
基于transformer 的维汉神经机器翻译
2023-11-21 14:12杜志昊
电子设计工程 2023年22期
杜志昊
(1.武汉邮电科学研究院,湖北武汉 430070;2.南京烽火天地通信科技有限公司,江苏 南京 210019)
机器翻译是自然语言处理领域的一个重要研究方向,具体是指通过计算机将源语言句子翻译成与之语义等价的目标语言句子的过程[1]。第一台现代电子计算机ENIAC 诞生不久后,美国科学家韦弗在《翻译》备忘录中正式提出机器翻译的基本思想[2]。机器翻译的发展主要可以分为三个阶段。第一阶段:规则时期,其基本方法是利用手写大量的语法解析规则对源语言进行解析,然后用语法转写规则生成目标语言文法,再通过生成规则产生最终文本。第二阶段:统计机器学习时期,Peter F.Brown 提出了基于词对齐的翻译模型,标志着现代统计机器翻译方法的诞生[3]。Franz Och 在2003 年的两篇文章中分别提出了对数线性模型及其权重训练方法以及基于短语的翻译模型和最小错误率训练方法[4]。这两篇文章的发表标志着统计机器翻译的真正崛起。第三阶段:神经网络机器翻译时期,Nal Kalchbrenner 和Phil Blunsom 提出了一种用于机器翻译的新型端到端编码器-解码器结构[5-6],他们的研究成果标志着神经机器翻译的诞生。
1 相关工作
1.1 seq2seq结构
seq2seq 框架主要由编码器和解码器两部分组成,在神经机器翻译任务中将编码器和解码器进行联合训练,进而提高模型的性能和泛化能力。
seq2seq 具体包含词嵌入层、编码器、中间向量和解码器四部分。词嵌入层一般有两个,一个用于将源文本转换为词向量,另一个则是将词向量转换为目标语言文本;编码器则能够将词嵌入层所生成的词向量进行改变,使得该向量能够更好地对源语言信息进行表征;中间向量实际上是包含语义信息的上下文向量,其将作为解码器的输入向量;解码器能将输入的上下文向量转化为目标语言的文本。在seq2seq 框架中的编码器和解码器要尽可能的不同,以此来增加模型的参数量,增强模型的性能,提高最终翻译的质量[7]。
1.2 自注意力机制
为了解决seq2seq 机器翻译模型中对长文本处理效果不佳的问题,Bahdanau[8]等人于2014 年借鉴了在图像处理中使用的注意力机制,首次将注意力机制应用在自然语言处理方向上。自注意力机制提出后,加入注意力机制的seq2seq 模型在各个任务上都有了提升,2017 年Google 团队提出了transformer模型,用全注意力机制的结构带来了LSTM,在翻译任务上取得了更好的成绩[9-10]。该模型引入了自注意力机制(self-attention)对输入序列进行编码,图1为self-attention 结构图。
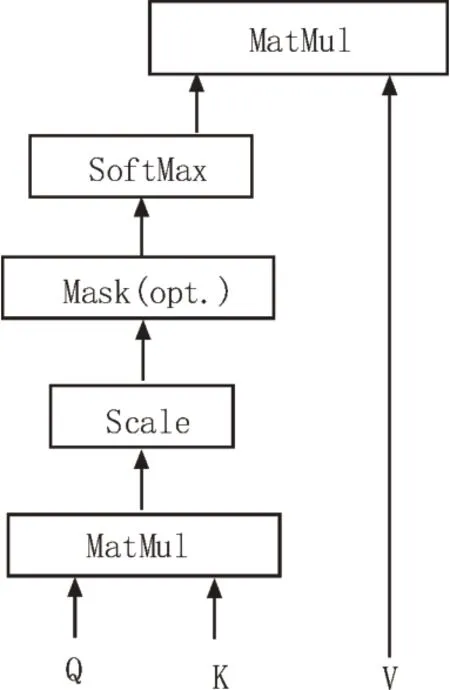
图1 self-attention结构

