
基于Web技术的传染病数据可视化平台的设计与实现
2023-11-02 12:34李金玲
计算机应用与软件 2023年10期
李金玲 袁 鑫 杨 彪
(南华大学计算机学院 湖南 衡阳 421001)
0 引 言
数据可视化旨在借助于图形化手段,清晰有效地传达与沟通信息,是一种以直观方式传递抽象信息的方法,是理解复杂数据的不可或缺的工具。随着计算机技术的成熟和搜索引擎技术的发展,政府信息公开化,众包模式的兴起,人们获取和解读数据的可能性大大提高。基于数据挖掘、理解数据基础上的数据可视化,成为一个新的发展方向和突破。
可视化技术应用于传染病领域可以追溯到较早的19世纪,英国医生通过标记地图发现了霍乱的源头,帮助控制当时的伦敦霍乱疫情,这也被认为是数据可视化的应用典范[1]。随着计算机技术推动可视化技术的不断进步,许多学者开始探索面向大数据的更加多元化的传染病相关领域可视化方法。例如金思辰等[2]通过构建交互式可视分析系统,帮助用户分析疾病的时空分布,利用热力图辅助查看聚类信息,并通过案例对系统进行评估。胡雪芸等[3]利用可视化技术对肺结核疾病进行分析。吴静等[4]对传染病相关的可视化虚拟仿真实验教学进行了分析。李拓[5]对信息可视化技术在疫情中的应用案例进行分析,以提供有价值的可视化范本。新型冠状病毒疫情进一步推动了数据可视化在传染病领域的运用,我国对全球传染病疫情信息系统进行了升级,使用地图直观展示全球传染病疫情信息,实现数据可视化应用。以上的研究与实践是数据可视化在传染病相关领域的有益探索,但大部分工作主要集中在对个例疾病的可视化分析,或面向普通用户的可操作性偏弱,或仅提出相应的设计范式,缺少整合性的平台支持等。
鉴于以上的不足,本文设计基于ECharts、Three、Spark等技术的传染病数据可视化分析平台,将我国法定的甲、乙、丙三类传染病的相关信息进行集成处理,面向普通用户利用可视化技术直观地展现各传染病的相关信息。面向专业用户利用Spark等大数据技术实现传染病相关热点数据的爬取和数据的分析挖掘,提供更为全面的数据相关性参考。
