
地球化学测量数据整合方法的探索
2023-11-16 11:11李永虎韩晓龙黄青华李晓民徐云甫
矿产与地质 2023年5期
李永虎, 韩晓龙, 黄青华, 李晓民, 徐云甫
(1.青海青藏高原北部地质过程与矿产资源重点实验室,青海 西宁 810012;2.青海省地质调查院,青海 西宁 810012)
0 引言
青海省是全国矿产资源大省,中小比例尺地质勘查工作已基本覆盖全省,其中地球化学勘查工作为全省找矿工作,如大场金矿[1-2]、夏日哈木铜镍矿[3]、卡而却卡铜矿[4]等中大型矿产发现和突破奠定了基础。为了对已获取区域地球化学勘查数据的集成和综合,实现全省区域地球化学数据库的更新和维护,2007—2013年间开展了全省地球化学潜力评价[5],在全省性数据处理中,统一以4 km×4 km网格化数据作为40元素(化合物)最基础数据源,编制了40种元素(化合物)的地球化学系列图件及数据集,为全省及全国部署找矿工作提供了详细的地球化学资料。
近年来,青海省通过科技创新,在青海省柴周缘陆续开展了1∶2.5万地球化学测量工作[6],有效解决了1∶5万地球化学普查在省内阿尔金、柴北缘及东昆仑等干旱—半干旱高寒山区及干旱荒漠戈壁残山区,因水系沉积物元素异常流长偏短,不能满足地质找矿的需要的问题,取得了较好的找矿效果,发现了如茶卡北山锂铍矿、大格勒西稀土矿等[7]一批具有中大型找矿潜力的矿产地。为有效利用最新取得的1∶2.5万地球化学测量成果,近年来计划开展以1∶5万水系沉积物测量和1∶2.5万地球化学测量为基础的系列编图工作,作为省内新一轮战略性找矿行动部署依据,但如何实现不同比例尺数据的整合,形成数据集以制作系列图件是最核心的问题;本文选择了一个1∶5万标准图幅水系沉积物测量数据和其所包含的4个1∶2.5万标准图幅的地球化学测量数据作为本次研究对象,开展数据整合方法探索及验证。
1 研究区地质背景
研究区(图1)地处秦祁昆地层大区,北昆仑地层分区,区内地层由老到新有古元古界金水口岩群白沙河岩组、上三叠统鄂拉山组及新生代地层;研究区由于受多期造山事件影响,岩浆活动频繁,基性—超基性、中-酸性岩浆侵入活动和火山喷发活动均有,成因类型复杂,测区岩浆侵入活动记录始于晚奥陶世,兴盛于华力西-印支期,止于早侏罗世,火山活动最早记录于白沙河岩组中的基性火山岩,最晚记录为鄂拉山组陆相火山岩。
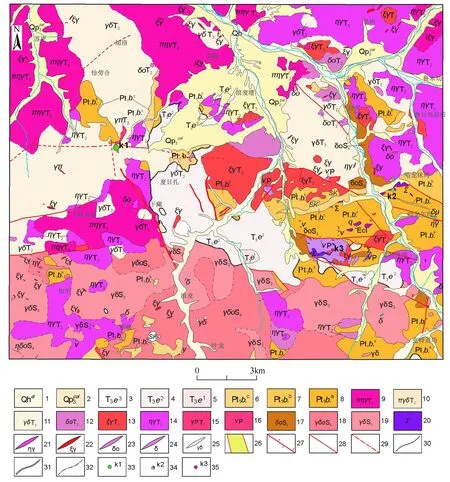
图1 研究区地质简图[14]
