
基于语义分析的恶意JavaScript 检测技术
2023-11-21 14:12陈典超
电子设计工程 2023年22期
陈典超,王 晨
(1.武汉邮电科学研究院,湖北武汉 430000;2.南京烽火天地通信科技有限公司,江苏 南京 210000)
随着互联网的快速发展,Web 应用技术不断推陈出新。其中,JavaScript 因跨平台、动态执行等特性而崭露头角,成为Web 开发中必不可少的脚本语言。而根据腾讯反病毒实验室《2018 年度安全报告》显示:非PE 病毒中JavaScript 病毒排名第二,占所有病毒的23.21%。因此,恶意JavaScript 代码检测不容忽视。为了识别恶意的JavaScript 代码,网络安全研究者提出了三种检测方式:静态检测、动态检测和动静态检测技术。文中采用的是基于语义分析的恶意代码静态检测方法。首先,通过将JavaScript 代码解析为AST 的方式来防止代码混淆,然后,将解析好的JavaScript 语法单元序列放入FastText 和深度LSTM,以转换成动态词向量。最后,通过DPCNN 模型来提取恶意代码的特征,形成恶意JavaScript 代码检测模型。通过与传统的检测模型进行比较分析,最终表明该模型具有较高的准确性。
1 相关研究
恶意JavaScript 代码给Web 应用用户带来的巨大损失引起了网络安全研究者的广泛关注。为此,研究者将恶意JavaScript 代码检测技术划分为三类:基于代码结构的静态分析方法、基于动态执行结果的动态分析方法以及实时提取特征的动静态结合的组合分析法。
1.1 静态分析方法
静态分析方法主要是通过分析收集到的恶意JavaScript 数据集来提取恶意代码的特征。传统静态分析方法使用的是机器学习算法[1],如SVM[2](支持向量机)、朴素贝叶斯等。随后,深度学习开始应用于恶意代码检测。最初,文献[3]利用语义信息和随机森林的方式来检测恶意代码。静态分析方法推陈出新,文献[4]利用注意力机制通过双向长短期记忆神经网络来检测恶意代码,文献[5-6]也提出了基于语义信息的深度学习的监测模型。
1.2 动态分析方法
