
基于OpenGL ES 的图像滤波算法实现及优化研究
2023-11-18 03:33:00常文斌牟明任贾海鹏张云泉张思佳
计算机工程 2023年11期
常文斌,牟明任,贾海鹏,张云泉,张思佳
(1.大连海洋大学 信息工程学院,辽宁 大连 116023;2.中国科学院计算技术研究所 处理器芯片全国重点实验室,北京 100190)
0 概述
图像滤波是图像处理领域中具有广泛应用场景的算法,主要应用于超声医学、航空航天、数字媒体、人工智能等领域。图像滤波可以起到降低椒盐噪声、图像二值化、边缘识别和提取图像特征的作用。常见的图像滤波方法有形态学滤波、盒式滤波、阈值滤波、压缩滤波、算术滤波等。从实现原理来分析,各种滤波算法根据原始图像的像素状态,经过一系列不同的运算得到目标像素值。
图像滤波算法的研究已经相当广泛,但是在实际应用中仍存在许多不足之处。例如,在Android 平台方面,虽然开源的OpenCV 库已经提供了较全面的图像滤波算法,但是与其他平台相比,其在Android 平台的性能表现仍存在较大的差距。目前,还没有广泛应用的专门针对Android 平台进行优化的高性能图像滤波算法库。
随着移动终端和Android 操作系统的发展和普及,面向多平台可移植嵌入式设备的高性能图像滤波算法库亟待完善。虽然目前在Apple 平台已有MPS、Core Image、Vision 等算法 库,但是其 仅支持Apple 硬件和iOS 系统,并不普遍适用于Android系统。
为进一步提高移动Android 端及相关嵌入式平台上图像滤波算法的实际性能表现,本文提出一种专门针对Android 端及其嵌入式平台进行优化的高性能图像滤波算法。在Android 平台上,基于OpenGL ES 编程接口,利用OpenGL 纹理对象和缓冲传递图像数据,通过计算着色器实现算法的并行优化,设计一种针对移动Android 端基于OpenGL ES接口的优化体系,实现并优化一系列滤波算法,以提升算法运算性能。
1 相关工作
1.1 针对OpenGL 的相关工作
OpenGL[1]是用于渲染2D、3D 矢量图形的跨语言、跨平台的应用程序编程接口,而本文用到的OpenGL ES 3.2[2]是OpenGL 的1 个子集,主要针对移动电话、手持设备、家电设备、汽车等嵌入式设备而设计的。研究指出,在移动设备上采用OpenGL ES实现的视频滤波算法[3],相比现有的OpenCV 滤波算法库,在内存和功耗方面具有更大的优势,在算法性能方面也有显著提升。相关研究显示,面向Android系统的硬件设备对OpenGL ES 有更加友好的支持[4]。然而,目前还缺少针对Android 平台设计、使用OpenGL ES 实现和优化性能较好的图像滤波算法。因此,上述研究为本文选择使用OpenGL ES 编程接口来实现和优化图像滤波算法提供了有价值的参考。
在OpenGL 的众多着色器中,计算着色器是一种用于通用计算的特殊着色器,其本身可以看作一种特殊的、单一阶段的管线,以更加充分地利用GPU的计算能力[5]。目前,研究人员提出采用OpenGL 计算着色器实现矩阵乘法[6]。但是在使用计算着色器进行图像滤波计算方面的研究还较不足,为本文基于OpenGL ES 计算着色器的算法优化工作提供了一定的参考。
相关研究指出,在OpenGL 中,纹理和缓冲的存储和访问方式非常适合在CPU 和GPU 之间高效地传输图像数据[7-9]。就纹理而言,在着色器内使用纹理坐标对纹理像素进行访问,实现像素级的计算和操作[10]。然而,在现有研究中,纹理主要被用于在片元着色器中对图像进行采样和处理[11],例如利用纹理映射技术将纹理图像应用于几何图形中,以获得更逼真的渲染效果[12]。在计算着色器中使用纹理操作数据的研究相对较少。因此,在OpenGL ES 中,将纹理与计算着色器相结合,以实现更高效的并行计算和数据操作的研究具有一定意义。
