
基于生成对抗网络模型的小样本PM2.5预测
2023-11-02 12:34汪祖民张嘉峰胡玲艳邹启杰盖荣丽
计算机应用与软件 2023年10期
汪祖民 张嘉峰 胡玲艳 邹启杰 盖荣丽 刘 艳
(大连大学信息工程学院 辽宁 大连 116622)
0 引 言
中国经济的快速发展和城市化进程的加快,伴随着高能耗和污染物的过度排放,对空气造成了严重污染,阻碍了城市地区的可持续发展[1-2]。尤其在京津冀以及周边地区,由于重化工产业的高度聚集,该范围内主要能源利用方式以煤炭为主,货物运输方式以公路汽车运输为主,这在一定程度上导致了大气污染物的排放量大幅上升。PM2.5是主要的空气污染物,是现阶段中国雾霾治理的重点,对人体健康具有较大的危害,成为了公众较为关注的问题[3]。PM2.5的浓度受到城市空间形态、土地利用布局和不利气象因素等影响[4],长期暴露在受污染的大气中会增加患心血管和呼吸系统疾病的风险[5]。为此,中国政府在大多数城市设立了空气质量监测站,并用于实时检测PM2.5和其他空气污染物浓度。然而,由于设备昂贵,政府不可避免地需要承担较大的财务负担。除了对PM2.5进行监测以外,对未来空气质量预测的需求也越来越大。因此,对PM2.5浓度进行在线预测对于空气污染控制和预防空气污染带来的健康问题至关重要。尤其是如果能在小样本下对PM2.5浓度实现较精准的预测,很大程度上将会减少政府的财政支出,并有利于各地区的环境治理,具有较高的实用价值。
1 研究现状
目前,PM2.5的预测方法主要有模型驱动和数据驱动的[15]。模型驱动的方法主要是通过建立数学统计模型对PM2.5浓度进行估计,数据驱动的方法主要是通过利用神经网络、支持向量回归等方法预测PM2.5浓度。随着近年来人工智能与机器学习的发展,人工神经网络(ANN)、支持向量回归(SVR)等方法已较为广泛地应用于空气污染物浓度的预测[6]。