
A Study of Ensemble Feature Selection and Adversarial Training for Malicious User Detection
2023-11-06 01:16LinjieZhangXiaoyanZhuJianfengMa
China Communications 2023年10期
Linjie Zhang,Xiaoyan Zhu,Jianfeng Ma
State Key Laboratory of Integrated Services Networks,Xidian University,Xi’an 710071,China*The corresponding author,email: xyzhu@mail.xidian.edu.cn
Abstract: The continuously booming of information technology has shed light on developing a variety of communication networks,multimedia,social networks and Internet of Things applications.However,users inevitably suffer from the intrusion of malicious users.Some studies focus on static characteristics of malicious users,which is easy to be bypassed by camouflaged malicious users.In this paper,we present a malicious user detection method based on ensemble feature selection and adversarial training.Firstly,the feature selection alleviates the dimension disaster problem and achieves more accurate classification performance.Secondly,we embed features into the multidimensional space and aggregate it into a feature map to encode the explicit content preference and implicit interaction preference.Thirdly,we use an effective ensemble learning which could avoid over-fitting and has good noise resistance.Finally,we propose a datadriven neural network detection model with the regularization technique adversarial training to deeply analyze the characteristics.It simplifies the parameters,obtaining more robust interaction features and pattern features.We demonstrate the effectiveness of our approach with numerical simulation results for malicious user detection,where the robustness issues are notable concerns.
Keywords: malicious user detection;feature selection;ensemble learning;adversarial training
I.INTRODUCTION
With the rapid development and popularity of the mobile Internet,the security concerns have become increasingly prominent.In mobile communication devices,Internet links and social service platforms,malicious users can pry user information without authorization and use templates to automatically generate a large amount of spam information.Malicious users carry out a variety of malicious activities,spread a variety of malicious information and publish malicious advertisements.Malicious users interact with other users in order to maximize their own benefits and try to steal users’privacy.Dewang et al.[1]reported that many users are misled by the false information sent by malicious users.Therefore,more efforts are needed to identify misleading malicious users to ensure the credibility of the network.Tang et al.[2]found some interesting properties in the research of malicious user behavior.That is,malicious users are generally created at one time,and multiple spam messages are often initiated by a large organization.The spam information disperse,harass and even cheat honest users to guide users’ judgment.It seriously affects the user experience and consumes network resources.
Research on malicious user detection can not only promote the theoretical development of network science and information science,but also has great practical value.It could be used in public opinion analysis[3]to prevent malicious users from misunderstanding and misinterpreting information.It can help to recover the list that cannot display normal information due to the interference of malicious users.In the application of community discovery,the malicious behavioural pattern could be spotted as an anomaly which provides useful information [4].In the exploration of influential people for viral marketing[5],it helps considering the influence of interaction between users and the authority of users during information dissemination.The later work[6]highlights the difference of information influence in a specific release.This can also be applied to the access control model [7].It uses further information from the user profile to detect malicious users,increase the richness and granularity of policies.
Similar to the web-based malicious communication samples [8],the rich and diverse forms of malicious users have caused increasingly serious security problems.On the one hand,some malicious users become more real with very detailed personal information.The possibility of spreading invalid information through forged identity increases,which leads to the spread of harmful content.The layers of data network architecture generated at different times are usually underutilized[9].On the other hand,malicious users are more intelligent and anthropomorphic,acting more complex interactions with normal users.Malicious users could automatically publish the collected information at a predetermined time,gradually simulating the content publishing characteristics of normal users.In the diverse environment of malicious users,timely and accurate detection of malicious users becomes a major challenge in current research [10].This can ensure the trustworthiness of user relationship,which maintain the stability and reliability of information detection[11].
Due to the limitation of feature representation,traditional methods are difficult to understand the inherent laws of data from multiple perspectives[12].This does not dig deep into the implicit attributes and is unlikely to reflect the significant structural differences with normal users.Furthermore,if a single relationship is used to detect malicious users,it violates the fact that users may connect with normal users through multiple relationships [13].Although capturing the short-term aspects of relationships,they may miss the long-term dependencies of users hidden in the relationships,making them more suitable for multidimensional heterogeneous data[14].These methods ignore the dimension of features and do not select the key features,so the classification ability of the detection system is limited[15],which could not effectively predict the deep abstract features[16].Ensemble feature selection is the fusion of ensemble learning idea and feature selection method.It combines the output of multiple feature selectors to improve performance,so that users do not have to choose a single method.
In addition,the classification model is easily affected by the adversarial disturbance.The network structures and properties are retained in the low dimensional embedding vector,while the existence of noise information and the over fitting problem in the process of embedding learning are ignored [17,18].The samples are mixed with some small disturbances,which may cause misclassification.Therefore,the adversarial training can be considered as an effective data enhancement technology and an important way to enhance the robustness of neural network[19,20].It does not need previous domain knowledge and can improve the test accuracy[21–24].The deep learning model has poor generalization ability and linear characteristics of learning model components.How to deploy adversarial training in practical application is an continuous research challenge.
In order to find the implicit preference of users,we apply feature selection and adversarial training to construct malicious user model.We make use of multifeature ensemble learning to realize intelligent,stable,and reliable malicious user detection.The main contributions of this study are summarized as follows:
• First,we analyze the characteristics of malicious users and normal users,screen out the initial features and carry out feature engineering for personalized and diversified malicious user detection.We explore explicit and implicit preferences reflected by malicious user characteristics and solve the data heterogeneity and complexity.
• Second,we use feature selection to reduce the dimension of data,accelerate the implementation of the comprehensibility of features.We explore the long-term behavior and short-term relationship behavior hidden in the multi relationship behavior of users from multiple perspectives.We calculate the detailed effect of feature influence,employing the ensemble learning to improve presentation ability.
• Third,we use the adversarial training to combine the deep learning architecture to against disturbances.We train the neural network model to minimize the loss of training data and the model becomes more robust to adapt to the disturbance.
• In order to verify the validity of the proposed model,we use the metric to measure the performance of the model and compare the model with its variants.We have obtained the promising and popular regularization methods for the detection results of the most advanced methods.
The remaining paper is structured as follows: We introduce the related work from user detection and adversarial training and analyze the development trend in Section II.In Section III,we deeply analyze the model architecture,optimization theory and theoretical knowledge of feature engineering,adversarial training and integrated learning.We analyzed the demand and the particularity of this scenario.In Section IV,we select the characteristics of malicious users,expounding the implementation process of feature mining.Following in Section V,we describe the model structure and optimization and present our solution in detail.Section VI includes the details and results of the experiments we conducted.The Section VII is the conclusion and the future work.
II.RELATED WORK
Effective malicious users need to select relevant features to describe the behavior of malicious users.On this basis,many researchers try to explore the characteristics of malicious users,such as distance,relevance,consistency,information and classifier error rate,in order to effectively solve this problem.
2.1 User Detection Taxonomy
For all kinds of malicious users,the current detection methods can be divided into content based detection,behavior based detection,graph based detection,relationship based detection and sequence based detection.
