
基于联邦学习的电力施工场景分类∗
2023-11-21 06:18:00公凡奎张俊岭牛爱梅王志鹏
计算机与数字工程 2023年8期
公凡奎 张俊岭 尹 朋 高 明 刘 猛 牛爱梅 王志鹏
(1.山东鲁软数字科技有限公司 济南 250001)(2.中国石油大学(华东) 青岛 266555)
1 引言
电力在日常生活中发挥着越来越重要的作用,电力系统的作业安全同时也受到了更多的关注。电力的安全生产[1]不仅是电力工业发展的前提和基础,也是电力企业发会社会效益和提高经济效益的保证。近年来,随着人工智能突飞猛进的发展,作为电力行业关键一环的变电站的安全生产也在追寻着智能化的监管[2],其不仅可以节省大量的人力物力,同时也可以减少因为监管不力导致的不安全事件的发生。
变电站存在着诸多场景,场景识别是进行智能监管的前提,所以对于电力施工场景的识别就尤为关键。由于变电站的特殊性,数据量往往达不到建立深度学习模型的需求,并且考虑到数据安全的因素,无法将数据进行长距离的运输,限制了模型的性能。为了在保证数据隐私的前提下得到具有高准确率的模型,现将联邦学习[3]与图像分类算法结合,提出了一种基于联邦学习的电力施工场景分类方法,利用联邦学习保护数据隐私的特点以及深度学习模型的高准确率的特点,充分利用来自各方的数据训练出一个可靠可信的场景分类模型,实现电力施工场景的智能化监管。
2 相关工作
2.1 图像分类
图像分类是计算机视觉三大任务之一,它的任务就是给定一张图像可以识别出它的类别。近年来,深度学习在图像分类任务上占据着统治的地位。2012 年,Alex Krizhevsky 提出了AlexNet[4]在ImageNet的比赛中以绝对优势获得冠军,使得卷积神经网络再度进入人们的视野。此后,各种网络模型如雨后春笋般不断涌入,2014年提出的VggNet[5],将卷积网络的深度提高到了16 层和19 层,并使用了3×3 的卷积核,显著提升了模型的准确率。其模型结构如图1所示。

图1 Vgg16 网络结构
