
基于ETM的消歧主题模型研究
2023-11-22 15:29郑静冯道鹏
现代信息科技 2023年19期
郑静 冯道鹏

摘 要:传统主题模型LDA使用词袋建模文档,无法建模词语之间的语义关系。虽然随后提出的ETM利用词嵌入的方法来建模词语之间的相似度,但是它们都无法处理一词多义现象。针对以上问题提出一种消歧主题模型。采用基于BERT的消歧方法并结合ETM对大型词表的鲁棒性,使得主题模型建模一词多义成为可能。通过在通用数据集上进行实验,验证了所提出模型在精确主题含义,增强主题可理解性上的优越性能,该模型能够挖掘出含义精确的主题,提高了主题建模的应用范围。
关键词:主题模型;词义消歧;词嵌入
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2023)19-0083-06
Research on Disambiguation Theme Model Based on ETM
ZHENG Jing, FENG Daopeng
(Hangzhou Dianzi University, Hangzhou 310018, China)
Abstract: The traditional theme model LDA uses word bags to model documents, which cannot model the semantic relationships among words. Although the ETM proposed later uses word embedding method to model the similarity among words, they are unable to handle the phenomenon of polysemy. Propose a disambiguation theme model to address the above issues. The use of BERT-based disambiguation method and combined with ETM's robustness to large word lists makes it possible to model polysemy in theme models. By conducting experiments on a universal dataset, the superior performance of the proposed model in precise theme meanings and enhancing theme comprehensibility are verified. The model can mine theme with precise meanings and improve the application range of theme modeling.
Keywords: theme model; word sense disambiguation; word embedding
0 引 言
潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)[1],是一种基于贝叶斯学习的话题模型。它的无监督学习的特性,免除了代价高昂的人工标注工作。又因为它出色的应用表现,使它在文本分析,文本挖掘领域获得广泛应用。如文献[2]直接应用LDA对语料库进行训练,得到文本背后隐含的主题,挖掘文本背后的信息。在深度学习方面,LDA可以生成文本的主题作为其他任务的输入特征[3]。
