
基于行业词表的自动语音转写后优化技术
2023-11-24 02:59:58马晓亮安玲玲邓从健杜德泉张国新
华南理工大学学报(自然科学版) 2023年8期
马晓亮 安玲玲 邓从健,3,4 杜德泉 张国新
(1.西安电子科技大学 广州研究院,广东 广州 510555;2.中国电信股份有限公司 广州分公司,广东 广州 510620;3.马晓亮劳模和创新工匠工作室,广东 广州 510620;4.广州云趣信息科技有限公司,广东 广州 510665;5.中国电信股份有限公司 广东分公司,广东 广州 510080)
自动语音识别(Automatic Speech Recognition,ASR)是指通过计算机将人类语音信号转录为具体命令和书面形式的文字进行输出的过程[1],是使人与机器之间的交流变得更顺畅的一种技术。早在2004年,王琦[2]就提出,应将ASR技术作为关键技术融入新一代呼叫中心的系统结构中,解决电话用户按键输入范围有限、操作不方便的问题。ASR技术是智能语音客服系统的基础,如互动式语音应答、用户身份校验等功能,都需要准确识别用户的语音并转为文本,才能进入后续的知识库检索、用户需求分流、数据核验等处理流程[3]。
ASR 技术最早可以追溯到20 世纪50 年代,贝尔实验室建立了世界第一个孤立的用于识别英文数字的语音识别系统Audrey[4]。20 世纪90 年代起,ASR技术逐渐被广泛应用,剑桥大学发布的开源工具包HTK 更是加速推动了ASR 技术的应用[5]。但是,ASR 技术的应用也伴随产生了新的问题。自20 世纪90 年代初以来,研究人员使用不同语言的标准语音数据库进行自动语音识别研究,但大部分的数据集是在受控环境下记录的(如广播新闻和会议类型的语音数据),而呼叫中心领域的语音数据由于环境噪声、频繁的交替讲话、语音重叠或不流畅、非语音事件等因素,使得能够适用于呼叫中心领域语音识别的数据集很少。Madhab[6]针对呼叫中心领域创建了一个真实的对话语音数据集,其中包含环境噪声等多类真实要素,用于实现真实通话环境中通话内容的准确识别。
目前,ASR技术已应用在生活的各个方面,为社会生活提供了极大的便利[7-9]。但是,通用ASR引擎均是针对日常场景构建的,行业关键词识别准确率较低,难以满足语音识别在细分行业中应用的精准度要求,为后续业务组件开发增加了难度。一种解决方案是根据行业特点构建一个专用于细分行业的ASR 引擎[10],但这种方案需基于目前通用的ASR 引擎重新进行行业化训练,成本高且适用性窄;另一种解决方案是在现有ASR引擎的基础上对ASR转写后文本进行纠错[11-15]。
对ASR转写后文本进行纠错的相关研究存在两类问题:一是基于日常场景数据集训练的ASR文本纠错模型[16-17]对ASR 识别错误的细分行业专业术语的纠正准确率较低;二是存在行业差异,如铁路信号领域的ASR文本纠错方法是针对简短、专业性较强的铁路车务术语设计[18-19],而客服通话是客户与专业人员之间的交流,通话内容既有专业术语也有日常对话,将其他行业的技术直接迁移至呼叫中心领域应用可能无法取得预期效果。