谷歌也在2014 年提出GoogleNet[6],引入了Inception模块,使得网络在更深层具有更强的表达能力,目前Google 已经从V1 版本更新到了V4 版本,也广泛的与其他网络结构结合。为了解决随着网络深度加深模型退化的问题,何凯明等人在2015年提出了ResNet[7],将提高了模型效果的情况下,将网络的深度加深到了150 层。ResNet 的创新在于其提出了残差模块,其在网络之间添加了捷径(shortcuts),使得网络可以学习一个恒等函数,其两种残差模块的结构如图2。
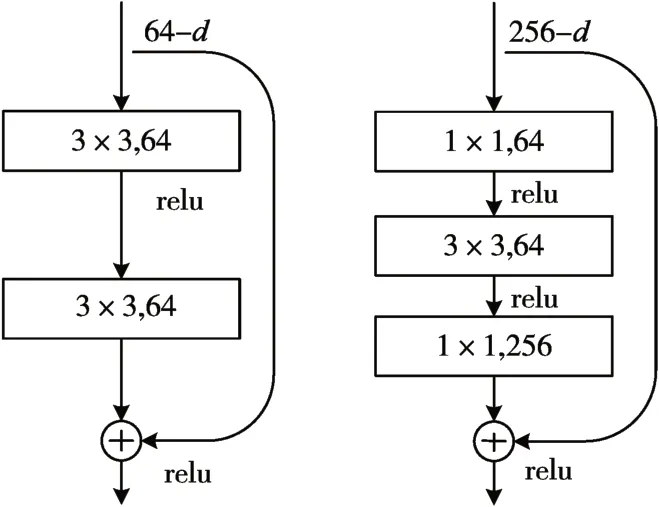
图2 ResNet两种残差结构
ResNet是图像分类史上最经典的网络之一,后来许多学者在ResNet 的基础上进行改进提升,包括Res2net[8]ResNext[9]等,何凯明团队还在2019 年通过调整网络深度、宽度、图像分辨率提出了Efficientnet[10],促进了图像分类的发展。
2.2 联邦学习
联邦学习最早是在2016 年由谷歌提出[11],可以让手机终端用户在本地更新输入法推荐模型。它本质上一种分布式的机器学习技术,但是它只收集模型而并不集中数据,这样就可以在保证数据隐私安全的基础上,实现利用各方的数据共同建模,提升模型的性能。联邦学习的多个节点通过Server-Client 模式建立通信,中心节点作为Server 端负责融合模型以及分发模型,Client 端负责利用本地数据训练模型并上传模型。联邦学习根据数据以及用户的重叠程度分为横向联邦学习、纵向联邦学习以及联邦迁移学习[12~13]。当用户重叠部分较少而数据特征重叠较多时成为横向联邦学习,当用户重叠较多而数据集特征重叠较少时成为纵向联邦学习[14],而当用户和数据特征都重复较少时成为联邦迁移学习[15]。其中横向联邦学习的示意图如图3所示。

图3 横向联邦示意图
3 动态权重算法
联邦学习需要收集各个客户节点的本地模型进行融合,通常所用的融合策略为平均融合,即将所有模型的参数求得平均值作为中心节点模型的参数值。很显然,联邦学习各个客户节点的数据量存在一定的差异,大数据集训练出来的模型与小数据集得到的模型进行平均融合很有可能使大模型的效率下降,为了解决这一问题,本文提出了一种基于节点数据量的动态权重算法。
