
COLLATE:控制相关数据的完整性保护
2023-11-17 13:26邓颖川刘维杰王丽娜
西安电子科技大学学报 2023年5期
邓颖川,张 桐,刘维杰,王丽娜
(1.武汉大学 国家网络安全学院空天信息安全与可信计算教育部重点实验室,湖北 武汉 430040;2.蚂蚁集团,浙江 杭州 310012)
1 引 言
使用C/C++编写的程序可能包含安全漏洞。控制流劫持攻击利用这些漏洞来篡改代码指针,从而将程序的控制流转移到目标代码片段上。通过篡改多个代码指针,攻击者可以构造图灵完备的代码重用攻击(Code-Reuse Attack),从而实现信息泄露或提权等目的。
针对控制流劫持攻击而提出的防御机制尝试确保间接函数调用时使用的函数指针为预期的值来阻止攻击。指针完整性(Pointer Integrity,PI)[1-4]是其中具有代表性的一种,它维护了代码指针和一部分数据指针的完整性。此外,控制流完整性(Control-Flow Integrity,CFI)[5-13]通过检查间接控制流跳转(Indirect Control-Flow,ICT)的目标是否符合预先分析得到的控制流图(Control-Flow Graph,CFG),实现对前向间接控制流转移的校验,并将后向间接控制流转移的校验交给影子堆栈(Shadow Stack)[14]。
然而,即便有了这些防御措施,攻击者依然能够“修改”函数指针的值,使它指向一个预期之外的目标[15]。间接控制流转移需要根据必要的运行时数据来选择目标地址,这些运行时数据就是它的依赖,也就是对应函数指针的依赖。如果依赖被篡改了,那么控制流可能流向控制流图中不同但是合法的路径,而PI和CFI很难检测到这类攻击。例如,给定一个函数指针数组,其元素指向不同的函数。一个间接调用点从这个函数指针数组中根据索引取出对应元素作为跳转目标。攻击者可以通过将这个索引篡改为另一个合法的值,导致跳转后执行预期之外的函数。
文中引入了COLLATE,一个包含LLVM pass和运行时支持库的工具链,用来保护函数指针及其依赖等控制相关数据的完整性。COLLATE首先使用静态分析识别出控制相关数据,然后使用Intel 内存保护密钥(Memory Protection Keys,MPK)(Intel Corporation.Intel(R) 64 and IA-32 Architectures Software Developer’s Manual,2016.https:∥software.intel.com/en-us/articles/intel-sdm),将它们和普通数据进行隔离,最后对程序进行插桩以允许合法的内存访问操作。为了识别控制相关数据,COLLATE首先利用基于类型的分析来找出所有的函数指针和它们归属的对象(如果有的话)作为污点源(source)。然而,在某些情况下,一个通用指针(如void *)也可以指向一个函数。这意味着基于类型的分析得到的是不完整的结果。因此,首先利用上下文敏感且流敏感的指针分析SVF(Static Value-Flow Analysis Framework for Source Code.https:∥github.com/SVF-tools/SVF)来识别这些潜在的函数指针。然后,COLLATE将间接调用点标记为汇聚点(sink),并执行污点传播,收集污点指令及其操作数作为控制相关数据。
为了保护控制相关数据,COLLATE为它们的内存分配提供了一个受限的安全内存域Ms,而为其它数据提供了一个常规内存域Mn。对于控制相关数据中的全局和静态变量,COLLATE首先将它们集中到可执行文件中一个特殊的节(Section)中,然后在加载到内存中后将这个节映射到Ms中。对于栈分配,COLLATE首先在Ms中维持了一个额外的Separated Stack,然后使用它的栈分配指令替换了原本的栈分配指令。对于堆分配,COLLATE提供了一个定制的堆管理器来管理Ms中动态分配的控制相关数据。
此外,COLLATE利用指针分析来识别那些在程序执行时预期修改控制相关数据的可信指令。通过使用专用的call gate,这些可信指令被授权访问受保护的内存域。call gate在一条可信指令执行前修改PKRU寄存器,授予它对Ms进行读写的权限,并在它执行完成后立刻收回权限。
