
基于DenseNet的人脸图像情绪识别研究
2023-11-07 09:15雷建云马威夏梦郑禄田望
中南民族大学学报(自然科学版) 2023年6期
雷建云,马威,夏梦,郑禄,田望
(中南民族大学 计算机科学学院 &湖北省制造企业智能管理工程技术研究中心,武汉 430074)
近几年来,基于卷积神经网络和循环神经网路的深度神经网络模型在计算机视觉和自然语言处理等领域应用广泛.自第一个大规模的深度神经网络AlexNet[1]诞生以后,各种骨干架构如VGGNet[2]、GoogleNet[3]、MobileNet[4]、ResNet[5]和DenseNet[6]等相继被提出,网络的性能不断提升,网络规模越来越大.情绪识别的难点之一,同一个人脸有不同的表情,对应不同的情绪分类,不同人脸有相同的表情,对应相同的情绪分类,因此,人脸情绪识别的分类任务有类间差异小,类内差异大的挑战.
1 研究现状
1.1 传统情绪识别
传统人脸情绪识别方法依赖手工设计特征或者浅层学习,如局部二值模式(local binary pattern,LBP)[7]、三正交平面的局部二值模式(local binary pattern from three orthogonal planes,LBP-TOP)[8]、非负矩阵分解(nonnegative matrix factorization,NMF)[9]和稀疏学习[10].2013 年起,表情识别比赛如FER2013(the Facial Expression Recognition 2013)[11]和EmotiW[12]从具有挑战性的真实世界场景中收集了相对充足的训练样本,促进了人脸表情识别从实验室受控环境到自然环境下的转换(表1).

表1 常见人脸表情数据集Tab.1 Common facial expression dataset
1.2 基于深度学习的情绪识别
由于静态数据处理的便利性及其可得性,目前大量研究是基于不考虑时间信息的静态图像进行.直接在相对较小的人脸表情数据库上进行深度网络的训练势必会导致过拟合问题.为了缓解这一问题,许多相关研究采用额外的辅助数据来从头预训练并自建网络,或者直接基于有效的预训练网络,例如AlexNet、VGG、ResNet、Mobelinet 和GoogLeNet 进 行微调.
大型人脸识别数据库CASIA WebFace、CFW 和FaceScrub dataset,以及相对较大的人脸表情数据库如FER2013 和TFD 是较为合适的辅助训练数据.Kaya 等人[13](2017)指出在人脸数据上进行预训练的VGG-Face 模型比在预训练的ImageNet 模型更加适合于人脸表情识别任务.Knyazev 等[14](2017)也指出在大型的人脸数据库上进行预训练,然后进一步在额外的表情数据库上进行微调,能够有效地提高表情识别率.
1.3 稠密网络架构DenseNet
卷积神经网络是深度学习领域中举足轻重的网络框架,尤其在计算机视觉领域更是一枝独秀.CNN从ZFNet到VGG、GoogLeNet再到Resnet和最近的DenseNet,网络越来越深,架构越来越复杂,解决梯度传播时梯度消失的方法也越来越巧妙.稠密网络架构DenseNet 高速公路网络是第一批提供有效训练超过100 层的端到端网络的架构之一.使用旁通路径和浇注单元,公路网络与数百层可以毫无困难地优化.旁路路径被认为是简化这些深度网络训练的关键因素.ResNet 进一步支持这一点,其中使用纯身份映射作为旁路路径.ResNet 在许多具有挑战性的图像识别、定位和检测任务上取得了令人印象深刻的、破纪录的性能,如ImageNet和COCO 目标检测.最近,随机深度被提出作为一种成功训练1202层ResNet的方法.随机深度通过在训练过程中随机丢层来改进深度残差网络的训练.这表明并非所有的层都是需要的,并强调了在深层(残差)网络中存在大量的冗余[6].
DenseNet 是一种网络架构,目的是训练更深的神经网络.由于单独的DenseNet 应用到人脸情绪识别时没有结合提取情绪特征,导致识别精度不高;DenseNet 网络通过通道上的融合,会减轻深度特征的权重,更多提取到的是浅层特征.本文针对人脸情绪识别的特点,在DenseNet 中结合中心损失函数,提高情绪识别精度;使用Adam 随机梯度优化器加快训练模型收敛;结合多尺度空洞卷积模块,分别用5、8 和12 的膨胀提权不同尺度图像特征;使用DenseNet-BC 的增长率k=12,24,32 分别进行情绪特征提取进行研究.常见DenseNet 网络结构如表2所示.