研究区主体构造主要发育近EW向、NE向、NW向三组断裂,近EW向断裂为早二叠世导岩构造,在成矿上有时控特征,为早二叠世侵入岩提供了岩浆通道;NE向断裂与早二叠世巴颜喀拉洋的扩张和燕山期造山期后的伸展两期构造事件有关,在成矿上为矿质沉淀提供了储矿空间的条件;NW向断裂构造有导岩导矿的双重特性,基本控制了印支期侵入岩的分布,与之有关的侧羽张剪裂隙或其本身为成矿提供了良好通道和储矿空间条件。
研究区已发现有哈日扎铜多金属矿[8]、哈龙休玛多金属矿[8]、希望沟铜镍矿[10]等多处矿床点,主体成矿时代属华力西-印支期-燕山期成矿,空间上矿化与鄂拉山组、白沙河岩组、花岗闪长斑岩及NW向断层关系密切,其中哈日扎铜多金属矿共圈出13条铜铅锌银矿体;哈龙休玛多金属矿圈出钼矿体34条,钼钨矿体1条;希望沟铜镍矿发现19处基性—超基性岩体,圈定20条镍钴矿化体,1条铜矿化体,呈现出研究区有较好的找矿潜力。
2 地球化学特征
通过全区1∶2.5万地球化学测量工作,本区开展了20种元素富集与离散特征、因子分析、聚类分析及元素时空分布特征研究,确定了五个类别的元素组合[11-12]。
结合研究区地质背景及矿产特征认为Cr、Ni、Co元素组合异常区与研究区希望沟地区基性—超基性岩体出露区吻合,说明该元素组合主要反映了区内基性—超基性岩体的分布特征;La、Nb、Th、U、Y元素组合异常区与研究区早侏罗世肉红色中细粒钾长花岗岩岩体分布特征较为一致,说明该元素组合主要反映了区内碱性岩体的分布特征;Ag、Cd、Cu、Pb、Zn元素组合异常区与调查区已有哈日扎矿区范围一致,说明该元素组合是区内主成矿元素;W、Sn、Mo、Bi元素组合异常区与研究区哈龙休玛斑岩体、矽卡岩体发育区及构造交汇区较为吻合,说明该类元素组合除反映已有成矿事实的矿区内元素组合特征外,在一定程度上反映了异常区岩浆活动及构造发育程度;Ag、Au、As、Sb元素组合异常区与构造密集区或者断层破碎带较为吻合,说明该元素组合主要反映区内构造热液活动。
3 数据基本情况
本文所使用的各元素原始数据分别来源于察汗乌苏河地区1∶5万区域综合调查报告[13]和察汗乌苏河地区1∶2.5地球化学测量报告[14];所选研究区为一个1∶5万标准图及所包含的4个2.5万标准图幅,面积为417.3 km2,样品粒级皆为-10目~+60目。
1∶5万水系沉积物测量工作是以1∶5万地形图为工作手图;采样点主要布置在地形图上可以辨认的最小水系(>300 m),即一级水系口上,对长度大于500 m的水系,溯源追加布点,二、三级水系适当控制,采样点布置以有效控制汇水面积为原创,水系最上游的采样点控制汇水域面积在0.125~0.25 km2范围内;研究区共计采样点数2435个,采样密度为5.84个点/km2,样品介质为水系沉积物;测试元素为Au、Ag、Sn、As、Sb、Bi、Cu、Pb、Zn、Co、Cd、W、Mo、La、Nb等15种。