1 平台设计原则
1.1 直观数据展示
面向非医学类普通用户,平台应能够通过适当的图形化处理方式,将海量、多维、复杂的传染病相关数据进行展示,使用户能够将注意力集中在最感兴趣的传染病数据信息中,轻松地浏览数据概貌,清晰地观察数据细节,多维度获取数据印象[6]。
1.2 增强数据理解
在为用户提供直观数据呈现基础之上,平台应该能够为其深入理解数据提供辅助。根据数据类别选取最恰当的图表可视化形式能够保证数据的有效展示。同时应注重时间轴、视觉属性、区域缩放、辅助参考、上卷下钻、数据联动等动态信息呈现与交互方式的有效利用,以便为用户提供灵活便捷的数据互动,从而提高对数据的深入理解。
1.3 辅助探索数据
数据呈现的交互化使辅助用户探索和发现隐含信息的重要抓手[7]。面向专业用户,平台应能够提供诸如个性化的传染病数据探索等深层次交互,允许用户通过相应的交互操作实现针对性的数据输出呈现。
2 可视化分析平台系统设计
2.1 总体架构设计
为实现数据的高效性存储、服务的分层性运行、信息的可视化分析,平台使用多元编程语言和框架技术来进行前后端交互、大数据存储。后端考虑到数据的庞大,时间的分布性明显,采用Hive数据仓库来进行大量高效率存储,采用Spark基于内存迭代计算框架进行数据分析。同时,为了进行及时和稳定的交互,使用MySQL关系型数据库对实现系统功能的数据进行存储。后端采用MVC架构风格,分离服务层、控制层、持久层,Dubbo+Springboot面向微服务架构将平台所需功能数据封装成订阅服务。前端使用Vue、ECharts、Three等框架,并设计相关请求接口,向后端服务进行数据请求,并将数据进行可视化展示。
(1) 整体技术实现。如图1所示。
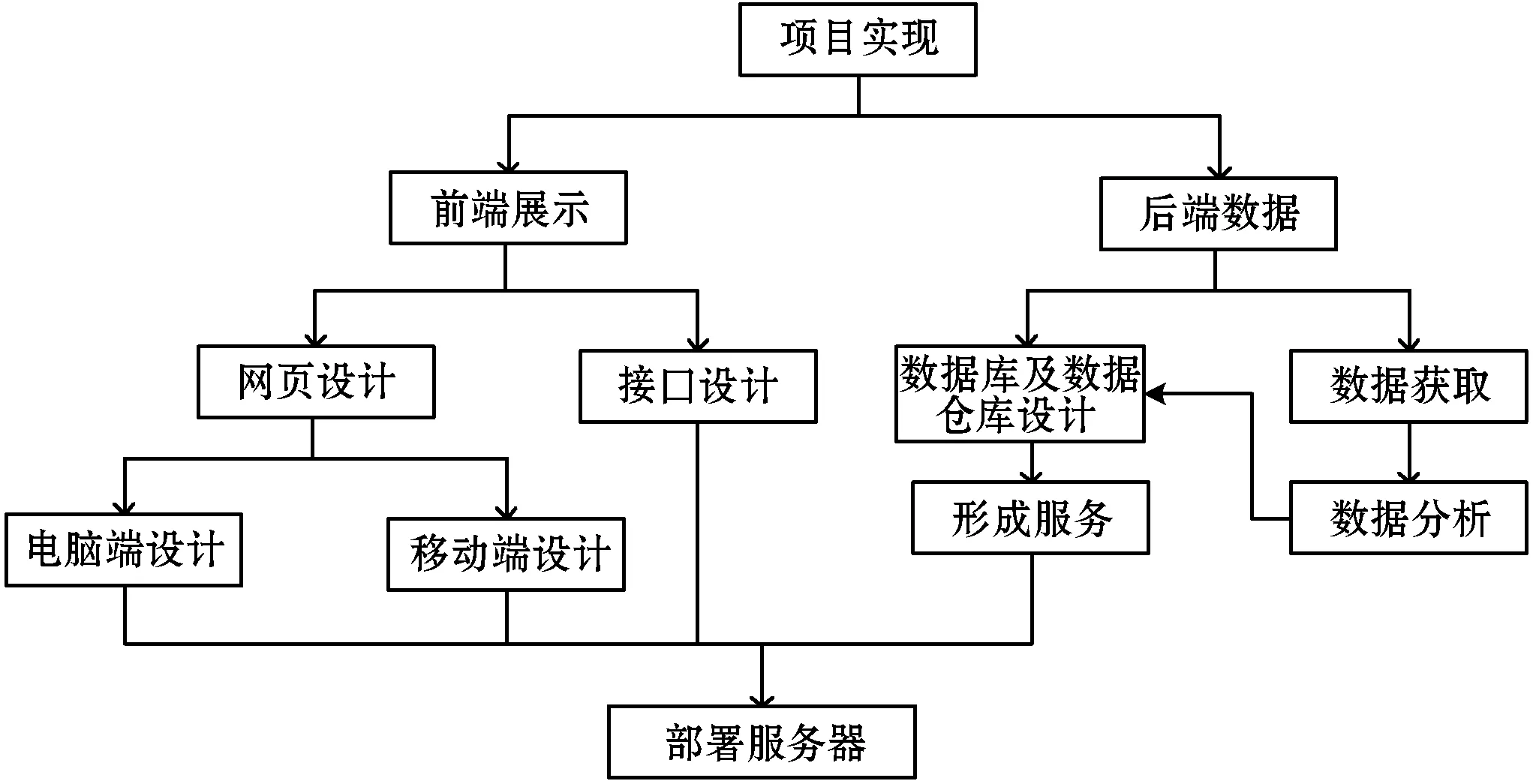
图1 平台整体技术实现
分析项目各种功能模块,以及各功能模块之间的关系,设计项目数据结构。分析各模块的子模块,以及要完成的各种详细功能,功能之间要相互关联,完成数据库建设,确立详细接口设计以及调用关系。通过后端技术,完成数据分析、数据存储,形成服务返回给前端。前端完成页面设计再通过可视化技术实现数据的渲染,同时分电脑端和移动端两部分设计,最后再部署到服务器上。