实现了COLLATE的原型系统,包含一个LLVM pass和一个运行时支持库。其中,LLVM pass负责控制相关数据的识别和插桩,动态库提供了separated stack和heap的实现。系统保证了函数指针及其依赖的完整性,并将返回地址的保护交给影子堆栈(Shadow Stack)。
对COLLATE的有效性和性能进行了评估。该评估测试了COLLATE面对3个真实世界的CVE漏洞和一个虚表指针劫持攻击[16]的测试集的防御效果。结果显示,COLLATE能够很好地防御控制流劫持攻击。而在SPEC CPU 2006 benchmarks上的测试结果显示,COLLATE引入的平均额外开销约为10.2%,在Nginx上更是只约有6.8%,这种开销是可以接受的。因此,解决方案提供了足够的安全保证,并且具备了实用性。
综上所述,笔者做出了以下三点贡献。
(1) 提出了控制相关数据的概念,即函数指针及其依赖。它们可以被用来影响代码指针的值,从而弯曲控制流。
(2) 构建了COLLATE的原型系统,它有如下设计亮点:使用指针分析识别指向函数的通用指针;使用过程间静态污点分析识别控制相关数据;将控制相关数据存储到使用Intel MPK保护的安全内存域中。
(3) 使用SPEC CPU2006、Nginx和一些具有代表性的漏洞彻底评估了原型的有效性和性能。
2 威胁模型及设计概览
文中把控制流劫持攻击防御措施的传统对手模型作为威胁模型,即假设强大但现实的场景:攻击者可以首先利用内存漏洞访问任意内存,然后控制代码指针来劫持或弯曲控制流。威胁模型与现有的相关工作[2-3,17-18]是一致的。DEP/NX(Data Execution Prevention)被启用,并且在系统中部署了一个影子堆栈或安全堆栈。笔者进一步假设所有的硬件(如Intel MPK)和操作系统都是可信的,这意味着针对它们的攻击不予考虑。
COLLATE的目标是保证间接控制流转移(ICTs)的目标符合预期。图1是COLLATE工作流程的概览。在获取目标程序的LLVM bitcode文件后,COLLATE首先以函数指针和它们归属的对象作为污点源,ICTs作为污点汇聚点。接着,COLLATE根据提出的传播规则执行静态污点传播,从而识别出控制相关数据。然后,COLLATE在bitcode上进行插桩,将控制相关数据的内存分配到受保护的安全内存域Ms中,并仅允许可信指令对它们进行修改。最后,COLLATE将bitcode编译为目标文件,并链接相应的运行时支持库,从而生成加固后的可执行文件。

图1 COLLATE工作流程
3 控制相关数据的识别
COLLATE的第1步是识别控制相关数据。首先,使用一个混合分析方法找出函数指针和它们所属的对象作为污点源。接着,创建用于识别函数指针的依赖的污点传播规则。最后,在过程间数据流图上执行污点传播,并收集所有被污染的对象作为结果。
3.1 污点源识别
污点源是指那些属于函数指针或至少包含一个函数指针的内存对象。利用基于类型的分析来快速识别污点源,并利用指针分析的优势来对结果进行补充。基于类型的分析的任务是通过轻量级的类型匹配找到污点源。
基于类型的分析的第一步是识别污点源类型。借助LLVM类型系统的优势,可以遍历程序中的所有类型,找到所有函数指针类型。污点源类型可能被嵌入到复合类型中(如结构体类型),此时它们都应当被视为污点源类型。注意,之前对于污点源类型的定义是递归的,这意味着需要递归地检查每一个复合类型及其复合类型字段。
第一步是获得所有内存对象的类型,并确定它们是否是污点源。LLVM IR提供了alloca指令来分配栈内存,并使用GlobalVariable类型来描述全局和静态变量的内存分配,这使得可以通过预定义的API获得内存对象的类型。然而,LLVM不能直接识别堆分配点,因为它被表示为一个函数调用,但缺乏类型信息。通常情况下,开发者会利用标准库函数,如malloc和calloc,来为程序分配堆内存。注意到LLVM的优化pipeline(如O1)包括一个名为tbaa的别名分析,它在元数据标签中保留了Clang前端获取的类型信息;这些元数据标签被附加到读/写之前分配的堆内存的内存操作指令(如load)中。因此,COLLATE利用轻量级的use-def分析来找到堆内存对象最近的内存操作指令,并获得存储在tbaa标签中的类型信息。有了所有对象的类型信息后,就可以通过类型匹配迅速识别污点源。
