
一种基于LSTM的中医药数据增强方法
2023-11-22 06:03柳鹏熊旺平晏燕
现代信息科技 2023年19期
柳鹏 熊旺平 晏燕

摘 要:中医药数据在许多领域中具有广泛的应用,但由于数据缺乏,导致中医药领域的发展受到限制。因此,文章提出了一种基于LSTM的中医药数据增强方法,以生成更多的中医药数据,以提高中医药领域的应用价值。研究从已有的中医药数据中构建了一个基于LSTM的生成模型,并通过实验验证了该方法的有效性。实验结果表明,基于LSTM的中医药数据增强方法可以生成与真实数据相似的数据,从而可以为中医药领域的研究和应用提供更多的数据资源。
关键词:中医药数据增强;LSTM;生成模型;数据资源
中图分类号:TP18;TP391.1 文献标识码:A 文章编号:2096-4706(2023)19-0117-06
A Chinese Medicine Data Enhancement Method Based on LSTM
LIU Peng1, XIONG Wangping1, YAN Yan2
(1.College of Computer, Jiangxi University of Chinese Medicine, Nanchang 330004, China;
2.Fengcheng People's Hospital of Jiangxi Province, Yichun 331100, China)
Abstract: TCM data has a wide range of applications in many fields, but the lack of data has led to the development limitation of the TCM field. Therefore, this paper proposes a TCM data enhancement method based on LSTM to generate more TCM data in order to improve the application value in the field of TCM. In this research, a generation model based on LSTM is constructed from existing TCM data, and the effectiveness of the method is verified through experiments. The experimental results show that the TCM data enhancement method based on LSTM can generate data similar to the real data, and thus can provide more data resources for research and application in the field of TCM.
Keywords: Traditional Chinese Medicine data enhancement; LSTM; generative model; data resource
0 引 言
随着科技的不断发展,深度学习已经成为一种热门的研究方向。在医学领域,深度学习已经被广泛应用于医疗影像分析、疾病诊断和治疗等方面。然而,在中医药领域,由于数据的质量和数量限制,深度学习的应用仍然面临许多挑战。
在中医药领域,数据增强[1]是一种解决数据不足问题的有效方法。数据增强可以通过对原始数据进行多种方式的扩充来生成新的数据集,从而提高模型的泛化能力和鲁棒性[2]。本文探讨了一种基于LSTM的中医药数据增强方法。
长短期记忆网络(LSTM)是一种常用的循环神经网络[3],它能够有效地处理序列数据。本文的方法是利用LSTM模型来生成新的中医药数据,具体来说,是将已有的中医药数据作为输入序列,通过训练LSTM模型来生成新的中医药数据。通过这种方法,可以有效地扩充原始数据集,从而提高模型的表现。
