
基于耦合算法的花生叶片光合色素含量反演模型
2023-11-26 10:12:50刘欣蓓邸俊楠徐良泉王仁义
农业工程学报 2023年16期
刘欣蓓 ,苏 涛 ※,雷 波 ,朱 菲 ,邸俊楠 ,孟 成 ,徐良泉 ,王仁义
(1. 安徽理工大学空间信息与测绘工程学院,淮南 232001;2. 中国水利水电科学研究院水利研究所,北京 100048)
0 引言
花生作为中国重要的经济和油料作物,富含油脂、蛋白、膳食纤维及微量营养素,具有丰富的功能成分和极高的营养价值,保障其产量的稳定性对于中国油料安全至关重要[1]。色素是植物进行光合作用的重要物质基础,主要包括叶绿素(Chlorophyll,Chls)和类胡萝卜素(Carotenoids,Caros)。叶绿素含量与植被的光合能力、生长发育以及营养状况有密切的关系,可有效反映其胁迫、生长和衰老等状况[2]。类胡萝卜素能吸收和传递太阳辐射能,在植被光能过剩时,还可以发散过剩能量来保护光合系统[3]。因此,快速准确预测叶片光合色素含量对花生生长监测、营养诊断、产量评估和病虫害的早期预警等科学化管理有重要价值[4]。传统的光合色素含量检测方法技术投入大,受环境影响,消耗时间长且为有损检测[5]。由于高光谱遥感技术具有高效、无损等优势,因此,现已广泛应用于作物生理指标及生长状态的快速检测[6-7]。马春艳等[8]对冬小麦光谱数据与叶绿素含量进行分析与建模,验证光谱反射率与叶绿素含量呈正相关性。柳维扬等[3]采用不同的建模方法构建枣树冠层色素的光谱定量反演模型,结果表明利用光谱数据预测色素含量的精度较高。然而以往此类研究中对作物生理指标预测,忽略了叶片近红外光谱的吸收峰重叠严重,导致光谱中冗余信息较多,影响高光谱预测色素含量模型的精度[9]。因此,如何更好地去除冗余信息,对提升模型运行效率、简化模型结构和增强模型稳定性具有重要的应用价值[7]。
变量筛选算法是常见的对高光谱波段进行信息挖掘的方法。筛选方法可分为2 类,一类是以变量数理统计特征为基础,主要包括无信息变量消除法(uninformative variable elimination,UVE)[10]、竞争性自适应重加权取样法(competitive adaptive reweighted sampling,CARS)[11]、连续投影算法(successive projections algorithm,SPA)[12]和相关系数分析法(correlation coefficient,CC)[13]等。另一类是基于智能优化算法的特征波长寻优方法,主要有遗传算法(genetic algorithm,GA)[14]、灰狼算法(grey wolf optimization algorithm,GWO)[15]、随机蛙跳算法(random frog,RF)[16-17]等。刘爽等[18]应用CARS 和SPA 等算法筛选光谱特征变量并建立大豆生理信息模型,校正集和预测集的相关系数Rc和Rp值提升至0.944 和0.911。YUAN 等[13]使用CC 和IRIV 等算法筛选特征波段并建立辣椒叶片相对叶绿素含量反演模型,决定系数R2cv和均方根误差RMSEcv分别达到0.81 和2.76。但此类基于高光谱技术检测作物生理指标的研究常采用单一算法进行特征变量提取,尽管这些算法可剔除部分包含冗余信息的变量或可全局搜索有效信息变量,但单独使用时仍存在保留变量过多、筛选结果存在较低信噪比变量或运算过程耗时长、模型参数复杂且难以彻底搜索所有可能变量组合等不足[9]。因此,寻找一种更合适的高光谱数据特征提取方法和更简洁的预测模型,以解决花生叶片光合色素含量的无损检测问题。
