
基于CEEMDAN-LSTM组合的兰州空气质量指数预测
2023-11-18 09:23赵煜韩旭昊
安徽师范大学学报(自然科学版) 2023年5期
关键词:兰州
赵煜 韩旭昊
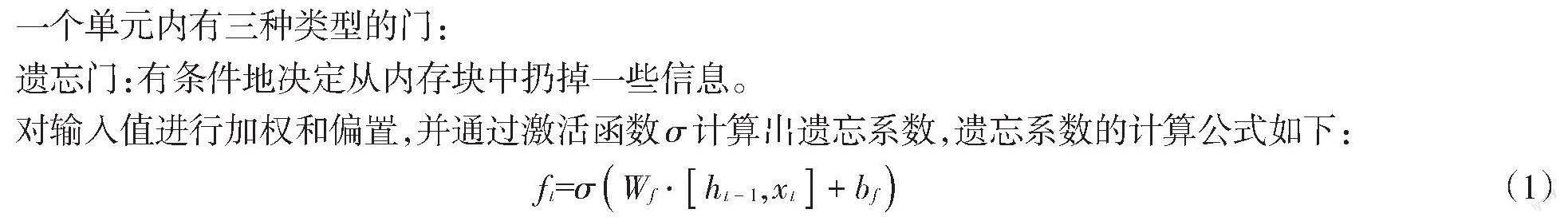

收稿日期: 2023-04-06
基金项目:国家社会科学基金项目(21XTJ004).
作者简介:通讯作者:赵煜(1972—),女,土族,甘肃临洮县人,博士,教授,主要研究方向为应用数理统计、生态经济统计.
引用格式:赵煜,韩旭昊.基于CEEMDAN-LSTM组合的兰州空气质量指数预测[J].安徽师范大学学报(自然科学版),2023,46(5):433-439.
DOI:10.14182/J.cnki.1001-2443.2023.05.004
摘要:针对兰州空气质量指数存在波动大和数据长期依赖性的问题,提出了一种基于CEEMDAN-LSTM组合的预测模型,并与EEMD-LSTM和LSTM模型进行了比较。首先采用CEEMDAN对兰州空气质量指数序列进行分解,然后使用LSTM神经网络预测得到各个分量,最后叠加各分量的预测值重构空气质量指数预测结果。实验结果表明,CEEMDAN-LSTM模型相比于LSTM模型和EEMD-LSTM模型,具有更小的预测误差和更高的预测精度。这得益于CEEMDAN方法的有效降噪和LSTM模型对长期依赖关系的强大处理能力。因此,该组合模型在兰州空气质量指数预测方面具有一定的实用价值。
关键词:兰州;空气质量指数;LSTM神经网络;CEEMDAN模态分解
中图分类号:X823 文献标志码:A 文章编码:1001-2443(2023)05-0433-07
引言
空气质量指数(AQI)是反映空气质量状况的综合指数,为评估区域空气质量及后续预防和治理空气污染提供了重要的量化依据。由于气象过程的多变性和随机性,准确预测空气质量指数相对困难,不同学者从不同角度引入多种模型,以期提升AQI预测的精度与稳定性,在早期的研究中,主要采用各个不同领域的单一方法。例如:李博群等[1]利用数学方法,引入模糊时间序列理论进行预测;Sigamani等[2]基于统计思想,建立多元线性回归模型进行预测;吴慧静等[3]借助机器学习模式,采用遗传算法改进的BP神经网络进行预测。当前的研究趋势主要是从智能算法、影响因素挖掘和序列属性分解三个角度进行深入探究。
智能算法角度:许毅蓉等[4]运用参数自动化智能算法得到AQI预测模型的最优参数,避免了传统机器学习模型中运行速度慢的问题;龚荣等[5]通过改进海洋捕食者算法增强了该算法的全局搜索能力,提高了空气质量指数预测的精度和可靠性;Zhan等[6]将开发的分解算法与广义学习系统(BLS)相结合,构建了一种更简单高效的神经网络,该神经网络在预测空气质量指数时模型训练速度更快;Chhikara等[7]使用联邦学习(FL)算法收集数据,创建了一个全局模型,通过不断迭代更新数据,该模型相比其他时间序列模型预测误差更小。尽管基于智能算法的空气质量指数预测方法简单且快速,但容易出现欠拟合问题。