Content based malicious users detection mainly analyzes user comments and published content.It mainly relies on natural language processing methods,which match and recognize words through their grammar,structure and related rules.Some statistical methods use credibility to identify words,such as the frequency of words in the corpus,the context information of words.Behavior based malicious users detection mainly uses behavior features such as user publishing and forwarding.The analysis of user behavior is helpful to the deep understanding of user intention.Graph based malicious users detection,it establishes the corresponding graph structure.It is very important to define the metric features that can best map the network structure to the vector space.Relationship based malicious users detection considers the inherent multiplicity of interactions.It captures different aspects of different relationships and activities can provide more clues to detect any suspicious activity.Sequence based malicious users detection method is based on the fact that an individual instance is abnormal in a specific situation and normal in other situations.It considers using time-varying sequence structure to continuously track suspicious activities under different time snapshots to balance efficiency.
2.2 Emerging Technology
In the early methods,the number of malicious users is relatively small,the behavior is not highly covert,and the generated spam usually has significant recognizable characteristics.Now the disguise of malicious users is more comprehensive,we need new technologies to detect.
Some methods are based on the traditional discrete sparse features,which can not effectively encode the effective information.Bhuvaneshwari et al.[25] bright up a model combining convolutional neural network and long-term and short-term memory network to learn document level representation to recognize spam comments containing context.They calculate the weight of each word in the sentence,learn the sentence representation with convolutional neural network and use bidirectional long-term and shortterm memory network as the document feature vector.Ahmad et al.[26] set up a support vector classifier composed of two Gaussian kernels and polynomial kernels to select the optimal subset of user profile features,account information features,user activitybased features,user interaction based features and content-based features for the learning process.These methods have low interpretability and can not give the internal meaning of the data.The feature utilization rate of these methods is too low,which will reduce the detection accuracy because of the data sparsity.
Ensemble learning changes the distribution of the original training samples,so as to build a number of different classifiers.These classifiers are linearly combined to get a more powerful classifier.In order to effectively solve this problem,Elakkiya et al.[27]developed a method based on genetic algorithm to combine feature subset selection with multiple evaluation,which paid attention to the feature with the lowest weight and comprehensively considered the features of all evaluation indexes to generate the appropriate subset.Budhi et al.[28] applied dynamic random sampling technique to text-based characterization.This method effectively solved the first class imbalance problem and the establishment of the first mock exam system with single model and integration model.These methods have high time and space complexity and need a lot of memory.In addition,there is a problem of sample imbalance.Some categories have a large number of samples,while others have a small number.
2.3 Adversarial Training
Adversarial training refers to injecting virtual adversarial samples into the training set to train the defense model.Virtual adversarial samples refer to the adversarial samples constructed by tags provided by trained models,which may lead to the deviation between the performance and expectation of the model.The training helps the features learned from high-dimensional data adapt to different but related low dimensional information.After adding disturbance to the input,the output distribution is consistent with the original distribution.Then,the model penalizes the sensitivity for disturbance.
Different network topologies used in adversarial training configuration can be extended to a variety of adversarial training network.Szegedy et al.[29] obtained the adversarial samples by finding the minimum loss function addition term and adding slight disturbance to the correctly classified input.Goodfellow et al.developed a method of resisting samples which benefits from the gradient sign matrix of loss function.In the direction of the gradient change of the loss function,it is the largest result to find the counter sample to realize the local class error.Moosavi et al.[30]generated the minimum gauge by iterative calculation to resist the disturbance and gradually pushed the image within the classification boundary out of the boundary until the wrong classification occurred.
Papernot et al.[31] used Jacobian matrix to evaluate the sensitivity of the model to each input feature,and ranked the contribution of each input feature to the misclassified target to obtain the countermeasure samples.Su et al.[32] used differential evolution algorithm,which does not need the gradient of neural network and can be used for non differential objective function.Carlini and Wagner [33] defined a new objective function,which can better optimize the distance and penalty term.Houdini et al.[34] used the gradient information of network differentiable loss function to resist attacks by generating task specific loss function.The idea of FreeAT[35]is to repeatedly train each sample continuously and reuse the gradient of the previous step.The starting point of YoPo[36]is to use the structure of neural network to reduce the calculation amount of gradient calculation.The FreeLB model [37] accumulates the gradients of parameters and updates them.
Xie et al.[38] present an Attentive Userengaged Adversarial Neural Network,which interactively learns the context information.Wang et al.[39]proposed a mobile user configuration framework based on adversarial training.The framework accurately simulates the mobile mode of users to obtain the optimal user configuration.The adversarial training is more and more integrated with deep learning.Therefore,we focus on generating robust representation based on adversarial training.The quality of representation can be improved by applying adversarial training to the neural language model.This not only enhances the diversity of representation,but also improves the classification performance of the classification model.
III.PRELIMINARY
3.1 Scene Model
In order to support large-scale connectivity,each device transmits information without authorization process,which makes the base station need to identify active devices among all potential devices [40].User personal data verification,user information trajectories and user communication behavior patterns make identity possible communication threats [41].Frequent communication leads to the information more abundant and increases the popularity of information,so that other users can find information with greater probability.But the appearance of malicious users makes the normal transmission distorted.According to the information dissemination,the malicious users excessively connect a large number of users with special purposes and publish content inconsistent with the topic.
Generally speaking,the classification of malicious users is a binary classification problem[42].Uiis the user to be determined,M is the normal user set and N is the malicious user set.The malicious user is represented as 1 and the normal user is represented as 0.
3.2 Feature Engineering
The increase of the number of features greatly affects the complexity of the model.Because complex network features can not be defined from the interaction relationship,the deep information hidden in the multi relationship network can not be fully utilized.As time goes on,some classic features will not be suitable for malicious user detection for a long time,so it is necessary to do feature engineering to select important features before model training.
3.2.1 Malicious User Category
Most of the existing researches acquire features based on experience,but malicious users have different forms in different stages.We need to mine features according to the specific categories of malicious users to enrich the diversity of detection features.
•Bot Account
The bot account is a false account created by an attacker through an automatic tool.It could spread false information by simulating some operations of normal users.It is the account registered by malicious users using automated programs or tools,so the detection of the bot account mainly uses the characteristics of naming rules.
•Sybil Account
The sybil account is originally used in P2P and other distributed networks to describe the false identity.These accounts describe the false account created by the attacker in the network structure.The detection of the sybil account is mainly based on the abnormal graph structure.
•Spam Account
The spam account is the general name of the false accounts created by attackers in the application stage.These accounts are mainly used to publish advertisements,phishing and pornography.The spam account detection mainly focuses on the characteristics of malicious behavior and content.
•Compromised Account
The compromised account refers to the hijacked account,which are normal accounts,but they are hijacked by attackers to carry out malicious behavior.Attackers often steal normal accounts through various methods to carry out malicious behavior.Because this is created by normal users,there is no characteristic of account creation and development stage,so the detection of compromised account mainly uses the mutation of account behavior.
•Spam Campaign Account
The spam campaign account is used to spread malicious information or perform malicious actions in a centralized period of time.The detection of spam campaign is mainly based on the group behavior of these accounts,such as publishing the same message or praising a page.
