
基于KPCA-SSA-BP的农业气象灾害预测
2023-11-25 10:38李思宇
江苏农业学报 2023年6期
李思宇, 李 玥
(1.甘肃农业大学理学院,甘肃 兰州 730070;2.甘肃农业大学信息科学技术学院,甘肃 兰州 730070)
中国是世界农业大国,但近几十年来农业气象灾害频繁发生,严重影响农业发展[1]。不利的气象条件引起的农作物减产被称为农业气象灾害[2]。据统计分析,中国农业受各种气象灾害影响的面积约为601.8 hm2,受灾人口约6×108[3],其中受灾面积较大的省份为山东省、河南省和黑龙江省[4]。农业气象灾害的准确预测可以为及时采取抗灾减灾措施提供科学依据,保证农业生产稳定发展,所以对农业气象灾害进行预测意义重大。
近年来神经网络被广泛应用于各个领域,一些学者也提出了利用神经网络预测农业气象灾害的方法。黄慧等[5]基于反向传播(BP)神经网络模型,根据气象资料与自然灾害统计数据,对湖南省洪灾、旱灾受灾率进行了预测,结果表明多元回归模型的预测精度低于BP神经网络模型。Li等[6]运用灰色关联分析方法,分析河南省主要农业气象灾害因子与粮食作物产量的关联度,基于灰色BP神经网络模型,对各种自然灾害覆盖率和影响率进行了模拟和预测,模拟预测结果较好。史风梅等[7]利用累加预测模型对黑龙江省的农业气象灾害进行了预测,模型是根据黑龙江省的农业洪涝、干旱资料建立的,其预测结果较好。李博等[8]以广东省台风灾害为例,在气象灾害发生后,利用GA-BP神经网络模型对广东省受灾引起的经济损失进行了预测,预测效果较好。杨雪雪等[9]采用核主成分分析(KPCA)对数据进行降维优化,通过RBF模型对优化后的数据进行训练,结果表明,KPCA-RBF预测模型的学习收敛速度较快,预测精度较高。Luan[10]采用基于主成分分析构建的BP神经网络预测方法和基于MM5数值模型的地质灾害预测方法,建立地质灾害分类短期客观预测模型,结果表明,这2种预测方法的拟合效果较好。
现有研究大多集中在农业气象灾害风险评估模型方面[11-13],分析农业气象灾害带来的影响。预测农业气象灾害的模型比较少,虽然前人研究结果为农业气象灾害预测提供了理论指导,但由于各地区地势的不同以及天气的波动性变化,所以不同地区的农业气象灾害预测模型存在差异性和不稳定性。已有的灰色预测模型对数据的光滑度要求很高,在数据光滑度较差的情况下灰色预测模型的精度不高,甚至通不过检验。农业气象灾害数据较为复杂,数据光滑度很差,不适合用灰色预测模型进行预测。BP神经网络适合数据较为复杂的预测模型,但BP神经网络收敛速度缓慢,容易陷于局部极小值,需要进一步优化。为了科学有效地提高山东省农业气象灾害的预测精度,本研究拟在前人研究的基础上,分析农业气象灾害致灾因子,提出BP神经网络预测模型,考虑到BP神经网络的不足,采用麻雀搜索算法(SSA)对BP神经网络进行优化,并与粒子群算法(PSO)和遗传算法(GA)优化的BP神经网络预测模型进行比较,以期为优化农业气象灾害预测模型提供理论依据。
1 材料与方法
1.1 数据来源
