
基于卷积神经网络的异常流量鉴别方法
2023-11-17 03:01詹鸿辉程仲汉
成都信息工程大学学报 2023年6期
詹鸿辉,程仲汉
(福建警察学院计算机与信息安全管理系,福建福州 350007)
随着云计算、大数据和第五代移动通信技术的发展,互联网化需求进一步扩大,网络安全防护内容也随之增加。入侵检测系统(intrusion detection system,IDS),能够在入侵到达计算机系统之前主动进行防御,加强了网络空间安全性,成为计算机安全检测和防御领域的一项重要技术。但是,网络威胁的多样性以及网络安全事件频发,基于传统机器学习的方法已经不适应新的网络安全防护场景。近年来,深度学习在网络安全领域广泛应用,但仍面临数据不平衡和实时检测等问题。如何提高鉴别异常流量的准确率,同时保障用户的安全访问,在网络安全防范领域具有重要研究价值。
1 相关研究
目前,入侵检测系统根据入侵检测的行为分为两种模式:异常检测和误用检测。基于异常的入侵检测领域研究主要有传统机器学习和深度学习。在传统机器学习研究上,陈晨等[1]利用PSOGWO 算法提出了一种融合粒子群搜索的灰狼优化算法。付子爔等[2]结合SVM 和K 最近邻近(K-nearest neighbor,KNN)算法,并采用平衡k维树作为数据结构提出了IL-SVM-KNN 分类器。Logeswari 等[3]提出了一种新颖的HFS-LGBM IDS,首先应用随机森林递归特征消除(RF-RFE)方法得到最优特征集,然后使用LightGBM 算法进行检测任务。Duo 等[4]采用粒子群优化-支持向量机(PSO-SVM)和遗传算法,构建了基于支持向量机的异常检测模型。以上方法需要人工提取特征,处理高维数据的特征需要消耗大量计算资源,不仅需要大量时间,还会遗漏部分有效特征,导致准确率低。
还有一类是基于深度学习的入侵检测方法。Yin等[5]基于深度学习对入侵检测系统进行建模,提出不同的神经元数量和学习速率对模型性能具有影响。董卫宇[6]采用堆叠含有多个通过残差模块的Attention(注意力)模块,提出一种基于堆叠卷积注意力(STACON-ATTN)的DNN 网络流量异常检测模型。曹卫东等[7]用变分自编码(variational auto-encoder,VAE)处理数据,提出基于深度生成模型的半监督入侵检测模型。连鸿飞等[8]结合CNN、双向LSTM 和注意力机制,提出一种过采样算法与混合神经网络相结合的入侵检测模型。上述方法取得了不错的效果,但是在对已知网络攻击的检测上仍待提高。
本文提出一种基于数据清洗的数据转换。首先,在数据预处理上使用特征值归一化方法,再将一维向量数据转换成二维的图像数据。其次,针对NSL-KDD数据集[9]的不平衡问题,在经典卷积神经网络[10]基础结构上将批归一化层应用于卷积层-池化层之后,卷积层过渡到全连接层使用Flatten 函数。最后,在全连接层中间引入Dropout 层。此外,运用Xavier 方法[11]初始化模型权重和Adam[12]优化算法等常用的深度学习技术。由此,提出一种基于卷积神经网络的改进异常流量鉴别方法CNN-BDF(CNN-BatchNorm_Dropout_Flatten)。在卷积神经网络的基础上,加入了批归一化层、Dropout 层、Flatten 函数三个层面的改进。实验结果表明,本文所提出的入侵检测模型在各项评估指标上具有不错的提升。
2 卷积神经网络
2.1 深度学习
