
基于隐私推断Non-IID联邦学习模型的后门攻击研究
2023-11-22 06:03梅皓琛李高磊杨潇
现代信息科技 2023年19期
梅皓琛 李高磊 杨潇

摘 要:联邦学习安全与隐私在现实场景中受数据异构性的影响很大,为了研究隐私推断攻击、后门攻击与数据异构性的相互作用机理,提出一种基于隐私推断的高隐蔽后门攻击方案。首先基于生成对抗网络进行客户端的多样化数据重建,生成用于改善攻击者本地数据分布的补充数据集;在此基础上,实现一种源类别定向的后门攻击策略,不仅允许使用隐蔽触发器控制后门是否生效,还允许攻击者任意指定后门针对的源类别数据。基于MNIST、CIFAR 10和YouTube Aligned Face三个公开数据集的仿真实验表明,所提方案在数据非独立同分布的联邦学习场景下有着较高的攻击成功率和隐蔽性。
关键词:联邦学习;非独立同分布数据;后门攻击;隐私推断攻击
中图分类号:TP309;TP181;TP393 文献标识码:A 文章编号:2096-4706(2023)19-0167-05
Research on Backdoor Attack Based on Privacy Inference Non-IID Federated Learning Model
MEI Haochen, LI Gaolei, YANG Xiao
(School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai 200240, China)
Abstract: Federated learning security and privacy are greatly affected by data heterogeneity in real scenarios. In order to study the interaction mechanism between privacy inference attacks, backdoor attacks, and data heterogeneity, a high covert backdoor attack scheme based on privacy inference is proposed. Firstly, based on generating adversarial networks, diverse data reconstruction is performed on the client side, generating supplementary datasets to improve the local data distribution of attackers; On this basis, a source category oriented backdoor attack strategy is implemented, which not only allows the use of hidden triggers to control whether the backdoor is effective, but also allows attackers to arbitrarily specify the source category data targeted by the backdoor. Simulation experiments based on three public datasets, MNIST, CIFAR 10, and YouTube Aligned Face, show that the proposed scheme has a high attack success rate and concealment in federated learning scenarios with non independent identically distributed data.