(2) 架构展示。如图2所示。

图2 平台架构
用户端通过视图层对系统界面进行访问,根据自己的需求,访问某种功能,从而向控制层发起数据请求;控制层解析请求后,向业务层发起业务访问;业务层再对持久层发起数据访问;持久层从数据库中获取对应数据,并逐层返回至系统界面。大数据分析层会从Hive中获取元数据,进行聚合分析,并将数据存于MySQL数据库中。
(3) 数据流程。如图3所示。
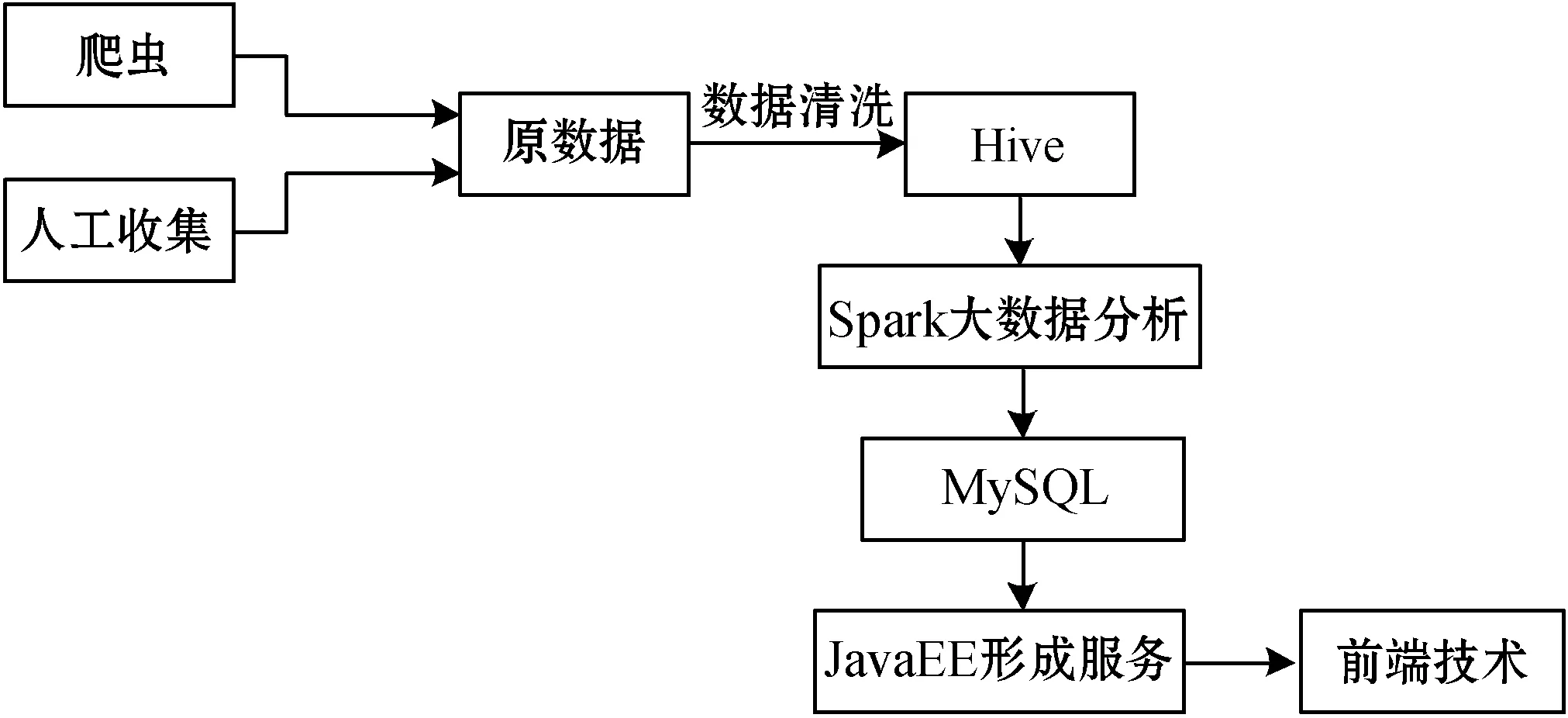
图3 平台数据流程
平台通过爬虫技术以及人工搜集的方法从各种网站信息源处获取原数据,经过数据清洗后存于Hive数据仓库。并通过大数据分析技术,建立算法模型以及分析模型,将原数据转化为本系统所需要的数据,存储于MySQL数据库中,通过JavaEE面向微服务技术形成各种服务,将数据传给前端界面,进行展示。
2.2 平台结构设计
传染病数据可视化平台一共分为三个模块:数据库、陈列馆以及诊疗室。主要功能结构如图4所示。
陈列馆包含传染病分类及其病原体相关信息,主要用于介绍法定甲乙传染病的基本信息,包括其种类数量、具体传染病病原体名称、简介、传染病传播途径、病原体3D模型以及传染病关键词信息滚动词云等。数据库涵盖历年大部分传染病的发病率死亡率以及地区发病状况,包括数据博物馆及数据调查局两部分。其中数据博物馆主要涵盖近几年来国内部分传染病的发病死亡情况,共分为四个模块。数据调查局以时间线方式串联起各类传染病的首次爆发历史背景,丰富传染病文字数据信息。诊疗室包含传染病的临床表现、预防措施以及治疗途径等基本信息。
为了使用户有更好的体验感,平台开发采用SPA(单页面应用)方式,用户在切换页面和获取数据的时候动态地更新页面和内容,不会出现白屏的闪屏的情况。同时,在各页面组件销毁前,释放其各个子组件的内存,从而提升后续浏览的速度与体验。
2.3 数据库设计