目前有利用机器学习的方法用于预测区道路、工厂和公园的空间特征预测PM10和二氧化氮的浓度[7]的相关研究,也有相关研究利用周边监测站的观测数据,使用SVR模型预测目标站的PM2.5浓度[8]。虽然上述方法都利用了影响污染物浓度的空间特征,但没有考虑空气污染物的时间相关性和PM2.5的时延特征。由于大气环境的动态特性,循环神经网络(RNN)可以处理任意输入序列,从而保证了学习时序的能力,特别适合模拟空气污染物分布的时间演化。Ong等[9]使用气象数据作为输入参数,输入至RNN中来预测PM2.5浓度。Feng等[10]结合随机森林(RF)和RNN对中国杭州未来24小时空气污染物PM2.5浓度进行了分析和预测。然而,传统RNN存在较长时间滞后,并且可能会出现梯度消失和梯度爆炸等问题,这些基于RNN的方法也没有充分利用空间特征。此外,特征形成的状态在不同时间对未来PM2.5浓度也会产生不同的影响[11]。现有的研究较少考虑过去不同时期的特征状态对空气污染物的影响,只是提取了历史数据的时间相关性特征。目前,在小样本下数据驱动的方法在预测PM2.5浓度时准确率较低,并且相关研究较少。为了解决上述难题,本文提出了基于生成对抗网络模型的PM2.5的在线预测方法,利用生成器和判别器之间的博弈过程,建立了以生成器预测为主,判别器判别为辅的新型PM2.5的预测模型,并在生成器中加入了长短期记忆网络用于提取输入数据的时序特征,相比于其他的基于数据驱动的PM2.5预测方法,本文提出的方法在小样本数据集上具有更高的准确率,并具备较好的应用价值。
2 相关方法分析
