
融合Albert模型的珍稀濒危植物知识图谱的构建
2023-11-18 07:30:16田梦晖陈明席晓桃
湖南农业大学学报(自然科学版) 2023年5期
田梦晖,陈明*,席晓桃
融合Albert模型的珍稀濒危植物知识图谱的构建
田梦晖1,2,陈明1,2*,席晓桃1,2
(1.上海海洋大学信息学院,上海 201306;2.农业农村部渔业信息重点实验室,上海 201306)
针对珍稀濒危植物形态特征、分类等级、濒危系数、保护措施等知识不明确的问题,设计了文本融合轻量级双向转换编码表示模型(Albert)的知识抽取模型框架,实现批量抽取珍稀濒危植物知识,从而构建珍稀濒危植物知识图谱:1) 在现存一般性植物本体的基础上,采用自顶向下的方式构建珍稀濒危植物本体,得到5个体系,即物种分类体系、生长形态特征体系、命名体系、保护现状体系和生态习性体系;2) 采取Albert预训练模型来增强下游任务模型输入向量的珍稀濒危植物属性描述文本语义的表征能力;3) 利用BiLSTM–CRF模型和BiGRU–Attention模型分别实现命名实体识别和关系抽取。在珍稀濒危植物数据测试集上对模型的有效性进行验证,结果表明,命名实体识别模型和关系抽取模型的召回率和准确率的调和平均值(1)值分别达到98.07%和93.76%,将得到的大量的实体和关系所形成的三元组存储在图数据库Neo4j中,完成珍稀濒危植物知识图谱的可视化展示。
珍稀濒危植物;Albert模型;知识图谱;本体;命名实体识别;关系抽取
知识图谱在植物领域的应用已经取得许多积极成果。陈亚东等[1]通过对8类苹果产业资源进行整合和分析,以树形结构呈现知识逻辑体系,利用知识抽取、知识融合等技术构建了苹果产业领域的轻量级知识图谱。于合龙等[2]结合自顶向下和自底向上2种方式构建水稻病虫害本体,分别采用CBOW–BiLSTM–CRF模型和机器学习算法实现知识实体抽取、关系分类,将获取的三元组存储在Neo4j,形成水稻病虫害知识图谱。