
因果图增强的APT攻击检测算法
2023-11-17 13:25朱光明卢梓杰冯家伟张向东张锋军牛作元
西安电子科技大学学报 2023年5期
朱光明,卢梓杰,冯家伟,张向东,张锋军,牛作元,张 亮
(1.西安电子科技大学 计算机科学与技术学院,陕西 西安 710071;2.西安电子科技大学 通信工程学院,陕西 西安 710071;3.中国电子科技集团公司第三十研究所,四川 成都 610041)
1 引 言
随着互联网在各个领域的运用越来越广泛,网络技术的不断发展,以及大数据、物联网等新技术的出现和发展,网络攻击行为和威胁也在随之增加,网络安全成为越来越尖锐的问题。最具威胁性的高级持续性威胁(Advanced Persistent Threat,APT)攻击[1]一般是由专业的高级持续性威胁组织发起,主要目的是获取目标的关键信息,长期综合运用多种攻击手段对特定目标进行渗透活动。高级持续性威胁攻击通常包括5个主要阶段:侦察、建立立足点(初始访问)、横向移动、数据泄露、持久化[2]。高级持续性威胁攻击具有3个重要特征,分别是[11]:①高级。实施攻击的人运用的专业知识、方法和工具都是高级的。②持续性。通常一个高级持续性威胁活动会持续很长一段时间,短的几个月,长的甚至几年,而且成功入侵之后,会对目标进行持久化的监视和数据窃取。③隐蔽性。高级持续性威胁会运用防御绕过技术来躲避目标系统的防御部署,通过信息收集、钓鱼等方式逐渐渗透。
近年来,机器学习越来越多地被用于网络安全的研究当中,比如检测网络环境中可能会受到的威胁和攻击。机器学习具有快速处理数据的能力,面对传统入侵检测系统难以检测到的攻击,它们能挖掘出攻击数据与正常数据的区别[3]。在大量的攻击行为中,最难以检测的攻击就是高级持续性威胁攻击,它涉及较长时间内的多个攻击步骤,对其调查需要分析大量日志以识别其攻击步骤。由于每天网络流量的数量过于庞大,网络分析师仅凭入侵检测系统难以全面且持续地应对攻击行为。
国内外的研究人员在高级持续性威胁攻击检测的研究上做了很多重要工作。在这些工作中,较为关键的是相关数据的采集和数据集的构建。加拿大网络安全研究所(Canadian Institute for Cybersecurity,CIC)和新不伦瑞克大学(University of New Brunswick,UNB)提出了CICIDS 2017数据集,该数据集涵盖了11种常见的攻击方式,通过机器学习算法进行评估[4]。2018年,加拿大网络安全研究所进一步提出了CICIDS 2018数据集[5],这次实验环境部署在亚马逊云上,攻击方和被攻击方都包含了多台计算机。CICIDS 2018数据集包含了7种攻击场景,收集了每台计算机的网络流量和系统日志。除此之外,还有新不伦瑞克大学提出的UNSW-NB15(University of New South Wales-Network Benchmark 15)数据集[12]和NSL-KDD(Network Security Laboratory-Knowledge Discoveny and Data mining)数据集[13]、美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)提出的DARPA TC(Transparent Computing)数据集[14]等。但遗憾的是,这些数据集大多数只收集了高级持续性威胁攻击侦察阶段和建立立足点阶段的异常数据,没有包含完整的高级持续性威胁多阶段攻击数据。缺少完整多阶段的开源高级持续性威胁数据是近年来开展科研工作的一大难点。直到2020年,MYNENI等人提出了DAPT 2020(Dataset for APT 2020)数据集[6],该数据集比前两个数据集涵盖了更多的高级持续性威胁攻击阶段,是第1个捕获高级持续性威胁所有阶段网络行为的数据集。这些数据集的不断推陈出新,极大地推动了高级持续性威胁攻击自动检测和防御的研究工作,填补了开源高级持续性威胁数据集的空缺。