GAN包含了两个网络模型[12],分别是生成器G和判别器D,两者处于对抗博弈的状态。在对抗的过程中,生成器可以扮演着一个骗子的角色,生成与真实数据相似的数据,通过生成假的数据去欺骗判别器。而判别器则充当着法官的角色,将真实数据与生成数据进行区分。理论上来说,判别器和生成器可以达到纳什均衡,即判别器无法区分真实数据和判别数据,生成器也生成接近于真实样本的数据。基于这一原理,我们提出了基于GAN的PM2.5的预测模型。
GAN的目标函数V(G,D)如式(1)所示。
V(G,D)=Ex~Pdata[logD(x)]+Ez~Pz[log(1-D(G(z))]
(1)
式中:z为服从于先验分布;Pz为随机噪声;x为服从真实数据分布Pdata的真实数据;D(x)表示真实数据x在判别器下的判别结果为真的概率;D(G(z))为G(z)在判别器下的判别结果为真的概率。
在G的训练过程中,G尽可能地使D(G(z))趋于1,即让目标函数尽可能地取到最小值。在D的训练过程中,D尽可能地使D(G(z))趋于0,让D(x)趋近于1,即让目标函数尽可能地取到最大值。
3 生成对抗网络预测模型
3.1 预测模型架构
通过构建的生成器和判别器模型,本文提出了基于GAN的PM2.5预测模型,该模型如图1所示。时间序列数据输入到生成器中,生成器输出PM2.5的预测值。PM2.5的真实值和生成器的预测值一起输入到判别器中,判别器通过比较生成器的预测值与真实值的真假,然后将误差反传至生成器。定义生成器G的损失和判别器D的损失来优化目标函数。在构建生成器的损失函数时,除了原始GAN的生成器损失,还加入了MSE损失函数。生成器和判别器的损失函数如式(2)-式(5)所示。
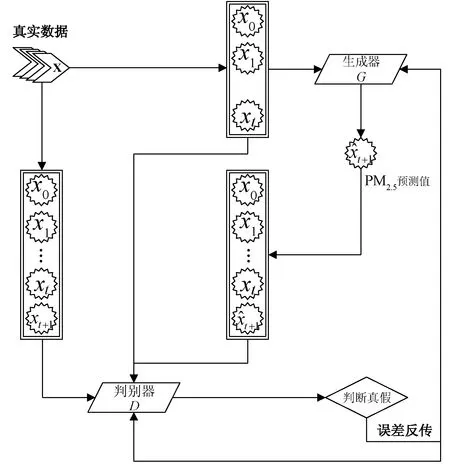
图1 基于GAN的PM2.5预测模型
(2)
(3)
(4)
Gloss=λ1gMSE+λ2gloss
(5)