With these user categories,we know where to refine and efficiently analyze features.
3.2.2 Feature Category
The most existing methods do not analyze the importance of features and consider the redundancy of features,which adopt the method of combining and comparing different eigenvalues.Through the in-depth analysis of these categories,we can get the characteristics of malicious users and the identification characteristics of malicious users are more clear.
•Basic Information
The Basic information including account ID,gender,age,education background,occupation and hobbies and long and meaningless naming features.
•Creation Time
The creation time refers to the time interval from account registration to the current time,which is used to measure the survival time of the account.
•Number of Connectors
Normal users have selective link users,while malicious users are random link users.The malicious user aims to get more connectors,pay attention to other users in order to get connectors.The malicious users do not have real interaction behavior.Few users know their existence,so few users pay attention to it.
•Number of Posts
The malicious users post an appropriate number of contents to avoid detection.
•Posts Time Interval
It carry out short-term illegal activities for certain profit purposes.When the activity ends,it will no longer send posts.
•Interaction Ratio
The he dissemination of information depends on the interaction between users.The malicious users form a relationship chain with other users through interaction.Real interaction bring a lot of mutual fans to normal users.For malicious users,even if they pay a lot of attention to others,most normal users can identify their identities and rarely choose to return fans.
•Spread Ratio
The users browse,forward and give feedback to get effective way of information diffusion.Because browsing operations can be repeated,it is the most difficult for malicious users to cheat on data forwarding and feedback.
•URL Link Ratio
The malicious users are likely to join the URL to induce normal users to enter,so as to achieve some malicious purposes.If a URL is too long,it will be converted to a short URL.Through short links,users can use a short URL instead of the original long URL,so as to share links more conveniently.However,the widespread use of short links makes the original URL hidden and users can not confirm whether it is a malicious link through intuitive observation.
•Special Characters Ratio
Through the form of special characters in the content,other users see the content published by malicious users with special characters.In order to increase the exposure of information,spam users often hijack hot topics to participate in the discussion,but publish spam information that has nothing to do with the topic.
•Content Properties
Content Properties include Content Similarity Ratio,Regular Content Proportion and Regular Content Interval.Malicious users often send things with similar content.
To delete irrelevant features,we need a feature standard,which can measure the correlation between each feature.With the increase of feature number,it becomes a NP problem to directly evaluate all feature subsets.Therefore,it is necessary to use the feature selection process,select several features each time according to the selected objective function and optimize the objective function by evaluating different subsets to generate the solution of the optimization problem.
IV.FEATURE LEARNING
The detection of malicious users thinks that the normal behavior conforms to a certain model,while the behavior of malicious users does not conform to this model.The key is to extract appropriate features to form the normal user corresponding model.Then it judge whether they are malicious users according to whether other users match the model.
4.1 Data Collection
Data collection realizes the grab of the corresponding fields and category annotation.First,we set the invalid and missing values of the collected data to zero.Then,we transform the set data into a form suitable for data mining through smooth aggregation processing.Moreover,we converte data into unified data.Afterwards,we summarize and sort out the initial user features.
4.2 Feature Selection
In order to detect malicious users,we employ the specific characteristics of malicious users’ content,behavior and network.Therefore,we make use of feature selection to remove irrelevant features and redundant features.Irrelevant features refer to features that do not affect learning performance after deletion.Feature selection is a process of selecting a subset of features from the original feature set,finding the smallest set of features without reducing the learning performance.
Recursive feature elimination method reduces the scale of feature set,eliminating features significantly.The main idea of recursive feature elimination is to build the model repeatedly,then select the best feature,put the selected feature aside,and then repeat the process on the remaining features until all the features are traversed.
Guyon et al.[43] proposed a recursive feature elimination method based on support vector machine,which rank features according to the influence weight of all features.It takes advantage of support vector machine as a classification model to consider the excellent training feature subset.The solving process is transformed into quadratic convex optimization problem,which avoids local optimization to some extent.The complexity of the algorithm has nothing to do with the dimension of samples,and it has high generalization ability,so it is more suitable to deal with small samples but high-dimensional data.
The influence of each feature on the objective function is used as the ranking coefficient to generate the classification hyperplane of support vector machine model.There is a hypersurface in the feature space to separate the positive class from the negative class.By using nonlinear function,the nonlinear separable problem can be mapped from the original feature space to a higher dimensional Hilbert space,and then transformed into a linear separable problem.The hyperplane as the decision boundary is expressed as follows.
Wherexis the user data object,wis the normal vector representing the direction of the hyperplane andbis the distance from the hyperplane to the origin.
Because of the complex form of mapping function,it is difficult to calculate its inner product,so we utilize the kernel method,that is to define the inner product of mapping function as kernel function,so as to avoid the explicit calculation of inner product.We use sigmoid kernel as kernel function.
Where tanh() is the nonlinear transformation,ais the normal vector function.
Since the weight vector determines the influence on the decision function,the size of the weight vector is the standard to construct the feature ranking list.Each iteration eliminate the feature with the smallest weight vector and then retrain the support vector machine to construct the ranking list.For example,relative to the content as the optimization objective,the importance of each feature is ranked as follows.
4.3 Feature Representation
We use feature representation model to learn representation among different data sources.We embed data into multidimensional feature space to detect important local sequence patterns in complete sequences to explore different intrinsic characteristics.Then we aggregate these information into a feature vector of fixed length and the corresponding set of feature vectors of the same attribute into content feature map,attention feature map and communication feature map.The content feature map refers to the basic information,creation time,number of connectors,number of posts and posts time interval.The attention feature map refers to the interaction ratio.The communication feature map refers to the spread ratio,URL link ratio and special characters ratio.
Where,σrepresents feature map function,nj,nkrepresent data node,zrepresents link relation,πnj=
We extract feature vectors from content feature map,attention feature map and communication feature map respectively.We calculate explicit feature preference of feature vectors.
Where,εnkis the explicit feature preference of feature vectorµnk.
By modeling the semantic space,the entity representation can encode the implicit entity preferences of related users with high-order connectivity.We calculate the implicit feature preference of feature vector.The corresponding set of feature vectors of the same attribute are aggregated into content feature preference,attention feature preference and communication feature preference.We use learning entity embedding and enhanced entity representation of user interaction data to explore user preferences related to entities.
Whereω2,χ2,ω1,χ1is the parameter vector,tanh()is the nonlinear transformation function,εxis the query feature preference vector.
4.4 Ensemble Learning
After extracting the feature preference,we use multiple learners to integrate according to the relationship between features to improve the accuracy.We first train a base learner from the initial training set,and then adjust the sample distribution according to the performance of the base learner,so that the training samples that the previous base learner did wrong receive more attention,and then train the next base learner based on the adjusted sample distribution.This is repeated until the number of base learners reaches the value specified by the implementation and these learners are weighted and combined.
Ensemble learning could increase the diversity of learners,reduce the generalization error of semi supervised learning,accelerate its convergence speed.Most importantly,it could reduce the bias of class imbalance on prediction.The performance of the ensemble learning method is better than that of most single models,especially in the case of superposition of probability distribution and engineering original features[44].
