
基于依存关系图的汉语话语标记可解释性识别研究
2023-11-16 06:10肖明,肖毅
华中师范大学学报(自然科学版) 2023年4期
肖 明, 肖 毅
(1.华中师范大学语言与语言教育研究中心, 武汉 430079; 2.华中师范大学信息化办公室, 武汉 430079;3.华中师范大学信息管理学院, 武汉 430079)
话语标记(discourse markers)是一种用来标示话语连贯,传递话语互动信息和人际功能信息的语言范畴[1-3].它们在言谈互动、话语理解和口语机器翻译中有重要意义,可用于帮助听话人预测即将出现的话语在会话中所发挥的关键作用.Fischer等[4]研究表明,此类语言成分在会话中的使用频率相当高.如,在非正式的德语人对人交际中,其使用频率高达8.8%~9.8%,在人机交互中其重要性略有减弱,但在前150个高频词中也达到了6.6%.
话语标记成员数量多,类型复杂,因此,其自动识别是自然语言处理中的一个难题.从话语标记的来源来看,涉及连词、副词、叹词、形容词、动词性短语等多种层级的语法成分,绝大多数的词(或短语)在演变出话语标记用法之后,一般还会保留原来的用法,因此,话语标记自动识别的关键问题是分解歧义.国内外不少学者就此做过一些研究,如Hirschberg等[5]利用话语标记的拼写环境对“now”和“well”进行歧义消解,Fischer等[6]依据话语标记小品词的句法位置和之前的对话行为这两类信息描述探讨歧义消解问题,在包含75个德语语篇的测试集中取得83%的准确率.Litman[7]采用CGRENDEL规则库和决策树c4.5两个机器学习的方法来改善对话语标记的识别,提取韵律特征、文本特征、词性特征和词法特征,比手工方法更具有可扩展性和灵活性.Popescu-Belis等[8]利用词汇、韵律/位置与社会语言学特征人工标注话语标记well和with,使用决策树模型检验各个特征的显著性,表明左侧窗口对识别贡献度最大.目前,国内学者主要聚焦关系词基于规则的自动识别、微博热点主题挖掘、话语标记语体分析和实体关系抽取,如胡金柱等[9-10]考察了基于规则的汉语复句关系词自动识别,提出了12点约束条件;李源等[11]利用依存句法分析汉语结构模型,得到语义和结构融合的依存关系,提高了依存关系界定的性能;杨进才等[12]运用依存语法分析汉语复句中关系词搭配,总结字面特征和语法特征规则用于自动识别复句关系词;李艳翠等[13]采用清华汉语树库用于复句关系词的识别分类,提取12种字面特征的模型获得较高的复句关系词识别率.复句关系词与话语标记词不同,两者有交集,弱化的关系词具有话语标记的属性特征,这些方法为话语标记的自动识别提供了思路.祁瑞华等[14-15]探讨依存关系在中文微博作者性别中的应用,采用支持向量机、朴素贝叶斯、最近邻和决策树等分类算法对作者性别进行识别区分,总体上依存关系特征集在中文微博数据集实验中的准确率、召回率和F值最高.孟晓亮等[16]提出话语标记的语体度概念,认为话语标记的语体特征对文本分类具有一定参考价值.陆亮等[17]探讨了融入对话交互信息的实体关系抽取方法,在DialogRE数据集上得到F1值为54.1%.综上所述,以上文献有的基于规则方法对关系词进行自动识别,有的利用句法依存关系进行微博热点挖掘、用户观点抽取和作者性别识别,都未对话语标记基于机器学习方法的自动识别进行相关研究.
为了验证本文所提方法的可行性和有效性,本文提出对话语标记句法依存关系、语义依存关系、语法位置、语义功能等特征的挖掘,探究判定话语标记的语言知识和语法规律.由于是首次分析话语标记的自动识别实验,语料库规模较小,而基于深度学习人工智能的不可解释性存在两个方面,一是原理上的不可解释性,因为深度神经网络模型和算法通常十分复杂,加上“黑盒”学习训练的性质,AI通常无法对预测的结果给出自我解释,模型十分不透明;二是语义上的不可解释性,深度学习用于挖掘数据中变量之间的关联性,而数据关联性产生于因果、混淆和样本选择偏差3种类型,混淆和样本选择偏差带来的虚假关联而做出的“解释”,不是因果关系,一定是不稳定和缺乏鲁棒性的,降低受众对模型的信任程度.而采用朴素贝叶斯、贝叶斯网络等结构化贝叶斯模型,既可以用来描述不确定性,又可用直观、清晰的图形描述变量之间的直接作用关系,刻画变量之间的条件独立性,从而学到可解释的、用户友好的特征[17].研究话语标记融合依存语法特征的贝叶斯自动识别方法,以期为自然口语的自动理解和分析提供可解释性理解知识.
1 话语标记的基本类型及其功能
话语标记是“语言成分、副语言成分或非言语成分通过它们的句法属性、语义属性以及在始发或终结位置切分话语单位的序列关系来标记话语单位关系的”,这是Schiffrin[19]从功能的角度划分出来的语用类别.从语法性质来看,汉语的话语标记来源于叹词、形容词、连词、副词以及一些短语.例如:
例句(1):女C:对..他们说最好的就是国产的这个宫灯跟大宝...其余的呢?
女B:别的都不太好.
女C:品牌啊--
女B:添加剂你知道×××
女C:嗯.
例句(1)为自然对话,“对”与“你知道”分别是由形容词与主谓结构演变而来的话语标记.
如例句(1)所示,话语标记来源于不同性质的语法成分,因此,不少词同时保留了非话语标记与话语标记两种用法.我们这里以常见的不同词长话语标记为例,用具体数据描述它们的实际使用情况,统计样本为100万字的自然会话语料和300万的中国传媒大学有声媒体语料(“乡约”“鲁豫有约”“锵锵三人行”栏目).相关数据如表1.