LDA使用一种分层结构。文档由隐含主题的多项分布表示,而话题则由单词的多项分布表示。这使得LDA具有优秀的可解释性,这也是其受到欢迎的原因之一。但是LDA模型在大型词汇表上—即大型语料库上的表现则不够优秀。在这种情况下,LDA生成的主题的质量会下降,一个显而易见的证据是困惑度的上升。因此在实际应用中,使用者将进行一些预处理工作,即过滤掉出现次数很低(通常只有几次)和出现次数过高的词汇(通常是定为一个较大的频率)。尽管这样使得词表的大小得到了控制,但是伴随而来的是遗漏重要信息的风险将增加。
嵌入式主题模型[4](Embedded TopicModel, ETM)将传统主题模型与词嵌入相结合。ETM将词设置为词嵌入向量,主题也相应地成为一个向量,而在一个主题下生成一个单词的概率由它们之间的相似性决定,比如它们的内积。这样做的好处在于,当我们使用ETM加载已经训练好的词向量时,即使出现训练语料库中未出现的词,ETM仍能通过词向量矩阵获得这个词与主题之间的联系。在ETM中,加载训练好的词向量的ETM,称为Labeled ETM, 其在主题质量(用主题的一致性和多样性来衡量)方面表现最优,且对停词具有鲁棒性,能够生成主要包含停止词的主题。这样即使不过滤停词,Labeled ETM仍能生成高度一致性的主题。
Labeled ETM使用Word2vec[5]来获取固定的词嵌入。随着近年来BERT模型[6]在众多领域取得最佳的成績。一个自然的想法就是将BERT模型的词向量应用于ETM中。这样做的出发点是,BERT模型能够根据输入文本的上下文动态的构建词向量。这样就为解决一词多义问题提供了一个新的方向。但这与ETM要求静态词嵌入相矛盾。因为把一个词在每个上下文中的动态表示都加入词表是不可能的。
利用BERT获得不同词义下的静态词向量,有两种解决方案。一种是直接对获得的动态词向量进行处理。聚类是一种首先想到的方法。然而根据实验,同一单词在表达一种意思时,受句子长短,上下文词的影响很大,聚类的效果通常很差[7]。
第二种方案是先对文本进行消歧,再根据消歧后的文本获得词向量。Loureiro[8]使用WordNet的注释得到每个词的词义的标准向量,将具体上下文中的目标词汇的向量与之进行比对,将相似度最高的标准向量对应的释义作为消歧结果,这种基于特征提取的1-NN方法被证明在词义消歧方面具有高效性和稳健性。为了控制词表大小,提高消歧精度。选择使用WordNet划分的25个独立起始概念进行标记。例如,对于“this mouse has no battery”中的mouse而言,mouse表示鼠标,其起始概念是artifact。
据此,本文提出了基于BERT的詞义消歧嵌入式主题模型,称为消歧主题模型。在能挖掘到高质量主题的同时,还能根据词义标记提高主题的可理解性。本文首先介绍了模型的构建方法,然后为了找出最佳方案,比较了直接训练获得词向量、Word2vec词向量、WordNet词向量三种词向量获取途径下的主题一致性和多样性,发现WordNet词向量表现更好;为了验证消歧主题模型能增强主题质量,分析了在不同词向量下的主题和可视化图像差异,发现使用WordNet词向量效果更好。
1 相关工作
1.1 ETM
ETM是基于词嵌入的主题模型。它在完成主题模型的主题建模这一功能外,使用词嵌入作为单词的表示,同时主题也是计算为嵌入空间中的一个点。这样,一个词在特定主题下的分布与它们之间的内积成正比,即词嵌入向量越相似,可能性越高。也正因为如此,对于停词而言,ETM能够通过形成“停词主题”,将停词分配到这种主题下,这增加了主题的质量,适合大型词汇表和语言数据的长尾情况。
ETM可以使用已经训练好的词嵌入输入,也可以在模型拟合的过程中学习。从实验结果上来看,使用预先训练好的词向量性能更好。
1.2 BERT