We use AdaBoost algorithm to adjust the sample distribution by adjusting the sample weight.That is to say,we can increase the weight of the samples that are misclassified in the previous round and reduce the weight of the samples that are correctly classified.In this way,the misclassified samples can receive more attention,so that they can be correctly classified in the next round.We increase the weight of if classifier with small classification error rate and reduce the weight of if classifier with large classification error rate,so as to adjust their role in voting.
In the robust feature space,AdaBoost algorithm can alleviate the imbalance classification problem[45].By adjusting the weights on the misclassified samples,the classifier is retrained.The accuracy of the model is improved by reducing the overall variance.The algorithm can explain the nonlinear relationship and the interdependence between variables to gain good performance in nonlinear data prediction[46].
The specific flow of AdaBoost algorithm is as follows.
where,yiis used to represent the category label of the dataset.yi∈Y={-1,1},i=1,2,...,N.
The input of the algorithm is dataset T while the output is final classifier,Gm(x) :X→{-1,1},m=1,2,...,M,whereMis the number of weak classifiers.
We initialize the weight distribution of training data and each training sample is given the same weight at the beginning.We set the initial weight distribution.
Then,we select a weak classifier with the lowest current error rate as the m-th basic classifierGm.We calculate the error of the weak classifier on the distributionDm.
We calculate the proportion of the weak classifier in the final classifier.
Where∂mis the weight of the weak classifier.
We update the weight distribution of training samples.
Where,Zmis the normalization factor.
Finally,we combine each weak classifier according to the weight of the weak classifier.
We get the final classifier through the sign function.
We use grid search algorithm to optimize the parameters of the integrated model.Grid search is an exhaustive search method for specifying parameter values.The parameters of the function are optimized by cross validation.We arrange the possible values of each parameter and combine all the results to generate the grid.Then,each combination parameter is used for ensemble learning and we use cross validation to evaluate performance.After the fitting function tries to combine all the parameters,it returns an appropriate classifier and automatically adjusts to the optimal parameter combination.
V.NETWORK METHODOLOGY
5.1 Neural Network
We cascade the input layer,the hidden layer and the output layer to form the neural network.Each layer is composed of several neurons and the neurons between the layers are connected with each other by weighted wires.In the input layer,bilinear interpolation is used for sampling operation and linear interpolation is performed in two directions respectively.The hidden layer and the output layer transform the input data and adjust the weights between neurons and the threshold value of each functional neuron according to the training data.Finally,the results are output through the output layer,and the parameters of the neural network are dynamically adjusted according to the error between the output layer results and the real results.By adjusting the connection strength between the input node and the hidden node,the connection strength between the hidden node and the output node and the threshold,the error decreases along the gradient direction.After repeated learning and training,the network parameters corresponding to the minimum error are determined.We use dropout to randomly ignore some neurons during training.This makes the network more robust to noise and input changes.
5.2 Adversarial Training
The adversarial training is an effective technique of local balancing.The results show that the classification performance of the model for legitimate samples and counter samples is gradually improved,and the model has higher robustness and can more effectively defend against counter attacks.The key step of adversarial training is to start from the input data points and transform them by adding small disturbances.The disturbance should be in the opposite direction and the model output of disturbance input should be different from that of non disturbance input.After finding the anti disturbance and transformation input,the weight of the model is updated,and the loss is minimized by gradient descent.
We use neural network to realize the adversarial training.The activation function is applied by inputting to the network and probability score.In order to produce adversarial disturbance,we start with random disturbance and make it unit norm.The output of the disturbance input will be to calculate the Kullback-Leibler (KL) deviation from the input and the disturbance input.The KL difference between the two output distributions should be the largest.We use this fixed function because we want to keep it fixed in the back propagation.We set the norm to a smaller value,which is the distance we want to go in the direction of adversarial training.
We need to add a loss to the model,which will damage the model and make it have a larger KL deviation compared with the output of the original input and disturbance input.The goal of adversarial training is to maximize the output before and after disturbance.In the classification task,loss uses symmetric KL divergence.
VI.EVALUATION
We introduce the implementation and evaluation of the proposed malicious user detection method based on Ensemble feature selection and adversarial training (EFA).This method not only uses the statistical characteristics,but also uses the behavior and network characteristics.By calculating the sum of its decision coefficients,we obtain the importance of different features to the target and the best feature combination.When the learning process depends too much on the training data,over fitting will occur.To prevent this,we exploit cross validation to retain the best performance features on the basis of recursive feature elimination.The training data is divided into k classes.The training process is executed k times.In each case,the k-1 class is regarded as training and the other classes is regarded as test.Each time the class is changed.We utilize actual datasets to perform the implementation.Then we compare the evaluation results with other methods based on standard evaluation criteria.
6.1 Datasets
6.1.1 Social Datasets
Social Datasets are collected from the real social network data set tagged.com.Tagged.com is a social networking site founded in 2004.The website aims to encourage users to meet new friends who share common interests and hobbies.Users can find friends,play games,share personality tags,give virtual gifts and chat in real time.Fakhraei et al.Released the data set at the top international conference sigkdd-2015,which contains the basic identity information of 5607447 users after implicit processing and 858247099 interactive records under seven kinds of relationships within 10 days.The data set contains user basic information and a large number of user interaction information.User basic information includes user ID,gender,age,and tag information representing normal or malicious users.User interaction information data includes the date of record occurrence,user information and relationship attributes of initiator and receiver.
6.1.2 Communication Datasets
Communication Datasets are obtained by Communication Network.The communication data set comes from the CTU malware data set,which contains hundreds of different malware communication samples.Only those communication pairs whose number of streams reaches a certain threshold are selected as samples.CTU malware data set is randomly divided into labeled samples and unlabeled samples.The communication samples we use are expressed in NetFlow format.All NetFlow records between two communication nodes are aggregated into a communication pair,and each communication pair represents a sample data item.The sample data items in the form of network flow sequence can not be directly input into the deep learning algorithm.The coding method based on the idea of spatial pyramid pool is adopted to apply the heterogeneous communication data to our model.
6.2 Hyperparameter Analysis
In order to study the influence of feature parameters on marker accuracy,experiments were carried out with feature parameters of 3,5,10,15,30,45 and 50 in different marker sample proportion datasets.Under the same characteristic parameters,the accuracy generally increases with the increase of the number of samples.In the overall trend,the accuracy decreases with the increase of feature parameters,and the feature parameters within 10 can get better performance.In order to study the sensitivity of neural network parameters,we set the neural network parameters as 0.001,0.005,0.01,0.05,0.1,0.5 and 1.0 respectively,and carried out the corresponding experiments.When the characteristic parameters are determined,the neural network has no obvious rising or falling rule,and it shows a changing trend on the whole.When the parameter is 0.005,better marking accuracy can be obtained.The shallower the network layer of feature layer,the stronger the universality of feature.The deeper the network layer of feature layer is,the stronger the correlation between feature and specific learning task is.The shallower the feature layer is,the better,and the deeper the feature layer is,the better.Three feature layers get the best labeling effect under the dataset.
