
基于边缘计算的鱼眼相机高空抛物检测系统
2023-11-10 08:14:34林诗妍刘宇翔魏宏安
福建师范大学学报(自然科学版) 2023年6期
林诗妍,刘宇翔,魏宏安
(福州大学物理与信息工程学院,福建 福州 350108)
高空抛物也被称为“悬在城市上空的痛”,是一种严重威胁公共安全的行为.由于抛物物体的高处释放,其速度和冲击力巨大,一旦击中行人、车辆或建筑物,将导致严重的人身和财产损失,这种不负责任的行为不仅给受害者带来巨大痛苦,也给社会带来恐慌和不安全感.但进行高空抛物巡查需要投入足够的人力来巡查和监控潜在的危险区域,并且巡查范围广泛,需要对多个区域进行巡查.这增加了巡查任务的复杂性和耗时性,同时也增加了发现高空抛物的难度.因此,引入计算机视觉监测技术来加强监管迫在眉睫.
计算机视觉监测在高空抛物检测中已经被广泛采用,主要使用目标检测技术来自动识别高空抛物行为.这些目标检测技术主要包括基于深度学习的方法,在一定程度上解决了传统手工提取特征难的问题,使得系统更加自动化和智能化.然而,当前的计算机视觉监测系统仍然面临一些新问题.首先,由于采用深度学习等复杂算法,计算复杂度较高,需要更强大的硬件资源来支撑系统的运行,这可能导致系统投入成本增加,尤其是在需要大规模监控的场景下.其次,由于高空抛物行为通常是不规律和随机的,监测系统在大部分时间可能处于空闲状态,这会导致资源浪费和运行效率低下,因此这些问题成为当前研究的重点.
一种解决方案是将复杂的任务集中到云端处理,以减轻终端设备的计算压力.但随着万物互联时代的到来,终端设备数量的增加,集中式的云计算模式无法负担海量数据的存储和处理.当前基于深度学习的视觉任务带来高复杂度的计算,终端设备的计算能力有限,并且也难以满足数据处理实时性、安全性以及能耗方面的需求.为了应对移动设备日益增长的数据处理需求,以及物联网应用需要的低延迟、高带宽、高性能的计算服务,边缘计算应运而生.
本文针对当前高空抛物行为监测难度大,取证困难等挑战,设计了一种基于鱼眼相机边缘计算的实时性抛物动目标检测系统.主要可以分为视频采集、动目标检测和目标识别3个模块,其中视频采集模块和动目标检测模块位于系统终端.视频采集模块的监控端能够采集到被检测楼房的全貌信息,并对采集到的视频进行预处理;目标检测模块算法可以检测到大小、形状以及种类不确定的被抛物体;放置在边缘端的目标识别模块基于深度学习对检测视频序列进一步精确识别物体.本文主要贡献如下:
(1)设计了一个高空抛物检测系统,旨在有效应对高空抛物行为带来的安全隐患.系统可以自动识别高空抛物行为,为城市安全提供强有力的保障.
(2)使用鱼眼相机作为移动端,将视频监控的视野范围扩大,确保全方位对高空抛物行为进行锁定,进一步提高系统的覆盖能力和准确性.
(3)为了进一步提高系统的效率和节省成本,引入边缘计算技术对图像在终端进行校正和初步排查,并将深度学习目标识别任务迁移至边缘服务器端,旨在有效减轻终端的计算负担,提高系统的实用性和可扩展性.
1 相关工作
1.1 动目标检测研究现状
动目标检测是图像处理和计算机视觉领域的基础性算法,在视频监控领域有着举足轻重的地位.其主要原理是对视频图像中发生变化部分的分离,基于几何和统计特征的图像分割,主要目的在于从视频图像中提取出运动目标并获得其特征信息.根据动目标检测算法特点可将其分为3类:背景减法[1]、帧差法[2]、光流法[3].光流法是物体在运动时图像亮度模式的表观运动,即空间物体表面上的点的运动速度在视觉传感器的成像平面上的表达,当目标区域运动时,计算图像帧的光流场,具有相同光流向量的区域,其运动模式也相同,则可以看作一个运动目标,达到将运动目标分割出来的目的;帧差法是常用的运动目标检测和分割方法之一,即利用视频流帧序列中的前后两帧或者当前视频帧与前某视频帧的差分来计算当前图像帧中的运动目标区域;背景差法是通过将当前帧与定义的背景帧的差分计算运动目标区域[4].
