
基于奇异谱分析和局部敏感哈希的调频辅助服务市场短期容量需求预测方法
2023-11-07 12:26黄佳玺容语霞季天瑶荆朝霞杜哲宇刘玲刘嘉宁
广东电力 2023年9期
黄佳玺,容语霞,季天瑶,荆朝霞,杜哲宇,刘玲,刘嘉宁
(1. 华南理工大学 电力学院,广东 广州 510641;2. 广东粤电科试验检测技术有限公司,广东 广州 510180;3. 广东电网有限责任公司电力调度控制中心,广东 广州 510600)
为提高国家自主贡献力度,深化电力体制改革,构建以新能源为主体的新型电力系统,我国明确提出碳达峰、碳中和目标[1-3];为此必须推动能源结构转型,促进高比例新能源接入电网[4]。随着风电、光伏及主动负荷等不确定性资源的比重不断上升,仅依靠传统电源侧和电网侧调节手段,已无法满足新能源持续大规模并网消纳的需求;因此对辅助服务的供应质量和充裕度提出了更高要求,辅助服务市场建设、辅助服务补偿机制完善势在必行[5]。
目前,我国调频辅助服务大多采用“两个细则”作为运行规则,主要存在调频辅助服务产品类型较为简单、调频辅助服务价格补偿机制不健全、调频辅助服务成本传导方法缺乏公平性等问题[6-7]。在调频辅助服务中,为平衡电力系统的有功偏差并维持系统频率稳定,降低电网风险,自动发电控制(automatic generation control,AGC)系统需要足够的二次调频容量,但过多调频容量将导致运行成本上升[8]。因此,合理确定电力系统调频容量对于维持频率稳定、提升运行效率具有重要意义[9]。
相关学者对国外成熟的辅助服务市场进行了研究。美国PJM电力市场的调频容量在负荷高峰期和低谷期分别取固定值,NYISO与ISO-NE按照月份、星期和小时制订了调频容量对照表,CAISO按照每小时负荷预测值的固定比例确定调频容量需求[10-12];此类调频容量需求计算方法较为简单,但未考虑可再生能源发电出力随机性的影响,使其合理性和适用性受到挑战。在国内,山西电网以全天直调发电需求最大值的5%~15%作为系统调频容量需求[13];华北电网京津唐控制区以周预测最大负荷的10%来确定调频容量需求[14]。无论是华北、山西还是其他省份电网,均根据调度运行经验或运行数据及简单计算公式来确定调频容量需求。为了减轻调频容量不稳定带来的不利影响,传统调频容量需求的计算方法越来越不适用,更加准确和稳定的调频容量需求预测至关重要且迫切需要。文献[15]提出根据达到一定频率控制性能分数的条件概率来确定调频容量,但没有考虑对信号的精确处理。文献[16]提出考虑常规发电中断和负荷预测不确定性的调频需求确定方法,根据风险指数的量化分数来给予系统运营商建议,但该方法弱化了新能源接入后对调频容量需求造成的影响。文献[17]采用滚动平均法对新能源波动分量进行降噪处理,从而确定调频容量的需求,该方法在一定程度上能够平滑极端场景对预测结果的影响,但会使得预测值对数据的实际变动更加不敏感,无法始终很好地反映预测趋势。