张桥英等[3]通过查阅资料、实地勘察自然环境、踏勘法结合植物群落样方调查、目测等方法,分析探讨大巴山国家地质公园的67种珍稀濒危维管植物和10个分布区类型;王双蕾等[4]利用Citespace和HistCite工具,基于1970年至2019年2个核心数据库的文献资源,构建重点保护珍稀濒危植物沙冬青的资源研究可视化图谱,通过对高频关键词和突现词等统计单位的分析理清研究脉络,提供科学参考。
笔者设计了一种管道式植物领域知识抽取模型框架,利用融合了Albert预训练模型[5]的BiLSTM– CRF和BiGRU–Attention分别进行命名实体识别和关系抽取任务,利用此框架实现大批量地从现存的珍稀濒危植物文本中自动抽取知识,构建知识图谱,以期为后续基于此知识图谱实现珍稀濒危植物的智能应用提供技术支撑。
1 珍稀濒危植物本体的构建
重点针对珍稀濒危植物概念抽取对应知识,复用现存的一般性植物领域本体的研究[6–7],以《中国植物志》电子版[8]、《中国珍稀濒危植物图鉴》[9]和中国珍稀濒危植物信息系统[10]提供的信息为主要数据来源,百度百科为辅助数据来源,加上对恩格勒植物分类体系[11]和秦仁昌分类系统[12]的参考,对植物领域本体共性概念进行扩展和完善;在遇到关于裸子植物分类体系的分歧时,采取百度百科的信息为数据支撑。采取自顶向下[13]的方式,定义珍稀濒危植物本体中的类、层级、概念之间的关系、约束和条件等。
将珍稀濒危植物本体分为5个体系(图1),即物种分类体系、生长形态特征体系、命名体系、保护现状体系和生态习性体系。其中物种分类体系指按照植物物种间的亲缘关系进行的物种分类,按照界、门、纲、目、属、种的层级结构进行分类;生长形态特征体系主要是对植物生长形态特征概念的描述;命名体系主要是针对植物的命名概念的描述;保护现状体系是对植物的各种濒危系数的概念描述;生态习性体系主要囊括了对植物生长环境、物候期、地理分布等概念的描述。
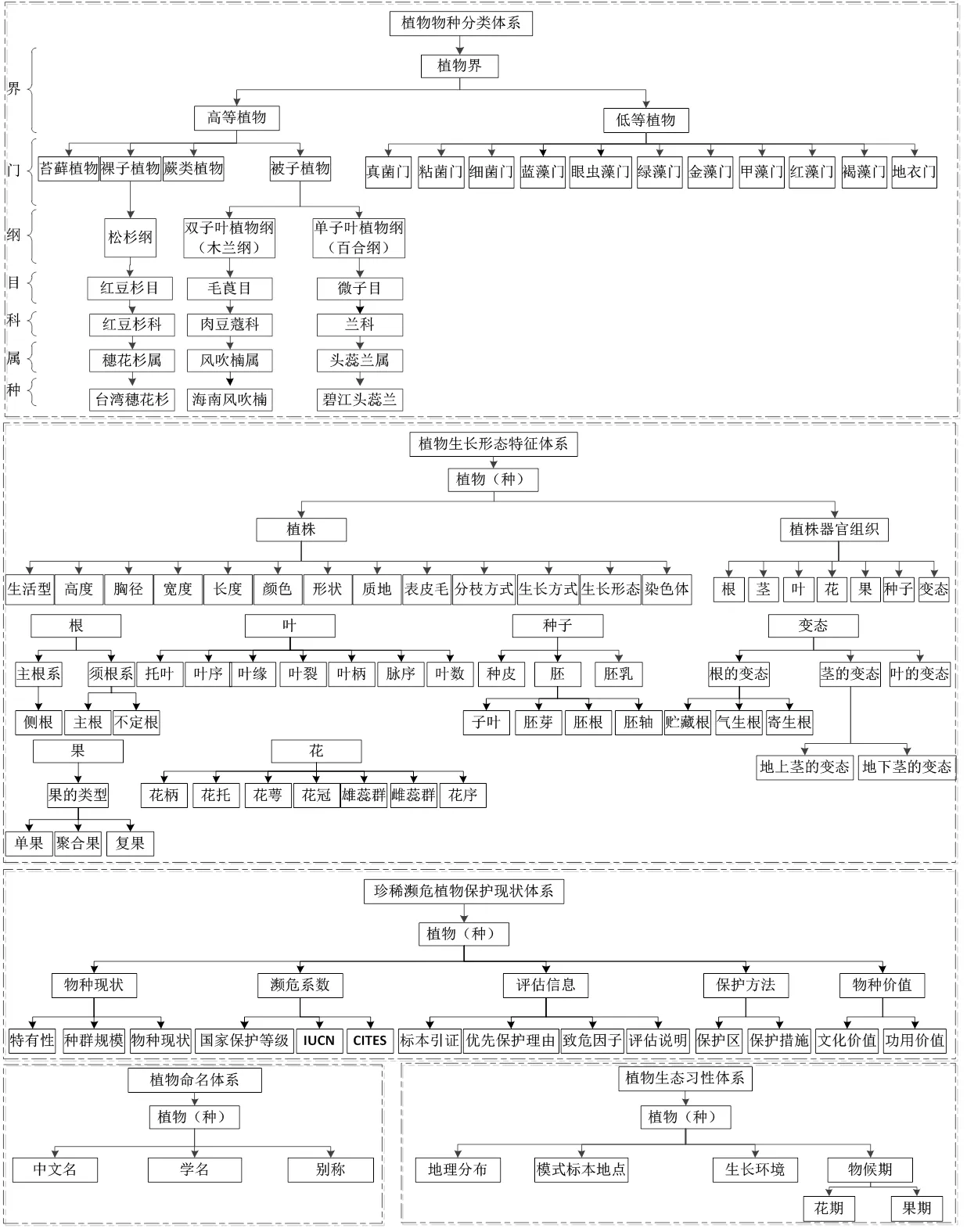
图1 珍稀濒危植物本体各体系的架构