其中,光流法由于计算量较大,难以达到实时性,而且噪声、多光源、阴影和遮挡等因素都会对光流场分布的计算结果造成严重影响,同时稀疏的光流场很难精确提取运动目标的形状,所以不适合适用于视频监控系统;背景差法由于外界环境变化频繁,会造成结果受外界环境影响而引入大量噪声,影响检测结果[5];帧差法具有算法简单、计算复杂度较低、实时性强等优点,并且由于误差和噪声在相邻帧之间位置相近,系统误差和噪声对检测结果影响不大.此外,由于相邻帧的时间间隔非常短,帧差法对光照有一定抗干扰能力.经过分析,结合视频监控场景的特有属性以及系统实时性要求,本文选择使用帧差法进行抛物检测.3种动目标检测算法的比较如表1所示.

表1 动目标检测算法比较Tab.1 Comparison of moving target detection algorithms
1.2 目标识别研究现状
目标识别技术的发展可以追溯到20世纪50年代,在那个时期,目标识别主要依赖于手工设计的特征提取器,例如SIFT[6]、HOG[7]等.这些方法能够从图像中提取局部特征,并将其用于目标检测、模板匹配等任务.然而,由于手工设计的特征提取器局限于人为经验,难以适应复杂多变的目标场景.随着时间的推移,目标识别算法不断进化.到了20世纪70年代,出现了以统计建模为代表的算法,如K-means聚类、K近邻分类器、支持向量机(SVM)等,这类方法利用大量数据进行特征学习和迭代训练,实现对目标的分类和识别.虽然这些算法在一定程度上提高了目标识别的准确性,但仍然存在对特征提取的依赖,且在复杂场景下效果有限.在20世纪末,出现了一些基于机器学习的目标识别方法,如主成分分析(PCA)、线性判别分析(LDA)、隐马尔科夫模型(HMM)等[8].这些方法在一些特定场景下取得了不错的效果,但对于大规模复杂的目标识别任务仍存在局限性.
随着物联网时代的到来,目标识别算法在人们生活中已经成为不可或缺的一部分,不仅能节省人力,也能大幅度提高工作效率.新的目标识别算法不断涌现,也在一定程度上推动了智能视频监控领域的蓬勃发展.当前深度学习已经成为目标识别的主流方法,其中卷积神经网络是应用最广泛的模型.目前主流的目标识别算法主要分为基于分类器和检测框的two-stage算法和基于回归的one-stage算法,前者有RCNN[9]、Fast RCNN[10]、Faster RCNN[11]等,而SSD[12]、YOLO[13]则为one-stage算法中的代表,其能在保证较高的准确率的同时拥有更低的时间和硬件损耗,具有更大实用性和广泛性.深度学习的优势在于能够自动从数据中学习特征表示,从而解决了传统方法中手工设计特征的瓶颈.此外,深度学习算法还能够逐层抽象和处理图像信息,有效地提取高级语义特征,提高了目标识别的精度和鲁棒性.
1.3 边缘计算研究现状
边缘计算是一种新型的计算模式,其核心思想是“计算要更靠贴近用户”,旨在将存储、计算能力从云数据中心迁移到距离数据较近的边缘一侧,可支持在网络边缘端处理大型深度学习模型,避免了视觉任务从网络边缘到远距数据处理中心的网络延迟,达到实时性的视觉应用要求.边缘计算并不是为了取代云计算,而是对云计算的一种扩展补充,在解决设备本身资源的缺陷的同时,也减少了需要传送云端的数据量,缓解网络带宽的压力.
边缘计算最直接的方法就是终端设备将其数据发送到附近的边缘服务器,并在服务器处理后接收相应的结果[14].Vigil[15]是一个实时无线监控系统,它在边缘计算节点上执行处理,以智能地选择帧进行分析.相比传统的视频流上云的方法,Vigil在与摄像头和云位于同一位置的边缘计算节点之间智能分区视频处理,可以减少带宽消耗.在Wang等[16]提出的用于物联网中射频传感的通用深度学习框架中,将DNNs卸载到边缘服务器来分析无线信号.类似地,Glimpse[17]也将所有的DNN计算部署到附近的边缘服务器.
为了满足当前用户数据公共安全隐患的需求,解决终端设备在资源受限、计算性能等方面存在的不足,需要对动目标检测系统进行必要的改进,提高数据处理的实时性,缓解云中心的计算压力.此外,为了能准确高效地提取高价值的数据信息,还需在边缘端对视频数据进一步处理.因此,针对实时抛物动目标检测系统,本文选择了终端和边缘服务器相结合的边缘计算架构.