得益于这些开源数据集,越来越多的研究人员在此基础上提出了异常检测算法。Holmes[15]是基于静态规则集的模式匹配算法,实验对象是DARPA TC数据集。Unicorn[16]是一个实时的异常检测系统,它的核心是基于异常的图形草图聚类算法,实验对象是DARPA TC数据集。LI等人[17]提出的基于注意力图神经网络的深度自编码模型,则属于基于学习的方法。这些方法由于采用了未包含完整的多阶段高级持续性威胁攻击数据集,因此更偏向于传统的异常检测。DAPT 2020的原作者在数据集上测试了传统的单类支持向量机(Support Vector Mchines,SVM)模型和栈式自动编码模型的性能,训练的时候只采用了良性数据;测试数据的时候检测异常的原理是,通过比较输入与重建输出的差异大小是否超过阈值来判定是否属于异常数据。由于他们忽略了高级持续性威胁攻击的上下文具有关联性,单独地对每个网络流进行重建误差判断,最终只得到了平均不到70%的准确率和不到30%的召回率。DIJK等人[18]对DAPT 2020数据集所有高级持续性威胁阶段的异常流量检测进行了实验,在DAPT论文算法的基础上提出了一种通过分析网络流量的有效载荷来成功检测高级持续性威胁数据泄露阶段的方法,准确率和召回率都有了较大程度的提升;但他们依旧没有从网络流的上下文联系方面着手,局限于单个流量数据包的异常检测方法。国内周杰英等人采用UNSW-NB15数据集,提出了融合随机森林和梯度提升树的入侵检测方法[7]。张兴兰等人提出了一种可变融合的随机注意力胶囊网络入侵检测模型,在NSL-KDD和UNSW-NB15数据集上实验,得到了很高的准确率[8]。刘景美等人提出了基于信息增益的自适应分箱特征选择的快速网络入侵检测算法,主要解决传统入侵检测系统查全率较低以及基于深度学习的入侵检测训练用时过长的问题[9]。
传统的入侵检测算法,如模式/特征匹配、机器学习等,能识别不同寻常的访问或对安全内部网络的攻击,但是大多数无法有效检测高级持续性威胁攻击,因为它们通常被设计为检测单个(已知)的攻击模式或方法,而不是涉及多个相互连接的恶意威胁[4]。另外,它们没有考虑对高级持续性威胁最重要的保密性、完整性和持久性方面进行建模,既不能识别也不能利用高级持续性威胁多个阶段的相关性。
高级持续性威胁攻击一般会在目标系统中留下操作痕迹,目前的研究工作收集高级持续性威胁攻击数据主要从两个方面入手,一个是网络流量抓包,另一个是分析系统日志。笔者针对网络流抓包记录的高级持续性威胁行为,提出了基于因果图序列的高级持续性威胁攻击检测算法。首先,利用因果图对网络数据包序列进行建模,将网络环境的互联网协议(Internet Protocol,IP)节点之间的数据流关联起来,建立攻击和非攻击行为的上下文序列;然后,将序列数据归一化,使用基于长短期记忆网络的深度学习模型进行序列二分类;最后,基于序列分类结果对原数据包进行恶性甄别。笔者在DAPT 2020数据集的基础上构建了新的数据集,并对文中算法进行了验证。
2 算法流程
2.1 算法基本框架
基于因果图序列的高级持续性威胁攻击检测算法的基本流程如图1所示,包含3个步骤:
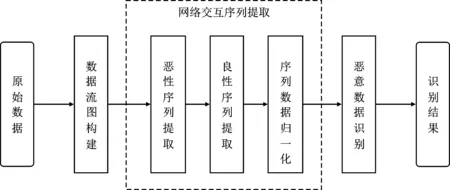
图1 算法流程
步骤1 利用网络流数据构建数据流图,在数据流图的辅助下,梳理出攻击路径,详见2.2节内容;