近年来,出现了各种用于负荷预测的模型,其中自动回归和移动平均(autoregressive moving average,ARMA)[18]、人工神经网络(artificial neural network,ANN)[19]和支持向量回归(support vector regression,SVR)[20]应用最为广泛,它们的主要优点是能快速计算出预测结果。但由于调频信号具有强波动性和高随机性,一般来说很难从原始时间序列直接预测;因此,有研究采用快速傅里叶变换(fast Fourier transform,FFT)[21]、经验模态分解(empirical mode decomposition,EMD)[22]、小波变换(wavelet transform,WT)[23]等算法来过滤原始时间序列或将其分解成多个子序列。FFT是采用将复杂时域信号分解成正弦波信号相加的方式进行简化分析,但由于无法改变FFT过程中的窗口大小,因此忽略了时频的局部特性[21];WT是在保留信号时域特性的基础上,将信号进行高低频率分离,在实际操作中,由于尺度因子和平移因子都是连续变换的,难以实现连续变换,只能用较小的变化量近似代替,且变化量越小,WT计算量就越大,所产生的误差也越大[22]。EMD能够在不需预先设定基函数的情况下,根据数据信号本身的时间尺度特性将其分解成有限个固有模态分量(intrinsic mode function,IMF)和余项,其中,IMF反映了原始序列在不同时间尺度下的信号特征,余项则反映了原始数据序列的趋势特征;但是,当选取信号的时间尺度存在跳跃性变化,对该信号进行EMD分解后,易造成模态混叠和端点效应的情况,此时产生的分解误差具有传递和累积性,影响预测性能[23]。
为了克服上述算法的缺点,本文提出在保证时频局部特性的基础上避免误差累计的预测模型来确定调频容量需求。该模型基于奇异谱分析(singular spectrum analysis,SSA)[24-25]和局部敏感哈希(locality-sensitive Hashing,LSH)进行短期预测[26-27]。SSA结合了时域以及频域的优点,并且弥补了2种方法的不足,对于处理调频信号这一类变化快且噪声多的数据具有良好的降噪作用,通过将原始数据分解为2个部分(平均趋势分量和波动分量),测算不同周期分量对时间序列的贡献率,重构分解后的周期序列。根据之前研究,局部预测比全局预测表现更好[28],因此,采用LSH对样本段进行分类,并搜索用于预测平均趋势段的相似段,减少训练数据集的大小,避免维数灾现象。为了获得更准确的预测结果,本文提出将相似的平均趋势段和相应的波动分量段合成到SVR机的训练输入中,而不是单独预测2个分量或单独预测平均趋势,据此确定调频容量需求。