式(5)中:判别器G的损失函数由gMSE和gloss两部分组成;λ1和λ2为手动设置的超参数,考虑到gMSE和gloss在Gloss中的比重应当相同,因此λ1和λ2均为0.5。
3.2 生成器
由于LSTM[13]具有较强的时序特征提取能力,将LSTM网络加入到GAN的生成器中,换句话说,就是把LSTM作为生成器。
本文从KnowAir数据集[14]中选取了中国京津冀地区13个城市的历史空气数据。由于PM2.5中含有硝酸铵的成分,温度和硝酸铵会产生化学效应,随着温度和湿度的升高有助于硝酸铵的挥发,因此温度和湿度都与PM2.5呈正相关[16];风速与旋涡状态有助于PM2.5浓度在空气中发生水平扩散和垂直扩散,因此风速和旋涡状态都与PM2.5呈负相关[14-17];降水对于PM2.5来说呈阻力作用,会产生湿清除和向下气流,因此降水量与PM2.5浓度呈负相关[18]。利用PM2.5浓度值、时间、温度、湿度、风速、降水量和旋涡状态等数据作为输入用于预测PM2.5的浓度变化。假设输入的矩阵X={x1,x2,…,xt},X表示由t个时间点的数据,其中x1,x2,…,xt分别表示在t个时间点内的PM2.5浓度值、时间、温度、湿度、风速、降水量和旋涡状态等数据。
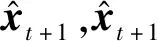
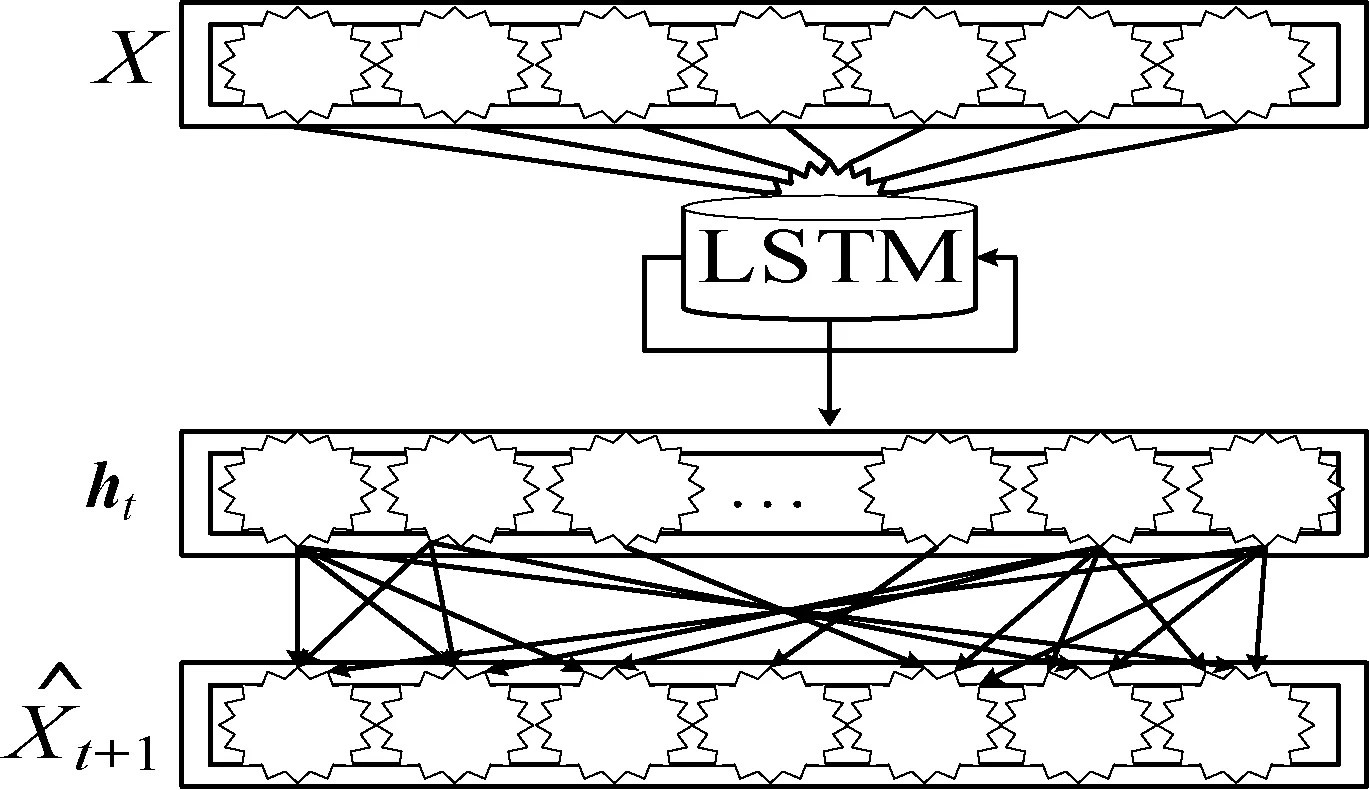
图2 PME-GAN生成器结构图
生成器的输出如式(6)和式(7)所示。
ht=g(X)
(6)
(7)
式中:g(·)为LSTM的输出,在输入为X={x1,x2,…,xt}时,LSTM的输出为ht;δ表示ReLU激活函数;Wh和bh分别表示全连接层中的权值和偏置。为了防止过拟合,加入了dropout作为正则化方法来避免过拟合的出现。
3.3 判别器
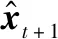
