
基于改进YOLO-MobileNet的近红外图像特征驾驶员人脸检测
2023-11-06 01:59苏童
兰州工业学院学报 2023年5期
苏 童
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
近年来,随着我国国民生活水平的提高,我国机动车保有量连年激增,随之而来的交通安全问题也不容忽视。据统计,在夜间光照条件恶劣的环境下发生的交通事故约占总事故的78%。驾驶员疲劳驾驶,危险驾驶等也多数发生在夜间[1]。因此,在夜间对驾驶员的状态进行监测就显得尤为重要。在对驾驶员进行检测时,使用摄像头进行图像采集这种方式对驾驶员的影响最小,也是最可行的方式。但普通的摄像头无法胜任在夜间的工作,因此本文采用了波长在700~1 100 nm范围内的近红外光配合硅基CMOS传感器进行图像的采集。
人眼对波长在400~700nm范围内的电磁波较为敏感,而对于图像采集设备常用的CMOS来说,能够感应到的最大波长约为1 100 nm,因此,波长在700~1 100 nm范围内的电磁波既可以被CMOS感应到,又可以对驾驶员不造成任何影响。
传统的面部识别技术多采用two-stage检测算法,如Faster R-CNN[2]算法,其工作原理是先生成可能包含被检测物体的候选框(region proposals),然后再对每个候选框进行分类并不断优化其框选区域。由于需要不断检测和分类以达到最优状态,其运行速度相对较慢。而另一种one-stage目标检测算法(也称one-shot object detectors),其特点是仅需将图片送入网络一次,通过一次检测和分类,就可以识别出图片当中的信息,因而速度较快,非常适合嵌入式设备。典型的如YOLO[3],SSD[4],SqueezeDet以及DetectNet。
针对驾驶时要求识别速度快但嵌入式设备算力低的问题,本文将YOLOv5s网络结合Mobile net网络进行轻量化,并对其C3模块进行改进,优化网络在嵌入式设备上的运行速度。为夜间驾驶员面部识别相关研究提供了基础。
1 YOLOv5s网络
YOLOv5是基于深度学习的one-stage回归方法,其主要由3个部分构成:Backbone: New CSP-Darknet53;Neck: SPPF,New CSP-PAN;Head: YOLOv3 Head[5]。其结构如图1所示。
与YOLOv4相比,YOLOv5s在Backbone部分并没有太大的变化,但在Neck部分将SPP换成了SPPF,两者作用一样,但后者效率更高。
二者结构如图2~3所示,SPP并联了多个不同大小的MaxPool,再进行融合,而SPPF则是串联了多个MaxPool,二者都能在一定程度上解决多尺度目标问题。
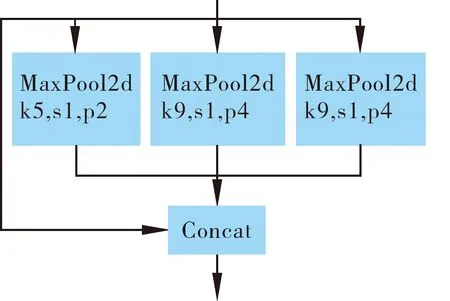
图2 SPP结构
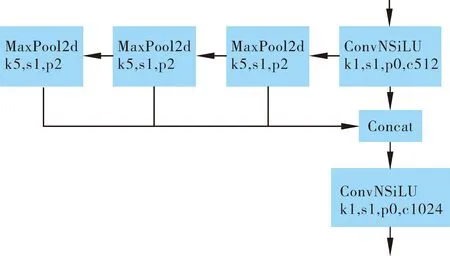
图3 SPPF结构
2 Mobile Net网络
Mobile net网络是Google针对手机等嵌入式设备提出的一种轻量级的卷积神经网络,其核心思想为深度可分离卷积,将标准卷积分解成一个深度卷积和一个1x1的点卷积,可以有效地减少网络参数。Mobile netv1采用的是标准残差,输入通道数会限制特征提取,并且在网络的最后采用了ReLU6激活函数,会造成depthwise 部分的卷积核废掉。Mobile netv2则采用了倒置残差,解决了特征受限于通道数的问题,并将ReLU6替换为Liner线性激活函数,避免了特征信息进一步丢失造成的depthwise 部分的卷积核废掉。而在2019年提出的Mobile netv3模型中,在继承前两代轻量化的基础上,采用互补搜索算法减少了计算开销,运行速度有了很大提升,网络深层使用h-swith激活函数,提高精度的同时,进一步减少了延时。并且还提出了一大一小2种模型,可根据任务规模选择更为合适的模型。