首先在训练开始时,各个客户节点需要向中心节点上传数据量,中心节点根据数据量依据式(1)为每个客户节点计算权重。如果该权重大于平均融合的权重,该节点的权重就会在未来的训练过程中线性减小至平均融合的权重大小;如果该计算得到的权重小于平均融合的权重,则该节点的权重会线性增大最终达到平均融合时的权重。该算法可以在联邦学习初期利用加权融合的方法充分利用大数据集收敛快的特点,同时在联邦学习的后期,各个客户节点的融合权重变为平均融合时的权重即客户节点总数分之一,所以可以发挥联邦学习充分利用各客户节点数据的特性,得到具有高准确率的模型。
其中,Ni为客户节点i的数据量,Wi为节点i模型融合时候的初始权值,n为此次联邦学习的客户节点数量。
4 实验及结果分析
4.1 实验配置
本实验共收集变电站不同场景数据2142 张,然后将数据分为训练集1809 张以及测试集333张。其中变电站的场景有五个,分别为敞开式设备,高空输电,开关柜设备,主变压器以及组合电器,其数据分布如表1所示。
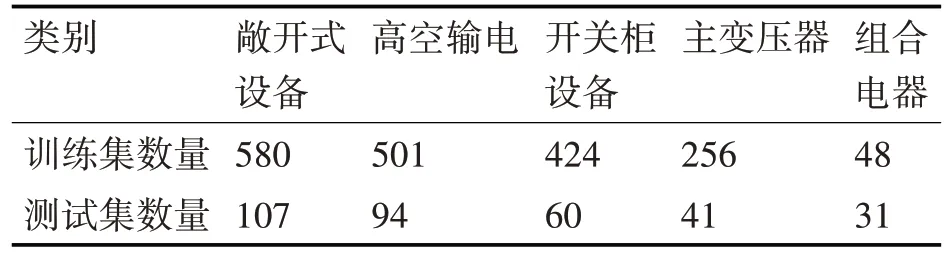
表1 数据分布
本实验选用GFL联邦学习框架进行,使用了三个客户节点以及一个中心节点,各个节点的实验配置如表2所示。
本次实验的batch_size统一设定为32,epoch设定为30,学习率为0.001,并且每10 个epoch 进行一次0.1 倍的衰减,联邦学习一共进行上传融合30次,每个子节点训练1个epoch后上传模型。
4.2 联邦学习有效性
本实验将收集的所有训练集平均分成三份分配到三个客户节点用作训练集,然后将测试集分配到所有节点包括中心节点。实验选用准确率作为评价指标。实验数据的分布情况如表3所示。
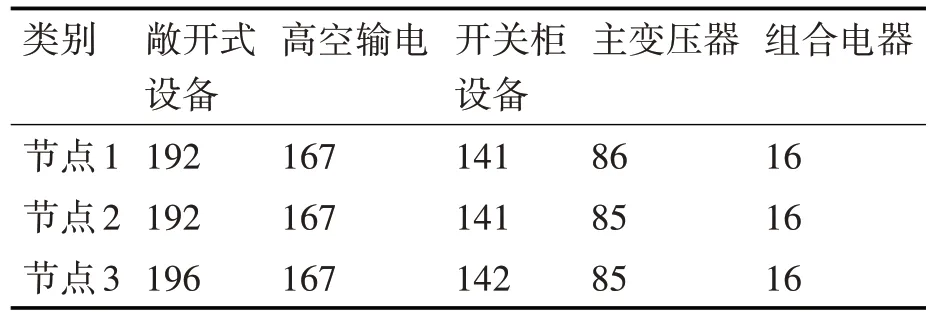
表3 联邦学习实验各客户节点数据分布