本文针对以上研究中的问题,尝试在单一变量筛选算法基础上,对提升模型精度效果最佳的部分算法进行耦合,拟通过提取最少量有效信息变量,简化模型结构,提高预测模型精确性及稳定性,为精准快速且无损的检测花生光合色素含量提供思路。
1 材料与方法
1.1 研究区概况
试验区位于安徽省淮南市田家庵区农田(32°33'58.11"N,117°1'11.54"E),位置如图1 所示。试验区地处亚热带季风气候和暖温带季风气候的过渡地带,受自然条件影响,淮南农作物具有明显的区域性和季节性。主要的农作物有水稻、小麦、玉米、油菜、花生等,综合生产能力较强。
图1 研究区位置及田块分布Fig.1 Location and field distribution of study area
1.2 数据源与预处理
1.2.1 数据源
试验于2023 年6 月27 日10:00—14:00 时进行,试验当天天气晴朗且无风无云。研究选用花生物候期的开花下针期,在选定的研究区范围内,划分100 个采样区域进行样本采集。采用Analytical Spectral Devices(ASD)分析光谱仪器公司生产的Field Spec4 型地物光谱辐射仪采集花生冠层叶片反射光谱,采集现场如图2。该仪器的光谱波长范围为350~2 500 nm,采样间隔为1.4 nm(350~1 000 nm)、2 nm(1 000~2 500 nm)。光谱仪使用前预热20 min,每次测量前进行标准白板校正。测量时探头始终保持垂直向下,距离花生冠层叶片高度大约50 cm,对每个区域选取的采样点重复测量5 次,取平均值作为该样本反射光谱测量结果,试验共采集69 个花生叶片样本。

图2 花生叶片数据测量Fig.2 Measurement of peanut leaf data
花生样本叶片色素含量的测定采用分光光度法。在光谱测量完成后将样本叶片剪下放入密封袋中,及时放入4 ℃冰箱内避光冷藏带回实验室。剪取主叶脉两边的叶片0.2 g,将样品剪碎研磨后加入95%的乙醇定容至25 ml,置于暗室浸提24 h,浸提后的溶液用分光光度计分别对波长470、649 和665 nm 进行测定,通过计算可得样本中叶绿素a、叶绿素b 和类胡萝卜素含量,其中叶绿素a、b 含量之和为叶绿素总含量。表1 对样本数据集色素含量进行描述性统计。

表1 数据集色素含量的描述性统计Table 1 Descriptive statistics of the pigment content of the dataset
1.2.2 数据预处理
试验使用的光谱仪测定波长范围是350~2 500 nm,已有的研究结果表明,叶片光谱在可见光波段与光合色素呈较强相关性[9],故截取400~1 000 nm 作为本次研究波长范围。地面高光谱数据受自身和背景环境等多种因素影响,为消除噪声等干扰因素对模型精度的影响,本研究采用Savitzky-Golay 卷积平滑(SG)结合标准正态变换(standard normal variate transformation,SNV)的预处理方式[18],有效过滤噪声,提高信噪比,同时减弱表面散射以及光程变化对漫反射光谱的影响[19]。
1.3 特征波长筛选方法