目前,学术界与工业界均没有针对呼叫中心领域的ASR转写后优化技术的相关研究。为了同时兼顾成本与效率,以一种低成本的方式满足细分行业的实际工程需求,文中提出一种基于行业词表的ASR转写后优化技术,通过在目前流行的基于统计方法建立的ASR引擎之外加入一个优化模块,即构建一个规则化的知识体,分段式地对通用ASR转写结果进行纠错,优化其在细分行业内应用的转写精准度,并以呼叫中心为例对所提出的语音识别优化技术进行实验验证,以期帮助客服人员快速地理解、响应并解决客户提出的问题,满足客户需求,提升客服人员的工作效率。
1 技术路线及模型构建
文中提出的ASR转写后优化技术路线如图1所示。首先,利用通用ASR对客户通话语音进行识别,得到客户通话文本,以此为基础进行语音识别纠错,即根据细分行业纠错词表进行专业性词语的错误识别与替换,最终输出经优化后的语音识别结果。
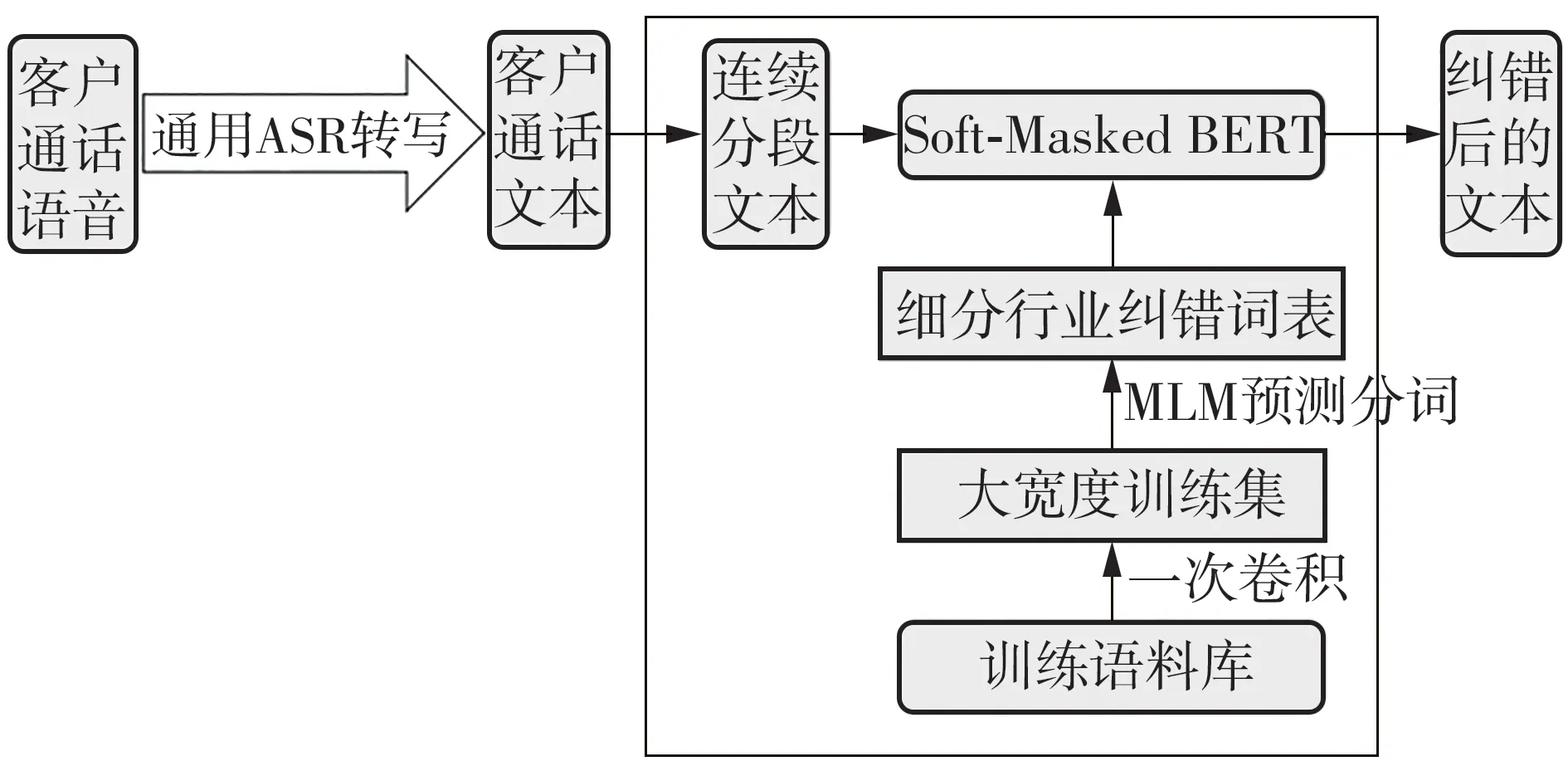
图1 分时段转写纠错技术流程Fig.1 Flow chart of time-segment translation error correction technology
细分行业纠错词表的构建主要由文本摘要提取、掩码语言模型(Masked Language Model,MLM)预测分词两个模块构成,下面做一详细介绍。
1.1 文本摘要和关键词提取
文本摘要提取模块的作用是从通用ASR转写结果中提取细分行业关键词,并对关键词打标签。首先,利用通用ASR将音频转写为文本,该文本为初始文本。然后,利用卷积神经网络(Convolutional Neural Network,CNN)[20]进行一次或多次卷积,从初始文本中提取重要特征,形成转写文本摘要。最后,利用分词工具对转写文本的摘要进行分词,并剔除停用词,同时按词频排序,获得音频关键词,这些关键词可以作为细分行业用词的正确标签。
1.2 细分行业纠错词表生成
采 用BERT(Bidirectional Encoder Representation from Transformers)模型[21]结合MLM 算法[22]实现词表、词语的预测识别,模型框架如图2所示。
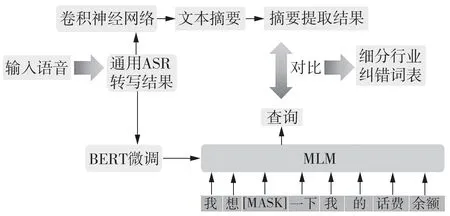
图2 细分行业纠错词表的模型框架Fig.2 Model frame for building a reference word list in a segmented industry
经过预训练的BERT 是一个蕴含丰富语义知识的大规模语言模型,利用呼叫中心细分行业数据对BERT 进行训练后的模型即可用于呼叫中心行业的词语预测。在通用ASR 转写的文本中随机选取词语进行掩蔽(即用[Mask]标记替换原词),利用训练后的BERT 预测[Mask]标记位置的原词,将预测结果与文本摘要的分词结果进行比对,比对结果一致的词标识为正确,比对结果不一致的词进行自动+人工辅助纠错,同时将纠错词对按照【错误词-正确词】的对应关系记录在细分行业纠错词表中。