BERT起源于Transformer[9],使用Self-Attention架构,通过Attention机制来计算词语之间的联系,并且使用掩蔽语言模型进行训练,从而生成深度的双向语言特征。BERT在许多子任务上都取得了全新的成绩,因此被广泛应用于各种自然语言处理任务中。
通常将BERT的使用方法分为两类。第一类是基于微调的方法,根据目标任务设计对应的下游分类器,替换原来的softmax层。在这之后在目标任务的领域数据集上继续预训练。如Areej Jaber[10]根据医疗缩略语含义预测这一任务,设计了一个347类的分类器,并在医疗领域预料上继续预训练。另一类是基于特征提取的方法,除最后一层外将模型的网络作为一个特征提取器,提取出学习到的特征输入另一个模型。Loureiro[11]研究讨论了基于BERT的WSD任务在微调和特征提取上的表现(后者主要是K-NN)。发现后一种方法在感知偏差方面更加稳健,并且可以更好地利用有限的数据。
2 基于词义消歧的词嵌入主题模型
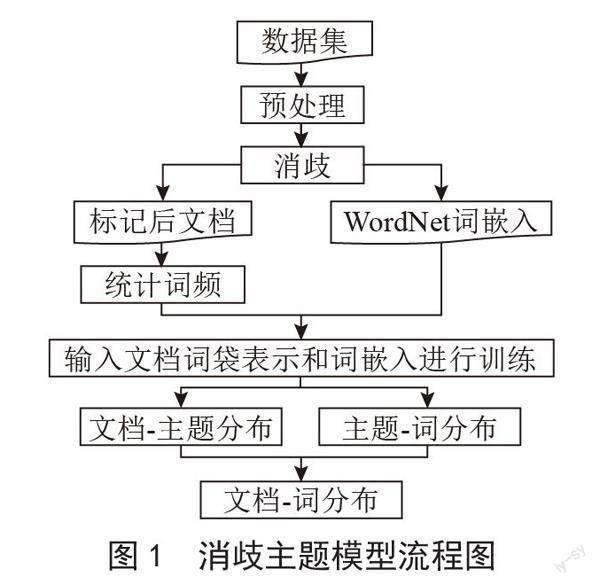
基于词义消歧的词嵌入主题模型同时利了ETM对大型词表的鲁棒性和基于BERT的1-NN消歧方法的高效性,这使得词义消歧能够应用于主题模型。消歧主题模型的流程图如图1所示。
其关键步骤为:
1)对原始数据集进行预处理,包括分词、删除特殊符号等。
2)将原始文本切分以适应BERT的输入长度要求。输入BERT获得动态词向量,并与WordNet标准词向量进行1-NN比较,将词打上对应的词义标记。
3)拼接打上标记后的文本,统计词频。
4)选择WordNet词向量或者Word2vec词向量,输入消歧主题模型,得到文档—主题矩阵和主题—词矩阵。
2.1 WordNet词义标记方法
将处理后的句子构造成BERT所需要的格式。得到每个词对应的动态词向量,同时使用spacy的spatial包对句子的每个token进行处理,得到每个词的lemma和pos。其中lemma是指词的基本形式,如liking将被还原成like。pos是指词性标记,如动词、名词。输入已经训练得到的WordNet词向量中根据1-NN进行匹配。匹配后对词语进行标记。例如意义为鼠标的mouse将被标记为mouse#artifact,表示其含义为人造物。
2.2 文档-主题结构及训练过程
具体而言,设词嵌入空间为RL,第k个主题是在此空间上的向量ak,即主题嵌入。和LDA一样,ETM是生成式的模型。它通过计算词嵌入和主题嵌入之间的相似性来计算主题生成单词的概率。
设ρ是L×V维的词嵌入矩阵,每一列ρv为词的词嵌入,词表大小为L,词嵌入可以输入WordNet词向量也可以训练得到Word2vec词向量。对第d个文档的生成过程为:
计算主题概率:θd~LN(0,1)
对文档d中的每一个词n:
计算主题概率:zdn~Cat(θd)
计算词概率:
其中LN(·)为logistic-normal分布。
δd~N(0,1);θd = softmax(δd) (1)
模型的拟合采用最大化文档的边际似然:
(2)
然而文档的边际似然函数计算的困难性,使用方程(2)来转化为:
(3)
生成每个单词的条件分布来边际化主题概率zdn。
(4)
其中θdk为式(1)中变换后的文档主题分布参数,βkv为主题词的分布参数。可由词嵌入ρ和主题嵌入ak得到。
由于上述的积分还是难以计算,因此使用变分推断构造一个后验分布的近似分布来拟合后验分布,用以最大化生成每个文档的对数边际似然的总和。假设文档—主题比例分布簇q(δd; wd, v),然后使用这个变分布簇来约束对数边际似然。对数边际似然的证据下界如式(5):
(5)
3 实验结果与分析
3.1 实验数据集及预处理
本次实验首先选取20newsgroups数据集来对提出的消歧ETM模型进行实验,验证所提出模型的可行性。20newsgroups数据集是用于文本分类、数据挖掘等自然语言处理研究的国际标准数据集之一。它涵盖了大约20 000个新闻文档,包括大概20个新闻主题。如摩托车、音乐,等等。