动态分析方法利用执行过程和执行结果来判断检测样本的恶意性。在沙箱、蜜罐等模拟环境中执行检测样本,在执行过程中将获取的代码执行细节、提取的类似行为作为特征,将这些特征作为依据来检测样本。2010 年提出的JSAND 检测技术利用蜜罐动态分析恶意代码的执行细节,提取相似性。之后,提出了基于攻击行为建模的恶意检测方法,它使用确定性有限自动机(DFA)来总结行为特征,获取恶意行为信息。
1.3 组合分析方法
组合分析方法种类繁多,如文献[7]使用机器学习和动态程序分析恶意代码的攻击特征向量或动态执行轨迹来进行检测,首先对代码进行动态解析;然后静态扫描解析出的内容,统计其特征,实现恶意代码检测;之后;使用静态方法解析代码的动态特征和静态特征,使用深度学习模型对特征进行综合分类,以实现恶意代码检测。
2 研究方法
2.1 系统概述
该文所使用的检测模型分为两个步骤:数据处理、模型训练与检测,如图1 所示。数据处理阶段采用Esprima 解析器将JavaScript 代码解析为AST(抽象语法树),通过遍历AST 生成语法单元序列实现代码的反混淆[8-9]。然后使用FastText 来训练对应的语法单元序列获得对应的静态词向量[10],根据获得的静态词向量,使用多层Bi-LSTM 来生成检测模型所需要的包含语义信息的动态词向量。模型训练与检测阶段主要是向DPCNN[11]输入动态词向量[12]提取相应的特征,然后根据特征来判断代码的恶意性。
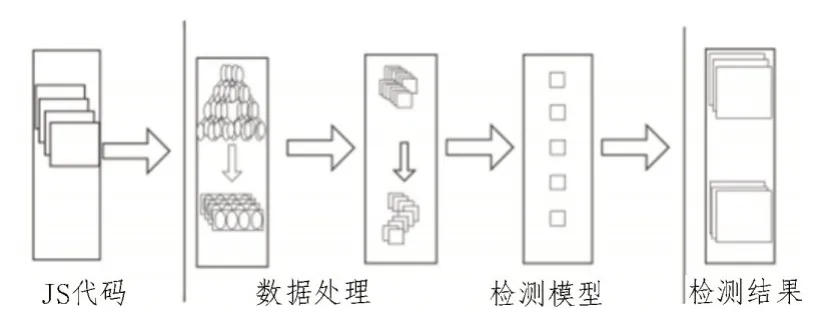
图1 监测模型框架
2.2 语法单元序列的生成
语法单元序列依赖上游的AST(Abstract Syntax Tree)抽象语法树生成,然后为下游的词向量提取做准备。该文采用高性能的语法分析工具Esprima 解析JavaScript 代码。作为常用的静态代码分析工具,Esprima 不仅可以生成合理的语法树,还可以实现语法可视化、代码验证等功能。其高性能则表现在不仅可以对不同版本的JavaScript 代码进行解析,还可以对混淆后的JavaScript 代码进行解析来实现反混淆的功能。Esprima 将JavaScript 代码解析成不同类型的节点,然后映射成对应的树形节点,继而形成抽象语法树AST。最后通过深度优先遍历的方式遍历语法树,生成语法单元序列,Esprima解析过程如图2所示。
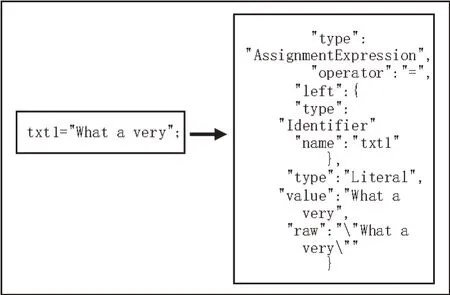
图2 Esprima解析过程
2.3 基于FastText和Bi-LSTM的词向量提取
