
基于CNN-ABC-BiGRU 的火电厂数据分析与应用研究
2023-11-21 14:12宗学军杨忠君
电子设计工程 2023年22期
李 萌,宗学军,连 莲,何 戡,杨忠君
(沈阳化工大学信息工程学院,辽宁沈阳 110142)
在当今大数据时代的产业界,深度学习在大数据场景下更能揭示数据内部逻辑关系,进而指导企业决策[1-2]。目前已有学者在电力领域广泛使用深度学习技术,文献[3]建立了基于卷积神经网络(Convolutional Neural Networks,CNN)-门控循环网络(Gate Recurrent Unit,GRU)的负荷预测模型;文献[4]基于CNN 对电厂热能循环进行了预测控制。但深度网络耗时较长才可达到预期性能。另有部分学者将并行计算技术用于算法优化[5],文献[6]提出了并行化深度卷积神经网络,提高收敛速度和并行效率。文献[7]提出了一种基于Spark 平台的并行决策树算法,保持分类精度的同时提高大规模数据的训练效率。然而电厂运行状态的并行预测模型仍有深入研究空间。文中在火电厂工业环境下将深度学习引入Hadoop 框架,实现设备健康状态精准高效预测,与以往数据分析平台相比,经Hadoop 框架优化的算法处理数据效率和模型的准确度有所提高。
1 火电厂环境的分布式框架
Hadoop 分布式框架主要解决大数据的存储和挖掘分析问题[8]。分布式文件管理系统(Hadoop Distributed File System,HDFS)将现场工业设备传感器采集的数据拆分多个数据块,其中时间序列数据由Spark 引擎调用,采用内存计算的方式实现锅炉主蒸汽流量的实时预测。
2 CNN-ABC-BiGRU模型
2.1 理论基础
CNN 主要包括卷积和池化两个组件,它们通常交替出现在CNN的结构中,以实现特征提取[9]。LSTM是循环神经网络(Recurrent Neural Network,RNN)的改进,以缓解RNN 在训练时出现梯度消失和梯度爆炸等问题[10]。GRU 处理等量数据时相较于LSTM 网络,裁汰了部分训练参数,降低了学习时间要求,并可防止LSTM 网络经过层层训练之后因参数过多而产生的过拟合问题[11]。传统的GRU 结构使用单向传播,t时刻只与过去的时间相关。为使对输入信息的分析更加完整,模型的准确性更高,遂构建BiGRU 模型。BiGRU 神经网络结构如图1 所示,其具体计算见式(1)-(3)[12]:
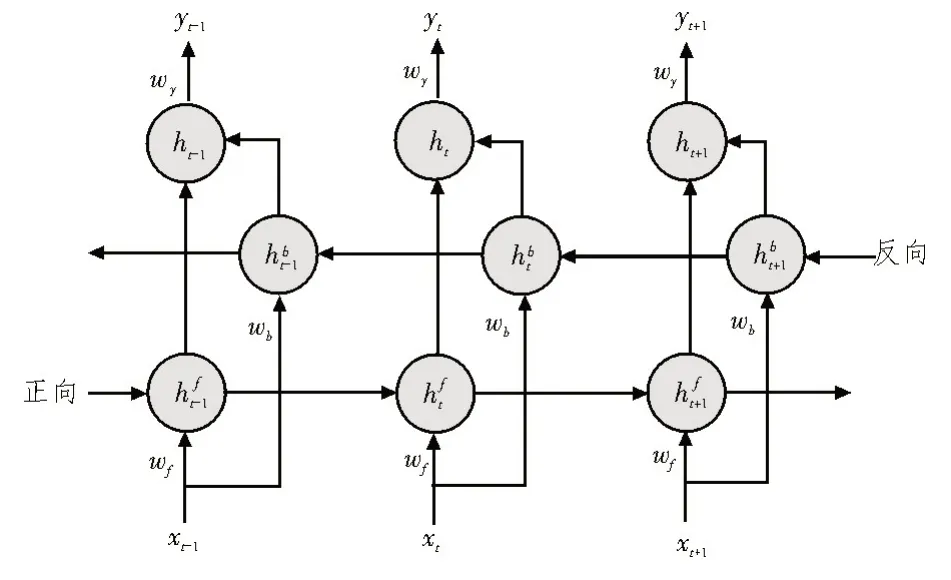
图1 BiGRU神经网络结构
其中,GRU()函数表示对输入时间数据的非线性变换,wf和wb分别为正反两个方向预测过程中输入层到隐含层的权重,ht为当前时刻的隐含层状态,wy为隐含层到输出层的权重,yt为当前时刻的输出值。
