
基于深度强化学习算法的机器人浮动打磨执行装置研究
2023-11-15 08:08张一然李长耿
制造技术与机床 2023年11期
张一然 杨 龙 袁 博 李长耿
(中车青岛四方机车车辆股份有限公司,山东 青岛 266111)
近年来,随着机械加工产品精度质量要求的提高和国内制造业的发展,机器人打磨抛光技术成为我国重要的发展方向之一[1-3]。传统的打磨抛光主要以手工操作为主,不仅会使工人面对打磨抛光产生的噪音和粉尘污染,而且难以保证打磨质量的一致性。使用工业机器人打磨可以保证打磨过程的可重复性,代替工人参与打磨的恶劣环境,并且可以消除人为误差,保证打磨精度和一致性[4-5]。然而,由于机器人打磨执行器与打磨工件为刚性接触,在打磨过程中容易造成打磨接触力的不稳定,甚至损坏工件。因此,打磨力的柔顺稳定控制是影响机器人打磨质量优劣的关键因素[6-7]。
针对机器人打磨的柔顺力控问题,国内外学者开展了相关研究[8-11]。目前,柔顺力控方法主要包括主动柔顺控制和被动柔顺控制。被动柔顺方法往往采用简单的弹簧机构进行柔顺,对简单零件的平面打磨有一定适用性。但被动柔顺方法不能精确地控制打磨接触力,在对复杂曲面零件进行打磨时,打磨效果不佳。因此,Nagata F[12]提出了基于力位混合控制的机器人主动柔顺力控打磨方法,实现了高精度的机器人曲面零件抛光。许家忠等[13]提出了一种基于自适应阻抗控制的机器人柔顺力控方法,并将其应用于复合材料工件打磨,获得了较好的打磨效果。然而,采用机器人主动柔顺力控算法进行打磨力控制,往往因难以获得机器人的精确模型而实现高实时性和鲁棒性的控制,导致力控精度和响应速度不佳[14]。
针对工业机器人存在的接触力难以恒定控制问题,为了实现打磨接触力的恒定,本文提出一种用于机器人末端的浮动打磨执行器。对浮动打磨执行器进行了结构设计,并进行了力控系统建模分析和控制算法设计;最后进行了恒力跟踪试验,验证了装置的恒力控制精度。
1 浮动打磨执行器工作原理与结构设计
1.1 浮动打磨执行器工作原理
浮动打磨执行器的工作原理如图1 所示。浮动打磨执行器作为一种主动柔顺力控装置,需要额外的驱动装置提供动力输出。气压驱动相比于液压和电磁驱动,具有结构紧凑、气源易获得、压缩性大等优点,因此选用以气缸为主要动力元件的气压驱动方式实现力的主动控制。气源提供气体,经由比例阀实现气体流量的控制,进而实现气缸内部压力和打磨头接触力的控制。力传感器实时测量打磨头接触力,控制系统根据反馈的打磨头接触力,调整比例阀开口大小,实现打磨力的闭环控制。

图1 浮动打磨执行器的原理
1.2 浮动打磨执行器结构设计
图2 所示为机器人浮动打磨末端执行器的结构示意图。考虑到运动的一致性,选用两个相同规格、内部带有磁环的气缸作为驱动结构,以实现气缸活塞位置的实时检测。通过调节比例阀控制进入气缸两腔的气体体积进而控制气缸内部压力,从而控制输出打磨力。直线导轨和滑块提供浮动自由度,与两个气缸对称放置,以减小偏载力矩对控制性能的影响。浮动打磨执行器装置通过机器人连接法兰与机器人连接,通过打磨头连接法兰与力传感器和打磨头连接。力传感器通过将实际打磨力实时反馈至控制系统,实现打磨力的闭环控制。

图2 浮动打磨执行器内部结构
2 浮动打磨执行器力控系统建模分析
2.1 受力分析
将浮动打磨装置分为浮动部分和固定部分,进行受力分析,如图3 所示。假设此时重力方向与打磨法向的夹角为θ,装置浮动部分的总质量为m。单个气缸的无杆腔面积为A1,压力为P1;有杆腔面积为A2,压力为P2。浮动打磨装置与打磨工件之间的接触力为Fn,摩擦力为Ff,打磨头的位移为x。

图3 浮动打磨装置受力分析
根据牛顿第二定律,可以得到浮动打磨装置的力平衡方程为
式中:Gθ=mgcosθ,为装置浮动部分的重力在打磨表面法向上的分量。
2.2 力控系统建模分析
由比例阀进行气体压力的调节。比例阀的输出压力P和输入电压U的关系可以表示为
式中:K1和k两个参数与气缸的特性有关。
对浮动装置受力分析得到的式(1)进行拉普拉斯变换可以得到:
力控系统的控制框图如图4 所示。