语法单元序列在输入检测模型进行特征提取和检测前,需要转换成模型所需的词向量数据。该文将词向量提取分为两步:静态词向量提取和包含语义信息的动态词向量提取。在静态词向量提取中,该文采用的是FastText 词向量模型。相比于传统的Word2Vec 模型,FastText 的一大优势就是字符级别的n-gram 分词。字符级别的n-gram 可以最大程度上解决相似词的词向量相似问题。以单词statement 为例,<为前缀,>为后缀,FastText分词结果如图3所示。
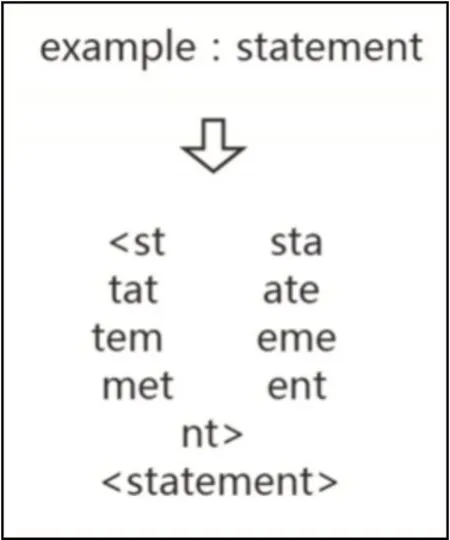
图3 FastText分词结果
然而,FastText 提取的静态词向量不包含上下文语义信息。为此,需要经静态词向量转换成具备上下文语义的动态词向量。为了构造包含上下文语义信息的词向量,该文引入了Bi-LSTM(双向长短期记忆)网络。单向的LSTM(长短期记忆)网络只包含上文的语义信息,而Bi-LSTM 则是通过正向和后向的双向LSTM,通过拼接的方式构造出了包含上下文语义信息的动态词向量。如图4所示,该文采用多层叠加的深度Bi-LSTM 来构造动态词向量Ht。
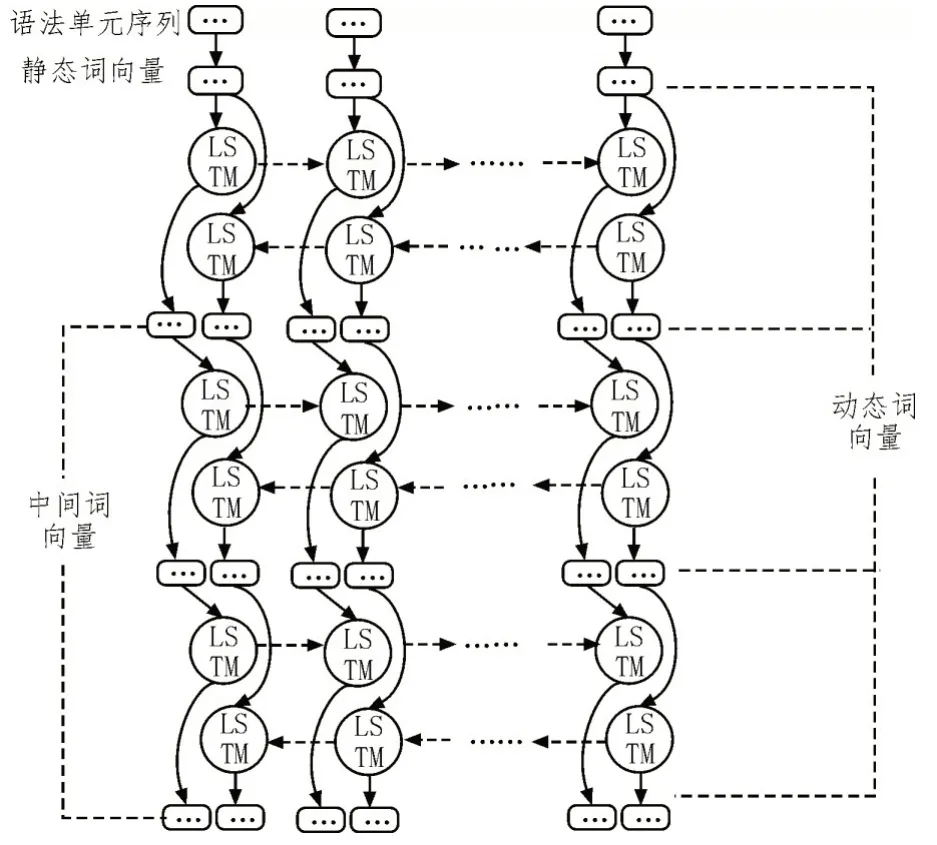
图4 动态词向量的生成
假设一个语法单元序列S 经过FastText 训练后,得到每个语法单元对应的静态词向量,如式(1)所示:
对于每个静态词向量Wt,通过每一层前向LSTM和后向LSTM 都会生成不同动态词向量,拼接后形成时间t的输出Ht,如式(2)所示:
而对于前向分量和后向分量的{Hi|i=1,2,3},其计算公式如式(5)-(6)所示:
动态词向量Ht由FastText 构造出的静态词向量Wt、Wt通过前向LSTM 得到的和Wt通过后向LSTM 得到的拼接而成。前向LSTM 提取上文的语义信息,后向LSTM 提取下文的语义信息。由此,每个输出都包含了上下文的语义信息。
2.4 恶意代码检测模型
在选择深度学习算法中,该文采用了层次更深、精度更高的深层金字塔卷积神经网络(Deep Pyramid CNN,DPCNN)。DPCNN 的模型架构如图5 所示。
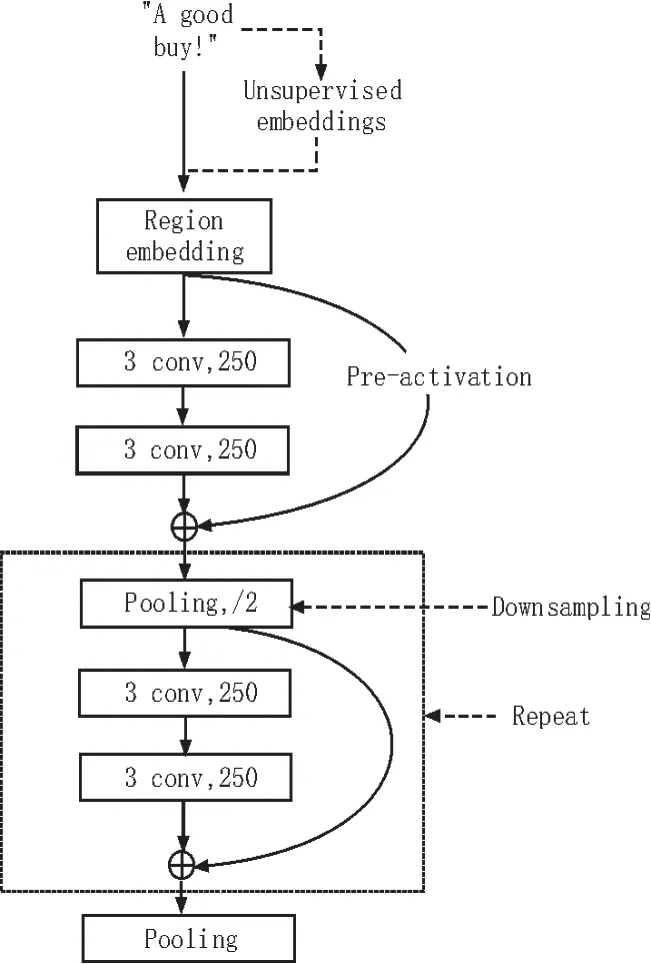
图5 DPCNN模型