1 SSA-LSH组合预测方法
1.1 奇异谱分析
SSA是一种处理非线性时间序列的强大数据处理技术,近年来被广泛关注。SSA从原始时间序列中提取并识别出平均趋势分量和波动分量,对分解出来的分量综合分析,以获得更好的预测结果。SSA包括以下4个步骤:
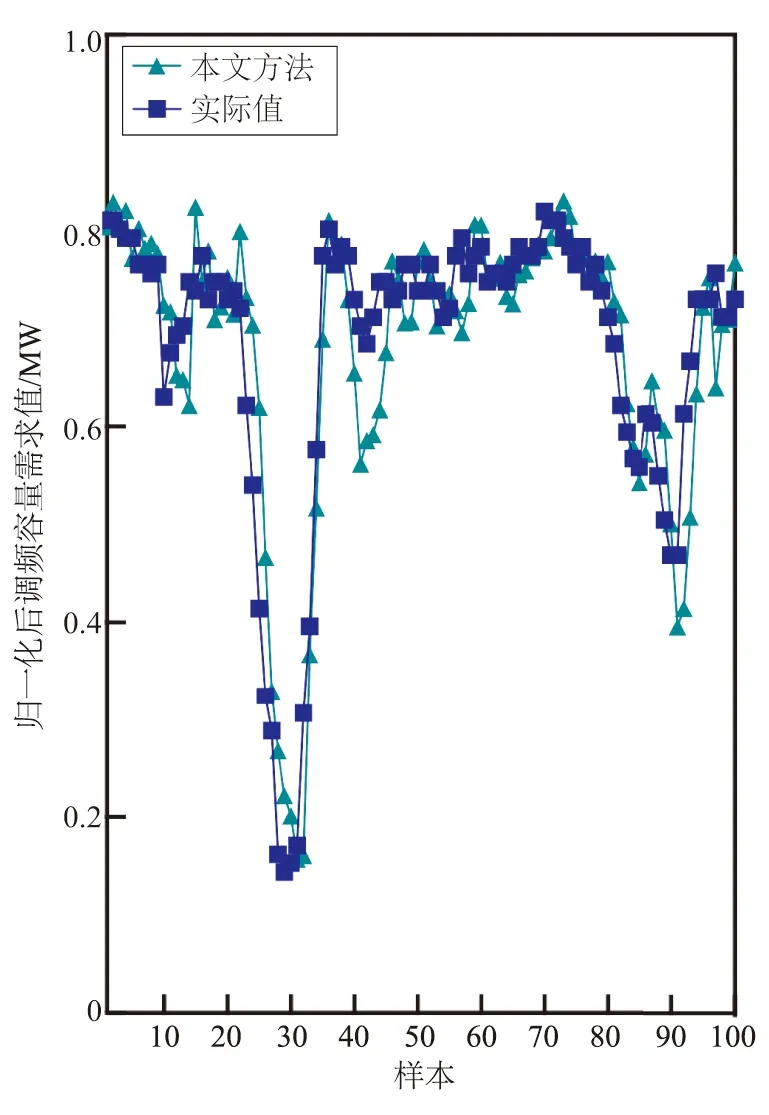
步骤1,嵌入。将包含N个样本点的时间序列y=(y1,y2,…,yN)T,按照指定嵌入维度(即窗口长度)L(1 xi=(xi,xi+1,…,xi+L-1)T,i=1,2,…K. (1) 将延迟向量重构为轨迹矩阵X,如下: (2) 步骤2,奇异值分解。对轨迹矩阵X的协方差矩阵S=XXT进行分解,λ1,λ2,…,λL为S的特征值,λ1≥λ2≥…≥λL≥0,特征值对应的特征向量为U1,U2,…,UL。轨迹矩阵X的奇异谱分解如下: X=X1+X2+…+XL; (3) (4) 步骤3,分组。将下标集合{1,2,…,L}划分成m个独立子集I1,I2,…,Im,此时步骤2中分解出初等矩阵X1,X2,…,XL被分成m组。令I={i1,i2,…,ip},p=1,2,…,m,对应于组I的矩阵定义为 XI=Xi1+Xi2+…+Xip. (5) 这些矩阵是针对I1,I2,…,Im计算的,代入式(3)获得新的轨迹矩阵的表达式: X=XI1+XI2+…+XIm. (6) 在本文中,原始时间序列被分解为2个组成部分。 X=XI1+XI2 (7) y=y(1)+y(2). (8) 式中:y(1)为平均趋势分量;y(2)为波动分量。 考虑到电网频率之间的连续性特征,某一时刻频率与之前短时间内采集的频率数据具有很强的相关性;因此,与其将所有样本段用于训练模型,不如使用与需要进行预测的时间段(称为预测段)具有相同趋势的段更有效。本文采用LSH方法来选择相似片段,分2步进行:建立索引和相似性搜索。 a)建立索引。将平均趋势分量y(1)重构到嵌入维数为s、时间常数为τ的高维相空间,可以得到N-(s-1)τ段,每个段的维数用d表示,其中1≤d≤N,每个段表示如下: (9) 其中i=1,2,…,N-(s-1)τ。 (10) (11) (12) (13) 式中:投影矩阵A=[a1a2…ak]∈d×k,每一列ai服从正态分布;β为k维向量,每个元素均从[0,r]的范围内统一选择;将d维数据段转化为桶,使得同一桶中的段是相似的。随机选择1个桶,并将其划分为统一宽度r。