
一种域增强和域自适应的换衣行人重识别范式
2023-11-17 13:25张培煦胡冠宇杨新宇
西安电子科技大学学报 2023年5期
张培煦,胡冠宇,杨新宇
(西安交通大学 计算机科学与技术学院,陕西 西安 710049)
1 引 言
行人重新识别(Re-ID)任务的目标是从不同地点和时间的视频数据中搜索目标人物。由于在监控系统中被广泛应用,行人重识别技术长期受到学术界和工业界的青睐。随着深度学习方法的发展,不同的行人重识别算法性能迅速提高,但是在长时间的视频数据中重新识别一个目标人物,换衣服问题带来的挑战是无法忽视的。随着季节和温度的变化,衣服厚度的变化会导致人的轮廓发生巨大的变化,给重识别任务带来一定程度的阻碍。同时,在一些短期的现实场景中也存在换衣问题,例如,嫌犯为了逃避追捕通常会更换衣服以避免被识别和追踪。因而,穿不同衣服的同一人和穿相同衣服的不同人就可能造成较大的类内差异和较小的类间差异,造成行人重识别算法的失效。
目前大多数行人重识别方法是对短期内穿相同衣服的同一目标人物进行识别[1],很大程度上依赖于衣服颜色、款式等外观特征。由于衣服的外观特征在换衣行人重识别任务中变得不可靠,模型很可能会将穿不同衣服的同一人归为不同类而导致准确率的下降,因此学习与衣服无关的特征是至关重要的。GU等人[2]发现在原始的RGB图像中还有丰富的与衣服无关的信息没有被使用,并且现有的方法并没有合理地设计适合行人重识别任务的损失函数,进而提出在行人重识别网络中增加一个服装分类器和衣服对抗损失函数CAL,来惩罚模型对衣服的分辨能力,使得模型专注于与衣服无关的特征。尽管CAL极大地提升了模型关注与衣服无关特征的能力,但该方法未考虑数据集中域单一的问题,特征缺乏泛化性。
换衣行人重识别的数据收集十分复杂,在数据标注上需要投入大量的人工成本,相关的数据集通常在规模和种类上受到限制,因此使用有限的数据和人工成本对扩充数据集进行扩充是十分必要的。目前主流的数据增强分为同类和混类的方式,基于同类增强的方法例如水平随机翻转、缩放、模糊、移位、抖动、旋转等是在单个图像上操作的基础增强。CutOut[3]先随机选择一个固定大小的正方形区域,然后采用全0填充;Random-erasing[4]随机选择一个区域,采用随机值进行覆盖,模拟遮挡场景,并为新样本被赋予其原始样本标签。除了同类增强的方法,基于混类增强的方式也被广泛应用于计算机视觉任务。Mixup[5]将不同类之间的图像以线性插值的方式进行混合,从而构建新的训练样本;CutMix[6]方法从样本中提取补丁,并随机粘贴到训练图像中,标签也与补丁标签成比例分配。但是以上这些数据增强的方法都没有对语义信息作限制,会破坏目标人物的身份语义信息;例如,换衣行人重识别模型需要重点关注人脸部位的语义信息,而生成的图像很可能会遮挡或缺失面部的信息,造成模型性能的下降。所以需要使用更有效的数据增强策略,在不破坏人物身份语义信息的情况下丰富样本空间。
域自适应[7]是一种在丰富且多变的不同域的数据中学习通用特征表示的方法,能够使模型在不同域数据上表现得更鲁棒,这与换衣行人重识别的要求相吻合。针对上述问题,笔者将域自适应的思想引入换衣行人重识别任务当中,提出了一种基于域增强和域自适应的换衣行人重识别范式。笔者通过语义感知的域数据增强方法,在语义信息的引导下,不使用额外数据和标注成本,生成保留人物身份信息且更换人物衣服颜色图像,构建新的换衣域数据来丰富训练数据。并且基于增强的域数据,笔者提出了一个新的基于域自适应的多正类损失函数,使得多域数据充分发挥作用,促使模型在有限的数据中充分挖掘与衣服无关的信息,提高了模型换衣行人重识别的性能。
2 方法概述
笔者提出了一种基于域增强和域自适应的换衣行人重识别范式,整体如图1所示,主要由服装语义感知的域数据增强和基于域自适应的多域行人重识别两部分组成。首先进行语义感知的域数据增强,对换衣行人重识别数据中缺乏的同人同衣不同色的域数据进行补充;接着使用预训练的人体解析模型SCHP[8]提取训练集中图像的人体的语义结构,根据语义信息将上衣和裤子部分的图像提取出来并使用LUT查找表对图像进行亮度增强;再将其转换至HSV颜色空间,改变衣服和裤子的色调;最后对域增强后的数据集进行翻转、裁剪等基础增强操作。这种方法不需要新的数据标注,生成的域数据与原始数据共同组成域增强后的数据集并共享相同的标签。