步骤2 以攻击路径为参照,构造出攻击序列的正样本和负样本,并对序列进行归一化,详见2.3节内容;
步骤3 基于序列分类结果对原始网络流数据进行分类,进行恶意数据识别,详见2.4节内容。
2.2 数据流因果图构建
数据流图:数据流图是从网络流量特征数据中提取处理出来的数据结构,用于确定各网络节点的连接关系,确定网络流量的流向。数据流图由代表源互联网协议地址和目的互联网协议地址的节点组成,以有向边相连,代表数据的流向。
节点:数据流图中的节点表示数据集网络环境中的一台主机节点,以互联网协议地址地址作为标识。
边:数据流图中的一条边就表示数据集中一个数据包,连接了源互联网协议地址和目的互联网协议地址,表示了两个主机节点的一次数据传输。边以源互联网协议地址、目的互联网协议地址、时间戳的组合作为标识。由于节点之间会有多次传输,因此每两个节点之间会有多条边。
将所有网络流数据包按上述原则生成节点和边,可以构建一个复杂的数据流因果图。图2数据流图中只展示了部分攻击节点之间的连接,且两个节点之间只显示一条连接;箭头表示流向。

图2 数据流图
2.3 网络交互序列提取
由数据流图确定数据集中的流量路径,配合原数据集的高级持续性威胁攻击阶段标签和数据包的正常和恶性标签,按照时间戳顺序和高级持续性威胁的阶段先后顺序,构造出序列数据。根据组成序列的数据包中是否包含良性数据包来判定该序列是否是完整的攻击序列,以此来给所有序列进行标签标定。构建序列的目的是为了引入高级持续性威胁攻击的上下文关系,帮助模型捕捉高级持续性威胁攻击的隐蔽性特征表示,提高异常识别的准确率和查全率。
2.3.1 恶性序列构建
在DAPT 2020数据集中,不是所有高级持续性威胁攻击都能完成全部阶段的攻击。有些攻击只完成侦察阶段,有些完成了侦察阶段和建立立足点阶段。按照数据流图中的路径和高级持续性威胁攻击阶段,分析出攻击网络流最多包含5个阶段:侦察、建立立足点、两次横向移动、数据泄露。因此,构建的攻击路径序列的长度也是不定的,最大长度为5。
构建恶性序列分为3个基本步骤:
(1) 在所有流量包中单独分离出带恶性标签的流量包。由于原本的DAPT 2020数据集跨越的时间段为5天,周一模拟日常使用产生的流量,周二到周五每天只模拟一个阶段的高级持续性威胁攻击,4天刚好对应4个高级持续性威胁阶段,这对构建恶性序列提供了很大的便利。
(2) 恶性流量涉及到的互联网协议地址数量比较少,可以依据因果图梳理出所有可能成立的攻击路径。
(3) 攻击路径中的每一步都可以在周二到周五的一天中找到对应的源互联网协议地址、目的互联网协议地址以及对应高级持续性威胁阶段的数据包,在这些数据包中选出一条数据。以此类推,就能组合出一条完整攻击链路对应的序列数据。这些序列里数据包的时间戳,也符合先后顺序。
表1所示是一个长度为5的恶性序列,实际训练的时候会删去源互联网协议地址、目的互联网协议地址、时间戳、活动和阶段,只保留源端口、目的端口、协议号和其他的统计特征,如:流持续时间,正向包/反向包的数量、大小、标准差,流字节率(每秒传输的数据包数),流包速率(每秒传输的包数)等。

表1 一个恶性序列的构成
2.3.2 良性序列构建
良性序列在恶性序列的基础上构建,方法是使用良性数据包替换掉恶性序列中的一个或多个恶性数据包。替换的条件是这些良性数据的源互联网协议地址和目的互联网协议地址要和被替换的恶性数据保持一致,而且重新组合的序列需要满足时间戳顺序。例如将表1中带有“建立立足点”标签的数据包替换成带有“良性”标签的良性数据包,源互联网协议地址是206.207.50.50,目的互联网协议地址是192.168.3.29,时间戳处在上下两个数据包之间。由于替换之后的序列不再符合高级持续性威胁攻击链路的完整性,因而将它们标记为良性序列。