使用预测分词技术自动生成纠错词表,不仅提升了劳动效率,而且纠错词表准确率达87.2%。具体工程实现和生产实例中,在人工辅助下准确率达100%(结果详见第3节)。
1.3 文本纠错模型
文中采用Soft-Masked BERT 模型来实现文本纠错[23]。如图3 所示,该模型结构包含5 个部分,分别是输入层、检测网络(Detection Network)、软遮蔽(Soft Masking)、纠错网络(Correction Network)和Softmax分类器。
首先,输入层将输入序列S=(s1,s2,…,sn)转换为包含每个字符的字向量、位置向量和片段向量之和的向量E=(e1,e2,…,en)。然后,检测网络通过双向门控循环单元输出每个字符识别正误的概率标签,概率标签范围为[0,1],越接近0 表示识别错误的概率越大,反之则识别错误的概率越小。概率pi的计算公式如下:
其中,σ为sigmoid函数,Wd为全连接的权重矩阵,为双向门控循环单元最后一层的隐藏状态,bd为偏置参数。在软遮蔽层,对输入向量和检测网络的输出概率pi进行加权求和处理,得到软遮蔽向量。第i个字符的软遮蔽向量的计算公式如下:
式中,emask是以误差率为权重的遮蔽向量。进入纠正网络,由BERT 模型处理输入序列,其中BERT包含12 个编码层,每个编码层由多头注意力机制与前馈神经网络构成。将BERT 最后一个编码层的所有隐藏状态和输入向量相加进行残差连接,残差连接的结果输入到全连接层中映射为向量。最后,将生成的向量送入Softmax 分类器,从候选词表中输出概率最大的字符,即为纠正后的正确字符。
1.3.1 模型训练
使用广州12345政务热线真实电话录音转文本数据(普通话版本)作为模型训练集。为了避免短句过多导致模型在训练过程中损失n-gram 信息的问题,对训练集进行了预处理,计算分析训练数据的句子长度,对部分短句子进行拼接处理,经过融合打乱处理后,训练集的长句与短句的比例为8∶2(结果详见第3.3节)。
模型训练过程中,采取每3 轮1 次梯度归零策略,即采取梯度累加策略。每次获得1个批样本数据就计算1次梯度,该次梯度不清空;累加到第3次后,根据累加的梯度更新网络参数,然后清空梯度,进行新一轮循环。这有助于在减少内存消耗的同时获得增大批样本数量的效果,提升训练效果。
1.3.2 引入纠错词表
在Soft-Masked BERT 模型外,增加细分行业纠错词表作为知识体。对Softmax 分类器输出的第一次纠正后字符,使用纠错词表进行错词替换,完成二次纠错,进一步提升纠错效果。
2 实验