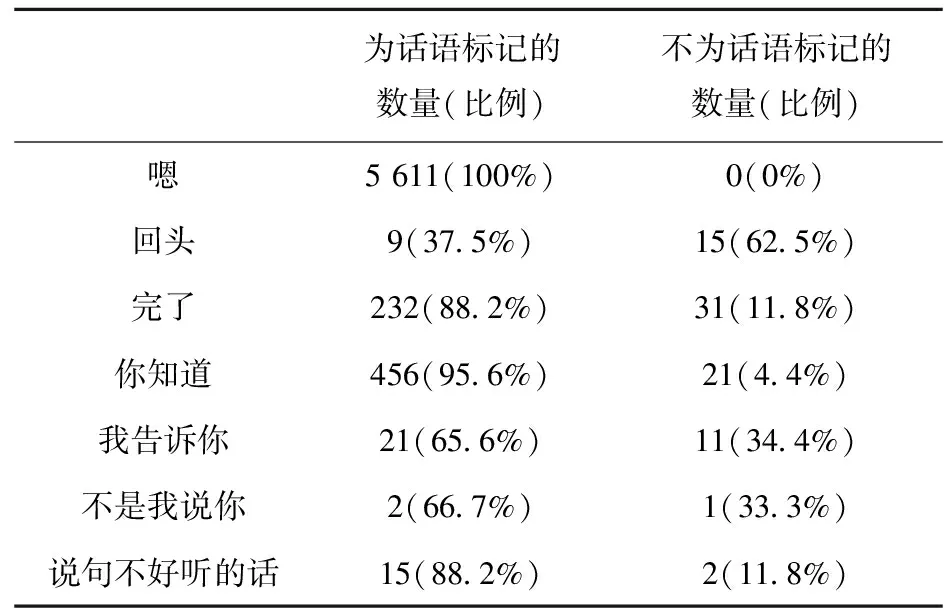
表1 部分话语标记两种用法的用例数和占比
表1说明,汉语中确实存在全职的话语标记(如“嗯”),但是这类话语标记极少.绝大多数是兼职的,它们除了有话语标记用法之外,还有大量的非话语标记用法(如“回头”“完了”“你知道”“我告诉你”等).话语标记用法主要表达程序性意义,而非话语标记用法主要表达概念意义,两种用法的显著差异从侧面说明了话语标记的识别对会话含义理解的重要性.
2 话语标记的特征
依存关系作为自然口语话语标记文体特征具有三个优势:依存关系三元组结构简单,可计算性好,对主谓易位、叠连、重复的自然口语环境具有良好的适应性[20];依存句法分析强调句子成分间的支配与从属的依存关系,不限于句子成分顺序的特性有利于分析句式灵活多变的口语文本,而且,依存关系提取深层句法结构信息,具有内容无关性.利用哈尔滨工业大学的LTP平台对口语语料库中的对话进行依存句法分析,构建依存树库,提取依存树中话语标记的句法依存关系和语义依存关系.LTP平台采用863词性标注,共14种句法依存关系和25种语义依存关系.
2.1 支配词词性
根据依存语法的五条公理,依存句法树中仅有一个中心词,称为根节点,句中所有词语仅有一个支配它的词,中心词除外,所以在依存树中,词之间只存在支配被支配、从属被从属的关系.在依存语法中,句子的支配词词性大多为动词,因为动词的支配能力比其他词都强[21-22],如例句(2)和(3)中分别列举了含有“回头”的例句,其依存句法分析和词性标注的结果如图1和图2所示.
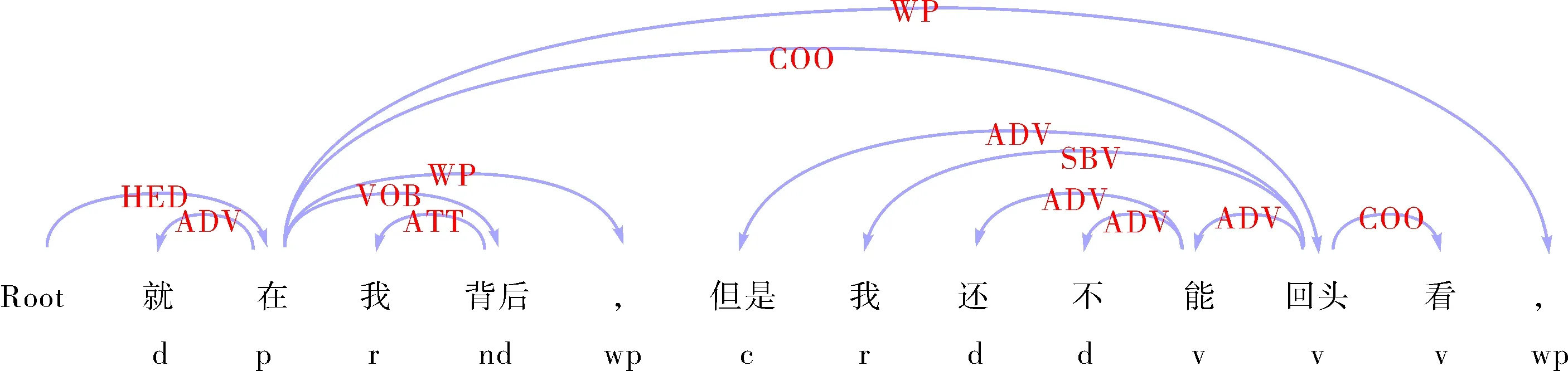
图1 例句2的依存句法分析Fig.1 Dependency syntax analysis of example 2
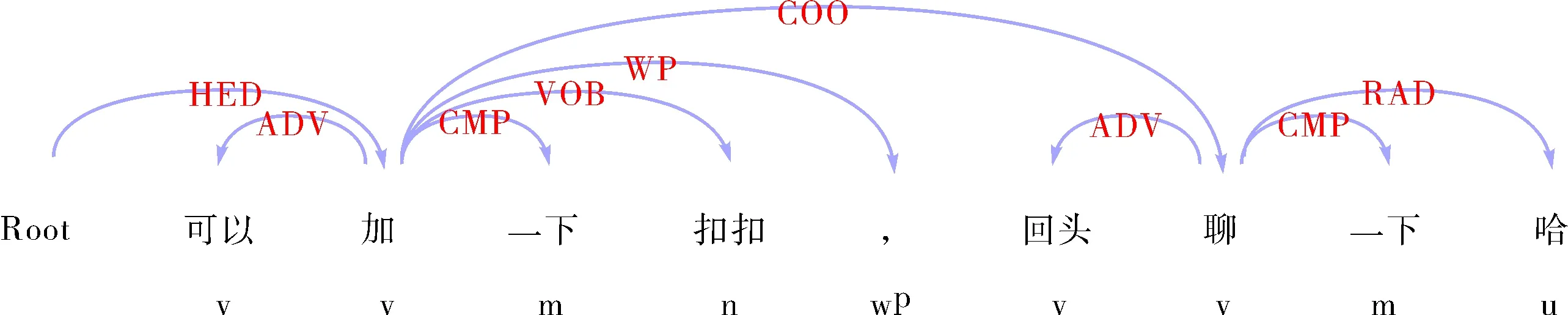
图2 例句3的依存句法分析Fig.2 Dependency syntax analysis of example 3
例句(2):就在我背后,但是我还不能回头看.