表1和表2分别展示了基于本体的珍稀濒危植物数据中实体关系和实体属性的映射。表1主要描述本体概念层中实体关系三元组实例,包括植物的别称、植物分类、濒危系数等关系,例如〈窄果脆兰,科类,兰科〉这个三元组表达的语义信息是“窄果脆兰是属于兰科的植物”。表2主要描述实体的属性关系,包括植物的生活型、高度、生长形态、共用价值、致危因子、保护措施等。

表1 珍稀濒危植物本体概念层的实体关系

表2 珍稀濒危植物本体概念层的实体属性
2 珍稀濒危植物本体知识抽取模型的建立
2.1 知识抽取任务
为了实现珍稀濒危植物的知识抽取,选取了预训练模型和神经网络模型结合的方式实现知识抽取任务[14]。以《中国珍稀濒危植物图鉴》珍稀濒危植物海南风吹楠()为例,利用人工标注提取的三元组如图2所示。

图2 海南风吹楠描述文本中待分类实体和关系
从图2可以看出,每一段文本都只针对同一种植物进行描述。而知识抽取模型最终要实现大批量从原始文本数据中提取符合本体规则的三元组实例,因此设计一种管道式[15]珍稀濒危植物领域知识抽取模型流程框架(图3),以便正确识别实体和关系抽取,从而获得三元组。2个子任务在句子级别上独立训练,首先,通过命名实体识别模型,在Albert模型和BiLSTM–CRF模型[16]的基础上对抽取的实体进行实体预测,再通过关系抽取模型,通过Albert模型和BiGRU–Attention模型[17]的处理对实体的关系进行预测,获得三元组。
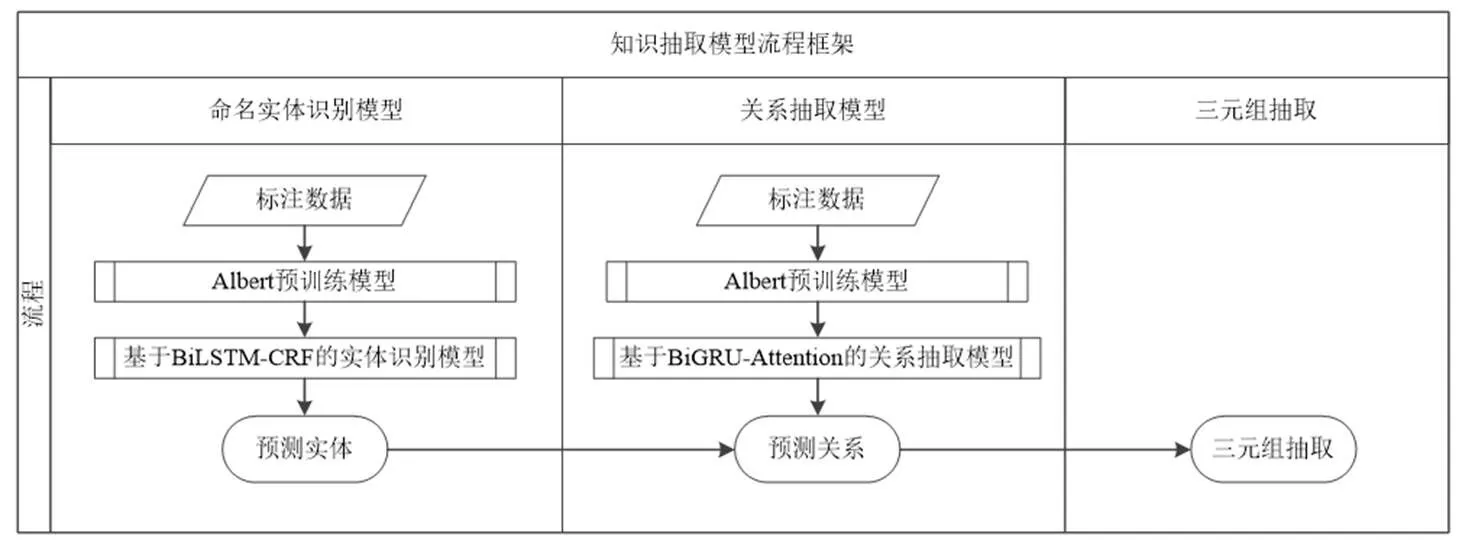
图3 管道式知识抽取模型框架
2.2 命名实体识别模型
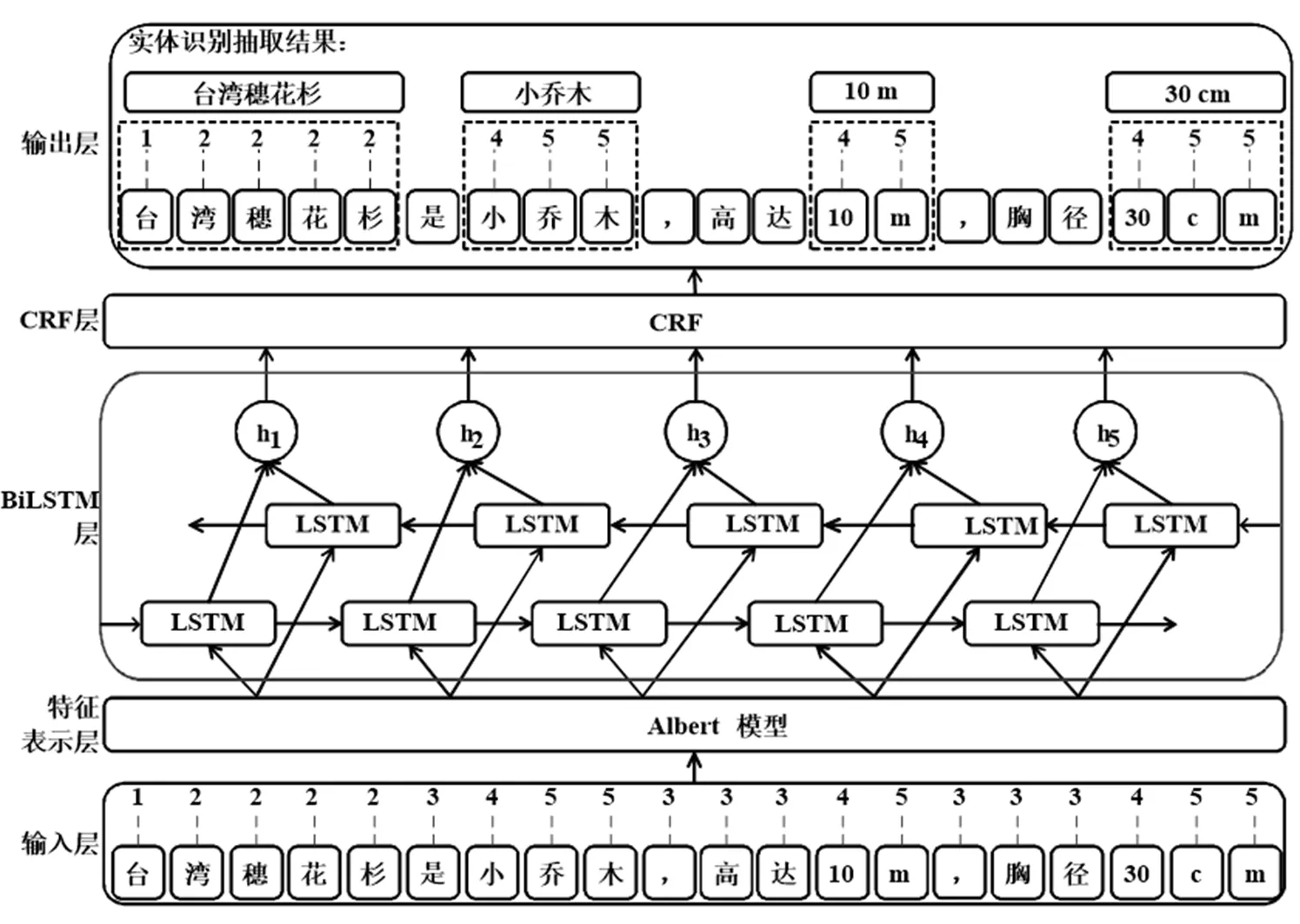
命名实体识别是构建濒危珍稀植物知识图谱的基础,模型需从非结构化的植物描述中识别出符合本体概念层的实体,实体识别模型结构如图4所示。
针对收集到的数据,首先利用BIO标注模式[18],采用编码方式对实体识别训练数据进行自动批量预处理,再通过Albert模型进行文本预训练,利用transformer中encoder的解码特性,学习句子的特征信息,从而获取数据的向量表示用于下游模型的训练任务,最后利用BiLSTM层对预训练模型输出得到的向量作进一步训练,并且经过全连接层的处理,获得实体标签的分数排名分布,送入CRF层,通过CRF的修正预测,最终获得实体标签最大得分的标注序列。