为了提高索引构建的准确性,应用l个哈希表函数g1(x),g2(x),…,gl(x),形成l个表H1~Hl。 本文所提出的预测模型的框架如图1所示。通过SSA对原始时间序列进行分解,得到9个特征向量,每个特征向量的贡献率见表1,前3个特征向量用于提取平均趋势。然后,在相空间中重构平均趋势,并分别转换为平均趋势段和波动分量段。 表1 特征向量贡献率Tab.1 Contribution rates of eigenvectors 图1 本文所提预测模型框架Fig.1 Framework of the proposed forecast model 由于波动分量具有高度随机性,对平均趋势段进行相似段搜索,通过LSH得到预测平均趋势段的若干相似段。为了避免时间序列分解产生的误差累积现象,训练输入为相似平均趋势段和相应波动分量段的合成。图2所示为采用所提方法进行预测的算例结果,图3所示为实现所提预测模型流程。 图2 步长为4的建议方法调频需求预测结果 Fig.2 Forecast results of regulation capacity demand of the suggestion method with 4 steps 图3 所提模型计算流程Fig.3 Flow chart of the proposed method 为了评估所提模型的性能,以华南地区某省在2021年2月20日至22日的区域控制偏差(area control error,ACE)数据作为原始调频信号数据,用于预测。调频需求容量主要用于分钟级波动分量调节,以ACE作为参考量,AGC系统每5 s发送ACE数据1次,反映一段时间内有功平衡控制偏差的大小,通过将ACE控制在死区范围内来保证电网的发用电平衡[29]。为了简化计算,对ACE数据进行离散标准化处理。2021年2月20日至22日的数据如图4所示,统计测量值(平均值、标准差、最小值和最大值)见表2。为了检验预测模型在不同时间的性能,分别对这3组数据进行预测,并与实际数据进行比较。 表2 3日区域控制偏差数据的统计特性Tab.2 Statistical properties of ACE data of three successive days in February 图4 不同预测方法结果对比Fig.4 Result comparisons of 4 different forecast methods 图4 2月连续3日的ACE数据Fig.4 ACE data of three successive days in February 为了评估所提出模型的预测准确性,采用2个常用标准来衡量误差:归一化平均绝对误差(normalized mean absolute error,NMAE)和归一化均方根误差(normalized root mean square error,NRMSE)。