
基于半直接法的高度激光里程计
2023-11-13 16:10高珂肖辉勇姜宇凡李琼峰杨济源王斐
应用科技 2023年5期
高珂,肖辉勇,姜宇凡,李琼峰,杨济源,王斐
1. 东北大学 信息科学与工程学院,辽宁 沈阳 110819
2. 湖南柿竹园有色金属有限责任公司,湖南 郴州 423037
3. 西北工业大学 玛丽女王工程学院,陕西 西安 710129
4. 东北大学 机器人工程学院,辽宁 沈阳 110819
随着国家对矿山安全要求指标不断提高和对井下作业人员安全的重视,目前的井下作业系统已经不足以满足信息化的需求。物联网、无人驾驶以及5G 等新一代技术日趋成熟,基于同步定位与建图(simultaneous localization and mapping,SLAM)技术的井下作业自动导向车(automated guided vehicle,AGV)的研究逐渐成为热点。对于井下作业AGV 来说,在降低计算成本的同时,保证AGV 运动的稳定性也非常重要。在SLAM 系统中,最重要的部分之一是前端部分,它通常执行逐帧姿态估计,从而形成里程计子系统[1]。目前主流的里程计分为视觉里程计(visual odometry,VO)和激光雷达里程计(liDAR odometry,LO)2类[2]。视觉里程计在纹理不丰富、光照变化明显的环境下鲁棒性较差;相比之下,激光里程计通过匹配激光点云数据完成帧间的匹配从而进行运动估计,在光照条件不足的情况下鲁棒性较强,是更加稳定的选择。但是激光雷达采集的数据中过多的点云数量造成了激光里程计计算成本过高的问题[3]。于是,研究人员开始尝试将激光与视觉传感器的优势融合在一起,形成激光雷达视觉里程计,这样的结合可能在各种场景环境中尤其是在特殊结构或者光照不足的环境中会具有更强的鲁棒性[4]。但是使激光里程计融合1 台或多台摄像机需要更复杂的设置,他们的融合并不容易;并且,同时使用2 种以上的传感器很难使系统速度更快。
目前现有的视觉SLAM 与激光SLAM 方法根据其地图的表示方式可分为2D、3D 和2.5D 这3 种[5]。其中由于2D 能体现的信息较少,因此不能应用于许多开放的室外环境;而3D 地图的信息量虽然较大,但一般效率较低[6];采用2.5D 的表示方法,可以缩小点云的维数和计算代价,从而实现精度与计算代价之间的平衡[7]。
在基于直接法的SLAM 算法中,瑞士苏黎世大学的研究人员[8]提出了基于半直接法的半直接视频里程计(semi-direct monocular visual odometry,SVO)。SVO 算法通过对关键帧提取(features from accelerated segment test,FAST)视觉点特征来构建新地图点,并采用深度滤波器进行地图点的深度估计。