
基于多尺度和局部特征融合的人脸表情识别
2023-11-25 05:29:12张金栋王宏志
长春工业大学学报 2023年4期
张金栋, 王宏志
(长春工业大学 计算机科学与工程学院, 吉林 长春 130102)
0 引 言
随着科技水平的快速发展,人工智能逐渐进入我们的生活,而如何在人机交互中让机器获得我们的情感状态成为机器视觉领域研究的热点。而人脸表情识别算法基本分为传统算法和深度学习两种,随着算力的不断提高,基于深度学习的人脸表情识别模型已经凭借其强大的拟合能力,以及端到端的训练方式获得了越来越多人的青睐。
目前,人脸表情识别已经广泛应用到各个领域。在智慧交通领域[1-2],用人脸表情识别技术来监测驾驶员情绪是否稳定,是否属于疲劳驾驶、酒后驾驶等状态,为交通安全提供更有效的保障;在智慧教育领域[3-4],人脸表情识别可以帮助教育工作者更好地了解学生的情绪状态和学习效果;在智慧医疗领域[5-6],人脸表情识别可以在情感类疾病的诊断和疼痛评估方面提供新的数据支撑和判断依据;在人机交互领域[7,8],现实增强和虚拟现实中通过识别用户的表情和情感信息,自动调整虚拟信息的呈现方式和内容,从而提高交互的效率。
虽然人脸表情识别算法已经被广泛应用到各个领域中,但是还仍然存在模型训练困难、鲁棒性不足等问题,诸多学者也提出了自己的解决方法。针对传统算法,文献[9-11]对常见的LBP(Local Binary Pattern)算子和方向梯度直方图(Histogram of Oriented Gradient, HOG)算法进行了改进,克服了人脸图像纹理的相邻像素丢失问题,有效地选择了最优的特征数据。在深度学习方面,注意力机制被认为是可以有效提升模型准确率的可嵌入模块,文献[12-14]使用通道注意力机制和自注意力机制等方式让模型更加关注输入图像中更具有决定性因素的部分,提升了网络模型的准确率。而文献[15-17]则使用残差结构构建网络,加大了网络中深层特征和浅层特征之间的联系,避免了由于网络过深而产生的过拟合问题。
为了更好地利用图像中的局部特征和全局特征间的联系,并获得图像中更多的特征信息,文中以ResNet18网络为基础模型,构建了一个融合局部特征和全局特征的网络结构,加入多尺度卷积模块,用迁移学习方式初始化训练权重,并通过在FER-2013数据集和RAF-DB数据集上的实验,验证了文中模型结构的有效性。
1 网络模型结构
1.1 整体网络模型结构
文中网络模型为双路结构,上路网络选择多尺度卷积块和ResNet18网络中的四个残差块组成全局特征提取网络,输入图像为原始图像;下路网络选择四层卷积层和一层池化层组成局部特征提取网络,输入图像为原始图像16等分后的局部图像。其中为了减少网络模型整体参数,分割后的16张局部图像共享下路网络模型参数,具体网络结构如图1所示。