山东省地处中国东部沿海,黄河下游,是中国重要的农业大省。但农作物产量受气候条件的影响较大,恶劣天气是制约农业发展的一个重要因素[14]。旱灾和涝灾是最主要的农业气象灾害。本研究选取山东省1978-2018年受灾(洪涝、干旱)的农作物种植面积以及山东省内17个气象站点1978-2018年的逐年气象数据。本研究所用的数据资料主要来自《新中国60年农业统计资料》[15]、山东省统计年鉴官网、NOAA官网,其中部分缺失值采用插值法进行补充。
1.2 指标的选取
农作物产量比正常年份减少10%以上的播种面积被称为受灾面积,减少30%以上的播种面积为成灾面积,农作物受灾面积和成灾面积与总播种面积之比被定义为受灾率和成灾率[16]。受灾率可避免受往年播种面积变化的影响,客观地反映出洪涝和干旱灾情的轻重[17]。选取山东省1978-2018年受灾总面积、旱灾受灾面积和洪灾受灾面积作为本研究的样本因子。对样本因子进行处理,把旱灾受灾率、洪灾受灾率作为评价因子。
气象要素偏离平均气象,就会形成气象异常,影响农业生产,成为气象灾害的致灾因子[18]。农业气象灾害按致灾因子可分为单因子和综合因子2大类。根据农业气象灾害致灾因子和年气象站含有的数据,本研究选取最低气温(℃)、最高气温(℃)、平均最低气温(℃)、平均最高气温(℃)、平均气温(℃)、最大日降水量(mm)、日降水量≥0.1 mm日数、20-20时降水量(mm)、年累计降水量(mm)、平均相对湿度(%)、平均水气压(hPa)、日照时数共12个影响因子。
1.3 试验平台
本研究的试验环境为Window 64位系统,使用Matlab2018b软件对原始数据进行预处理,建立BP、SSA-BP、PSO-BP、GA-BP神经网络模型。
1.4 预测模型的方法
1.4.1 核主成分分析法 核主成分分析(KPCA)是Schölkopf等[19]提出的将核函数引入主成分分析(PCA)的方法,是对PCA的扩展。KPCA主要使用核函数,即对于当前非线性不可分的数据,将其映射到更高维的空间进行线性可分,然后进行降维,提高了原始数据的质量,降低了计算成本。本研究首先利用KPCA对原始数据进行降维。
核主成分分析的具体步骤如下:
步骤一:用核函数表示特征空间中重构变量的内积。
(1)
式中:Xi是第i个样本的所有列;Xj是第j个样本的所有列;n表示矩阵的维度;α是核函数的宽度函数。
步骤二:对核矩阵K中心化,得到中心化的核矩阵K′:
K′=K-Ln×K-K×Ln+Ln×K×Ln
(2)
式中:Ln是N×N的矩阵。
步骤三:计算核矩阵的特征值,将特征向量和特征值从大到小排序。
步骤四:计算各特征值的累计贡献率r,给定贡献率阈值p,若r大于p,则选取前t个分量作为降维后的数据。
1.4.2 麻雀搜索算法优化BP(SSA-BP)神经网络模型 麻雀搜索算法是由Xue等[20]在2020年提出的一种新型优化算法,该算法具有更高的搜索能力。在觅食时,麻雀被分为2部分:发现者和接受者,分别负责提供方向和跟随它们寻找食物。当麻雀感觉到危险时,就会产生反扑食的行为,并更新它们的种群状态。
麻雀搜索算法实现步骤如下:
第一步:初始化参数值。
第二步:开始循环
第三步:对种群进行排序,得到最佳适应度值和最优麻雀个体位置。
第四步:食物搜索,根据公式3更新发现者位置。