因为算法作用于稀疏的像素点,因此能够在机载嵌入式计算机上以55 f/s 的速度运行。同济大学的研究人员[1]使用基于2.5D 网格图的直接LO 方法用于室外环境中的自动驾驶汽车。该方法借鉴了SVO 结构,将视觉中的直接方法与ORB (oriented fast and rotated brief)方法[9]中的FAST 关键点相结合,专注于解决运算性能问题。该方案是基于视觉方法的高效激光测距里程计,不仅充分利用高度图信息,也在一定程度上降低了直接法的不确定性;并且提出的方法使用激光雷达代替相机,解决了传统VO 受光照影响较大的问题,可以在大多数系统上实现高效定位。到目前为止,研究人员已经在这一领域进行了大量的研究工作,但是想要在复杂的环境中保持系统的轻量化与高效率仍然面临较大的挑战[10]。
受到以上研究启发,本文专注于使用纯三维激光点云数据完成快速精确的定位,而无需任何额外的视觉传感器或强度信息。同时,为了节省计算资源,本文提出了基于半直接法的高度激光里程计(height laser odometer based on semi-direct method,SLO)方法,将三维激光点云投影至指定平面上,然后存储每个点云在世界坐标系中的高度信息,将其点云高度平均值作为图像中该像素点的灰度值,生成2.5D 深度图像,从而避免了对三维点云的直接计算。因为视觉方法中的灰度不变假设是一个很强的假设,在实际应用中很难成立。对此,本文算法将灰度不变假设改进为高度不变假设,在激光里程计中使用视觉里程计中的方法,基于高度不变假设[11]进行位姿估计,这在现实中比灰度不变假设的鲁棒性更强。
本文的主要贡献是将激光雷达与基于2.5D栅格地图的半直接单目视觉方法相结合,将其应用于复杂的室外环境,大大降低了复杂环境数据计算成本,保持了系统的轻量化和高效率。
1 SLO 系统概述
1.1 预处理
首先给定图像序列和激光雷达序列,其次假设已经完成了激光数据球坐标向笛卡尔坐标的变换。本文将激光的局部坐标设置为本体坐标,将世界坐标设置为本体坐标的起点。
1.2 系统总体框架
系统的整体框架如图1 所示,该框架包含位姿估计与局部地图构建2 个运行线程。在运动估计过程中,SVO 将运动估计与建图分成了2 个并行计算的线程。它基于构建的稀疏地图点,首先通过最小化图像之间的光度误差,初步计算了每帧图像的位姿;然后通过优化视觉点特征位置并最小化重投影误差,进一步优化了位姿估计。由于算法作用于稀疏的图像像素点,因此它能够在CPU 上以很高的帧率运行。本文提出的SLO 算法参照了SVO 的架构,综合了直接法和特征点法的优点,设计了3 步策略。此方案能够很好地处理稀疏的3D 点云数据,从而比一般的激光里程计更加轻量,比基于直接法的视觉里程计更加鲁棒。

图1 SLO 算法整体框架
1.3 创建高度图