在基于域自适应的多域行人重识别部分中,笔者提出多正类域自适应损失函数(Multi-Positive-class Domain Adaptive Loss,Lmpda),综合考虑多域数据在模型训练时做出的贡献,使得模型在不同的域中学习通用的与衣服无关的身份特征,如脸部、脚部、体型和步态等,提升了模型的鲁棒性和泛化性。模型的训练分为两步:在第1步中,使用基于域增强后的数据对服装分类器进行训练,服装分类损失函数为Lc,此时多域数据在Lc中使用相同的权重,域增强数据的加入使得服装分类器学习了更丰富的样本。在第2步中,利用第一步中训练的服装分类器来计算多正类域自适应损失Lmpda,笔者将Lmpda定义为包含多正类的分类损失函数;其中,同人同衣定义为硬正类,同人同衣不同色定义为软正类,同人不同衣定义为伪正类,不同人定义为负类。根据不同类分别为其在损失函数Lmpda中赋予不同的权重,利用域对抗学习的方法,通过最小化Lmpda和身份损失Lid来联合优化身份分类器和主干网络,惩罚模型区分衣服的能力,使得模型专注于与衣服无关的特征。
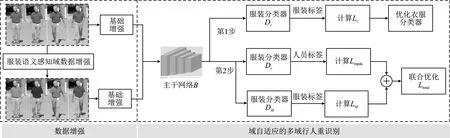
图1 域增强和域自适应的换衣行人重识别范式
3 基于域增强和域自适应的换衣行人重识别范式
3.1 服装语义感知的域数据增强
为了弥补原始数据集中同人同衣不同色域的数据缺失,笔者提出服装语义感知的域数据增强方法来丰富样本域空间。该方式不使用额外的人工成本或数据(如衣服模板[9]或其他数据集[10-11]),极大地提升了模型构建效率。
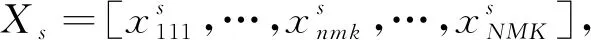
由于很多衣服的颜色太深,RGB的值都接近0,因此需要改变衣服图像的亮度且不影响衣服图像的明暗变化。首先计算衣服图像Xt和Xu的像素值的均值Rmean,Gmean,Bmean并使用LUT查找表对图像进行亮度调整,将增强系数Bf定义为
(1)
其中,增强系数由图像素值大小所决定,像素值越低,增强系数越大;像素值越高,增强系数越小。遍历衣服图像像素值并与增强系数Bf相乘,并限制像素最大值为255,当像素值大于255时向下取255。
由于HSV色彩空间更符合人类对色彩的感知情况,因此首先将调整亮度后的Xt和Xu转换至HSV颜色空间再进行颜色变换操作。根据经验,人们通常不会穿颜色过于鲜艳的裤子,所以针对衣服和裤子部分分别设计了不同的增强策略。对于衣服部分,在0°~360°中随机取值赋给Xt的色调Ht,获得换色图像Xtf达到改变衣服颜色但不影响衣服款式信息的效果;对于裤子部分,由于人们通常不会穿红色或绿色的裤子,所以随机取30°~90°的黄色区域和210°~270°的蓝色区域的值赋给Xu的色调Hu,获得换色图像Xuf,达到模拟牛仔裤和休闲裤的目的。
如图2所示,将Xuf、Xtf按位置与Xb合并,得到新的同人同衣不同色域数据Xnew。Xnew和X共享同样的标签,但是会作为软标签参与模型的训练,在不同损失函数中占不同的比重。为了尽可能提升模型的性能,如图1的基础数据增强部分所示,还需要将域增强后的数据经过水平翻转、随机裁剪和随机擦除等基础增强操作。
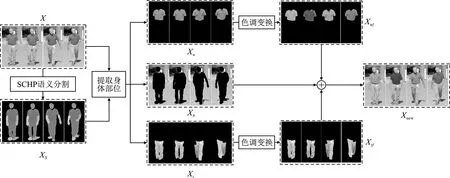
图2 服装感知域数据增强流程
3.2 多正类域自适应损失函数
笔者考虑不同域数据对模型学习身份特征时所做出的贡献不同,基于服装语义感知增强后的多域数据设计了一种多正类域自适应损失函数,通过对多正类赋予不同的损失权重来训练模型。首先将同一身份的人的所有样本定义为正类,将同人同衣定义为硬正类,将同人同衣不同色定义为软正类,将同人不同衣定义为伪正类。