影响因素挖掘角度:刘媛媛等[8]考虑时空因素的影响,引入注意力机制以关注重要特征,从而提升预测效果;李志刚等[9]采用交叉递归定量分析AQI影响因素间的关联度,筛选影响AQI的重要因素,为后续预测提供优质的先验数据;李乾等[10]以主成分分析法筛选影响AQI的关键因子,降低了輸入维度并减少运算量,提高了预测精度;周凯等[11]分析空气质量指数的平稳性、季节性,并通过ARIMA拟合预测,在48小时内预测结果与实际结果较吻合。基于影响因素挖掘的空气质量指数预测模型在短期预测方面表现较好,但随着预测时长的增加,预测精度逐渐降低。
序列属性分解角度:有基于时域方法的分解,如朱雪妹等[12]基于时域方法构建了SARIMA模型,用于提取AQI的趋势和季节特征,从而揭示空气质量的规律性变化;有基于频域方法的分解,如李婷婷等[13]利用经验模态分解(EMD)算法对AQI数据进行分解,使数据的波动具有规律性,有助于提高模型的预测效果;姚清晨等[14]采用小波去噪建立AQI的四季预报方程,小波滤波图比原时间序列图更加平滑,拟合效果更好;徐洪学等[15]应用奇异谱分析方法,得到不同时间子序列,根据序列特点对不同子序列建模,最终结果明显优于传统ARIMA模型;Li等[16]基于快速傅立叶变换提取信号的最高频率部分和其余部分的频域边界,在模态混叠方面比EMD具有更好的性能,有助于提升序列分解的稳定性。
更多学者在视角重叠与方法组合方面进行了尝试。常恬君等[17]利用随机森林组合Prophet模型,弥补了Prophet模型无法预测随机非线性部分的缺点;Zhao等[18]引入拓扑结构的相似性提出了非参数和数据驱动模型,提高了空间模型的准确性和适应性;Zuo等[19]提出了集合经验模态分解(EEMD)和小波包阈值联合去噪的方法,解决了小波变换容易丢失高频细节信息的问题。基于视角重叠与方法组合的模型弥补了单一模型的缺点,提高了预测精度。
综合来看,基于机器学习与序列属性分解方法的组合在AQI预测中优势明显,其中,相较于时域分解,频域分解在提取AQI属性方面更有效。常用的频域分解方法主要有小波分析、奇异谱分析和经验模态分解等。而现有研究表明,小波分析对于基函数的选择和分解层数的确定缺乏自适应性,而不同的基函数和分解层数会对结果产生显著影响[20],奇异谱分析在选取滞后窗口时存在一定的主观性,不同窗口长度会对信号提取的效果产生较大影响[21]。相对而言,EMD方法可以很好地处理非线性和非平稳信号,但EMD在实际应用中容易出现端点效应和模态混叠现象[22]。基于EMD优化的EEMD通过引入噪声克服了模态混叠问题,但仍然存在一些不确定性。进一步改进的完全自适应噪声集合经验模态分解(CEEMDAN)具有自适应分解特性,能够根据非线性序列自身特征进行分解,解决了EMD算法的模态混叠问题[23],通过对原始信号进行多次添加噪声并分解的思路,进一步提升了稳定性,得到更稳定可靠的时间序列分解结果。
目前对于空气质量的研究多集中于经济快速发展和人类活动频繁的东部地区,这类地区外部气候条件类似,内陆城市呈现空气循环较弱、空气污染具有长期性和稳定性等特点,其研究结果对外部气候条件特殊的西部地区借鉴意义不强[24]。兰州作为典型的河谷城市,气象条件相对特殊,逆温现象及低风条件等阻碍空气垂直运动,大气气溶胶和一些气态污染物难以扩散出去[25]。这导致兰州空气质量指数序列存在长期依赖关系,当前空气质量指数不仅受数月之前空气质量影响,而且呈现较大的波动特征。