为了适配设置的BERT词向量长度。将长度超过512的文章切分为长度小于512的子文章。同时,为了保留句子的完整性。被切分的句子是一个整句,即每个输入子文章是若干完整句子的组合,且长度不超过512。
通过预训练模型获取词向量并对词义进行标注后,将各个子文章再进行拼接,得到可供ETM使用的数据集。
本实验选取数据集的80%作为训练集,20%作为测试集。
3.2 参数设置
本文选取的batch_size为32,学习率选择0.002,使用adam优化器,使用L2正则化防止过拟合,参数为1.2×10-6。
主题数的选取以困惑度为指标。如果模型对主题的预测有较好的效果,最后会得到较低的困惑度。同时,随着主题数的增加,困惑度会相应降低。困惑度的计算公式为:
(6)
其中,D为文档集合,共M篇,Nd为每篇文档d中的单词数,wd为文档d中的词,p(wd)为文档中词wd产生的概率。
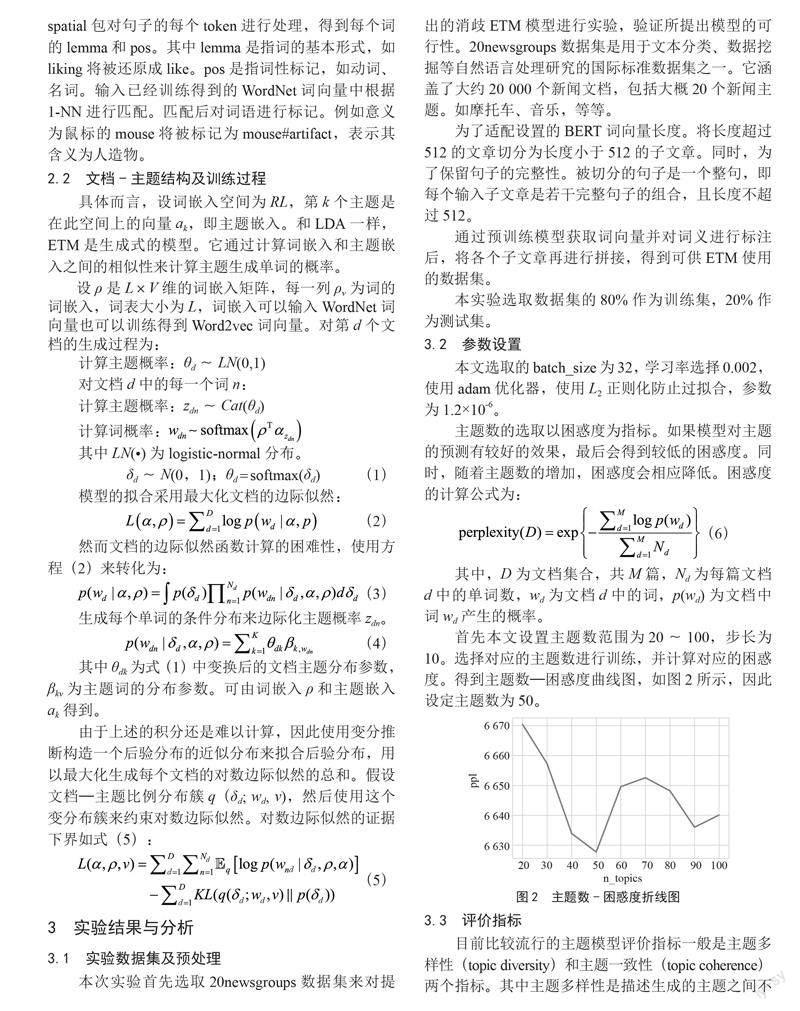
首先本文设置主题数范围为20~100,步长为10。选择对应的主题数进行训练,并计算对应的困惑度。得到主题数—困惑度曲线图,如图2所示,因此设定主题数为50。
3.3 评价指标
目前比较流行的主题模型评价指标一般是主题多样性(topic diversity)和主题一致性(topic coherence)两个指标。其中主题多样性是描述生成的主题之间不相似程度,主题越多样越好;主题一致性是描述生成的某个主题的词的联系紧密程度,主题的一致性越高越好。
两种指标的计算公式为:
主题一致性:
(7)
(8)
主题一致性衡量的是主题中出现的词在文章中贡献的可能性。如果这些词经常同时在文章中出现,这说明主题的一致性更强,聚合程度更高。其中, 为在主题k中,第i个概率最大的单词,f (·,·)为标准化点互信息。p(wi,wj)为wi和wj在文档中共现的概率,p(wi)为词wi的边际概率。
主题多样性:
(9)
主题多样性衡量的是在主题中概率排名前N个单词中不同单词的百分比,百分比越大表示主题更丰富。
最后,使用主题一致性与主题多样性的乘积作为模型主题质量的衡量标准。
3.4 结果分析
3.4.1 主题模型指标分析
在进行词义标注后,有三种可选的ETM训练方式。第一种是直接进行训练,第二种是应用Word2vec模型训练词向量,第三种是使用在消歧过程中获得的词向量。对这三种模型产生的结果采用前述的指标进行计算,得到结果如表1所示。
可见,在进行消歧标注后,三种方法中,直接训练的主题多样性很低,而输入Word2vec或者WordNet
词向量的模型均表现出不错的主题多样性。这主要是由于经过消歧后,词汇变得稀疏,模型很难提炼出多样的主题出来。WordNet词向量的表现又优于Word2vec词向量。后面所做出的分析仅针对Word2vec和WordNet词向量。
3.4.2 主题模型主题质量分析
如表2所示,wn_topic和wv_topic分別呈现了输入WordNet词向量或Word2vec词向量后生成的主题示例。由图可见,消歧主题模型至少有3个好处。
第一,注释了含义的词使得模型生成的主题更容易被理解,归纳,形成有价值的主题。例如auto标注了artifact会提示这是指“汽车”的意思而不是“自动”,drink标注了food会提示这是指“饮料”而不是动词“喝”。这些含义更清晰的词使得主题1意义更加清晰,它们都指向了关于酒精、暴力、犯罪等线索。在关于计算机的主题37中这种作用更加明显,chip、driver、memory、server、mouse这些词语都被标注了与计算机组件更相关的含义。分别指向了“芯片”“驱动程序”“存储器”“服务器”和“鼠标”,这些标注清楚的含义使得主题的含义变得非常清晰。