首先,三个客户几点利用本地节点的数据独立训练出一个模型并测试其准确率,然后每个客户节点利用本地数据参与到联邦学习中,并在中心节点测试平均融合后的准确率。实验选用了两个比较常用的分类网络,分别是Vgg16 网络和ResNet101网络,实验结果如图4所示。
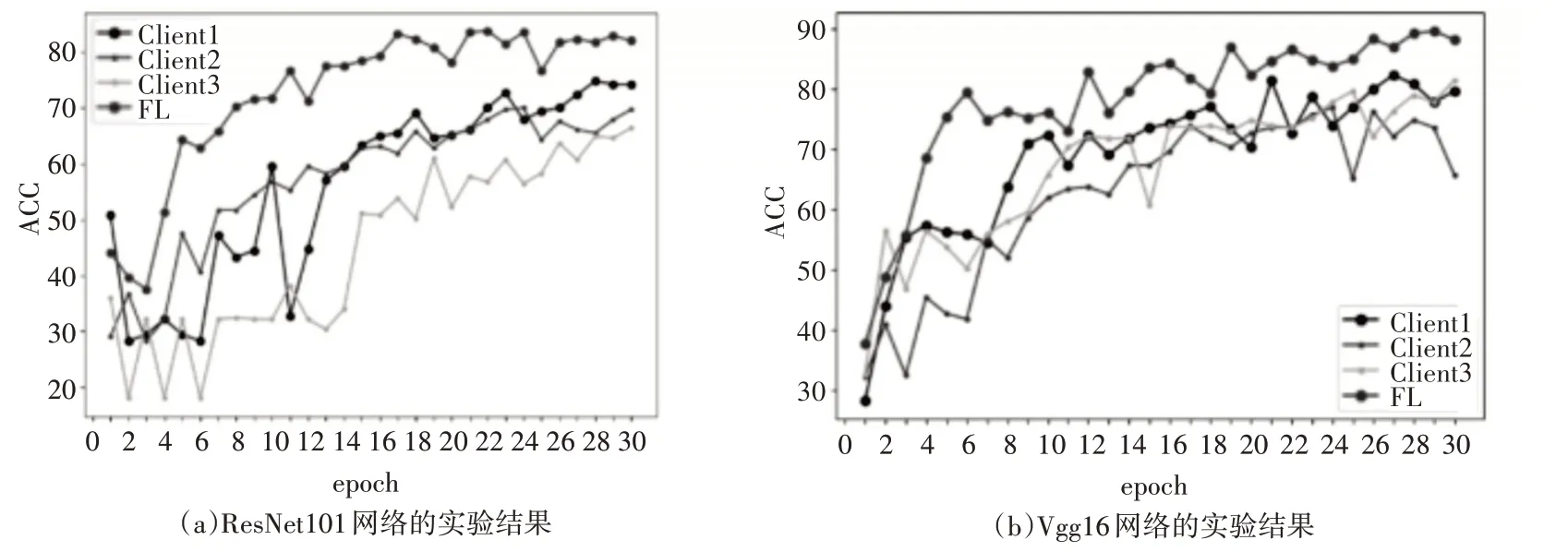
图4 联邦学习实验结果
从实验结果可以看出,无论是ResNet101 或者Vgg16 网络,联邦学习都可以有效地提升模型的准确率。对于ResNet101 网络来说,客户节点得到的模型准确率最高为62.18%,而联邦学习中心节点模型的准确率最高为82.88%;而Vgg16网络的两项数据分别为82.28%和89.58%。由于联邦学习可以在不中心化数据的情况下有效的扩充数据量,所以准确率的提升是符合预期的。实验中我们也发现,无论是中心节点或者本地节点,Vgg16 网络的表现都要优于ResNet101 网络,这也证明了模型的效果并不直接相关于网络的深度。
为了进一步验证联邦学习在电力场景分类数据上的有效性,我们考虑了另外一种比较极端的数据分布情况,即每个客户节点只存在其中某几种种类的数据,这种数据分布成为非独立同分布,具体的数据分配如表4所示。
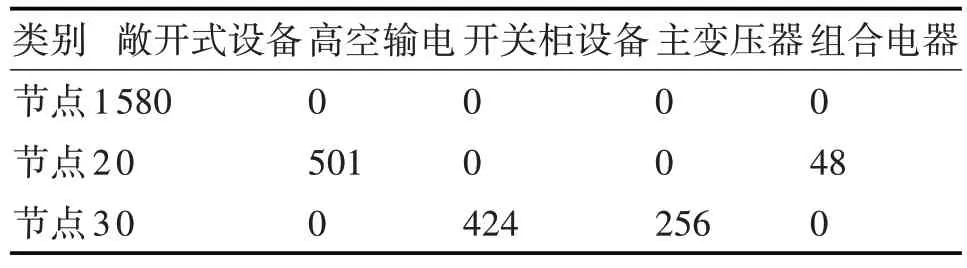
表4 非独立同分布数据分布
同样,我们首先在在各个客户节点训练本地数据得到本地模型,然后进行联邦学习的实验,得到的结果如图5所示。
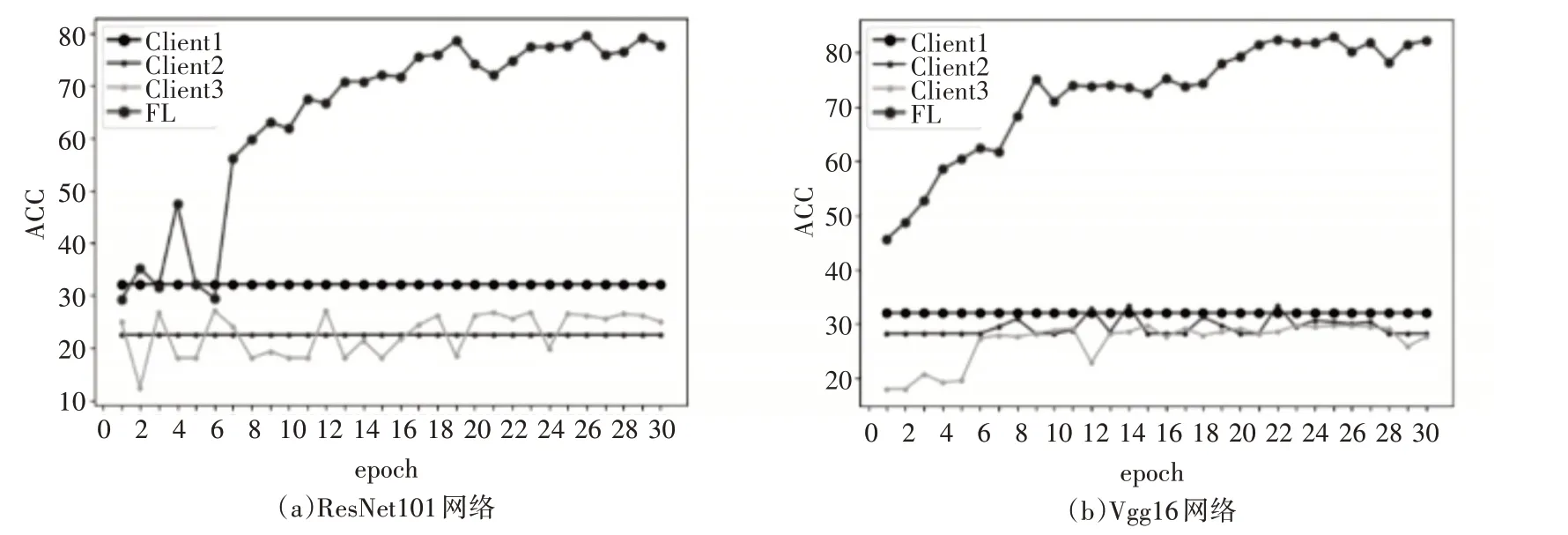
图5 非独立同分布实验结果
从实验结果可以看出,联邦学习可以很好地适应非独立同分布的数据分布,并且可以有效的提升模型的准确率。当某一节点只存在某几种类型的数据的时候,得到的模型在整体测试集上的表现较差,经过联邦学习将模型平均融合之后,两种实验网络都可以将准确率从32%提升至80%以上。
以上两组实验有效地验证了联邦学习在电力场景分类问题上的有效性。由于联邦学习中心节点的模型最终要下发到客户节点供客户节点来使用,所以有效地提升了客户节点的模型效果,同时保护了数据隐私。