由于某一时间点的过去与未来时刻对当前时刻隐含层状态都有影响,BiGRU 相较于单向GRU 添加了一层隐含层,使预测过程改良为正向预测与反向预测两个过程,新模型的输出结果由正反双向的隐含层共同决定。因此,BiGRU 网络有能力学习过去和未来主蒸汽流量影响因素与当前主蒸汽流量之间的关系。
2.2 CNN-ABC-BiGRU网络
ABC 是D.Karaboga 于2005 年提出的一种基于蜜蜂群体特定智能行为的最优化算法。ABC 算法在每次迭代过程中都会执行全局和局部最优搜索任务,其控制参数较少、鲁棒性强、收敛速度快。
文中提出一种基于CNN-ABC-BiGRU 网络的预测模型,具体步骤为:
1)将实验数据划分为训练数据、验证数据和测试数据。
2)初始化ABC 参数,确定种群数、最大迭代次数、控制参数等其他参数的初始值。
3)构建CNN-BiGRU 主蒸汽流量预测模型,确定所需寻优的CNN-BiGRU 模型的超参数和寻优范围,然后在范围内依据式(4)随机生成N个初始可行解,并将它们被分配给引领蜂:
其中,xij为第i个可行解的第j个参数。每个初始解xi(i∈(1,2,…,N))为D维向量,D是待优化参数的数目,j∈{1,2,…,D},和分别为第j个参数的最大值与最小值,即待优化参数的可行区间;rand(0,1) 为[0,1] 范围内的随机数。
4)针对初始解对CNN-BiGRU 模型展开训练,根据式(5)寻找初始种群中每个可行解的适应度fit(xi):
其中,f(xi)为可行解的目标函数。
5)引领蜂在每一个可行解邻域进行搜索,根据式(6)寻找新的可行解vij(t+1),并计算适应度:
其中,i,k∈(1,2,…N),j∈{1,2,…D},k为随机生成的数值且k≠i,vij为算法对第j个参数计算的新解,φij为[-1,1] 范围内的随机数。
6)根据式(7)所示的贪婪算法,比较新解与现有解,保留适应度大的可行解:
7)根据式(8)得出第i个可行解被选择的概率值Pi:
8)跟随蜂依据概率值Pi以轮盘赌的方式选定某一个可行解,并根据式(6)在其邻域随机搜索新的可行解以及计算新可行解的适应度值。
9)根据式(7)所示的贪婪算法,更新可行解。
10)判断是否存在因连续未更新次数达到限制而被放弃的可行解,若存在,则由侦查蜂根据式(4)随机得到一个新的可行解替代它。
11)保留最优可行解。
12)如果满足终止条件,或者已经用尽迭代次数,返回最优可行解,否则跳转到步骤5)重新循环。建立该预测模型的流程如图2 所示。

图2 CNN-ABC-BiGRU网络建模流程图
3 实验与分析
3.1 数据选择
利用基于逐步回归的变量选择方法选择最优变量,得出相关因素的相关性,然后采用VIF 检验排除因具有多重共线性而对算法结果有影响的变量,从而决定输入模型变量数量。
3.1.1 逐步回归分析
逐步回归方程变量较少,且能保留最为显著的变量[13]。逐步回归分析变量之间的相关性,逐个引入新变量,每引入一个新变量时考虑模型包含的变量能否被剔除,直至不再引入新的变量,这时回归模型是最优模型。