平台采用MySQL管理数据信息,主要数据库表格为传染病分类(contagion_sort)、传染病(contagion_main)、年限分布(annual_distribution)、空间分布(site_distribution)、传染病历史(contagion_hitory),如表1-表5所示。
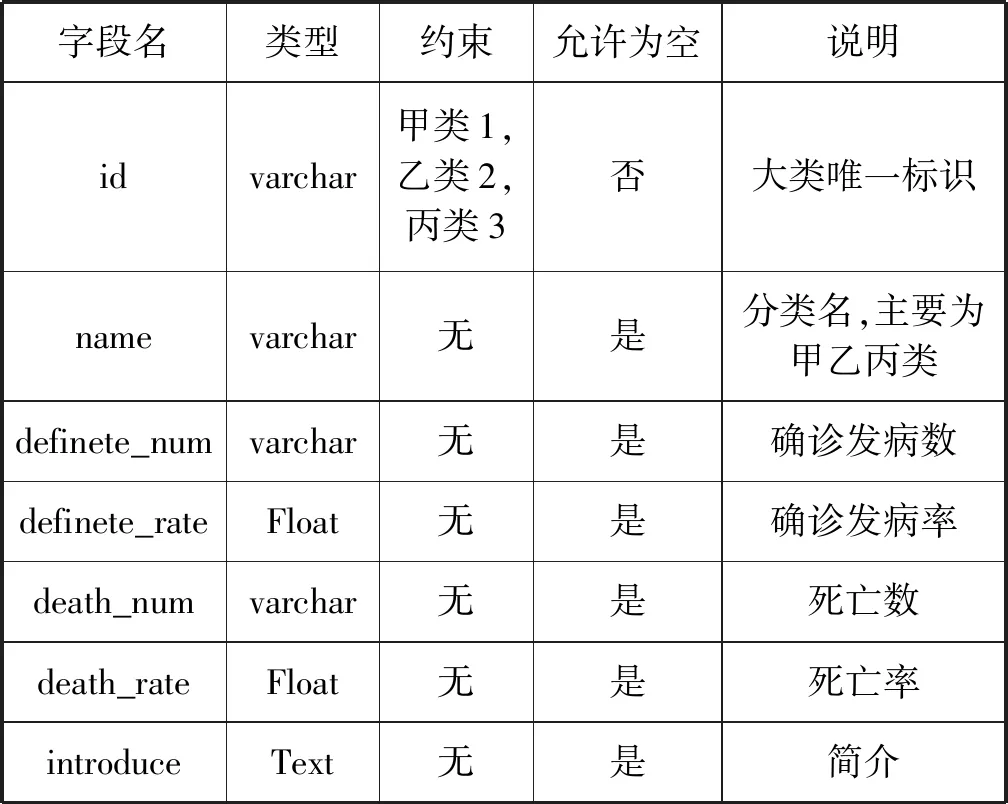
表1 传染病分类表(contagion_sort)

表2 传染病基本信息表(contagion_main)
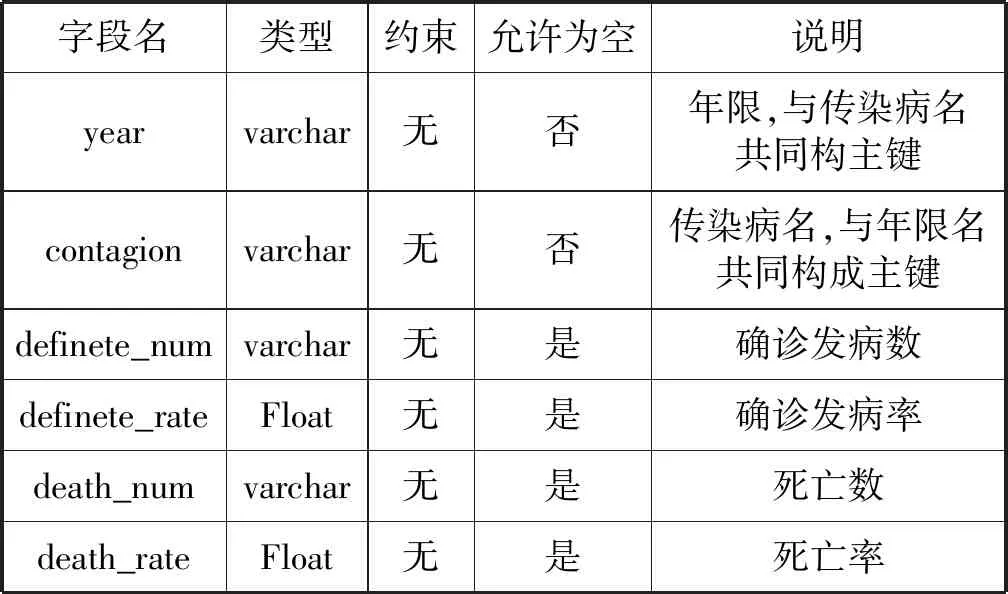
表3 年限分布表(annual_distribution)
3 可视化分析平台具体实现
3.1 相关技术
平台基于Vue、ECharts、Three、Spark、Springboot等技术,前端采用MVVM架构,是一个典型的SPA项目,后端采用mvc架构风格,基于Java面向微服务设计,Spark基于内存迭代计算框架,实现对数据的时间与空间分析,整体采用B/S结构开发实现,主要涉及如下相关技术:
(1) Vue.js:构建用户界面的渐进式JavaScript框架。Vue框架最大的特点是自底向上逐层应用[8]。Vue的核心库只关注视图层,方便与第三方库或既有项目整合。在本平台中用于构建单页面应用,并实现相应的数据绑定和组合的视图组件,整合第三方库,构建丰富的UI视图。
(2) ECharts:商业级数据图表库。ECharts是基于Java Script的开源可视化图表库[9],能够应用于PC机或移动设备上绝大部分主流浏览器,底层依赖轻量级的矢量图形库ZRender构建,提供直观、交互丰富、可高度个性化定制的数据可视化图表。在本平台中实现传染病数据的可视化,定制出丰富的可视化图表。
(3) Three.js:JavaScript编写的WebGL第三方库。提供了非常多的3D显示功能,是一款运行在浏览器中的3D引擎,利用该库可以创建各种三维场景,包括摄影机、光影、材质等各种对象[10]。在本平台中实现病原体3D模型的交互展示。