对基于类型的静态分析所识别的污点来源可能是下近似的。即通用指针(如void *)也可能指向函数,而这是无法通过基于类型的分析识别的。因此遗漏的函数指针和依赖没有得到保护,导致它们可以被攻击者篡改。
如算法1所示,COLLATE利用指针分析来补全污点源集合。算法的输入是通用指针集合,输出是污点源集合。COLLATE用空集初始化额外的函数指针集合,用基于类型的分析结果初始化输出(第①行)。对于通用指针集合中的每个元素,COLLATE找到其points-to set(第④行)。如果该指针是一个潜在的函数指针,COLLATE将其插入到函数指针集合中(第⑤~⑩行)。
算法1基于别名分析的污点源识别算法。
输入:GPtrSet:程序中所有通用指针的集合
输出:TaintSet:指向污点源的指针的集合
① ExFunPtrSet←Ø
② TaintSet ← typeBasedAnalysis()
③ foreach GPtr in GPtrSet do
④ GPTSet ← getPointToSet(GPtr)
⑤ foreach Target in GPTSet do
⑥ if Target isa Function then
⑦ ExFunPtrSet ← ExFunPtrSet∪{Target}
⑧ break
⑨ end
⑩ end
加入函数指针集合后,COLLATE首先使用后向数据流分析来找到该函数指针所在的内存对象(第行)。最后,COLLATE再次利用别名分析,找到所有作为污点源的内存对象(第~行)。
3.2 污点传播规则
在识别污点源之后,COLLATE分别创建前向传播规则以找到所有污点路径和创建后向传播规则以识别依赖。对于前向污点传播,COLLATE提出以下规则:
(1) 前向污点分析从污点源开始,在间接函数调用点结束。
(2) 如果一条指令的任何操作数被污染,这条指令也会被污染。
通过应用规则(1)和规则(2),COLLATE确定了从污点源到间接调用点的所有污点路径。每条污点路径都由一组污点指令组成,描述了一个指针从创建到调用的生命周期。需要注意的是,在LLVM IR中,指令和它的结果在语义上是等价的,可以相互替换。
为了识别函数指针的依赖,COLLATE创建了如下后向传播规则:
(3) 后向污点分析从(之前的)污点指令开始,在内存分配点结束。
(4) 如果一条指令被污染,那么它的所有操作数都会被污染。
(5) 如果一条内存操作指令被污染,那么它的指针操作数可能指向的所有目标都会被污染。
(6) 如果一条phi指令被污染了,那么它所对应的分支指令的条件也会被污染。
规则(3)和规则(4)描述了基本的后向污点传播方向。 规则(5)介绍了内存操作指令的污点传播规则,这些指令在值操作数和指针操作数之间传输数据。具体来说,以load指令为例:如果一条load指令被污染,COLLATE就会污染所有在其指针操作数的points-to set中的内存对象。
在LLVM IR中,phi指令用于实现静态单赋值(Static Single Assignment,SSA)的Φ节点。当一个变量会根据控制流的路径的不同(例如,根据if或else分支)被赋予不同的值时,它将被表示为一个Φ节点。因此,正如规则(6)所述,phi指令的值不仅取决于前面的基本块,而且还取决于对应分支指令的条件。
3.3 污点传播
为了进行污点传播,COLLATE首先构建一个过程间的def-use链,然后根据前面提出的规则进行污点分析。
事实上,LLVM为每个函数构建了一个函数内的def-use链。因此,COLLATE首先用指针分析和类型匹配构建一个函数调用图。函数调用图表示了调用点和目标函数间的映射关系,将它们关联起来。然后,COLLATE根据函数调用图将现有的def-use链扩展为过程间的def-use链。具体来说,COLLATE以函数调用点的实参为def,目标函数的形参为use,为def-use链创建新的前向边。同时,COLLATE将目标函数的返回值视为def,将函数调用点的结果值视为use以创建新的后向边。
笔者用一个具体的例子来阐明污点传播的过程。图2中展示了一个函数的控制流图。每个方框代表一个基本块。基本块之间的实线代表控制流,虚线表示两个基本块之间的支配(dominance)关系。例如,BB_1支配(dominates)BB_4,因为从入口节点到BB_4的每条路径都必须经过BB_1。