图2 循环机制结构图
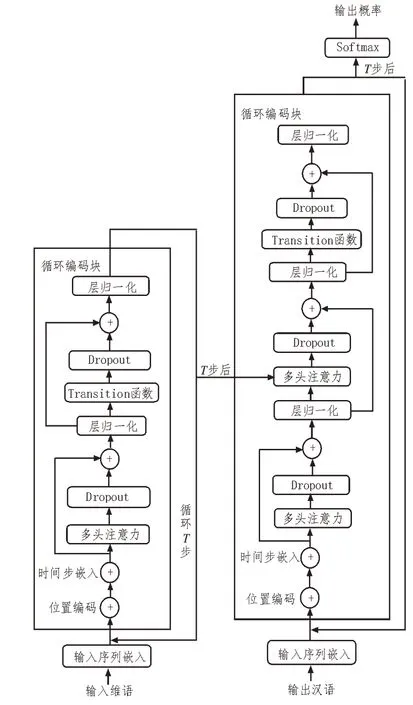
图3 维汉翻译模型架构图
2 模型的构建
2.1 基于transformer的机器翻译模型
transformer 只考虑了特征的位置信息,而该文加入了时间维度,每循环一次就会做一次位置坐标的嵌入,Embedding 公式为:
2.2 输出结果优化
在机器翻译任务中,需要利用语言模型来判断模型输出句子的优劣。由于机器翻译模型不会考虑所有可能的输出,只保留最可能的k个解,同时模型输出的长度又是可预测的,因此,利用beam search 优化算法得到最优的输出结果[11]。得到输出最优结果的计算过程为:
2.3 惩罚短句和惩罚重复
由条件概率公式可知,beam search 倾向于选择长度最短的句子,同时当多个小于1 的条件概率相乘时容易出现数值下溢及k参数自适应等问题。因此,该文加入惩罚短句[12]来缓解这一问题。
由于注意力机制的覆盖会导致过度翻译或翻译不全的问题,针对这一问题该文加入了惩罚重复项来防止一些token 获得过多的attention[13],这样便可以得到一个新的beam search 得分。
惩罚短句和惩罚重复的具体计算方法如下,其中α用于惩罚短句,β用于惩罚重复:
3 数据处理
3.1 数据增强
神经机器翻译很大程度上需要大规模的平行语料,而对于低资源语料获取平行语料却十分困难[14],为了获得更多的平行语料进行训练,需对数据进行数据增强。目前在机器翻译领域最主要的数据增强方法有两种,分别是词汇替换和回译[9]。该文利用回译的方法进行数据增强来扩充平行语料,其主要思想是首先训练一个反向翻译模型,即汉语到维语的模型来生成伪平行语料,并将得到的伪平行语料应用于维语到汉语的翻译模型。图4 为回译流程图。

图4 回译流程图
3.2 BPE编码
在训练模型前,构建词表是极其重要的一项工作,传统方法一般用训练语料中所有出现过的单词来构建词表或基于单个字符来构建词表。如果采用基于训练语料的方法,则很难处理未登录词,且若训练语料中的单词数目很多会导致构建的词表庞大,进而影响训练速率。若采用字符构建词表,由于粒度太细,则会丢失很多语义信息。而BPE 算法通过将词划分为子词的方式,分词的粒度在字符和单词之间,这样既减小了词表的大小又能尽可能得到语义信息[15]。
3.3 输出检测与纠正
在模型训练完成得到模型输出后,对测试集数据进行分析,发现部分维语到汉语使用音译的方法,可能存在谐音字词、混淆音字词以及形似字错误等情况。为了检测这些类型的错误,该文从字粒度的角度构建语言模型来计算困惑度,对输出的结果进行评判,检测某字的似然概率值是否低于句子的文本平均值,若低于均值则判定该字可能是错别字[16]。通过错误检测定位所有疑似错误后,选取所有疑似有误的候选词,使用候选词进行替换,基于语言模型得到类似翻译模型的候选排序结果,得到最优纠正词。但可能由于出现该问题的数据占比较少,对结果的优化及最终BLUE 结果提升并不明显。输出文本优化流程如图5 所示。