表2 DenseNet网络架构 k=32,卷积=BN-ReLu-ConvTab.2 DenseNet Network structure k=32 conv=BN-ReLu-Conv
2 基于DenseNet 模型的面部表情识别
2.1 整体网络结构
针对原始的稠密网络不能有效提取情绪特征,多尺度特征提取不充分,且稠密网络内存占用高的问题.本文提出多尺度卷积提取多尺度特征,减少稠密网络内存占用,同时结合改进的稠密网络模型,使用中心损失函数,加强模型对表情分类损失的学习.网络由两部分组成,第一部分为多尺度空洞卷积模块,第二部分为结合Adam 优化器和中心损失函数的稠密网络DenseNet169.网络结构如图1.

图1 网络结构图Fig.1 Network structure diagram
2.2 多尺度空洞卷积
对于人脸情绪识别,不同的人脸都由五官组成,相同的人脸受不同的外界条件影响,能表达不同的情绪,面部肌肉做不同程度的收缩与舒张,因此人脸情绪识别需要模型重视深层的图像特征,针对类内差异大类间相似度高的问题,在稠密卷积网络模型中如何提高不同尺度特征的表达能力也是解决该问题的有效方法,V-J 人脸检测算法采用多尺度融合的方式提高模型的精度,Inception 网络则是通过不同大小的卷积核来控制感受野,MTCNN[15]人脸检测算法采用了多尺度模型集成以提高分类任务模型的性能.除了不同大小的卷积核控制感受野外,在图像分割网络Deeplab V3[16]和目标检测网络Trident Networks[17]中使用空洞卷积来控制感受野.还有方法是通过直接使用不同大小的池化操作来控制感受野,这个方法被PSPNet[18]网络所采用.本文提出结合多尺度空洞卷积的稠密网络形成更紧凑和位置不变的特征向量,提高不同尺度卷积特征表达能力,从而有效解决类内差异大和类间相似度小导致人脸情绪识别分类性能问题.
空洞卷积也叫扩张卷积或者膨胀卷积,在卷积核中插入空洞,起到扩大感受野从而进行多尺度卷积,多尺度卷积在情绪特征识别任务中对于识别准确率相当重要,广泛应用在语义分割等任务中.在深度网络中为了增加感受野且降低计算量,采用降采样增加感受野的方法,但空间分辨率会降低,为了能不丢失分辨率,且仍能扩大感受野,可以使用空洞卷积,在分割任务中十分有用,一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标,捕捉多尺度上下文信息.空洞卷积有一个参数可以设置,空洞率,具体含义就是在卷积核中填充一定数量的0,当设置不同的空洞率,感受野就会不一样,即获得了多尺度信息.
该模块包含四个分支,每个分支都由3 个batchnorm、relu 和conv 组成,中间的卷积为3×3 的空洞卷积,三个空洞卷积的膨胀分别为5、8和12.第4 个分支在原始图像的基础上,为了和前三个分支的特征图像尺寸一致对边缘做了一定的裁剪且使用3×3 卷积计算使图像变成40×40×18,最后在四个分支上进行通道上的融合,形成40×40×54的特征图,作为稠密网络的输入.通道融合如公式(1).
x1、x2 和x3 分别为不同膨胀的空洞卷积分支,x4是原始图像分支,cat表示对这四个分支在通道上面进行融合.
2.3 DenseNet-BC网络模型
DenseNet 网络由稠密块、过渡层交替连接组成.在稠密层中,任何层直接连接到所有后续层,加强特征传递,因此后面所有层都会收到前面所有层的特征图,即X0、X1、X2、…、Xμ-1做为输入,如公式(2):
2.3.1 Adam优化器
Adam 是一种随机梯度优化方法,占用很少的内存,只需要一阶梯度.该方法根据梯度的第一和第二矩估计值计算不同参数的学习率.该优化器结合了比较流行的两种方法AdaGrad和RMSProp方法分别在稀疏梯度和非平稳设置梯度的优点,该优化器有如下优点:参数更新幅度对于重新缩放梯度是不变的,其步长由步长超参数限制,不需要固定的目标.
2.3.2 中心损失函数
中心损失函数针对softmax 损失函数类内间距太大的问题,对每一个类都维护一个类中心,而后在特征层如果该样本离类中心太远就要惩罚,也就是所谓的中心损失,每一个特征需要通过一个好的网络达到特征层获得类中心,计算后所有样本的特征平均值为类中心,而好的网络需要在类中心加入的情况下才能得到.没法直接获得类中心,所以将其放到网络里自己生成,在每一个batch里更新类中心,即随机初始化类中心,每一个batch 里计算当前数据与center 的距离,而后将这个梯度形式的距离加到center上.类似于参数修正.同样的类似于梯度下降法,增加一个度量,使得类中心不会抖动.