3 改进YOLOv5s-Mobile net网络
车载嵌入式设备相较于桌面端处理器,算力相对较低,并且对于与驾驶员交互的应用场景而言,响应速度是非常重要的一项性能指标。过于复杂的模型可能会在运行的过程中面临内存不足等问题。并且车载嵌入式处理器还需要应对驾驶时的各种辅助操作。因此,一种紧凑并且高效的检测模型对于这些应用场景来说至关重要。
YOLOv5s主干特征提取网络采用C3结构,检测速度较慢,并且参数量较大,并不适用于嵌入式设备。但其回归的思想在检测精度上具有较大的参考价值。因此将YOLOv5s的主干特征提取网络替换为更轻量级的Mobile netv3网络,并且针对近红外图像的特点进行优化,以实现模型的轻量化,以实现速度与精度兼得。
3.1 改进特征提取网络
YOLOv5网络的最轻量级模型YOLOv5s通过9组特征层进行下采样,对输入图片进行降维,图像尺寸不断减小,深度不断增加,然后再通过8组卷积层进行升维,而后进入检测层再一次降维,最后输出检测结果。为实现轻量化目标,将该网络模型的特征提取部分替换为Mobile netv3-small模型。
此外,针对近红外图像为单通道图像的特点对网络结构进行优化,将整个网络的卷积维度进行适当降低,并对整个网络进行剪枝压缩。
3.2 YOLOv5s head部分优化
针对YOLOv5s网络的head部分优化,单纯靠降低输入来减少运算对检测效果损失很大,并且模型体积并没有减少。因此可以通过添加L1正则来约束BN层系数,使得系数稀疏化,通过稀疏训练后,裁剪掉稀疏较小的层。因为稀疏小的层对应激活也会很小,因此对最后的结果影响也很有限。
BN层计算公式为
所以每个channel激活大小zout和系数γ正相关,如果γ太小接近于0,那么激活值也非常小。通过添加L1正则约束,即
L=∑(x,y)l(f(x,W),y)+λ∑γΓg(γ).
上式第一项为正常训练的loss函数,第二项为约束,其中g(s)=|s|,λ是正则系数,根据数据集调整。将参数稀疏化,并且在反向传播的时候改为
L′=∑l′+λ∑g′(γ)=∑l′+λ∑|γ|′=∑l′+λ∑γ*sign(γ).
在BN层权重乘以权重的复合函数输出及系数即可。
另外,YOLOv5s head部分也存在多个C3结构,为减少参数量,对其进行优化。YOLO中的C3模块是由2个1x1的卷积层夹着一个3x3卷积层组成,通过1x1卷积层来降维和升维,让3×3卷积层成为输入/输出维数更小的瓶颈。虽然原有的Bottleneck减少了参数量,但还存在进一步优化的空间。参照Mobile net的分离卷积操作,对其先进行PointwiseConv,再进行DepthwiseConv。通过计算可以看出修改后大大减少了该模块的参数量。
3.3 Mobile netV3 backbone部分优化
针对backbone部分的Mobile netV3网络的优化,由于Mobile net网络采用的深度可分离卷积操作已经使得卷积核的数量大大降低,得益于近红外图像为单通道图像的特点,可将卷积核数量进一步压缩。
输入部分改进如图4所示,可以看出:YOLOv5s对于RGB图像的卷积需要九个filter,Mobile net网络仅需要3个filter,而针对近红外图像进行优化的网络仅仅需要1个filter,这在网络的参数量上得到了极大的简化。
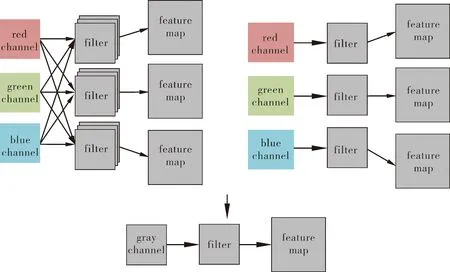
图4 输入部分改进
4 试验分析
4.1 试验环境