本文的主要贡献如下:首先,本文提出了一种基于LSTM的中医药数据增强方法,可以有效地扩充中医药数据集;其次,对比了使用增强数据和不使用增强数据的模型性能,证明了数据增强的有效性;最后,还对LSTM模型进行了深入的分析,探讨了其在中医药数据增强中的应用。
本文的组织结构如下:第二部分介绍了相关工作,包括数据增强和LSTM模型;第三部分详细描述了本文提出的基于LSTM的中医药数据增强方法;第四部分通过实验验证了本文的方法的有效性;最后,本文在第五部分进行了总结和展望。
1 相关工作
本文提出了一种基于LSTM的中医药数据增强方法。在相关工作部分,本文将介绍一些与本文相关的研究工作,包括数据增强和LSTM模型的应用。
数据增强是一种常用的解决数据不足问题的方法。在图像领域,数据增强的方法包括随机旋转、随机缩放、随机裁剪等[4]。在自然语言处理领域,数据增强的方法包括词向量替换、句子重构等[5]。在医学领域,数据增强的方法包括对医疗影像进行旋转、镜像等操作[6]。这些方法都可以有效地扩充数据集,提高模型的泛化能力和鲁棒性。
LSTM是一种常用的循环神经网络,它能够有效地处理序列数据。在自然语言处理领域,LSTM模型已经被广泛应用于语言模型、机器翻译和情感分析等方面[7]。在医学领域,LSTM模型也被用于疾病预测和药物发现等任务中[8]。
在中医药领域,也有一些相关的研究工作。例如,刘金垒等人[9]通过挖掘中医药领域的知识图谱,构建了一個中医药知识图谱库,以帮助医生和研究人员更好地理解中医药知识。此外,芦霞[10]将深度学习应用于中药配方的研究,通过建立中药配方的预测模型,来预测其功效和治疗效果。
然而,在中医药数据增强方面,尚未有太多的研究。因此,本文提出的基于LSTM的中医药数据增强方法具有一定的创新性和实用性。通过扩充中医药数据集,本文可以更好地应用深度学习模型来解决中医药领域中的问题,为中医药研究和临床实践提供更好的支持。
2 LSTM模型的构造
2.1 数据集和数据预处理
在采集数据的过程中可能会出现错误,这会使得部分数据缺失。缺失数据会影响模型的预测,因此必须对缺失数据进行处理。本文采用上一个时间表和下一个时间表相同时间段的数据的均值来填补缺失值。
由于原始输入数据的不同特征所用的评价指标的量纲不同,会影响数据分析的最终结果。为了消除这种指标间的量纲影响,将原始数据进行标准化[11]。经过标准化处理后,各指标将处于同一数量级。同时,标准化有助于提高神经网络的训练速度以及提高模型的精度。本文采用最大最小标准化方法(Min-Max Normalization)又称离差标准化[12],将数据映射到[0,1]之间,转换函数如式(1)所示:
其中xmin表示该血药浓度特征数据中的最小值;xmax表示该特征数据的最大值;xn表示将要归一化的值; 表示经过归一化之后的值。
2.2 长短期记忆网络
本文中提出的基于LSTM的中医药数据增强方法,主要包括以下几个步骤:数据预处理、LSTM模型构造、数据增强和模型训练。
在LSTM模型构造中,本文采用了经典的LSTM结构,用于处理中医药序列数据。LSTM模型由多个LSTM层和一个全连接层组成,其中每个LSTM层包括多个LSTM单元。每个LSTM单元包含一个输入门、一个遗忘门和一个输出门,用于控制输入数据的流动和记忆数据的存储。LSTM的内部结构模型如图1所示。
式(2)中:Gt表示通过遗忘门后的信息,σ()表示sigmoid激活函数,ωf表示遗忘门中输入的特征向量的权重矩阵,[ht-1,xt]表示由两个向量拼接成的新向量,xt表示当前的输入向量,ht-1表示上一次的输出向量,bf表示遗忘门的偏置值。式(3)中:ωi表示输入门中输入的特征向量的权重矩阵,bi表示输入门的偏置值。式(4)中 表示需要更新的信息,Ct表示输入门更新后的信息。式(5)表示t时刻的输出,并作为历史信息被保留。式(6)表示最终输出的表达式,输出整个LSTM模型的最终结果。
在模型的输出层,本文采用了Softmax函数,将模型输出的结果转化为概率分布。模型的损失函数采用交叉熵损失函数[13],用于衡量模型的预测结果与真实结果之间的差异。模型的训练使用反向传播算法进行优化,更新模型的参数以最小化损失函数。