第二,含义更清晰的词使得主题的含义更确切,主题之间的边界更清晰。例如,在主题9中,driver标注了person,而在主题37中,driver标注了communication。这是因为主题9指向的是汽车而主题37指向的是计算机组件。因此它的两种含义,“驾驶员”和“驱动程序”使得两个主题之间的界限更加清晰。
第三,标注了含义的词会反过来提供一个能粗略的衡量模型效果的途径。简而言之,如果有某一主题下的词语标注的含义非常零碎,没有什么关联,那么这可能暗示模型的训练效果可能比较差。而在使用其他主题模型的情况下,人脑将自动地将词语的含义猜测出来去配合其他的词语。这不利于探知模型主题生成的效果。
3.4.3 词向量可视化分析
图3中包含三个主题,分别用方块、叉、三角呈现。其中方块是犯罪主题,包含汽车、枪支、犯罪、酒精等词语;叉是汽车主题,包含汽车、驾驶员、引擎等词语;三角是计算机主题,包含了计算机的各零部件。其中auto#artifact和automobile#artifact实际上同时是犯罪主题和汽车主题的词语。
在图中,很容易注意到driver这个词语。当它被标记为communication时,它与计算机相关概念更加接近,而被标记为person时,它与汽车相关概念更加接近。这说明这种消歧主题模型在区分词义方面是有效的,它也使得主题之间的耦合程度降低。同时也能观察到一些词嵌入与现实世界联系的有趣特性,例如酒精、酒吧与犯罪联系紧密。而dock#artifact既有泊位的意思,因此在汽车主题下出现,同时dock的另一个意思“程序的侧边栏”又与计算机有一定的联系。因此在图中,dock#artifact相比其他词语更靠近计算机主题一些。
Word2vec词向量下的可视化结果散布不太均匀,如图4所示。可以观察到计算机主题之间结合地的比较紧密,而另外两个主题内部则呈现比较稀疏的结果,它们的散布远远高于计算机主题。在这一点上,WordNet词向量下的结果更好一些,图3中的3个主题的紧密程度相似。另外,在主题之间的边界上,图3更容易辨认出3个不同而又相互关联的主题,主题之间的边界由两个主题之间共有的词或相关程度高的词组成。而图4中,主题之间的边界比较模糊,不容易辨识主题之间的关系。
综合而言,在主题内部的词语散布和主题之间的关联性上面,使用WordNet词向量的性能优于Word2vec词向量。
4 结 论
本文提出的消歧主题模型将消歧模型融入词嵌入主题模型中。通过利用词嵌入主题型的鲁棒性和限制了消歧的粒度。使得词嵌入主题模型含有消歧词有较好的表现。经过直接训练、Word2vec词嵌入和WordNet词嵌入输入三种模式下的一致性、多样性的对比实验,证明了WordNet词向量在消歧词嵌入模型下运用的优越性。通过对消歧模型产生主题的仔细讨论和可视化分析,证明消歧模型能够增强主题的可理解性,和准确性。考虑到目前的划分粒度还是会产生大型的词表,某些划分方式并不尽合理,对于词义的辨识方面具有较小的价值。未来,将在词义消歧的粒度和角度方面进行进一步研究,例如领域角度。领域角度的词义消歧能够提供更有价值的视角,并使得词表的大小得到进一步控制。在领域角度的词义消歧将对推进词义消歧研究发展、提高主题建模质量、为海量文本分析提供创新视角产生现实意义。
参考文献:
[1] BLEI D M,NG A Y,JORDAN M I. Latent dirichlet allocation [J].Journal of machine Learning research,2003,3(Jan):993-1022.
[2] BASTANI K,NAMAVARI H,SHAFFER J. Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints [J].Expert Systems with Applications,2019,127:256-271.