根据权威的ASR 行业公开评测项目SpeechIO TIOBE在2022年第3季度公布的结果[24],对音频采样率为16 kHz的互联网识别场景,当前领先的公共语音识别服务的字准确率已达95%以上。由于电话呼叫中心音频采样率为8 kHz,加之细分行业数据的专业性,通用ASR在实际客服领域存在对行业专有用词识别精度低的问题。文中结合广州12345政务热线真实电话录音,将所提出的基于行业词表的自动语音转写后优化技术加以训练并校正。
2.1 实验环境
实验硬件配置为4 核CPU、8 G 内存、GeForce GTX 1660 显卡,操作系统为Centos7.6,编程环境为Python3.7.0,深度学习框架为PyTorch 1.2.0。
2.2 数据集
(1)训练集
使用广州12345 政务热线真实电话录音(普通话版本)作为训练集进行模型训练,共1 638.4 M。对部分长度较短的句子进行拼接处理,确定最佳的训练集长短句比例,以提升模型训练效果。
(2)验证集
使用广州12345政务热线真实电话录音(普通话版本)作为验证集,进行模型参数调优,共409.6 M。
(3)测试集
使用广州12345 政务热线真实电话录音(普通话版本)作为测试集,进行模型调优后的结果对比,共14.8 M。
2.3 基准模型
选择清华THASR与阿里ALIASR这两个在国际上领先的通用ASR模型作为基线模型,利用文中提出的技术对基线模型的语音识别结果进行优化与对比,评估所提出的转写后优化技术的效果。
2.4 评价指标
2.4.1 Soft-Masked BERT模型评价指标
采用准确率、精确率、召回率和综合评价指标F1来评价Soft-Masked BERT 模型的纠错效果,各指标的定义及计算方式为
准确率(Accuracy)A:
查准率(Precision)P:
召回率(Recall)R:
综合评价指标F1:
式中,NTP为将“正确”预测为“正确”(True Positive)的字数,NTN为将“错误”预测为“错误”(True Negative)的字数,NFP为将“错误”预测为“正确”(False Positive,即误报)的字数,NFN为将“正确”预测为“错误”(False Negative,即漏报)的字数。
2.4.2 ASR转写结果评价指标
文中主要采用插入错误率RI、删除错误率RD、替换错误率RS以及字准确率Rw来评价不同ASR 转写结果的准确率,各评价指标定义如下:
式中,N为真实样本字数,D为删除的错误字数,I为插入的错误字数,S为替换的错误字数(为使识别出来的字序列和标准的字序列之间保持一致,需要替换、删除或者插入某些字)。
3 结果与分析
3.1 行业纠错词表准确率测试结果与分析
经过测试验证,使用MLM 预测分词技术生成的行业纠错词表准确率达87.2%,具体结果如表1所示。
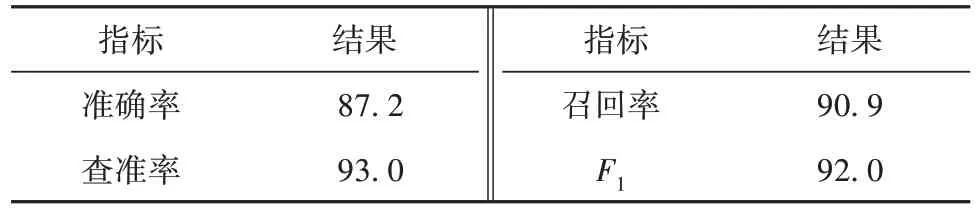
表1 纠错词表准确率实验结果Table1 Experimental results of the accuracy of error correction vocabulary %
3.2 训练集长短句比例实验结果与分析