将预处理后的光谱数据分别通过CC、RF、UVE、SPA、CARS、IRIV 和GA 7 种单一变量筛选算法进行特征波长提取。CC 法计算光谱矩阵中每个波长和样本色素含量的相关系数,其相关系数值的绝对值越大,波段所包含的信息就越多[18],将400~1 000 nm 整个波段的原始光谱反射率分别与花生叶片叶绿素含量、类胡萝卜素含量进行相关性分析,通过P=0.05 的显著性水平检验,选取相关系数绝对值较大的波长;RF 法通常选择概率值较高的部分变量,或人为设置一个概率阈值,取概率值高于阈值的变量作为特征波长变量[20]。本研究RF 法参数设置为运行次数N为10 000 次,主成分个数A为10,蛙跳初始模型中的变量数Q为2;UVE 法由PLSR 回归系数衡量变量相关性,引入变量稳定指数作为筛选标准,消除在阈值线之间具有稳定性的无信息变量[21];SPA 法运算过程中不同的波长子集分别建立不同的多元线性回归模型,分别计算模型的RMSE 值[22];CARS 法中的蒙特卡罗采样会随不同采样次数得出不同的运算结果,因此试验设定不同的采样次数独立运算来筛选相对较好的变量[23]。本试验经过验证,将采样次数设为50 次时呈现最佳运算结果;迭代保留信息变量法(iteratively retains informative variables,IRIV)[24]经过多次测试后确定最大主成分个数为10,交叉验证次数为10;GA 法进行特征波长提取,其参数设置为群体数目69,交叉概率0.5,变异概率0.01,迭代次数100 次,依照上述参数独立运行GA100 次,每次输出0~1 二进制编码字符串,计算波长点标识为“1”的概率[25]。但单一算法在筛选特征波长时仍存在一些局限性,如保留变量冗余度高、共线性强,导致模型运行速度缓慢。因此,本试验通过建立单一算法筛选特征波长变量模型,根据模型评价指标优选出3 种最佳的算法进行两两耦合,利用耦合算法对高维光谱数据进行降维,简化模型结构,提升模型精度。
1.4 模型建立与评价
本试验使用偏最小二乘回归(partial least squares regression,PLSR)[26]、支持向量回归(support vector regression,SVR)[27-28]、梯度提升树(gradient boosting decision tree,GBDT)[29]和极端梯度提升(extreme gradient boosting,XGBoost)[30]这4 种模型来建立花生叶片色素含量预测模型。使用等间隔抽样法将69 个样本以2:1 的比例划分为46 个建模样本集和23 个验证样本集。本研究以单一算法和耦合算法所筛选的特征波长作为输入变量,构建花生叶片光合色素含量反演模型,通过模型的精度评估耦合算法的可行性。模型的预测精度由决定系数R2和均方根误差RMSE 的参数确定。R2反映了模型建立和预测的稳定性,R2值越接近于1,表明模型的稳定性及拟合度高;RMSE 值(RMSE)越接近于0,表明模型预测能力越强。
2 结果与分析
2.1 单一算法波长筛选结果
CC 法筛选花生叶片特征波长结果如图3a、3b。

图3 CC、RF、UVE 和SPA 方法筛选特征波长Fig.3 Characteristic wavelengths selected by CC (correlation coefficient),RF (random frog),UVE (uninformative variable elimination) and SPA (successive projections algorithm) algorithm