例句(2)中“回头”不是话语标记时,其词性标注为v动词,是支配词.
例句(3):可以加一下扣扣,回头聊一下哈.
例句(3)中“回头”充当话语标记时,词性标注为d副词,支配词分别是“加”和“聊”,词性标注都是v动词.
2.2 话语标记与支配词之间的句法依存关系
根据依存树库中词与词之间的14种句法依存关系,准话语标记与支配词之间的关系一般根据准话语标记在句中是否充当话语标记而有所变化,因此可以把两者之间的依存关系作为判断准话语标记是否为话语标记的条件.例如图3、图4是“回头”在句中与其支配词的依存关系.

图3 例句4中的依存句法分析Fig.3 Dependency syntax analysis of example 4
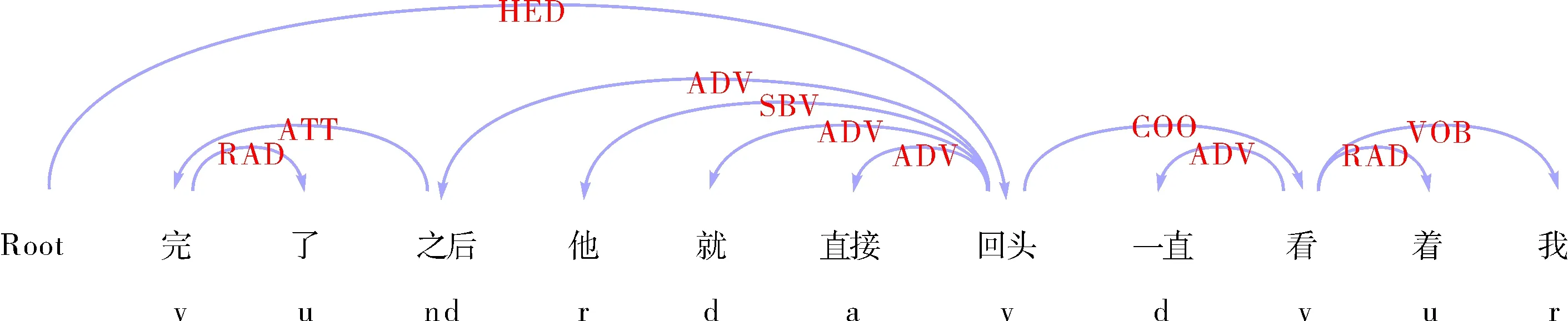
图4 例句5中的依存句法分析Fig.4 Dependency syntax analysis of example 5
例句(4):你回头留我们这儿吧,别回去了.
例句(5):完了之后他就直接回头一直看着我.
如图3所示,例句(4)中“回头”充当话语标记,与其支配词“留”之间的关系是ADV(状中结构).图4例句(5)中的“回头”依存于其前的“他”,构成SBV主谓关系,“回头”作为“他”的谓语,因此不作为话语标记.
2.3 话语标记与支配词之间的语义依存关系
根据依存树库中词与词之间的25种语义依存关系,一个词可以支配不同的词,形成不同的语义依存关系,在依存树中除去叶子节点的其他节点都至少有一个从属词,根据依存语法分析,口语句中的话语标记在依存树中属于叶子节点,是不支配其他词的,以“完了”为例,对例句(6)进行语义依存关系分析.
例句(6):完了,这下没情调了,曲子也就吹完了.
为了区分例句(6)中出现的两个“完了”,分别标注为“完了1”和“完了2”,由于句子较长,分析的语义依存树节点太多,此处只分析与“完了”直接相关的依存节点.图5是依存树的语义依存关系图及简图.
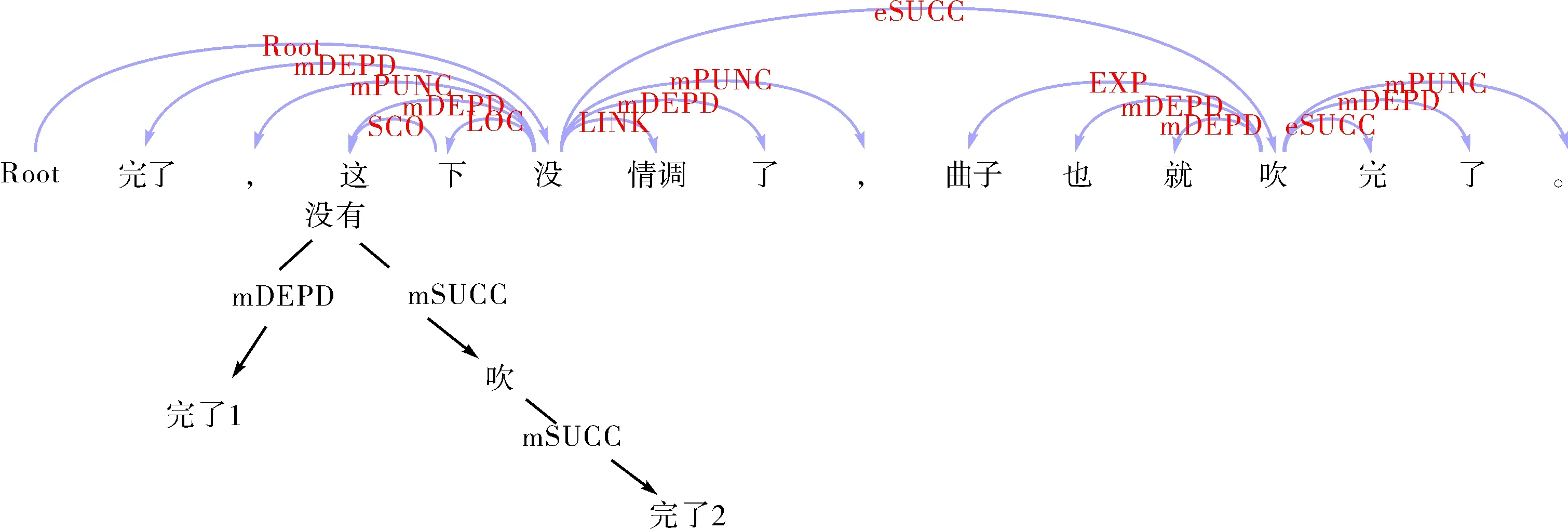
图5 例句6两个“完了”的语义依存分析及简图Fig.5 Example 6 semantic dependency analysis and diagram of two “wan le” words

图6 例句7中“完了”的语义依存分析Fig.6 Semantic dependency analysis of “wan le” in example 7
图5左分支是“完了1”的语义依存关系,第一个“完了”是话语标记,在依存树中为叶子节点,是支配词“没”的依附标记;右分支是第二个“完了”的语义依存关系,与支配词“吹”是后继关系.