[3] 张志飞,苗夺谦,高灿.基于LDA主题模型的短文本分类方法 [J].计算机应用,2013,33(6):1587-1590.
[4] DIENG A B,RUIZ F J R,BLEI D M. Topic modeling in embedding spaces [J].Transactions of the Association for Computational Linguistics,2020,8:439-453.
[5] MIKOLOV T,CHEN K,CORRADO G,et al. Efficient Estimation of Word Representations in Vector Space [J/OL].arXiv:1301.3781 [cs.CL].[2023-03-06].https://arxiv.org/abs/1301.3781v1.
[6] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2023-03-06].https://arxiv.org/abs/1810.04805.
[7] YENICELIK D,SCHMIDT F,KILCHER Y. How does BERT capture semantics? A closer look at polysemous words [C]//Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP.BlackboxNLP:Association for Computational Linguistics,2020:156-162.
[8] LOUREIRO D,JORGE A. Language modelling makes sense:Propagating representations through WordNet for full-coverage word sense disambiguation [J/OL].arXiv:1906.10007 [cs.CL].[2023-03-06].https://arxiv.org/abs/1906.10007.
[9] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [J/OL].arXiv:1706.03762[cs.CL].[2023-03-06].https://arxiv.org/abs/1706.03762v4.
[10] JABER A,MART?NEZ P. Disambiguating Clinical Abbreviations Using a One-Fits-All Classifier Based on Deep Learning Techniques [J].Methods of Information in Medicine,2022,61(S1):28-34.
[11] LOUREIRO D,REZAEE K,PILEVAR M T,et al. Analysis and Evaluation of Language Models for Word sense Disambiguation [J].Computational Linguistics,2021,47(2):387-443.
作者簡介:郑静(1970—),女,汉族,安徽庆市人,教授,硕士生导师,博士,研究方向:隐马尔可夫模型、随机过程、文本挖掘;冯道鹏(1998—),男,汉族,湖北仙桃人,硕士研究生在读,研究方向:文本挖掘。
收稿日期:2023-04-04
基金项目:国家社会科学项目(21BTJ071)