分别选取阈值线±0.3(Chls)和±0.55(Caros),筛选出特征波长变量分别为196 和271 个;图3c、3 d 为RF 法运行后每个波长变量被选择的概率,选取0.1 为阈值,分别得到满足条件的51(Chls)和61 个(Caros)波长变量;图3e、3f 为UVE 法变量稳定性分析结果,左侧曲线为光谱变量矩阵,右侧为添加的与光谱变量数相同的随机噪声矩阵,图3e 阈值线分别为21.303 6 和-22.337 3,图3f 阈值线分别为20.662 8 和-17.807 9,两阈值线之间为被剔除的无用变量,阈值线外分别筛选出32(Chls)和30 个(Caros)波长变量;SPA 法运行过程中随变量数的增加,RMSE 值整体趋势下降,图3 g 中方框表示当RMSE 为最小值0.230 53 mg/g 时,对应的子集包含23 个波长,图3 h 中RMSE 为最小值0.027 43 mg/g时,对应的子集包含24 个波长,筛选出的两个子集即为最优特征波长变量;CARS 法运行结果如图4,采样次数低时,在指数衰减函数的作用下保留的波长变量数呈迅速下降趋势,当采样次数上升时,保留变量数量下降速度减缓。经过十折交互检验所得交叉验证均方根误差RMSECV的变化趋势图结合所有变量在每次采样过程中的回归系数路径变化图,分析发现第19(Chls)和第25 次(Caros)采样时,RMSECV值最小即所选择的光谱变量子集最优,对应的最优变量数分别为74 和37 个;IRIV 法运行结果如图5a、5b,分别进行了5(Chls)和7 轮(Caros)迭代,光谱波长变量从601 个迅速减少,基本剔除了无用信息波长和干扰波长,在反向消除后最终得到18(Chls)和11 个(Caros)特征波长变量,因篇幅所限,仅展示两个色素反向消除前一轮迭代后余下波长的DMEAN 和P值;GA 法运行结果如图5e、5f,筛选出频率较高的18(Chls)和24 个(Caros)特征波长变量。

图4 CARS 方法筛选特征波长Fig.4 Characteristic wavelengths selected by CARS (competitive adaptive reweighted sampling) algorithm

图5 IRIV 和GA 方法筛选特征波长Fig.5 Characteristic wavelengths selected by IRIV (iteratively retains informative variables) and GA (genetic algorithm)
图6 是针对不同算法在400~1 000 nm 波长中筛选特征波长变量结果,其结果显示花生叶片光合色素的敏感波长所在位置。7 种算法所提取出来的叶绿素含量反演模型变量数量顺序如下:CC >CARS >RF>UVE>SPA>IRIV=GA,分别为196、74、51、32、23、18 和18个特征波长变量,提取波长数量分别占全波段的32.61%、12.31%、8.49%、5.32%、3.83%、3.00%和3.00%;所提取出来的类胡萝卜素含量反演模型变量数量顺序如下:CC >RF>CARS>UVE>SPA=GA>IRIV,分别为271、61、37、30、24、24 和11 个特征波长变量,提取波长数量分别占全波段的45.09%、10.15%、6.16%、4.99%、3.99%、3.99%和1.83%,结果显示单一算法筛选特征波长能有效剔除冗余光谱信息,提高建模效率。