2 高空抛物系统设计
2.1 系统总体框架
系统总体框架如图1所示.终端设备是部署在公共场所、建筑物和工地等需要进行高空抛物检测的位置的计算设备,通常为嵌入式系统,具备一定的计算能力.终端设备通过鱼眼相机扩大视频监控视野,负责实时采集视频流并进行处理.然而,由于鱼眼相机产生畸变,影响了动目标检测的准确率.为解决此问题,在终端设备上进行畸变矫正和动目标检测,实时结构化分析视频并寻找运动目标轨迹,并将可能为高空抛物事件的图片视频传输至边缘端.
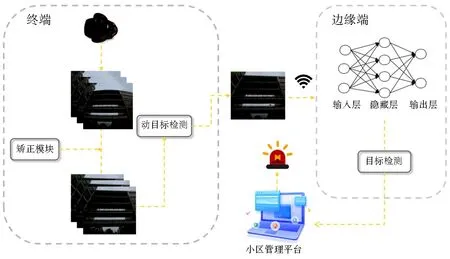
图1 系统总体框架Fig.1 General framework of the system
边缘服务器基于深度学习算法对经过初步动目标检测的视频序列进行识别,过滤掉误识别事件,例如树叶、飞虫等.一旦识别到有垃圾被抛下,小区管理平台将立即触发告警.将初步动目标检测和预处理部署至终端,可在本地快速处理数据,并将关键信息传输到边缘服务器进行深度学习推理,从而降低网络传输延迟,提高实时性和系统性能.边缘服务器负责对实时性、计算能力要求较高的目标识别任务进行处理,通过深度学习算法进一步精确识别物体,以获得更高质量的服务体验.该系统架构有效利用了边缘计算的优势,将处理任务分配到终端设备和边缘服务器,优化了计算资源的利用,提高了高空抛物检测系统的效率和准确性.
2.2 视频矫正模块
鱼眼相机在拍摄过程中会使图像产生畸变,拍摄后需要对图像进行畸变矫正.相比于其他方法,基于棋盘格标定法的相机畸变矫正具有精确性、简便性、可靠性和广泛应用性,能够满足实时抛物动目标检测系统对于高质量图像的要求,并为系统提供更准确的图像数据.本文使用OpenCV中的鱼眼矫正模块对采集到的视频进行矫正,模块使用的是Kannala提出的鱼眼相机的一般近似模型[18],该模型基于等距投影模型而提出.图2显示的是用于实验的棋盘格标定图.

图2 棋盘格标定示例图Fig.2 Checkerboard calibration map
利用OpenCV寻找棋盘格中的角点位置[19],角点后将以一定的顺序排列,并进行棋盘格角点的绘制.图3显示的是棋盘格图绘制前后的对比图.

图3 角点绘制前后对比图Fig.3 Comparison of before and after corner plotting
相机标定的目的是得到鱼眼相机的内外参以及畸变系数.函数在求出相机参数后利用ceres进行优化[20],再利用优化后的内外参以及畸变参数矫正整幅图像.经过鱼眼相机标定,成功获得本文使用的鱼眼相机的内参和畸变参数.计算得出的相机内参矩阵K和畸变参数矩阵D如下所示:
(1)
(2)
上述参数对于后续的图像校正非常关键,利用这些参数可进行无畸变和修正转换映射计算,并得到映射结果.最后,通过应用这些映射,成功获得经过校正的视频图像.图4展示了原始图像和校正后图像的对比,图4中清晰显示该矫正算法的有效性.本文通过去除鱼眼相机造成的图像畸变问题,提高了后续目标检测的准确性.

图4 畸变矫正前后对比图Fig.4 Aberration correction comparison chart
2.3 终端动目标检测
对于经过校正的图像视频序列,采用动态目标检测技术进行初步排查,以识别并定位可能存在的移动目标.在终端上执行这一过程,使得高空抛物检测系统能够在终端设备上进行实时快速的数据处理.并且终端设备的计算能力和存储资源相对较小,仅将关键的初步处理放在终端可以更好地适应不同规模和需求的系统部署,优化了系统性能和可扩展性.
2.3.1 动目标检测技术
帧差法是在视频序列中快速提取多运动目标的算法,主要用于相邻帧之间,其基本思想是通过当前帧与相邻帧之差,以此判断物体运动.帧差法主要分为两帧差分法和多帧差分法.帧差法具体步骤如下:
首先,将第k帧灰度图像fk(x,y)和第(k-1)帧灰度图像fk-1(x,y)相减得到差分图像,并取绝对值,如式(3)所示:
D(x,y)=|fk(x,y)-fk-1(x,y)|.