值得注意的是,为了防止模型过拟合,本文在模型中加入了dropout[14]和正则化[15]等技术。dropout技术可以随机丢弃一部分神经元,防止模型对某些特征的过度依赖。而正则化技术则可以限制模型的参数大小,防止模型过度复杂。
3 实验结果与分析
3.1 实验数据介绍
本文使用的数据是大承气汤血药浓度实验数据和UCI数据集中的Tetuan City power consumption和AirQualityUCI。大承气汤血药浓度数据来源于江西中医药大学中医病因生物学重点实验室。
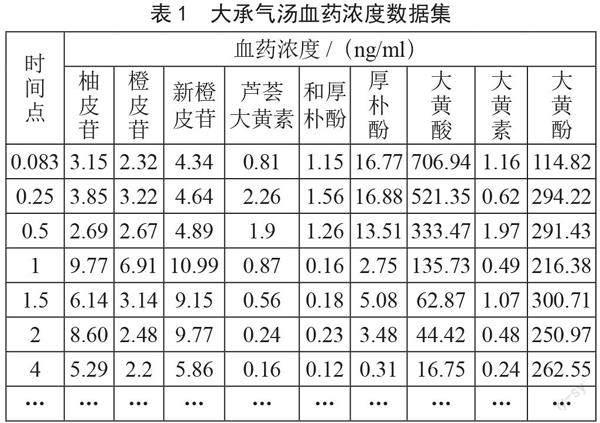
大承气汤血药浓度实验数据包含6组大的时间序列样本,每组样本包含12个时间点,总共72条样本。每个时间点有9个成分的血药浓度,分别是柚皮苷、橙皮苷、新橙皮苷、芦荟大黄素、和厚朴酚、厚朴酚、大黄酸、大黄素和大黄酚,大承气汤血药浓度的部分实验数据集如表1所示。
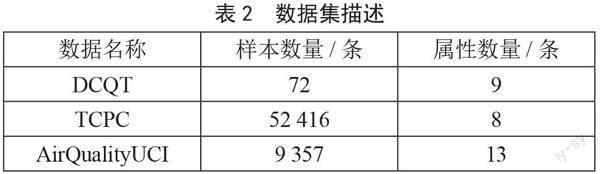
UCI数据选取Tetuan City power consumption (TCPC)和AirQualityUCI,样本量分别为9 357和52 416条,UCI数据集的详细描述见http://archive.ics.uci.edu/ml/。数据集的具体描述如表2所示。
3.2 评价方法介绍
在本文中使用的评价指标为:均方根误差(RMSE),平均绝对误差(MAE),均方对数误差(MSLE)。各指标的计算方法如式(7)~(9):
在上述的三个式子中:n表示所有训练样本的数量,yl表示待预测数据的真实结果, 表示模型输出的预测结果,RMSE,MAE和MSLE表示模型的预测结果与真实结果之间的误差,误差越小,模型的精度也越高。
3.3 实验环境
本文所提出的LSTM数据增强模型是在Windows 10操作系统上进行的实验,设备的内存为32 GB,处理器为Intel Core i7-9700K CPU @ 3.60 GHz 3.60 GHz,GPU为Nvidia GeForce GTX 1660 Ti 6GB GDDR6。本文使用的编程语言版本为Python 3.7.10,运行框架及版本为TensorFlow 2.5.0和Keras 2.4.3。
3.4 模型有效性
为了验证LSTM模型的有效性,本文将LSTM分别跟PLS,XGBoost和RNN进行比较,结果通过评价指标RMSE,MAE和MSLE来评估,RMSE,MAE和MSLE的值越小,模型的精度越高。实验结果如表3所示。
根据表3的实验结果可知,在预测三个数据集的四个模型中,LSTM的拟合效果最好,在三个数据集中的平均RMSE(12.49)、MAE(8.12)、MSLE(0.51)最小,而XGBoost模型的平均RMSE(15.87)、MAE(10.79)、MSLE(0.73)在三个数据集中的拟合结果最差。
大承气汤实验数据属于小样本数据,在实验中,LSTM的RMSE小于XGBoost、RNN和PLS。四个模型的RMSE分别为13.08、12.52、11.34和11.28。LSTM的MAE小于XGBoost、RNN和PLS。四个模型的MAE分别为8.89、7.23、7.46和6.73。LSTM的MSLE小于XGBoost、RNN和PLS。四個模型的MSLE分别为0.43、0.26、0.15和0.11。从结果来看,LSTM模型比PLS和XGBoost模型的预测效果好,说明LSTM也可以很好地处理小样本数据。
在UCI数据中,AirQualityUCI数据集属于中等数据量样本,Tetuan City power consumption数据集属于大数据量样本。在各类数据量中,LSTM的效果都是最好的,在AirQualityUCI数据集中,RMSE分别为13.66、12.56、12.40和11.34,MAE分别为8.45、