3.1.2 基于VIF的多重共线性检验
假设存在不全为零的m+1 个数c0,c1,c2,…,cm,使得c0+c1xi1+c2xi2+…+cmxm≈0,i=1,2,…,n,此时自变量x1,x2,…xm有完全共线性。检验后若变量与变量出现多重共线性,消去共线性之后计算得到回归方程系数并可以进行VIF 检验[14]。
自变量相关矩阵记为:
主对角线元VIFj=cjj是自变量xj的方差扩大因子(Variance Inflation Factor,VIF),若1≤VIF≤5,则无多重共线性。
3.1.3 特征选择结果
如表1 所示,对采集的10 组数据进行逐步回归分析,最终得到六个特征变量,包括给水流量、汽包液位、一次风量、二次风量、炉膛床压和氧含量,以主蒸汽流量作为因变量建立多元回归方程组,对模型都进行显著性和VIF 检验。
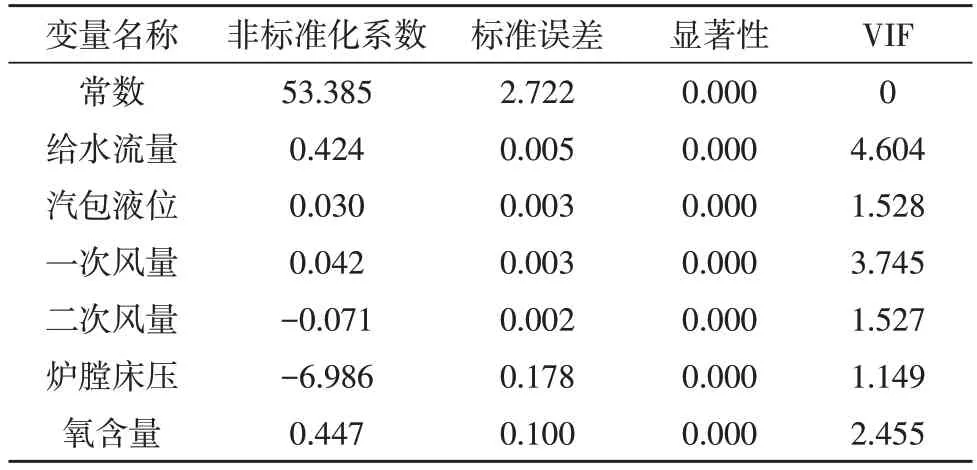
表1 逐步回归模型及VIF检验结果
检验结果显示,x1,x2,…,x6的VIF 皆小于5,表明该模型无多重共线性。检验统计量F=9 501.770,显著性p<0.05,表明该回归方程显著性较强,特征变量对主蒸汽流量影响性很强。将特征变量依次设为x1,x2,…,x6,主蒸汽流量设为y,可得:y=0.424x1+0.030x2+0.042x3-0.071x4-6.986x5+0.447x6+58.385。
3.2 实验环境
实验总计使用11 万条电厂运行数据,预测模型中包括被选入训练集的九万个数据,和被随机选入测试集用来评估模型效果的两万个数据。Hadoop集群实验硬件平台选用三台主机,包含一台主节点和两台副节点。
3.3 算法评估与比较
根据均方根误差(RMSE)、平均绝对误差(MAE)以及平均百分比误差(MAPE)三种评价指标评价所有模型,定义如下:
为了全面评估CNN-ABC-BiGRU 模型的预测效果,将其与CNN-BiGRU[15]、BiGRU、GRU[16]、LSTM、BP五种常见的预测方法进行预测性能比较。
3.4 预测结果分析
使用特征筛选后的数据集对提出的组合模型与其他对比模型进行训练和测试,所得预测结果如图3、4 所示。

图3 日期A预测曲线与真实曲线对比
图3 中的主蒸汽流量波动较大,在21-30 个采样点区间内,主蒸汽流量值从220.736 16 t/h 增加到236.267 78 t/h 又减少到222.145 31 t/h,只有CNNABC-BiGRU 模型GRU 实现了准确跟踪变化趋势。图4 中的主蒸汽流量值较为平稳,除BP 算法以外,其余五种算法预测曲线都贴合真实值变化趋势,其中CNN-ABC-BiGRU 模型预测曲线最接近真实值曲线。对比结果表明,自适应CNN-ABC-BiGRU 模型在预测变化范围较大和近乎稳定的数据时,都具有良好的预测性能。

图4 日期B预测曲线与真实曲线对比