(3)
进而通过OTSU算法[21]获得适当的阈值.前景像素指的是将图像种差分结果大于阈值的点视为运动目标,背景像素指差分结果小于阈值的部分.在理想状态下,差分运算能保留前景像素,除去背景像素.为了更好监测各种不同场景的视频图像,需要选用合适的阈值对灰度图像进行二值转换,以消除噪声干扰:
(4)
其中,T为预先设定的阈值,若选取阈值过大,则检测目标可能会出现目标运动区域空洞或漏检现象;若阈值选取过小,将会出现大量噪声.当(x,y)差分结果小于阈值T时,像素值为0即代表背景像素.当两帧之间的差异大于或等于T时,像素值为255代表前景像素.最后将聚集前景点的区域作为目标区域[21].
两帧差法同时具备两个缺点:
(1)检测到的目标内部存在空洞、漏检.从帧差法公式可以看出,如果物体匀速运动,帧差法得到的运动目标会比较一致,但当物体加速或减速时,可能会产生漏检现象.并且因为相邻帧之间时间间隔非常短,导致相邻帧中的移动物体具有重叠区域.重叠区域上个点的灰度差值小于阈值,因此会被误认为背景,导致移动物体内部出现空洞.
(2)无法有效检测得到物体的轮廓.因为两帧之间的运动目标变化不能反映在目标的边界,提取到的目标区域就会轮廓模糊.
这两个缺陷影响了帧差法运动物体检测的准确性.为解决上述两个缺点,有学者提出三帧差法.三帧差法充分考虑了运动像素的时间相关性,对动态监测比较敏感,对随机噪声也有很好的抑制作用[22],检测结果优于两帧差法,可以避免“空洞现象”.但其需要根据经验选取最合适的阈值[23].本文使用三帧差法,其关键在于选取合适的阈值对图像进行二值化变换.
图5为三帧差法原理框图,具体过程如下:
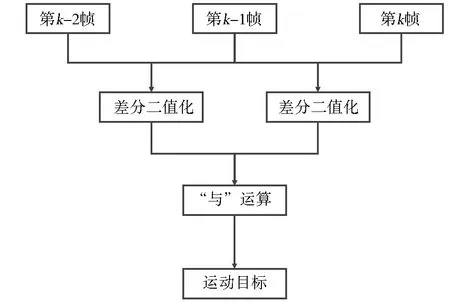
图5 三帧差法算法原理框图Fig.5 Block diagram of the three-frame difference algorithm
首先,由式(3)可知,对连续的三帧图像进行差分,可得到两个差分图像,即k-1帧与k-2帧的差分图像和k帧与k-1帧差分图像;其次,分别通过选定与之对两个差分图像通过式(4)进行阈值化处理,得到对应二值化前景图像Dk(x,y)和Dk+1(x,y);最后,通过式(5)可知,两个二值化前景图像通过“与”运算,得到运动目标图像Sk(x,y).
Sk(x,y)=Dk(x,y)∩Dk+1(x,y).
(5)
2.4 边缘端目标识别
通过帧差法进行差异分析,能够精确锁定运动轨迹,并输出经过处理的视频序列,以提醒相关人员.为了进行更进一步的目标识别,这些视频序列将被传输至边缘服务器端.
考虑到高空抛物视频场景的背景复杂性和目标尺寸较小,本课题选择采用先进的YOLOv5模型进行目标检测.本文利用边缘端的计算资源,运用YOLOv5模型来进行视频序列的检测工作.相较于传统的目标检测算法,YOLOv5具有更快的检测速度和更好的检测精度,不仅可以进行高空抛物目标的类别分析和运动轨迹定位,还能够有效过滤误识别事件.这使得系统能够快速而准确地识别高空抛物目标,提高了系统的可靠性、响应能力和实用性.
YOLO系列是目前工业领域使用最多的目标检测网络模型,目前已有多个较为成熟的版本.YOLOv5是一种端到端的目标检测算法,通过使用先进的数据增强技术和新颖的网络结构,能够在相对较少的数据集上训练出高性能的检测模型.此外,YOLOv5具有较快的检测速度和较高的精度,能够在实时系统中进行目标检测,同时还支持在不同的场景和应用中进行自定义的训练和调整.YOLOv5目标检测模型相比于其他YOLO系列模型,采用了新的网络架构和训练策略.YOLOv5的网络架构如图6所示[26],基于主干网络和检测头.主干网络采用了CSP(cross-stage partial)[24]架构,这是一种轻量级的特征提取网络,可以在减少参数的同时提高准确性.检测头包括一个3×3的卷积层和一个预测层,用于生成目标的边界框、类别和置信度等信息.在训练方面,YOLOv5采用了一种新的方法SWAC(self-train with accumulated confidence)[25],它通过在模型中累积置信度高的样本来增强模型的泛化能力.此外,YOLOv5还使用了一种自适应的图像增强策略,可以提高模型的鲁棒性.