Keywords: federated learning; non independent identically distributed data; backdoor attack; privacy inference attack
0 引 言
聯邦学习为合作学习提供了一种新范式,它允许多个参与方在不共享本地私有数据的情况下共同训练全局模型[1]。然而,在提供隐私保护的同时,联邦学习也暴露出了比集中式学习更大的攻击面。最典型的威胁之一来自恶意客户端,其可以通过上传精心设计的本地更新对全局模型发起投毒攻击。其中,后门攻击作为一种目标性投毒攻击,以其隐蔽性和威胁性著称,其目的是诱导模型在特定情况下产生错误行为,而在原始任务上性能不受影响[2]。
后门攻击自提出以来已在传统集中式机器学习中得到广泛研究,并且出现了许多强力变体。尽管已有一系列的研究[3-6]证明了向联邦学习中植入后门的可能性,但在这样一个复杂的分布式系统中,保持后门的长期有效性依然具有很大的挑战性。首先,来自良性客户端的更新会削弱有毒更新的影响(特别是当恶意客户端的占比很小时),这使全局模型快速“遗忘”后门。其次,数据异构性会导致本地模型在分布不均衡的数据上过拟合,且本地恶意数据分布与全局数据分布之间的差异对后门有效性也有着重大影响。
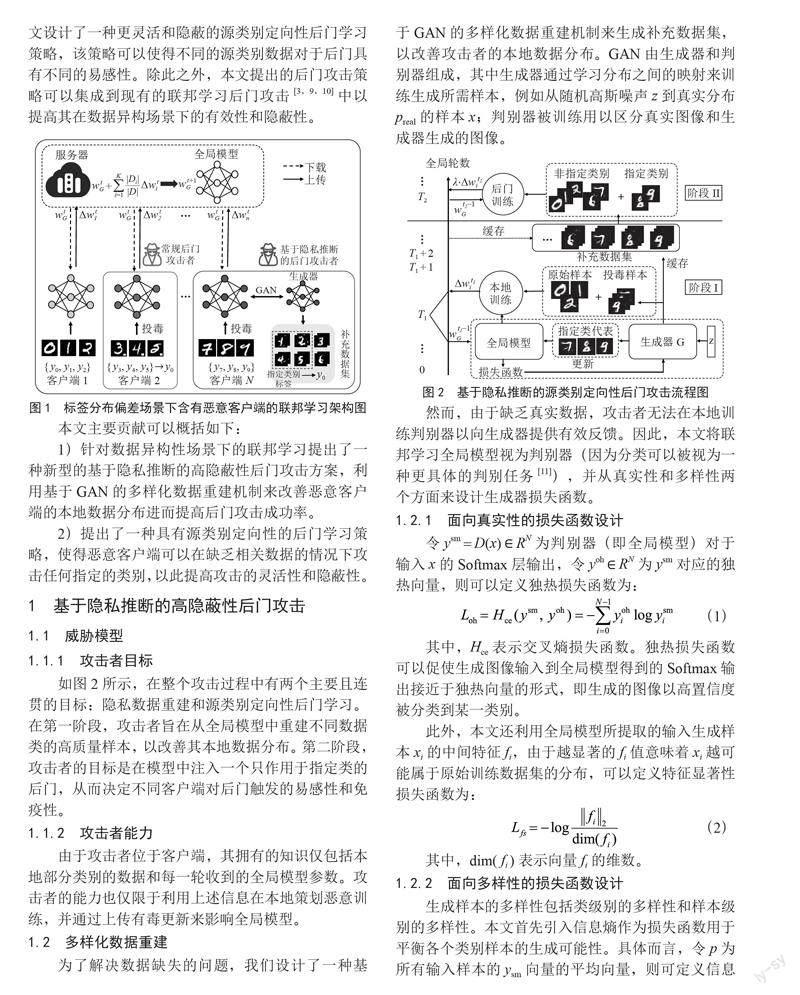
为缓解在联邦学习中数据异构性带来的限制,本文提出了一种基于隐私推断的高隐蔽性后门攻击方案。该方案首先利用生成对抗网络(Generative Adversarial Networks, GAN)构建由兼具真实性与多样性的重建样本组成的补充数据集,以减少本地和全局数据分布之间的差距。具体而言,本文以标签分布偏差[7,8]这一Non-IID场景作为主要研究对象。如图1所示,每个客户端只能访问所有数据类的一个子集。基于此,本文设计了一种更灵活和隐蔽的源类别定向性后门学习策略,该策略可以使得不同的源类别数据对于后门具有不同的易感性。除此之外,本文提出的后门攻击策略可以集成到现有的联邦学习后门攻击[3,9,10]中以提高其在数据异构场景下的有效性和隐蔽性。
本文主要贡献可以概括如下:
1)针对数据异构性场景下的联邦学习提出了一种新型的基于隐私推断的高隐蔽性后门攻击方案,利用基于GAN的多样化数据重建机制来改善恶意客户端的本地数据分布进而提高后门攻击成功率。
2)提出了一种具有源类别定向性的后门学习策略,使得恶意客户端可以在缺乏相关数据的情况下攻击任何指定的类别,以此提高攻击的灵活性和隐蔽性。
1 基于隐私推断的高隐蔽性后门攻击
1.1 威胁模型
1.1.1 攻击者目标
如图2所示,在整个攻击过程中有两个主要且连贯的目标:隐私数据重建和源类别定向性后门学习。在第一阶段,攻击者旨在从全局模型中重建不同数据类的高质量样本,以改善其本地数据分布。第二阶段,攻击者的目标是在模型中注入一个只作用于指定类的后门,从而决定不同客户端对后门触发的易感性和免疫性。
1.1.2 攻击者能力
由于攻击者位于客户端,其拥有的知识仅包括本地部分类别的数据和每一轮收到的全局模型参数。攻击者的能力也仅限于利用上述信息在本地策划恶意训练,并通过上传有毒更新来影响全局模型。
1.2 多样化数据重建
为了解决数据缺失的问题,我们设计了一种基于GAN的多样化数据重建机制来生成补充数据集,以改善攻击者的本地数据分布。GAN由生成器和判别器组成,其中生成器通过学习分布之间的映射来训练生成所需样本,例如从随机高斯噪声z到真实分布preal的样本x;判别器被训练用以区分真实图像和生成器生成的图像。
