
基于双通道混合神经网络的房颤风险预测模型
2023-11-18 03:33:06柯博文陈艳红
计算机工程 2023年11期
柯博文,杨 湘,陈艳红
(1.武汉科技大学 计算机科学与技术学院,武汉 430065;2.国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室,北京 100038;3.武汉亚洲心脏病医院 心血管内科,武汉 430022)
0 概述
心房颤动是心血管疾病中常见的慢性心律失常[1],随着年龄增长,患病率逐渐上升。房颤具有隐秘性,患者在病发前不会出现任何明显的身体异常,但病发时容易致命[2]。因此,针对心房颤动的早期筛查和风险预测工作是非常有必要的。
心电图(Electrocardiogram,ECG)是一种常用的心房颤动诊断手段,但具有普适性的电子健康病历(Electronic Health Records,EHR)更适合用于心房颤动的早期筛查工作[3]。EHR 直接反应了患者一段时间内的身体健康状况,其中涵盖了患者一段时间内做过的诊断、检查检验、用药等信息。不同于心电图,EHR 来源于患者的日常治疗过程,是一种较易获取的数据。
受益于近些年来深度学习的发展,卷积神经网络(Convolution Neural Network,CNN)[4-5]和循环神经网络(Recurrent Neural Network,RNN)[6-7]被广泛应用于疾病风险预测任务。CNN 是一个能够提取数据中的局部特征,并不断汇聚以反映数据整体特征的深度神经网络,在图像处理[8]、语音识别[9]等领域表现理想。EHR 涵盖了非常多的医疗事件,医疗事件之间的多依赖关系使得数据的全局特征更为重要,而CNN 无法完全提取到数据的全局特征。
除了EHR 的数据特性以外,在实际临床诊断过程中,房颤的发生也受到其他医学指标的影响。临床医学[10]与早期的分析方法[11]已经证实,高血压、甲状腺功能异常等指标会直接导致房颤发生,因此重点关注这些特定指标是非常有必要的。
为了克服上述挑战,本文提出因素风险-注意神经网络(Factor Risk-Attention Neural Network,FRANN),FR-ANN 的一个通道通过引入注意力机制来提取数据的全局特征,另一个通道对一些重要的医疗事件独立进行特征提取,解决CNN 无法有效提取到数据全局特征的问题。根据患者近几次就诊记录,预测患者半年内是否有患病风险,并采用专用通道提取单个医疗事件的变化特征,捕捉医疗事件对结果的直接影响。在MIT 的公共数据集MIMIC-Ⅲ[12]和武汉亚洲心脏病医院提供的私有数据集上验证FR-ANN 在房颤风险预测工作中的有效性。
1 相关研究
在现代医学领域,基于EHR 的房颤早期筛查技术对于降低疾病致死率具有重要意义,它能够帮助医生预防疾病的发生。EHR 数据包含大量的医疗事件,主要由医疗诊断和检查检验构成。特征提取是疾病预测工作中最重要的一步,它将经过特征工程的数据输入到模型中,模型通过手动或自动的方式提取特征,最后预测结果。