(3)

第五步:按公式4更新加入者位置。
(4)

第六步:反捕食行为,重新定位麻雀种群。
(5)
第七步:更新历史最优适应度。
第八步:执行第二步到第七步,到达最大迭代次数时,结束循环。得到最优个体的位置和适应度值。
1.4.3 神经网络模型的参数选择 根据隐含层节点数k=m+n+a的经验公式,其中a∈[1,10],m表示输入层个数,n表示输出层个数,利用遍历选优的原则,选出适应度值最小时对应的隐含层节点数值[21]。所以本研究的BP神经网络结构为6-10-2,即输入层、隐含层、输出层分别输入6、10、2。为了证明SSA-BP算法的优越性,利用粒子群算法、遗传算法改进BP神经网络模型,将结果进行对比,为保证公平,同一参数设置相同,关键参数如表1所示。设置好参数,把数据分别带入传统BP神经网络模型、SSA-BP模型、GA-BP模型和PSO-BP模型中进行分析。

表1 参数选择
1.4.4 模型训练与精度验证 基于山东省1978-2018年17个气象站点的逐年气象数据,各影响因子数据求平均值作为山东省的逐年气象数据,利用KPCA降维后的影响因子作为模型输入数据,旱灾受灾率和洪灾受灾率为输出数据。将研究时段分为1978-2012年和2013-2018年2个时段,第一时段数据用于模型训练,第二时段数据用于模型验证。以平均绝对误差(MAE)、均方误差(MSE)和均方根误差(RMSE)3个指标形成评价指标体系,用于评判不同模型的精度[22]。MAE用来衡量预测值与真实值之间的平均绝对误差,MAE越小表示模型越好;MSE的值越小说明预测模型有更好的精确度;RMSE可以反映数据的离散程度,做非线性拟合时,RMSE越小越好。计算式分别为:
(6)
(7)
(8)
式中,i表示逐年数据个数;m表示年数;Xi和Yi分别表示预测值、实测值。
2 结果与分析
2.1 核主成分分析
首先对农业气象灾害数据进行核主成分降维处理,降低训练时间,保留原始变量的大部分信息,从而可以提高模型性能。主成分累计方差贡献率见表2。将主成分累计方差贡献率设定为90.00%。表2显示,前6个主成分的累计方差贡献率达到92.09%,即前6个主成分包含了所有指标的大部分信息。
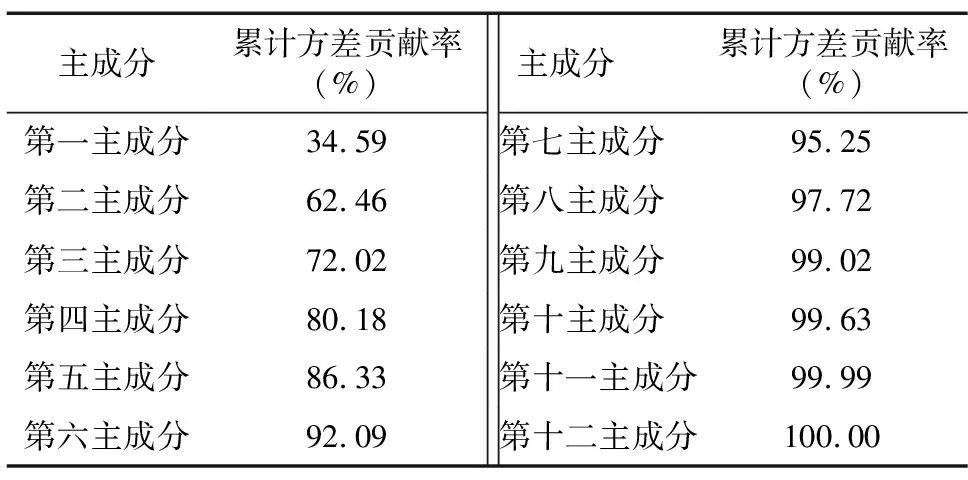
表2 主成分累计方差贡献率
2.2 神经网络
利用训练好的神经网络模型进行预测。图1显示,SSA-BP神经网络模型的适应度值最小且最快趋于平稳,说明SSA-BP神经网络模型的迭代精度和趋于平稳的速度要大于PSO-BP神经网络模型和GA-BP神经网络模型。

BP、PSO-BP、GA-BP、SSA-BP见表1注。
表3是不同模型对旱灾受灾率的预测值及其实测值,表4是不同模型对洪灾受灾率的预测值及其实测值。我们发现,与传统BP神经网络模型相比,总体上SSA-BP神经网络模型对旱灾受灾率的预测值更接近实测值,说明将SSA与传统BP神经网络模型相结合产生了更好的预测效果。此外,我们还比较了不同优化算法的性能。为了进一步提高预测结果的可靠性,将SSA-BP模型、GA-BP模型、PSO-BP模型、传统BP神经网络模型的MAE、MSE、RMSE进行比较,具体数值见表5和表6。