1.2 针对滤波算法优化的相关工作
目前,已经有相当一部分针对图像滤波算法进行优化的研究,例如,基于NVIDIA 公司的GPU 采用CUDA 编程模型[13]对盒式滤波、高斯滤波进行并行优化[14],基于ARMv8 处理器,采用SIMD 和汇编指令对图像滤波算法进行优化[15]。此外,研究人员通过引入Graph-Waving 架构[16],提升SIMD 元件利用率,以有效提升算法性能。针对SIMD 等指令级并行性和流水线的优化工作[17-19]都不同程度地提高其研究算法的性能。上述研究表明,通过并行优化方式可以显著提升图像滤波算法性能,有效提高图像滤波的处理速度和效率。然而,目前的优化工作大多都基于多核CPU[20]或者基于GPU,使用图形渲染方式进行优化。基于Android 平台,使用OpenGL ES计算着色器并行优化的研究相对不足。
此外,还有相当一部分研究是对基于图形学的图像滤波效果进行优化[21-23],并未对算法的运算效率和性能优化做更多的阐述。例如,相关研究在移动Android 设备中将油画滤波算法通过OpenGL ES图形渲染管线实现并进行优化[24],取得较优的图像效果。但是,该类工作主要侧重于图形学效果的优化,对算法运算效率的提升并不显著[25]。也有研究从图形学的实现原理出发,对形态学滤波算法的并行实现进行研究[26],取得了较高的计算精度和较优的图像效果。然而,在许多应用场景中,本文更加关注在满足一定精度要求的同时优化算法性能,以提高其在实际应用中的速度和效率。
在插值和投影等优化算法中,查表法具有较好的优化效果[27]。这项研究为本文在阈值滤波算法中使用查表法提供了一定的参考。
2 算法原理
2.1 线性滤波算法
线性滤波是指由源图像某一像素点周围滤波窗口数量的像素值经过一系列的算术运算,得到最终输出图像像素值的滤波算法。线性滤波算法计算式如下:
其中:kkerne(lx',y')为不同的卷积算子;x'和y'的值随卷积算子大小而定,不同的卷积核对应不同的滤波算法。本文研究的线性滤波算法有盒式滤波和算术滤波。
从原理方面分析,线性滤波根据某一特定卷积算子(由具体的滤波算法而定),按照从左到右、从上到下的顺序,对原始图像逐个像素进行卷积运算。
以盒式滤波为例,当Normalize 参数设定为True时其算法原理如图1 所示,图中kernel 为1 个3×3 的卷积算子。将3×3 窗口内的源图像数据与卷积算子对应位置的数据相乘,再把求得的9 个数相加,将最终值赋给当前的锚点,即为算法所求的值。锚点为滤波窗口的中心,对于某些特殊的计算需求,锚点也可自定义为滤波窗口内的任一位置。
2.2 非线性滤波算法
非线性滤波是指源图像通过取最值、置零和取绝对值等一系列逻辑运算(而非算术运算),求得目标像素点的滤波算法。本文研究的非线性滤波算法包含形态学滤波、阈值滤波和压缩滤波。从实现原理来分析,非线性滤波也有线性滤波中类似卷积算子的概念,但两者的区别在于:线性滤波的卷积算子是不同算法有不同的值;在非线性滤波中,卷积算子的数值可以看作是滤波窗口内源图像的像素值。非线性滤波算法通过在源图像卷积窗口内进行逻辑运算,以替换源图像像素锚点的值,从而实现相关滤波功能。
形态学滤波是一种基于数学形态学的典型非线性滤波方法,通过计算滤波窗口内的最值来替换源图像像素值,使得图像内的噪声被滤波窗口内的最值代替,以达到形态学的腐蚀和膨胀等目的,为图像边缘检测和特征提取提供数据基础。1 个大小为3×3 滤波窗口的形态学腐蚀滤波算法示意图如图2 所示,src 为源图像像素值,dst 为输出图像像素值。

图2 形态学腐蚀滤波算法原理示意图Fig.2 Schematic diagram of the principle of morphological erode filtering algorithm
形态学腐蚀滤波、膨胀和梯度算法计算式分别如式(2)~式(4)所示:
其中:eelement为滤波窗口。本文只研究矩形滤波窗口,通常其长、宽相等且为奇数如3×3、5×5、7×7 等。
根据算法性质,形态学执行次数可以与卷积窗口大小相关联,当执行次数大于1 时,通过式(5)和式(6)改变窗口大小,达到多次进行滤波的图像学效果,从而提升算法性能。
此外,形态学的开(Open)、关(Close)算法均基于erode 和dilate 计 算,不同之 处在于:Open 算法先执行erode 后执行dilate,而Close 算法先执行dilate后执行erode。此外,Gradient 算法则是将源图像执行1 次dilate,再将该计算结果与源图像进行erode 的计算结果做减法,得到形态学梯度图。
3 基于OpenGL 的优化策略
3.1 naive 实现
本文所完成的图像滤波算法首先在CPU 端进行naive 实现,再通过OpenGL ES 移植到移动设备的CPU+GPU 异构平台上进行优化。
在形态学滤波的naive 实现中,本文采用先行后列求最值方式,输入整幅图像,按照滤波窗口大小,先将经过边界处理源图像的行按照滤波窗口宽度大小求出最值,将每行的计算结果放至环形缓冲区(在算法程序内部声明,以首尾相连的方式组织数据的存储结构),将足够数量的行(根据声明的空间大小和图像数据量而定)计算完成后,再按照滤波窗口高度计算列最值,如此往复,直至循环整张图像。该方式的优点:减少重复访存,在计算列最值时直接重复使用求得的行最值,不须重复访问源图像数据,将访存不连续的滤波窗口变成访存连续的行,大幅减少访存的时间开销。
盒式滤波的naive 实现与形态学先行后列的方法类似。本文将取最值操作改为求和操作,将滤波窗口内的像素值累加并存储在中间矩阵中,然后与滤波核中的数值做乘法,求得源图像均值。在盒式滤波中,本文通过权值置一的方法提供了非归一化的滤波算法。该算法可以用来计算源图像各像素在滤波窗口邻域内的积分特征。
在阈值滤波算法的naive 实现中,分为定阈值滤波算法和自适应阈值算法。在定阈值滤波算法中,本文支持自定义阈值和指定阈值计算方法。阈值计算的具体方法可以通过计算类间最大方差确定阈值的大津阈值法(Otsu's),该计算方法适合双峰直方图,还可以通过计算直方图曲线与直线之间最大距离确定Triangle 阈值,适合单峰直方图。Otsu's 算法计算类间最大方差的计算式如式(7)所示:
其中:x为像素值;n为权重。
阈值滤波还提供了5种不同的图像二值化类型供用户选择。二值化(THRESH_BINARY)计算式如下:
反二值化(THRESH_BINARY_INV)计算式如下:
阈值截断(THRESH_TRUNC)计算式如下:
阈值置零(THRESH_TOZERO)计算式如下:
反阈值置零(THRESH_TOZERO_INV)计算式如下:
自适应阈值滤波的naive 实现示意图如图3 所示。本文首先采用高斯滤波或盒式滤波将源图像(这里的源图像为灰度图)转换为均值图像;然后通过src-mean 对源图像与均值图像做减法,再结合权重,自适应地将源图像转换为二值化图像。此外,在算法的实现中,本文还引入查表法,提前计算灰度图(像素值为0~255)所有可能像素值的二值化结果,并将结果存储在Tab 表中,通过查表法将均值图像的值与表的索引进行对比。对于二值化计算,本文只需要将对比成功表中的二值化结果直接存入输出图像中。该方法在处理大规模的图像像素数据下可以减少一部分计算量。
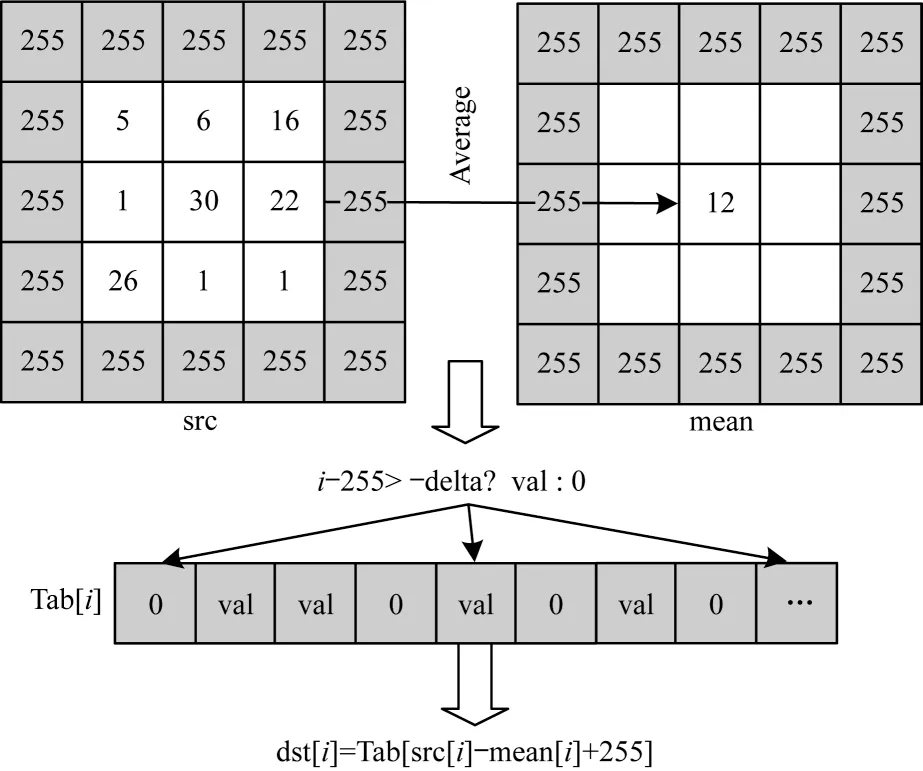
图3 自适应阈值滤波的naive 实现示意图Fig.3 Schematic diagram of naive implementation of adaptive threshold filtering