在早期的疾病预测任务研究中,许多研究人员通过逻辑回归、决策树、随机森林、贝叶斯网络等机器学习算法从EHR 中提取与患者相关的特征[13]。机器学习算法能够结合临床医学知识,帮助研究人员重建疾病的潜在机制,构建符合任务特点的框架。但这些方法建立在手动特征提取的模式之上,需要加入大量的医学专业知识以及专家辅助完成特征提取工作,这将会限制实际应用的适用性。
随着计算机性能逐渐提升,更多的研究偏向于使用深度学习方法对EHR 数据进行建模。在医学领域,深度学习的自动特征提取模式使其使用范围非常广泛,它不需要手动加入医学专业知识。CNN是疾病风险预测任务中最常用的深度神经网络结构之一[14],能够提取到EHR 中的局部特征,通过增加模型深度的方式建立医疗事件之间的联系,其池化层能够对特征进行压缩与下采样,以扩大感知视野。LANDI 等[15]使用CNN 提取医疗事件的时间特征,并预测最终结果。文献[16]使用基于CNN 的方法预测心力衰竭的患病风险。CNN 擅于捕获数据的局部特征,然而EHR 的全局特征使CNN 方法的分类效果与医疗事件序列的排列规则具有紧密联系。值得注意的是,FRDLS 通过多种分析方法计算每个医疗事件的得分,根据得分从高到低重新排列医疗事件序列。通过不同的分析方法得到多种排列规则,并对多种排列规则的数据同时进行建模,分析排列规则对结果的影响,提供几种性能较优的排列方式。
RNN[17-19]同样适用于疾病风险预测任务。RNN善于通过链式的方式将多个医疗事件联系起来,使前后医疗事件之间的时间关系显而易见。文献[20]将时间1 到t的医疗代码序列输入Bi-LSTM 模型中,从而预测第t+1 次的医疗代码。双向LSTM 很好地保留了前t次医疗代码之间的时序关系,以此推断出第t+1 次的结果。XU 等[21]将医疗 事件按 时间排 序输入到LSTM 中,提取医疗事件之间的时间特征。RNN 对于数据的时序关系是非常敏感的,但是将EHR 数据链式排列时,并不能直接断定前后两个医疗事件存在潜在多依赖关系。虽然LSTM 加入了“门”机制,但是每个单元的计算过程依然依赖于上一个单元,这可能会加入原本不存在的潜在关系。
近年来,随着自然语言处理的发展,注意力(Attention)机制[22]开始被普及。注意力机制并行计算的特点降低了其性能消耗。在注意力机制的特征提取过程中,每个医疗事件的特征提取过程相对独立,但在提取过程中医疗事件之间又相互依赖,清晰的界限能够很好地解决数据存在多依赖关系带来的全局特征问题。文献[23]引入Attention 机制提取每个医疗事件对结果的贡献,然后通过一个3 层的多层感知机(Multilayer Perceptron,MLP)得到预测结果。在MLP 之前加入注意力机制,相当于先进行一次特征提取,能够降低模型的资源消耗,提高计算效率。文献[24]基于LSTM 结构在医疗事件和就诊记录两个级别分别加入注意力机制预测哮喘疾病的风险。TSANN 加入的两层注意力机制能够分析单次就诊与单个事件在各自维度内的权重,并提供就诊和医疗事件两个维度的事后可解释性。文献[25]通过构造多尺度的注意力机制的方式对单次就诊进行建模,然后将多尺度信息汇集,减少序列长度。多尺度注意力机制可以理解为多个局部注意力机制,这种方式可以定制化地获取数据不同尺度的特征,贴合任务特性。