1∶2.5万地球化学测量工作是以放大的1∶5万地形图和充分利用高分辨率的遥感影像图,精确配准后勾绘出全区大于200 m的水系作为野外工作手图;采样点主要控制一级水系,稀疏控制二级水系,采样点主要布设在长度大于200 m的水系沟口,对长度大于350 m的在水系中间增加布设一个点,采样点布置以有效控制汇水面积为原则,水系最上游的采样点控制汇水域面积在0.031 25~0.0625 km2范围内;研究区共计采样点数8437个,采样密度为20.21个点/km2,样品介质以水系沉积物为主,无水系沉积物的则由多点组合残坡积物代替;测试元素为Cr、Cu、Pb、Zn、Co、Ni、Mo、Sn、W、Nb、Y、La、Cd、Th、U、As、Sb、Bi、Ag、Au等20种。
根据上述两种工作方法采样密度、采样位置、采样介质等的差异,作者已选择研究区已知矿床进行了1∶2.5万地球化学测量有效性分析,研究表明1∶2.5万地球化学测量采集样品更接近源物质,结果更为准确,对地质背景的反映更为精确[11];本次数据整合方法验证,以选择两批数据共有元素为前提,以1∶2.5万标准图幅接图线为界,形成“田”字格,对4个1∶2.5万标准图幅进行编号,西北角为A,顺时针依次为B、C、D,其中A、C两个图幅使用1∶2.5万地球化学测量数据,B、D两个图幅采用1∶5万水系沉积物测量数据。
4 数据整合方法及数据集
近年来青海省依据以前人1∶5万地物化成果及数据,开展了多个整装勘查区找矿部署研究及靶区优选项目的实施,为省内新一轮的找矿及部署提供了可靠的依据,其中地球化学测量工作需完成全区各元素丰度、富集离散及元素组合等特征的分析及单元素异常图、地球化学图、组合异常图及综合异常图等成果图件的制作,开展上述工作的基础是实现全区数据的整合,形成数据集;在数据整合的过程中发现因采样密度、采样介质、样品粒级、测试方法等不同的原因,各批数据之间存在台阶,需采用合理方法消除台阶,同时保持数据的精确性方可开展下步工作。本文选择了常用的三种数据整合方法,并尝试提出“汇水域网格均值法”与之对比,以期获得最好的成图效果及最高的数据利用率。三种常用方法分别为常规拼接法、离散网格化数据法、标准网格均值法;对形成的数据集本次研究工作统一采用 GeoIPAS V4.0软件进行数据处理,离散数据网格化方法统一采用:趋势面法,网格间距采用250 m×250 m,搜索半径为1250 m×1250 m,制作地球化学图进行验证。
4.1 常规拼接法
常规拼接法是指对不同地区、不同比例尺原始数据直接拼接,不做人为修改,形成常规拼接原始数据集;该方法是最简单也是最能代表原始态,但是因不同数据之间可能存在密度差异等原因,在后期地球化学制作过程中可能出现图面存在台阶的情况。