图4 力控系统控制框图
力控系统的开环传递函数可以表示为
式中:Gc为控制器的传递函数;Gd为D/A 转换器传递函数;Gh为零阶保持器;Gp为力控系统传递函数;Gpr为打磨过程的传递函数。
当浮动打磨装置与打磨工件接触时,打磨输出力Fn可以使打磨头产生位移x,其关系可以表示为
式中:Km、ωn、ζ分别为刚度、自然频率和阻尼比。
将摩擦力Ff视为扰动,可得系统整体的传递函数为
至此,完成浮动打磨力控系统建模。由式(6)可知,力控系统可以视为三阶系统,系统存在惯性环节,需要设计控制算法以提高力控系统的控制性能。
3 基于深度强化学习算法参数整定的PID控制
3.1 传统PID 控制
PID 控制算法是工业中技术成熟、应用广泛的一种控制算法[15-16],结合比例、积分和微分3 个环节于一体,以实现闭环系统的控制,其控制算法框图如图5 所示。
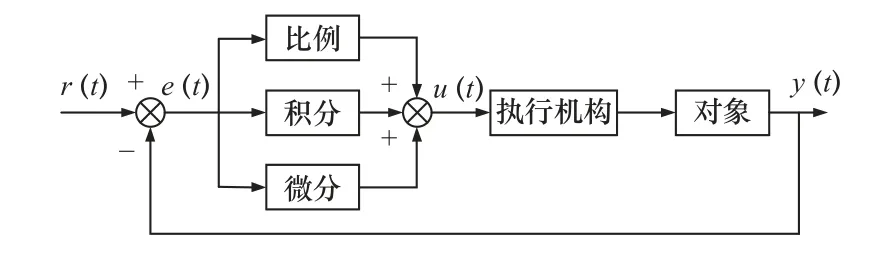
图5 PID 控制算法图
PID 控制算法基于误差信号e(t)(即期望值r(t)与实际值y(t)之间的差异),向误差信号减小的方向调整控制信号u(t),基于控制信号u(t)实现执行机构控制,进而控制系统的实际输出值y(t),使其尽可能接近期望输出值。在浮动打磨执行器的浮动打磨控制过程中,期望输出值为用户设定的期望打磨力,实际输出值为打磨执行器作用在工件上的实际打磨力,从而实现打磨力的控制。
PID 调节器的微分方程可表示为
式中:e(t)=r(t)-y(t)。
PID 调节的传递函数可表示为
PID 控制参数对系统性能影响较大[17-18],需要对比例环节、积分环节和微分环节进行分析。
(1)比例环节:通过比例参数与误差信号的乘积产生控制信号,按比例调节使误差信号减小。选择较大的比例系数往往会减小系统的稳态误差和上升时间,提升系统的控制精度和反应时间。但过大的比例系数,也会相应地提高系统的超调量,产生系统震荡。
(2)积分环节:仅调节比例系数,无法消除系统的稳态误差,因此需要引入积分环节。增大积分系数,往往会降低系统的上升时间,改善提高系统的稳态性能。但过大的积分系数,容易使系统产生震荡,影响系统的稳定性。
(3)微分环节:通过预测偏差的变化趋势对系统调整,从而达到超前的控制效果。
3.2 DDPG 深度强化学习算法
深度强化学习算法是将深度学习和强化学习结合起来的算法[19-22]。深度学习在感知问题上具有强大的理解能力,而强化学习具有强大的决策能力。深度强化学习融合了两者的优点,具有强大的感知和决策能力,在研究中广泛得到应用[23]。深度强化学习算法框架如图6 所示。智能体作为一个可以获取环境状态作的实体,首先观察环境状态,并根据经验策略进行下一步的动作。智能的动作可以对环境状态产生改变,环境状态发生改变后会反馈智能体奖励值,智能体根据奖励值对经验策略进行优化,以在之后获取更高的奖励值。如此反复进行迭代学习,最终获得满足要求的智能体和策略。

图6 深度强化学习算法框架图
DDPG 算法是将Actor-Critic 算法和DQN 算法结合起来、应用于连续控制领域的一种深度强化学习算法[21-24],适用于状态空间连续和动作空间连续的问题,其算法原理图如图7 所示。