目前绝大多数的研究都是基于深度学习进行的,这得益于自动特征提取模式。对于疾病风险预测任务来说,深度学习有很多方法可以使用,但选择符合数据与疾病特性的方法才是解决问题的关键。总的来说,CNN 适用于提取数据的局部关系,以局部特征反映全局特征;RNN 的结构优势使得它善于提取数据的时序性特征;注意力机制使用较少的参数提取数据的全局特征,并挖掘数据之间的潜在依赖关系。
以上方法均在考虑如何解决数据特性,除此之外,疾病带来的特性同样重要。年龄较大是最有可能直接导致房颤发生的因素之一,但更深层次的原因是患有多种其他疾病导致心房颤动发生的概率上升,心房颤动的并发性需要引起重视。现有的临床医学知识已经可以筛选出一部分与心房颤动相关性较高的医疗事件,例如高血压、甲状腺功能等,独立捕获这些医疗事件对心房颤动的预测非常必要。
2 心房颤动风险预测模型
心房颤动的疾病风险预测工作可以看作是一个二分类任务,即是否患有心房颤动。本文将患有房颤的样本分为阳性样本(正样本),未患有房颤的样本分为阴性样本(负样本)。本节将描述FR-ANN 的模型结构,并介绍FR-ANN 中的每个模块。
2.1 数据表示
本文数据集以病人为单位,用X代表每个病人。每个病人的EHR 数据可构成一个二维矩阵,如式(1)所示:
其中:ci表示病人的第i次就诊记录,每次就诊记录中包含多个医疗事件,即ci=[si,1,si,2,…,si,m],si,m表示病人的第i次就诊记录中的第m个医疗事件。
本文模型将从时间序列特征分析通道和单指标特征分析通道两个不同的通道进行分析,它们的输入由原始EHR 矩阵切割得到。图1 所示为数据切割的过程。EHR 矩阵纵向切割得到多个医疗事件向量,即Sj代表由第j个医疗事件在多次就诊记录中的表现构成的向量,本文根据医学专业知识从m个医疗事件中筛选出100 多个对房颤影响较大的医疗事件(表1 给出了部分筛选出的医疗事件),将这些筛选后的医疗事件作为最终得到的Sj=[s1,j,s2,j,…,sn,j],j∊[1,m]医疗事 件向量序列MR=[S1,S2,…,Sm]。由EHR 矩阵横向切割将得到多个就诊记录向量,即ci=[si,1,si,2,…,si,m],i∊[1,n],ci代表第i次就诊记录,多个就诊记录向量构成最终的就诊记录向量序列VR=[c1,c2,…,cn]。数据切割过程只是把病人的EHR 矩阵转换成了两种形式,它们依然是同源的数据。

表1 部分筛选出的医疗事件(用于单指标特征分析通道)Table 1 Selected medical events(for single indicator characteristic analysis channel)
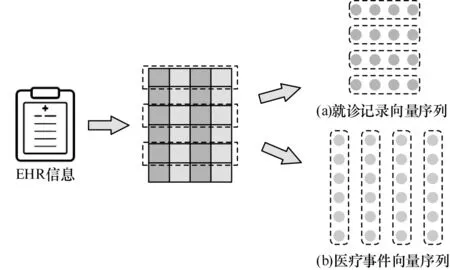
图1 数据切割过程Fig.1 Process of data cutting
2.2 模型结构
图2 所示为FR-ANN 的模型结构。
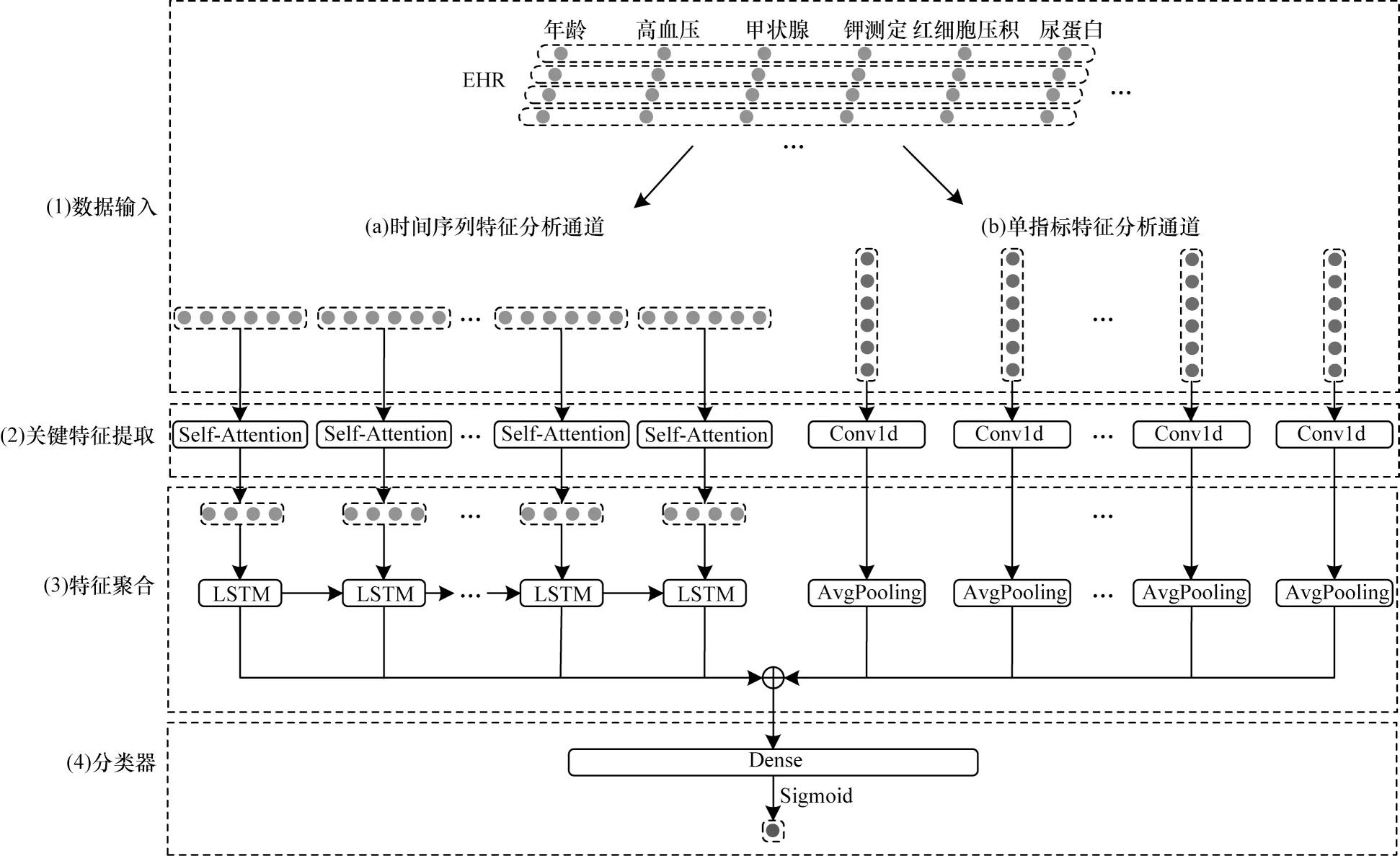