6.3 Detection Performance Experiment
6.3.1 Baseline
We use Random forest model,Bayesian statistics model,support vector machine model,K nearest neighbor method model,linear discriminant analysis model,classification regression tree model to evaluate the performance of malicious user detection with feature learning.
(1)Random Forest Model,RF
Random forest model is a kind of tree based integration.Each tree depends on a set of random variables,and the final result is voted by all trees.As an integrated algorithm,random forest has the advantages of fast running speed and strong anti fitting ability.Because each sampling method is random,some samples will be extracted many times,while some samples will never be extracted.These samples are called out of bag data,which can be used to estimate the generalization error,correlation coefficient and strength of random forest.
(2)Bayesian Statistics Model,BS
Bayesian Statistics model selects an appropriate probability density of parameter distribution,selects a probability distribution model,and calculates the posterior distribution to update the cognition of parameter distribution after observing the data.Bayesian statistics not only uses model information and data information,but also makes full use of prior information.Bayesian model not only uses the previous data information,but also adds the decision-maker’s experience and judgment information,and combines the objective factors and subjective factors,so it has more flexibility.In addition to the small number of parameters to be estimated,it can also reflect the advantage of error rate.However,the premise of the model is that the features are independent of each other.
(3)Support Vector Machine,SVM
The support vector machine model is a kind of generalized linear classifier which classifies data by supervised learning.Its decision boundary is the maximum margin hyperplane of learning samples.Support vector machine uses the hinge loss function to calculate the empirical risk,and adds a regularization term to the solution system to optimize the structural risk.
(4)K Nearest Neighbor model,KNN
The K nearest neighbor model uses K categories of data closest to the data to be discriminated to determine the category of the data to be discriminated.The nearest neighbor model calculates the Euclidean distance between the object to be tested and each sample point in the training set,sorts all the distance values above,and selects K minimum distance samples to predict the classification of samples.The principle of this method is simple and easy to implement,but it needs to save all data sets
(5)Logistic Regression Model,LR
Logistic regression model assumes that the dependent variable obeys Bernoulli distribution and introduces nonlinear factors through sigmoid function,so it can easily deal with the problem of binary classification.
(6)Linear Discriminant Analysis Model,LDA
Linear discriminant analysis model tries to project the sample onto a straight line to make the projection points of the same kind of samples as close as possible,and then determines the category of new samples according to the position of the projection points.
(7) Classification and Regression Tree Model,CART
The classification and regression tree model is composed of a root node,several non leaf nodes and leaf nodes from top to bottom.The root node is the vertex of the decision tree.The root node and non leaf node are used to divide the data subset,and the leaf node is located at the bottom of the decision tree structure,which is used to identify the sample label.When the sample to be predicted falls to a leaf node,the class with the largest category of all samples in the leaf node will be output.The generation of decision tree is the process of Constructing Binary Decision Tree recursively.
6.3.2 Evaluation Index
According to the results,the number of malicious users,the total number of users available for detection and the number of candidate malicious users are counted.TP represents the number of malicious users correctly classified,FN represents the number of malicious users wrongly classified as normal users,FP represents the number of normal users wrongly classified as malicious users,and TN represents the number of normal users correctly classified.
We calculate the precision rate as follows.
We calculate the recall rate as follows.
The number of negative samples is far less than the number of positive samples in some research problems,so as to avoid the traditional experimental evaluation index misjudging the experimental results due to the imbalance of sample data.We introduce F1 measure,which is a comprehensive index based on precision and recall,and can effectively evaluate the classification effect of unbalanced data sets.The level of F1 measure can indicate the detection accuracy of malicious users.We calculate F1 measure as follows.
6.3.3 Results
As shown in the Figure 5,Figure 6 and Figure 7,our scheme has achieved the best detection performance,which reduces the complexity of the model to a certain extent.It enhances the flexibility of the model and verifies the effectiveness of the feature selection performance.Obviously,ensemble feature selection plays an important role in distinguishing normal users from abnormal users.On the one hand,redundant features increase the complexity of data extraction and collation.On the other hand,it affects the detection performance of the model,which is helpful to find the significant differences between normal users and malicious users in feature preference patterns.
We construct an unbalanced dataset by retaining all normal users and randomly eliminating malicious users in proportion.We train and test the results in the above data sets and detect the accuracy,recall rate and F1 Measure in the unbalanced datasets.The detection performance in the unbalanced datasets is shown in the Figure 8,Figure 9 and Figure 10.The performance of detecting malicious users in unbalanced data sets is even better than that in balanced datasets,which proves the excellent ability of integrated learning to deal with unbalanced data.
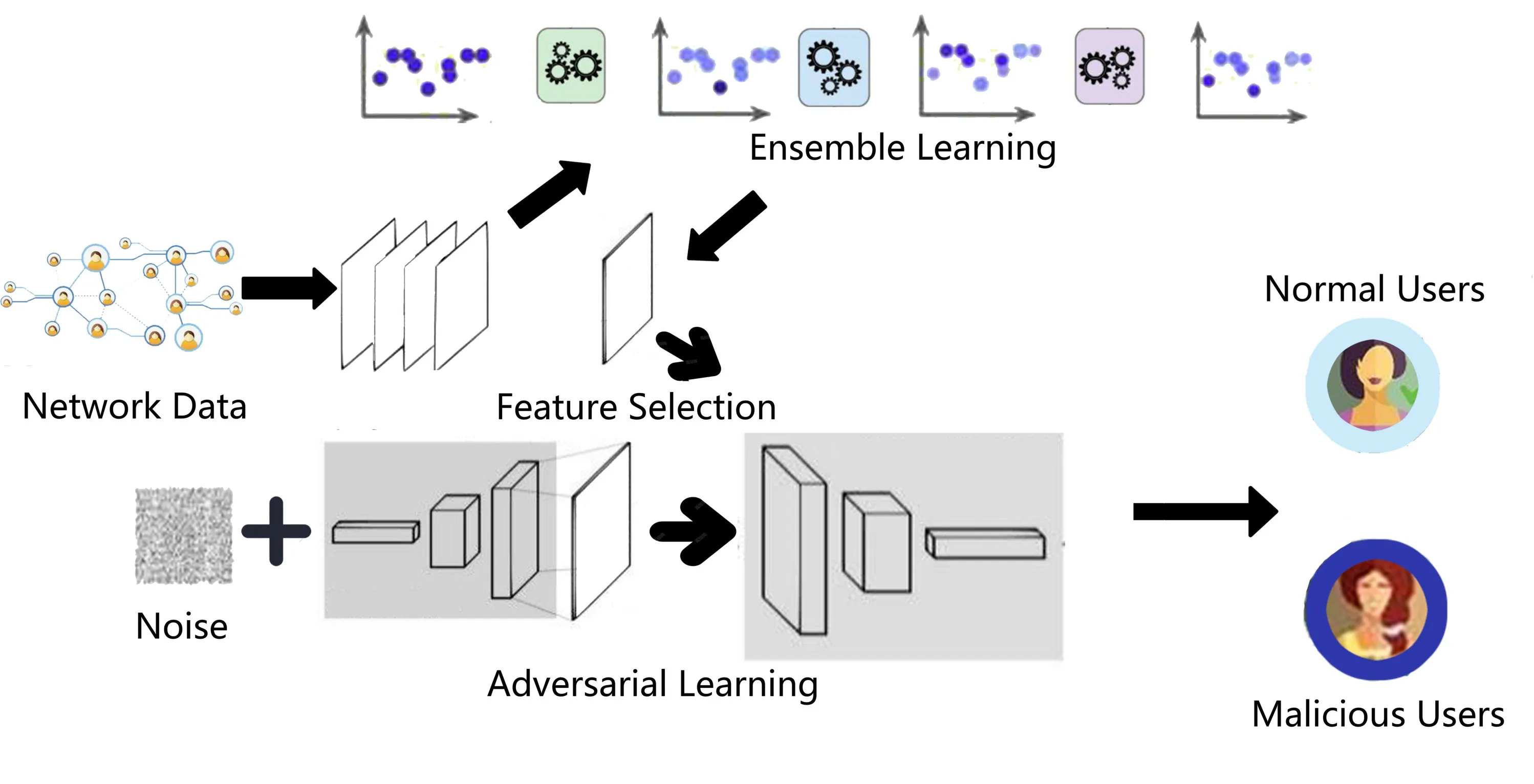
Figure 1.The overview of the malicious user detection model.