NMAE(其量符号为ηNMAE)表示预测结果与最终结果的接近程度,而NRMSE(其量符号为ηNRMSE)评估预测值与实际值之间的标准差,这反映了预测模型的稳定性。NMAE或NRMSE值越小,预测结果越准确和稳定。二者定义如下: (14) (15) 分别采用SVR、SSA-SVR和SSA-LSH-SVR模型进行预测并与所提模型进行比较,预测方法结果如图5所示。由图5可知:作为典型的机器学习模型,SVR模型通常在大多数预测应用中表现良好,并且被视为基准。SSA-SVR模型提取信号的平均趋势分量,并将剩余部分视为噪声,然后将频率调整的平均趋势分量输入到SVR模型中。预期SSA的应用可以减少随机性的影响,而SSA-LSH-SVR模型中SSA的功能与SSA-SVR模型相同,并且使用LSH来寻找与预测均值趋势段相似的段,然后使用这些段形成训练输入以建立SVR模型;以这种方式实现局部预测,并且期望其显示出比全局预测更好的性能。通过对比,突出了SVR、SSA-SVR和SSA-LSH-SVR这3种预测方法的优劣。4种预测模型的性能评估对比见表3。 表3 4种预测模型的性能评估Tab.3 Performance evaluation of 4 forecast models 与其他模型不同,本文所提模型将SSA产生的余数视为波动分量,LSH也用于寻找与预测平均趋势段相似的段。SSA-SVR和SSA-LSH-SVR模型的训练样本仅为平均趋势段,但所提模型的训练样本是相似平均趋势段和相应波动分量段的合成。这样,SVR模型中的2个分量被独立处理,解决了调频信号分解过程中误差累积的问题。 对SVR、SSA-SVR、SSA-LSH-SVR模型和所提模型分别在3个数据集上进行验证。所提模型3月4个步长的预测结果见表3,可以看出,预测值与实际值几乎一致。 如表3所示,本文总结了步长为4、6和8预测的数值结果,检验了所提模型在各种数据集上的表现。由于频率在不同日期可能有不同的自然特征,所以预测在2月连续3日进行。可以看出,对于所有3个数据集,所提模型均给出了最小的NMAE和NRMSE,表明所提模型在准确性和稳定性方面均优于其他模型。 为了使LSH在预测中更加有效和适用,本文所提模型通过合成相似的平均趋势段和相应的波动分量段来作为训练样本,从而进一步改进SSA-LSH-SVR模型的精度和稳定性。同时有必要分析如何获得模型的最佳参数。 在样本间隔为5 s的ACE数据集上进行的一系列实验结果表明,随着步长增加,可以获得更精确的预测嵌入维数L;然而,当L达到临界点时,精度开始下降。另一方面,散列表的数量l和LSH函数的数量k不会显著影响预测结果。