提升换衣行人重识别模型性能的核心是惩罚其学习与衣服有关的信息,使得模型更加关注与衣服无关的特征,但服装作为行人重识别人物中重要的特征,惩罚对其的识别能力相当于降低了行人重识别模型的性能。所以需要合理设计损失函数,让其在关注目标身份的同时,去关注部分的衣服特征。 而为了达到这一目的,笔者抛弃现阶段行人重识别算法常用的交叉熵和三元损失函数,借鉴CAL[2]的方法和域自适应思想设计了一种多正类域自适应损失函数Lmpda。 与CAL不同的是,Lmpda增加了针对同人同衣不同色域数据的损失分量,将同人同衣数据划分为同人同衣域和同人同衣不同色域。Lmpda的数学形式为
(2)
(3)
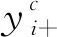
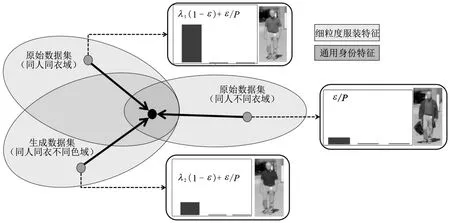
图3 Lmpda中各域权重示意图
3.3 基于域自适应的多域行人重识别
基于域自适应的多域行人重识别模型结构如图1所示,首先训练一个服装分类器Dc,待其收敛后固定参数,利用域自适应中的对抗思想,将Lmpda通过梯度反转层实现对多域间差异的消除,迫使模型专注于提取与衣服无关的身份特征。
在第1阶段,为了获得每件衣服特有的特征,需要优化Dc来增强其判别性。 服装分类损失函数Lc定义为
(4)

在第2阶段,当服装分类器训练完成后,主干网络B和人员分类器Did使用Lmpda和Lid进行联合优化。利用域自适应梯度反转层,惩罚模型学习衣服款式颜色的能力,迫使模型学习与衣服款式颜色无关的特征,提升模型在换衣行人重识别任务上的准确性和泛化性。 而在训练时,如果过早加入Lmpda,让模型基于Lmpda和Lid两个损失函数同时进行优化,可能会导致陷入局部最小值,使模型难以收敛。 于是先由身份损失Lid训练模型,使得模型首先学习容易获得的特征,当模型拥有了基本的识别人员身份的能力后,再使用最终的域自适应多域行人重识别损失Ltotal进行训练。其数学形式为
Ltotal=Lmpda+Lid。
(5)
4 实验方法及结果分析
4.1 数据库和评价标准
为了验证文中所提出范式的有效性,笔者分别在PRCC[13]和CCVID[2]两个数据集上分别训练并评估了算法的性能。它们都是基于换衣数据的行人重识别数据集。PRCC数据集在换衣和非换衣的测试集上进行性能评估;CCVID数据集在换衣测试集和由换衣图像和非换衣图像混合的测试集上进行性能评估。使用行人重识别模型评价中常用的首位命中率(Rank-1)、平均精度均值(mean Average Precision,mAP)作为评价指标,这两个值越高,表示模型的性能越好。
4.2 实施细节
模型在PyTorch平台上实现,在一个NVIDIA RTX3090 GPU上运行。对于模型训练部分,使用应用最为广泛的ResNet-50[14]作为模型的主干网络,使用BatchNorm对视频特征进行归一化。模型使用adam[15]优化器进行训练。初始学习率为0.000 35,τ设置为1/16,ε设置为0.1,λ2设置为0.05。
对于PRCC这样基于图片的数据集,对增强后的训练集使用随机水平翻转、随机裁剪和随机擦除[8]用于基础数据增强。每个批次包含8人,每人包含8张,共64张图像。将输入图像的大小调整为384×192,共训练70轮,25轮后使用Lmpda进行训练,学习率在第20、35轮后除以10。
对于视频数据集CCVID,为了不破坏视频帧间语义的连续性,只对增强后的训练集使用水平翻转用于基础数据增强。在训练过程中,遵循CCVID的方法。对于每个原始视频,模型随机采样8帧,步幅为4,形成一个视频剪辑。每个输入帧大小被调整到256×128。每个批次包含8人,每人包含4个,共32个视频剪辑。共训练150轮,Lmpda用于第50轮之后的训练,学习率每40轮后除以10。
4.3 性能评估