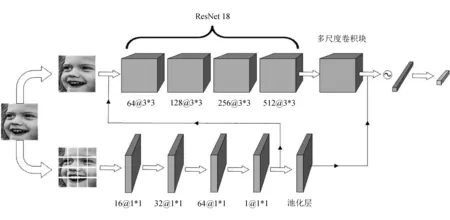
图1 网络模型整体结构
其中,上路网络ResNet18中的64@3*3、128@3*3、256@3*3和512@3*3表示对应残差块中四层卷积层的卷积核数量,分别为64、128、256和512,卷积核的大小为3*3。下路网络中的16@3*3、32@3*3、64@3*3和1@3*3表示对应四层卷积层的卷积核数量,分别为16、32、64和1,卷积核的大小为1*1。
从图1可以看到,网络共进行了两次局部特征和全局特征的融合:
第一次融合是将分割后的图像经过下路四层卷积网络提取到的与原始图像大小相同的局部特征,与原始图像进行融合,然后输入上路网络;
第二次融合是分割后的图像经过下路整体网络提取到的大小为4*4的局部图像特征,与上路经过多尺度卷积块提取得到的图像特征进行融合,然后输入全连接网络进行分类。
整体网络特征提取分类具体公式为
M(F)=σ(MLP(MC(f))),
(1)
式中:F----输入图像;
M(F)----分类结果;
MLP----通过全连接层进行特征提取;
σ----通过Sigmoid函数进行最终分类;
MC(f)----网络卷积层提取特征,其具体公式为
Mc(F)=Mu[F*Md(F)]*AvgPool[Md(F)],
(2)
式中:F----输入图像;
Mc(F)----经过网络卷积层后提取到的特征;
Md(F)----输入图像分割后经过下路四层卷积层提取特征;
Mu----经过多尺度卷积块后提取到的特征;
AvgPool----平均池化。
1.2 多尺度卷积块
在使用卷积神经网络提取特征的时候,不同大小的卷积核感受野不同,所提取到的特征也不一样。为了更好地获得图像中的特征,文中构建了一个多尺度卷积块,在同一层中使用不同大小的卷积核以及池化操作提取特征,具体结构如图2所示。
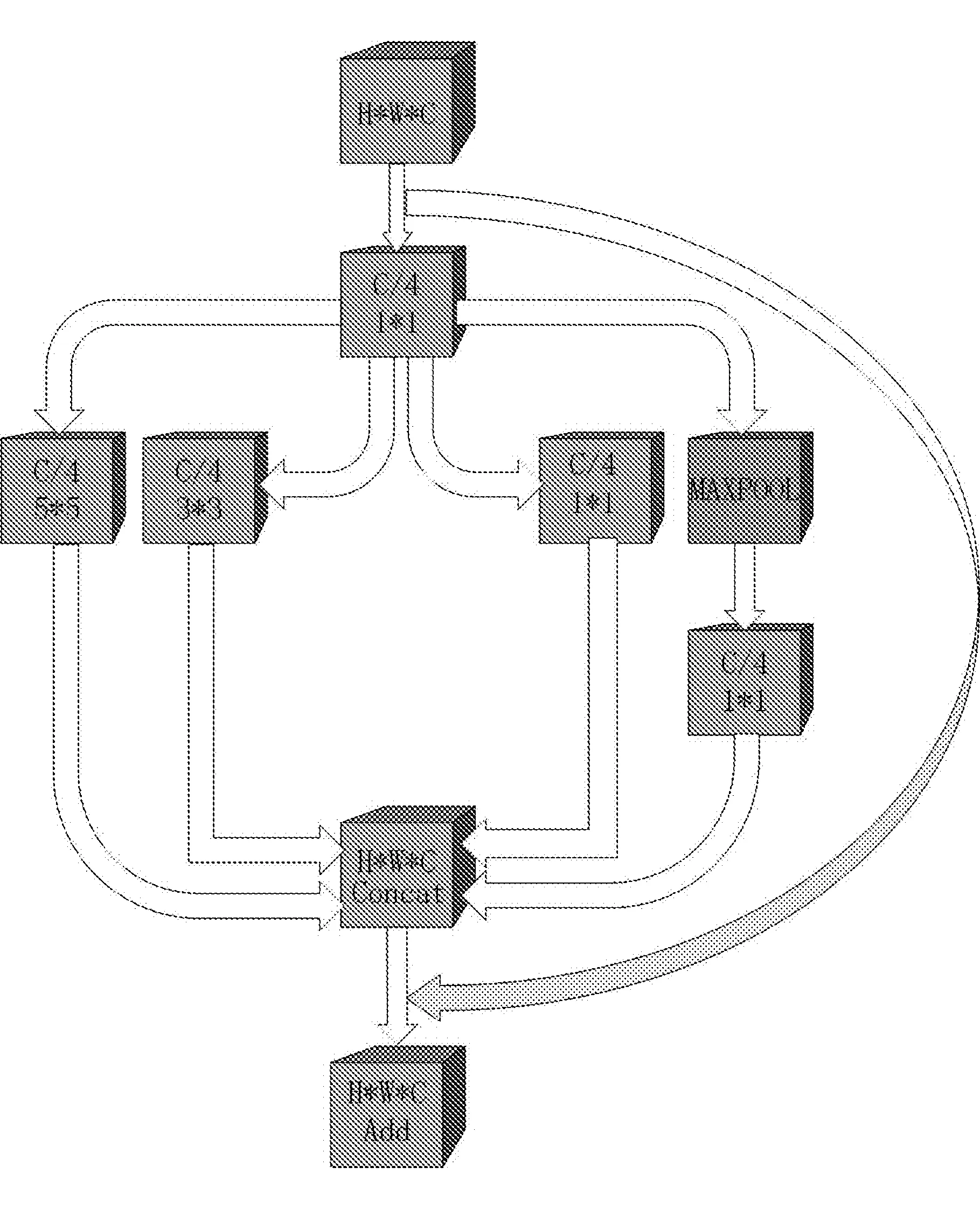
图2 多尺度卷积块结构
图中:H,W,C----分别表示高、宽和通道维度;
H*W*C----输入特征的大小;
C/4----该卷积层的卷积核个数;
1*1,3*3,5*5----该卷积层的卷积核大小;
MAXPOOL----最大池化层;
Concat----特征拼接操作;
Add----特征相加操作。
多尺度卷积块特征提取公式为
Mout(FI)=FI+Mcp(FI),
(3)
式中:FI----输入原始特征;
Mout----多尺度卷积块输出特征;
Mcp----经过卷积层和池化层拼接后的特征,其具体公式为