图7 DDPG 算法原理图
DDPG 深度强化学习算法首先初始化Actor 网络和Critic 网络,并生成一组同样参数的目标网络。Actor 网络在与环境交互后,将其状态、动作、奖励和下一时刻的状态记录在经验缓冲区内,然后从经验缓冲区中生成新的状态、动作、奖励和下一时刻的状态信息,并在Critic 网络中计算Q值,并按照Q值最大的方向进行Actor 网络参数的修正。最后将目标网络与主网络参数同步,进行下一轮的迭代处理。
相比于其他参数优选算法,DDPG 算法能在连续的动作空间确定地选择唯一的动作。而参数调整是基于高维状态空间以及连续动做决策的,因此采用DDPG 算法可以很好地完成参数优选问题,进而更适用于浮动打磨执行器的柔顺控制。
3.3 基于DDPG 算法的PID 控制参数整定
PID 参数对控制系统的控制性能影响很大,因此选取合适的PID 控制参数是影响控制效果优劣的关键。在大多数工业场合,PID 控制参数的选取依靠经验进行试选,从中选取一个合适的值。然而本文设计的浮动打磨装置,具有强耦合和非线性的特性,仅依靠经验进行PID 控制参数整定,往往难以取得较好的控制效果且效率低下。DDPG 深度强化学习算法适用于在连续状态空间和动作空间中寻找最优解,可用于PID 控制参数整定,其原理框图如图8 所示。

图8 基于DDPG 算法的PID 参数整定原理框图
采用DDPG 深度强化学习算法进行PID 控制参数整定步骤如下。
步骤1:首先进行DDPG 的网络初始化,设置网络相关参数和PID 参数初值,并且设置输出的PID 参数范围,以避免不合理的PID 控制参数可能引起的较差的控制效果。
步骤2:Actor 网络将打磨过程中的性能指标作为奖励信息,与新的状态信息放入经验缓冲区中,并在Critic 网络中计算Q值,并按照Q值最大的方向更新Actor 网络和Critic 网络,完成此次DDPG算法的迭代学习。
步骤3:DDPG 算法输出PID 控制参数值到PID 控制器中,进行一次打磨过程。计算此次打磨过程的性能指标,包括力偏差均值、力偏差均方差值和上升时间,并将性能指标以状态向量的形式输入到DDPG 算法。
步骤4:判断此次打磨过程的性能指标能否满足控制性能要求,若满足要求则输出此次PID 控制参数,结束迭代学习;若不满足要求,则重复步骤2 和步骤3,进行下一次迭代学习。
4 浮动打磨执行器恒力性能验证
搭建图9 所示的xPC Target 浮动打磨执行器实验平台,对本文设计的浮动打磨执行器进行恒力控制性能验证。实验平台主要由浮动打磨执行器、高速数据采集卡、PC 上位机和xPC 目标下位机组成。实验平台中,上位机软件进行控制参数的设定,并进行打磨输出力的实时曲线显示;下位机采集浮动打磨过程中的传感器信号发送给上位机,并依据上位机控制参数设定进行打磨力的控制。实验过程中,保持打磨头为开启状态,通过给定阶跃信号的打磨期望力,测量实际打磨力的跟随情况,以测试打磨执行器的恒力控制性能。