论文以兰州空气质量指数预测为研究内容,以有效提取AQI数据内在特征为切入点探讨组合预测模型的构建。选取LSTM模型以提取空气质量指数序列中的长期依赖关系,LSTM模型的长短期记忆网络通过引入遗忘门、输入门和输出门可捕捉时间序列中跨度较大的依赖关系;针对兰州空气质量指数序列波动大的特点,选取CEEMDAN分解方法,提取空气质量指数序列中的趋势、季节性和周期性等,使序列的分解更稳定可靠。通过预测效果评价及与LSTM、EEMD-LSTM模型预测结果的比较可知,本文最终建立的CEEMDAN-LSTM组合模型,预测效果良好。
1 基本理论
1.1 LSTM神经网络
长短期记忆网络是使用反向传播训练并克服消失梯度问题的递归神经网络。针对时间序列的无序性,LSTM提供了有效的解决方案。LSTM网络使用循环结构,可以学习时间序列数据的依赖关系,以便预测结果。相比于传统的神经元,LSTM内部包含多个内存块,这些块之间进行层层相连。每个块包含管理块状态和输出的门,这些门使用sigmoid激活单元,可以控制状态的变化和信息的添加。
一个单元内有三种类型的门:
遗忘门:有条件地决定从内存块中扔掉一些信息。
对输入值进行加权和偏置,并通过激活函数[σ]计算出遗忘系数,遗忘系数的计算公式如下:
[ft]=[σWf?ht-1,xt+bf] (1)
其中:[ht-1]为隐藏层上一时刻的状态;[xt]为当前时刻实际值;[ft]为遗忘系数;[Wf]和[bf]分别表示遗忘门权重及偏置量。
输入门:有条件地决定从输入中更新内存状态的值。
输入门通过tanh层决定保留的信息,并更新数值。
[it]=[σWi?hi-1,xi+bi] (2)
[ct=tanhWc?ht-1,xt+bc] (3)
[it]为要更新的数值,[ct]为新的候选数值,[Wi]、[WC]和[bi、bc]分别表示权重和偏置量。
输出门:根据输入条件决定输出结果。
[Ot=σW0ht-1,xt+b0] (4)
1.2 CEEMDAN经验模态分解
集合经验模态分解(CEEMDAN)算法在EMD算法基础上改进得到,如前文所述,EMD方法在应对端点效应和模态混叠等问题上存在一定的局限性,改进的EEMD虽然克服了模态混叠问题但容易存在重构误差[26]。为克服这些问题,采用CEEMDAN方法,CEEMDAN方法通过引入随机白噪声,增强了分解的稳定性和鲁棒性。此外,相比EEMD方法,CEEMDAN在处理波动大的序列时具有抗噪性强、分解精度高等优势,成为空气质量指数序列分解的优良选择。CEEMDAN的基本逻辑如下:
生成含有白噪声的序列:
[xit=xt+wit ] (5)
对[xit]进行分解,得到各样本的1阶IMF分量,将其均值作为[xt]的1阶IMF分量,即:
[IMF1t=1Ii=1IIMFi1] (6)
计算1阶残差量、2阶IMF分量。1阶残差量、2阶IMF分量的表达式分别为:
[r1t=xt-IMF1t] (7)
[IMF2t]=[1Ii=1IE1r1t+ε1E1wit] (8)
k阶残差,k+1阶IMF分量的表达式分別为:
[rkt=rk-1t-IMFkt] (9)
[IMFk+1t]=[1Ii=1IE1rkt+εkEkwit] (10)
重复这一步直到残差不可再分解,其判断标准为残差的极值点个数至多为2,若残差满足:
[Rt=xt-k=2KIMFkt] (11)
则原始序列[xt]最终被分解为:
[xt=k=2KIMFkt+Rt] (12)
1.3 模型评价指标
一般通过对比实际值和预测值评估预测效果,单一评价标准没有说服力,因此选取以下指标度量模型的预测效果。
(1)平均相对误差绝对值
[EMAP=1lt=T+1T+lXt-XtXt] (13)
(2)均方根误差
[ERMS=1lt=T+1T+l(Xt-Xt)2] (14)
式中:[l] 表示预测序列的长度,从时间[T+1]开始预测,一直到[T+l],[Xt]是实际值,[Xt]是预测值,EMAP、ERMS值越小,代表预测误差越小。
2 数据获取及处理
2.1 研究区概况
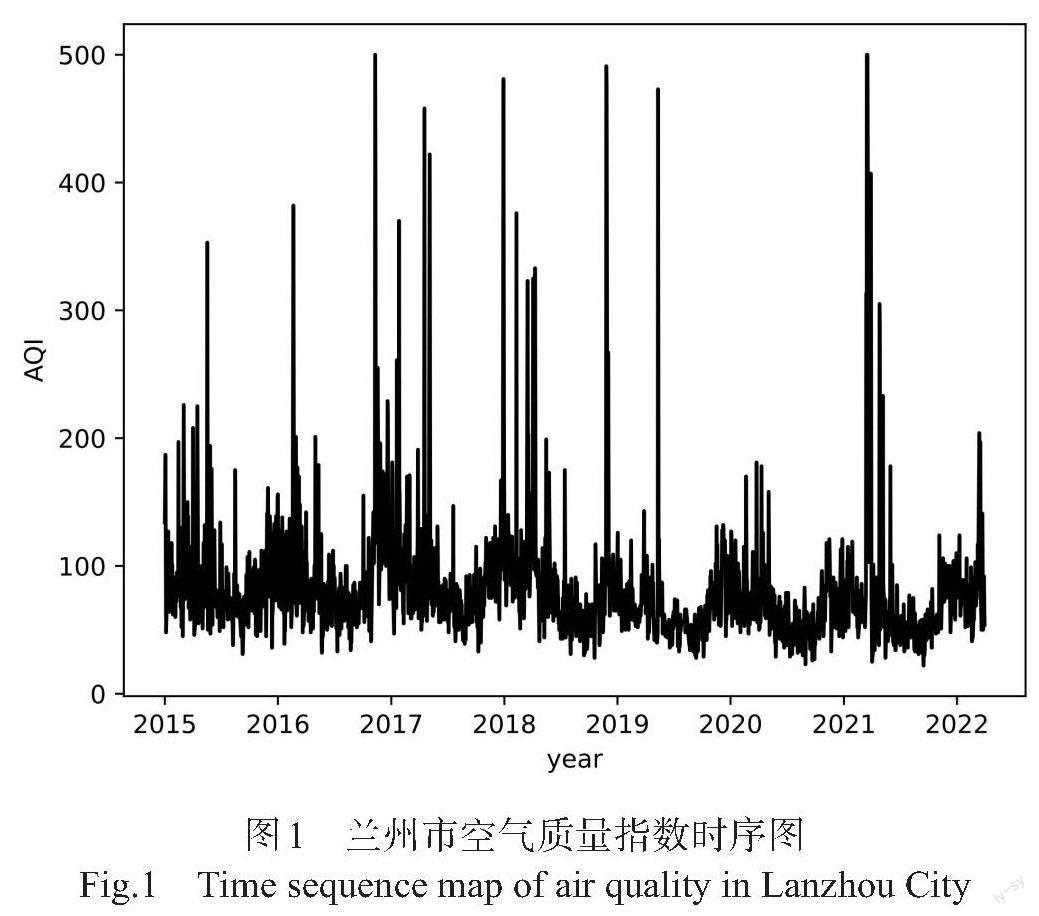
河谷城市指在城市发展中受到河流以及山谷限制的城市,城市一般会被迫沿着地形和河流走向而发展布局,顺着河流主干道形成带状密集的空间结构。兰州地区南北方向被群山环抱,东西由盆地组成,是典型的河谷城市,其气候环境比较特殊,外部气象条件相对复杂。一方面,大气污染物扩散缓慢,不同种类的污染物长时间滞留空中并混合在一起,形成更难处理的混合污染物;另一方面,受天气条件、地形和逆温现象等因素的影响,兰州空气质量指数序列波动幅度大、季节趋势强(见图1),空气质量指数序列的多因素叠加特征鲜明。
2.2 数据来源及预处理
考虑到从海量网页信息中获取数据时,爬虫方法具有爬取速度快,可以提取生成特定格式数据等优点,因此,本文选用爬虫方法,使用开源平台Python的BeautifulSoup库构建网络爬虫,爬取“天气后报”网站的兰州市2015年1月1日至2022年3月31日历史空气质量指数作为研究数据,并对缺失值和异常值进行数据预处理。其中,缺失值补全采用均值替代,使用缺失值前后两天数据来计算均值并代替缺失值。异常值判定采用三倍标准差方法,通过对比历史上同一季节的数据均值来判断是否是异常值。如果当前数据在平均值的正负三倍标准差之内,则判定为正常值,否则视为异常值,剔除后进行缺失值插补处理。
爬取的数据时间跨度从2015年1月1日至2022年3月31日,包括质量等级、AQI指数、AQI排名等,经过剔除异常值和补全缺失值,共计2514组数据。
2.3 CEEMDAN-LSTM模型构建
本文构建的CEEMDAN-LSTM模型如图2所示。为有效捕捉AQI序列的细节特征,对其进行CEEMDAN分解,得到IMF分量,通过IMF分量反映AQI数据的总体变化趋势,与原始数据相比,分解后的分量波动更小,建模难度降低。LSTM为预测基础模型,LSTM是一种递归神经网络,通过自适应门控机制来记忆和更新序列中的信息,能更好地捕捉到空气质量指数序列中的长期依赖性,本文将每个IMF分量作为LSTM模型的输入,利用LSTM的记忆性质来建模序列中的长期依赖性,以提高对空气质量指数预测的准确性。
具体建模环节中,使用CEEMDAN方法将原始AQI序列分解时,对原始信号随机添加白噪声分解得到n个IMF分量,每个IMF分量代表不同频率范围内的振动模式,分解方式见图3。
对各序列分量进行LSTM预测时,look_back设置为1,指用前一天的数据预测后一天,在模型编译的过程中使用adam优化器,使用平均绝对误差作为网络训练的损失函数,单隐层设置500神经元节点,迭代500次,最终得到不同频率分量的预测结果,以相等的权重将所有分量的预测结果相加汇总,即为最终预测结果。