3 实验与结果分析
对提出的网络模型进行实验验证,使用PyTorch深度学习框架,在DenseNet 网络前面加入多尺度空洞卷积,同时在通道维度上结合原始输入的图像,在稠密网络中使用softmax+center 损失函数减少同类之间的距离,增加不同类的距离.使用Adam 优化器进行梯度反向传播.具体分为实验环境和实验细节、数据集预处理、多尺度特征提取实验和对比实验.
3.1 实验环境和实现细节3.1.1 实验环境
本实验在Ubuntu 18.04.2 LTS操作系统环境下,基于PyTorch深度学习框架构建.实验环境见表3.
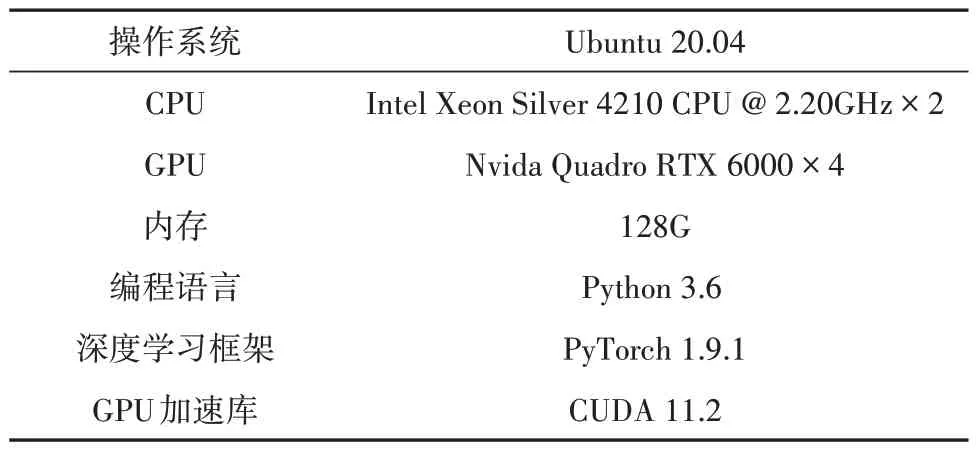
表3 实验环境Tab.3 Experimental environment
3.1.2 实验过程
输入48×48×3的图像经过多尺度空洞卷积处理之后得到46×46×54 的人脸图像,批量大小为256,结合权值衰减参数为0.00001,学习率参数为1e-1 的Adam 算法,使用DenseNet-BC169k=24 的稠密网络训练300 轮.分类全连接层包含8 个神经元输出实现8分类,8个输出中最大输出的序号对应情绪状态.具体对应关系如下:生气-0,轻蔑-1,厌恶-2,害怕-3,高兴-4,中性-5,伤心-6,惊讶-7.
3.2 数据集预处理
本文所采用到的实验数据集为网上公开数据集FER2013+,数据集由48×48×1 的3 万张图片组成.数据集分为3 部分,分别是训练集、验证集和测试集,其中公开测试集用于训练过程中的验证,私有测试集用于训练最后的测试.使用OpenCV 对原始数据集进行尺寸和通道的调准,将尺寸通过双线性插值法调整到60×60的三通道图片.
卷积神经网络在分类问题中,对于数据集的不同类的样本量要求均衡,本文借助数据增强,用水平翻转、垂直翻转、旋转45°、旋转90°、高斯模糊添加噪音、仿射变换的方法,训练集中各类样本数量变为24000 张,测试集各类样本数量变为4000 张.预处理前后数据集见表4~5和图2.
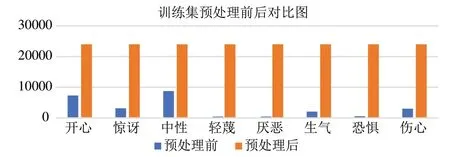
图2 训练集预处理前后对比图Fig.2 Comparison of training set before and after preprocessing
3.3 多尺度特征提取实验
在实验过程中,分别使用不同空洞率的三分支结构网络模型进行训练,分别使用了5、8 和12 的膨胀进行多尺度特征的提取的资源消耗和识别性能最佳,太大的空洞卷积无法提取细粒度信息,太小的空洞卷积无法提取大尺度信息.本实验为了保证通道融合上面尺寸的统一,使用公式(3)和公式(4)对图像的填充和裁剪进行计算,Win和Hin表示输入图像尺寸,padding 表示填充数组,dilation 表示膨胀数组kernel_size,描述卷积核大小数组,stride描述卷积步长数组.为了证明多尺度空洞卷积模块的有效性,将在改进的DenseNet 模块前,分别添加多尺度模块和不添加多尺度模块进行训练学习情绪特征,实验结果对比如表6 所示,其中训练时间是指batch size为128的单批训练耗时.