2.3.3 序列数据归一化
使用CICflowmeter工具对抓取到的网络流数据包进行特征提取,输出的特征一共有83个维度,包含了网络流身份标识号码、源互联网协议地址、源端口、目的互联网协议地址、目的端口、时间戳以及其它统计特征。考虑到网络流身份标识号码、源互联网协议地址、目的互联网协议地址、时间戳等特征对检测模型的构建并无太大价值,去掉这些特征后,最终保留了79维特征。为了减小不同特征值之间的大小差异,避免不同数据之间数量级差距过大的干扰,对序列的数值特征进行归一化处理,将所有特征值映射到[0,1] 之间。
2.4 恶意数据识别
为了从输入的数据中挖掘出攻击序列和非攻击序列的差别,文中采用了序列分类模型,通过添加多个网络层线性堆叠来构建模型。在实验中,我们还引入了其它论文中的模型,比较它们检测异常流量的表现,以此体现出所提算法的优势。下面将详细介绍模型的设计,以及实验中引用的对比模型。
2.4.1 序列分类模型
如图3所示,除了输入层和输出层,分类模型由5层网络构成,分别是卷积层、池化层、随机失活层(Dropout层)、LSTM层、全连接层。
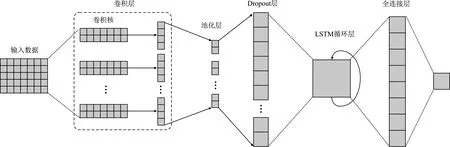
图3 顺序模型
模型使用:①用正则化的 Dropout 层以减少过拟合并改善泛化误差。②用具有最大池化的 Conv1D 层来处理序列,输入数据维度为[Lmax,Dw],Lmax为序列的最大长度,Dw为词向量的维度。③用具有 Sigmoid 激活的全连接层来预测这些序列的攻击相关概率[10]。
在实验用到的模型中,长短期记忆网络(Long Short-Term Memory,LSTM)发挥了重大作用。长短期记忆网络是循环神经网络(Recurrent Neural Network,RNN)的一个变种,长短期记忆网络的广泛应用证明了它对不同任务中的基于序列的学习是有效的。门控循环单元(Gate Recurrent Unit,GRU)是长短期记忆网络的一种变体。长短期记忆网络使模型能够自动学习区分攻击序列和非攻击序列。该模型还包括一个卷积层,它有助于我们的模型捕获高级持续性威胁攻击的隐蔽性和动态性。
该模型是二分类模型,输入的数据是上文提取的网络交互序列。需要注意的是,前面提取的序列数据并不是定长的,序列长度从1到5分布。但是模型只接受输入维度大小相同的序列,所以笔者对序列进行了填充,统一序列长度为5,特征维度为79。模型最后输出的数据是一个实数,表示该序列属于类别1的概率;若大于0.5则判定为攻击(恶性)序列,小于等于0.5则判定为非攻击(良性)序列。
2.4.2 基于序列预测结果的数据包分类
通过序列分类模型实现对序列的分类,基于序列分类结果可以回归用于生成序列的原始网络流量的分类。具体方法如下:
原始数据中,每一条网络流数据包可能多次出现在不同的序列中。遍历所有序列的类别概率,并赋予序列里包含的网络流数据包相同的类别概率。比如,某序列的预测概率为0.9,那么该序列包含的网络流数据包也被赋予0.9的概率。随着遍历的进行,也不断更新各个网络流数据包的类别概率。更新的原则是:如果某网络流数据包跟随序列被预测为恶性数据(即概率大于0.5),那么之后只有遇到更大的恶性类别概率时才会更新它的概率值;反之,如果某网络流数据包跟随序列被预测为良性数据(即概率小于等于0.5),那么之后只有遇到更小的良性类别概率时才会更新它的概率值;最终获得基于序列分类结果的网络流数据包的类别概率。
3 实验设计
3.1 数据集构建
3.1.1 DAPT 2020数据集