3 结果与讨论
3.1 基于CEEMDAN的AQI序列分解结果
由图4可知,通过CEEMDAN将空气质量指数序列分解成10个IMF分量和1个残差分量,右侧频谱对应IMF分量在不同频率范围内的能量分布情况,频谱用来描述分量的频率特征和频率分布情况。
从原始数据的波动性可以看出AQI在一年内周期性变化,峰值代表每年污染最严重的几个月份,峰值的高低与兰州当年的逆温、风速等气象条件关系密切,峰值信息可以帮助识别污染高峰期和低峰期,总结兰州市空气质量季节性变化规律。
IMF1~IMF4变化幅度较大,表明气象条件和地形等对兰州空气质量指数产生了一定的影响,如兰州突发的沙尘天气带来高浓度的颗粒物,导致空气质量指数急剧上升。
IMF5~IMF10分量的波动呈现出规律性,逐渐放缓,这可能与一些长期的、缓慢变化的环境因素有关,如城市发展、工业结构和污染治理等因素,這些因素变化较为缓慢,不会对空气质量产生即时影响,但它们的长期累积效应对兰州市空气质量影响深远。
3.2 基于CEEMDAN-LSTM模型的AQI预测结果
选取2015年1月1日至2022年2月28日的数据作为训练集,2022年3月1日至2022年3月31日的数据作为测试集,分别采用改进的CEEMDAN-LSTM模型、EEMD-LSTM模型和LSTM模型对AQI进行预测分析,各个模型的预测结果如图5所示。
图5(a)为LSTM模型预测结果,可以看出,在LSTM预测图像的数据上升或下降阶段出现了预测值滞后的现象,原因可能是当使用LSTM进行预测时,该神经网络会选择使用时间窗口之前的某个时间点的值来作为预测值,这样可以最小化误差。虽然这种方法可以最小化误差,但实际上回归算法并没有学习到任何新的知识或规律。图5(b)为EEMD-LSTM组合模型预测结果,相比LSTM模型预测精度有所提高,但是滞后性改善并不明显。综合来看,CEEMDAN将时间序列分解成多个IMF分量后进行LSTM预测有效减少了滞后性及不稳定属性,实验结果表明,本文所构建的CEEMDAN-LSTM组合模型在处理非平稳时间序列时能够更好地捕捉变化模式和特征,预测效果更好,精度更高。
3.3 结果分析与讨论
为进一步研究不同模型对于模型精度的影响,证明模型优劣还需结合评价指标分析,于是计算三个模型的评价指标。
如表1所示,基于CEEMDAN-LSTM的均方根误差和平均绝对百分比误差均优于其他两种模型,与单一的LSTM基线模型相比,RMSE下降了56.61%,表明经过CEEMDAN模态分解后的模型可以更好地挖掘数据中的隐藏信息。同时与EEMD-LSTM模型相比,RMSE下降了42.13%,表明CEEMDAN的数据降噪能力相比EEMD更为出色。
由于空气污染成因复杂、多源性,加之气象条件和地形地貌因素的影响,使得兰州市的空气质量变化非常不稳定,很难进行准确预测。本文中AQI的预测是基于机器学习视角展开,未将外部影响因素作為显性因子引入模型,事实上,兰州市的空气质量预测可综合考虑多个因素,后续可将有效甄别气象条件、地形等外部因素的影响作用作为切入点,构建多视角组合模型进行预测方法的对比研究,以进一步提高预测的准确性和可靠性。
4 结论