Figure 2.Recursive feature elimination with support vector machine.
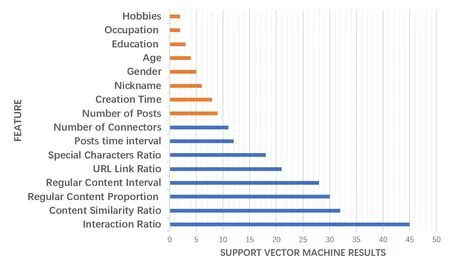
Figure 3.Support vector machine results.
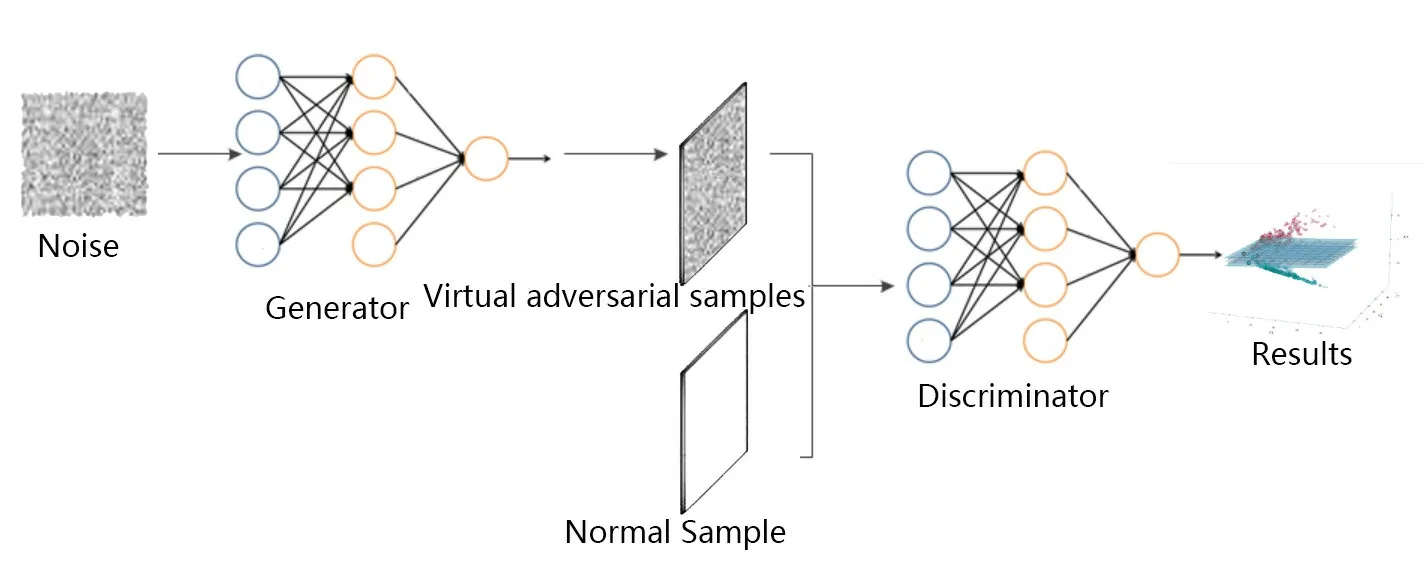
Figure 4.The neural network model based on adversarial training.
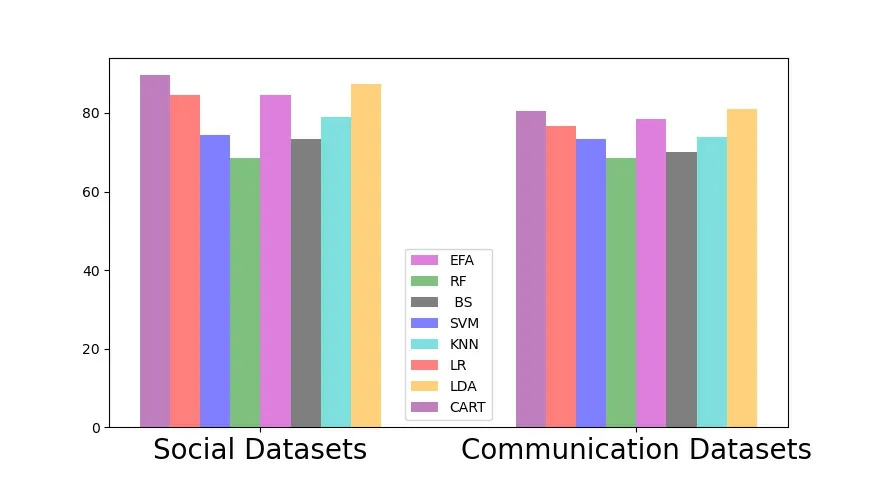
Figure 5.Comparison of detection performance on precision index.
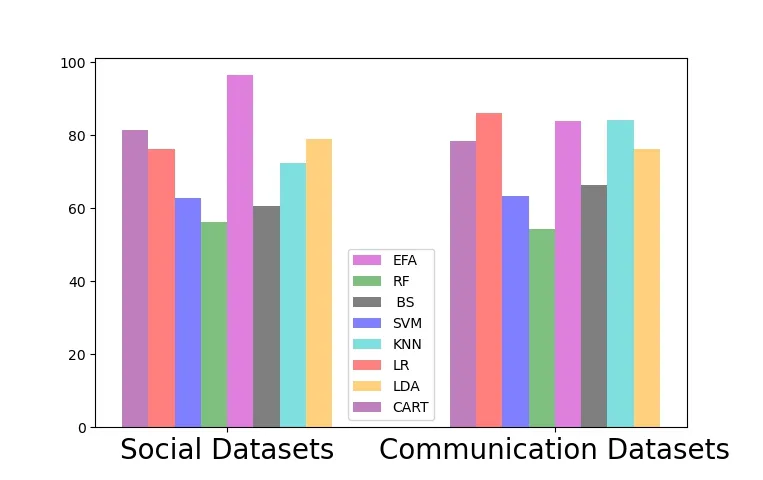
Figure 6.Comparison of detection performance on recall index.