例句(7):这下没情调了,曲子也就吹完了.(自建)
2.4 位置分布
自然口语中,话语标记在话轮中有经常出现的位置,位置是判定话语标记的重要参数之一.话语标记在口语中可能出现的位置有五:话轮首、话轮中、话轮尾、其他标记后(组合性话语标记出现的位置)、独立话轮.据此,笔者详细统计了7个常用话语标记在口语对话语料库中的位置分布(详见表2),发现它们各自有不同的位置分布格局,且存在明显的位置分布偏向.
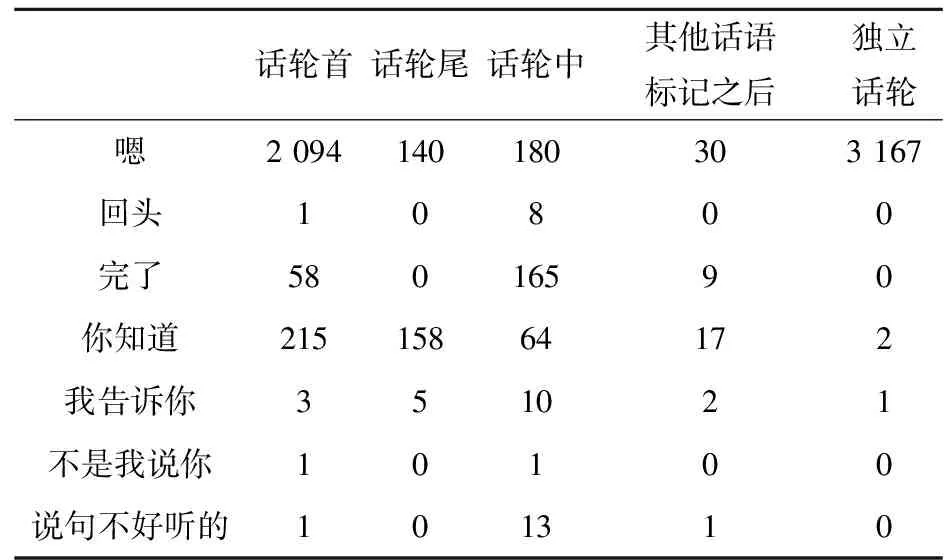
表2 话语标记的位置分布及比例
表2数据显示,“嗯”更常分布在独立话轮和话轮尾;“回头”“完了”“我告诉你”“说句不好听的”主要分布在话轮中;“你知道”更常分布在话轮首和话轮尾;“不是我说你”的分布位置相对均衡.有些话语标记不会出现在话轮尾、其他话语标记之后或独立话轮中.话语标记有各自的位置分布偏向,所以位置分布可作为识别话语标记的重要特征参数.结合话语标记词表和位置分布来识别话语标记,可以减少误判.
2.5 共现成分的主语/话题特征
话语标记共现成分的语义与功能特征主要包括是否有停顿性话语信息或连续性话语信息,前后话语是否有主语/主题、前后主语/主题的关系、前后话语内容的关系等6个方面.这些语义与功能特征对话语标记的判定具有重要的意义.比如,“完了”为话语标记时,前面通常有停顿性话语信息(如例句(7)、(9)、(11)、(13)、(15),而它不为话语标记时,前面通常没有停顿性话语信息(如例句(8)、(10)、(12)、(14)、(16).这种现象说明了共现成分能够作为话语标记的判断依据.
例句(8):我没寻思整这一套,一串儿啊,整个玩意还绕老半天完了举出一个这个,完了因为我推她一下子,完了,人家啊,我给你学一个,我说你别老逗你爸.
例句(9):我补补补补补,然后就补完了.
例句(10):它在2008年房价最高的时候,你知道吗?它大概就是这么大,30平方厘米,就是一平方英尺,要卖到2 700美元.
例句(11):你知道味道是怎么出来的吗,你说有微波炉烤箱的味道,烧焦那种味道是吧?
例句(12):我告诉你,别以为你有文化就可以欺负人啊,真没见过你这号的!
例句(13):小雨,我,我告诉你一个秘密.
例句(14):不是我说你,别一天到晚只知道赚钱赚钱,赚那么多钱干嘛.
例句(15):问题不是我说你正义,是法律上.
例句(16):说句不好听的话,还不是你教出来的吗?
例句(17):你不通过民政局,我跟你说句不好听的话,我真的没法跟你说,知道吗?
3 特征的析取与算法
综合以上的分析,话语标记的句法依存关系、语义依存关系、位置分布、共现成分的语义与功能特征等都是作为识别话语标记的重要参数.以下为本文提取这些特征的方法.
3.1 依存关系的提取
本文基于话语标记的依存关系特征研究,依据14种句法依存关系和25种语义依存关系,具体的依存关系类型描述如表3所示.