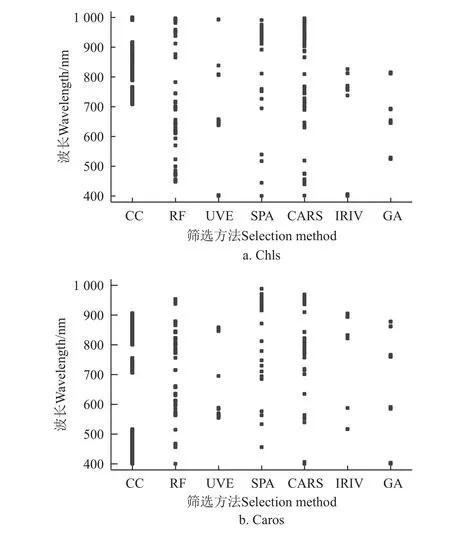
图6 单一算法筛选特征波长分布Fig.6 Screening characteristic wavelength distribution by single algorithm
2.2 单一算法模型建立与分析
表2 是由不同色素的7 种单一变量筛选方法建立的模型预测结果。表2 在叶绿素含量反演模型中,基于UVE、IRIV 和GA 法变量压缩率达到94.68%、97.00%和97.00%,所建模型性能整体优于全波段所建模型。其中,UVE-XGBoost 模型达到了全局最佳精度,R2=0.591,RMSE=0.244 mg/g;在类胡萝卜素含量反演模型中,基于UVE、IRIV 和GA 法变量压缩率分别为95.00%、98.17%和96.01%,基于GA 法所建模型精度整体提升,UVEPLSR 和IRIV-XGBoost 模型则达到全局最佳精度,R2=0.565,RMSE=0.056 mg/g。CC、RF、SPA 和CARS 法虽也对变量进行了有效降维,但就总体模型精度而言,无明显提升。由此表明,UVE、IRIV 和GA 法适用于筛选花生叶片光合色素含量的特征波长,能够有效压缩建模数据量,提高模型运行效率和稳健性,效果优于其他4 种算法。

表2 基于7 种单一算法的不同色素含量模型预测结果Table 2 Prediction results of different pigment content model based on 7 single algorithms
2.3 耦合算法波长筛选结果
本试验将优选出的UVE、IRIV 和GA 3 种算法进行两两耦合,结合光谱数据和试验的实际情况,设计耦合方式为UVE-IRIV、GA-IRIV 和GA-UVE 三种形式,图7是耦合算法筛选特征波长变量结果。在基于耦合算法的叶绿素含量反演模型中,利用UVE-IRIV、GA-IRIV 和GA-UVE 法二次降维,分别提取出8、10、10 个变量;类胡萝卜素含量反演模型中,利用UVE-IRIV、GA-IRIV和GA-UVE 法分别提取出10、14、11 个变量。
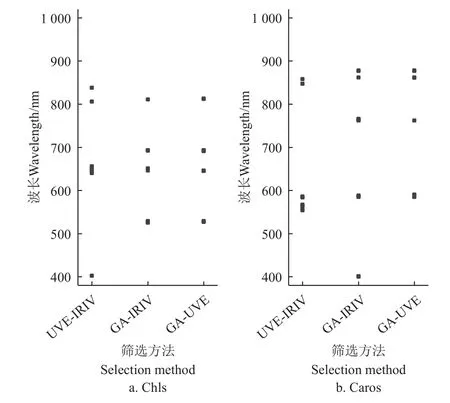
图7 耦合算法筛选特征波长分布Fig.7 Screening characteristic wavelength distribution by coupling algorithms
2.4 耦合算法模型建立与分析
分别将UVE-IRIV、GA-IRIV 和GA-UVE 法提取的特征波长作为输入变量来建立花生叶片光合色素的定量分析模型,表3、图8、图9 结果表明,利用耦合算法筛选特征波长所建立的色素含量反演模型整体精度有明显提升。其中,基于GA-IRIV-XGBoost 的叶绿素含量反演模型预测集为R2=0.622,RMSE=0.235 mg/g,相对全波段、单一算法及其他耦合算法提取的特征波长所建立的模型,该模型达到最佳精度,同时变量压缩率可达98.34%;最佳类胡萝卜素含量反演模型为UVE-IRIV-XGBoost 模型,预测集为R2=0.575,RMSE=0.056 mg/g,变量压缩率同为98.34%。此结果进一步证明了本研究所采用的耦合算法筛选波长方法可对全波段的进行有效变量信息提取,减少变量数目和建模时间,提升模型鲁棒性。