在纠错模型训练中,为了避免短句过多损失n-gram信息的问题并确定长短句的最佳比例,通过拼接增加长句比例进行了对比实验,结果如表2所示。可以看出,长短句比例为8∶2时训练模型的效果最好,准确率达85.1%。
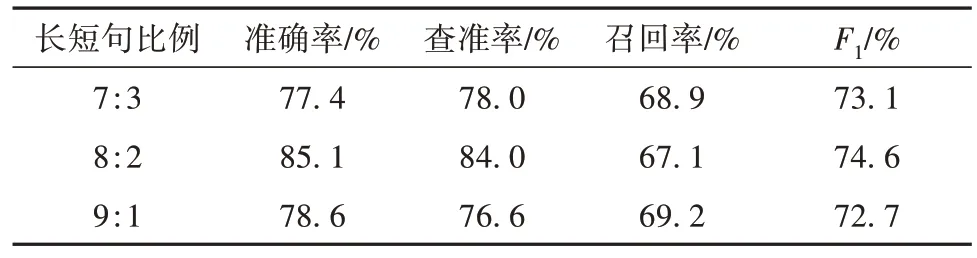
表2 长短句比例对模型训练效果的影响Table 2 Effect of the proportion of long-to-short sentences on model training results
3.3 Soft-Masked BERT 参数调优实验结果与分析
Soft-Masked BERT 模型的参数设置会影响最终的纠错准确率,因此,进一步对模型进行调优实验,结果如表3-5所示。

表3 遮蔽率调优实验结果Table 3 Experimental results of mask rate optimization
3.3.1 遮蔽率调优结果
表3 所示为遮蔽率(Mask Rate)调优实验结果。可以看出,遮蔽率设置为15%时,模型的纠错结果最优。
3.3.2 丢失率调优结果
表4所示为丢失率(Dropout)调优实验结果。可以看出,丢失率设置为10%时,模型的纠错结果最优。

表4 丢失率调优实验结果Table 4 Experimental results of dropout optimization
3.3.3 学习率调优结果
表5 所示为学习率(Learning Rate)调优实验结果。可以看出,学习率设置为1×10-4时,模型的纠错结果最优。

表5 学习率调优实验结果Table 5 Experimental results of learning rate optimization
3.4 文本纠错技术对比实验结果与分析
直接使用通用Soft-Masked BERT 模型与加入纠错词表的模型进行对比,结果表明,引入纠错词表后,模型的准确率由85.1%上升到了92.9%,提高幅度达7.8个百分点。
3.5 模型总体提升结果
利用文中提出的转写后优化技术对清华THASR、阿里ALIASR 两个通用ASR 模型进行优化,分别得到表6所示的清华纠错THASR-E、阿里ALIASR-E的语音识别结果。
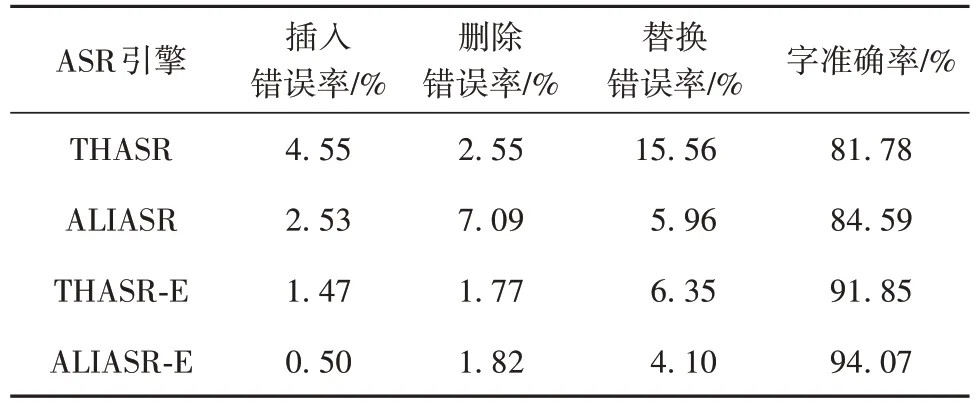
表6 不同ASR在普通话数据集的实验结果Table 6 Experimental results of different ASR on mandarin datasets
从表6 可以看出,通用模型THASR 与ALIASR的字准确率在80%~ 85%之间,采用文中技术优化后,THASR-E 与ALIASR-E 的字准确率较通用模型均提高约10 个百分点,表明文中提出的转写后优化技术对于提升语音识别结果的准确率有显著效果,而且不依赖于ASR引擎,有良好的适应性。
3.6 案例分析