相比于传统的TextCNN[13],DPCNN 在不增加运算成本的情况下,通过加深网络的方式来获取更高的准确率。在DPCNN[14-15]模型中,词嵌入可以包含多个词的嵌入,之后卷积层和下采样层交替重复出现。在下采样层中,DPCNN采用数量不变的特征图。因为特征图尺寸减半,卷积运算的时间也相应减半。经过这样的下采样,模型实现了不增加运算成本的情况下加深网络和增强全局特征提取能力的功能。不仅如此,DPCNN 还采用了等长卷积和区域词嵌入的方式来提高词向量的语义内涵。经过上述步骤后,检测模型获得了JavaScript 恶意代码的特征。最后,使用这些特征通过一个全连接的Softmax层来计算检测样本相应的概率分布。
3 实 验
3.1 实验设计
1)数据集
该实验的JavaScript 数据集主要来自两方面:爬取Alexa平台前100名的网站获取良性数据集2 000个,在GitHub 等平台上获取恶意数据集2 000 个。最后,将所有的数据集以4∶1 的比例随机分为测试集和训练集。实验环境信息如表1 所示。
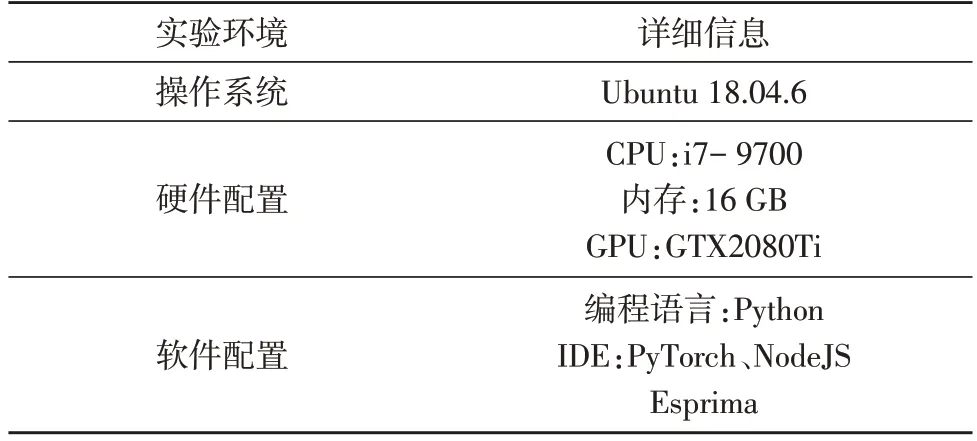
表1 实验环境信息
2)参 数
该模型在表1 所示的实验环境中运行,样本数据和语法单元序列的提取使用NodeJS 和Esprima 来实现。词向量的训练和模型的构建则是由Python 实现的。模型的训练参数包括epoch=20,batch_size=32,batch=100,seq_len=128,pool_size=3,stride=2,学习率设置为0.001,dropout设置为0.1。
3)评估标准
在分类算法中,通常使用TP(真正率)、FP(假正例)、TN(真反例)和FN(假反例)作为评估的基本标准[16]。为了更加准确地评判每种分类算法的准确性,该文采用准确率、精准率、召回率和F1 值作为模型的评估标准。其计算公式如式(7)-(10)所示:
3.2 实验结果
实验将该文检测模型与SVM(支持向量机)[17-18]、朴素贝叶斯两种传统机器学习算法和双向LSTM、结合注意力机制的Bi-LSTM、JSContana 三种深度学习算法进行对比。如表2 所示,所有算法均采用准确率、精确率、召回率和F1 值来进行评估,评估指标为加权平均值。

表2 该文检测模型与其他算法的检测结果对比