图2 FR-ANN 模型结构Fig.2 Structure of FR-ANN model
由图2 可知,FR-ANN 模型将就诊记录向量序列VR输入到时间序列特征分析通道,将医疗事件向量序列MR输入到单指标特征分析通道。
单指标特征分析通道会对医疗事件向量序列MR中的每个医疗事件向量独立分析,以提取每个医疗事件在多次就诊中不同表现的综合特征,并汇总得到所有医疗事件的综合变化特征coutput;时间序列特征分析通道会先对VR中的每条就诊记录向量单独进行特征提取与注意力分析,并将多条就诊记录向量的特征汇总输入到一个LSTM 中,根据前几次的就诊记录得到下一次的预测状态信息hn。分类器模块把2 个通道的输出拼接,通过多个全连接层与一个Sigmoid 分类器得到最终预测结果。具体的计算过程如下:
其中:W1∊Rr×(4+4m)、W2∊Rs×r、b1∊Rr×1、b2∊Rs×1是全连接层的参数矩阵;yD是全连接层的计算结果;y是yD通过Sigmoid 函数得到的最终预测结果。
数据样本比例不平衡是医疗数据的通病,本文使用的数据同样存在此类问题。为了与医学临床过程保持一致,本文在模型方法上做出一些优化,而不是直接增加正样本的占比。在损失函数的选择上,本文使用了Focal Loss[26]代替常用的二值交叉熵损失函数作为FR-ANN 的损失函数。这是因为Focal Loss 的出现就是为了解决训练集正负样本极度不平衡的问题。损失函数的计算过程如下:
其中:y为标签值为模型预测值;α和γ是超参数,α用于调和正负样本比例,γ负责缓解易分类样本(负样本)的影响。实验过程中使用的超参数均设置为Focal Loss 推荐的值,即α=0.25、γ=2。
2.3 时间序列特征分析通道
EHR 数据中的潜在关系可分为两种形式:单个就诊记录形成的时间片内和多个就诊记录之间。在单个时间片内,各个医疗事件的指标综合反映了患者一段时间内的身体状况;在多个就诊记录之间,每个就诊记录根据时间顺序排列。分级提取两种潜在特征是有必要的。首先,本文基于注意力机制提取每个时间片内医疗事件之间的多依赖潜在特征,然后再使用LSTM 提取多个就诊记录之间的时序特征,最后将提取到的特征输入到分类器中。
2.3.1 基于注意力机制的片内特征提取
在时间序列特征分析通道中,本文拿到患者单次就诊 记录向 量ci=[si,1,si,2,…,si,m],i∊[1,n]。CNN在特征提取工作中,由于卷积核大小的限制,一般通过增加模型深度的方法达到提取与距离较远的单元之间的潜在关系的目的。而注意力机制由于并行计算的优势,可以独立考虑医疗事件与其他事件之间的潜在关系,不会受到距离与其他因素的影响。并且注意力机制计算得到的注意力分布体现了单个医疗事件在整体上的权重,增强了模型的可解释性。所以本文在FR-ANN 中引入注意力机制,代替时间序列特征分析通道中的常规卷积方法。
对于每一个就诊记录ci,本文都将接入一个独立的注意力层。注意力机制的计算过程可以简写为:
其中:ci表示病人第i次就诊记录;ai表示ci计算得到的注意力权重是可训练参数矩阵;Dk表示ci的维度m,即医疗事件的个数。