深度学习是机器学习新的研究方向,是一种网络层更深的神经网络,能够学习样本数据的内在规律和表示层次[13]。卷积神经网络(convolutional neural networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforward neural networks),是深度学习的代表算法之一。
2.2 卷积神经网络基本原理
卷积神经网络是一种前馈神经网络,对于图像识别有出色表现。本文先将一维的入侵检测数据转换为二维数据,然后再进行训练。卷积神经网络由具有可学习的权重和偏置常量的神经元组成。每个神经元都接收一部分输入,并进行卷积计算[14]。卷积神经网络的基本结构由输入层、卷积层、池化层、全连接层和输出层组成。卷积神经网络通常包含以下几层:
(1)卷积层(convolutional layer),卷积神经网络中的卷积层由若干卷积单元构成,各个卷积单元的参数通过反向传播算法优化得来。卷积运算能提取输入数据的不同特征,首层卷积层可能只提取部分低级的特征。例如线条、边缘和角等层级,更深卷积层则能从低级特征中迭代提取更复杂的特征。
(2)激活层(activation),是神经网络中神经元上运行的函数,负责将神经元的输入映射到输出端。其中,线性整流层(rectified linear units layer,ReLU layer)[15]是神经网络常用的激活函数。公式如下:
f(x)=max(0,x)
(3)池化层(pooling layer),在卷积层处理后一般会产生维度较大的特征,该层将特征切分成几个区域,取其最大值或平均值,产生新的、维度更小的特征。其作用是降低数据的空间尺寸,减少网络中参数的数量,计算资源耗费,也能有效控制过拟合。
(4)全连接层(fully-connected layer),将所有局部特征结合转换成全局特征,用于计算每一类的得分。根据计算神经网络的推测结果与真实标签的差距,构造损失函数。将损失函数对各种权重、卷积核参数求导,慢慢优化参数找到损失函数的最小值。这一过程称为梯度下降。经过训练的模型即可用于分类任务。
2.3 网络结构
对异常流量的鉴别实际上是根据数据特征对进行分类的问题。本文采用卷积神经网络对数据进行训练后得出异常流量分类CNN-BDF 网络。针对实验采用的NSL-KDD 数据集的不平衡问题,在经典卷积神经网络基础结构上将批归一化层应用于卷积神经网络。CNN-BDF 还将Flatten 层应用于卷积层到全连接层的过渡,在全连接层中间引入Dropout 层。并调整卷积层的关键参数以提高模型准确性。
CNN-BDF 神经网络共有14 层,结构和参数如图1所示。
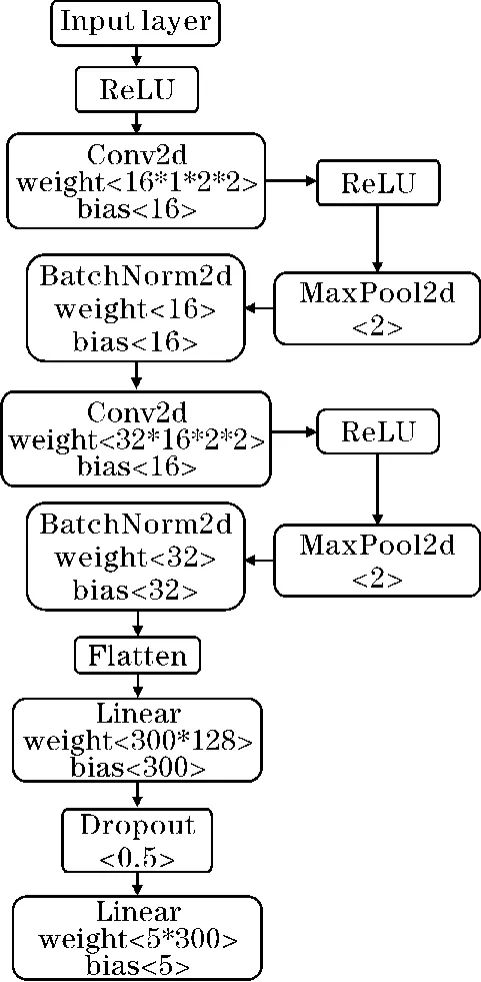
图1 CNN-BDF 模型结构
CNN-BDF 的分层结构描述如下:
(1)第1 层为输入层。入侵记录数据是一维数据,经过特征编码和数据特征值归一化处理后,首先去除一列空值数据,将单条数据由一维1×41 处理为一维1×40,最后将剩余40 列一维数据转换成二维1×5×8大小的图像数据。
(2)第3 和第7 层是卷积层。卷积层进行卷积运算,对于输入数据,以一定间隔滑动卷积核的窗口并应用。在卷积运算之前需要进行填充处理,以调整输出的大小,填充值设置为1。卷积核的位置间隔,也称为步幅。在保证网络精度的情况下,减少参数,将卷积核大小都设置为2×2,步幅设置为1。在一定程度上提高了对数据特征的获取。
(3)第2、4、8 层为激活函数层,使用ReLU 作为激活函数。第5 和第9 层为最大池化层,其作用是对微小的位置变化具有鲁棒性[16],并且能减少计算量。