为了验证文中算法的有效性和优越性,本节将文中算法与其他具有代表性的算法进行比较,有基于传统行人重识别算法的PCB[16]、IANet[17];专为换衣行人重识别任务而诞生的RCSANet[18]、FSAM[19]和CAL[2];还有最新流行的Swin Transformer[20]。可以发现,文中所提出算法在换衣行人重识别任务上有很好的表现,与最先进的算法相比,mAP和Rank-1均有较大的改进。根据换衣或非换衣任务不同,可以调整式(3)中的λ2的值来训练不同的模型。表1、2的数据为笔者在换衣和非换衣任务之间达到性能平衡时选择的λ2所得到的结果。
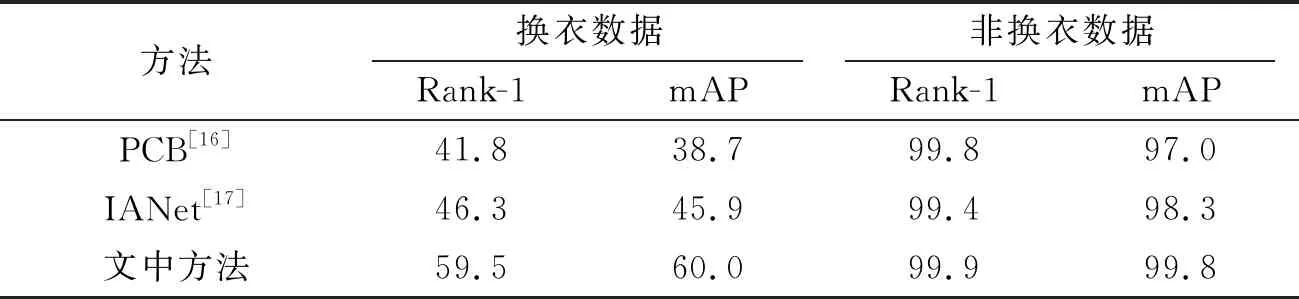
表1 在 PRCC 数据集上与其他算法的对比 %
在表1中可以观察到,在使用PRCC数据集训练模型并使用换衣图像进行测试时,文中算法的Rank-1和mAP分别达到了约59.5%和60.0%。而最新的CAL[2]算法约为55.2%(mAP)和55.8%(Rank-1),文中算法性能提升了约4.3%(mAP)和4.2%(Rank-1)。由于损失函数添加了改变衣服颜色的分量,模型对非换衣的行人重识别性能有轻微的下降,Rank-1下降了约0.1%。但这对实际应用的影响很小。
有别于PRCC数据集的评价模式,此数据集除了在换衣数据上做评估外,还在换衣与非换衣混合数据上评估了算法的性能。表2为文中所提出算法与CAL在CCVID数据集上的性能表现,结果表明,由于文中算法使用服装语义感知的数据增强扩充了域数据,并且在损失函数中添加了同人同衣不同色域的损失分量,在换衣、混合数据上可以达到约88.0%(Rank-1)/84.5%(mAP)和89.2%(Rank-1)/86.2%(mAP)。相比CAL分别提升了约6.3%(Rank-1)/4.9%(mAP)和6.6%(Rank-1)/4.9%(mAP)。这说明文中方法在视频数据集CCVID中依然有优秀的表现。混合模式中Rank-1和mAP的大幅提升,证明了文中算法在实际场景中的应用价值。

表2 在CCVID数据集上与CAL算法的对比 %
4.4 参数分析
为了研究λ2的大小对算法性能的影响,模型固定了其他的参数,只改变λ2的值。图4显示了模型在选择不同λ2时在CCVID数据集上的首位命中率Rank-1。

图4 模型性能与λ2的关系
当λ2=0时,损失函数就变成了CAL这样没有领域增强分量的损失函数。随着λ2的增加,换色数据在损失函数公式(3)中所占的比重越大,模型对换色数据就越加敏感;在0.05时,混合数据和换衣数据的首位命中率Rank-1达到了最高。当λ2的值超过0.05后再增加,模型的性能开始下降,这是因为换色增强数据的随机性很强,只能在损失函数中作为小权重进行训练。当权重过大时,模型在换衣数据上的性能提升会小于其在非换衣数据上性能的下降,这种情况体现为模型在混合数据中性能的下降。所以笔者将λ2设置为 0.05,作为模型性能最优时的参数。
5 结束语
笔者提出了一种域增强和域自适应的换衣行人重识别范式。通过语义分割提取上衣或裤子部分并改变色调,在不需要额外数据和人工成本的情况下对数据中缺乏的同人同衣不同色的域数据进行补充。与多正类域自适应损失函数相结合,使得模型在不同的领域中学习通用的身份特征,提升了模型在换衣行人重识别任务上的性能。文中所提出的算法和大多数算法不同的是,其损失函数与领域增强相结合,对域增强后的数据依据不同的域类别在损失函数中赋予不同的权重,训练方式更加灵活,模型的泛化性也更好,实验证明了所提出的方法在换衣行人重识别任务中的有效性。而换衣人重新识别仍然是一项具有挑战性但重要的任务,希望文中工作可以为未来的研究提供一些参考价值。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
今日农业(2019年15期)2019-01-03
学生天地·小学低年级版(2018年4期)2018-05-17
小天使·一年级语数英综合(2017年6期)2017-06-07
阅读与作文(小学高年级版)(2017年1期)2017-04-01
少年科学(2015年11期)2015-12-08
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
中学生阅读(初中版)(2015年6期)2015-09-16