试验环境的操作系统为Win10专业版,CPU为Intel Core i5-12400F 2.5 GHz,内存为16 GB,编译语言为Python 3.7,深度学习框架为PyTorch 1.12.0,CUDA版本为11.6.58,基准模型选择YOLOv5轻量化版本YOLOv5s和Mobile netV3的小型版本Mobile netV3-small。
4.2 数据集
由于近红外图像数据集种类和数量都比较少,为了更加贴合真实夜间驾驶场景,试验收集了2类公共的近红外人脸图像(FADIA + NIR_face_dataset)并且加上了重新采集的图像自建数据集(见图5),整合3类数据集的图像一共5 000多张图片,包含各类发型、姿势及服装配饰并且使用Labelimg工具重新整理标签,对于是否佩戴眼镜进行区分。采集设备采用索尼Super HAD CCD传感器,传感器尺寸为1/1.8英寸,有效像素为710万,红外补光波长为850 nm,采集地点为车内驾驶位,传感器置于仪表台上方。

图5 数据集图像
由于近红外图像里主体与背景差别非常突出,随机打乱并划分非常容易导致过拟合。试验前先将数据集按照拍摄角度分为正前方、左侧方、右侧方、上方、下方5个子集,以模拟在驾驶过程中驾驶员头部的动作,然后对每个子集以8∶1∶1的比例进行顺序划分,分别作为训练集、验证集、测试集。
4.3 试验结果与分析
针对以上对算法的改进,相较于其他算法,设计了模型参数量、检测精度、检测速度3个方面进行比较分析来验证该算法的优越性。
1) 模型大小。在模型参数量方面,3种网络的对比如表1所示。

表1 模型参数量对比
试验结果表明,经过优化的YOLO-Mobile net在参数量上远低于原来的2个模型,训练后的最优模型大小为7.39 M,为能够在内存空间有限的嵌入式设备上正常运行提供了可能。
2) 检测精度。检测精度对比见表2。

表2 检测精度对比
试验结果表明,YOLOv5s的检测精度为85.37%,Mobile netv3-small的检测精度为85.32%,所构建的YOLO-Mobile net检测精度为84.93%。模型的轻量化的确带来了一定的精度下降,但也并没有出现太大的差距。检测结果见图6。

图6 检测结果
3) 检测速度。在检测速度方面,对训练完成的YOLOv5s,Mobile netv3-small,YOLO-Mobile net进行检测速度对比[6](见图7),试验过程不使用GPU加速,仅使用CPU运算,所构建的YOLO-Mobile net模型检测速度远高于另外二者,达到了20.4 ms/张。
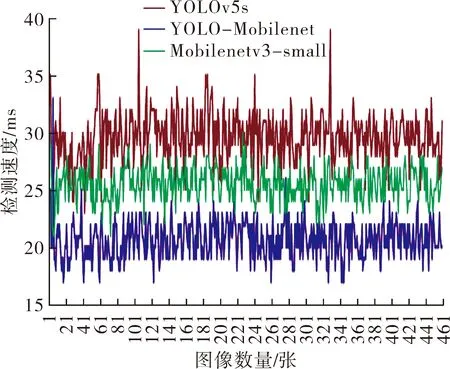
图7 3种模型检测速度对比
综上所述,本文搭建的YOLO-Mobile net模型在轻量化方面要优于一般轻量级算法,并且在检测精度上也没有出现明显的落后。该模型具有较高的检测速度,能够达到20.4 ms/张;具有一定的检测精度,达到84.93%;参数量也比较少,为142 998,适用于暗光环境下的驾驶员人脸检测。
5 结语
针对暗光环境下驾驶员人脸检测问题,提出了一种基于改进YOLO-MobileNet轻量级深度学习算法的近红外图像特征驾驶员人脸检测方法。在保证检测精度的同时,大幅提高检测速度,降低运算量,为在嵌入式设备中正常运行提供了理论支撑。
在下一步的工作中,根据不同光照条件下的检测环境进行相应的图像预处理,进一步提升模型的普适性,同时进一步优化模型结构,将模型搭载于嵌入式设备。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
铁道通信信号(2018年2期)2018-04-18
电镀与环保(2016年3期)2017-01-20
公民与法治(2016年4期)2016-05-17
电视技术(2014年19期)2014-03-11
单片机与嵌入式系统应用(2014年9期)2014-03-11