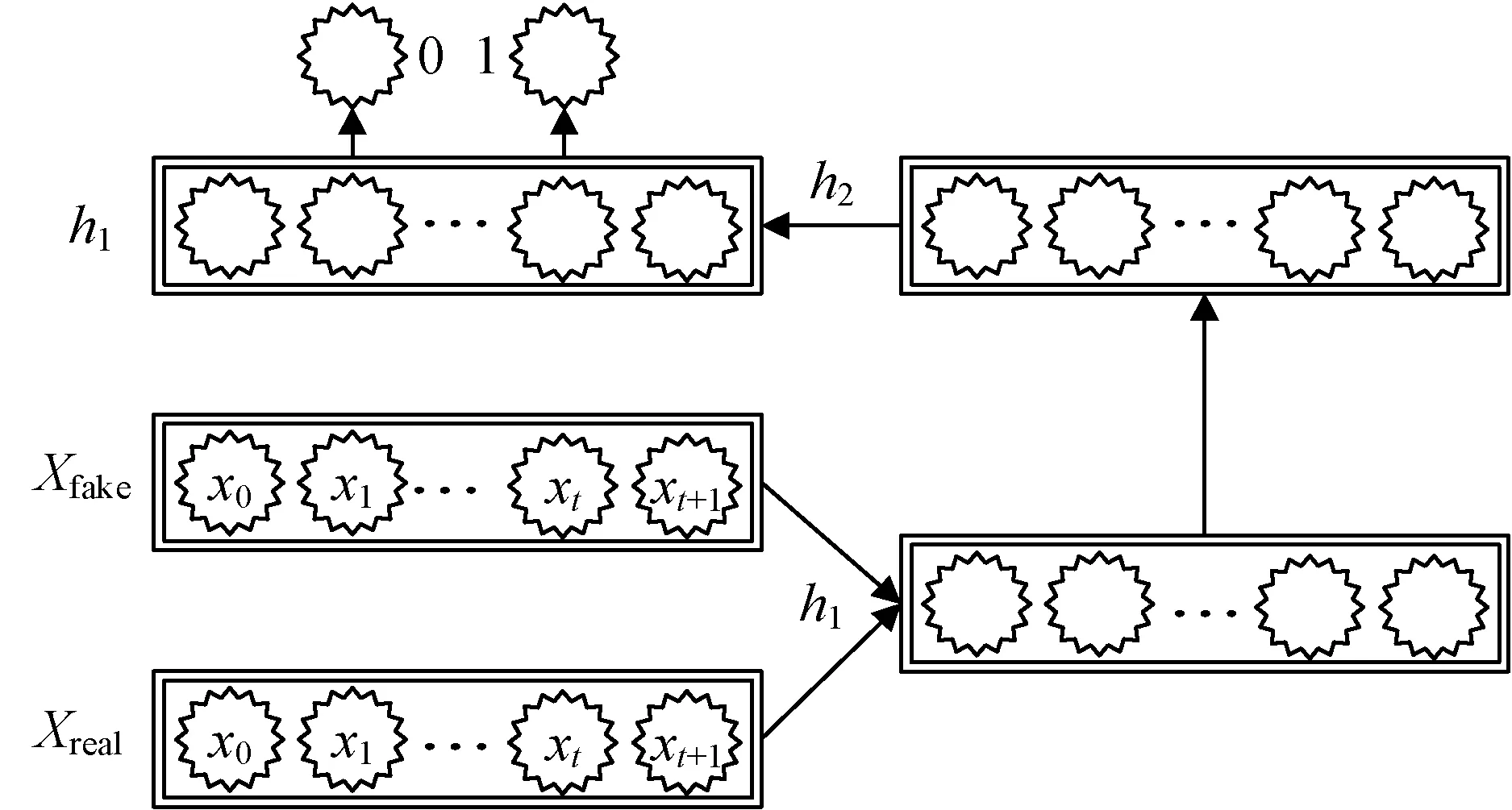
图3 PME-GAN判别器结构图
D(Xfake)=σ(d(Xfake))
(8)
D(Xreal)=σ(d(Xreal))
(9)
式中:d(·)为MLP的输出;σ为sigmoid激活函数。真实数据和假的数据输入到判别器中,最终得到一个标量,即为判别器的判别结果。
4 实验与结果分析
从KnowAir数据集[14]中选取了京津冀地区13个城市的历史空气数据,由于这13个城市均为中国空气污染较为严重的城市,且单独抽取这13个城市的数据后,获得的数据集较少,研究小样本下对PM2.5进行准确的预测具备较高的实用价值。与此同时,从13个城市的数据集中选取了2015至2018年间的空气数据。在划分数据集时,分别将2015年1月至2017年12月三年的数据用于训练,并用2018年1月至12月的数据用于测试,即训练集和测试集之比为3∶1,并对数据进行归一化处理,如式(10)所示。
(10)
式中:μ和τ分别表示X的均值和方差。
在训练PME-GAN时,为了防止出现判别器或者生成器任意一方出现局部最优的情况,判别器和生成器交替迭代,判别器每迭代一次后,生成器随后迭代一次,如此重复,直至PME-GAN的模型训练稳定为止。在实验中epochs设置为2 000,batchsize的大小为64,LSTM各层的神经元个数为8,dropout值为0.1。
在PME-GAN的训练过程中,实验中判别器和生成器的loss曲线分别如图4和图5所示。由两个loss曲线可以看出,判别器和生成器处于对抗迭代的状态,随着训练次数的增加,生成器和判别器的loss曲线不断震荡,生成器和判别器在对抗训练中得到了优化,模型变得稳固。

图4 判别器loss曲线