由于选择BIO序列标注方法,实体标签类别有5个,分别为B–SUBJ(1)、I–SUBJ(2)、O(3)、B–OBJ(4)、I–OBJ(5),通过判断实体标签类型,识别多个类别的实体。
2.3 关系抽取模型
设计的关系抽取任务模型如图4所示,自底向上分为输入层、Albert层、BiGRU层、注意力层、全连接层和输出层。设计训练数据时,考虑到1条语句中存在1个subject实体与多个object实体相交互的情况,将存在掩码的语句作为1条训练数据输入到Albert模型,以获得特征向量传输到BiGRU层进行上下文信息语义理解,最终结合注意力机制层进一步实现对局部信息的抽取,进行词级别权重分配;权重高代表对关系抽取的影响较大,最后全连接层的加入进一步提升关系预测的准确率,从而实现对实体之间关系的分类。
2.4 模型训练与评价
2.4.1数据源
针对数据来源,首先利用Python脚本,遵循http协议,通过解析网页结构请求网站并且获取相应的网页url,其次采用Xpath和lxml网页解析工具按照设计好的数据规则进行批量爬取,同时将数据以Json的格式存储在MongoDB数据库当中。最终获取的标注数据总计11 688条珍稀濒危植物物种文本。以“猪血木”为例,收集到的文本数据有:常绿乔木,高约15~20 m,胸径约1.5 m,全株除顶芽和萼片外均无毛;……星散分布于广东阳春八甲村及广西平南思旺村和巴马县灵禄乡;生于海拔100~400 m的低丘疏林中或村旁林缘,数量极少;根据实地调查,目前仅在广东阳春八甲村村旁丘陵地田边及八甲小学校园中尚保存有3株大树,其他各地似乎均已灭绝。
另外在其结构化数据中,“猪血木”的拉丁学名、科名、国家保护级别、CITES、IUCN和特有性的实体分别为、山茶科、Ⅰ级、Ⅱ、CR、中国特有。
2.4.2数据标注及评价指标