表3 依存关系类型
3.2 句法位置的提取
会话中,不同话语标记出现的位置是不一样的,而这些位置信息可以作为分析话语标记的一个重要参数.比如,话语标记“回头”基本上不出现在独立的话轮位置,在调查的语料库中,该位置上出现的概率为0.这样的位置特征对于判定“回头”是不是话语标记非常有价值.有些词在某些位置上倾向于用作话语标记,这样的统计数据对话语标记的自动识别同样非常重要.关于语法位置的提取,本文的做法是利用训练语料查询话语标记的位置(记为“Pos”),计算公式如下:
(1)
3.3 主语/话题特征的提取
会话中,说话人通常围绕共同关心的人物或事件展开,所涉主语/话题多具有同一性或相关性,这些信息对话语标记的判定具有参考价值.本文的具体做法是将认为的该特征分成6类,并在训练集中进行标注,具体如表4所示[23].针对主语/话题的标记逻辑,将话语中的所有名词或代词性成分作为主语/主题候选词,然后利用候选词分析前言后语所用主语/话题的关系.具体说来,在语料样本中以潜在的话语标记为切割点,分为两个片段,以此为基础比较前后两个话语片段中主语/话题的同一性,通常使用的方法包括匹配法与删除法.如前片段中主语/话题为“我”,后片段话语中主语/话题词也为“我”,则二者匹配成功,表明主语/话题的同一性.或利用删除法进行比较,如前片段中主语/话题词为“公司的张经理”,后片段话语中主语/话题词也为“张经理”,二者也是相同的.有些主语虽然字面上不同,但是在语义上具有回指等语法关系,二者是相同的,比如“市场经济”与“它”在前后句中做主语/话题时,大多数是同指关系.计算表层形式不同的主语/话题之间的语义关系需经过两个步骤,一是借助扩展的《同义词林》分析二者的语义关系,二是通过语法上的共现计算二者的相关性.公式如下:
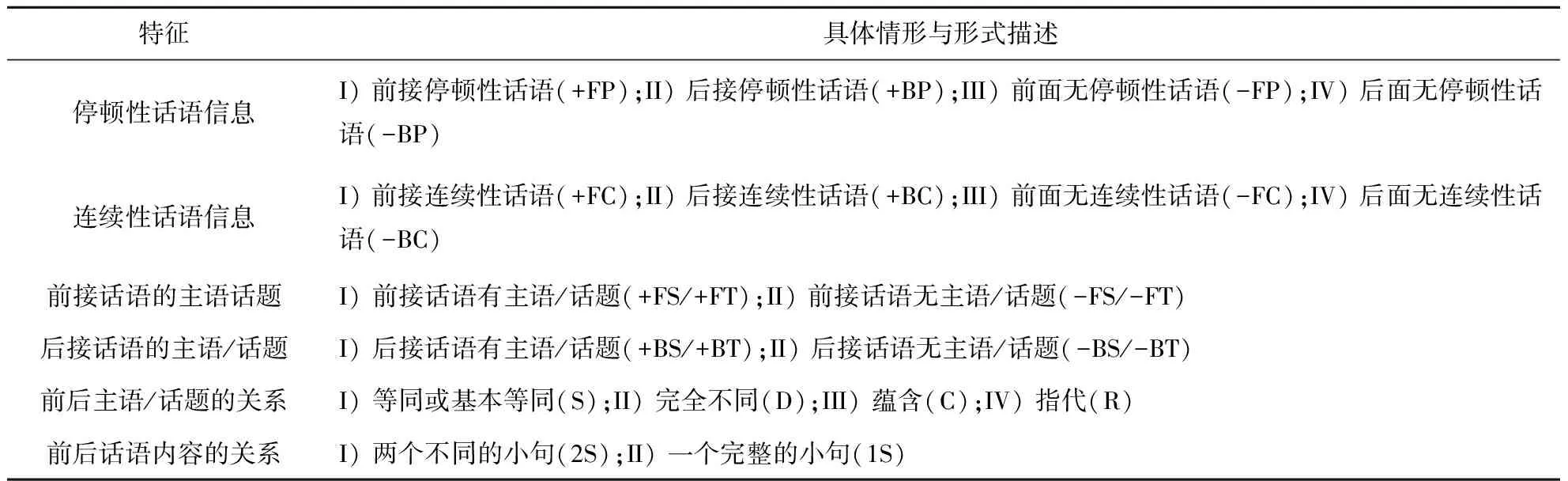
表4 话语标记共现成分的语义与功能特征
Association=
(2)
3.4 词性特征的提取
基于窗口的概念对词性特征进行提取,即只统计词距离小于等于窗口大小的临近词语的分布情况.之所以引入窗口概念,主要有两个原因,首先是降低系统开销,设词性分类一共有n种,窗口大小为w,那么词性排列一共将出现nw.如果不对w加以限制,最终对排列结果的统计将占用很大的系统开销,同时这样的开销也不能换来准确率的提升,因为词距离越远,词与词的关联性将越小.第二个原因数据稀疏问题,由于目前我们的数据集规模在千句和万句之间,当存在较多词性排列时,由于数据集的规模不足,词性排列将存在数据稀疏问题,从而使得统计得出的概率存在一定的偶然性,影响识别准确率.计算公式如下:
P(特定词性排列|话语标记)=
N(话语标记下的词性排列)/N(特定词性排列).
(3)
4 实验及数据分析
在基于依存关系图的话语标记可解释性方面,算法和模型等可解释性方法的采用是必需的.人工智能的可解释性方法根据模型解释的算法复杂度分成两类,一类是事前解释(ante-hoc),另一类是事后解释(post-hoc).事前解释适用于复杂度较低的模型,多采用传统机器学习中的自解释模型.例如,线性模型、K近邻算法、决策树、朴素贝叶斯模型、贝叶斯网络等;事后解释适用于复杂度较高的模型,多运用知识蒸馏、激活最大化方法、概念激活矢量测试、反向传播、沙普利解释模型等[24].尽管当前人工智能的可解释性方法种类较多,但每种方法都不够完善,或多或少的存在一些缺点.例如:自解释模型准确性偏低,受到多种因素的限制,预测性能与可解释性之间的矛盾较大;激活最大化方法仅适用视频等连续型数据,无法应用于离散型数据,且容易受到噪音的影响.因此,在不同场景下,应当根据各类方法充分利用其优势,避免其不足,选取合适的模型和算法来实现系统的可解释性.