算术滤波naive 算法实现了单通道图像(只包含一种颜色通道的图像)和三通道图像(R、G、B 图像)像素值的加权算术运算。通过2 幅相同尺寸图像上对应的像素点,将对应通道像素值的和、差、商、积算术运算作为目标像素点值。加权积和加权商算法计算式如下:
其中:sscale为权值;ssaturate将像素值限制在0~255 之间。
压缩滤波在naive 实现中支持单通道和三通道这2 种图像格式,支持将源图像像素值按照行和列压缩的2 种压缩方法。算法原理为求得当前行或列的像素最值、均值或者像素和,用所求值代替源图像的当前行或当前列,使图像一维化。图4 所示为三通道图像数据按照求均值按行压缩以及三通道图像数据求和按列压缩示意图。本文通过压缩滤波将1 个三通道图像变成1 个一维的三通道向量。
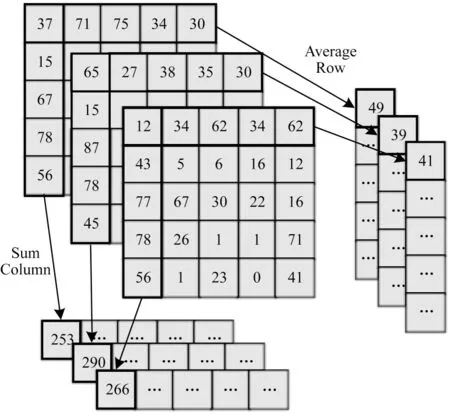
图4 三通道图像压缩滤波算法示意图Fig.4 Schematic diagram of three-channel image compression filtering algorithm
在本文所实现的图像滤波naive 算法中,当算法处理到图像边界像素时,时常会出现超出图像边界的情况。如果不对边界进行处理,那么在访问这些位置时可能会产生越界操作。针对该问题,本文提出如图5 所示的边界处理方法。
该方法包括默认边界、由用户指定的常数边界、用源图像同侧值填充的复制边界、用源图像边界镜像像素值填充的镜像边界。
3.2 访存优化
图像滤波算法本身具有较优的数据独立性、局部性和数据重用性的并行特征,适合在大规模的细粒度图形处理器GPU 中进行处理。图像滤波算法按照计算和访存的特性可以大致分为数据无关算法和数据相关算法。
数据无关算法是指在算法中,源图像各个连续的像素点通过各自单独运算获得目标像素值,各像素点之间没有关联,互不影响,如本文实现的算术滤波和固定阈值的阈值滤波算法。该类算法计算独立并且访存连续,具备良好的并行性。因此,本文对该类算法的优化重点在于提高单个像素点的计算效率、提高数据的访存以及对数据的并行计算效率。
对于这类问题的访存优化,通过同时执行多个处理单元,采用批量读写数据的方式可以极大程度地提升访存效率。在CPU 向GPU 传递数据时,OpenGL 支持纹理和缓冲2 种大规模数据的存储形式。相比缓冲这种通用的存储形式而言,图像滤波算法对图像纹理这种结构化的存储形式更加友好。纹理存储形式也更加适用于计算海量数据的着色器。本文通过纹理来实现大规模图像数据在本地和着色器间的传递和操作,提高计算着色器对图像像素数据的处理效率。
在着色器内部对图像纹理进行读取和写入操作的具体方法有imageLoad()、imageStore(),其中imageLoad()方法的返回值类型是vec4,在单通道图像数据中,本文尝试使用vec4 数据类型将单通道的数据向量化,以达到高效访存的目的。经过实验发现,imageLoad()方法在单通道图像数据中的返回值虽然仍是vec4 类型,但是实际上该方法只支持单独像素单元的存取,在单通道数据中,并不支持使用其他通道。因此,计算着色器内的访存优化以更加合理的线程布局和纹理存取像素值为主的方式实现。
数据相关算法是指目标图像中每个目标像素值计算需要依赖源图像中其他像素值参与的算法。例如,在计算目标像素值时,需要利用源图像锚点像素值周围一定范围内的邻域像素值作为卷积核的一部分,共同参与计算,从而得到目标像素值。本文所实现的形态学滤波、自适应阈值滤波和盒式滤波均为数据相关算法。该类算法的优化重点在于利用数据局部性原理,减少对内存的频繁访问,提高访存,以提高算法的效率和性能。例如,更加充分利用GPU的共享内存或纹理缓存从而减少数据传输和访问的延迟。本文所使用的实验平台采用的共享内存没有性能提升,其原因可能是该设备的GPU 中没有共享内存硬件,也没有高速存储设备做支持。这一点在ARM Mali GPU 的开发 者文档 中得到证实[28],Mali GPU 不为计算着色器实现提供专门的片上共享内存,而是使用系统的RAM 实现相关功能。因此,对于该类算法的优化策略,本文使用纹理访问图像数据、充分利用数据局部性、合理分配线程、提高Cache的命中率,进一步提升访存性能的优化策略性能。