在模型的训练过程中,按照训练需求将数据设计为特定三元组格式,得到最终的训练数据。例如原文本句子“text”:“海南韶子是常绿乔木,高5~20 m”。标注的三元组训练数据格式为:“spo_list”: [{“predicate”: “生活型”, “object_type”: “生活型”, “subject_type”: “中文名”, “object”: “常绿乔木”, “subject”: “海南韶子”},{“predicate”: “高度”, “object_type”: “高度”, “subject_type”: “中文名”, “object”: “5~20 m”, “subject”: “海南韶子”}]。为了避免训练过程出现过拟合现象,将语料按照7∶3的比例将其划分为训练集和测试集,主要对珍稀濒危植物属性描述文本中28类关系(表3)进行分类提取。
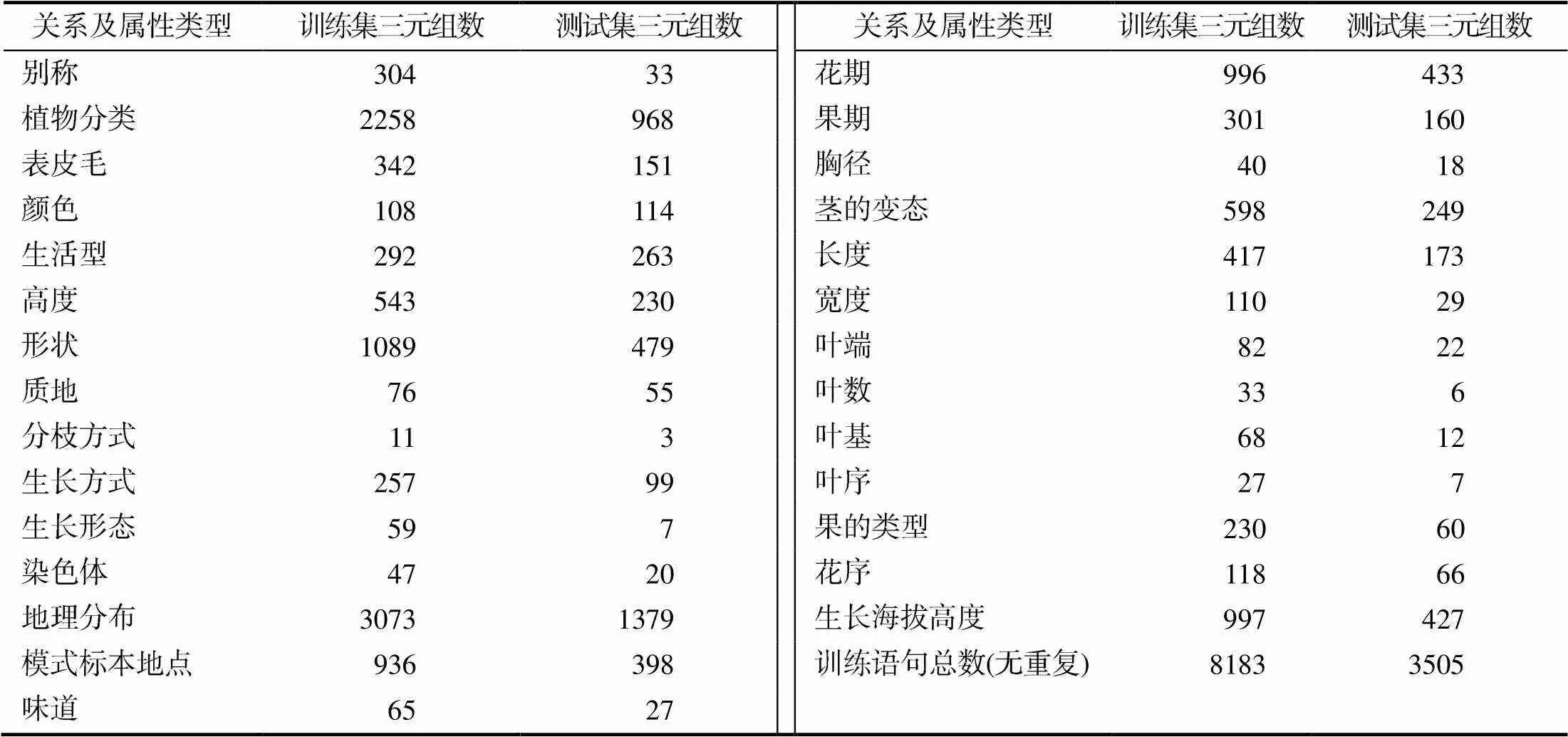
表3 珍稀濒危植物知识抽取试验数据集的分布
2.5 对比结果
按照任务流程,评价模型应充分考虑实体识别和关系抽取的准确率,因此采取精确率()、召回率()、精确率和召回率的调和平均值(1)来对模型的性能进行评判。命名实体识别模型结果如表4所示。

表4 珍稀濒危植物命名实体识别模型的精确率和召回率及调和平均值
从表4可以看出,所用的Albert–BiLSTM–CRF模型的NER结果中,在珍稀濒危植物实体识别任务上优于其他模型。Albert–BiLSTM–CRF模型与BiLSTM–CRF发现,加入Albert后识别的精确率提高了1.74%,召回率提高了1.46%,1值提高了1.6%,说明预训练模型的加入能够更好地对输入文本进行语义编码,捕捉到深层次语义信息,从而提高模型识别性能,达到有效识别珍稀濒危植物实体的目的。对比Albert–BiLSTM–CRF模型与Albert– BiLSTM模型发现,加入CRF层后识别的精确率提高了3.57%,召回率提高了2.77%,1值提高了3.16%,说明加入CRF层后对修正最终结果起积极作用,使得识别结果准确率更高;对比Albert– BiLSTM–CRF模型与Albert–BiGRU–CRF模型发现,精确率提高了0.15%,召回率提高了0.08%,1值提高了0.11%,说明针对NER任务,BiLSTM在识别效果上优于BiGRU。