图9 xPC Target 实验平台
经过多次手动整定PID 参数,设置比例参数为0.3、积分参数为0.05、微分参数为0.1,测试结果如图10 所示。
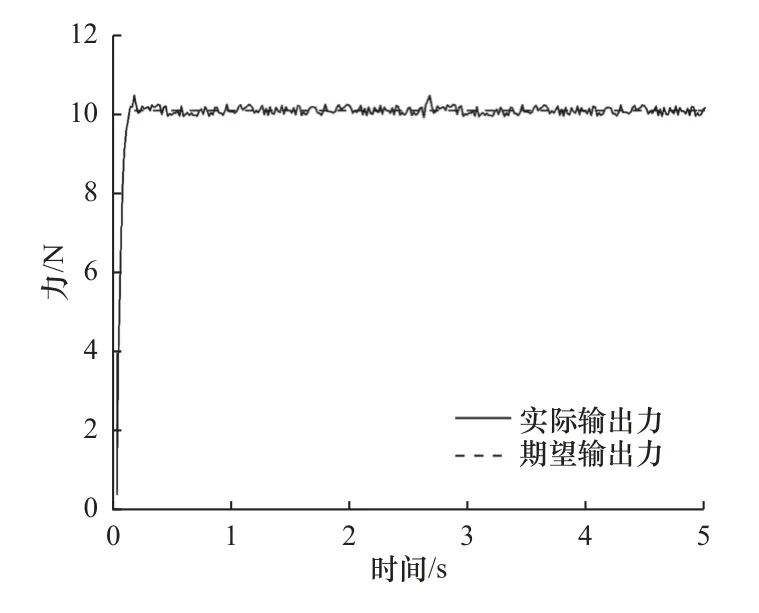
图10 PID 控制实验曲线
试验结果表明,由于打磨头的开启,实际打磨力会产生一定程度的抖动,实际输出力能较稳定地跟随期望输出力。
基于DDPG 深度强化学习算法进行PID 参数整定,进行了打磨实验测试,测试过程开启打磨头,测试结果如图11 所示。
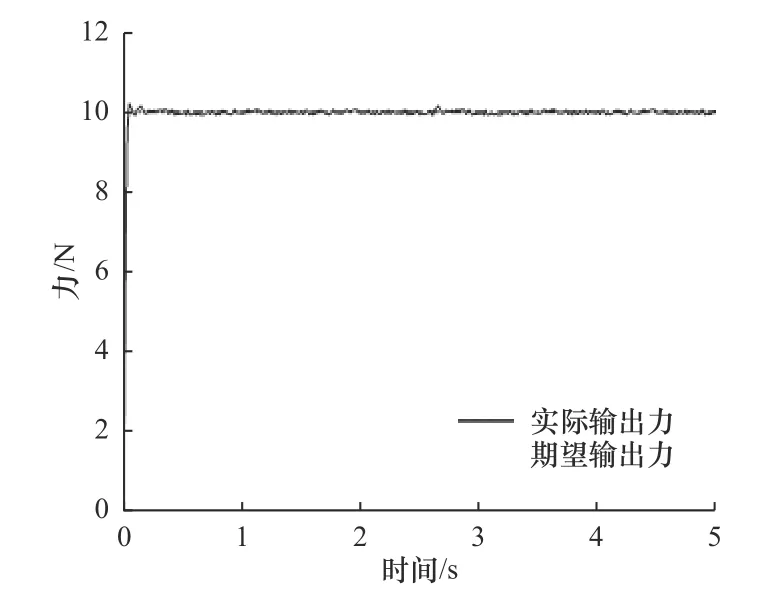
图11 DDPG 参数整定后的PID 控制实验曲线
分别计算两组实验输出力数据的性能指标,包括实际输出力与期望输出力的偏差的均值、均方差以及实际输出力的上升时间,结果见表1。
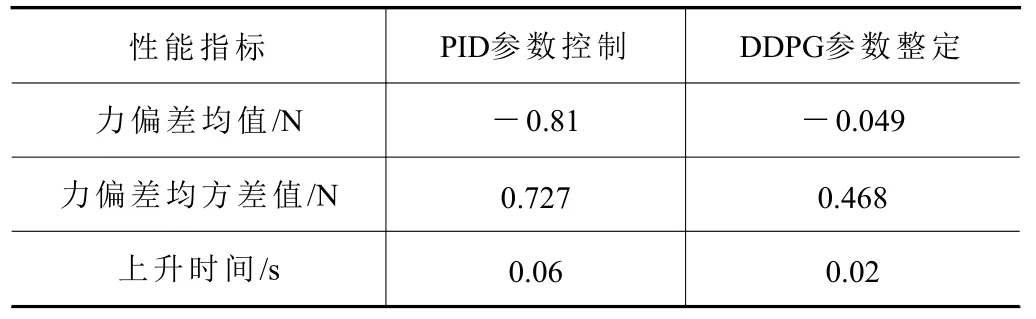
表1 输出力性能指标比较
由表1 中数据可知,采用DDPG 深度强化学习算法进行PID 参数整定,获得了更小的力偏差均值和均方差值以及更快的上升时间,从而具有更高的力控精度和响应速度。
5 结语
本文面向机器人自动化打磨抛光需求,进行了浮动打磨执行器的结构设计和力控系统建模分析,并开展浮动打磨执行器的控制方法设计。在传统PID 控制算法的基础上,采用DDPG 深度强化学习算法进行PID 控制参数的整定,进行了浮动打磨执行器恒力打磨实验验证。实验结果表明,本文设计的浮动打磨执行器,在采用DDPG 算法进行PID 控制参数整定后,获得了较好的恒力控制性能,具有较强的力控精度和鲁棒性,可以实现接触力的实时监测与恒力控制,可应用于各种机器人自动化打磨抛光领域。
猜你喜欢
船舶标准化工程师(2023年2期)2023-09-30
飞控与探测(2022年6期)2022-03-20
力学学报(2020年4期)2020-08-11
中国外汇(2019年19期)2019-11-26
石油化工建设(2019年4期)2019-10-10
制造技术与机床(2018年11期)2018-11-23
制造技术与机床(2017年9期)2017-11-27
黑龙江电力(2017年1期)2017-05-17
投资者报(2017年18期)2017-05-13
汽车与安全(2016年5期)2016-12-01