对于相似段NV,精度随着NV的增长而增加,并最终收敛到某一值。 不同种类数据的最佳参数是不同的,需依据大量实验获得。为了更有效地进行实验,可以提出一些一般性的建议。首先,为SSA选择1个合适的嵌入维数L,考虑到上述临界点,对于每个步长,存在使NMAE最小的L值,对哈希表的数量l和LSH函数的数量k没有严格的限制。最后,为了确定相似段的最佳数量NV,建议研究应从NV=100开始,并以4为步长增加。 本文提出一种基于SSA和LSH的调频辅助服务市场短期容量需求预测计算方法。该方法首先利用SSA将原始时间序列分解为2个分量——平均趋势分量和波动分量,其中平均趋势分量揭示原始时间序列缓慢变化的趋势,波动分量代表其随机特征。其次,采用LSH对平均趋势段进行分类,并找出与预测平均趋势相似的趋势段,在SVR中只包含这些相似的部分可以改善预测结果。最后,选用SVR作为预测模型,其训练样本为平均趋势分量和波动分量的综合,这有助于确保这2个分量是独立的,且互不干扰,从而产生更准确的预测结果。 数值仿真部分的结果表明:与实际历史结果相比,所提模型通过合成相似的平均趋势段和相应的波动分量段来代替训练样本,进一步改进了SSA-LSH-SVR模型的精度和稳定性。与其他已有方法相比,所提方法预测的调频容量需求更为合理。 本文未区分不同类型调频资源调节特性的差异,未来研究中拟考虑调频资源速率的差异,研究含多种调频资源的调频容量需求计算方法。

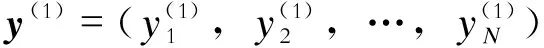
1.2 局部敏感哈希
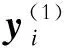




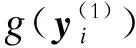
2 预测模型



3 算例分析
3.1 数据来源


3.2 结果评估

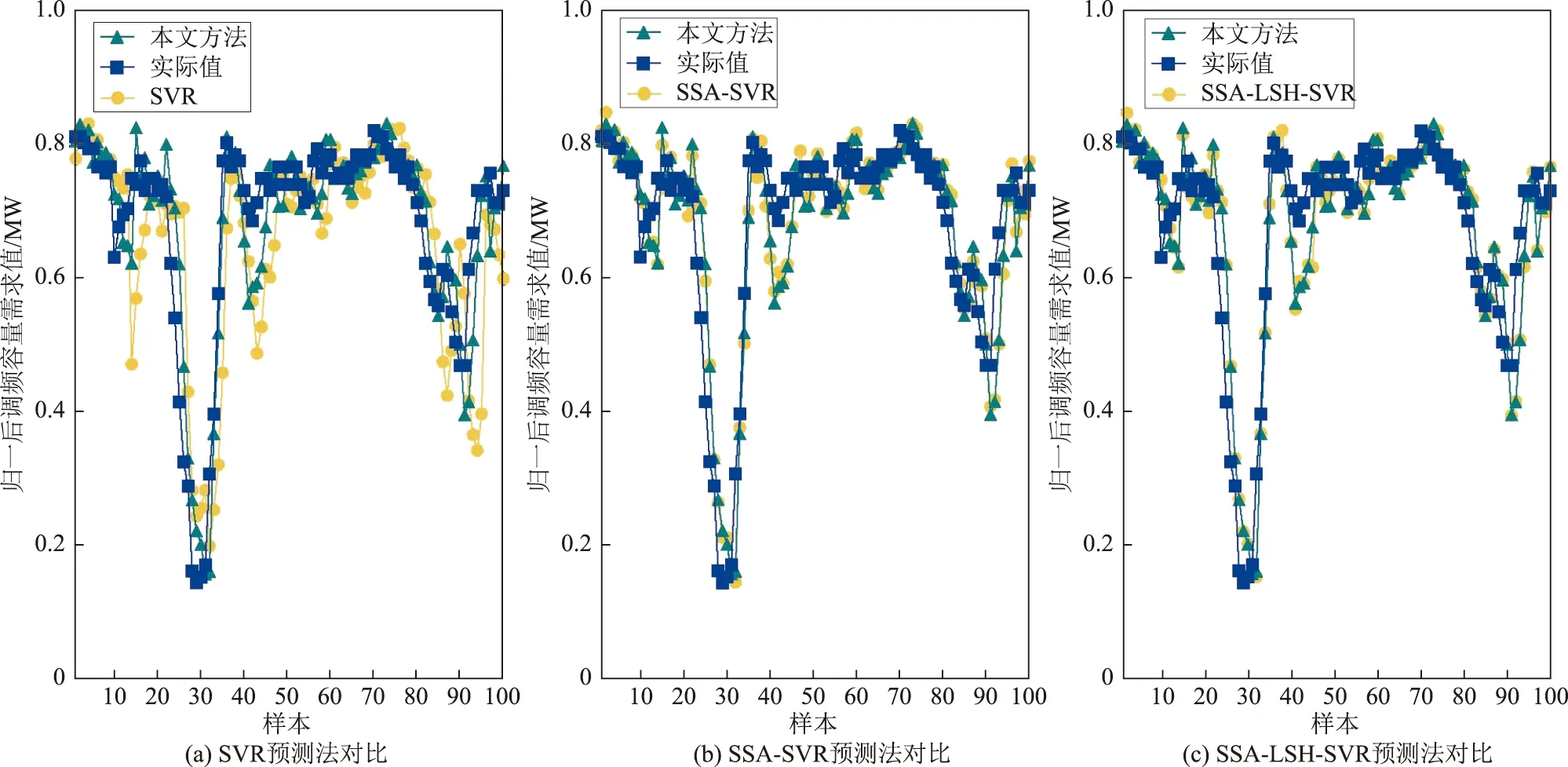
3.3 方法比较
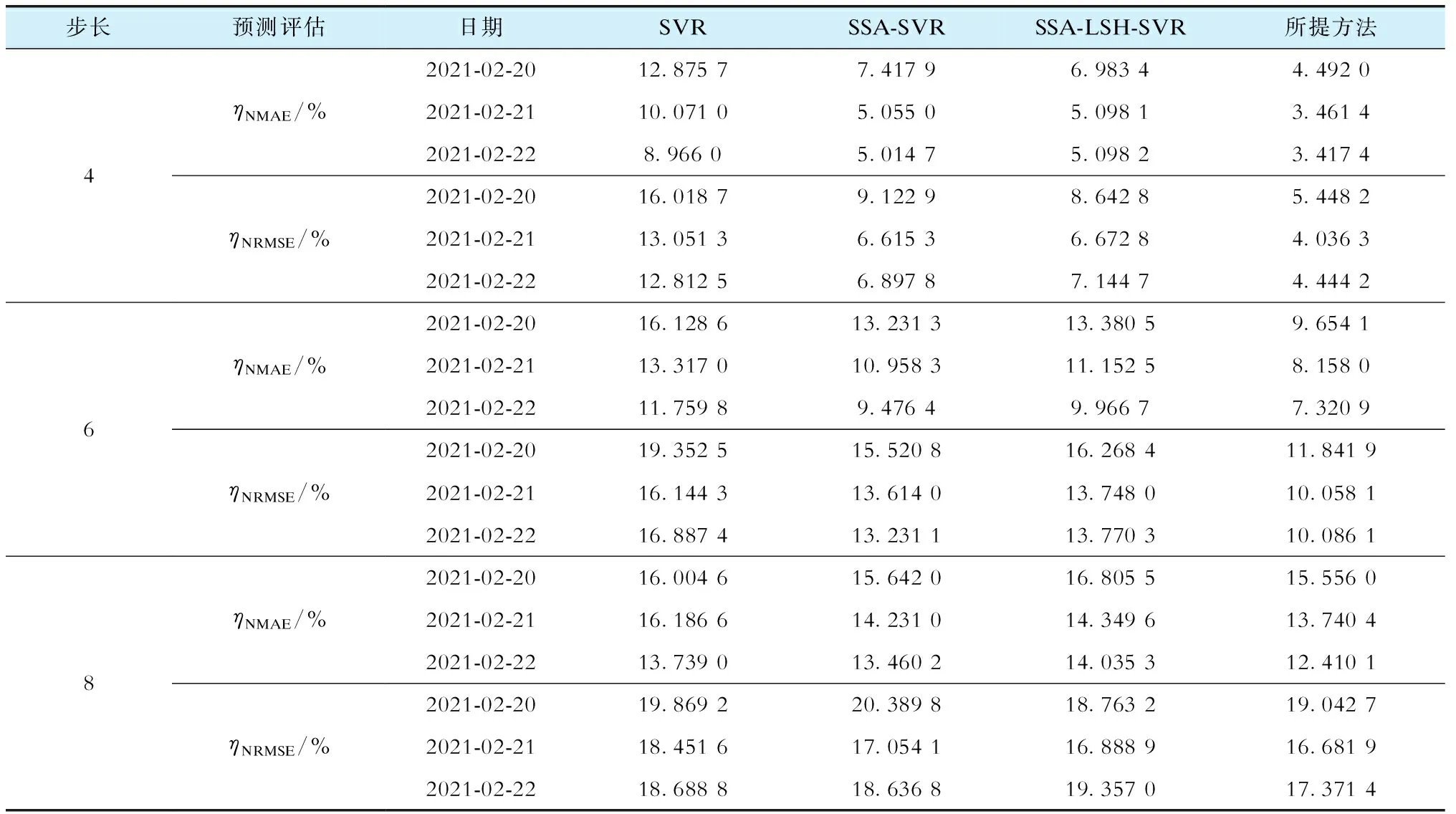
3.4 预测结果和讨论
3.5 参数讨论
4 结束语
猜你喜欢
能源工程(2021年5期)2021-11-20
第一财经(2021年6期)2021-06-10
基层中医药(2021年12期)2021-06-05
英美文学研究论丛(2018年1期)2018-08-16
Coco薇(2017年9期)2017-09-07
纺织科学研究(2017年6期)2017-07-03
纺织服装流行趋势展望(2016年2期)2016-05-04
西部广播电视(2015年9期)2016-01-18
西部广播电视(2015年9期)2016-01-18
汽车科技(2015年1期)2015-02-28