4.2 离散网格数据法
离散网格数据法是指对不同地区、不同比例尺原始数据使用同一网格化方法和网格化参数进行离散数据转换,形成离散网格化数据集;该方法现阶段 GeoChem Studio、GeoIPAS 等多个软件都能实现,在处理过程中只需考虑选择合理的网格化方法和网格间距,最终导出离散网格化数据集,进行地球化学参数统计及地球化学特征分析。该方法同样存在可能出现图面台阶的情况。
4.3 标准网格均值法
标准网格均值法是指对不同地区、不同比例尺原始数据,使用1∶5万水系沉积物测量中最小方里网格(0.25 km2)作为标准网格,对网格区数据进行均值化,每一个网格作为一个点,中心点位置作为坐标,均值作为数据,进行数据整合,形成标准网格均值数据集;该方法需提前按照500 m×500 m方里网网格形成含有不同ID的标准网格区文件,再与原始数据点文件进行空间分析,使原始数据归属到每一个标准网格中,再使用 Excel 数据表进行汇总统计,算出每个标准网格中各元素均值,并把标准网格中心点位置作为均值坐标,整合为数据集,可作为地球化学参数统计及地球化学特征分析的依据。
4.4 汇水域网格均值法
汇水域网格均值法与标准网格均值法数据处理方法有一定相似之处,但不是简单的全域数值规则网格化,而是首先对不同地区、不同比例尺原始数据,应用水系沉积物测量中汇水域概念,以山脊及水系长度形成不规则汇水域网格,其次对各不规则汇水域网格中的数据进行均值化,形成每一个网格均值点,以中心点位置作为坐标,均值作为数据,最后进行数据整合,形成汇水域网格均值数据集;该方法需采用对DEM数据进行水文分析的方法,将研究区进行汇水单元[15]的不规则网格剖分,根据区内的河流分布特征以及地质环境条件的复杂程度,全区离散为不同面积的格网单元,后期处理方法与标准网格均值法类似。
本次数据验证期望解决的核心问题是:① 不同类型的数据集在进行再次利用和分析时是否存在失真,能否作为全域数据分析研究的基础,是否能够作为地球化学系列图件制作的基础。② 不同类型的数据集使用时需要解决不同图幅同一比例尺以及不同比例尺之间可能存在的数据台阶,数据台阶形成的不同原因分析及解决办法;③ 需根据工作区地质-地球化学特征,分析和判断按照不同方法整合的最终数据集,能够保留或反映多少信息,为再次利用使用或者进一步工作能否提供有利的数据支撑。④ 提出每一种数据集最终实现一张图[16]的最合理方法,提出优缺点,为今后的工作提出合理的建议。
5 数据验证及对比分析
