信号特征的提取能力,同时为减少网络面对新类信号识别任务时所需训练的参数量,在元学习阶段冻结特征提取部分的网络参数,并通过引入缩放偏移参数将其迁移到对新任务的学习过程中,在元测试阶段,网络从通过元训练得到的最优初始权重下开始微调分类部分的网络参数,仅需少量信号样本就能快速适应新类信号的识别任务,通过对比实验进一步验证了本文算法的可行性以及相较其他算法在极少量样本条件下的性能优势。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2018年19期)2018-11-14
知识经济·中国直销(2018年8期)2018-08-23
电子测试(2018年1期)2018-04-18
自动化学报(2017年11期)2017-04-04
数学学习与研究(2017年3期)2017-03-09
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国老区建设(2016年1期)2016-02-28
噪声与振动控制(2015年4期)2015-01-01
