
基于BP 神经网络的英语语音识别混合算法
2023-11-10 07:38:02王飞燕徐衡
成长 2023年11期
王飞燕 徐衡
南通理工学院 (江苏省南通市 226002)
1 引言
语言是人类不同于其它动物所独有的技能,语音作为语言的媒介,在信息传播与情感抒发过程中扮演着独一无二的角色。正是由于这个原因,一直以来,人类都希望人与机器之间能够像人与人之间进行自然的语音交流,即让机器能够“听懂”人的语言并做出正确的反应。语音识别技术需要在最短的时间内使机器正确识别语音指令的内容并做出正确的响应,包括了信号处理,模式识别、人工智能算法等[1-2]。近几年来,随着数字时代的发展,语音识别技术得到了长足的发展,逐渐由实验室走向应用。伴随着移动互联网、大数据、云计算的飞速进步,语音识别技术呈现出了前所未有的使用前景和市场价值,很多互联网公司的产品都以语音识别技术来吸引用户。而语音识别技术作为人机交互的关键技术手段,在世界范围内也掀起了研究热潮[3-4]。所以,探索语音识别技术并研发出相关的产品,具有普遍的社会意义和经济意义。
对语音识别技术的研究,首先是从国外开始的,贝尔实验室首先开发出了Andry 系统,该系统可以进行语音识别,并且可以简单地识别10 个英语数字[5]。21 世纪的二十年代,语音识别的研究主要集中于两个方向:一是继续提升基于DNN-HMM 的语音识别的性能;二是开发端到端的语音识别系统,改变传统的将声学模型和语言模型区分开的识别方式。随着语音识别研究的开展,其应用场景也从单一的特定任务场合扩展到与人们生活息息相关的各个方面。微软公司发布了Cortana 个人智能助手,可以实现办公室娱乐聊天、与用户语音交互等功能。我国对语音识别研究起步较晚,于五十年代开始,但最近几十年代有了迅猛的发展,从实验室逐步走向实用。其中比较有代表性的是科大讯飞研制语音识别系统,其识别精度达到了98% 以上,已成为国内外领先的佼佼者。神经网络中的诸多方法在语音识别中应用越来越普遍,随着人们对这些现代智能算法的运用更加成熟,语音识别技术也必将迎来一个飞跃式的发展。
语音识别不仅在各个领域发挥着重要的作用,同时也逐步融入到人们的生活中来。所以,如何提高识别准确率成为了关键性因素,它体现的是一个公司乃至一个国家的科技前沿的发展水平。
2 BP 神经网络在英语语音识别中的应用
2.1 BP 神经网络原理
如今,人工智能的研究日益受到人们重视,同时将人工智能技术与其他学科领域结合应用到工程实践中也越来越流行于多层前馈网络的训练经常采用误差反向传播算法,人们也常把多层前馈网络称为BP 网络。BP(Back-Propagation) 神经网络是发展最为成熟也是至今应用最广泛的神经网络之一。其学习原理是计算实际输出结果与期望结果之差,然后从后向前反馈,通过不停的迭代修正内部参数来实现进化学习的效果。其在复杂的非线性系统中具有较高的建模能力,所以十分适合应用于预测和模式识别领域。由于BP 神经网络具有稳定优越的性能,其被广泛应用于模式识别分类、系统仿真、故障预测诊断、图像处理等领域。如图1 所示为BP 神经网络算法的流程。
BP(back propagation)神经网络是根据误差反向传播的计算理论生成的多层前馈神经网络。它由输入层、输出层和一个或多个隐藏层组成。每一层都由多个可以并行计算的神经元素组成,同一层的神经元之间没有连接,层与层之间的神经元节点都是相互连接的。
BP 神经网络的学习分为两个阶段。第一级是通过输入信号的前向传播;第二阶段是误差反向传播。在第一阶段,训练样本信息被输入到输入层,然后被隐藏层处理,然后传输到输出层。如果实际输出和预期输出之间存在误差,它将进入第二阶段,即误差反向传播阶段。在这个过程中,输出信号的误差最终按照原始路径从隐藏层传输到输入层,然后将每一层的误差信号分别分配给每一层的所有神经元单元。每个神经元根据信号改变每个网络的连接权值,最终误差信号逐渐减小。这两个阶段反复出现。事实上,网络学习阶段是一个不断调整和修改连接权重的过程。该过程持续进行,直到误差值降低到允许的范围或达到预设的训练时间。
2.2 BP 神经网络的应用
BP 神经网络语音识别系统的工作流程有以下两个步骤:
(1)对语音信号进行特征参数提取;
(2)通过神经网络的计算和学习,输出准确的识别结果。
设计神经网络和语音识别系统时,应坚持以下原则:
选择正确的语音表现形式:为了使神经网络能够接受和识别,要从语音中进行特征参数的提炼。
设定网络模型:包括激活函数、选择正确的连接方式,还要针对各类语音的特点、以及所采用的典型模型,扩充和改造原来的神经元,还可以将多种网络模型结合起来。
设定网络参数选择:设定好网络的层数、输入、输出、隐层神经元的数目。
选择学习和训练算法:设定严格的网络规则,并及时改进,学习时还要从各个算法出发,来进行初始化。因为如下两个原因,本文在进行时间规整处理时,以前端网络为主:
因为人们在说话时,速度快慢发生变化,有的音节速度较快,难以持续太长时间,有的音节则过慢,拖得时间很长。这种现象的存在,造成难以通过权重处理语音各帧的特征矢量。而要解决这个问题,可以通过合并一些特征矢量来解决,经过这样的处理后,最终导致从语音中提取到的特征参数和语音中的一样,从而改善了说话速度快慢不定所造成的影响,也避免了因为说话语速问题引起的语音识别的误差。
为了提高神经网络分类器识别的准确率,对于每一个单词在特征矢量提取上都设定相关的规则,在对语音进行段落划分后,和词汇表中的各单词相比,其数量比这些词的音素数更高。在实际的孤立识别实践中,通常将语音分为4-8 段,这样的话,只要用2-3 个特征矢量,就能对任何一个音素进行描述。
2.3 BP 神经网络算法的改进
通常来说,BP 算法有两种改进方案,一是提高自适应学习速率,另一种则是提高动量因子的数量,但这两种方法都有各自明显的不足之处。前者对学习速率的初始值要求高且非常敏感,通常为了加快收敛速率会设置较大的初始值,但是修改不当则会使得整个网络不收敛,而过小的初始值又会使得收敛速率降低,后者的缺点则是无法避免陷入局部极小值点。本文基于传统的改进方法做如下改进:
(1)动量因子的优化方法。BP 算法的标准权值调整如式(1)所示,它兼容性不强,不适用于以前的梯度,所以有时会出现振荡现象。式(2)便是动量因子得到增加后,所进行的调整过程。而权值的调整不但要将本次误差计算在内,还要加入上一次的部分计算量。这样在利用BP 网络来局部调整误差曲面时,敏感度可以进行调节。其中,α 为动量因子,η 为学习速率。
但是各种方法都有一个弊端,那就是若是α 固定不变了,BP 网络的整个学习过程也就定型了,而且在设置α 的时方法并没有统一,主要靠惯例,一般会先定为0.9。
(2)自适应速率方法。在一般的BP 算法中,η 通常被设为固定值,但这样的话,不一定是网络最佳学习速率。观察整个误差平面发现:在平坦区间内,η 较小时,迭代次数会增多,若是区间内曲面急剧变化,η 如果设得太大,权值也会跟着出现较大的调整,从而引发振荡现象。因此,本文提出了如式(3)所示的自动调节的方法。
本文后续就将使用结合着两种方法的改进方法。既能通过动量因子来有效的加快网络的收敛速度也能通过η 的自动调整来降低初始η 对网络的影响,使得最佳的η 能较快得出。
3 语音识别仿真实验
3.1 实验数据来源
本文仿真实验所选用的英文语音数据库叫做 TIMIT,TIMIT 语音库包含总共6300 句话,即来自于美国8 个主要方言区域的630 名说话人分别说10 句话,采样频率为16kHz,总共大约 500M 左右大小。
3.2 数据预处理
对于神经网络,大多数都有时间规律性的问题。由于神经网络分类器的结构是固定的,输入语音信号的长度是可变的,即提取的语音特征参数存在维数不等的问题,因此必须将可变长度的语音特征参数转换为相同长度的特征向量。本文采用分段平均法对TIMIT 数据集的语音特征参数进行预处理,如降维和正则化。
4 仿真实验结果分析
本文使用DTW 和HMM 模型语音识别算法的与本文提出的算法进行性能对比,性能指标为语音识别正确率,其值均为统计平均结果。
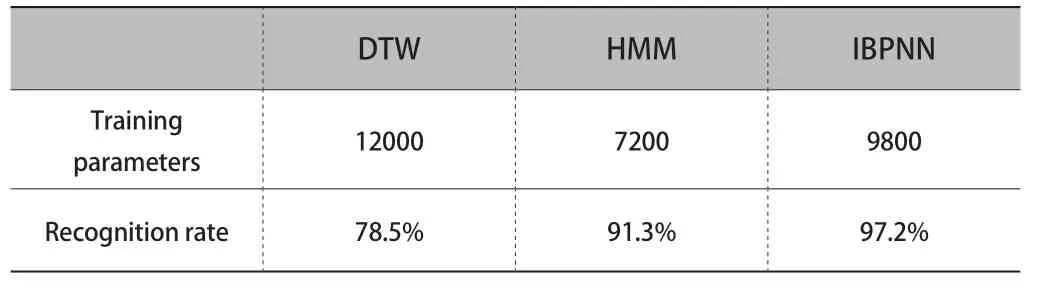
表1 语音识别率比较结果
如表1 所示,DTW 的语音识别正确率低于HMM 和IBPNN,证明本文提出的IBPNN 模型性能更优。其次,分析不同语音识别算法的训练参数规模。对于DTW,其训练参数规模为12000;而对于HMM 和IBPNN,其训练参数规模最大分别为 7200 和 9800,远远小于 DTW 训练参数规模。在训练集中语音样本有限的情况下,如果训练参数规模较大,很容易导致训练模型的过拟合问题。通过减小训练参数的规模,可以有效地避免训练模型的过拟合问题。在训练集中语音样本有限的情况下,本文提出的IBPNN 模型大大减少了训练参数的规模,从而提高了模型的识别性能。
5 结论
在计算机辅助语音学习中,语音识别技术和语音评价技术是核心所在。其中,语音识别技术尤为关键,发挥着至关重要的作用。原因在于,语音识别是语音评价的重要基础和前提条件,只有高准确度的语音识别才能进一步取得良好的语音评价结果。因此,本文将BP 神经网络技术应用于英语语音识别,建立基于改进BP 神经网络的语音识别模型。通过对比实验证明,本文提出的语音识别模型性能较优,但仍有很大的完善空间。不同群体(如小学生、中学生、大学生、商务人士等)对学习英语口语的要求不尽相同,其英语发音质量评价标准也不同。因此,后续可从评价指标及模型的效度和信度分析验证入手,研究面向不同对象的多参量评价指标及其评价模型。
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
电子制作(2019年19期)2019-11-23 08:42:00
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
制造技术与机床(2017年11期)2017-12-18 06:46:39
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