为更准确的对比上述数据整合方法的适用性和有效性,本文整合了1∶2.5万地球化学测量原始数据集、1∶5万水系沉积物测量原始数据集、离散网格数据集、常规拼接法数据集、标准网格均值数据集及汇水域均值数据集共6个数据集(下文及图、表中6个数据集依次以a、b、c、d、e、f表示),并通过地球化学参数统计及地球化学特征分析开展研究,地球化学参数统计选择了Au、Ag、As、Sb、W、Sn、Mo、Bi、Cu、Pb、Zn、Co、Cd、La、Nb等15种元素测试数据为对象,计算不同数据集中各元素平均值、中位数、变化系数等,对比分析其差异性;地球化学特征分析选择了Cu、Co两种元素作为研究对象,制作不同数据集元素地球化学图,对比分析各数据集同一元素空间分布特征与地质背景及成矿事实的对应性。
5.1 地球化学参数统计及分析
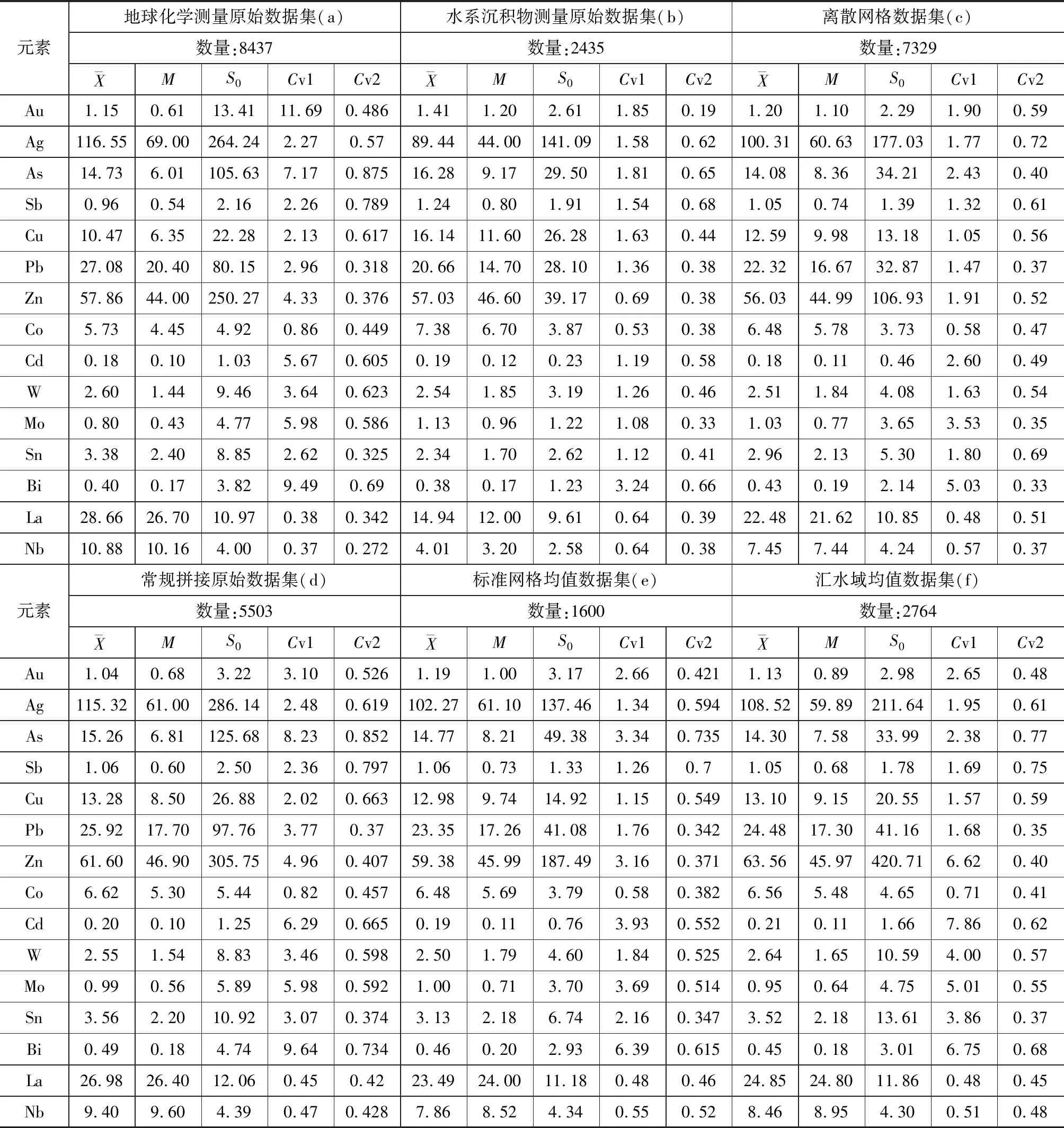
表1 数据集参数特征
5.1.1 元素丰度值差异
本文通过各元素丰度、标准离差的对比中分析不同数据集各元素丰度差异,以便对比分析不同数据集的可利用程度。
通过各元素丰度比值变化拟合图[16](图2),对比分析各数据集之间的差异,其中元素丰度比值等于各数据集元素丰度值除以全区数据元素丰度值;拟合图显示:① 不同数据集各元素比值越接近1,则该数据集越贴合背景值,所反映的地球化学特征越准确。② 拟合图形态越接近圆形,规则程度越高,则该数据集的全元素可利用程度越高。
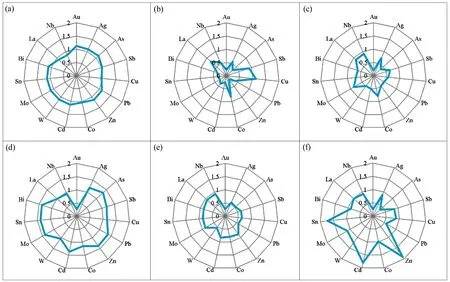
图2 各数据集丰度比值拟合图
如图2所示,从数据集贴合背景程度看,汇水域均值数据集最为准确,次之为标准网格均值数据集,第三为地球化学测量原始数据集,其中地球化学测量原始数据集为单一数据,不具备数据整合研究的作用;从拟合图形态规则程度看,汇水域均值数据集拟合图最接近圆形,其他数据集图像均存在不同程度的偏差,显示出某一或某几种元素准确度偏低,故认为汇水域均值数据集更适合全元素分析利用。综合分析确定汇水域均值数据集能够在充分利用全部拼接数据的基础上,兼顾原始数据的准确性和全元素的可利用性。
各元素标准离差是反映一个数据集不同元素的的离散程度。通过各元素标准离差比值变化拟合图(图3),对比分析各数据集之间的差异,其中各元素标准离差比值等于各数据集标准离差除全区所有数据标准离差;图3中,图3a、3b为单一数据集,图3c~3f为整合数据集,通过对比不同整合数据集离差拟合图以分析其对图3a、图3b单一数据集的融合程度。
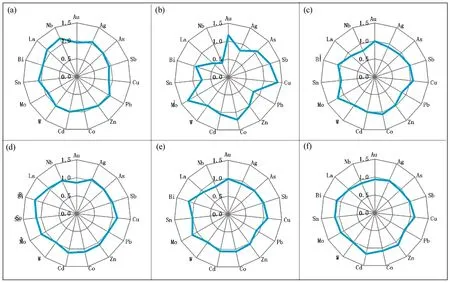
图3 各数据集标准离差比值拟合图
由图3可见: 各元素标准离差比值越大则反映该数据集中该元素在区内的离散程度越高,更有利于凸显异常,反之则越低;拟合图各元素形态越接近圆形,说明数据集受地球化学测量数据影响越大,反之受水系沉积物数据影响越大。