表3 不同模型对旱灾受灾率的预测结果
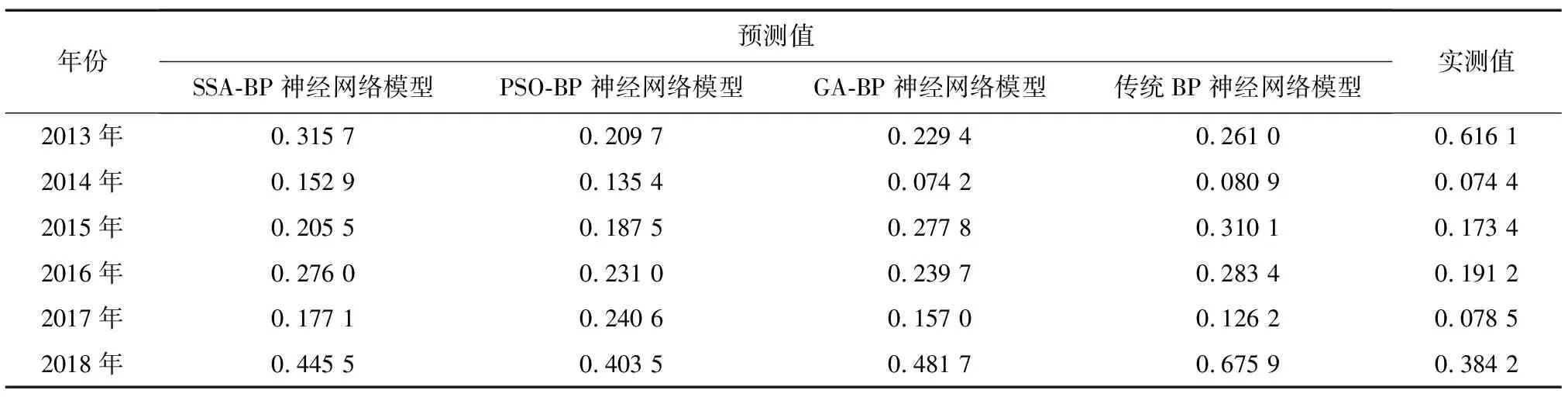
表4 不同模型对洪灾受灾率的预测结果

表5 旱灾受灾率的模型评价指标对比

表6 洪灾受灾率的模型评价指标对比
表5显示,对旱灾受灾率的预测中,SSA-BP神经网络模型的MAE最小,与传统BP神经网络模型相比,SSA-BP神经网络模型、PSO-BP神经网络模型、GA-BP神经网络模型的MAE分别下降40.91%、18.96%和25.92%。同样,SSA-BP神经网络模型产生的MSE最小,与传统BP神经网络模型相比,SSA-BP神经网络模型、PSO-BP神经网络模型、GA-BP神经网络模型的MSE分别降低了41.47%、23.06%和32.36%;与传统BP神经网络模型相比,SSA-BP神经网络模型、PSO-BP神经网络模型、GA-BP神经网络模型的RMSE分别下降23.55%、12.28%和17.74%。
表6显示,对洪灾受灾率的预测中,与传统BP神经网络模型相比,SSA-BP神经网络模型、PSO-BP神经网络模型、GA-BP神经网络模型的MAE分别下降了29.48%、24.45%和23.03%,MSE分别下降了50.87%、17.96%和25.69%;RMSE分别下降了29.96%、9.49%和13.88%。
从模型的RMSE数值中可以看出,SSA-BP神经网络模型的预测结果比较好。结果表明,与GA相比,SSA更好地提高了BP神经网络模型的预测精度。虽然个别预测值出现偏离,但农业气象灾害本身就具有突发性和随机性,所以不会影响模型的有效性。通过RMSE的比较可以看出,SSA-BP模型的预测精度得到了提高,预测值整体更接近实测值。
3 讨论
对于农业气象灾害的预测,现有研究大多集中在农业气象灾害影响因子的灰色关联,分析其主要影响因子,再进行BP神经网络模拟。可是BP神经网络初始的阈值和权值是随机的,不同初始值对预测结果影响较大。PSO、GA、SSA都可以对传统BP神经网络模型进行优化。GA中染色体之间的信息相互共享,种群是相对均匀地移动到最佳区域;PSO中的粒子是对当前搜索的最佳点进行共享,是遵循当前最优解的一个搜索迭代过程。SSA将种群中的所有因素考虑在内,使麻雀移动到整体最优值,并在最优值附近快速收敛[23]。单晓英等[24]将SSA与PSO的性能进行了比较,结果表明,SSA具有很好的探索全局最优潜在区域的能力,从而有效避免了局部最优问题。胡建华等[25]、Wang等[26]采用SSA-BP模型进行学习与训练,将得到的结果与传统BP神经网络模型、GA-BP神经网络模型的预测结果进行对比,结果表明,SSA-BP神经网络模型具有较高的准确性与稳定性。本研究为了提高传统BP神经网络模型的预测精度,采用SSA、PSO、GA优化传统BP神经网络模型,SSA优化的传统BP神经网络模型在搜索精度、收敛速度方面优于PSO、GA优化的传统BP神经网络模型。
4 结论
本研究根据农业气象灾害的成灾特点建立了旱灾预测模型和洪灾预测模型,通过核主成分分析,保留原始数据的绝大部分信息,从而提高数据质量,减少网络训练时间,提高模型性能。用传统BP神经网络模型进行预测,BP神经网络收敛速度缓慢,且易陷于局部极小值,利用SSA优化传统BP神经网络模型,提高预测精度,同时使用PSO、GA优化传统BP神经网络模型,并对模型精度进行对比。结果表明,SSA优化的传统BP神经网络模型具有较好的效果。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01
作文周刊·小学一年级版(2022年24期)2022-06-18
江苏安全生产(2021年6期)2021-08-05
内蒙古气象(2021年2期)2021-07-01
江苏安全生产(2020年5期)2020-06-15
河北果树(2020年2期)2020-05-25
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
水利规划与设计(2017年5期)2017-06-09
黑龙江水利科技(2016年6期)2016-09-02