图2 一个函数内部的污点传播过程
对于前向污点传播,将fp_arr作为污点源(第⑦行),将间接控制流传输作为污点汇聚点(第行)。因此,总结出一条用实线下划线标出的前向污点路径,即:fp_arr(第⑦行)→%8(第⑦行)→%9(第⑧行)→%14(第行)→call(第行)。
后向污点传播从之前的污点指令开始,被污染的%0(第⑦行)用方框进行了标注;它是这个函数的一个参数。此外,一条被污染的phi指令%14(第行) 使得对应的条件值%6(第⑥行)被污染,就像3.2节中规则(6)所描述的那样。因此,COLLATE识别出另一条用虚线下划线进行标识的后向污点路径:%6 in br(第⑥行)→%6(第⑤行)→%5(第④行)→%4(第③行)→alloca(第①行)。最终,COLLATE将这些污点值视为控制相关数据。
4 插 桩
4.1 控制相关数据的内存分配
为了将各种控制相关数据分配到受保护的内存域,COLLATE利用各种策略来处理不同的内存分配方式。
(1) 栈分配。COLLATE在Ms域中维护一个separated stack,以保存分配在栈中的控制相关数据。COLLATE模拟常规栈的操作,为局部变量分配和回收栈内存。具体来说,COLLATE在Ms域分配一个内存区域,并将separated stack的栈指针(即%sep_sp)初始化为该内存区域的高地址,如图3所示。给定一个局部变量,COLLATE首先根据类型和对齐方式计算其大小。然后,COLLATE利用sub指令来调整%sep_sp的位置以分配栈空间。最后,sub指令的结果被转换为原本的类型,可用于引用这个栈对象。为了回收栈帧,COLLATE在函数序言之后保存了%sep_sp的位置,并在所有的ret指令之前恢复%sep_sp的位置。
(2) 堆分配。对于动态分配的控制相关数据,COLLATE用一个专门的堆分配器取代了原来的glibc分配器。这个堆分配器将受保护的内存区域划分为16字节的chunk,从低地址开始分配动态内存。在分配动态内存时,堆分配器会找到一个由连续的chunk组成的、符合请求大小的block,并返回该block的基址。为了找到可用的块,COLLATE维护了一个空闲链表,将未分配的block连接成一个链表,如图3所示。空闲链表记录了每个block的大小和后续block的地址,有利于分配和删除操作的实施。

图3 Separated stack和heap的内存布局
(3) 静态存储区分配。COLLATE使用一个separated segment来保存静态的控制相关数据。为了实现这一功能,COLLATE首先为它们创建一个特殊的ELF section,然后分别在该section的开始和结束处插入两个填充变量,使得它按页对齐。当可执行文件被加载到内存中时,这两个填充变量可以用来确定内存中segment的实际地址范围。最后,在程序执行前,COLLATE将该segment映射到Ms以进行保护。
4.2 可信指令
可信指令是那些原本就会写入控制相关数据的内存操作指令(例如,store)。对于每个可以写入内存的内存操作指令,COLLATE利用指针分析来获得其指针操作数的points-to set。如果points-to set中包含属于控制相关数据的内存对象,COLLATE将该指令视为可信指令。在外部call指令的情况下,如果其参数的points-to set中包含属于控制相关数据,COLLATE也将其视为可信指令。
4.3 内存域切换
COLLATE利用Intel MPK将进程空间分割成两个内存域:普通数据的域Mn和受保护数据的域Ms。当CPU运行在Mn上下文时,属于在域Ms的内存区域默认为只读,以保证完整性。为了确保程序的正常运行,COLLATE用call gate来包裹可信指令,暂时允许它写入受保护的内存区域。
call gate首先使用WRPKRU指令将PKRU_ALLOW_D1写入PKRU寄存器(第①~⑤行),允许之后的代码写入Ms。PKRU_ALLOW_D1是一个宏,代表了Mn和Ms都可读可写时PKRU的值。call gate的汇编代码如下所示:
① xor ecx,ecx
② xor edx,edx
③ mov PKRU_ALLOWED1,eax