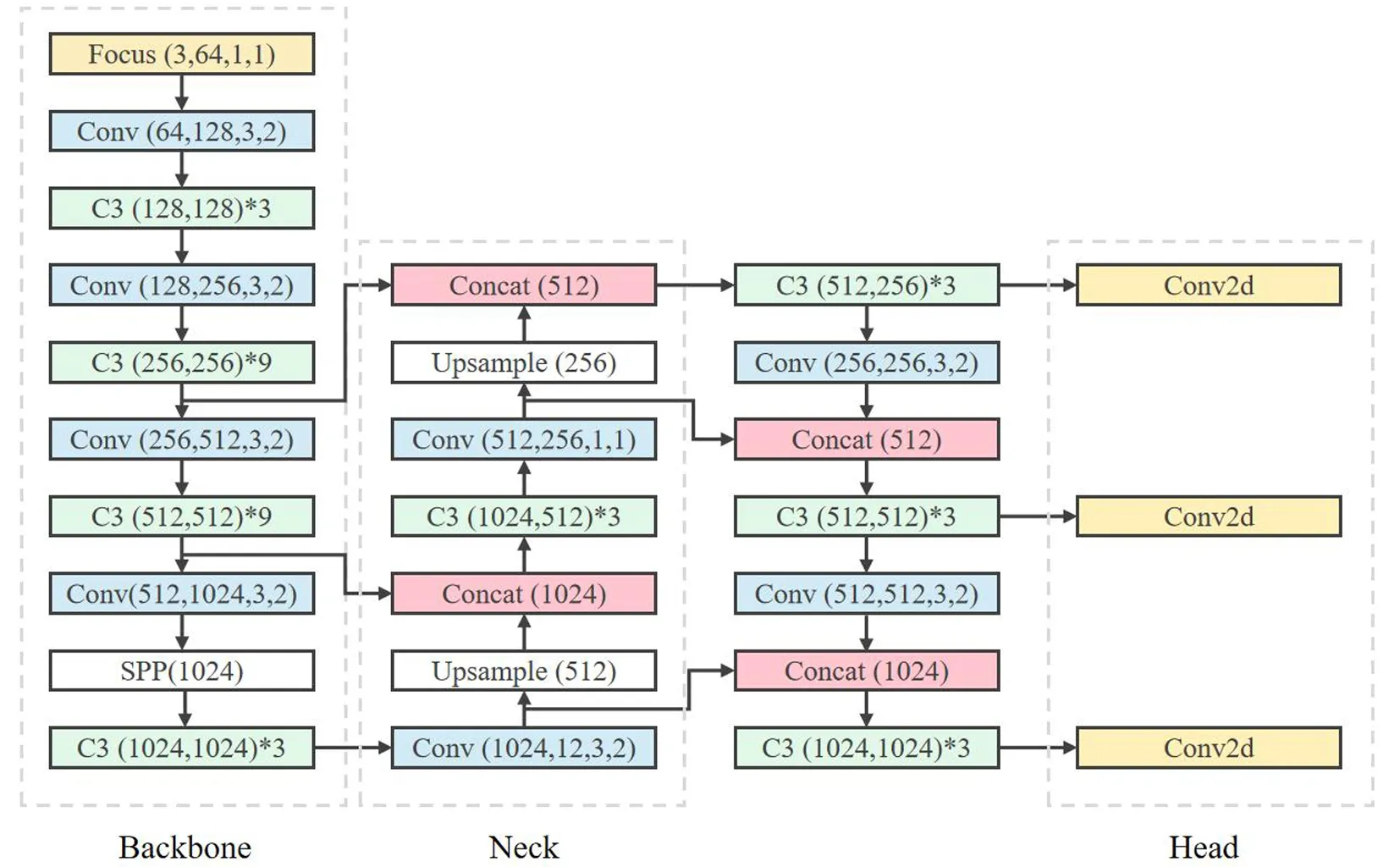
图6 YOLOv5网络架构图Fig.6 YOLOv5 network architecture diagram
3 实验与结果分析
3.1 数据集简介
本文实验数据使用了kaggle社区的Plastic-Paper-Garbage Bag Synthetic Images数据集(图7).该数据集包含塑料袋、纸袋和垃圾袋的合成图像.Bag Classes包含每个图像类的100张图像,而ImageClassesCombined包含所有组合的类的注释图像,注释采用COCO格式.实验随机抽取数据样本总数的90%训练集,10%测试集.针对样本不足引发的模型过拟合问题,对部分数据集进行随机裁剪、上下翻转、随机缩放、高斯噪声等数据增强处理,提升模型对新领域的适应能力.