2.3.2 基于LSTM 的时序特征提取
AATTs=[a1,a2,…,an]是多个自注意力层的输出构成的注意力权重序列,at对应患者的第t次就诊记录。多次就诊记录之间存在的时序关系反映了患者在一段时间内的身体变化趋势。LSTM 既能够捕捉多次就诊记录之间的时序关系,又可以保留每个就诊记录内的潜在关系。所以本文把LSTM 放在自注意力层之后,用于提取多个就诊之间的时序特征。
整个LSTM 模块由一层LSTM 构成,具有n个隐藏层单元。LSTM 模块的结构图如图3 所示。对于LSTM 的每个单元而言,它的输入由一个自注意力层的输出at得到,AATTs通过LSTM 层得到多个隐藏层状态h1,h2,…,hn,本文取最后一个状态hn作为LSTM 层的输出。LSTM 每个单元中的计算过程如下:
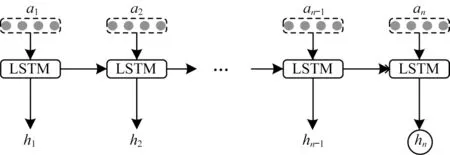
图3 LSTM 模块的结构Fig.3 Structure of LSTM module
其中:第t次的输入at和第t-1 次的隐藏状态ht-1的拼接得到[ht-1,at],构成每个单元的输入;在保留隐藏状态过程中,主要起作用的是记忆门和输出门ot;⊗表示逐元素相乘。
2.4 单指标特征分析通道
医学临床知识能够筛选出与心房颤动相关性较大的医疗事件,本文专门在单指标特征分析通道上独立提取每个筛选得到的医疗事件在多个时间片之间的变化趋势,加强对结果的预测能力。本文通过CNN 提取单个医疗事件在多次就诊中的变化特征,将多个医疗事件的变化特征拼接得到的综合变化特征coutput输入到分类器中,由分类器拼接特征并预测结果。
房颤是一种慢性疾病,它与许多疾病关系密切。现代临床医学已经证实,高血压、心动过速等症状会直接导致房颤的发生。第2.1 节已经筛选出部分相关性较大的医疗事件作为此通道的输入。因为患者的就诊次数在4 次左右,所以CNN 的卷积核可以轻松地帮助本文模型捕捉到单个医疗事件在较低跨度上的变化特征。由于房颤的治疗过程较为漫长,因此更早的记录产生的影响会逐渐减弱。所以本文把卷积核的大小设置为1×2,以关注单个医疗事件前后两次就诊之间的变化趋势。
在得到单个医疗事件的变化曲线之后,本文还需要对特征进行收敛。平均池化层(Average Pooling Layer)和最大 池化层(Maximum Pooling Layer)是两种常用的池化手段,前者保留信息的平均值,后者保留信息的最大值。对于单个医疗事件的变化特征而言,平均值能够权衡医疗事件在每一次就诊时的表现,而最大值只记录了极端情况。结合实际情况,平均池化层更适用于收敛单个医疗事件的变化特征。
单指标特征分析通道的模块结构如图4 所示。对于每个医疗事件向量Sj,都将经过3 个卷积层和1 个平均池化层,卷积层的通道数均为16,卷积核大小均为2×1,平均池化层的卷积核均为16×1。计算过程如下:

图4 单指标特征分析通道的模块结构Fig.4 Module structure of single index feature analysis channel