④ ;Write PKRU ALLOW DI to PKRU,allow access domain 1
⑤ WRPKRU
⑥
⑦ ;Execute trusted instruction
⑧
⑨ xor ecx,ecx
⑩ xor edx,edx
接着,可信指令在对Ms有完全的权限的情况下被执行(第7行)。在执行完成后,call gate再次将PKRU_DISALLOW_D1写入PKRU寄存器(第⑨~行),禁止之后的代码写入Ms。
关于call gate的安全性,一个合理的担忧是,WRPKRU指令是否会被攻击者利用。答案是否定的,因为控制流劫持攻击必须首先篡改能够影响控制流的数据,而COLLATE通过保护控制相关数据的完整性,使得它在源头上就不可能做到。
5 实验评估
笔者进行了实验性的评估来展示COLLATE的效率和有效性。为了测试COLLATE的效率,将其应用于SPEC CPU 2006 benchmark和一个真实世界的应用程序上以测量它的开销。为了测试COLLATE的有效性,使用3个CVE漏洞和CFIXX测试套件来测试它的防御效果。
在AWS EC2实例上进行实验。 该实例的类型为c2n.xlarge,运行64 bit Ubuntu 20.04系统,配备8核Intel Xeon Platinum 8124 MB CPU和16 GB RAM。利用wllvm(Whole-program LLVM.https:∥github.com/travitch/whole-program-llvm.)编译源代码,然后提取出LLVM bitcode作为COLLATE的输入。然后,用COLLATE分析输入的bitcode并进行插桩,生成转换后的bitcode文件。最后,将bitcode编译成目标文件,并和COLLATE的运行时支持库链接起来,产生加固的可执行文件。在编译目标程序时,使用默认的优化级别(SPEC CPU 2006为O2,Nginx为O1)和选项。
5.1 插桩开销
修改指令的数量如表1中第3列所示,绝大多数C编写的benchmark中的插桩的指令少于CPI,甚至少于它的1/10。极少数情况下(bzip2)插桩的指令数量多于CPI。
这是由两者设计上的不同导致的:CPI的权限检查需要通过插入判断函数,在软件层面上判断写入内存时写入的地址是否超出预期内存的边界。因此它修改的指令中大部分都是这样的判断函数。而COLLATE使用MPK来保护数据,因此权限检查是交由MPK自动进行的,这是在硬件层面上的检查,因而不需要额外插桩。在一些benchmark上(如mcf和libquantum),没有进行插桩。这是因为这些benchmark中不存在间接函数调用。
存在受保护数据的函数数量(FNprotected)如表1中第4列所示,笔者的工作同样少于CPI。这一方面是因为保护的对象不同,CPI保护的是那些可能以内存不安全的形式访问的内存对象,而COLLATE保护的是函数指针及其依赖;另一方面也是因为两者判断的方式不同,CPI仅仅是根据简单的def-use关系判断一个内存对象是否安全,没有考虑通过指针访问这个内存对象的情况,因而不够准确;而COLLATE同时考虑了这两种情况,通过使用指针分析更精确地确定需要保护的内存对象。当然,也找到许多不属于任何函数的全局控制相关数据。
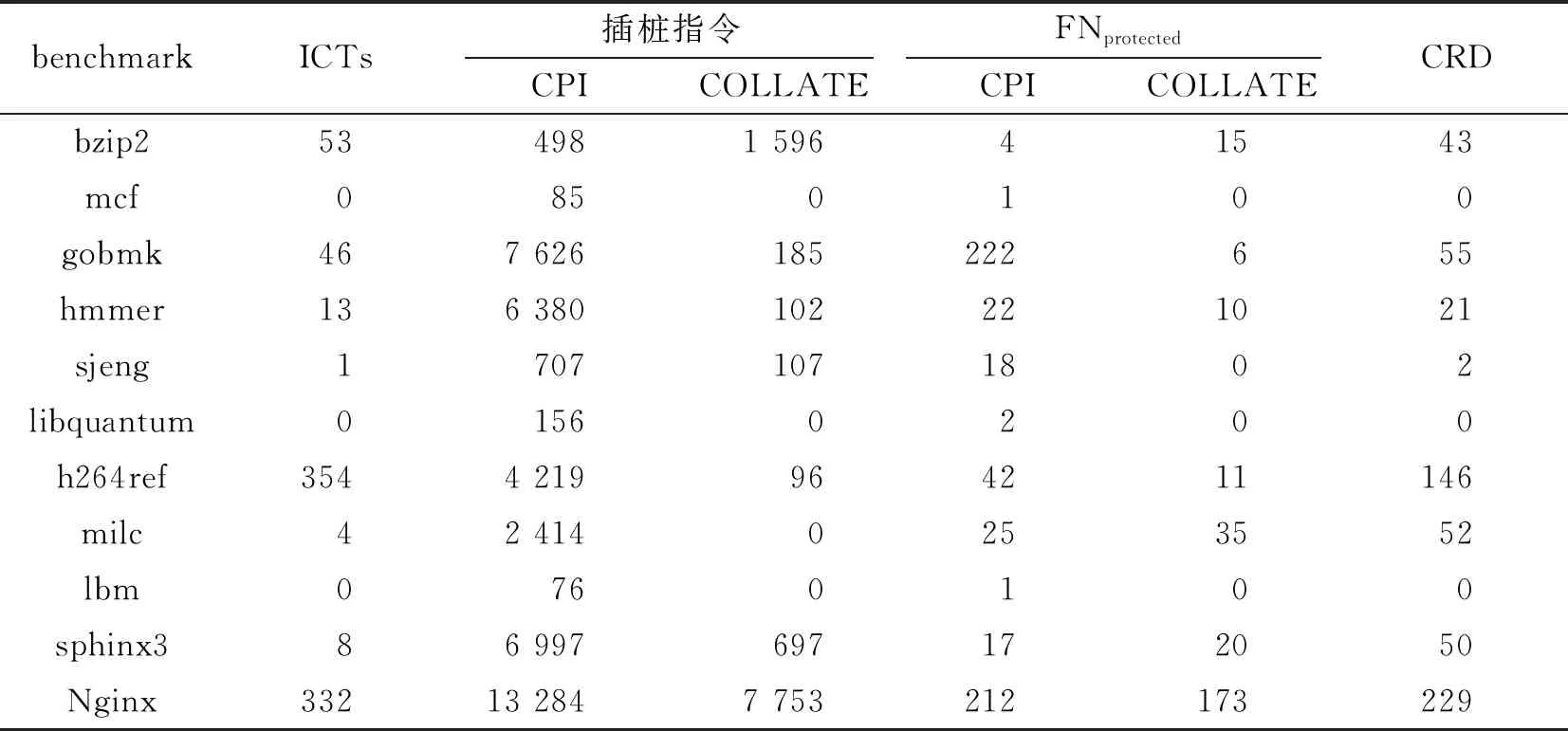
表1 控制相关数据的识别和插桩的结果
控制相关数据的数量(CRD)如表1第5列所示,控制相关数据的数量与ICT的数量呈正比。因为控制相关数据与函数指针密切相关。对于 h264ref和nginx来说,它们的控制相关数据的数量远远多于其他benchmark,因为它们有超过300个ICT。milc有不成比例的控制相关数据。这是因为它的4个ICT都用于回调,直接使用函数作为参数。所以,没有任何指令会修改函数指针。
5.2 性能开销
SPEC CPU 2006共包含了17个C/C++语言编写的benchmark。在实验中,测试了所有这些benchmark和一个真实世界的应用程序Nginx。测试结果展示在图4中。
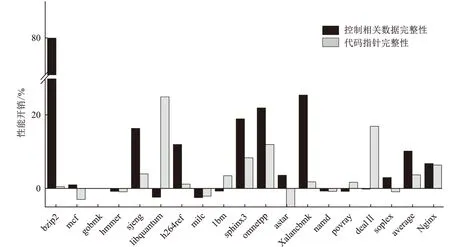
图4 归一化的性能开销,average显示的是不包括Nginx的平均开销