图7 Plastic-Paper-Garbage Bag Synthetic Images数据集Fig.7 Plastic-Paper-Garbage Bag Synthetic Images
3.2 模型训练性能评价
本文采用了准确率Accuracy、AP(average precision)、mAP(mean average precision)等指标来评估分类模型的性能.准确率反映了模型的分类准确性和预测能力,AP衡量了分类器在面对不平衡数据时的分类能力,mAP则是各类AP的平均.衡量指标公式如下:
(10)
其中,TP代表真正例,FP代表假正例,FN代表真反例,TN代表假反例,Precision衡量的是模型在预测为正类别的样本中有多少是真正的正类别样本,Recall衡量的是模型能够正确预测出所有正类别样本的能力,对于AP的计算,根据标准可以将其定义为经过插值(r1,r2,…,ri是升序排列的Precision插值段第一个插值处对应的Recall值)的PR曲线与横轴包络的面积,这种方式称为AUC(area under curve),计算出所有种类的AP后,可以根据总类别数K和总AP之和计算mAP.
3.2.1 Loss函数变化
在本次实验中,使用了垃圾的训练集对YOLOv5网络模型进行训练,并利用验证集对该检测模型进行了评估.训练的epoch为300次,可以看出在约270个epoch之后,验证集的损失已经下降到了一定的程度没有大幅度减少,则说明模型逐渐收敛,震荡越来越微弱,逐步保持稳定,Loss收敛于0.000 65,如图8所示.因此,本文选择使用训练300个epoch后的网络模型来进行后续实验.
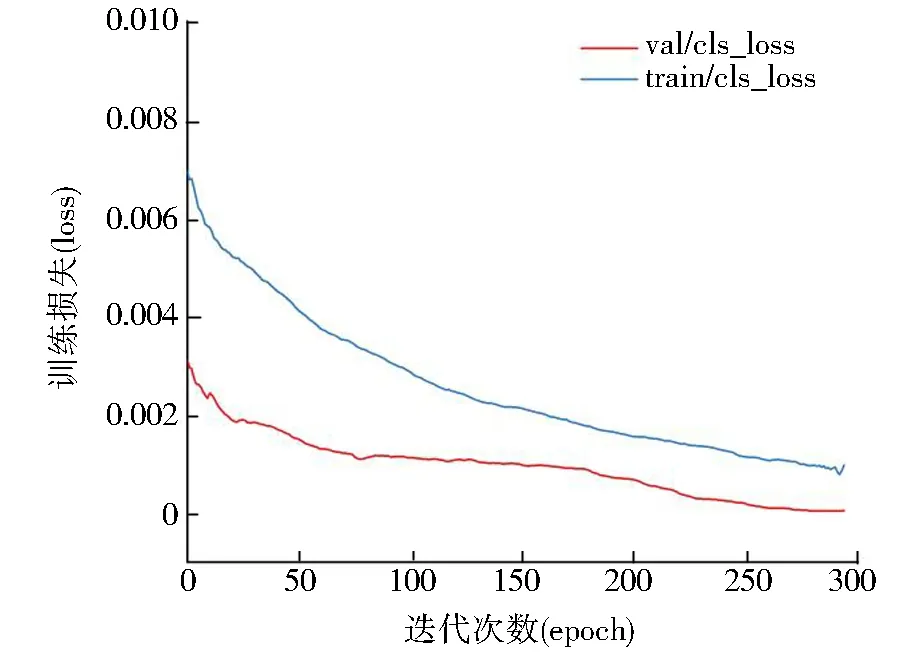
图8 模型训练损失函数变化曲线Fig.8 Model training loss function change curve
3.2.2 模型Precision、Recall及mAP
检测结果如图9所示,其中,box_loss表示预测框损失,obj_loss表示目标检测损失,cls_loss表示分类损失,模型损失值Loss由三者共同构成.