DAPT 2020数据集是由亚利桑那州立大学和美国海军研究实验室共同设计提出的,和CICIDS 2017、CICIDS 2018数据集一样,首先从自主设计的网络环境中模拟日常使用和高级持续性威胁攻击,然后抓取网络流数据包。使用CICflowmeter工具提取数据包流量特征,考虑到网络流身份标识号码、源互联网协议地址、目的互联网协议地址、时间戳等特征对检测模型的构建并无太大价值,去掉这些特征后最终保留了79维特征。
对比其它开源的高级持续性威胁数据集,DAPT 2020数据集多了横向移动和数据泄露两个攻击阶段。这是第一个具有较为完整的高级持续性威胁攻击的开源数据集,用到的技术也比较丰富[6]。表2说明了DAPT 2020数据集高级持续性威胁的时间分布和各阶段用到的攻击技术。

表2 数据集中高级持续性威胁攻击的时间分布和各阶段用到的技术
3.1.2 实验数据集构建
DAPT 2020原始数据数量庞大,如果直接用原始数据来构建数据流图,建成的数据流图将极其复杂,每两个节点之间将会有大量平行边。这是由于原始数据中多次出现了两个网络协议地址之间在短时间内频繁进行数据交换的情况。过于复杂的数据流图会影响梳理攻击路径,所以笔者采取了适当地合并网络流数据的操作。
如果两个网络协议地址的短期内多次进行了数据交换,我们会设置一个定长时间30 s,将30 s内的同类型流量数据做合并,合并的条件是源网络协议地址、目的网络协议地址、标签要相同。其它统计特征的合并,共有4种合并方式,分别是取最大值、取最小值、取平均值、取总和。需要根据每个特征的含义,来选择合适的合并操作。这样可以得到一个新的适合实验的数据集,其统计如表3所示。在此基础上,按照第2节所述方法生成训练和测试的序列数据,最终训练集序列数量为192 022,测试集序列数量为59 533。

表3 不同种类的网络流数据包合并前后数量对比
3.2 实验设置
3.2.1 实验参数
文中算法(命名为CGSeq-LSTM)模型用到的参数如表4所示,经过处理后网络流序列特征维度为79,序列长度为5,则输入到卷积层的数据维度为[5,79]。经过卷积层、池化层、Dropout层的处理后,进入循环网络层。无论采取何种循环网络,该层节点数都是256。

表4 文中算法模型参数
3.2.2 对比指标
在文中实验的数据中,存在有类别不平衡的问题,良性数据比恶意数据数量多很多。如果采用准确率作为评价指标,那么可能会出现一种情况:即使所有数据都预测为良性,这样仍然有98%的准确率。显然这是不合适的,所以要考虑其它评价指标。
在不平衡数据分类中,受试者工作特征(Receiver Operating Characteristic,ROC)曲线、准确率-召回率(Precision-Recall,PR)曲线都是比较常用的指标。受试者工作特征曲线是以假正例率(False Positive Rate,FPR)为横轴,以真正例率(True Positive Rate,TPR)为纵轴做出的曲线。受试者工作特征曲线有个很好的特性:当测试集中的正负样本的分布变化时,受试者工作特征曲线能够保持不变。而准确率-召回率曲线是以准确率(Precision)和召回率(Recall)这两个变量做出的曲线,其中召回率为横坐标,准确率为纵坐标。受试者工作特征曲线和准确率-召回率曲线一样,一个阈值对应曲线上的一个点,不同的阈值对应不同假正例率、真正例率或准确率、召回率值。
曲线下面积(Area Under Curve,AUC)被定义为受试者工作特征曲线或准确率-召回率曲线下的面积,取值范围一般在0.5和1之间。使用曲线下面积值作为评价标准是因为很多时候曲线并不能清晰地说明哪个分类器的效果更好,而作为一个数值,对应曲线下面积更大的分类器效果更好。