如图4所示,时间开销总体上比CPI略大。在SPEC CPU 2006上的结果显示,CPI的平均开销约为3.7%,而COLLATE的平均开销约为10.2%。笔者的开销约是CPI的3倍。考虑到受保护数据的范围,这种额外的开销是可以接受的。CPI只保护函数指针和用于访问函数指针的数据指针,而COLLATE保护函数指针和与函数指针的计算有关的所有数据。因此,只用2倍的额外开销就提供了更全面的保护。此外,笔者发现平均开销的差异有很大一部分是由bzip2带来的。忽略bzip2后,COLLATE的平均开销低至约6%,仅仅不到CPI的2倍。对于nginx,CPI的开销约是6.4%,而COLLATE的开销约是6.8%,仅增加了约0.4%。显然,COLLATE在实际应用中的开销比SPEC CPU 2006上的开销要小,与CPI相差不大。综上所述,COLLATE在保护了更多的对安全至关重要的数据,提供了更加全面的安全保障的情况下,性能开销仍然保持在可接受范围内。
很多情况下,尽管benchmark中应用了COLLATE,但是它的性能却没有降低,反而还略微提高了,如hmmer、namd等。这种现象的原因有两个:一是由于应用了MPK,权限的切换仅需写入专用的PKRU寄存器即可完成,使得修改后的指令增加的开销很小;二是由于修改的指令原本的执行频率就相对较低。以hmmer为例,hmmer中COLLATE修改的指令约46%都位于hmmio.c中,用于IO操作。而相较于IO本身的开销来说,COLLATE为指令本身增加的开销几乎可以忽略不计。同时,hmmer被修改的指令约有98%是标准库函数调用,本身执行频率就远低于store等写指令。对于这些指令,与它们本身的开销相比,COLLATE引入的开销几乎可以忽略不计。
尽管在大多数benchmark上COLLATE的开销都很正常,但是,在bzip2上,COLLATE的开销异常的高(约80%)。事实上,笔者发现,平均开销上的很大一部分是由bzip2带来的,在去除bzip2后,COLLATE的平均开销减少到约6%。分析bzip2和COLLATE的工作机制后,得出原因如下。
bz_stream结构体中包含有函数指针类型(第⑥行)。因此,COLLATE将所有bz_stream结构体类型的数据都识别为需要保护的数据,使用MPK进行隔离,并且每一次对它的修改都需要使用call gate临时授予权限。而bz_stream结构体保存了所有与压缩相关的数据,它的字段包含用户可见的全部数据。所以bzip2中修改这些数据的频率特别高,再加上这些修改都是以字节为单位进行的(第,行),最终导致了bzip2 benchmark的开销异常得高。
bzip2的bz_stream结构体类型和一条访问其实例的指令如下:
① typedef struct {
② …
③ char *next_in
④ char *next_out
⑤ void *(*bzalloc)(void *,int,int)
⑥ …
⑦ } bz_stream
⑧ …
⑨ while (True) {
⑩ ∥type of s->stnn is bz_stream
5.3 有效性
为了证明COLLATE能够提供足够的安全保证,笔者使用真实世界的漏洞进行了测试。首先复现了2个针对FFmpeg的堆溢出漏洞(CVE-2016-10190和CVE-2016-10191),以及Nginx的1个栈溢出漏洞(CVE-2013-2028)。复现完成后,利用这些漏洞发起前向控制流劫持攻击。最后,在FFmpeg和Nginx上应用COLLATE进行防御,并检查攻击是否被阻止。此外,还以相同的方式使用CFIXX test suite测试COLLATE在C++程序上的有效性。测试结果显示,COLLATE成功检测到了所有的控制流劫持攻击。
CVE-2016-10190:这是一个由整数溢出引起的堆溢出漏洞。利用溢出来覆盖read_packet实例中的函数指针AVIOContext,以劫持控制流。在COLLATE中,由于read_packet是一个函数指针类型,AVIOContext的实例被分配在Ms中。当攻击者试图通过堆溢出来修改它时,MPK会检测到这种非法访问,并报告错误。系统成功地检测到了这种攻击的发生。