三维激光里程计获取的大量点云数据可以显示环境物体的位置和高度,但点云数据是在重建过程中采集的,这消耗了大量的处理器硬件资源。因此,本文主要关注点云表征数据,以减少CPU 的计算压力。为了识别地面,提出了2 个假设:一是假设传感器大致安装在水平移动底座上;二是假设地面的曲率很低。
采用灰度值保存高度信息的方法,在不牺牲物体高度信息的情况下,将3D 点云转换为2D 图像,保留了2D 网格图易于存储和构建的优点,同时也保留了高度信息,生成的高度图如图2 所示。

图2 激光点云数据转化
1.4 跟踪线程初始化
算法首先初始化变换矩阵T为单位矩阵,检测第1 张灰度图像的特征点,若灰度图像中检测的特征点数量超过设定的阈值,就把这张图像作为第1 个关键帧。然后从第1 帧图像开始,使用LK (lucas-kanade)光流法持续跟踪特征点,并计算从第1 帧图像开始的连续图像与第1 帧图像的视差,如果视差中位数大于阈值,就认为初始化成功,并将与此对应的帧设定为第2 个关键帧,将提取的特征点作为地图点加入局部地图,进入正常跟踪模式。
1.5 位姿估计
在运动估计线程中,SVO 算法基于构建的稀疏地图点,通过最小化图像之间的光度误差,初步计算每帧图像的位姿;然后通过最小化重投影误差优化了视觉点特征的位置,进一步优化了位姿估计[12]。本文SLO 算法位姿估计跟踪线程流程如图3 所示。

图3 跟踪线程流程
1)基于角点的图像对齐。使用稀疏直接法粗略计算当前帧的位置和姿态,并建立损失函数(最小化光度误差),利用高斯–牛顿(Gauss-Newton,GN)优化算法得到帧间的2 个位姿变换。目标函数为
式中
其中:π-1(u,du)为根据高度图像素位置u逆投影到三维空间后得到的三维点坐标p,T·π-1(u,du)为将三维坐标点旋转平移到当前帧坐标系下,π(T·π-1(u,du))为将当前帧坐标系下的三维坐标点投影到当前帧高度图像坐标,I(u)为特征点周围4×4的像素块的高度值。由于这一步是一个粗略的计算,为了加快计算速度,因此没有进行仿射变换。
利用GN 法求解2 个高度映射的转移矩阵T,即2 个栅格地图之间的最小高度差误差[1]。根据直接法和链式法则,雅克比矩阵Ji可分为3 部分。
式中:
像素梯度计算使用双线性插值方法计算,即
然后,用高斯牛顿法求出扰动
式中。H=JTJ
最后,判断此帧是否满足关键帧要求,若满足则插入局部地图,并在这个新的关键帧上检测新的特征点作为地图点。
2)基于点的特征对齐。关键帧中提取的特征点在被赋予深度后得到的三维点被称为地图点,由于本文使用的灰度图为激光点云投影生成的图片,激光关键帧中的关键点信息伴随着深度信息,他们的灰度值就是深度,即整个图片相当于“上帝视角”的图片,故本文算法去除了SVO 中的深度估计步骤,地图点经过筛选后可直接放入到局部地图中[13]。