3.2.3 对比算法
以下的对比算法是引用了DAPT 2020论文里的算法或者对其改进后的算法。
(1) 基于连续包序列的有监督分类
为了与前面的基于因果图构建序列的算法作对比,文中设置了基于连续时间戳构造序列的有监督分类算法作为对比实验。所有网络流数据按时间戳排序后,设置滑动窗口,大小为5,滑动步长为1,每次生成一个包含5个连续时间戳数据包的序列,以第3个数据包的标签作为整体序列的标签。与基于攻击路径构建序列的算法一样,使用同样的训练模型,最后比较这两个在测试集的表现。该算法被命名为Seq-LSTM。
(2) 基于长短期记忆网络和自动编码器的半监督分类
文中引用了DAPT 2020数据集作者采用的半监督模型,作为实验的对比参照。常规的堆叠式自动编码器(Stacked Auto-Encoder,SAE)已被用于许多研究工作,但是由于堆叠式自动编码器的输入层只接受单个网络数据包作为输入,因此它无法检测上下文异常,这是检测高级持续性威胁攻击所欠缺的。为了解决这个问题,使用了一个堆叠的自编码器,它使用长短期记忆网络层而不是堆叠式自动编码器的隐藏全连接层,改进后的堆叠式自动编码器称为LSTM-SAE。多层长短期记忆网络可以在时间序列分析中起到比较好的效果,把多个连续的时间戳的网络流数据包先经过多层编码,然后再经过多层解码,最后达到重构输入数据的目的。
这个模型检测异常的原理是,通过对大量的正常良性数据进行训练,获得重构模型;测试集中同时包含良性数据和攻击过程恶性数据,输入数据经过模型的计算重构后,如果与原始数据差距比设定的阈值大,就判定为恶性。这种半监督模型有一个优点,它们适用于网络流数据的数据不平衡的情况。
3.3 实验结果
为了验证所提高级持续性威胁检测模型的有效性,设计了两组实验。
实验1文中算法自我对比,分析不同的循环网络和不同的数据处理方式对模型的高级持续性威胁攻击检测效果的影响。
实验2文中算法模型与其他方法的分类效果进行对比分析。
3.3.1 文中算法自我对比
(1) 不同循环网络的性能对比
观察图4和表5可以发现,对比于门控循环单元(GRU)和循环神经网络(RNN),长短期记忆网络(LSTM)在文中模型的预测中更具有优势,长短期记忆网络网络的受试者工作特征曲线的曲线下面积达到0.948,准确率-召回率曲线的曲线下面积是0.531,都是3者中最高的。门控循环单元的预测效果比长短期记忆网络稍差,标准循环神经网络的预测效果最差,受试者工作特征曲线的曲线下面积(ROC-AUC)只有 0.809,准确率-召回率曲线的曲线下面积(PR-AUC)只有0.439。

(a) 受试者工作特征曲线

(b) 准确率-召回率曲线
长短期记忆网络是循环神经网络的一个优秀的变种模型,继承了大部分循环神经网络模型的特性;同时长短期记忆网络解决了循环神经网络的长期依赖问题,并且缓解了循环神经网络在训练时反向传播带来的“梯度消失”问题。文中实验也表明,在所提模型中,长短期记忆网络比普通循环神经网络表现更加出色。
(2) 4种不同数据处理方式实验情况对比
图5是当循环网络是长短期记忆网络时,4种数据处理方式组合对应的曲线。归一化和未归一化是指是否对网络流特征进行归一化操作,取最大值和取平均值是指从序列分类结果计算每个网络流数据包的分类概率时是按2.4.2节所述方法,还是把所有包含某个网络流数据包的序列的分类概率的平均值作为该网络流数据包的分类概率。对比后可以发现,归一化和取最大值的组合处理方式的受试者工作特征曲线的曲线下面积(ROC-AUC)和准确率-召回率曲线的曲线下面积(PR-AUC)的值最高。采用最大值作为数据包的类别概率比采用平均值更有优势,是因为这样可以最大可能地提高异常数据的查全率,提高检测最终恶性数据的敏感程度。