图5 输出文本优化流程图
4 实验设计与分析
4.1 实验环境和评价指标
该文实验是在Linux 系统下进行的,CPU 为Intel Core i5-12400F 4.4 GHz×12,显卡为四张GeForce GTX 2080Ti,实验是在GPU环境中运行的。编程环境为Python3.6,深度学习开发工具框架为Pytorch1.10.0版本。
为了能够及时有效地评价维汉翻译模型,在综合考虑已有的机器翻译性能评价方法后,该文选用应用最为广泛的BLEU(Bilingual Evaluation Understudy)评价方法作为评价指标。具体算法为:
数加权和。
4.2 数据增强实验
实验的训练语料有25 万对平行语料和20 万条汉语单语语料,回译数据增强阶段使用了开源的fairseq,以transformer 为基线模型进行测评,同时还对比了是否使用BPE 编码的结果。transformer 模型参数中设置句子最大长度为50 词,词向量的维度为512 维,训练时的batch_size 大小为32。网络层数为6 层,多头注意力机制设置为8,dropout 为0.1。训练时选用Adam 优化算法[17],学习率初始值为2.0,模型迭代步数为8 000 步。
实验结果如表1 所示。从表1 可以看出回译的数据增强方式和加入BPE 编码的结果均优于基线模型,利用回译模型BLUE 增加了0.59%,引入BPE 编码则增加约2.21%,同时使用BPE 编码和数据增强能够提升约5.4%。

表1 不同数据处理方式BLEU大小
4.3 改进的transformer实验结果分析
改进的transformer模型参数中设置同transformer基线模型相同。同时还选用了RNN、CNN+attention与transfomer 基线模型和改进的transformer 模型进行对比实验,实验结果如表2 所示,可以很明显看出基于transformer 模型的BLUE 值相较于CNN+attention和RNN 模型有着明显的提升,同时该文提出的改进的transformer 模型的BLUE 也提升了0.93%。
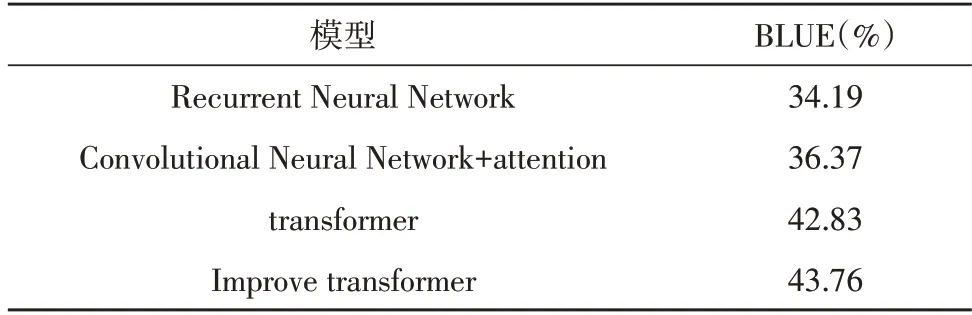
表2 测试集BLEU对比结果
4.4 实验结果展示
利用测试集在已训练好的改进transformer 模型上实际翻译效果的对比如表3 所示。

表3 翻译效果展示
5 结论
该文利用改进的transformer 维汉翻译模型,在transformer 的基础上引入了循环机制和时间编码,使得除了第一次是以原始信息作为输入,之后都是由前一个时间步的输出作为后一个的输入,并在输出端对模型的输出结果利用语言模型进行纠正。同时还引入了回译和BPE 编码对数据进行预处理。根据实验结果显示,加入数据预处理后,transformer 模型有了明显的提升。将transformer 维汉翻译模型对比改进的transformer 维汉翻译模型,效果又有了明显的提升,BLUE 值在transformer 的基础上提升0.93%。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
英语世界(2021年13期)2021-01-12
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
国家图书馆学刊(2016年2期)2016-10-09
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