综上所述,为了验证本文提出的多视角话语标记特征模型的科学合理性,采用事前解释方法的自解释模型,以位置特征作为基准特征集,依次增加词性特征、话题特征和依存关系特征,依次递增的对照识别实验特征集如表5所示.实验采用张华平研发的NLPIR-Parser[25]进行中文语料分词和词性标注,分类算法实验环境为scikit-learn.在对照实验中运行十折交叉验证,以话语标记识别的准确率(precision)、召回率(recall)和调和均值(F-measure)作为模型识别结果的评价标准.正确率P=Ncorrect/Nprogressive×100%,召回率R=Ncorrect/Nall×100%,调和平均数F1=2×P×R/(P+R)×100%.Ncorrect表示识别正确的话语标记个数,Nprogressive表示识别为话语标记的样本个数,Nrecg表示识别正确的话语标记和非话语标记个数,Nall表示原样本准话语标记个数.对“回头”[26]“完了”[27]“你知道”[28]“我告诉你”[29]“不是我说你”[30]“说句不好听的(话)”[31]6个话语标记进行标注.
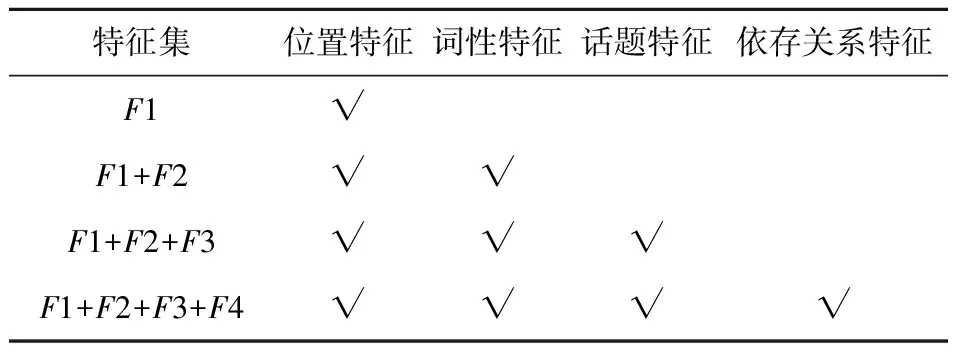
表5 对照识别实验特征集
在各组对照实验中分别应用4种分类算法:朴素贝叶斯(NBC)、决策树(C4.5)、大规模线性分类支持向量机(LIBLINEAR)[32]以及贝叶斯网络(BN)[33-35].贝叶斯网络是贝叶斯机器学习方法的一种,又称信念网络.它是基于有向无环图(directed acyclic graph,DAG)来刻画特征之间依存关系的一种网络结构,可以由变量节点和所有连接这些节点的有向边组成.节点代表随机变量(词),节点间的连接边代表节点(词语)之间的依存关系,并可用条件概率来表达这些关系的强弱.可用下式表示.
(4)
其中,pa(xk)表示节点xk的父节点.依据公式4分析例句3的贝叶斯网络模型可表示为:
P(加)P(可以|加)P(一下|加)P(扣扣|加)P(聊|加)P(回头|聊)P(一下|聊)P(哈|聊).
表6反映了模型针对不同话语标记词的4种模型的分类准确率、召回率和调和均值,各个特征集上的最高数值用加粗字体显示.从模型分类效果的角度看:4种分类模型中,大规模线性分类支持向量机和贝叶斯网络的话语标记识别性能最好,尤其是,在4种特征组合对照实验数据上准确率、召回率和调和均值都是最高值;朴素贝叶斯分类性能最低,具体原因是朴素贝叶斯分类要求特征属性之间相互独立,而4种特征集合中词与词之间存在依存关系,不能满足独立性假设,故而效果最差;决策树的性能居中.
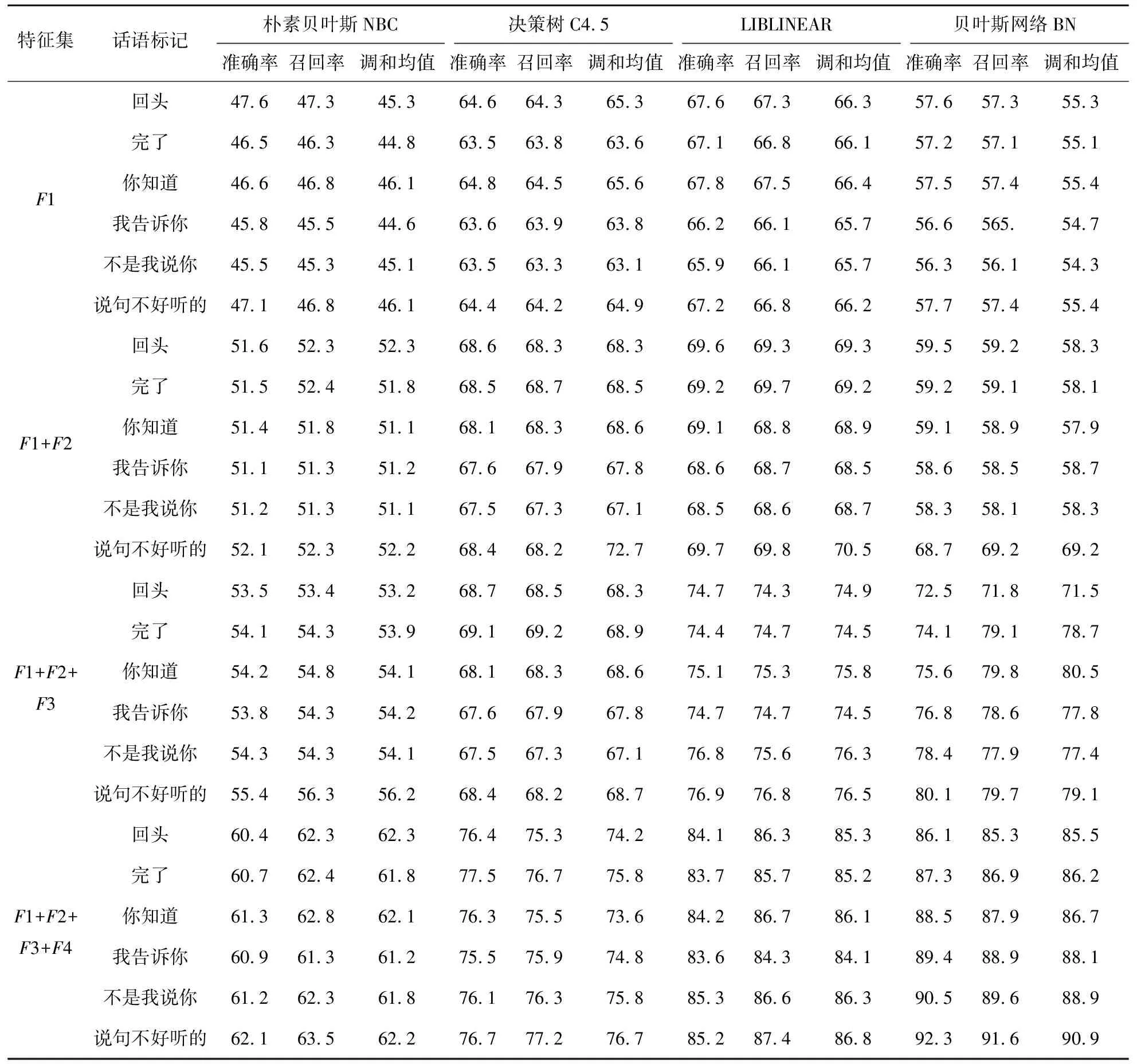
表6 4种模型在不同话语标记词的识别实验结果