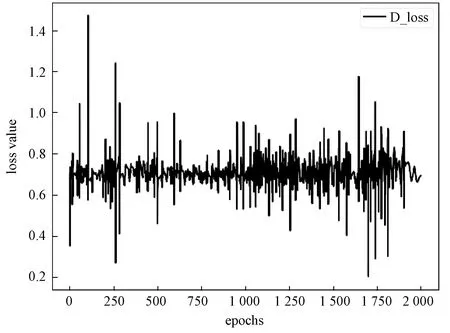
图5 生成器loss曲线
为了验证提出的方法的有效性与优越性,与其他主流的数据驱动方法做了对比实验。分别利用GRU、LSTM、CNN-GRU、CNN-LSTM四种不同的模型与PME-GAN进行实验,在保定测试集上的PM2.5预测结果如图6-图10所示。保定为京津冀的重要城市之一,由于集中供热缺乏,较多居民用散煤取暖,因此空气污染较为严重,并且单独针对保定空气污染的研究较少[19]。图6-图10可以更加清晰地呈现出各个方法的预测效果,可以看出,本文模型的实验结果要明显地优于其他4个模型,在拟合程度上,PME-GAN能够更精准地预测出PM2.5的变化趋势。由于本文只采用了京津冀地区13个城市的数据用于训练和测试,数据量较少,虽然在PM2.5的浓度值上各种方法并不能预测的很精准,但是本文的方法能够通过前三年的训练数据较为准确地预测出后一年的PM2.5变化趋势。
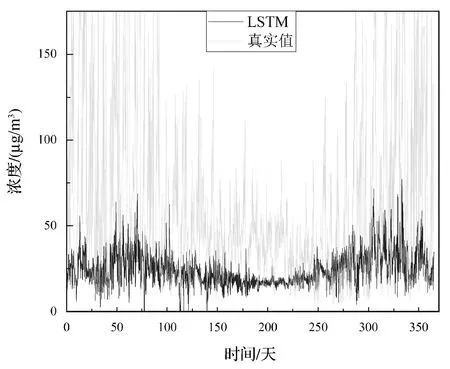
图6 LSTM方法在保定测试集的实验结果
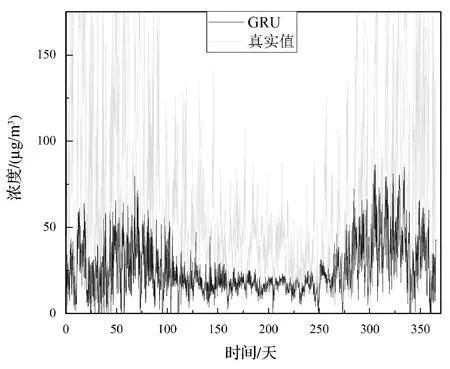
图7 GRU方法在保定测试集的实验结果
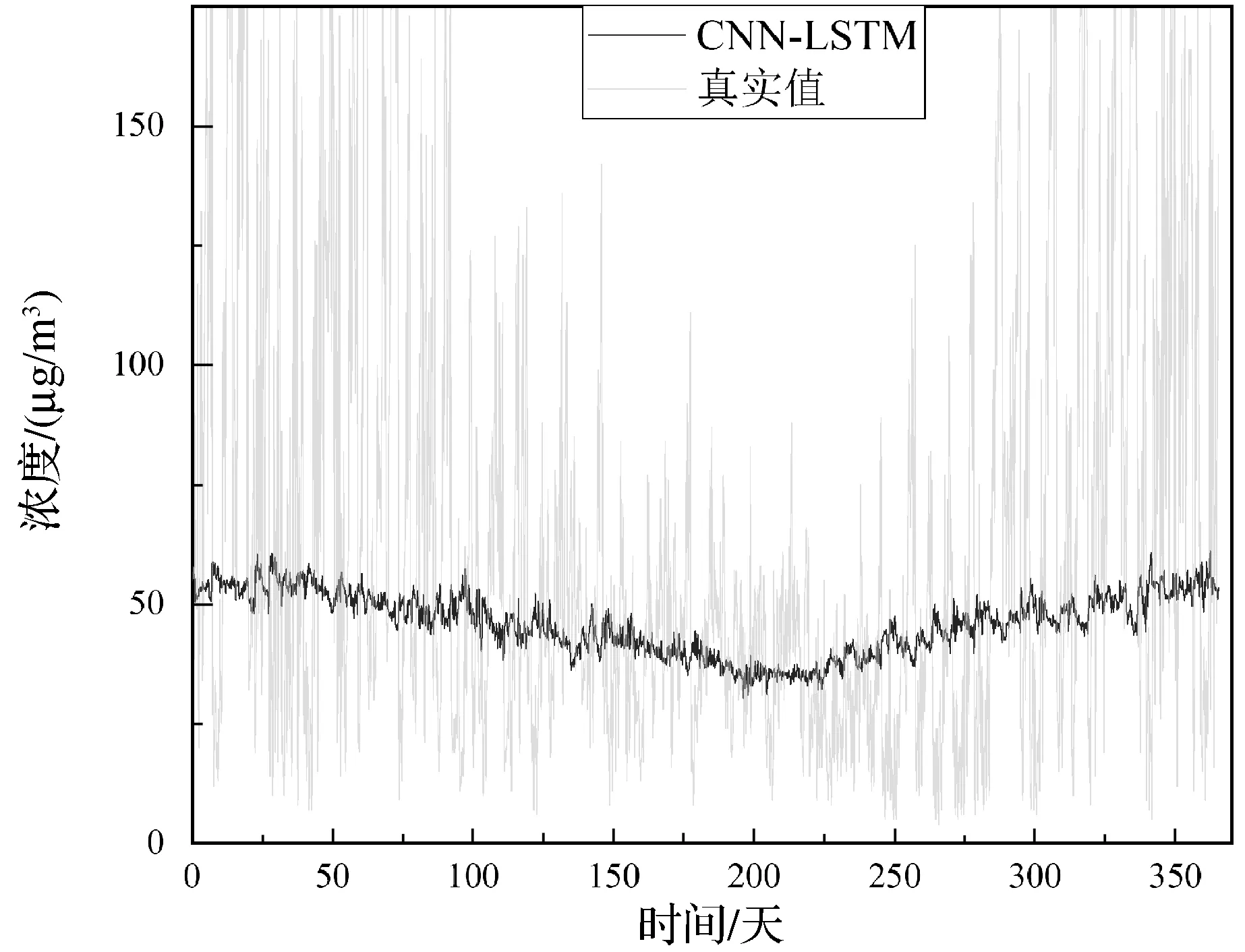
图8 CNN-LSTM方法在保定测试集的实验结果
为了更加直观地刻画出各种方法的预测准确率,本文引用了RMSE和MAE两种评价指标,用于评价各模型的预测效果,RMSE和MAE的计算如式(11)和式(12)所示。
(11)
(12)
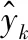
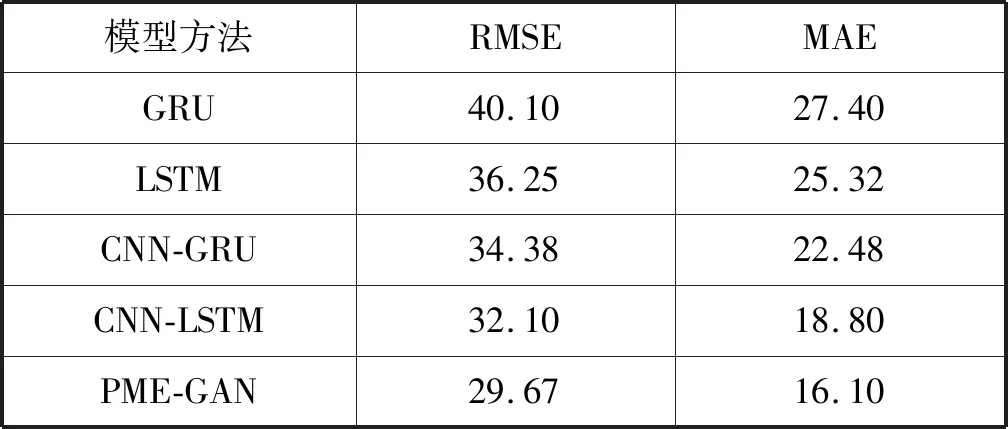