(4)
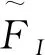
C1,C2,C3,Cp----分别为经过卷积核大小为1*1,3*3,5*5的卷积层和池化层后的特征;
Concat----在通道内将特征拼接。
从式(4)和图2可以看到,原始特征在输入到不同大小卷积核的卷积层以及池化层之前,先经过一层卷积核数量为原始特征通道数四分之一的卷积层,这样做的目的是在保证提取并融合各个尺度特征的前提下,减少多尺度卷积块的参数。而为了防止在网络训练过程中产生梯度消失的问题,在每一个卷积层后都进行了批标准化(Batch Normalization)操作,其公式为

(5)



2 实验及分析
2.1 数据集预处理
人脸表情数据集根据是否在实验室状态下收集分为两种,在实验室状态下收集到的数据集一般都存在样本数量少和丰富度低的问题,因此虽然实验室数据集的准确率普遍很高,但依然无法真实反映网络的性能。故文中选用非实验室状态下收集到的数据集FER-2013和RAF-DB来进行实验。
在FER-2013数据集的35 886张图像中,有28 708张是训练集,3 589张是验证集,3 589张是测试集,而RAF-DB数据集的29 672张图片中,有12 271张训练图像和3 068张测试图像。两个数据集的表情分类为生气、厌恶、恐惧、开心、伤心、惊讶和中性7种,在输入网络前将图片大小均改变为112*112,并进行随机水平翻转、随机角度旋转、随机剪裁、随机擦除和归一化的数据增强方式。
2.2 实验结果与分析
文中实验使用深度学习框架为Pytorch1.10和python3.7,操作系统环境为Windows10,CPU为i9-10920X,GPU为RTX3090。批处理大小设置为256,使用SGD优化器,动量设置为0.9,学习率设置为0.1,每10轮变为原来的十分之九,并使用迁移学习对网络参数进行初始化。
文中算法在FER-2013数据集和RAF-DB数据集的准确率曲线如图3所示。

图3 准确率曲线
从图3可以看到,两个数据集的最终准确率分别达到72.16%和86.83%,由于通过迁移学习对参数进行初始化,模型训练初期准确率提升速度很快,在训练后期也没有产生过大的准确率波动情况。而FER-2013数据集与RAF-DB数据集相比,由于其样本本身难度更大,分辨率更低,还存在一定的标签标注错误情况,因此准确率达到峰值,并趋于稳定所需的训练轮数明显增多,准确率也更低。
文中算法在FER-2013数据集和RAF-DB数据集的混淆矩阵如图4所示。

(a) FER-2013数据集 (b) RAF-DB数据集
从图4可以看到,两个数据集中识别准确率最高的表情均为开心,分别达到90.3%和94.1%。而两个数据集识别率最低的表情类别却并不一致,FER-2013数据集中为恐惧,准确率只有57%,RAF-DB数据集中为厌恶,准确率只有53.1%。
文中算法与其他文献算法在FER-2013数据集和RAF-DB数据集上的准确率比较见表1。
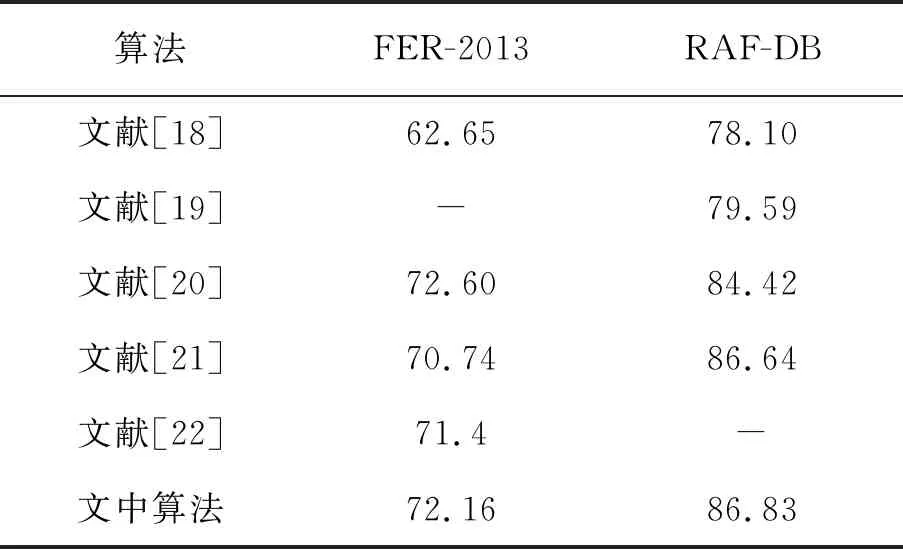
表1 模型准确率对比 %
从表1可以看出,除了在FER-2013数据集中的准确率低于文献[20]中的算法,其它均高于对比算法,证明了文中算法的有效性。
3 结 语
以ResNet18网络为基础,采用双路网络模型对输入图像的全局特征和局部特征进行提取,并进行两次全局和局部的特征融合,将图像的全局和局部联系起来,并构建了多尺度卷积块,利用不同大小的卷积核提取到感受野大小不同的特征,更好地利用图像中包含的特征信息,通过在FER-2013和RAF-DB数据集中的实验,证明了文中算法的有效性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
