
向量搜索在电商商品批量检索的应用
2023-11-15 01:51:28朱俊
宝钢技术 2023年4期
朱 俊
(欧冶工业品股份有限公司,上海 201900)
1 批量检索背景介绍
在采购任务的背景下,企业或组织通常需要采购大量的工业品,以满足生产和运营的需求。这些工业品可以包括原材料、零部件、设备和其他必要的物资。为了高效地完成采购任务,采购商经常依赖于工业品电商平台,这些平台提供了一个集中展示和销售各种工业品的市场。
然而,传统基于分词索引的搜索方法在处理这类批量检索任务时面临许多困难,这些困难点限制了采购商在工业品电商平台上的效率和准确性:
(1)大规模查询:采购商需要查询大量的商品以了解不同产品的特性、价格和供应商等信息。传统的搜索方法在处理大规模查询时往往效率低下,需要耗费大量时间和资源。
(2)搜索时间长:采购商需要尽快获得关于大量商品的信息,以便做出及时的决策。然而传统的搜索方法由于基于分词索引和词条匹配的方式,搜索时间较长,无法满足采购商的快速查询需求。
(3)意图理解困难:传统搜索方法无法理解采购商的意图。它们只依赖于词条匹配,而无法准确捕捉采购商的具体需求和意图。这导致搜索结果可能不够准确,使采购商在评估和比较商品时面临困难。
(4)不准确的搜索结果:传统方法的词条匹配搜索可能产生不准确的结果,因为它们无法考虑商品的多维特征和相似性。这使得采购商在选择合适的商品时可能遇到困难,增加了采购决策的风险。
综上所述,批量采购任务在工业品电商平台上存在一些挑战和困难。为了解决这些问题,引入向量搜索技术可以提供快速、准确的商品检索,同时能够更好地理解采购商的意图,提升搜索结果的准确性和效率。
2 向量搜索技术背景介绍
2.1 向量搜索框架和原理
向量搜索技术也被称为近似最近邻搜索(approximate nearest neighbor search,ANN),是一种针对海量高维数据进行快速查询的算法技术。该技术的基础是将复杂的对象或数据转换成高维空间中的向量,通过计算向量之间的距离来进行相似性比较。在人工智能和机器学习领域,数据通常被表示为高维向量。例如,在自然语言处理中,词语和句子可以被表示为高维向量,这就需要使用向量搜索技术来查找最相关的信息。
向量搜索技术可应用于较多场景,例如在推荐系统中,需要找出与用户历史行为最相似的物品来进行推荐,可以将用户的行为和物品的属性都转化为向量,然后通过计算向量之间的距离来找出最相似的物品;在图像和视频搜索中,可以将图像和视频的特征提取出来,转化为向量,然后通过向量搜索技术来找出最相似的图像或视频;在自然语言处理里,可以将词语和句子转化为向量(词向量和句向量),然后通过向量搜索技术来完成诸如语义搜索,文本相似度计算,机器翻译等任务。在生物信息学领域,基因序列、蛋白质序列等也可以被表示为高维向量,通过向量搜索技术快速找出具有相似特性的基因或蛋白质。
向量搜索能够将语义信息映射到高维向量空间中,通过向量间的相似度计算,在检索过程中找到与查询条件相似的对象。向量搜索框架通常包括以下几个部分:
(1)向量表示:利用深度学习模型(如Word2Vec、GloVe、BERT等)进行嵌入,将被搜索文本转换成高维向量。这些模型通过对大量文本数据进行训练,学习到每个词汇(或短语)在语义空间中的表示,从而捕捉词汇间的关系和上下文信息[1]。
(2)索引构建:以哈希表等数据结构构建好文本向量索引,并采用近似的搜索策略[2]。例如FAISS、Annoy、HNSW等都是流行的向量索引库。
(3)查询处理:将用户的查询转换为相应的向量表示,然后在索引中检索与该查询向量相似的结果。相似性通过计算查询向量与索引中向量之间的距离来实现。
(4)结果排序与优化:对检索到的结果进行排序和优化,以提供更准确的检索结果。
2.2 向量搜索用于批量检索的优点
相较于传统搜索方法,向量搜索在批量检索方面支持批量快速运行,可高效地在大规模向量空间中查找最相似的结果。此外向量搜索方法能够捕捉词汇和语义信息,使得向量搜索能够更好地理解用户输入的搜索语句,并在搜索结果中体现语义相关性。
3 基于向量搜索的批量检索方案及试验结果分析
3.1 基于FAISS的商品批量检索方案
本文提出了一种基于FAISS的向量搜索方案,用于快速搜索大规模向量数据集中与给定向量最相似的项[3],具体步骤如下:
(1)商品的文本嵌入。
首先通过内部商品数据产生一个文本嵌入模型。这里采用Sentence-BERT模型作为文本嵌入工具,Sentence-BERT能够结合人工整理后的商品专业词库按词进行嵌入,相比BERT按token嵌入有更好的效果[4]。方案中采用1 790 100条商品数据进行微调,包含商品名称、型号规格、品牌、技术属性信息、商品类别信息等。
(2)建立FAISS索引。