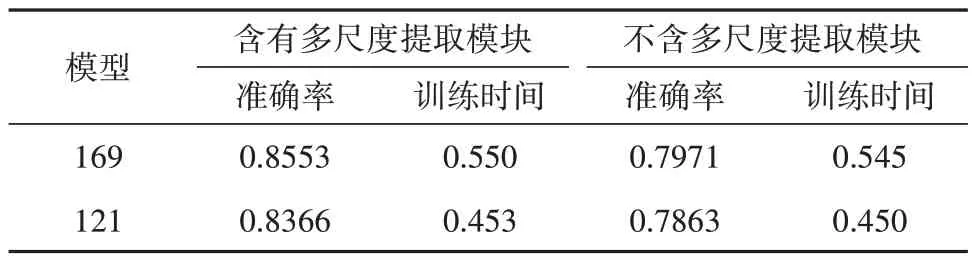
表6 多尺度提取模块对比Tab.6 Comparison of multi-scale extraction modules
3.4 算法复杂度
为了说明本文模型的优越性,分别将DenseNet-BC 模型和ResNet 模型进行算法复杂度对比实验,实验数据如表7.本文提出改进的稠密网络模型的模型参数量明显少于其他的旁路网络.表7 是在FER2013+的8 分类网络条件下进行实验,时间是指batch size为128的单批训练耗时.
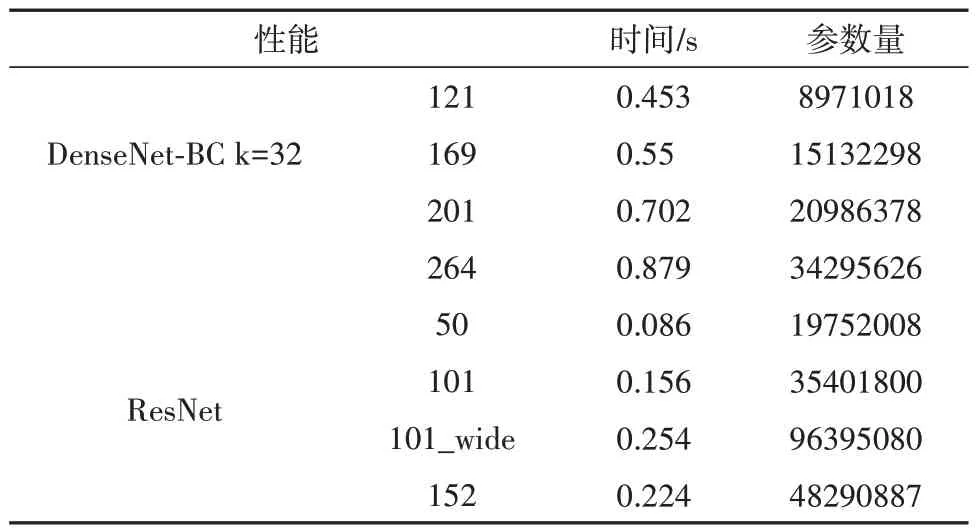
表7 模型参数对比Tab.7 Model parameter comparison
3.5 对比实验
3.5.1 超参数调优实验
在预处理后的FER2013+数据集上研究不同超参数对模型收敛速度和情绪分类正确率的影响.分别从DenseNet-BC 网络增长率k,DenseNet-BC 层数c,权重衰减d三个方面对模型进行训练.实验结果如表8 所示,结果表明k=24,c=169,d=1e-5时网络性能最好,收敛最快.更深的网络会在数据集上产生过拟合,k值太大会通过通道融合的方式加强浅层特征对深层特征的干扰,导致模型提取深层情绪特征比例较少,不利于人脸情绪识别.

表8 超参数实验对比Tab.8 Comparison of superparametric experiments
图3 为不同模块的识别性能对比.中心损失函数和softmax 损失相结合,学习类间的差异和类内的共同特征,有利于网络模型对情绪特征的学习,结合在深度学习中表现优秀的Adam 优化器和多尺度空洞卷积,最终模型的收敛速度快,收敛效果好.这说明,多尺度特征和中心损失函数对情绪识别的精度有帮助,Adam优化器能帮助模型加速收敛.