其中,subject的识别准确度比object要高,主要原因在于subject是植物中文名,较为单一,而object针对的主要是本体中除了中文名的一些概念实体,由于存在人工标注的错误和对某些概念缺乏足够的标注数据的原因,导致object的识别率比subject要低。
关系抽取模型结果如表5所示。
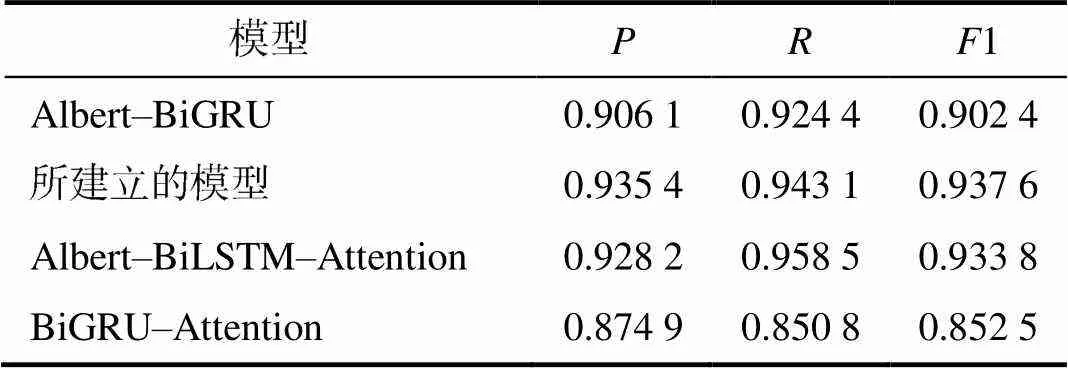
表5 珍稀濒危植物关系抽取模型的精确率和召回率及调和平均值
所建立的关系抽取模型Albert–BiGRU– Attention模型效果较好。与BiGRU–Attention模型对比,精确率、召回率和1值分别提高了6.05%、9.23%、8.51%,说明Albert更好地捕捉到上下文信息,有助于提高模型预测实体之间的关系类别的性能;与Albert–BiGRU模型对比,精确率、召回率和1值分别提高了2.93%、1.87%、3.52%,说明Attention层的加入提高了关系抽取的准确度,有效地实现了对珍稀濒危植物实体之间的关系类别的预测;与Albert–BiLSTM–Attention模型对比,精确率和1值分别提高0.72%和0.38%。
在28类关系抽取当中,有一些关系的抽取还存在错误,例如“生长形态”和“分枝方式”,主要是这两类关系在实验语料数据集所占比例较低,以及由于人工标注数据的一些误差,导致一些文本中还存在概念的重叠,因此在训练过程中降低了模型对“生长形态”“生长方式”关系抽取的准确率。
3 珍稀濒危植物知识图谱的存储及应用
采用Neo4j图数据库存储实体和关系,采取2种方式导入数据:一是在导入Json格式数据集时,借助Neo4j的Python工具包py2neo,按照设计好的数据规则直接编码导入Neo4j;二是针对CSV格式数据,直接采用Neo4j脚本语言Cypher语句加载CSV至Neo4j中,并实现知识融合,避免信息冗余,释放内存压力[19]。输入“MATCH (n: Plant) where n.name=“斑叶杓兰” RETURN n”语句后,在Neo4j中可出现如图5所示的植物知识图谱可视化结果。