完成角点的图像对齐后,算法获得了当前帧雷达的位姿,因此可以通过重投影将地图点投影到当前帧中,而正是由于这种帧与帧之间的位姿估计会有累计误差,所以投影后的地图点在新的图像帧中的投影位置也会随之产生误差。因此算法可以根据高度不变假设构造一个残差,对于每个特征点单独考虑,对特征预测位置进行优化,即
式中:Ik(ui′)为当前第K帧图像中第i个特征点的亮度值(即高度值);后一部分为Ir(ui)而不是Ik-1(ui),因为它是根据局部地图投影的地图点追溯到这个地图点所在的关键帧中的像素值,而不是相邻帧。
相比于基于角点的图像对齐粗测,基于点的特征对齐选取了8×8的图像块范围来比较均值差,可以得到亚像素级别的精度。
3)位姿迭代优化。利用优化后的特征块预测位置,使用直接法再次对位姿构建优化函数进行估计:
最后建立局部地图,判断这个帧是否是关键帧,如果是关键帧,提取新的特征点。
2 SLO 算法验证实验
采用KITTI 数据集[14]与AGV 移动平台来验证所提出的算法。在本实验中,使用HDL-16 激光雷达在东北大学浑南校区收集数据来进行实验测试。
将图像分成固定大小的单元(像素值大小为800×800)。算法中的参数设置为:处理点云数据截取的窗口的宽度Iwidth=400、高度Iheight=400,灰度图的每个栅格的大小fx=0.1、fy=0.1,像素值倍增系数cx=200、cy=200。
正态分布变换与迭代最近点方法是传统的处理三维激光点云的算法,因此本文首先对比了他们的性能。本部分实验全部为完成畸变补偿的情况下进行,在实验中分别比对了PCL (point cloud library)中集成的迭代最近点(iterative closest point,ICP)算法、正态分布变换 (normal distributions transform, NDT)算法以及改进的基于高斯牛顿算法的ICP 算法。实验记录了每50 和100 m 的阶段误差以及全程的累计误差,阶段误差实验结果对比如图4 所示。数据如表1 和表2 所示,由数据可以看出在3 种算法的每50 m 均方根阶段误差(root mean squared error, RMSE)和每100 m 的均方根阶段误差的对比实验中,NDT 算法的效果最好,基于高斯牛顿的ICP 算法次之。
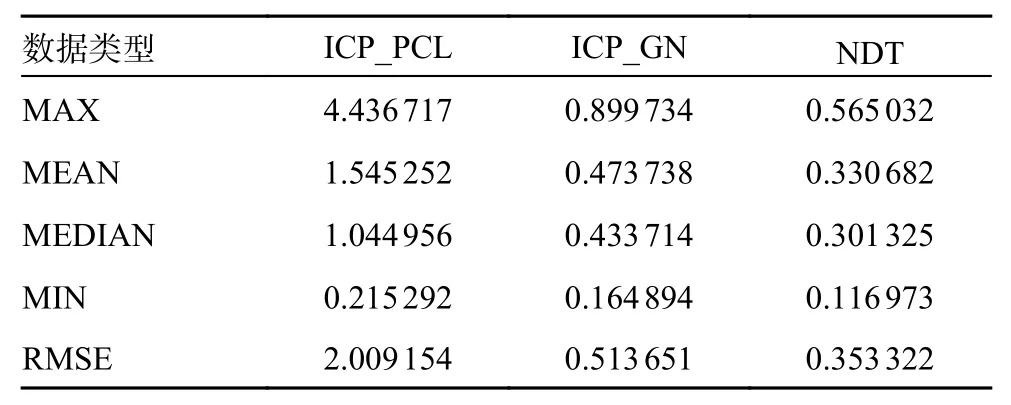
表1 ICP 和NDT 的分段距离误差/50 m
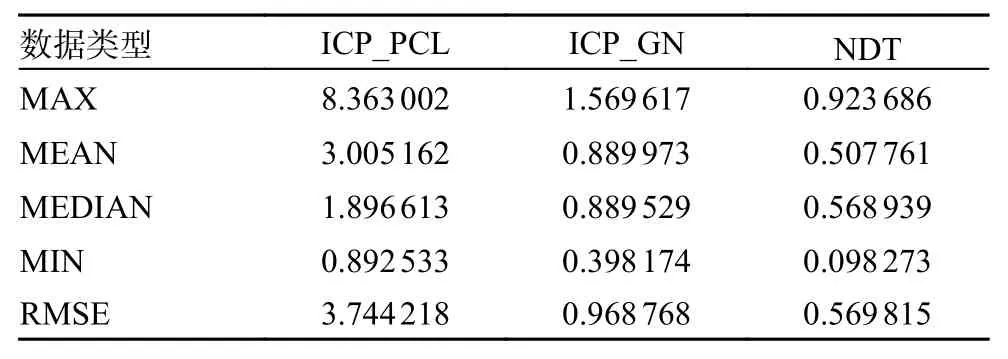
表2 ICP 和NDT 的分段距离误差/100 m

图4 3 个匹配算法的位姿估计结果与真值的对比
累计误差的实验结果图如图5 所示,在全程的累计误差中,基于高斯牛顿的改进ICP 算法显示出了更好的优势,数据如表3 所示。

表3 ICP 和NDT 的全程累计误差