4.3 动态权重实验
本部分将通过实验验证提出的动态权重算法的有效性。上述四个实验均采用了平均融合算法,本实验将平均融合算法替换成动态权重算法,将实验结果与平均融合联邦学习的结果进行对比,实验结果如图6所示。
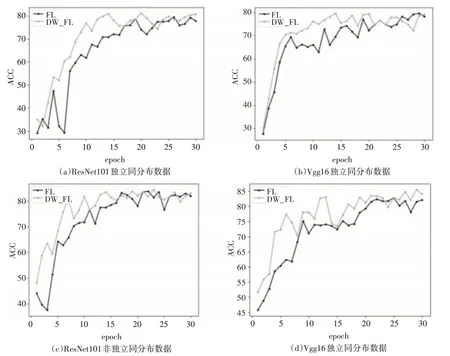
图6 动态权重实验结果
从实验结果可以看出来,本文提出的动态权重融合算法相较于平均融合算法可以提升准确率0.5~1.5%。除此之外,该算法可以大幅度加快模型的拟合速度。采用平均融合的普通联邦学习过程达到最高的准确率时的epoch 值在18~25 之间,而采用动态权重融合算法之后,可以将该值提前至8~15之间。
5 结语
本文使用深度学习的方法对电力施工场景进行分类,为智能化安全管控提供了宝贵的支撑。为了在保护施工现场场景不外露的前提下增加数据量和提升模型的准确率,使用了联邦学习,在不收集数据的情况下综合使用来自各方的数据。同时,我们结合客户节点的数据量,改进了平均融合算法提出了动态权重算法。实验证明,联邦学习在不中心化数据的情况下,可以有效地提升各个节点模型的准确率,提出的动态权重算法可以加快模型的拟合速度,并提升模型的准确率。
本文使用了独立同分布和非独立同分布两种数据分布,但现实中数据的分布多种多样,下一步将验证各种不同的数据分布,并进一步对融合算法进行研究。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
家庭影院技术(2020年10期)2020-12-14 07:54:16
当代陕西(2020年17期)2020-10-28 08:18:18
家庭影院技术(2019年7期)2019-08-27 02:42:06
中国交通信息化(2018年5期)2018-08-21 03:37:40
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
河南科技(2014年15期)2014-02-27 14:12:51