(4)第6 和第10 层为批归一化层(batch norm,BN)。为了使各层拥有适当的广度,BN 层可以将激活值的分布调整成高斯分布。
(5)第12~14 层包含全连接层和Dropout 层。Dropout 可以简单地实现,在某种程度上能够抑制过拟合,在每一个batch 的训练中随机减掉一些神经元。这里将Dropout 值设置为0.5。
(6)第11 层为Flatten 全连接层。Flatten 层将输入“压平”,即把多维的输入一维化,多应用于卷积层到全连接层的过渡。
2.4 超参数设置
在CNN-BDF 的基础上,采用以下3 种优化方法:
(1)Xavier 初始化方法。在深度学习中,神经网络的权重初始化方法对模型的收敛速度和性能具有重要的影响。随着网络深度的增加,训练中容易出现梯度消失或梯度爆炸等问题。因此,对权重W的初始化至关重要,本文采用正态分布N(mean=0,std=0.01)的值填充输入张量,将网络中参数weight 初始化,初始化参数值符合正态分布。参数初始化的目的是为了让神经网络在训练过程中抑制过拟合、提高泛化能力,有利于提升模型的收敛速度和性能表现。
(2)本文模型训练所采用的损失函数为交叉熵损失函数,这是一个平滑函数,其本质是信息理论中的交叉熵在分类问题中的应用。NSL-KDD 数据集的各类标签分布不平衡,交叉熵相比其他方法计算得到梯度更加稳定。
(3)梯度下降是一种通用的优化算法,能为大范围的问题找到最优解。梯度下降的中心思想就是迭代地调整参数从而使成本函数最小化。Adam 优化算法结合AdaGrad 和RMSProp 两种优化算法的优点。对梯度的一阶矩估计(即梯度的均值)和二阶矩估计(即梯度的未中心化的方差)进行综合考虑。在深度学习中易于实现,能降低模型训练对计算机资源的需求。这里对Adam 算法的网络参数学习率、权重分别预设为0.001和0.0001开始学习以提升模型性能。
3 实验
3.1 实验方法与环境
为验证模型的有效性,进行实验对比,将原生的卷积神经网络所训练的模型记为CNN。为验证本文模型具有更好的效果,同时对比CNN、SVM、RandomForest、lightGBM 方法,选取多分类任务中常用的3 种指标,分别为准确率、查准率、查全率,以此评估模型。
(1)准确率(Acc)是模型正确检测的样本数占总样本数的比值。
(2)查准率(precision)是被正确检测的样本数占被检测到样本总数的比值。
(3)查全率(recall)是被正确检测的样本数占该类样本总数的比值。
实验环境参数如表1所示。

表1 实验环境参数
3.2 数据集与数据预处理
使用2009年公开的NSL-KDD 数据集,它是对KDD CUP99 数据集的改进,解决了KDD99 的一些固有问题[17]。NSL-KDD 训练集中没有冗余记录,不会导致分类器频繁的记录。NSL-KDD 测试集没有重复记录,使检测评估更具有准确性。NSL-KDD 中共有数据148517 条,每条数据有41 位特征值。其中,训练集有125973 条数据,测试集有22544 条数据。数据中的入侵检测攻击类别如表2所示。

表2 NSL-KDD 训练集的攻击类型
(1)NSL-KDD 内的训练集和测试集中包含的攻击方法不同,在测试集中含有17 种未在训练集出现的标签类型,共计3751 条,删除这类样本更易于评价模型对已知网络攻击的检测效果。