CVE-2016-10191:这是一个堆溢出漏洞。利用溢出覆盖RTMPPacket中的data指针构建任意写漏洞,最后修改write_packet实例中的AVOutputFormat函数指针,实施控制流劫持攻击。在COLLATE中,由于write_packet是一个函数指针类型,AVOutputFormat结构的实例被分配在Ms中。根据指针分析的结果,原本的data指针并没有指向控制相关的数据。所以将data指针指向的数据写入内存的指令不允许修改控制相关数据。因此,当通过任意写入漏洞覆盖 write_packet 指针时,MPK会检测到这种非法访问。
CVE-2013-2028:这是一个由整数溢出引起的栈溢出漏洞。利用溢出来覆盖ngx_conf_t的实例中的函数指针handler,以劫持控制流。在COLLATE中,ngx_conf_t结构的实例将被分配到Ms中。当攻击者试图通过缓冲区溢出来覆盖它时,COLLATE将检测到这种非法访问。
CFIXX test suite:这个测试套件演示了vtable指针被篡改的各种可能情况。总共有5种类型,即FakeVT、FakeVT-sig、VTxchg、VTxchag-hier和COOP。以VTxchag-hier的测试为例。VTxchag-hier攻击将虚表指针修改为同一个类层次结构中另一个类的虚表指针。此时,虚函数调用的目标就变成了另一个类的虚函数,因为虚表指针被篡改了。在COLLATE中,虚表指针是控制相关数据,当程序调用构造函数创建对象时,在Ms处进行备份。当调用虚函数时,将虚表指针与它的备份进行比较。如果校验失败,则说明虚表指针被攻击者篡改,COLLATE将终止程序并在检查后报告错误。
6 讨 论
6.1 安全分析
分析哪些类型的攻击可以被COLLATE阻止。
(1) 直接修改函数指针的攻击,在进行修改时就会被发现并阻止。
(2) 修改控制相关数据(如函数指针数组的下标和虚表指针)的攻击,由于这些数据受到保护,同样会被阻止。
(3) 修改user identity data和decision-making data等关键数据的非控制数据攻击无法被阻止,因为它们不在保护范围内。
(4) DOP攻击无法阻止,因为它完全不涉及控制流。
展望未来,COLLATE也许能够防御(3)中的一部分,user identity data等数据经常用在分支语句中,并决定直接控制流转移的目标。如果将直接控制流转移纳入考虑,那么这些数据就可以认为是控制相关数据,并用COLLATE来保护。
6.2 指针分析的精度
笔者大量使用了指针分析的结果,包括使用它来识别可信指令。然而指针分析的精度并不高,运行使用COLLATE保护后的SPEC CPU 2006 benchmarks,并记录在运行时修改控制相关数据的指令。结果显示,这些指令只占可信指令的1/5。如果能提高指针分析的精度,那么COLLATE的开销将会进一步降低。也许未来可以结合静态和动态指针分析来提高精度,或者寄希望于静态指针分析的进步。
6.3 保护粒度
现在保护的粒度是整个内存对象,也就是说,即便函数指针依赖的只是结构体中的一个元素,依然要将整个结构体的内存分配到安全内存中。同时,即便是访问这个内存中其它元素的指令,也必须被允许访问受保护数据。如果能将保护的粒度降低到字段级别,那么就能进一步减少COLLATE的开销。
7 相关工作
在保护forward-edge control flow的过程中,笔者的工作和以往的相关工作有一些相似处和不同处。在这一节中,对相关工作进行简要的介绍。
CFI是常用的控制流劫持攻击的防御措施。早期的CFI是无状态的(stateless)[5,10-11,13],它们通过静态分析生成CFG,不考虑上下文信息。Intel更是在芯片上添加了对CFI的支持(Intel control-flow enforcement technology),这个硬件特性还被最新的研究用于内存隔离[19]。这些CFI无法防御控制流弯曲攻击[15],因为它们的等价类(Equivalence Class,EC)很大。最近的上下文敏感的CFI利用上下文信息来减少EC的大小。PathArmor[12]在运行时使用last branch record (LBR)获取最近的16个分支信息作为上下文。然而LBR的容量太小,导致PathArmor无法防御history flushing攻击[20]。PITTYPAT[6]和μCFI[17]都利用Intel PT记录的执行路径信息来缩小EC,μCFI还额外利用了约束数据(constraining data)。但是Intel PT的性能和存储开销很大,可能带来实用性上的问题。此外,在静态分析时,CFI-LB[21]使用函数调用点(call-site)作为上下文,OS-CFI[8]则选择了函数指针和对象的起源(origin)。但是,CScan[9]的测试结果显示它们缩小EC的实际效果和声称的存在差距。在上述研究聚焦于缩小EC时,最新的研究[7]认为这并不能很好地提高程序的安全性,并提出使用不同基本块对攻击者的有用程度作为新的衡量标准。