选择广州12345实际客服通话录音转写文本进行ASR转写后优化案例分析。案例中共有313条语句,总字数为5 770,其中通用ASR 转写结果中有506 个错误的字,应用文中提出的转写后优化技术从中检测到489 个错误字,并对其中470 个错误字进行纠正,在原始ASR 转写结果基础上实现了92.9%的提升。
选取部分纠错示例进行详细分析,结果如表7所示。可以看出,文中提出的转写后优化技术可以对通用ASR引擎转写错误的政务热线行业用词进行有效纠错。

表7 实际12345客服通话转写纠错示例结果Table 7 Results of the examples of correcting the translation of real 12345 customer service calls
4 结语
目前,一些通用ASR产品在细分行业内的应用已经十分广泛,但针对通用场景所构建的ASR引擎在窄带低采样的语音环境下无法准确识别细分行业内的专业术语,导致语音识别准确率难以满足行业需求。重新构建一个细分行业专用ASR引擎需要花费较高成本,而且已有的语音识别后文本纠错技术也存在不适用于呼叫中心细分行业的问题。有鉴于此,文中提出了一种兼顾工程实现成本与效率的ASR转写后优化技术,以模板匹配方式高效地实现了对通用ASR识别结果的纠错。
该技术通过文本摘要技术和MLM 预测分词技术,构建了一个词量约为3 000 的细分行业纠错词表,用于解决现存专业词汇识别不准确的问题,通过对通用ASR转写结果进行快速纠错,在不产生较大延迟的前提下,提升呼叫中心客服场景中通话语音转写为文本的准确率。选取清华THASR、阿里ALIASR 两个通用ASR 作为基线模型在广州12345政务热线真实电话录音数据集上进行测试,结果表明,文中提出的优化后转写技术可将字准确率提高约10 个百分点,且纠错速度较快,不会产生明显延迟,具有良好的适用性,可帮助客服人员快速地理解、响应并解决客户提出的问题与需求,提升客服人员的工作效率。
本研究的贡献可以概括如下:
1)以人工与自动化结合的方式优化通用ASR转写结果,相比纯人工或纯自动化的方法,文中方法有效实现了运行效率与准确性的兼顾;
2)通过对通用ASR输出结果进行优化,在实际应用可接受的延迟时间内,以较高的工程效率提高了语音识别准确率;
3)采用自监督学习的掩码语言模型高效构建了呼叫中心细分行业纠错词表,有效节省了人工标注数据所需花费的时间成本与劳动资源。
后续研究中,拟将ASR转写后优化技术应用到方言环境的转写纠错研究中,提升方言环境下细分行业的语音转写成功率。
猜你喜欢
英语世界(2021年13期)2021-01-12 05:47:51
华人时刊(2020年23期)2020-04-13 06:04:12
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
专用汽车(2016年9期)2016-03-01 04:17:02
专用汽车(2015年2期)2015-03-01 04:05:42
中国记者(2014年1期)2014-03-01 01:36:30