(2)本文使用的数据集的41 列特征内含有字符数据和数值数据,在机器学习中一般使用数值数据。数据含有protcol_type、service、flag 和label 4 列字符数据。因此,使用LabelEncoder(标签编码)中的fit_transform 函数进行特征编码将上述4 列特征转化为数值型特征。为加快本文模型收敛速度,使用MinMaxScaler(特征值归一化)方法对所有数据预处理。
3.3 实验方法
由于原始的入侵数据是一维的向量数据,而卷积神经网络一般用于处理二维的图像数据。因此,本文采用数据清洗的方法对一维41 列数据进行检查后发现数据集中第20 列全为空值,予以删除。而后将剩余的40 列一维数据转换成二维5×8 大小的图像数据,该方法简单且易于实现。
对于对比模型SVM,将C 设置为100 且选择高斯核函数作为模型的超参数。将lightGBM 模型的最大深度设置为3,学习率设置为0.1。
3.4 实验结果分析
将本文的CNN-BDF 算法与CNN、SVM、Random-Forest、lightGBM 算法进行实验对比,以验证本文方法的有效性。对比结果如表3~5所示。

表3 总体指标对比
表3 是CNN-BDF 和CNN、SVM、RandomForest、lightGBM 在总体准确率、查准率、查全率上的对比结果。CNN-BDF 的准确率达到89.01%,准确率高于CNN,也高于传统的机器学习算法。CNN-BDF 的查准率达到84.72%,与CNN 相比有效提高了查准率、查全率。在高于传统机器学习算法查准率的同时保证了较好的查全率。由表3 可知,本文提出的CNN-BDF 模型在数据集的分类效果上高于其他模型。
由表4 可知,CNN-BDF 模型在normal 类型的查准率上高于其他4 种模型。CNN-BDF 模型在Dos 类型的查准率上略低于其他模型,但在Probe、R2L 两种类型上分别高于CNN 模型和CNN、SVM 模型。SVM 在U2R 类型的查准率仅有4.54%,而文中模型达到了62.5%。总体来说,CNN-BDF 模型在查准率上优于其他4 种模型。

表4 查准率对比
由表5 可知,CNN-BDF 模型在Dos、Probe、normal类型上的查全率总体上优于CNN、SVM、lightGBM 模型,虽与RandomForest 模型相比有微小差距,但在U2R、R2L 类型的查全率上本文模型远高于Random-Forest 模型。本文提出的模型对U2R、R2L 类型的检测有较好的效果。

表5 查全率对比
综合表3~5 实验结果,本文提出的模型在提高查准率的同时也保证了好的查全率。
4 结束语
针对目前入侵检测算法对已知的异常网络流量的检测率低和准确率不高的问题,提出了特征值归一化的预处理方法和基于数据清洗的数据转换方法,将向量数据转换为图像数据。CNN-BDF 算法采用经典卷积神经网络基础结构上加入批归一化层和Flatten 函数,并在全连接层间引入Dropout 层。实验结果表明,相比CNN、SVM、RandomForest、lightGBM,CNN-BDF 模型具有较高准确率和查准率,有效提升了已知的异常网络流量的检测效果。不过,在未知攻击类型的检测效果上还有待改进,今后将继续研究网络结构,分析特征间的关联性,以改进模型对未知攻击类型的检测效果。此外,将增加时间维度的衡量,提高检测的实时性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
电视技术(2014年19期)2014-03-11
中国管理信息化(2009年10期)2009-06-19