(a) 受试者工作特征曲线

(b) 准确率-召回率曲线
从表5中可以发现,数据归一化后,各特征数据处于同一数量级,避免较大数量级数据对较小数量级数据造成干扰,无论是采用最大值还是平均值,模型都具有更好的性能。
表5也展示了3种循环网络和4种数据处理方式的完整实验结果,从整体来看,长短期记忆网络、归一化以及取最大值的组合对比其他组合的分类效果更好,这也是文中算法最终呈现的效果。
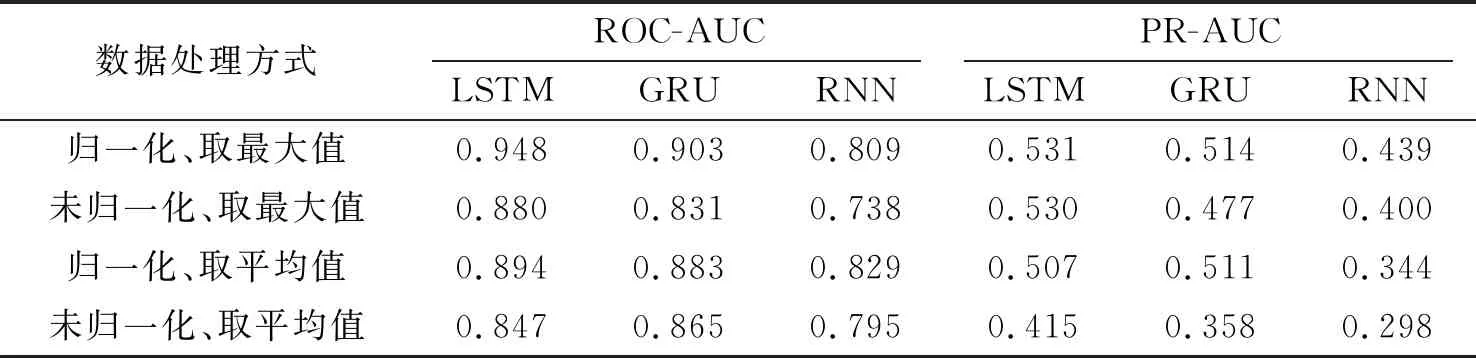
表5 文中算法自我对比
3.3.2 不同算法的异常检测性能对比
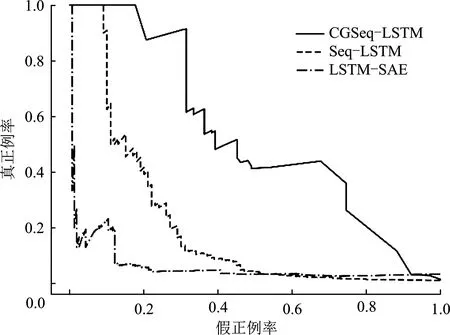
图6和表6是文中算法和设置的另外两个对比算法的实验结果。很明显,文中提出的基于因果图构建序列的异常检测算法CGSeq-LSTM,在受试者工作特征曲线的曲线下面积(ROC-AUC)和准确率-召回率曲线的曲线下面积(PR-AUC)上都是大幅领先于其他两个算法的,最优情况下受试者工作特征曲线的曲线下面积可达到0.948,准确率-召回率曲线的曲线下面积可达0.531,体现了所提算法的优势和可行性。3者中LSTM-SAE无监督算法最不理想,两个指标都未达到0.5。
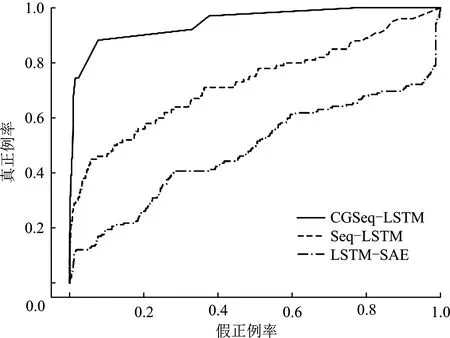
(a) 受试者工作特征曲线
(b) 准确率-召回率曲线

表6 不同算法对比
对比所提算法,分析其他两个算法表现不佳的原因:
(1) 基于连续时间数据包序列的分类算法,虽然采用和所提算法一样的训练模型,但它的缺陷在于,很多情况下这些连续时间的相邻数据包之间并没有明显的上下文关系,比如两个数据包之间的源IP和目的IP之间完全没有关联,所以它并不能体现高级持续性威胁攻击阶段的前后顺序和完整性。文中基于因果图序列的检测算法是根据因果图构建序列,序列中的数据包之间有较强的上下文关系,在异常检测中更有优势。
(2) LSTM-SAE半监督算法,虽然训练数据无需人为打上标签,但相对于有监督的模型,异常识别的精度不理想。对于预测、分类、性能比较、预测分析、定价和风险评估等任务,有监督学习更为适用。
4 结束语
高级持续性威胁攻击的精确检测是非常具有挑战性的工作。尽管现在很多研究人员已经在试图解决高级持续性威胁攻击检测,但还是有很多困难。文中提出通过构建数据流图来提取高级持续性威胁攻击路径,基于攻击路径组合网络流数据形成序列。这样做的目的是通过多个高级持续性威胁攻击阶段的流量,从完整性来考虑引入上下文关系,将多个异常进行关联,提高异常检测的全面性和敏感性。在DAPT 2020数据集上,对模型进行测试,虽然在真正例率、假正例率、受试者工作特征曲线的曲线下面积(ROC-AUC)值上能得到比较高的性能,但是在精确率、召回率和准确率-召回率曲线的曲线下面积(PR-AUC)值上的表现还是不够突出。今后的研究工作,需要投入更多的精力改进算法,挖掘出更有效的高级持续性威胁攻击检测模型。
猜你喜欢
经济与管理(2020年4期)2020-12-28
红领巾·探索(2020年5期)2020-05-19
网络安全和信息化(2018年4期)2018-11-09
小学科学(学生版)(2018年9期)2018-09-21
新闻传播(2018年13期)2018-08-29
家教世界(2017年11期)2018-01-03
英语学习(2015年2期)2016-01-30
微生物与感染(2015年1期)2015-02-28
中国新通信(2014年11期)2014-09-11
深圳信息职业技术学院学报(2013年3期)2013-08-22