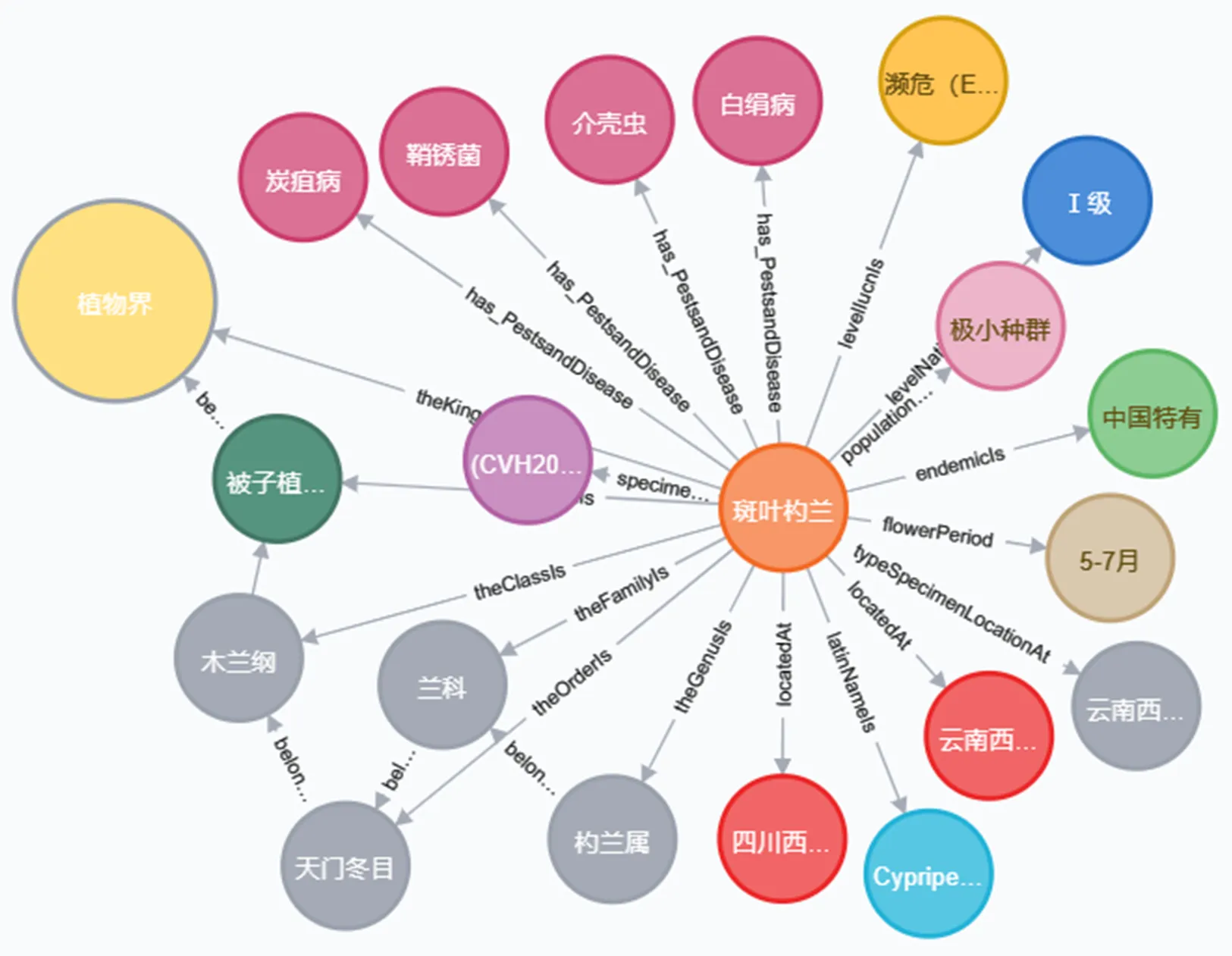
图5 珍稀濒危植物知识图谱的可视化
4 结论
以中国珍稀濒危植物信息系统和植物科学数据中心所提供的《中国植物志》电子版为主要知识来源,构建了珍稀濒危植物本体,设计了一种知识抽取模型流程框架,通过知识图谱构建技术进行知识抽取,获取大量珍稀濒危植物领域三元组,试验结构表明该框架可以实现大批量的知识抽取,有效地提高了准确度,并且满足数据存储要求。
基于知识抽取获取的珍稀濒危植物知识图谱,明确了珍稀濒危植物的物种形态特征、濒危等级、保护现状等信息,为实现植物领域智能系统提供技术支撑。后续将围绕基于珍稀濒危植物知识图谱,构建智能问答系统,加强珍稀濒危植物知识关联度。
[1] 陈亚东,鲜国建,寇远涛,等.我国苹果产业知识图谱构建研究[J].中国农业资源与区划,2017,38(11):40–45.
[2] 于合龙,沈金梦,毕春光,等.基于知识图谱的水稻病虫害智能诊断系统[J].华南农业大学学报,2021,42(5):105–116.
[3] 张桥英,吴勇.大巴山国家地质公园珍稀濒危植物资源[J].生态环境学报,2018,27(11):2011–2016.
[4] 王双蕾,韩航,冯金朝,等.基于文献计量学分析沙冬青属植物的研究进展[J].中央民族大学学报(自然科学版),2020,29(1):24–35.
[5] LAN Z,CHEN M,GOODMAN S,et al.Albert:a lite BERT for self-supervised learning of language represent- tations[C]//ICLR 2020 Area Chairs.ICLR 2020.Addis Ababa:ICLR,2020.
[6] 段宇锋,黄思思.基于BFO构建中文植物物种多样性领域本体的研究[J].现代图书情报技术,2015(12):72–79.