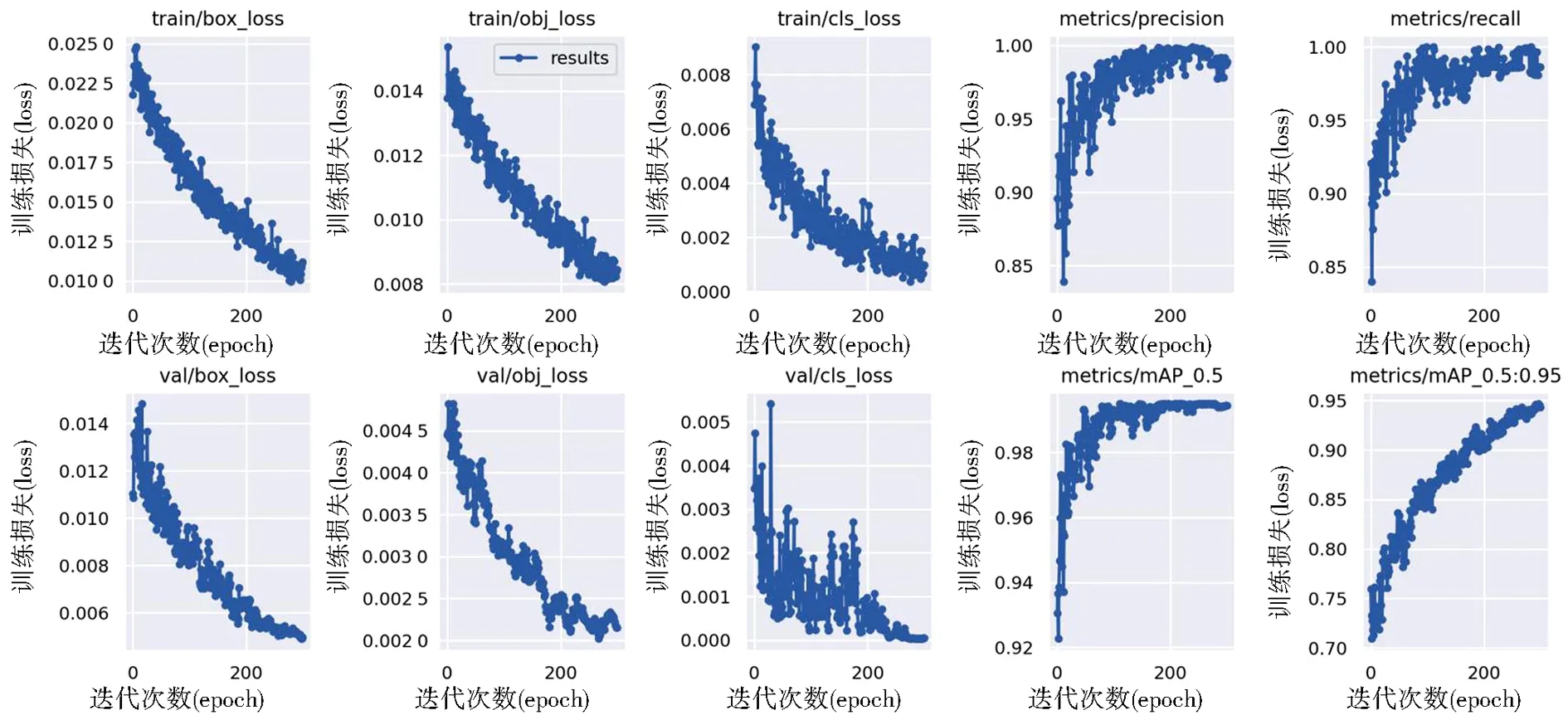
图9 损失率与准确性Fig.9 Loss rate and accuracy
F1曲线表示F1分数与置信度阈值(X轴)之间的关系.F1分数是分类的一个衡量标准,是精确率和召回率的调和平均数,介于0到1之间.如图10所示,F1曲线下的面积(通常称为平均精确率均衡点)大,说明模型在召回率和精确度之间的平衡性好.并且顶部接近1,说明模型训练数据集上表现优异.根据F1曲线可以调整合适的阈值,选择靠近左上角的平衡点为阈值,使得精确度和召回率相对均衡,从而达到最优的模型性能.
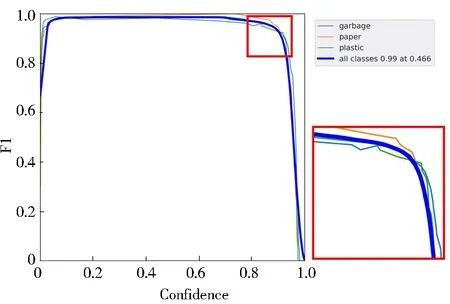
图10 F1曲线Fig.10 F1 Curves
PR曲线体现精确率和召回率的关系,对于所有类别的预测结果进行评估.如图11所示,0.994代表平均精确率均值mAP,在计算mAP时选择阈值为0.5的置信度阈值.这意味着该模型在目标检测任务中具有较高的综合性能,能够在多个类别上准确地检测和识别目标.