图3 识别效果Fig.3 Recognition effect
3.5.2 表情识别性能
本文方法在常用的面部情绪数据集FER2013+上进行十折交叉验证,实验结果如表9 和图4、5 所示,针对损失函数、Adam 优化器和多尺度空洞卷积对实验结果的影响见图4 所示.根据实验数据分析发现,都引入旁路连接的DenseNet 和ResNet,明显能加快模型的收敛速度和取得更好的收敛效果,旁路连接有利于提取情绪特征和情绪特征复用;注重宽度的GoogLeNet 收敛速度不如有旁路连接的网络模型,但也取得了不错的收敛效果;不过VGG 实验效果较差,说明浅层网络很难提取到有用的情绪特征.

图4 不同模快性能对比Fig.4 Performance comparison of different models
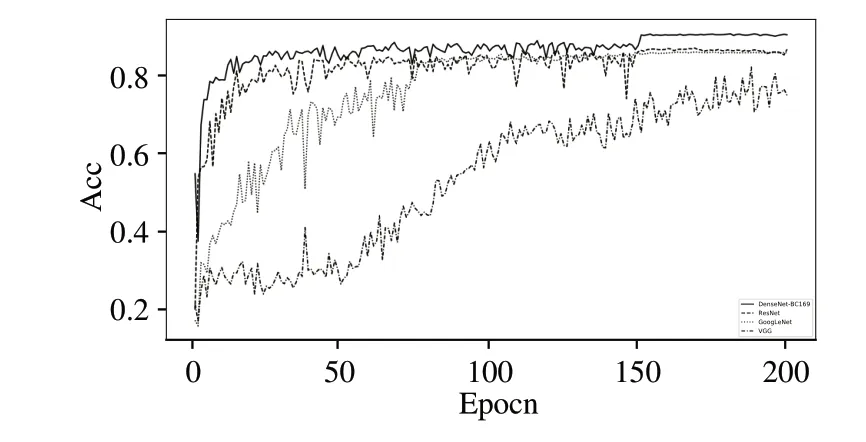
图5 不同网络模型性能对比Fig.5 Performance comparison of different network models

表9 不同网络模型性能对比Tab.9 Performance comparison of different network models
本文在DenseNet 神经网络结构进行表情识别性能的验证,结果表明,使用更深层的DenseNet 网络容易在FER2013 数据集上产生过拟合,大模型需要训练的参数过多,数据集数量过少导致的原因,本文采用基于静态图像的单幅图像识别,相比于图像的视频序列方法,单幅图像方法的计算量更小,关于模型的正确率没有明显差别.静态图像方法中DeRL 方法[19]和PPDN 方法[20]使用了中性表情图像作为其他情绪的参考,因此取得了比其他方法更好的性能.刘露露[21]将4 个尺度特征融合放到模型的后端,DenseNet 模型中将多尺度特征放到模型的前端,显著加强多尺度特征在模型中的作用,提高表情特征的重要性,减少无用特征的干扰,实现多尺度情绪特征提取.本文的方法使用稠密网络DenseNet-BC169,模型的参数量为1855130,相比其他的轻量级模型,参数量较少,但模型准确率并没有下降,在预处理后的FER2013+上面训练300轮在公共测试集上达到93.99%的正确率.本文方法相比于其他静态图像方法有更小的计算量和更好的情绪识别性能.
4 结语
针对人脸情绪识别问题提出基于DenseNet-BC169 的面部表情识别网络模型,该网络模型由多尺度空洞卷积模块和稠密网络模块两部分组成.通道多尺度空洞卷积模块关注不同尺度特征的重要性,加强表情特征的作用,减少无用特征的干扰,实现对多尺度特征的提取.DenseNet 模块使用旁路加强特征传递,实现对显著表情区域的关注.该网络通过通道融合的方式,以较小的计算开销实现了对特征图的面部表情识别.此外,在DenseNet 中结合Adam 优化器加快网络收敛速度,中心损失函数得到更好收敛效果.实验结果表明,本文方法对预处理后的FER2013+表情数据集的面部情绪识别准确率能达到93.99%.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
动漫星空(2018年9期)2018-10-26
故事作文·高年级(2017年2期)2017-03-01
太空探索(2016年5期)2016-07-12
新闻传播(2015年20期)2015-07-18
发明与创新(2015年33期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
奇闻怪事(2014年5期)2014-05-13
世界科学(2013年11期)2013-03-11