8.88、8.51和7.98,MSLE分别为0.86、0.79、0.78和0.64。在Tetuan City power consumption数据集中,RMSE分别为20.88、21.66、17.09和14.84,MAE分别为15.02、16.48、11.26和10.64,MSLE分别为0.92、0.82、0.8和0.78。结果表明,LSTM无论在大承气汤数据集中还是UCI数据集中,预测的准确率都是最高的,在预测效果方面优于其他模型。
为了更直观地显示实验结果,分别绘制图表以体现均方根误差(RMSE),平均绝对误差(MAE),均方对数误差(MSLE)的波动情况。由于各个数据集的RMSE、MAE和MSLE的数量级不同,为了方便比较各数据集在不同方法上的RMSE、MAE和MSLE的波动情况,将实验结果数据按照RMSE、MAE和MSLE分别绘制出图2、图3和图4。
在本文中,从表2中可以知道,TCPC属于大型数据集,AirQualityUCI属于中型数据集,而DCQT属于小型数据集。从实验结果来看,本文提到的方法在这三类数据上都有较好的表现,而从图2、图3和图4可以直观地看出LSTM在各项指标中效果相比XGBoost、RNN以及PLS都有明显的提升。
3.5 数据增强
本文的数据是时间序列的,训练模型的方式是通过输入一行起始时间的血药浓度数据来预测下一个时间点的血药浓度数据,直到完成12个时间点的预测。因此,本文實现数据增强的方法是将多个起始时间的数据批量输入模型,起始时间的数据来自原始数据。为了避免数据过拟合,输入的数据将添加一个噪音,噪音的范围限制在原值的15%的大小,原始数据添加噪声后变为一个新的值。新的数据经过模型处理后,可以获得增强数据。
例如从大乘气汤的数据集中随机挑选5组数据,在图表中展示如图5所示。
选取每组数据的第一行属性值并添加随机噪音,然后经过LSTM模型处理后,可以得到新的增强数据。例如使用图5中的5组数据进行数据增强,如果模型对数据进行6次预测(每次预测的数据添加的噪音是随机的),可以得到6倍于原始数据的数据量,实验结果如图6所示。
通过图5和图6的对比,可以看出模型生成的新样本与原始样本都处在一个相似的规律和范围内。说明模型能实现对原始数据的数据增强。
实验结果表明,LSTM模型可以有效地对中医药数据进行增强,并可以在不增加数据采集和标注成本的情况下提高预测模型的精度。通过使用LSTM模型生成合成数据,可以扩展原始数据集的规模,并使预测模型更好地捕捉数据的特征。此外,与其他模型相比,LSTM在预测性能方面表现出更好的结果,特别是在处理序列数据的长期依赖关系方面。
4 结 论
本研究使用LSTM模型进行中医药数据增强,并通过与其他模型的对比,证明了该方法能够有效提高预测模型的性能。结果表明,LSTM模型生成的合成数据可以增加数据集的规模,并提高模型的精度,同时避免了增加数据采集和标注成本的问题。本文还将LSTM模型与其他模型进行了比较,包括XGBoost、RNN和PLS,并在RMSE、MAE和MSLE等指标上进行了评估。实验结果表明,LSTM模型在预测中医药数据方面表现优异。这表明,对于序列数据这种类型的预测任务,LSTM模型可以更好地处理长期依赖关系,从而提高预测精度。
本文提出了一种有效的中医药数据增强方法,证明了LSTM模型在这种方法中的有效性。此外,通过与其他模型的对比,还证明了LSTM模型在序列数据预测任务中的优越性。这些结果对于中医药数据的分析和预测具有实际意义,并对其他序列数据的分析和预测也具有参考价值。
参考文献:
[1] 宋辉,苑龙祥,郭双权.基于数据增强和特征注意力机制的灰狼优化算法-优化残差神经网络变压器故障诊断方法 [J/OL].现代电力:1-9(2023-02-27).https://www.cnki.net/KCMS/detail/detail.aspx?dbcode=CAPJ&dbname=CAPJLAST&filename=XDDL20230223002&v=MjQ0NjRaT3NOWXdrN3ZCQVM2amg0VEF6bHEyQTBmTFQ3UjdxZFpPWm5GQzNsVmIvQUlscz1QU25QWXJHNEhOTE1yWTFH.