3.3 计算着色器并行优化
3.3.1 并行算法
本文采用计算着色器对图像滤波算法进行并行优化,计算着色器属于无固定输入输出的着色器(可以自定义输入输出变量),是OpenGL 中一种特殊的管线。这种特性使得它具有更强的灵活性,可用于执行各种通用计算任务,而不仅仅局限于图形渲染。本文所提算法采用纹理来存储数据,使得计算着色器在GPU 上执行计算任务时可以并行地直接访问和处理大规模图像数据,无须频繁地访问全局内存,这种方式能有效发挥计算着色器的优势。在本文的工作中并行算法计算的核心是在计算着色器的众多工作组中执行,通过调用gldispatchCompute()方法启动并发计算任务,将图像按照像素点分配线程,在GPU 上进行处理。在GPU 中,全局工作组被划分为多个局部工作组,局部工作组的大小可以自定义,在每个工作组中的若干个工作项通过计算着色器进行运算和操作。二维工作组的划分示意图如图6所示。在计算着色器中,每个像素点在全局中的位置坐标可由当前工作组的坐标、局部工作组大小和工作项坐标表示,即gl_GlobalInvocationID=gl_WorkGroupID*gl_WorkGroup Size+gl_LocalInvocationID。本文在计算着色器内全局的规划线程进行运算和操作。合理划分工作组大小可以在一定程度上有效提升算法性能。
在划分工作组后,OpenGL 的每个工作组都根据计算着色器的核心算法并行地执行相同的运算。所有的计算和操作均在计算着色器内完成。三通道图像并行算法的示意图如图7 所示,pipeline 为仅有计算着色器的特殊管线,每个工作项均进入以计算着色器为核心的特殊管线中。

图7 三通道图像并行算法示意图Fig.7 Schematic diagram of three-channel image parallel algorithm
在形态学滤波的并行算法中,本文无须将图像整体按照行列拆分运算,而是同时开启图像像素点数量的工作项,以单个像素点为单位进行计算。在计算着色器中,本文提取当前锚点附近的滤波窗口大小的像素点,依次比较求出最值,再传入到目标图像中。针对单通道、三通道和四通道图像数据,本文分别采 用OpenGL 自带的GL_R、GL_RGB 和GL_RGBA 向量化的方式来实现。由于OpenGL ES 3.2在计算着色器内仅支持布尔类型、32 bit 整数和浮点操作,因此在8U 图像中,相比单通道数据,三通道数据和四通道数据能更加充分利用存储空间,具有较优的优化效果。
在盒式滤波的并行算法中,本文开辟图像像素点大小的工作项,将每个像素点所在位置作为锚点,向周围扩展滤波窗口大小的像素点,在计算着色器内,将这些像素点求和,并乘以权值(计算均值时为1(/kernel.x*kernel.y))的大小,在计算完成后,将结果传到输出纹理坐标上,每个工作项均执行这一相同计算。
在自定义阈值的阈值滤波并行算法中,本文将阈值和最大值(maxval)作为统一变量,通过统一变量绑定点传入计算着色器内,在计算着色器内判断当前像素值与阈值的大小关系,按照不同的阈值类型,将正确的目标值写入到输出图像所在的纹理坐标中。
在自适应的阈值滤波中,本文将经过盒式滤波和高斯滤波计算后的中间矩阵mean 和源图像src 一起传入计算着色器中,用式(15)和式(16)替代naive实现中使用的查表法,减小Tab 表所占用的内存空间和多次访存开销,将查表法的功能拆分重组,在计算着色器内使用如下公式精简计算,进一步提升算法性能:
在算术滤波的并行算法中,本文针对2 幅图像的像素值进行并行算术运算。为实现该目标,本文同时将2 幅图像的像素值绑定到纹理单元并传入计算着色器中,在着色器内部对2 幅图像的每个坐标位置数据进行加、减、乘、除算术运算,各纹理坐标对应像素点并行地通过计算着色器,将计算结果传入至输出图像纹理单元中。算术滤波算法是典型的数据无关算法,单独目标像素值的计算只需要2 个源图像对应的坐标值和权值即可,不需要其他源像素值和中间计算结果的参与。这种算法对于并行访存和并行计算非常友好。本文优化算法在实验设备中相对于OpenCV 开源库中对应算法的性能提高7 倍左右。
在压缩滤波的并行算法中,本文基于算法原理将源图像根据最值、均值以及求和压缩成一行或者一列。在划分工作组时根据目标矩阵的情况(即一行或者一列)将工作组划分为对访存和计算更加友好的状态。例如,将矩阵压缩为一列时,本文将每行作为1 个工作组,并将工作组大小设置为height 为1 的块。本文采用这种方式在每个工作组中计算当前行的数据,从而减少重复的计算次数和访存操作。
3.3.2 边界处理优化
在并行算法的边界处理中,由于每个线程都通过相同的计算着色器,因此并行算法将边界处理移至计算着色器中。在这种情况下,本文只须在着色器中判断当前计算所需坐标像素是否在源图像内部。如果超出了源图像的边界,本文赋予其对应边界镜像坐标值或特定值等边缘填充值即可。该方案在一定程度上提升了并行算法的整体性能,减少处理图像边界所带来的大部分空间和时间开销。
3.3.3 数据类型优化
在数据类型方面,本文所使用的OpenGL ES 3.2目前支持32 bit 整数、浮点数和布尔类型数据,对于其他数据类型并不支持。本文提供除整数和32 bit浮点数以下的其他数据解决方案:将8UC1 数据转换为GL_R32UI 类 型,将8UC3 和8UC4 数据转换为GL_RGBA32UI 类型,目前本文已经安全地支持所有常用的8~32 bit 的有符号数和无符号数在OpenGL ES 进行传输和运算。
3.4 数据通信优化
在CPU+GPU 的异构平台下,将数据在CPU 和GPU 之间进行高效的通信是非常重要的,这也是本文优化的重点方向。为此,本文分别针对小规模数据和大规模数据提出不同的解决方案。
在小规模数据方面,OpenGL 提供统一变量(Uniform)关键字,允许将这些数据作为全局变量通过glUniform*()方法绑定到缓冲区。由于本文所使用的计算着色器具有在着色器和本地之间保持同步和共享数据传输的特性,因此将缓冲区作为存储和传输小规模数据的媒介。
对于大规模数据,采用Uniform 需要依次绑定,这显然是非常低效的。为此,OpenGL 提供一致区块,将需要输入和输出计算着色器的大量全局数据映射在统一缓冲对象(Uniform Buffer Object,UBO)上,并通过绑定点使其相互对应。UBO 绑定数据示意图如图8 所示。
本文在图像数据由CPU 向GPU 上传的过程和从GPU 向CPU 下载的过程中采用一致区块,在GPU部分采用更利于计算着色器进行并行访存和计算的纹理存储形式。在OpenGL ES 中纹理也可以绑定在Uniform 绑定点上,本文经过纹理坐标在计算着色器内部访问图像像素点,完成与图像滤波相关的操作和计算。
4 实验结果与分析
4.1 实验环境搭建
本文实现的高性能图像滤波算法库在天玑1200处理器上进行运行测试。该处理器包含1 个主频为3.0 GHz 的A78 大核心、3 个主频 为2.6 GHz 的A78中核心,以及4 个主频为2.04 GHz 的A55 小核心。此外,处理器还搭载了基于ARM Mali-G77 架构的Mali-G77 MC9 GPU。实验中采用了4.5.5 版本的OpenCV 库和3.2 版本的OpenGL ES 接口。具体的实验环境配置如表1 所示。
4.2 性能对比分析
