
基于循环神经网络的多核处理器层次化存储技术
2023-11-21 14:12辛明勇祝健杨徐长宝刘德宏
电子设计工程 2023年22期
辛明勇,祝健杨,徐长宝,姚 浩,刘德宏
(1.贵州电网有限责任公司电力科学研究院,贵州贵阳 550002;2.南方电网数字电网研究院有限公司,广东广州 510663)
在电网数字化转型过程中,海量电网数据的同步性存储是一个亟需解决的难题。电网数据的存储体系,直接影响着处理器的整体工作性能和功耗水平,合适的存储技术能够显著提升处理器的数据处理效率,避免重复的数据计算。其中,多核处理器通过增加核的数量以提升处理器的可扩展性和并行性,逐渐取代了单核处理器在电子产品中的应用。但目前应用于海量电网数据储存的多核处理器存储技术研究尚不成熟,数据存储同步性差、数据重复显著且数据存储缺乏条理性,影响了多核处理器的整体工作质量。
为此,国内的研究学者对此展开了深入研究和探索。文献[1]提出的基于FPGA 和FLASH 的多核处理器层次化存储技术采用FPGA 微型处理器,采用RS422 串行转换模式将串行数据转换为并行数据模式,包含一级存储模块和二级存储模块,内设FLASH处理器,执行控制模块的控制指令,存储稳定性高且易于实现,但该技术不能有效剔除重复数据,存在抗冗余度较低的问题。文献[2]提出的基于CloudSim 的多核处理器层次化存储技术,以层次组织结构进行设备划分,并采用CloudSim 层进行拓展功能集成,整体灵活性较强,且抗冗余度高,但数据存储同步性较差,易出现存储误差等现象。文献[3]提出的基于Hadoop 云存储架构的多核处理器层次化存储技术,采用Hadoop 云存储架构对数据存储技术进行优化,能够有效提升数据存储的吞吐量和存储效率,但整体同步性较低,仅适用于网络数据存储,适应性不高。
为解决以上问题,文中提出了基于循环神经网络的多核处理器层次化存储技术,并针对其实际应用性能进行了实验验证。
1 多核处理器层次化存储处理
1.1 非对称多核处理器
非对称多核处理器属于异构处理器的一种,其设计原理是在同构处理器的基础上保留中断控制器、寄存器、总线以及电源等结构设计,采用指令集架构设计方案进行整体设计,保证指令的正确生成、发送和执行,并引用并行ILP 设计流水线,提升处理器的资源处理效率,且为满足异核同步运行需求,每个核的流水线设计架构各不相同。与此同时,异构多核处理器的缓存系统采用可动态配置缓存架构,支持算法替换和策略回写,有效降低程序访存带宽,提升程序访存效率[4-5]。异构多核处理器和同构多核处理器的结构差异如图1 所示。
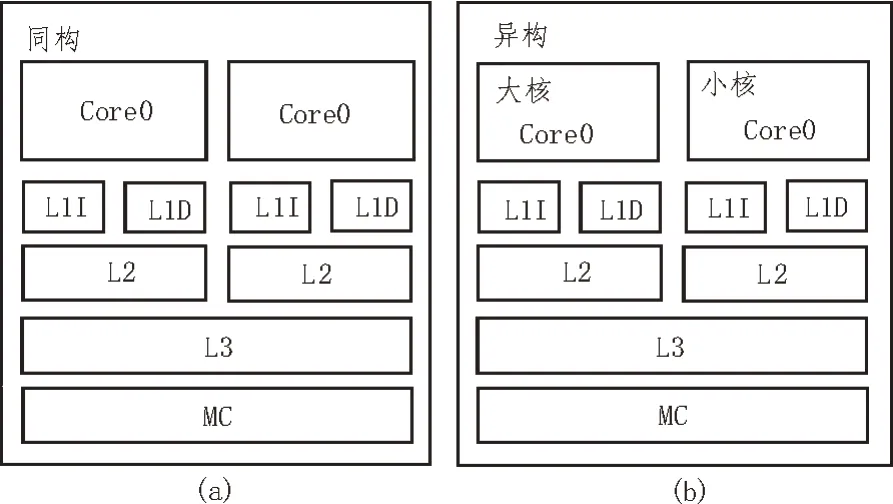
图1 异构多核处理器和同构多核处理器的结构差异
1.2 并行多核处理器快速卷积算法
并行多核处理器快速卷积算法以循环神经网络算法为基础,包含数据布局、数据转换以及矩阵乘等三部分核心内容。首先,数据布局是指数据在多核处理器存储单元中的存储方式,文中综合考虑数据布局转换开销、矩阵乘算法的访存顺利、算法实现的访存范围等多种影响因素设计数据布局。