[2] 曹钢钢,王帮海,宋雨.结合数据增强的跨模态行人重识别轻量网络 [J/OL].计算机工程与应用:1-11(2023-02-16).http://kns.cnki.net/kcms/detail/11.2127.tp.20230214.1543.064.html.
[3] 宋刚,张云峰,包芳勋,等.基于粒子群优化LSTM的股票预测模型 [J].北京航空航天大学学报,2019,45(12):2533-2542.
[4] 李阳,高轼奇.基于数据增强及注意力机制的肺结节检测系统 [J].北京邮电大学学报,2022,45(4):25-30.
[5] 黄国栋,徐久珺,马传香.基于BERT-Encoder和数据增强的语法纠错模型 [J/OL].湖北大学学报:自然科学版:1-7(2023-03-03).http://kns.cnki.net/kcms/detail/42.1212.N.20230302.
1647.004.html.
[6] 曾子明,张瑜.基于数据增强和多任务学习的突发公共卫生事件谣言识别研究 [J/OL].数据分析与知识发现:1-16(2023-02-10).http://kns.cnki.net/kcms/detail/10.1478.g2.20230208.
1132.001.html.
[7] 孔繁钰,陈纲.基于改进双向LSTM的评教文本情感分析 [J].计算机工程与设计,2022,43(12):3580-3587.
[8] 秦佳杰,陈聪,关静,等.基于滞后效应的多变量LSTM模型对儿童呼吸道疾病就诊人数的预测 [J].中华疾病控制杂志,2022,26(9):1057-1064+1116.
[9] 刘金垒,惠小珊,张振鹏,等.基于中医诊疗指南的冠心病知识图谱构建 [J].中国实验方剂学杂志,2023,29(7):208-215.
[10] 芦霞.基于神经网络的感冒中药配方模型建立和性能考察 [D].南昌:华东交通大学,2011.
[11] 董雪情,荆澜涛,田瑞,等.基于LSTM模型的变压器顶层油温预测方法 [J].电力学报,2023,38(1):38-45.
[12] WU T,LIU C C,HE C. Prediction of Regional Temperature Change Trend Based on LSTM Algorithm [C]//2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). Chongqing:IEEE,2020,1:62-66.
[13] HUANG H H,WANG T Y,LIU J,et al. Predicting Urban Rail Traffic Passenger Flow Based on LSTM [C]//2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC).Chengdu:IEEE,2019:616-620.
[14] 于家斌,尚方方,王小艺,等.基于遗传算法改进的一阶滞后滤波和长短期记忆网络的蓝藻水华预测方法 [J].計算机应用,2018,38(7):2119-2123+2135.
[15] AKITA R,YOSHIHARA A,MATSUBARA T,et al. Deep Learning for Stock Prediction Using Numerical and Textual Information [C]//2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS).Okayama:IEEE,2016:1-6.
作者简介:柳鹏(1995—),男,汉族,江西宜春人,硕士研究生在读,研究方向:医药数据挖掘;熊旺平(1982—),男,汉族,江西丰城人,教授,博士,研究方向:数据挖掘;晏燕(1986—),女,汉族,江西丰城人,主管护师,硕士,研究方向:医药信息学。
收稿日期:2023-03-09
基金项目:国家自然科学基金(61762051);国家自然科学基金(82160955);国家自然科学基金(82274680)