如图3所示:①地球化学数据集更接近全区所有数据富集离散特征,水系沉积物数据集存在明显差异,只有个别元素接近比值1,说明水系沉积物数据集对异常的凸显较弱;②离散网格数据集、标准网格均值数据集中各元素标准离差比值小于1,说明整合方法削弱了数据离散程度,不利于认定成矿元素;③常规拼接原始数据集标准离差比值最接近地球化学数据值准离差比值,受数据量多少较为严重,说明该数据集在参数统计过程中,可能产生诱导;④汇水域均值数据集中标准离差比值,既有利于凸显异常,又利于成矿元素的确定,便于综合利用。
5.1.2 元素富集离散度差异
本文通过变异系数拟合图(图4),对比分析各数据集中元素富集离散特征差异,其中Cv2为剔除高低值后变化系数。
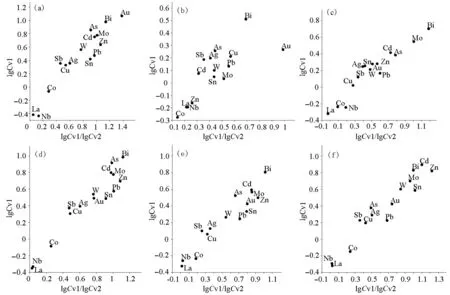
图4 各数据集变异系数拟合图
图4a、4b为单一数据集,图4c~4f为整合数据集。通过对比不同整合数据集变异系数拟合图以分析其对图4a、4b单一数据集的融合程度。对比显示: ① 总体线性分布的基础上,图4f线性形态最为均衡,图4c存在弯曲,图4d存在断折,图4e集中度不足; ② 从找矿利用上分析,离散度高的元素成矿可能性较大,图4f离散极值明显大于其他,可见该数据集更有利于凸显异常,指导找矿; ③ 从元素分组上分析,按照离散度高低分类,图4f分为Cd-Zn-Bi-Mo-W-Sn,Au-As-Ag-Pb-Sb-Cu,Co-Nb-La三组,基本融合了图4a、4b元素组合,且准确度最高。
5.1.3 元素相关性差异
本文通过R型聚类分析(图5),对比分析各数据集中元素组合特征差异。图5a、5b为单一数据集,图5c~5f为整合数据集。通过对比不同整合数据集R型聚类分析谱系图以分析其对图5a、5b单一数据集的融合程度,综合元素富集离散度分析元素分组的准确度。谱系图显示: ① 图5c~5f整合数据集元素分组相比于图5a、5b单一数据集,在细微分组上更加精确,且分组程度更高。 ② 综合分析,汇水域均值数据集元素分组更接近于图5a、5b单一数据集,且对成矿元素的分组更贴合地质背景。

图5 各数据集元素相关性谱系图
5.2 地球化学特征对比分析
通过不同数据集主要元素地球化学图(图6、图7)的对比,拟获得最为贴合成矿事实、图面效果最佳、细微变化最显著的数据集;依据研究区地质背景、地球化学元素富集规律、矿产勘查成果及地球化学特征,可知主成矿元素Cu富集区主要代表哈日扎铜多金属矿床范围,指示元素Co富集区主要代表超基性岩体分布范围。
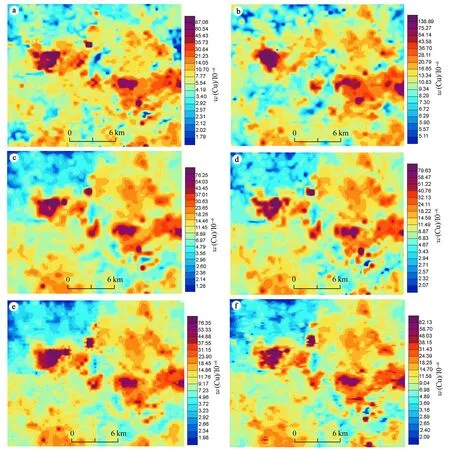
图6 各数据集铜元素地球化学异常图
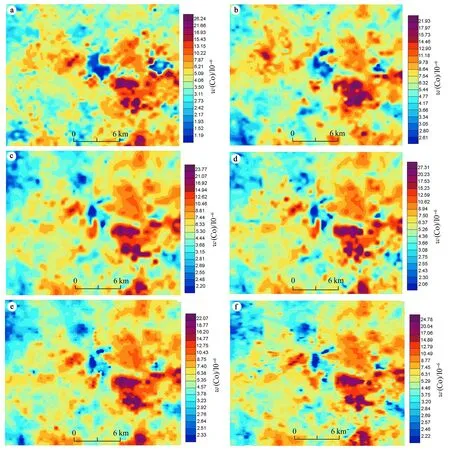