从特征组合对话语标记识别的效果来观察:1) 随着特征依次的增加,4种分类模型实验中话语标记的准确率、召回率和调和均值均有改善,在所有特征都输入模型后,准确率、召回率和调和均值到达最优值,还说明每种特征集或多或少起到区分识别话语标记的作用;2) 从依存关系特征的作用效果来观察,表7中所示的是缺失依存关系特征后的准确率变化情况,4种模型的识别实验数据中,缺失依存关系特征后准确率存在显著降低.以贝叶斯网络模型为例,在缺失依存关系特征后“回头-完了-你知道-我告诉你-附带说几句-还是那句老话”识别准确率分别下降13.6%、13.2%、12.9%、12.6%、12.1%和12.2%,进一步验证了依存关系特征在话语标记识别中的显著作用;3) 从特征组合对准确率的改善程度来观察,特征组合逐步增加是贝叶斯网络模型准确率的变化状态,如图7所示,在依次加入词性特征、话题特征和依存关系特征的过程中,对照观察,依存关系特征相对于其他特征能够有效提升模型准确率,反映出依存关系特征更有利于提取自然口语文本中蕴涵关联信息.
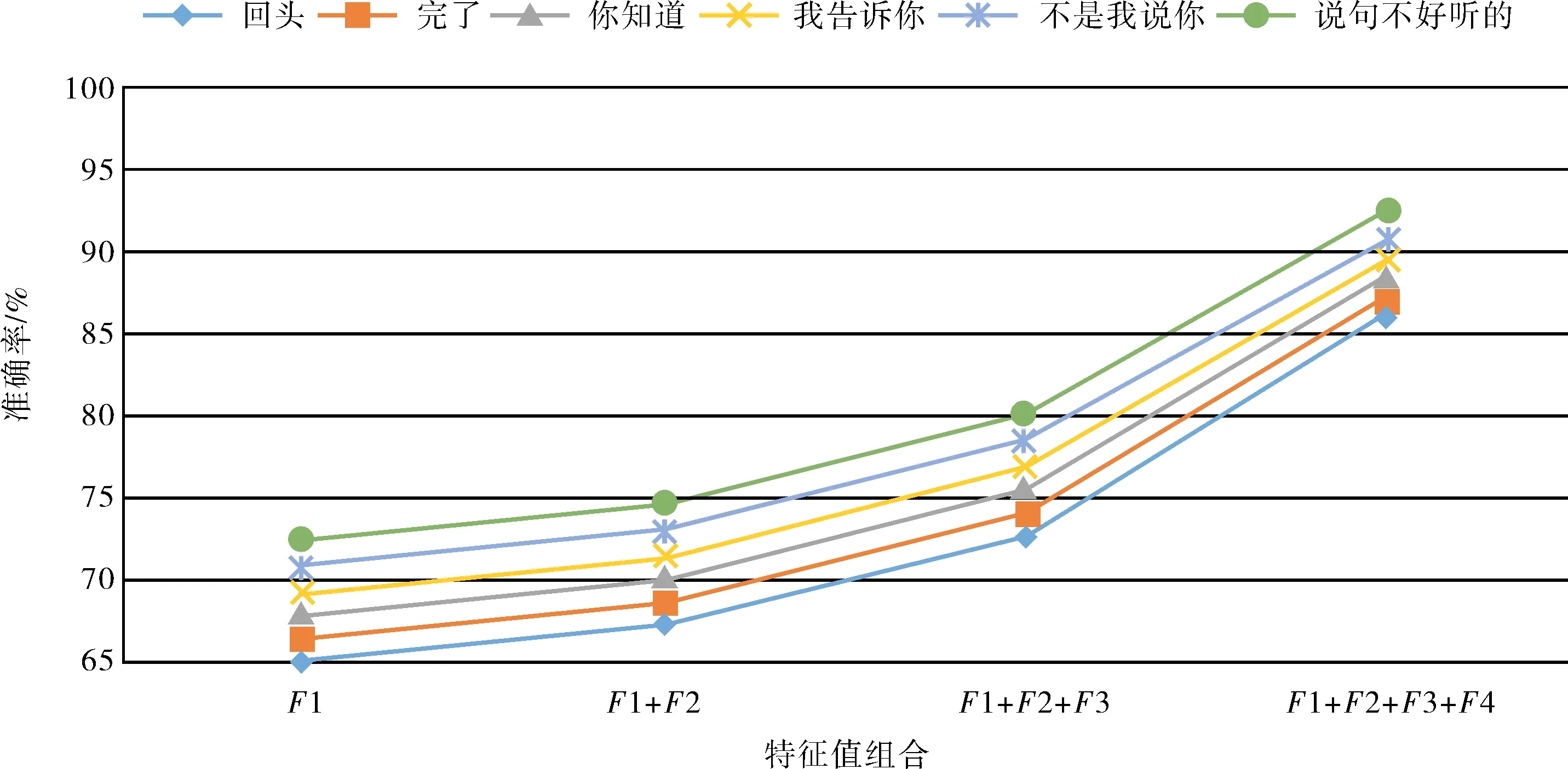
图7 话语标记识别增加特征组合对贝叶斯网络模型准确率的贡献Fig.7 Contribution of feature combination to the accuracy of Bayesian network model by discourse marker recognition
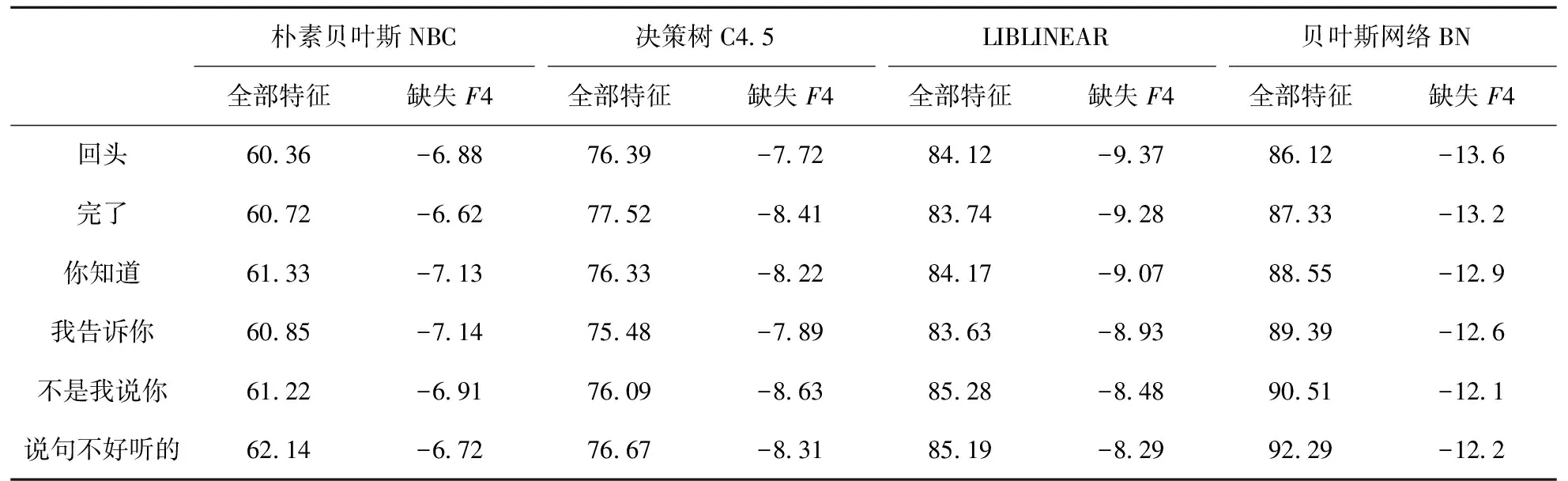
表7 缺失依存关系特征的四种模型在不同话语标记词的识别实验结果
从话语标记词语长度对自动识别的影响来分析:1) 从表7中的“回头”和“我告诉你”全特征组合实验数据可观察出,贝叶斯网络话语标记识别平均准确率为90.5%,平均召回率为91.2%,平均调和均值为91.3%,验证本研究采用的特征组合模型较好适应话语标记识别,鲁棒性较优;2) 总体上观察,发现话语标记依次从2字词到6字词时,话语标记识别的准确率逐步提升,特征组合模型对于词的长度增加识别力逐步提升;3) 从话语标记识别率最高的贝叶斯网络模型来分析,表8所示为话语标记字数增加贝叶斯网络准确率的变化情况,表明当字数逐步增加时,贝叶斯网络模型准确率与话语标记字词长度是正相关的;4) 从特征组合对话语标记字数的敏感度来观察,图7说明了依次增加特征集合时,从2字词话语标记到6字词话语标记上贝叶斯网络模型准确率的识别趋势,可观察到字词越少,则导入依存关系特征后准确率改善越明显,分析原因是位置特征和词性特征在2字词等兼类词上特征相对稀疏,使得依存关系特征对少字符的话语标记识别的作用更加显著.

表8 话语标记字数增加贝叶斯网络准确率的变化