从表2 可以看出,该文检测模型在几种机器学习算法和深度学习算法中效果最好,准确率最高。在使用五折交叉验证时,准确率和召回率都达到了0.96。然后是JSContana 和Bi-LSTM-Attention,双向LSTM 表现一般。最后是SVM,朴素贝叶斯算法的性能最差,准确率和召回率分别为0.73、0.75;相对而言,使用深度学习算法的模型性能较机器学习算法的模型性能好。而在深度模型算法中,DPCNN 和Bi-LSTM 组合模型的性能最好。
不同模型处理时间的对比如表3 所示。
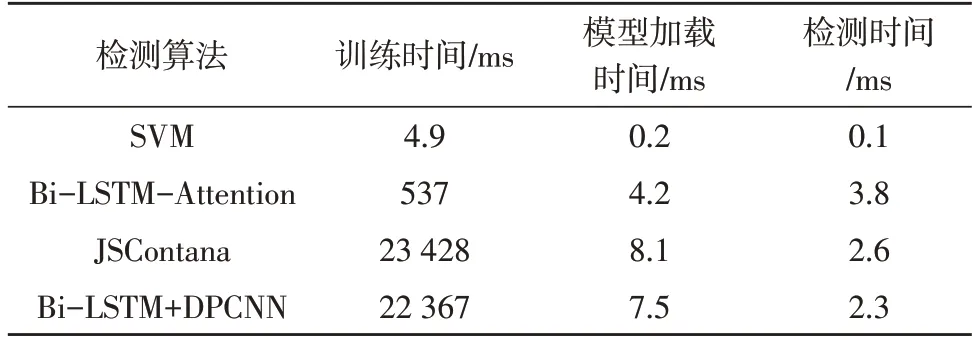
表3 不同模型处理时间的对比
由表3 可以看出,在模型训练和加载时间上,因为动态词嵌入模型收敛较慢,JSContana 和结合Bi-LSTM 的DPCNN 模型耗时都是最多的。此外,JSContana 和该文检测模型在加载时间和检测时间都是最为接近的,证明了机器学习耗时虽短,但是准确率不高。而深度学习算法在检测时间成本和性能上,结合Bi-LSTM 的DPCNN 模型是最佳的。
4 结论
该文提出了一种基于语义的JavaScript 恶意代码静态分析检测模型。为了提高检测效果,避免版本更迭和混淆代码造成检测失真,该文检测模型在数据处理时,首先使用抽象语法树提取详细的语法单元序列。然后,使用叠加的双向LSTM 生成动态词向量使词向量携带代码的真实上下文语义信息。最后,DPCNN 为模型提取恶意代码特征并进行检测。经由上述实验对比可知,该检测模型准确率高达0.985。这也意味着该检测模型可以有效地检测JavaScript 恶意代码。
但是,该检测模型仍具备较大的缺陷。模型由叠加的双向LSTM 和卷积神经网络DPCNN 组成,这意味着模型需要较多的训练样本和较长的训练时间。此外,随着网络的飞速发展,恶意代码的种类和数量也会快速增加,该检测模型对恶意代码的敏感性会不断降低。因此,文中提出的检测模型仍需进一步研究和改进。
猜你喜欢
云南画报(2021年8期)2021-11-13
中学生数理化·高一版(2021年4期)2021-07-19
阅读(低年级)(2019年4期)2019-05-20
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
摄影之友(影像视觉)(2016年2期)2016-08-16