图7 各数据集钴元素地球化学异常图
Cu、Co元素地球化学图显示: ①相比于相比于图6a、6b单一数据集,图6c~6f整合数据集在微细变化上更优于图6b,接近于图6a,说明其地球化学指示作用强于水系沉积物测量原始数据集。 ②相比于图6a、6b单一数据集,图6c~6e整合数据集均存在一定的拼接痕迹,而图6f图面效果最好,拼接处转化更为自然或基本可以忽略图面拼接痕迹。 ③结合地质背景分析,图6c~6f均能较好的突出细微变化,对线性构造、局部岩体均有充分反映。图6f则兼顾了图面微细变化充足和地质背景反映充分的特点。
6 探讨及结论
(1)通过分析对比认为,离散网格数据集、常规拼接原始数据集、标准网格均值数据集、汇水域均值数据集均在一定程度上存在失真,但能基本反映全域地球化学信息,仍可作为全域数据分析研究的基础,从数据真实程度和可利用程度上排序,汇水域均值数据集 >常规拼接原始数据集 >离散网格数据集 >标准网格均值数据集。
(2)通过分析对比认为,不同类型的数据集在制作地球化学图中均存在一定的拼接痕迹或数据台阶,但仍可作为研究全域地球化学规律的基础图件,不同数据集地球化学图在地质信息全面——准确度和图面优化度两方面的综合排序,汇水域均值数据集 >标准网格均值数据集 >离散网格数据集 >常规拼接原始数据集。
(3)相较于其他基于数学模式的数理统计方法,汇水域网格均值法是在遥感数据水文分析的基础上,结合地形地貌、水系分布、流长及汇水面积等因素,以自然汇水域为网格单元形成数据集,减少了机械式数理统计造成的异常偏移、叠加混乱等影响,更能代表所在区域地球化学属性。
综上所述,文章认为相较于常规使用的数据拼接法,汇水域网格均值法虽然存在不同区域间存在拼接痕迹、数据存在一定失真等问题,但基本解决了数据拼接中的如数据台阶过于明显、数据失真度较高、拼接数据反映地质背景不足、图面信息弱化严重等系列问题;在使用方面能够实现全域一张图的设想,在数据量较大、数据来源众多、数据间偏差较大的综合研究中,其作用更加明显。
猜你喜欢
China Report Asean(2022年8期)2022-09-02
水利水电快报(2022年7期)2022-07-18
物联网技术(2020年12期)2021-01-27
水上消防(2020年5期)2020-12-14
水利规划与设计(2020年1期)2020-05-25
文史春秋(2019年11期)2020-01-15
学苑创造·B版(2019年3期)2019-04-24
智能城市(2018年7期)2018-07-10
汽车零部件(2017年4期)2017-07-12
中国洗涤用品工业(2015年3期)2015-02-28