本文提出的SLO 算法在预处理部分参考了DLO[1]中的方法,算法使用KITTI 数据集中序列07 的轨迹中的某帧点云来测试提出的投影方法,算法生成灰度图后使用LK 光流跟踪算法[15]跟踪的结果如图6 所示。

图6 某帧灰度图LK 光流法的效果
算法针对相邻两帧点云进行了ORB 特征点[16]的提取与匹配,特征点的匹配结果如图7 所示,可以看出匹配结果绝大多数是正确的。

图7 某帧灰度图的ORB 特征点匹配结果
本文在真实环境中分别进行了灰度图的生成以及匹配实验,实验选用的平台为AGV 移动平台,该平台配置16 线激光雷达,雷达测量距离为100 m 左右,垂直测量角度30°(±15°),扫描过程中从下往上计数,-15°记为初始线(第0 线),一共16 线。使用镭神16 线激光雷达进行实验的结果如图8 和图9 所示。

图8 东北大学324 室实验室场景图匹配实验
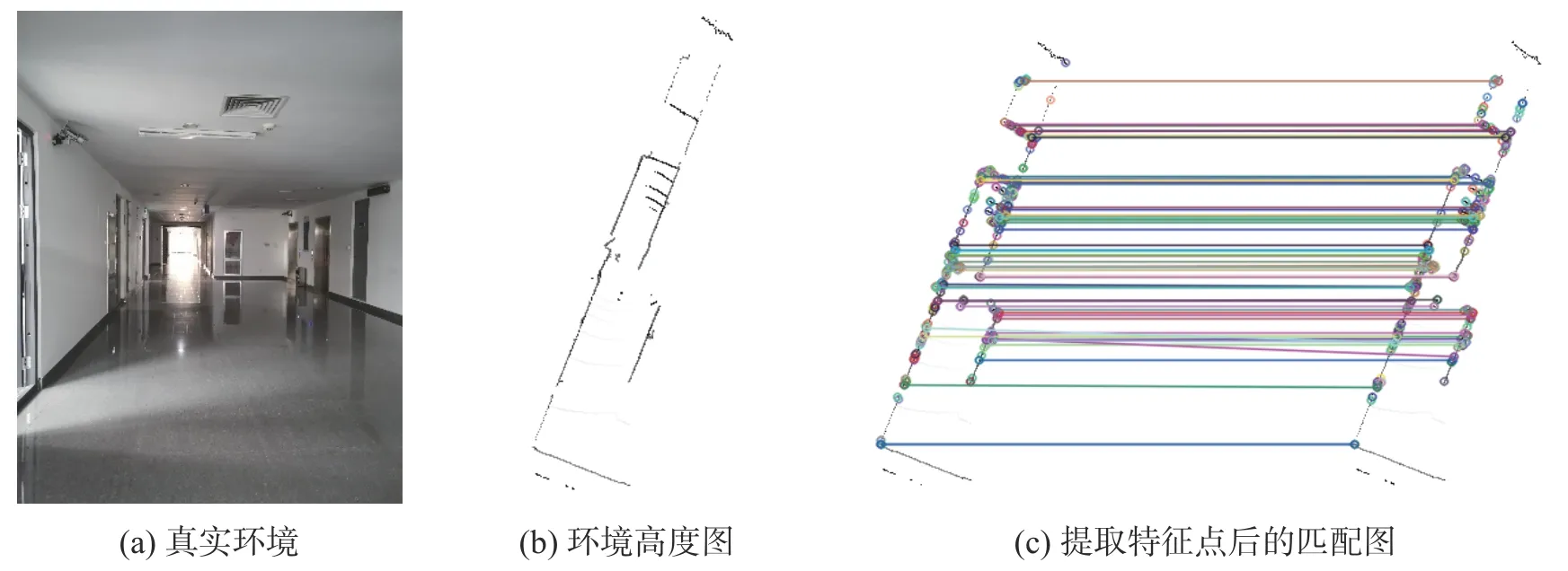
图9 东北大学教学楼3 楼走廊场景图匹配实验
SLO 算法将点云处理成高度图阶段的精简效果如表4 所示。由表4 中数据可以看出,本文提出的投影方法有效地缩少了点云的原始数据;并且在对高度图进行特征点提取后,算法可以在保证场景环境特征的基础上完成对数据大数量级的精简。
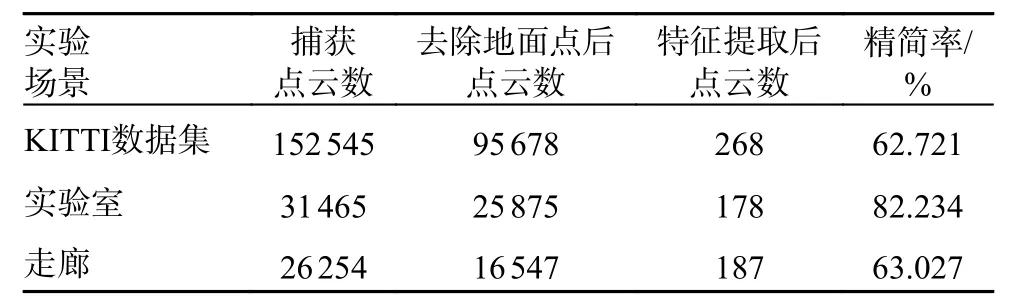
表4 点云精简效果
3 结束语
由于井下作业AGV 平台的应用场景可以是室内也可以是室外,因此本文选择了一种不受环境因素影响的激光里程计来估计平台的姿态。考虑到激光数据处理需要大量的计算量,本文选择将点云数据转换为高信息特征点,它将三维点云转换为灰度,可大大节省数据存储和计算,并且通过应用半直接法,提高了精度,使整个过程轻量化。此外,当图像特征匹配时,使用迭代最近点法执行姿势估计,这使得最小二乘问题实际上具有解析解,并且不需要迭代优化。
本文提出的SLO 方法合理地结合了视觉里程计和激光里程计的优点。在未来的研究中,基于高度图提取点和线特征会更容易,基于投影构建拓扑图也是一个值得尝试的思路。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年6期)2022-07-02
昆明医科大学学报(2021年6期)2021-07-31
高技术通讯(2021年3期)2021-06-09
科学(2020年5期)2020-11-26
中国惯性技术学报(2019年1期)2019-05-21
小哥白尼(趣味科学)(2019年2期)2019-04-17
传感器与微系统(2018年7期)2018-08-29
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年1期)2016-11-07