本文使用的所有源图像数据都是通过程序生成的随机数,使用随机数生成的图像数据能够消除真实图像数据的特殊性和偏差,从而更准确地评估不同算法和优化技术的性能,同时确保了实验结果的可重复性,使得其他研究人员可以在相同条件下进行复现和比较,使用随机数生成的图像数据也使得实验更具普适性。因此,本文实验结果不仅适用于特定类型或特定领域的图像数据,而且具有一般性和广泛适应性,对于算法和优化技术的推广和应用具有重要意义。此外,本文调用了部分OpenCV 库中图像滤波算法与本文所提的优化算法进行性能对比。除非特别说明,否则本文在调用这些算法时均使用了默认参数,以确保对比实验的公平性和一致性。
本文实现的形态学滤波与OpenCV 库中morphologyEx()函数在8UC3(三通道的8 bit 无符号整数)的图像数据下进行对比。形态学滤波性能对比如图9 所示(3×3、5×5、7×7 表示卷积窗口的大小)。本文将算法中iterations 参数设置为1,得到最直观的性能差异。在不同规模图像中,本文实现的基于OpenGL ES 的优化算法性能提升最大约为30.543 倍,性能提升最小约为1.994 倍,平均性能提升约为16.269 倍。
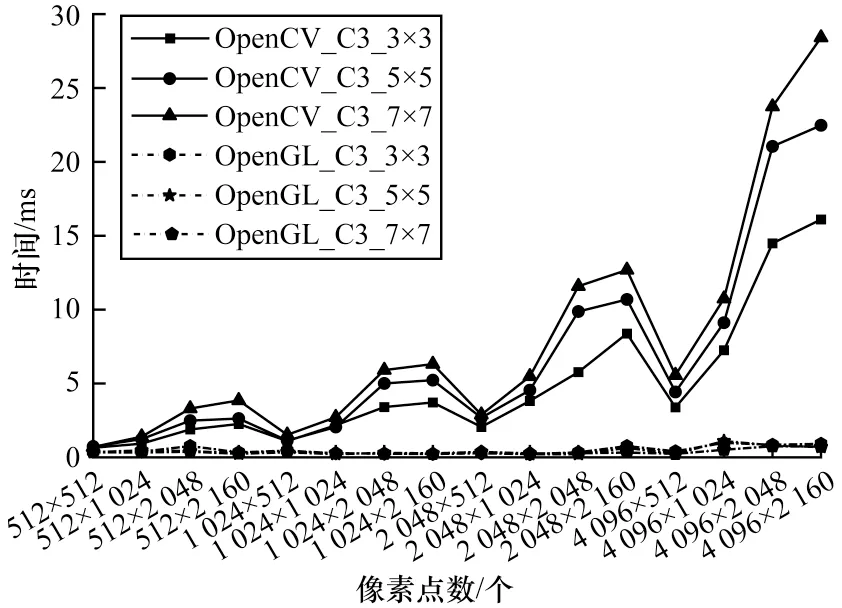
图9 形态学滤波性能对比Fig.9 Comparison of morphological filtering performance
从图9 可以看出,在OpenCV 算法中,随着卷积窗口变大,相同计算规模下的算法耗时有不同程度增加,导致算法的整体性能下降。本文所实现的优化算法OpenGL 在相同情况下并未显示出明显的性能差异,其原因为在卷积窗口由3×3 变为7×7 时,计算单个目标像素值需要参与运算的数据由9 个(3×3)增加到49 个(7×7),即每个目标像素值的计算需要增加40 个数据。在OpenCV 的算法中,整幅图像所有像素值的计算耗时会累积,从而导致算法的整体性能下降。相比OpenCV,本文实现的基于OpenGL ES优化算法将由增大滤波窗口所带来的负载均衡地分配到GPU 的每个核心上(从算法的角度将负载平均分配到每个工作项上)进行并行执行,而不是在单个计算核心上累积计算耗时。因此,滤波窗口的变化对该算法性能的影响大幅减小。
本文实现的盒式滤波优化算法与OpenCV 的boxFilter()函数进行对比。图10 所示为8UC1(单通道的8 bit 无符号整数)盒式滤波性能对比。8UC1 图像数据中性能最高提升34.425 倍,最低提升1.602 倍,平均提升15.299 倍。图11 所示为8UC3 盒式滤波性能对比。8UC3 图像数据下性能最高提升110.018 倍,最低提升3.903 倍,平均提升42.150 倍。从图10和图11可以看出,本文实现的基于OpenGL ES优化算法在处理三通道数据时表现更明显的优化效果。这是因为在进行三通道数据运算时,本文进一步利用OpenGL 中纹理的特性,对三通道图像中每个像素点上的3 个8U 数据进行向量化操作,使得数据访问更加连续且高效。该方法将优化前使用3 条指令才能完成的工作减少到1 条指令,显著提升算法的执行性能和效率。

图10 8UC1 盒式滤波性能对比Fig.10 Comparison of 8UC1 box filtering performance

图11 8UC3 盒式滤波性能对比Fig.11 Comparison of 8UC3 box filtering performance
本文实现的自适应阈值滤波算法与OpenCV 的adaptiveThreshold()函数性能对比如图12 所示,将对比的2 个算法adaptiveMethod 参数均设置为ADAPTIVE_THRESH_GAUSSIAN_C,threshold--Type参数均设置为THRESH_BINARY。本文实现的基于OpenGL ES 优化算法性能最高提升39.251 倍,最低提升2.125 倍,平均提升20.688 倍。