[7] 罗贝,吴洁,曹存根,等.从文本中获取植物知识方法的研究[J].计算机科学,2005,32(10):6–13.
[8] 中国科学院植物研究所.植物智:中国植物志[EB/OL]. [2021–10–11].http://www.iplant.cn/frps.
[9] 国家林业局野生动物保护和自然保护区管理司,中国科学院植物研究所.中国珍稀濒危植物图鉴[M].北京:中国林业出版社,2013:249.
[10] 中国科学院植物研究所.中国珍惜濒危植物信息系统:中国珍稀濒危植物图鉴[EB/OL].[2021–10–11]. https:// www.plantplus.cn/rep/protlist.
[11] 吴征镒,路安民,汤彦承,等.中国被子植物科属综述[M].北京:科学出版社,2004:6–7.
[12] 李晓娟,李建秀.山东水龙骨科植物孢粉学研究及其在分类上的意义[J].广西植物,2020,40(4):443–451.
[13] 刘博,张佳慧,李建强,等.大气污染领域本体的半自动构建及语义推理[J].北京工业大学学报,2021,47(3):246–259.
[14] 鄂海红,张文静,肖思琪,等.深度学习实体关系抽取研究综述[J].软件学报,2019,30(6):1793−1818.
[15] 隗昊,周爱,张益嘉,等.深度学习生物医学实体关系抽取研究综述[J].计算机工程与应用,2021,57(21):14–23.
[16] 马诗语,黄润才.基于ALBERT与BILSTM的糖尿病命名实体识别[J].中国医学物理学杂志,2021,38(11):1438–1443.
[17] 张德政,范欣欣,谢永红,等.基于ALBERT与双向GRU的中医脏腑定位模型[J].工程科学学报,2021,43(9):1182–1189.
[18] 宋晔璇,陈钊,武刚.基于部分标签数据和经验分布的命名实体识别[J].中文信息学报,2021,35(4):51–57.
[19] 闫丽华.基于知识图谱的葡萄病虫害自动问答系统[D].杨凌:西北农林科技大学,2021.
Construction of the knowledge graph for the rare and endangered plants based on Albert model
TIAN Menghui1,2,CHEN Ming1,2*,XI Xiaotao1,2
(1.College of Information Technology, Shanghai Ocean University, Shanghai 201306, China; 2.Key Laboratory of Fisheries Information, Ministry of Agriculture and Rural Affairs, Shanghai 201306, China)
Aiming at the problem of unclear knowledge of morphological characteristics, classification levels, endangerment coefficients, and protection measures in the field of rare and endangered plants, a knowledge extraction model framework based on Albert is designed to realize the batch extraction of rare and endangered plant knowledge and construct the knowledge graph of rare and endangered plants: 1) On the basis of the existing general plant ontology, the rare and endangered plant ontology is constructed in a top-down manner, and five systems are obtained, namely, species classification system, growth morphological characteristic system, and nomenclature system, conservation status system and ecological habit system; 2) The Albert model was adopted to enhance the representation ability of the text semantics of the rare and endangered plant attribute description text input vector of the downstream task model; 3) The BiLSTM CRF model and BiGRU Attention model are used to realize named entity recognition and relation extraction, respectively, and the effectiveness of the model was verified on the rare and endangered plant data test set, and the results showed that the harmonic mean (F1) values of recall and accuracy of the named entity recognition model and the relation extraction model reached 98.07% and 93.76%, respectively, and the triples formed by a large number of entities and relationships were stored in the graph database Neo4j in order to complete the visual display of the knowledge graph of rare and endangered plants.
rare and endangered plants; Albert model; knowledge graph; ontology; named entity recognition; knowledge extraction
TP391.1
A
1007–1032(2023)05–0616–08
田梦晖,陈明,席晓桃.融合Albert模型的珍稀濒危植物知识图谱的构建[J].湖南农业大学学报(自然科学版),2023,49(5):616–623.
TIAN M H,CHEN M,XI X T.Construction of the knowledge graph for the rare and endangered plants based on Albert model[J].Journal of Hunan Agricultural University(Natural Sciences),2023,49(5):616–623.
http://xb.hunau.edu.cn

2022–05–08
2023–06–20
上海市科学技术委员会项目(20dz1203800)
田梦晖(1996—),女,湖北孝感人,硕士研究生,主要从事知识图谱研究,1178851697@qq.com;*通信作者,陈明,博士,教授,主要从事农业信息技术和知识图谱研究,mchen@shou.edu.cn
10.13331/j.cnki.jhau.2023.05.017
责任编辑:罗慧敏
英文编辑:吴志立
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
计算机与数字工程(2023年5期)2023-08-31 08:40:44
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
少先队活动(2020年12期)2021-01-14 01:47:40
中国音乐学(2020年4期)2020-12-25 02:58:06
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
文学教育(2016年27期)2016-02-28 02:35:15
现代防御技术(2014年6期)2014-02-28 18:26:29