表1 不同方法在测试集上的RMSE和MAE对比(%)
通过表1中的结果,可以得出PME-GAN在5种模型中RMSE和MAE均是最小的,预测的PM2.5浓度更接近于真实的PM2.5浓度,预测的准确度要高于其他方法,充分地验证了所提出的PME-GAN模型在小样本条件下的有效性。
5 结 语
本文提出了基于PME-GAN的PM2.5预测的方法,通过利用GAN的博弈思想,在生成器中加入LSTM,提取了输入数据的时序特征,并在判别器中加入MLP,最终通过生成器与判别器的对抗训练,通过生成器对PM2.5进行预测。与基于LSTM、GRU、CNN-LSTM和CNN-GRU的PM2.5的预测方法相比,本文的方法具有更高的准确率和一定的应用价值。
虽然通过PME-GAN的PM2.5预测的方法能够对PM2.5的浓度进行有效地预测,但是预测的精度还有进一步提升的空间。基于小样本下用数据驱动的方法对PM2.5实现较高精度的预测,可利用数据增强的方法,通过现有的数据集,对原始的小样本的训练数据进行扩充,并对扩充后的样本进行筛选,将合适的样本加入到原有的训练集中,这将在一定程度上提升数据驱动的方法预测PM2.5的精度。
猜你喜欢
中国银幕(2022年4期)2022-04-07
今日农业(2021年11期)2021-11-27
环境科学研究(2021年6期)2021-06-23
环境科学研究(2021年4期)2021-04-25
少儿科学周刊·儿童版(2021年23期)2021-03-24
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
小天使·五年级语数英综合(2017年3期)2017-04-25
文苑·经典美文(2017年4期)2017-04-24
数学学习与研究(2017年3期)2017-03-09