本文针对时间序列波动大的问题,采用了CEEMDAN(经验模态分解方法)进行数据分解;针对兰州空气质量监测数据呈现出的长期依赖关系,选用LSTM(长短期记忆神经网络)作为基本模型,构建了CEEMDAN-LSTM组合模型。该组合模型通过LSTM神经网络对CEEMDAN得到的各个分量进行预测,各个分量预测结果加总得到预测结果。实验证实,相较于其他模型,该组合模型在兰州空气质量指数的预测上具有更高的精度和准确性。因此,该模型对于空气污染治理方面具有一定的参考意义,为未来的研究提供了新的思路和方法。
参考文献
[1]李博群,贾政权,刘利平.基于模糊时间序列的空气质量指数预测[J].华北理工大学学报(自然科学版),2018,40(3):78-86.
[2]SIGAMANI S,VENKATESAN R. Air quality index prediction with influence of meteorological parameters using machine learning model for IoT application[J]. Arabian Journal of Geosciences, 2022, 15(4): 340.
[3]吴慧静,赫晓慧.基于GA-BP神经网络的空气质量指数预测研究[J].安徽师范大学学报(自然科学版),2019,42(4):360-365.
[4]许毅蓉,连金海,张小蓉,等.运用智能型算法预测空气综合质量指数的研究[J].福建电脑,2022,38(6):17-21.
[5]龚荣,谢宁新,李德伦,等.基于海洋捕食者算法和ELM的空气质量指数预测[J].广西民族大学学报(自然科学版),2022,28(4):68-76.
[6]ZHAN C, JIANG W, LIN F, et al. A decomposition-ensemble broad learning system for AQI forecasting[J]. Neural Computing and Applications, 2022, 34(21): 18461-18472.
[7]CHHIKARA P, TEKCHANDANI R, KUMAR N, et al. Federated learning and autonomous UAVs for hazardous zone detection and AQI prediction in IoT environment[J]. IEEE Internet of Things Journal, 2021, 8(20): 15456-15467.
[8]刘媛媛,曹宇飞.集成CNN-LSTM预测模型的空气质量可视化平台[J].信息技术与信息化,2022(4):19-22.
[9]李志刚,秦林林,付多民,等.基于CRQA-DBN-ELM空气质量数据预测模型[J].电子测量技术,2022,45(19):76-82.
[10]李乾,乔栋,李博文,等.基于T-S模糊神经网络的空气质量预测模型分析研究[J].内蒙古煤炭经济,2022, 358(17):142-144.
[11]周凯,刘萍.基于数据挖掘的空气质量预测模型研究[J].计算机与数字工程,2021,49(8):1631-1636.
[12]朱雪妹,米江晅,郑冬冬,等.基于SARIMA模型的保定市空气质量指标的预测[J].绿色科技,2018(14):43-45.