表3 基于3 种耦合方式不同色素含量建模预测集结果Table 3 Prediction results of different pigment content model based on 3 coupling algorithms
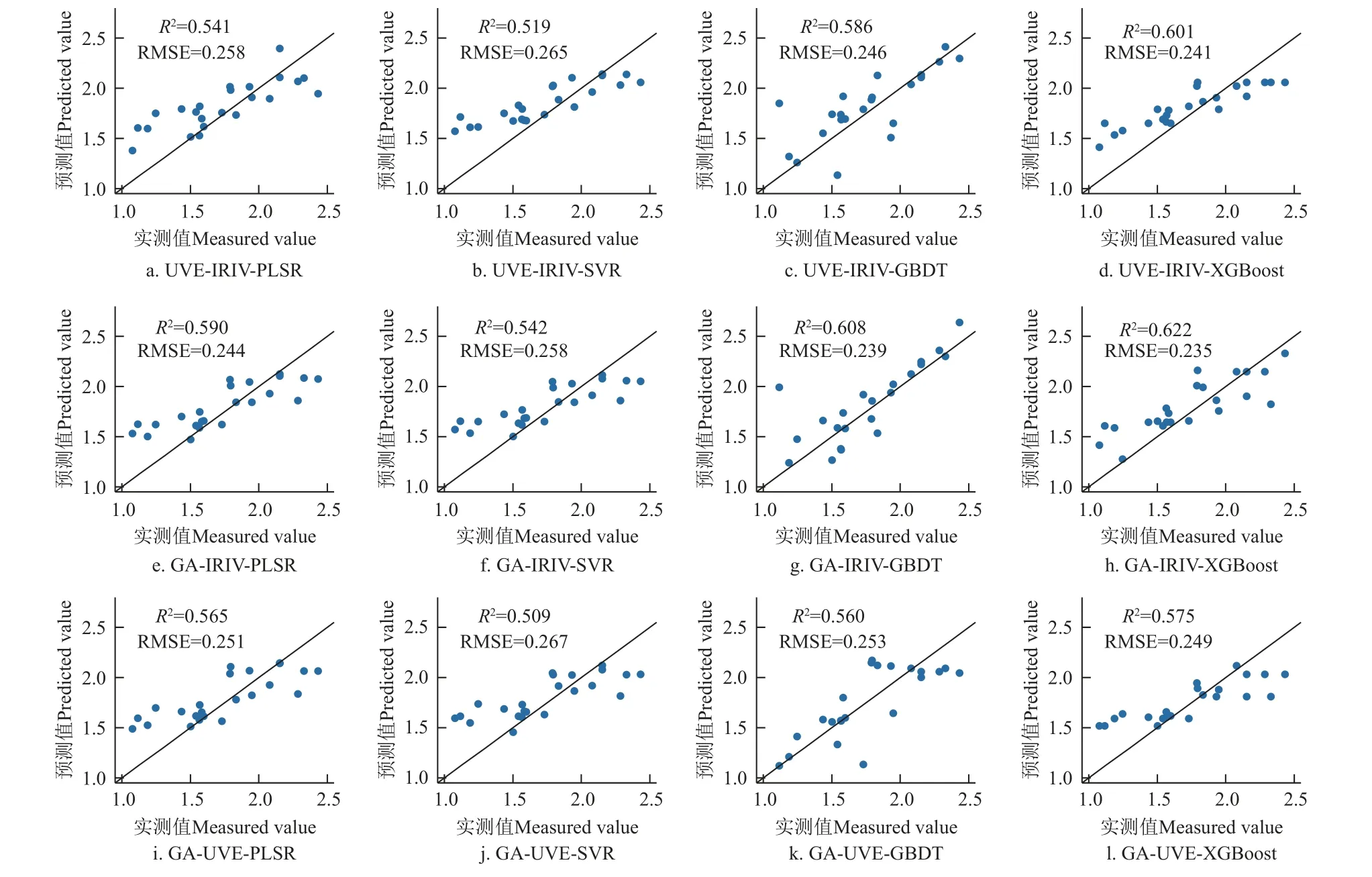
图8 不同耦合算法和建模方法的叶绿素含量反演模型预测结果 (mg·g-1)Fig.8 Prediction results of chlorophyll content inversion model with different coupling algorithms and modeling methods

图9 不同耦合算法和建模方法的类胡萝卜素含量反演模型预测结果 (mg·g-1)Fig.9 Prediction results of carotenoid content inversion model with different coupling algorithms and modeling methods
3 讨论
CC、RF、UVE、SPA、CARS、IRIV 和GA 7 种波长筛选算法能在极短的计算时间内提取出少量包含有用信息的特征波长,实现变量有效降维,提升模型运行速率和预测精度。形成此结果的原因是近红外光谱波长间存在严重自相关性,基于高光谱反演光合色素含量的研究若未充分考虑这一情况,将会导致波长变量与色素含量的相关性较弱[9,13]。UVE、IRIV 和GA 法 3 种算法在本研究中表现出优异效果,其中,在单一算法筛选特征波长变量建立类胡萝卜素含量预测模型中,IRIVXGBoost 模型达到最高精度;以耦合方式建立色素含量预测模型时,GA-IRIV-XGBoost 叶绿素含量预测模型和UVE-IRIV-XGBoost 类胡萝卜素含量预测模型表现出最好预测效果。从上述结果可以看出,IRIV 算法无论是单一使用还是耦合使用,都表现出优于其他算法的性能。YUAN 等[13]采用CC、sCARS 和IRIV 反演辣椒相对叶绿素含量的研究中也证实了这种情况。这是由于信息量较强的变量由于相互间具有显著的积极影响,被选取为最佳变量集,但信息量较弱的变量所具有的积极影响被忽略了,因此并不一定达到最优变量集。IRIV 算法注重波长变量间的协同效应,通过多次迭代循环消除无信息或干扰的变量后再进行反向消除,搜索出重要变量的同时保留了信息量较小的变量[9,24,31]。对比单一算法和耦合算法提取的特征波长变量数目和建立的反演模型结果(表2、表3),耦合算法在降低模型复杂性和提高模型精确性上具有明显优势,与许丽佳等[17]和WANG 等[31]的试验呈现相同结果。主要原因可能在于单一算法筛选特征波长变量较为集中,导致多样性缺乏,部分包含有用信息的波段缺失。而耦合算法能一定程度上改善光谱信息缺失问题,提高特征波段的多样性,所以具有更好的光谱信息提取性能。
本研究选用1 个线性模型PLSR 和3 个非线性模型SVR、GBDT 和XGBoost,在基于高光谱技术预测花生叶片光合色素含量阶段均取得了良好的结果。且同陈倩等[32]采用 PLSR 和 XGBoost 等模型反演冬小麦叶片相对叶绿素含量的结果,GBDT 和XGBoost 相比于PLSR 和SVR,大多数情况表现出更优的预测效果。这是因为PLSR 是一种线性回归模型,在处理高维数据时具有一定的局限性,而GBDT 和XGBoost 可以更好地解决自变量和因变量之间的复杂非线性关系问题[13]。且与已有研究YUAN 等[13]的试验结果相同,GBDT 和XGBoost模型精度接近,但不同的是本研究中这两种模型的精度高于PLSR。这可能是由于作物类型和环境因素不同,以及GBDT 和XGBoost 模型所配置的参数不同导致的结果。