图12 自适应阈值滤波性能对比Fig.12 Comparison of adaptive threshold filtering performance
在本文实现的算术滤波算法中,除法(DIV,divide)算法与OpenCV 的divide()函数性能对比如图13 所示。该算法性能最高提升13.365 倍,最低提升1.509 倍,平均提升7.437 倍。
在压缩滤波中,最值(MAX)、均值(AVG)以及求和(SUM)算法与OpenCV 中的reduce()函数的性能对比如图14 所示。相比OpenCV 中对应算法,本文优化算法性能最高提升57.863 倍,最低提升1.509 倍,平均提升29.686 倍。

图14 压缩滤波性能对比Fig.14 Comparison of compression filtering performance
从图9~图14 可以看出,随着图像规模的增大,本文优化算法相对于OpenCV 中对应算法的性能提升也逐渐增大。这种性能提升的原因主要有:本文采用计算着色器将整幅图像的计算任务均匀分配到GPU 的多个核心上,能够更充分地利用GPU 的计算资源,有效提高算法的并行性;本文通过纹理存储图像数据的方式减少对图像数据的频繁读写操作,从而减少访存延迟和数据传输开销,进一步提升访存性能。当图像数据由4 096×512 个增加到4 096×2 048 个时,图像数据增加到原来的4 倍。在OpenCV 算法中,处理这些数据所需的时间在单个核心上累积,导致大规模图像的计算时间呈倍数增加。本文优化算法能够将计算任务并行地分配到GPU的多个计算核心上,该计算核心同时处理这些计算任务,更充分地利用GPU 的计算资源,使得性能提升逐渐增大。随着图像规模的增大,本文优化算法在并行性和访存优化方面的优势也变得更加显著。
此外,OpenCV 对应的算法出现了一些明显的性能下降点。这是因为在该实验中,本文按照从小到大的趋势分别设置了图像的长和宽。当图像的宽度从2 160 个像素点减小到512 个像素点时,因图像规模变小,相应算法的运行时间也会缩短。
整体上,本文实现的基于移动Android 端使用OpenGL ES 的图像滤波算法性能明显优于OpenCV库中的相关算法。实验结果表明,本文实现的图像滤波算法进行的一系列优化手段是有效的。
5 结束语
本文实现针对移动Android平台基于OpenGL ES的图像滤波算法库,实现了形态学滤波、多种阈值滤波、盒式滤波、压缩滤波、算术滤波。通过OpenGL计算着色器、纹理和统一变量对算法进行优化,总体上其性能与OpenCV 开源库相关算法相比得到显著提高,平均性能为OpenCV 的21.561 倍,在优化性能的同时也为基于Android 平台使用OpenGL ES 的高性能图像滤波算法提供了新的优化方案。本文所实现的图像滤波算法全面适配8U 数据类型且满足少量32S 数据类型。下一步将在更多数据类型上对算法的实现和优化进行研究,以扩大高性能图像滤波算法库的数据类型应用场景。
猜你喜欢
智能计算机与应用(2020年6期)2020-11-11 08:02:18
计算机技术与发展(2020年7期)2020-07-15 05:04:26
中国新通信(2020年2期)2020-06-24 03:06:44
软件(2020年3期)2020-04-20 01:45:18
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
Coco薇(2017年8期)2017-08-03 15:23:38
Coco薇(2015年5期)2016-03-29 23:22:15
空间控制技术与应用(2015年3期)2015-06-05 14:30:31
遥测遥控(2015年2期)2015-04-23 08:15:18
电子设计工程(2014年20期)2014-02-27 12:01:00