然而,由于缺乏真实数据,攻击者无法在本地训练判别器以向生成器提供有效反馈。因此,本文将联邦学习全局模型视为判别器(因为分类可以被视为一种更具体的判别任务[11]),并从真实性和多样性两个方面来设计生成器损失函数。
1.2.1 面向真实性的损失函数设计
令ysm = D(x) ∈ RN为判别器(即全局模型)对于输入x的Softmax层输出,令yoh ∈ RN为ysm对应的独热向量,则可以定义独热损失函数为:
其中,Hce表示交叉熵损失函数。独热损失函数可以促使生成图像输入到全局模型得到的Softmax输出接近于独热向量的形式,即生成的图像以高置信度被分类到某一类别。
此外,本文还利用全局模型所提取的输入生成样本xi的中间特征fi,由于越显著的fi值意味着xi越可能属于原始训练数据集的分布,可以定义特征显著性损失函数为:
其中,dim( fi )表示向量fi的维数。
1.2.2 面向多样性的损失函数设计
生成样本的多样性包括类级别的多样性和样本级别的多样性。本文首先引入信息熵作为损失函数用于平衡各个类别样本的生成可能性。具体而言,令p为所有输入样本的ysm向量的平均向量,则可定义信息熵损失函数为:
其中,Hie表示信息熵函数。通过最大化p的信息熵,可以促使生成器以尽量均衡的概率生成所有类别的样本。
此外,考虑到GAN在生成样本时常见的“模式塌陷”问题,本文进一步设计了一个模式搜索损失函数以提升每个类别内的样本多样性:
其中,z1和z2表示两个不同的隐层向量。
最后将上述损失函数进行加权组合可得生成器总损失函数:
其中,α表示平衡两类损失的超参数,可针对不同的数据集进行调整。
1.3 源类别定向性后门学习
借助第一阶段基于GAN的数据重建得到的补充数据集,攻击者能够有效缓解本地的数据缺失并缩小本地和全局数据分布之间的差距。具体而言,攻击者首先从所有N类数据中指定若干受害者类别。令Ds={(xs,ys)}和Dns = {(xns,yns)}分别表示指定类和非指定类的数据集。攻击者后续的后门训练按照以下3个指标进行:
1)攻击成功率(Attack SuccessRate, ASR):表示来自Ds的样本在添加触发器后被包含后门的全局模型成功分类为目标标签yt的比例。
2)主任务准确率(MainTaskAccuracy, MTA):表示包含后门的全局模型对干净样本的分类准确率。
3)后门分数(BackdoorScore, BS):表示后门的差异性程度,即后门触发器只应该对指定类别生效而对非指定类别的分类性能不产生影响。其计算公式定义为:
其中,I表示指示函数,I(A) = 1当且仅当事件A为真。
源类别定向性后门学习损失函数为:
其中,β1和β2表示平衡权重的超参数, 表示对于添加触发器的指定类别的样本
,模型f对其预测值与后门目标标签yt的交叉熵; 表示对于添加触发器的非指定类别的样本 ,模型f对其的预测值与原始标签yns的交叉熵; 表示对于干净样本(x,y)的原始交叉熵。
2 实验与分析
2.1 实验设置
本文在MNIST、CIFAR 10和YouTube Aligned Face(YAF)三个公开数据集上进行图像分类任务,全局模型采用AlexNet[12]网络结构,并在100个客户端上进行500轮训练。在训练开始之前,对数据集进行数据增强(例如旋转、裁剪和翻转),以确保每个客户端至少包含1 000个样本。在每一轮全局训练中,10个客户端将被选中并接受2轮本地训练。模型使用批处理大小为64的随机梯度下降算法进行优化,初始学习率为0.01,学习率每20轮的衰减系数为0.95。
2.2 基于GAN的數据重建有效性验证
2.2.1 数据重建效果可视化