如表2-3 所示,在两天的预测结果中,所提组合模型相较于其他模型,具有最小的均方根误差、平均绝对误差和平均百分比误差。
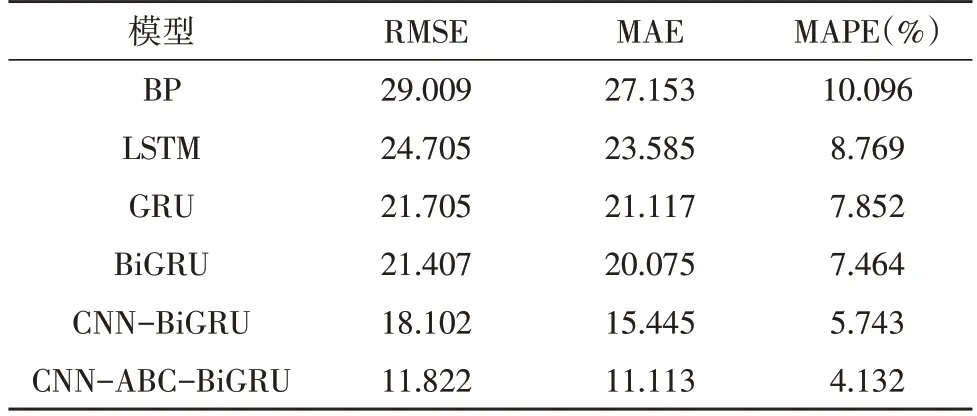
表2 2020年10月8日对比实验结果
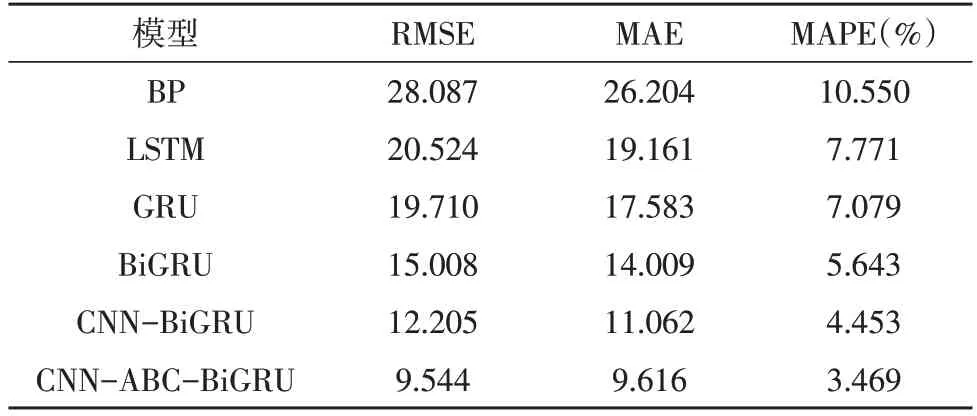
表3 2021年3月8日对比实验结果
在六种模型的预测误差对比中,深度学习模型误差小于机器学习模型误差,具体表现为深度学习的组合模型误差最小,单一模型次之,机器学习模型误差最大。在主蒸汽流量值波动较大的第一天,深度学习模型与机器学习模型误差结果对比更为明显,主蒸汽流量值较为平稳的第二天差距较小。产生这种结果的原因是,在处理火电厂大数据时,深度学习模型利用训练集大量特征数据动态地进行学习,学习动态特征与预测目标之间的内在规律,在解决非线性波动问题时表现效果更好。
分布式训练与单机训练用时比较如图5 所示。

图5 分布式CNN-ABC-BiGRU算法训练与单机用时对比
传统单机CNN-ABC-BiGRU 算法运算用时表现为一次函数趋势,样本数量小于60 000 个时,单机运算和通过分布式运算用时相差不大,随着训练样本不断增加,基于Hadoop 的CNN-ABC-BiGRU 算法用时缓慢增加,二者用时差距随着样本数量的增加而增大。实验结果表明,处理火电厂运行积累的大规模数据时,Hadoop 框架下的分布式运算相较于单机运算有效节省训练时间,能够更快得出预测结果,具有更好的可行性和高效性。
4 结论
文中面向大数据背景下的工业系统数据分析的现实需求,结合火电厂燃烧系统设备监测大数据的特点构建分布式深度学习模型,研究结果表明:
1)将CNN-ABC-BiGRU 网络用于设备健康预测,避免了单一预测模型难以获得最优结果的问题。
2)基于Hadoop 框架的算法训练相较于传统单机算法有效缩短模型训练时间,实时处理速度相较于传统的数据分析平台显著提升,对比结果表明了该方法的优越性。
3)该数据分析体系结合深度学习建模方法的提出为电力生产数据的处理提供了研究方向,实时追踪锅炉系统的动态运行过程,预测性维护可应用于故障检测、工业设备评估等方面。在后续的研究中,可通过增加集群数量,对建模方法进行进一步优化研究。
猜你喜欢
设备管理与维修(2022年21期)2022-12-28
科学与财富(2021年3期)2021-03-08
——以多重共线性内容为例
长沙航空职业技术学院学报(2019年2期)2019-07-13
温州大学学报(自然科学版)(2019年2期)2019-06-04
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中国核电(2017年1期)2017-05-17
小猕猴智力画刊(2017年4期)2017-05-04
军事文摘·科学少年(2017年1期)2017-04-26
雷达与对抗(2015年3期)2015-12-09