对于每个医疗事件ei都有输出Aj,将所有的输出拼接得到序列coutput=[A1,A2,…,Am]。
3 实验结果与分析
3.1 研究的数据
本研究使用的数据来源于武汉亚洲心脏病医院房颤中心的私有数据库和MIT 的公开数据库MIMIC-Ⅲ。私有数据集经过武汉亚洲心脏病医院伦理委员会批准,所有数据都经过去标识化处理,即去除了所有可能跟患者个人隐私相关的信息。
本文从数据库中收集病人的诊断数据、检查检验数据和人口学数据,将其组合得到患者的电子病历信息。对于各种医疗事件,来自亚心的私有数据库保留频率不小于1 000 次的事件,最终筛选出480 种诊断、检查检验等项目;而MIMIC-Ⅲ数据库保留了频率不小于5 000 次的事件,最终筛选出241 种诊断、检查检验等项目。本文统计了所有病人的就诊次数,最终确定将患者的前4 次就诊记录作为实验用数据,以预测患者半年内是否会发生房颤。
3.2 实验环境
本文涉及的所有代码均基于Python3.8.3 完成。机器学习模型通过sklearn 实现,深度学习模型基于Keras2.4.3 实现。在深度学习模型中,自动学习的参数使用Adam 优化器自动更新,初始学习率为0.001,训练20 个轮次。所有模型均采用批量大小为1 024的小批量训练方式。深度学习模型使用Dropout 和L1、L2 正则化防止过拟合问题。在训练开始前将数据集随机打乱,再以6∶2∶2 的比例区分训练集、验证集和测试集。在每个轮次过程中,模型利用训练集来训练模型,使用验证集验证模型训练后的结果并自动调整可训练参数。在所有轮次训练完成后,使用测试集测试模型的最终性能,并计算评价指标。
3.3 评价指标
在疾病预测任务中,如何评判模型的性能非常重要。在实验过程中,本文使用了4 种评价指标:精确率(P)、召回率(R)、F1 值(F1)以及AUC 曲线。计算式如下:
其中:精确率指的是预测为患病的结果中实际患病的占比;召回率指的是对于实际患病的样本中,预测正确(预测为患病)的比例;精确率体现了模型对样本整体预测的准确性;召回率体现了对患病群体判断的准确性;F1 值兼顾了精确率和召回率,是一种综合性能指标;AUC 代表模型区分阳性样本和阴性样本的能力,数值越高,表示模型的分辨能力越强。
3.4 基线模型
为了验证模型性能,本文选取了几种机器学习算法以及基于EHR 数据并应用在疾病风险预测任务上的深度学习模型,和本文提出的FR-ANN 模型进行比较。本文所选用的机器学习算法包括逻辑回归(Logistic Regression,LR)和随机森林(Random Forest,RF)。深度学习模型分别是基于MLP 与注意力机制 的MLP_Attention[23]、基 于CNN 的FRDLS[16]和基于LSTM 与注意力机制的TSANN[24]。
3.5 实验结果
实验分别在来自武汉亚洲心脏病医院的私有数据库(简称亚心数据库)和MIT 的公开数据库MIMIC-Ⅲ中进行。基线模型与FR-ANN 模型的性能评分如表2、表3 所示。
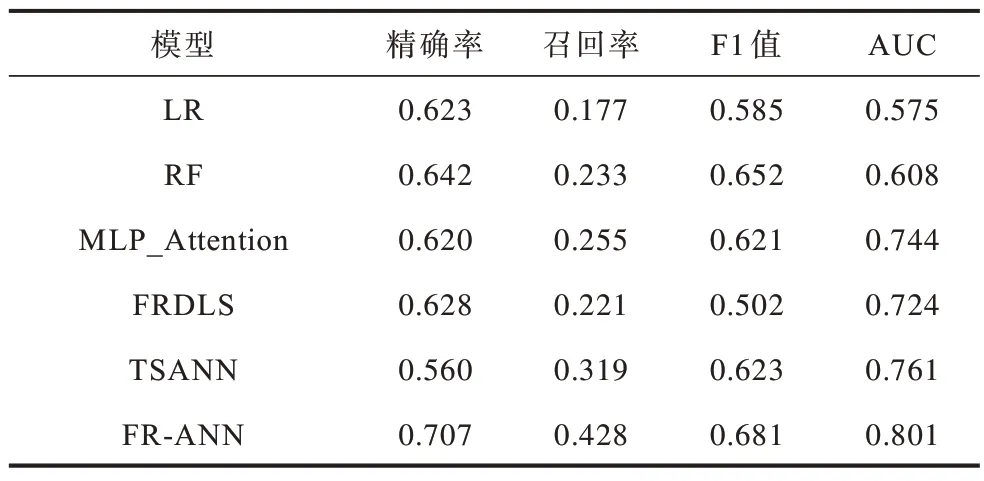