定义I表示数据输入特征图,O表示数据输出特征图,F表示数据存储格式,D、U均表示存储矩阵的内部张量,α、β、γ均为矩阵分块计算中的参数。
在上述数据布局下,当数据存储格式和大小确定后,建立数据转换矩阵AT,P和Q为常数,数据转换过程如式(1)所示:
式中,z为转换后的输出数据。
经过上述数据转换后,采用向量单元计算矩阵乘,由于非对称多核处理器由寄存器、一级缓存器、二级缓存器等层次组成[6-8],故采用分块式方法最大限度地挖掘数据价值,将矩阵分为大小为4×4 的子矩阵,矩阵乘的计算方法如下:
其中,C为矩阵乘的计算结果;ui为子矩阵;CN为ui在寄存器中重用次数。
优化后的矩阵乘示意图如图2 所示。
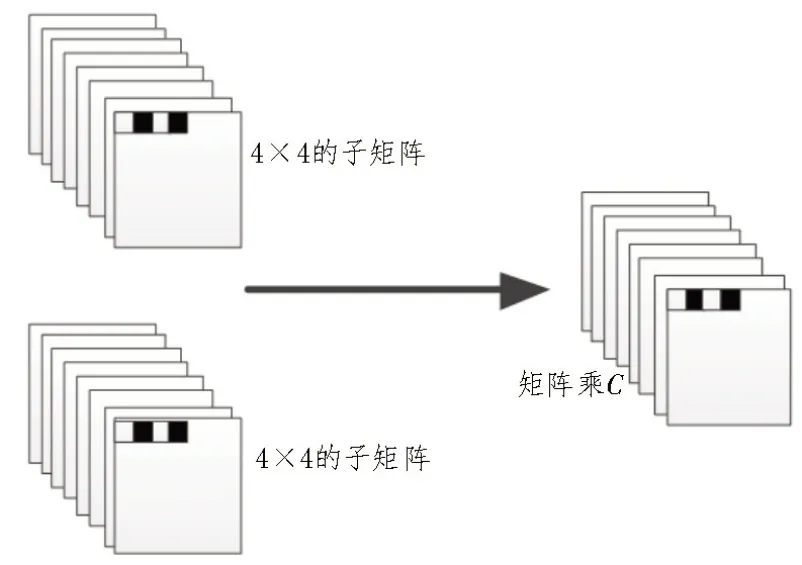
图2 优化后的矩阵乘示意图
2 基于循环神经网络的存储优化
2.1 数据存取流程优化
为提高数据存储效率,文中以循环神经网络为基础构建神经网络模型,采用分层次数据存储方式,将不同结构的数据进行分类存储,在数据存储时,统一化数据存储格式,以IFC 数据为标准数据存储格式,并将数据的属性信息以osg 格式存入数据库中,在进行数据查询和提取时,通过存储节点读取数据库中osg 数据,再调用属性信息查询函数,就能实现高效率且高精度的数据存取[9-11]。基于循环神经网络的数据存取过程如图3 所示。

图3 基于循环神经网络的数据存取过程
2.2 数据库设计优化
数据库的设计需综合考虑多种因素,既要满足数据的存储需求,又要减轻编码负担,保证数据存储的安全性和稳定性的同时,又要便于维护和管理。为此,针对多核处理器的存储需求,根据数据与数据、数据与存储空间之间的组织关系,建立CompoenentInfo 数据表存储数据组织关系,包含存储节点、数据编号、属性编号、数据类别、数据名称、存储层级等字段[12]。
2.3 存储节点的选择
1)ES 存储节点的复杂度计算
由于ES 存储节点只具备数据存储功能,不具备数据查询功能,故ES 存储节点的总体网络消息传输复杂度TMCES为:
其中,n为数据传输数量;ri为第i个子存储节点的存储效率;为数据发送节点的发送效率。
根据数据存储复杂度的定义,计算一个存储节点最大可能存储的数据量,即考虑最极端存储状态下,多核处理器中产生的所有数据都经过一个存储节点进行存储,则ES 存储节点的数据存储复杂度HTCES为:
式中,sd为数据存储的报文大小。
2)LS 存储节点的复杂度计算
相较于ES 存储节点,LS 存储节点不具备数据存储通信功能,仅具备数据查询功能,LS 存储节点的总体网络消息传输复杂度TMCLS为:
式中,Ri为第i个子存储节点的查询效率。
同上,考虑数据存储复杂度,在最极端存储情况下,LS 存储节点的数据存储复杂度HTCLS为:
式中,sq为查询数据的大小。
3)DCS 存储节点的复杂度计算
相较于以上两种存储节点,DCS 存储节点兼具数据存储功能和查询功能[13-16],使用散列函数将每个数据类型映射到特定的存储空间,每个子存储节点在主存储节点的控制下进行分层次数据存储,DCS存储节点的总体网络消息传输复杂度TMCDCS为:
在极端存储状态下,所有数据包、查询数据以及恢复数据都经过同一个子存储节点,则DCS 存储节点的数据存储复杂度HTCDCS为:
3 实验研究
选用文中提出的基于循环神经网络的多核处理器层次化存储技术与传统的基于FPGA 和FLASH 的多核处理器层次化存储技术及基于Hadoop 云存储架构的多核处理器层次化存储技术进行实验对比。
参考多核处理器的相关配置需求,设置的实验参数如表1 所示。

表1 实验参数
根据上述实验参数,选用文中提出的存储技术和传统存储技术进行数据存储,为保证实验结果的权威性和可靠性,以数据存储的同步性和抗冗余度为三种存储技术的评价指标,对三种存储技术进行综合评价。其中数据存储抗冗余度是指存储技术抗数据重复的抗重复度,数据存储抗冗余度T的计算公式如下:
式中,w为相邻数据属性值的累计变化次数;x为数据的存储行数;y为数据的存储列数。
数据存储同步性的实验结果如图4 所示。
从图4 可以看出,基于FPGA 和FLASH 技术的最高同步误差为0.18,平均同步误差为0.13,数据存储同步性较为不理想。基于Hadoop 云存储架构的最高同步误差为0.23,平均同步误差为0.17,数据存储同步性差,不适用于多核处理器的设计中。相较于之下,本文提出的基于循环神经网络的存储技术,同步误差普遍低于0.1,平均同步误差为0.04。
对三种存储技术的存储同步性进行验证后,针对三种存储技术的数据存储抗冗余度进行实验对比,实验结果如图5 所示。

图5 数据存储抗冗余度对比结果
从图5 可以看出,随着重复数据数量的不断增加,三种存储技术的抗冗余度不断下降,但下降程度各不相同。基于FPGA 和FLASH 的平均抗冗余度为76%,基于Hadoop 云存储架构的平均抗冗余度为84%,而文中提出的基于循环神经网络的存储技术,最低抗冗余效果为89%,平均抗冗余度为96%,整体抗冗余度高。原因在于,文中提出的存储算法以循环神经网络为基础进行并行多核处理器快速卷积运算,通过数据布局、转换以及矩阵乘,能够过滤大部分冗余数据,避免绝大部分的数据重复存储。
4 结束语
随着处理器数据存储数量的不断增加以及应用环境的逐渐复杂,处理器的存储需求逐渐升高,传统的多核处理器层次化存储技术虽然搭载便捷、存储量大,但处理同步性差、抗冗余度低,为此,为满足多核处理器的存储需求,并解决传统存储技术出现的问题,文中提出了基于循环神经网络的多核处理器层次化存储技术,实现对数据的多层次稳定存储。实验结果表明,文中提出的存储技术同步性好、抗冗余度高,能够对数据进行稳定且安全的存储,使处理器的数据处理更加高效、可靠。
猜你喜欢
廊坊师范学院学报(自然科学版)(2021年2期)2021-09-10
电子制作(2018年16期)2018-09-26
电子测试(2018年6期)2018-05-09
山西建筑(2017年29期)2017-11-15
黑龙江交通科技(2017年7期)2017-09-20
电子测试(2017年23期)2017-04-04
黑龙江交通科技(2017年10期)2017-03-01
山东工业技术(2016年15期)2016-12-01
现代工业经济和信息化(2016年4期)2016-05-17
黑龙江交通科技(2016年11期)2016-03-11