在图3中,我们将数据重建的结果可视化,并将其与现有方法进行比较。本文提出的数据重建方法在生成具有真实性和多样性的样本方面表现更好,其多样性不仅体现在能够生成不同类别的数据上,还体现在每个类别内部样本的差异性上。
2.2.2 后门增强效果验证
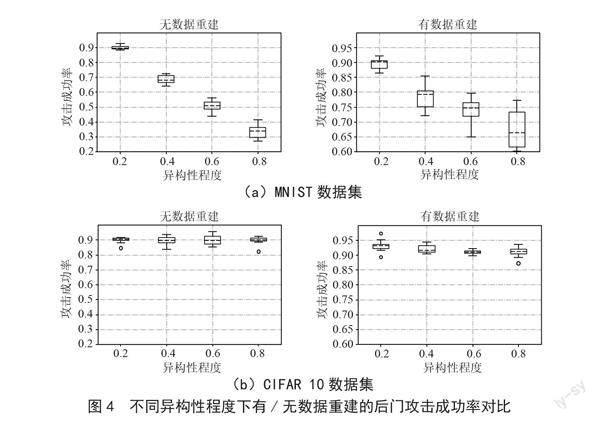
为了更直观地验证数据异构性如何限制后门攻击的有效性,以及本文的数据重建方法对该限制的缓解作用,分别选择了典型的模型替换后门攻击[3]和PGD后门攻击[5]在数据集CIFAR 10和MNIST上以不同数据异构性程度进行实验。恶意客户端的数据投毒率设置为50%。实验结果如图4所示。
2.3 源类别定向性后门学习攻击效果
源类别定向性不仅要求对指定类进行概率的错误分类,还需要确保不影响非指定类的准确性。为体现此种差异性,在图5中使用混淆矩阵来展示攻击的有效性。对于MNIST、CIFAR 10和YAF数据集分别指定了5、3、1个受害者类,并将数据集中的第一个类别设置为后门目标。此处对目标类别的选择没有限制,因为在攻击过程中不涉及来自目标类的数据。如图5所示,本文的攻击方法能够大大降低模型在指定类上的性能,而对非指定类的影响要小得多(甚至对某些类无影响)。
2.4 攻击隐蔽性验证
本文在下文两种流行的后门检测防御方法上验证了所提出攻击方案的隐蔽性。
2.4.1 面对Neural Cleanse方法的隐蔽性
面对Neural Cleanse方法[13]基于梯度下降算法为每个类生成可能的触发器,再使用中值绝对偏差作为异常检测算法进行检测,进而识别后门目标类。本文在MNIST和CIFAR 10数据集中使用第一个类别作为后门目标,并分别指定了3个源类别。触发器恢复效果如图6所示,对于本文的源类别定向性攻击,该防御方法未能恢复触发器或区分目标类别。此外,表1报告了Neural Cleanse在不同指定类别数下的检测结果,当指定的类别越少,攻擊就越难被检测到。
2.4.2 面对Activation Clustering方法的隐蔽性
面对Activation Clustering方法[14]使用K-means聚类算法对从模型最后一个隐藏层提取的激活值进行聚类,并通过分析聚类结果的轮廓分数,识别出被投毒的类别。如表1所示,该方法在大多数情况下未检测到本文提出的后门攻击,但相比Neural Cleanse方法更为有效和稳定,其原因在于无论指定源类的数量有多少,Activation Clustering都可以基于聚类来识别异常样本群体。但该方法有一个严重的缺点,即防御者需要访问大量训练数据,包括中毒数据,这违背联邦学习中隐私保护的原则。
3 结 论
本文提出了一种面向Non-IID联邦学习的高隐蔽性后门攻击方案,该方案使位于客户端的攻击者能够在标签分布偏差的场景下发起更有效而隐蔽的后门攻击。基于MNIST、CIFAR 10和AlignedFace数据集开展的大量实验验证了所提出方法的有效性。通过多样化的数据重构机制,可将联邦学习中的常规后门ASR提高20%~60%;而源类别定向性后门学习策略通过改变攻击范围可以成功规避目前先进的后门检测方法。总体而言,本文提出的攻击方案具有更高的可行性和灵活性,并可与现有其他后门攻击兼容,以提高其有效性和隐蔽性,为未来Non-IID联邦学习安全研究提供了有力支持。
参考文献:
[1] MCMAHAN H B,MOORE E,RAMAGE D,et al. Communication-Efficient Learning of Deep Networks from Decentralized Data [J/OL].arXiv:1602.05629 [cs.LG].[2023-02-20].https://arxiv.org/abs/1602.05629v3.