综合以上讨论,能够进一步说明耦合算法对提高作物生理指标含量检测精度方面具有有效性,在本研究中,耦合算法可以最大限度地提取具有有效信息的特征波长,能够简化模型结构并增强模型鲁棒性,对花生叶片光合色素含量预测具有一定的指导和实践意义。GBDT和XGBoost 在各变量组中体现出的优势,说明了此类模型应用到花生叶片光合色素含量定量分析中具有较强的适用性、较高的预测精度和泛化能力,有着重要的研究价值。
本研究虽对基于高光谱技术预测花生叶片光合色素含量进行了充分的研究并取得一定成果,但鉴于试验采用的数据量有限和作物生长期单一等因素限制,该研究结果能否应用于作物整个生长期还需进一步考察。且由于不同环境因素和所选用各种算法方案影响,模型参数会产生差异,所以研究结果是否通用于不同试验方案还需进一步探究。
4 结论
以开花下针期花生叶片为研究对象测量冠层叶片的高光谱和光合色素含量数据,对原始高光谱进行SG 结合SNV 预处理后分别采用7 种单一算法筛选特征波长变量,建立PLSR、SVR、GBDT 和XGBoost 花生叶片色素含量预测模型,从模型预测结果中优选出3 种筛选变量算法进行两两耦合后再次筛选建立预测模型。研究结果表明:
1)通过对比研究采用的7 种单一筛选波长变量算法可知,7 种算法均对变量进行了有效降维,且优选出UVE、IRIV 和GA 算法。其中,叶绿素含量反演最佳模型为UVE-XGBoost 模型,R2=0.591,RMSE=0.244 mg/g;类胡萝卜素含量反演最佳模型为 UVE-PLSR 和IRIVXGBoost 模型,R2=0.565,RMSE=0.056 mg/g。
2)对于分别基于UVE-IRIV、GA-IRIV 和GA-UVE 3 种耦合算法的光合色素含量预测模型,模型精度整体提升。在叶绿素含量反演模型中,GA-IRIV-XGBoost 模型达到最高精度,R2=0.622,RMSE=0.235 mg/g;在类胡萝卜素含量反演模型中,UVE-IRIV-XGBoost 模型达到最高精度,R2=0.575,RMSE=0.056 mg/g。研究表明耦合算法可以有效压缩变量、简化模型且提高模型稳健性,可为花生叶片光合色素含量预测提供新的思路。
3)通过对比花生叶片叶绿素含量和类胡萝卜素含量反演模型的预测精度,表明叶绿素含量的预测精度优于类胡萝卜素含量。
猜你喜欢
特产研究(2022年6期)2023-01-17 05:06:16
中等数学(2022年5期)2022-08-29 06:07:38
娃娃乐园·综合智能(2022年9期)2022-08-16 02:00:08
科学大众(2021年9期)2021-07-16 07:02:50
石油地球物理勘探(2017年4期)2017-12-18 07:14:55
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
中国调味品(2017年2期)2017-03-20 16:18:21
中国照明(2016年4期)2016-05-17 06:16:15
现代食品(2016年24期)2016-04-28 08:12:04