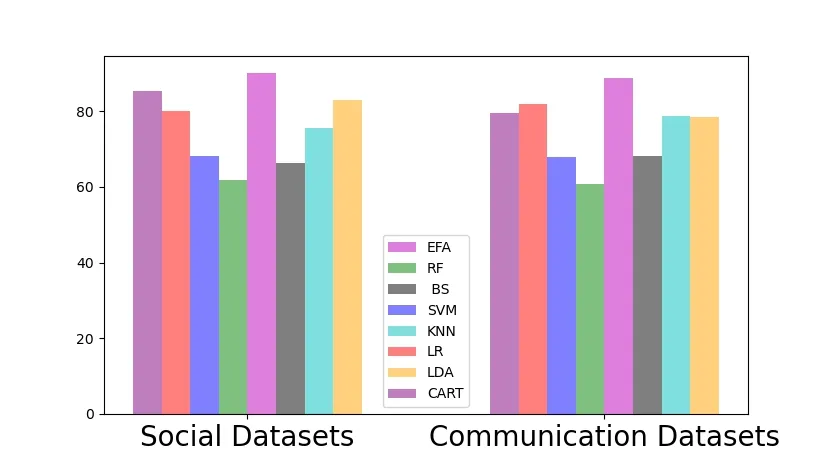
Figure 7.Comparison of detection performance on F1 measure index.
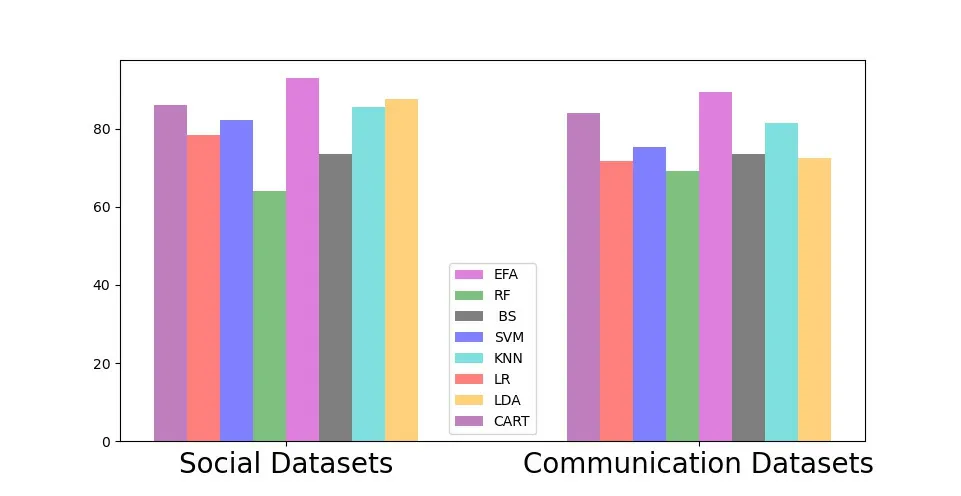
Figure 8.Comparison of detection performance on precision index in the unbalanced dataset.
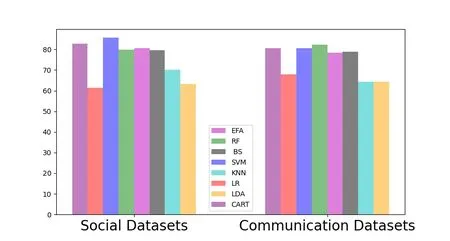
Figure 9.Comparison of detection performance on recall index in the unbalanced dataset.
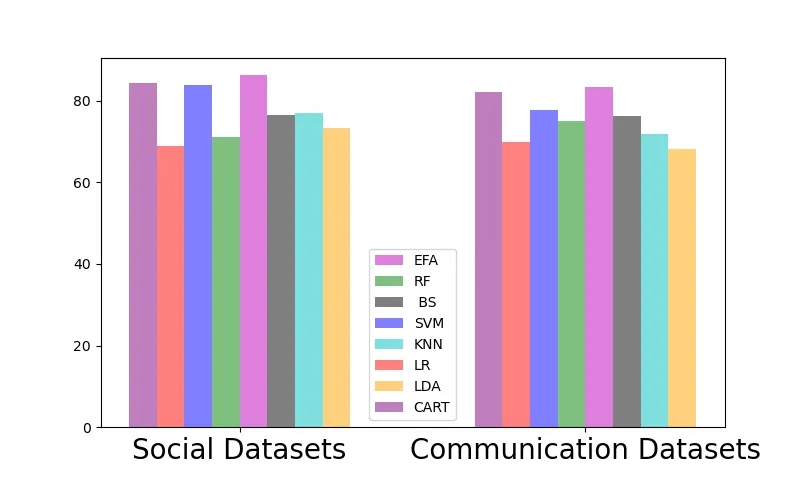
Figure 10.Comparison of detection performance on F1 measure index in the unbalanced dataset.
6.4 Neural Network Performance Experiment
6.4.1 Baseline
We use multi-layer perceptron,convolutional neural network,cyclic neural network,long-term memory network,bidirectional long-term memory network to evaluate the accuracy performance of neural network.
(1)Multilayer Perceptron,MLP
The multilayer perceptron takes a feature vector as an input,transfers the vector to the hidden layer,and then calculates the result through the weight and excitation function,and transfers the result to the next layer until finally it is transferred to the output layer.It calculates and learns the weight,synapse and neuron of each layer.Multi layer perceptron solves the XOR problem by combining multiple perceptrons to realize the segmentation of complex space.
(2)Graph Convolution Network,GCN[47]
The graph convolution network is a kind of feedforward neural network with convolution calculation and depth structure.It has the ability of representation learning,and can classify the input information according to its hierarchical structure.The convolution kernel parameter sharing in the hidden layer and the sparsity of inter layer connections of graph convolution network make it possible for convolution neural network to dot features with less computation.
(3)Recurrent Neural Network,RNN
The recurrent neural network is a kind of recurrent neural network which takes sequence data as input,recurses in the evolution direction of sequence,and all cycle units are connected by chain.Recurrent neural network has memory,parameter sharing and Turing complete,so it has certain advantages in learning the nonlinear characteristics of sequence.
(4) Long Short Term Memory Network,LSTM[48]
The core components of long short term memory network play a role of limiting information.There are some gate structures to filter and restrict information,so that the recorded information can be passed on,and the information that should not be recorded will be stuck by the gate.Through this structure,the long-term dependence problem can be solved,so that the network can remember long-term information,In this way,the later and early information can also play a role in the later network output.