表2 对比模型评分表(亚心数据库)Table 2 Scoring table of comparison model(Yaxin database)
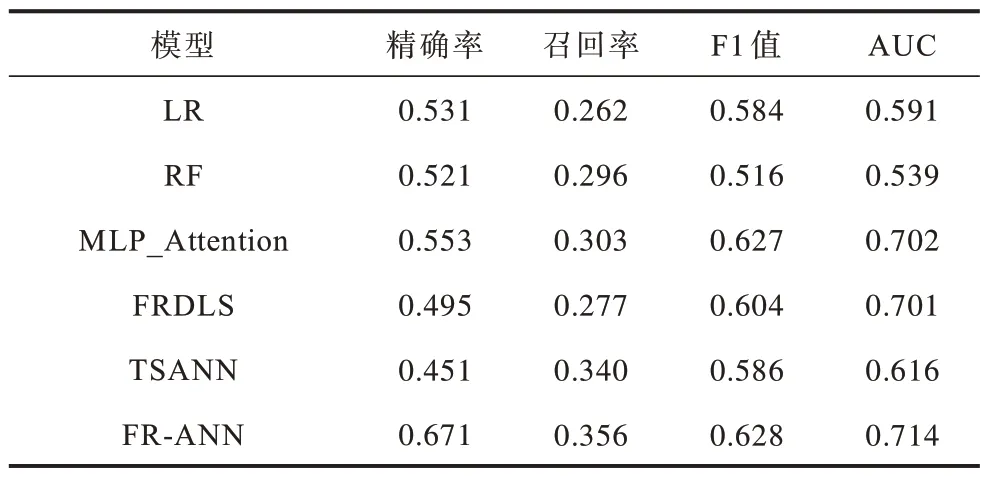
表3 对比模型评分表(MIMIC-Ⅲ数据库)Table 3 Scoring table of comparison model(MIMIC-Ⅲ database)
在基于私有数据集的实验中,MLP_Attention 和FRDLS 的AUC 分别为0.744 和0.724。多层感知机是一种全连接的神经网络,虽然MLP 增加了参数数量,但它的性能优于FRDLS 模型,而TSANN 模型的召回率要优于前两者,这归功于注意力机制准确地注意到了医疗事件之间的多依赖关系,捕捉到了数据中的潜在知识。FR-ANN 模型的时间序列特征分析通道完成了医疗事件之间的多依赖关系与就诊记录之间时序关系的特征提取工作;单指标特征分析通道通过提取每个医疗事件的变化特征,增加FR-ANN 模型对重要医疗事件的关注度,两者结合使得FR-ANN模型的各项指标均优于几种基线模型。
3.6 消融实验
首先,本文在消融实验中以仅使用时间序列特征分析通道和仅使用单指标特征分析通道两种模式预测患者的心房颤动风险,并与FR-ANN 模型进行比较,以分析单个通道对FR-ANN 模型的贡献。其次,本文还将FR-ANN 模型的时间序列特征分析通道中的注意力层替换成卷积层,分析两种不同模块给FR-ANN 模型带来的影响。消融实验均在亚心数据库上进行。
图5 为消融实验评分图。图5(a)展示了两种模式以及FR-ANN 的性能评分。仅使用单个通道时,各项性能指标读数有所下降,两个通道的差异主要体现在精确率和召回率上。时间序列特征分析通道的召回率有所提升,这归功于注意力机制能在全局范围内提取医疗事件之间的潜在关系。单指标特征分析通道的精确率较高,这是因为此通道的输入均是经过医学专业知识鉴定的、与房颤疾病相关性较大的医疗事件,使得单指标特征分析通道能够直接聚焦于疾病相关性较大的医疗事件,排除了其他医疗事件的干扰。

图5 消融实验评分图Fig.5 Rating chart of ablation experiment
从性能与功能上看,FR-ANN 模型中的两个通道各自承担了不同的职责。时间序列特征分析通道采用多层级的特征提取方法,在医疗事件层级提取医疗事件之间的多依赖关系,在就诊记录层级提取就诊记录之间的时序特征。单指标特征分析通道针对每个输入的医疗事件独立分析,并且输入的医疗事件由医学临床知识筛选得到,能够加强模型的可解释性。
图5(b)展示了FR-ANN 模型的时间序列特征分析通道中,使用CNN 或者使用注意力机制两种情况下的性能差异。由实验结果可看出,引入注意力机制主要提升了召回率。相较于CNN,注意力机制的优势在于全局性,这使得它能够兼顾所有医疗事件之间的潜在关系。实验结果表明,使用注意力机制的FR-ANN:Attention 的各项指标均优于FR-ANN:Conv1d。
3.7 结果分析