PI通过保护指针不被篡改来缓解攻击。PointGuard[1]和CCFI[4]都对要保护的指针进行加密,并在使用时进行解密。但是,PointGuard通过异或进行加解密,只要获取多个指针就能推测出密钥。CCFI则没有保护嵌入C的结构体中的指针。CPI[2]将函数指针及用于访问它们的数据指针隔离到用信息隐藏(x86-64)或段寄存器(x86-32)保护的安全区域中。然而,信息隐藏(information hiding)已经被基于时间的侧信道攻击(timing side-channel attacks)[22]绕过,不再安全。ARMv8-A架构中增加了对指针认证 (Pointer Authentication,PA)的支持,并且已经被证明能够有效地保护代码指针和返回地址[23],甚至实现内存安全[24]。类似地,ZeRØ[25]提出在ISA中增加一些专用于读写指针的指令以保护代码和数据指针的完整性,并设计了一个新型的元数据编码方案。
许多工作使用基于硬件的隔离来保护敏感数据或安全区域。xMP[26]使用Intel虚拟化技术(Intel VT-x)来保护它的不连续的xMP域,不过这需要对内核进行大量修改。Hodor[27]和ERIM[28]都使用MPK来实现进程内隔离,并分别在高吞吐率和高切换率的情况下取得了优异的性能。VIP[18]采取了另一种思路,将安全敏感数据的值备份在MPK保护的HYPERSPACE中,并在使用时取出记录进行验证。为了提高性能,VIP中普通内存和HYPERSPACE是直接映射的,这导致内存开销最大可约达103.1%。此外,VIP不能自动识别安全敏感数据,需要人工标注,主要用来加固其它安全措施。与之相比,能够自动识别控制相关数据,并且没有额外的内存开销,只是改变了要保护的数据的分配位置。cryptoMPK[29]也能首先自动识别加密(crypto)相关的缓冲区和操作,然后在源代码层面上将它们转移到MPK保护的域中。TDI[30]则在隔离方面有更细的粒度,它将不同类型的内存对象隔离在不同的内存区域,并对这些区域的加载操作进行限制。PKRU-SAFE[31]将在混合语言环境中将安全语言和不安全语言的内存隔离开来,从而防止攻击者通过攻击不安全语言编写的部分来破坏安全语言的安全保证。PKRU-SAFE只考虑堆内存,并使用动态分析识别需要保护的内存,而非COLLATE采用的静态分析。这虽然避免了假阳性,却会导致假阴性的出现,从而发生漏报。Jenny[32]则用MPK来保护自己的系统调用监视器(syscall monitor)相关的代码和数据,对系统调用进行过滤。
8 结束语
文中提出了COLLATE,一种新型的保证间接控制流转移的目标为预期值的防御措施。COLLATE的关键思想是保护函数指针和它们的依赖不被篡改。实现了COLLATE的原型并评估了它的性能和有效性。评估结果表明,COLLATE在实际应用和测试套件中成功地阻止了控制流劫持,并将平均开销保持在可接受范围内。这证明COLLATE是有效的且是低开销的,具有实用性。
猜你喜欢
网络安全与数据管理(2022年2期)2022-05-23
数字技术与应用(2021年5期)2021-06-29
电子科技(2021年2期)2021-01-08
计算机工程与设计(2020年11期)2020-11-17
广东第二课堂·小学(2017年9期)2017-09-28
摄影之友(影像视觉)(2017年1期)2017-07-18
山西省政法管理干部学院学报(2015年2期)2015-07-31
电测与仪表(2015年5期)2015-04-09
电子设计工程(2015年6期)2015-02-27
单片机与嵌入式系统应用(2014年9期)2014-03-11