通过微调后将每个商品嵌入768维的向量并建立FAISS indexFlatL2索引,即通过计算搜索文本与商品向量的欧几里得距离进行索引(图1)。

图1 商品嵌入及FAISS索引建立
(3)搜索文本加强。
借助积累好的品牌、型号规格词库,通过对搜索文本进行处理以加强搜索文本的特征,处理内容包括:
① 基于型号规格词库,使用jieba分词提取文本中的型号规格信息。
② 基于商品专业词库,使用Sentence-BERT分词对搜索文本进行分词。
③ 使用Sentence-BERT对搜索文本进行嵌入。
(4)FAISS召回。
使用FAISS对搜索文本进行召回,取相较于搜索文本向量的欧几里得距离最近的1 000条商品作为召回结果,并对计算得到的欧几里得距离进行归一作为距离权重。搜索文本对第i个召回结果的距离权重S1i的计算方法为:
(1)
式中:Dmax为1 000个召回结果中的最大距离;Di为第i个召回结果的距离。
(5)型号规格权重计算。
对搜索文本中提取出来的型号规格进行切词,得到一系列切开的型号规格,并去除空格、逗号等无意义符号。计算搜索文本对第i个召回结果的型规权重S2i:
(2)
式中:Ci为搜索的型号规格切词在第i个召回结果中出现的个数;L为搜索文本切词的数量。
(6)加权排序。
将距离权重S1i和型规权重S2i加权相加,得到第i个召回的排序权重Si(图2):

图2 搜索文本召回及排序
Si=0.3S1i+0.7S2i
(3)
因为应用场景中对型号精确匹配有较高的要求,故此处经人工试验后距离权重S1i的加权设置为0.3,型规权重S2i的加权设置为0.7,加权可以根据实际场景需求进行调整。计算每个商品的排序权重后,根据排序权重进行降序排序,取前五个结果作为匹配结果。
上述步骤为针对单条搜索文本的处理过程,在批量搜索的场景中,采用FAISS的批量索引方法进行批量召回及距离权重计算,再针对每条搜索文本进行常规权重计算和加权排序即可。
3.2 试验结果对比
基于FAISS的向量搜索方案与传统基于分词索引的ES搜索从如下两个方面进行对比:
(1)准确率Precision。
取Precision@20、Precision@10、Precision@5,即分别取20、10、5个返回结果,判断它们是否都符合搜索意图,若有不符合的则认为此条结果不准确,取正确结果数量/n作为准确率。
(2)搜索耗时。
以100条商品搜索信息(包含搜索商品名称与主要型号规格信息,且每条商品均有5条以上可匹配商品)为输入,从170 W商品集合中进行数据匹配,此外,ES搜索和FAISS向量搜索部署在同一台服务器上,算力及网络环境相同。本次采用FAISS-CPU模式,未使用GPU资源进行加速。搜索准确率对比如表1所示。
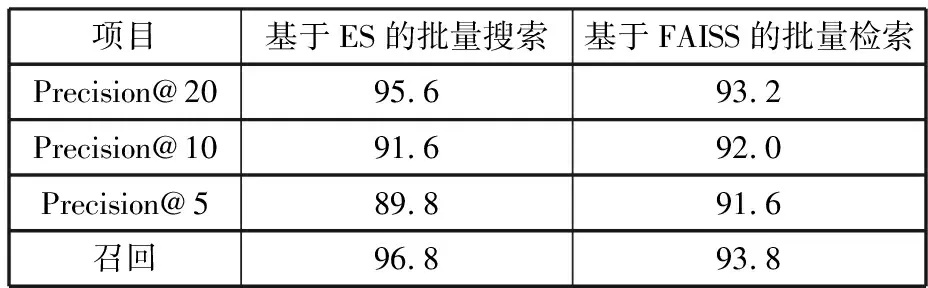
表1 基于ES和FAISS的批量检索准确率对比
试验结果表明,在搜索速度上向量搜索有较大优势,在100条搜索文本下向量搜索仅需4.40 s就能完成搜索,而ES需要耗时约18.21 s。但FAISS相对ES搜索的召回率略低,经结果分析发现,主要问题在于文本嵌入模型无法很好地学习一些低频专业词的语义,尤其是型号规格,而当搜索文本仅包含型号规格时,向量搜索无法召回全部正确结果,此问题后续可以通过针对这些语义理解效果差的词进行数据增强,并再次微调Sentence-BERT以优化语义嵌入表现。这仍将导致FAISS检索在Precision@20的准确率略低于ES搜索。但由于FAISS检索在召回阶段后可以加入更精细的排序策略,因此排序效果优于ES搜索,在Precision@10以及Precision@5上均高于ES搜索。
4 结语
本文针对电商商品批量检索场景,提出了一种基于FAISS的向量搜索方案。相较于传统搜索方法,该方案具有搜索速度快、能够理解搜索语义及针对召回结果进行精确排序的优势。本文提出的方案仍有改进空间,例如可尝试更多的预训练模型,以及在后处理排序阶段可以考虑更多的特征进行加权。
猜你喜欢
中国商人(2025年2期)2025-01-24 00:00:00
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
科学家(2021年24期)2021-04-25 12:55:27
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
现代企业文化·理论版(2017年17期)2018-01-08 11:07:14
阜阳职业技术学院学报(2015年4期)2015-05-17 03:58:58
中国管理科学(2014年8期)2014-04-10 01:51:50
温州职业技术学院学报(2014年3期)2014-03-11 19:03:39