(5) Bi-Directional Long Short Term Memory Network,BiLSTM[49]
The basic idea of bi-directional long short term memory network is to propose that each training sequence forward and backward is two recurrent neural networks.This structure provides complete past and future context information for each point in the input sequence of the output layer.
6.4.2 Evaluation Index
The area under the curve (AUC) is an important criterion to determine the classifier efficiency.The area under the curve represents the area under the working characteristics of the classifier.The larger the value of the classifier,the higher the efficiency of the final classifier.The area under the curve represents the output reliability of a given classifier for different data sets.First,the scores are sorted from large to small,and then the rank of the sample corresponding to the largest score is N,the rank of the sample corresponding to the second largest score is N-1,and so on.Then we add the rank of all positive samples,and subtract the M-1 combination of two positive samples.What we get is how many pairs of positive samples have a score greater than that of negative samples.And then divide by M×N.
6.4.3 Results
The neural network performance is shown in the Figure 11.Our improved neural network reduces the weight of irrelevant features by learning among neurons,and can learn the hidden information between redundant features,which is very helpful to improve the accuracy of the model.In addition,we extend the receptive domain of local structure,learn the dependence between feature preferences,and reduce the detection bias caused by data imbalance.This improves the representation ability of neural network and improves the reliability of detection.
6.5 Regularization Performance Experiment
6.5.1 Baseline
We evaluate the performance of neural network loss optimization using several regularization methods such as norm regularization and local distribution smoothing regularization.
(1)Norm Regularization,NR
Norm Regularization adds a loss term to reduce the L1 norm or L2 norm of the weight matrix.Smaller weight values will lead to simpler models,which are not easy to over fit.The L1 norm represents the total absolute difference between the original sample and the counter sample.The L2 norm represents the square difference between the original sample and the counter sample.
(2)Local Distribution Smoothing,LDS
Local Distribution Smoothing is defined as the smoothness of the model output distribution relative to the input.The artificial data points are generated by applying small random disturbance to the actual data points.Then,the model is encouraged to provide similar outputs for real and disturbed data points,and the smoothness of the model distribution is rewarded.It is also an invariant of the parameters on the network,which only depends on the output of the model.A smooth model distribution should be helpful to the generalization of the model,because the model will provide similar output for invisible data points,which are close to the data points in the training set.Some studies show that making the model robust to small random disturbances is effective for regularization.
6.5.2 Evaluation Index
The precision,recall and F1 measure indexes of different regularization methods to detect malicious users can indicate the stability of regularization methods.The hit rate can indicate the reliability of the method.The higher the hit rate,the lower the reliability of the positive method.
6.5.3 Results
The regularization performance is shown in the Figure 12.As the training error of the network is against the training loss,the regularization term is introduced into the error function,which makes it difficult to over fit.It can make the neural network adapt to the abnormal situation of misclassification,reduce the influence of data noise.It does not need to set the domain knowledge in advance,which helps to enhance the generalization ability of the neural network and improve the stability of detection.
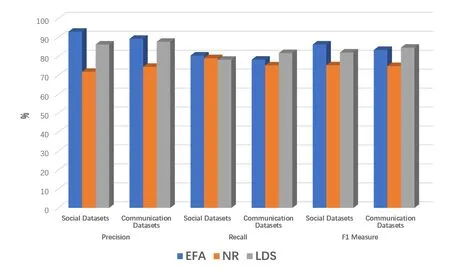
Figure 12.Comparison of regularization performance.
In order to verify the effectiveness of anti attack,the training set is composed of real data set and data set with anti disturbance.There are several types of disturbances.
(1)Random Users Attack
Random users attack refer to randomly choosing users to inject trust relationship among all existing users in the system.
(2)Important Users Attack
Important users attack refers to attacking the users who have great influence in the system in order to increase the influence of the attacke.
(3)Target Users Attack
Target user attack refers to attacking the users who helps to improve the pertinence of the attack.
The specific parameters in the experiment are set as follows.The attack loading rate is 5%,the selection rate is 5%,the relationship attack strength is 0.1%,and the attack rate of important users is 0.1%.
The attack performance is shown in the Figure 13.The adversarial training is an effective technique of local balancing.The results show that the classification performance of the model for legitimate samples and counter samples is gradually improved,and the model has higher robustness and can more effectively defend against counter attacks.
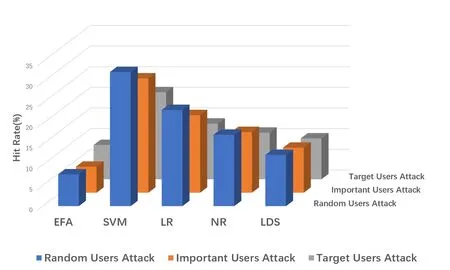
Figure 13.Comparison of three attacks performance on hit index.
VII.CONCLUSION
Users make decisions with the help of various kinds of information,which leads to a large number of false and fraudulent information.Malicious users who spread spam information seriously endanger the information security of users and destroy the experience of users.We use ensemble feature selection technology to select the best feature from the existing features to reduce the dimension of the dataset.We analyze implicit preference of features to describe users from different perspectives.We discuss an effective regularization technique called adversarial training to optimize the neural network.The adversarial training is to learn general relationship invariance features,which can bridge the gap between related relationships.The implicit knowledge is adapted to the target relationship to improve the prediction performance.By integrating and regularizing the neural network parameters,we improve the robustness and representation ability of the neural network.This technology can be used in link prediction,relation extraction,question answering,language understanding,relation data analysis and recommendation.
In the future work,we will commit to the sample in the local feature space for micro disturbance,the application of virtual anti trapezoidal network using random noise.We train the decoder to assimilate the output of each layer.We can use normalized information maximization to maximize the mutual information between input and model output.However,the research of these schemes is in the initial stage,which has the characteristics of large amount of computation and high complexity.Secondly,on the premise of ensuring the high accuracy of the model,it is worth studying how to improve the interpretability and traceability.Third,the training set or architecture parameters of the target model can be obtained maliciously by attackers.Privacy attack is easy to be used by the malicious party to restore the data provided by other data sources,which plays a role in the reasoning stage.However,in order to alleviate this problem,how to add some randomness to the deep learning algorithm needs to be studied.
ACKNOWLEDGEMENT
This work was supported in part by projects of National Natural Science Foundation of China under Grant 61772406 and Grant 61941105.This work was supported in part by projects of the Fundamental Research Funds for the Central Universities and the Innovation Fund of Xidian University under Grant 5001-20109215456.

- China Communications的其它文章
- SR-DCSK Cooperative Communication System with Code Index Modulation: A New Design for 6G New Radios
- Sparsity Modulation for 6G Communications
- Sparse Rev-Shift Coded Modulation with Novel Overhead Bound
- Reconfigurable Intelligent Surface-Based Hybrid Phase and Code Modulation for Symbiotic Radio
- Model-Driven Deep Learning for Massive Space-Domain Index Modulation MIMO Detection
- Modulation Recognition with Frequency Offset and Phase Offset over Multipath Channels