在临床治疗过程中,医生往往需要结合多项指标综合分析才能给出治疗方案。常见的诊断依据包含高血压、冠心病等与心脏、血液相关的疾病,也包括钾测定、血糖、血清总蛋白等检查检验指标。而FR-ANN 模型在训练过程中会自动学习这些模式,本文引入的注意力机制通过分析医疗事件之间的潜在依赖关系,得到每个医疗事件在整个集合中的注意力权重,权重越高表示它越可能导致房颤发生。图6 所示为在亚心数据库中FR-ANN 的注意力层输出的注意力分布结果。
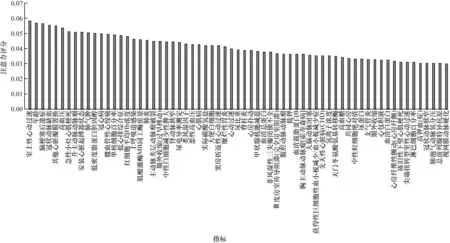
图6 FR-ANN 自注意力层输出的注意力分布Fig.6 Attention distribution outputing by FR-ANN self attention level
在注意力评分超过0.03 的医疗事件中,多数指标是与心血管疾病相关的,例如心包积液、心房扑动、冠心病、高血压、胆固醇等指标,这些指标均预示着人体健康状况异常,提高心房颤动发生的概率。
由图6 可知,心房颤动与其他心血管类疾病具有非常大的关联性,同时也受到高血糖、高血压等其他疾病的影响。并且当蛋白胆固醇、血清蛋白等常规检查检验指标异常时,也需要结合其他指标综合考虑心房颤动的风险。注意力分布得到的信息与临床诊断结果较为接近,注意力机制不仅注意到了高血压、高血糖等相关性较大的医疗事件,而且能发现一些常规检查检验指标对房颤的影响,例如红细胞浓度、钾测定、血清蛋白等。
图6 的注意力分布的结果表明,以上对注意力权重的分析结论与临床医学知识相吻合,能够为临床诊断提供建议。
4 结束语
基于EHR 的心房颤动风险预测有助于更早地预防心房颤动。本文提出一种新的基于深度学习的模型FR-ANN,模型结构充分考虑了目前EHR 存在的问题以及心房颤动的隐蔽性等疾病特性。实验结果表明:FR-ANN 模型对多项医疗事件的筛选工作提升了模型的召回率;注意力机制的引入能够代替卷积层完成特征提取工作,提升了模型的计算性能,注意力机制的事后可解释性为临床诊断提供了解决方案。但目前模型只考虑了医疗事件的变化趋势,没有考虑单个医疗事件的时间间隔因素,例如,持续30 天与持续300 天的高血压所反映的症状严重性是不同的。因此下一步将在数据中融入时间信息以刻画症状的严重性程度,并改善模型,提升模型的可解释性。
猜你喜欢
保健医苑(2023年2期)2023-03-15 09:02:50
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
成都信息工程大学学报(2017年3期)2017-11-09 02:56:41
大众健康(2017年8期)2017-08-23 21:18:22
老友(2017年7期)2017-08-22 02:36:30
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
雷达与对抗(2015年3期)2015-12-09 02:38:53
河南科技(2014年16期)2014-02-27 14:13:27
卫生职业教育(2014年9期)2014-02-16 07:23:14