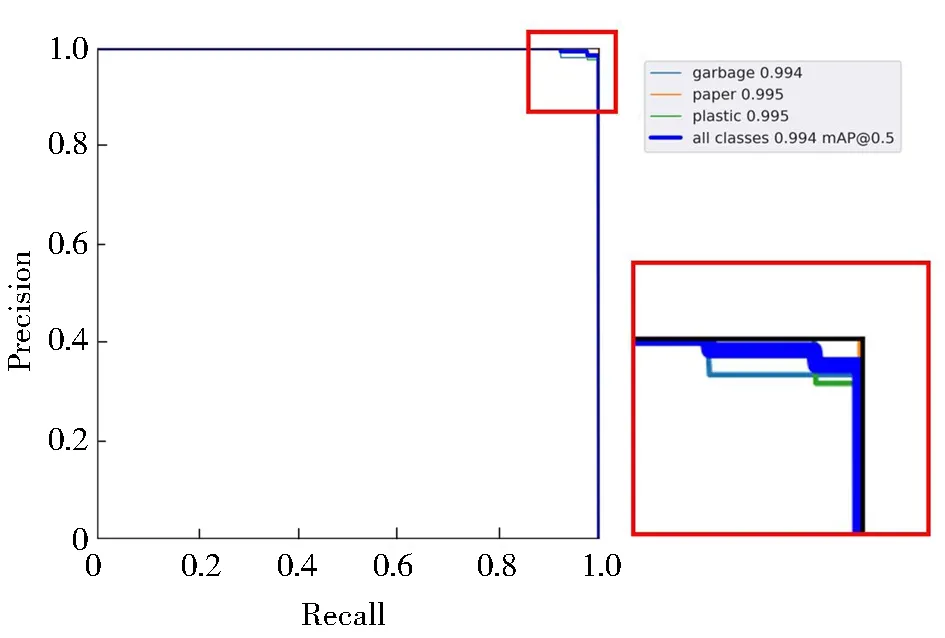
图11 PR曲线Fig.11 Precision-Recall Curves
3.3 实验结果
3.3.1 终端动目标检测结果
动目标检测模块在终端执行.对于三帧差法而言,阈值T的选取尤为重要,阈值过小就无法抑制差分图像中的噪声,阈值过大又会产生目标漏检现象,本文在实验多次后选取合适阈值T=10.将矫正后的实际高空抛物视频送入目标检测模块,如图12所示,三帧差算法可以很好地检测到抛物目标,将其精准标记以便于锁定抛物对象及抛物者.

图12 帧差法目标检测结果Fig.12 Frame difference method target detection results
3.3.2 边缘端目标识别结果
实验结果如图13所示,当垃圾从高空落下时,模型会实时定位垃圾的位置并将其框选出来.由于YOLO原本模型中获取的坐标格式为目标框的中心点、相对高度和相对宽度,是基于原图尺寸的百分比大小,这不利于管理平台的下一步操作,本文优化了模型检测模块输出部分,将输出坐标改为基于原图的真实坐标系,输出框的左上角坐标以及右下角坐标.使得在管理平台中不需要再对图片进行坐标提取操作,优化了步骤,减少了运行时间.

图13 目标检测结果Fig.13 Target detection result
4 结束语
本文主要针对高空抛物这一备受热议的社会性问题,设计了一个高空抛物检测系统.该系统使用鱼眼相机对图像视频进行采集,并在终端进行矫正处理以及动目标检测,随后在边缘端部署基于YOLOv5的目标识别任务,进一步精准检测高空抛物.实验结果显示,mAP数值达到0.994,表明本课题所提出的检测系统能够高效实时地捕捉高空抛物者以及抛物目标,解决了对于高空抛物行为难以取证的难题,做到了有迹可循、有据可依,有利于协助进一步完善取证、追责以及监管制度,也能有效预防和震慑高空抛物这一不文明行为.
猜你喜欢
高中数理化(2023年7期)2023-08-31 16:35:00
法律方法(2022年2期)2022-10-20 06:45:28
环球时报(2022-02-28)2022-02-28 16:16:01
河北理科教学研究(2021年3期)2022-01-18 05:34:22
数学物理学报(2019年5期)2019-11-29 07:46:42
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
小天使·一年级语数英综合(2018年11期)2018-11-23 09:47:26
小学阅读指南·低年级版(2018年5期)2018-11-02 10:19:50
中国交通信息化(2018年6期)2018-08-29 01:19:34
新高考·高二数学(2015年11期)2015-12-23 18:15:33