[2] 杜巍,刘功申.深度学习中的后门攻击综述 [J].信息安全学报,2022,7(3):1-16.
[3] BAGDASARYAN E,VEIT A,HUA Y,et al. How to backdoor federated learning [J/OL].arXiv:1807.00459 [cs.CR].[2023-02-20].https://arxiv.org/abs/1807.00459.
[4] 王坤庆,刘婧,李晨,等.联邦学习安全威胁综述 [J].信息安全研究,2022,8(3):223-234.
[5] WANG H Y,SREENIVASAN K,RAJPUT S,et al. Attack of the tails: Yes, you really can backdoor federated learning [J/OL].arXiv:2007.05084 [cs.LG].[2023-02-20].https://arxiv.org/abs/2007.05084.
[6] 陈大卫,付安民,周纯毅,等.基于生成式对抗网络的联邦学习后门攻击方案 [J].计算机研究与发展,2021,58(11):2364-2373.
[7] ZHAOY,LI M,LAI L Z,et al. Federated Learning with Non-IID Data [J/OL].arXiv:1806.00582 [cs.LG].[2023-02-23].https://arxiv.org/abs/1806.00582.
[8] YU F X,RAWAT A S,MENON A K,et al. Federated Learning with Only Positive Labels [J/OL].arXiv:2004.10342 [cs.LG].[2023-02-23].https://arxiv.org/abs/2004.10342.
[9] XIE C L,HUANG K L,CHEN P Y, et al. Dba: Distributed backdoor attacks against federated learning [EB/OL].2020:1-15[2023-02-26].https://openreview.net/attachment?id=rkgyS0VFvr&name=original_pdf.
[10] 林智健.针对联邦学习的組合语义后门攻击 [J].智能计算机与应用,2022,12(7):74-79.
[11] ODENA A. Semi-Supervised Learning with Generative Adversarial Networks [J/OL].arXiv:1606.01583 [stat.ML].[2023-02-26].https://arxiv.org/abs/1606.01583.
[12] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. ImageNet classification with deep convolutional neural networks [J].Communications of the ACM,2017,60(6):84-90.
[13] WANG B,YAO Y S,SHAN S,et al. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks [C]//2019 IEEE Symposium on Security and Privacy (SP).San Francisco:IEEE,2019:707-723.
[14] CHEN B,CARVALHO W,BARACALDO N,et al. Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering [J/OL].arXiv:1811.03728 [cs.LG].[2023-02-26].https://arxiv.org/abs/1811.03728.
作者简介:梅皓琛(1999.02—),男,汉族,江西南昌人,硕士在读,研究方向:联邦学习、人工智能安全;李高磊(1992.12—),男,汉族,河南开封人,助理教授,研究方向:人工智能与系统安全;杨潇(1994.01—),男,汉族,重庆人,博士在读,研究方向:图神经网络、人工智能安全。
收稿日期:2022-11-08
基金项目:国防基础科研项目(JCKY2020604B004);上海市科委“科技创新行动计划”(22511101200,22511101202)