[13]李婷婷,田瑞琦,汪漂.基于经验模态分解的空气质量指数组合预测方法及应用[J].价值工程,2019,38(16):134-138.
[14]姚清晨,张红.基于小波分析的太原市空气质量变化特征及预测[J].山西大学学报(自然科学版),2019,42(1):265-274.
[15]徐洪学,孙万有,杜英魁,等.基于奇异谱分析的多模型融合空气污染物质量浓度预测方法[J].沈阳大学学报(自然科学版),2021,33(6):470-479.
[16]LI J, WANG J, ZHANG X, et al. Empirical mode decomposition based on instantaneous frequency boundary[J]. Electronics Letters, 2017, 53(12): 781-783.
[17]常恬君,过仲阳,徐丽丽.基于Prophet-随机森林优化模型的空气质量指数规模预测[J].环境污染与防治,2019,41(7):758-761+766.
[18]ZHAO X, SONG M, LIU A, et al. Data-driven temporal-spatial model for the prediction of AQI in Nanjing[J]. Journal of Artificial Intelligence and Soft Computing Research, 2020, 10(4): 255-270.
[19]ZUO L Q, SUN H M, MAO Q C, et al. Noise suppression method of microseismic signal based on complementary ensemble empirical mode decomposition and wavelet packet threshold[J]. IEEE Access, 2019, 7: 176504-176513.
[20]劉涛,杜世昌,黄德林,等.基于改进的集合经验模态方法振动信号分解[J].上海交通大学学报,2016,50(9):1452-1459.
[21]戴前伟,丁浩,张华,等.基于变分模态分解和奇异谱分析的GPR信号去噪[J].吉林大学学报(地球科学版),2022,52(3):701-712.
[22]GUPTA A, KUMAR D, VERMA H, et al. Recognition of multi-cognitive tasks from EEG signals using EMD methods[J]. Neural Computing and Applications, 2022: 1-18.
[23]KALA A, VAIDYANATHAN S G, FEMI P S. CEEMDAN hybridized with LSTM model for forecasting monthly rainfall[J]. Journal of Intelligent & Fuzzy Systems, 2022, 43(3):2609-2617.
[24]张人禾,李强,张若楠.2013年1月中国东部持续性强雾霾天气产生的气象条件分析[J].中国科学:地球科学,2014,44(1):27-36.
[25]陈桃桃,李忠勤,周茜,等.“兰州蓝”背景下空气污染特征、来源解析及成因初探[J].环境科学学报,2020,40(4):1361-1373.
[26]王彤彤,严华.基于EMD和时空图神经网络的污染物浓度预测研究[J].现代计算机,2021,27(34):29-35.
Prediction of Lanzhou Air Quality Index Based on CEEMDAN-LSTM Model
ZHAO Yu, HAN Xu-hao
( School of Statistics, Lanzhou University of Finance and Economics, Lanzhou 730020, China)
Abstract: Aiming at the problems of large fluctuation and long-term data dependence of Lanzhou AQI, a prediction model based on CEEMDAN-LSTM is proposed in this paper, and compared with EEMD-LSTM and LSTM models. Firstly, CEEMDAN was used to decompose the AQI sequence of Lanzhou, then LSTM neural network was used to predict each component, and finally the predicted value of each component was added to reconstruct the AQI prediction result. The experimental results show that CEEMDAN-LSTM model has smaller prediction error and higher prediction accuracy than LSTM model and EEMD-LSTM model. This is due to the effective noise reduction of CEEMDAN method and the strong handling ability of LSTM model for long-term dependencies. Therefore, the combined model has certain practical value in Lanzhou AQI prediction.
Key words:Lanzhou;air quality index;LSTM;CEEMDAN
(责任编辑:王海燕)
猜你喜欢
草堂(2023年1期)2023-09-15
声屏世界(2022年13期)2022-10-08
猪业科学(2021年6期)2021-08-12
黄河之声(2021年8期)2021-07-23
中国石油石化(2021年10期)2021-07-16
学生天地(2020年8期)2020-08-25
学生天地(2020年19期)2020-06-01
学生天地(2020年19期)2020-06-01
学生天地(2020年19期)2020-06-01
幸福(2017年18期)2018-01-03