另外,当不同候选词统计概率相当时,准确率也出现了一定的波动.例如“回头”包含两种用法,即动词用法和话语标记用法.然而在部分情况下,两种用法在上下文环境的区分非常不明显,如“回头一看”和“回头一想”,显然前者是动词用法,后者是话语标记用法.这种需要引入语义信息,甚至是固定搭配才能识别的情况一定程度上影响了最终的分类准确率.
5 结语
目前针对中文话语标记识别的研究相对较少,且中文话语标记识别也存在着语料不足,话语标记识别复杂度高的问题.本文将句法依存关系和语义依存关系表示自然口语的模型特征,与自然口语的话轮位置特征、词性特征和主语话题特征相比,它可以有效地刻画口语流水句易位、叠连、重复的特点.本文提出句法依存关系和语义依存关系,均能显著提升4种模型对话语标记的识别准确率,对照观察,依存关系特征相对于其他特征能够有效提升模型准确率,反映出依存关系特征更有利于提取自然口语文本中蕴涵关联信息.进一步验证了依存关系特征在话语标记识别中具有较强的可行性和鲁棒性.
本文通过自建的汉语自然口语语料库,针对当前深度学习人工智能方法存在的原理上不可解释性和语义上不可解释性两个方面难题,综合分析后采用事前解释类型的自解释模型方法,具体为朴素贝叶斯、决策树、大规模线性分类支持向量机以及贝叶斯网络4种解释性强的机器学习方法,完成自然口语话语标记的识别对比实验,得出最优识别准确率为92.3%.实验结果还表明句法依存关系和语义依存关系对话语标记识别贡献更大,远距离和跨句的语义依存关系是识别的难点.本研究的识别对比实验例证了本方法的可行性和有效性,为今后研究提供基础的准确率指标参照.
下一步将在语义依存关系表示基础上,引入更多语义信息,同时在扩充汉语自然口语标注语料库规模的基础上,探索基于新一代无监督预训练模型以及融合更多可解释性潜在特征信息的知识,提高话语标记识别准确率.语言智能是人工智能的重要组成部分,是让计算机拥有人类的语言智能[36].话语标记与人工智能的“交叉融合”,对言谈互动、话语理解、情感分析、人机问答和口语机器翻译都具有重要意义.
猜你喜欢
开放教育研究(2020年2期)2020-03-31
数理化解题研究(2017年4期)2017-05-04
小天使·一年级语数英综合(2016年4期)2016-11-19
铁道通信信号(2016年6期)2016-06-01
现代语文(2016年21期)2016-05-25
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2016年6期)2016-05-14
电子器件(2015年5期)2015-12-29
小天使·一年级语数英综合(2015年10期)2015-10-14
大连民族大学学报(2015年2期)2015-02-27