(4) Springboot:Spring体系框架,可以简化Spring应用程序的创建和开发过程,使用户可以轻松快捷地创建基于Spring框架的应用程序[11]。在本平台实现中用于创建服务及前端交互。
(5) Spark:基于内存的分布式迭代计算框架,其核心技术主要有Spark Core、Spark SQL和Spark Streaming,同时内置许多算子方便对数据的分析,兼容多种框架接口[12]。在本平台中主要用于对传染病原始数据的清洗,对数据进行比对、预测与分析。
3.2 主要功能实现过程
平台主要由前端和后端两大块组成,后端通过JavaEE封装成API,前端通过Ajax局部刷新技术获取后端处理后的数据,通过Vue和ECharts动态地渲染到图表之中,其主要功能实现如下。
(1) 基于Vue-CLI构建SPA项目,完成前端路由搭建。利用Vue-CLI脚手架搭建出带有vue-router的SPA项目,首先在命令提示窗口输入以下代码安装Vue-CLI脚手架:npm install -g Vue-CLI。然后搭建Vue项目,在命令提示窗口输入:vue init webpack。在main.js中搭建vue-router,部分关键代码如下:
import Vue from ′vue′
import App from ′./App′
import router from ′./router′
new Vue({
el: ′#app′,
router,
components: { App },
template: ′
})
(2) 通过Ajax技术调用后端API,将数据保存到Vue组件实例的data中通过ECharts的setOption函数将数据渲染到图表中,部分关键代码如下:
export default {
data(){
sjkData:{},
sjkOption:null,
sjkChart:null
},
mounted(){
var _this=this;
$.ajax({
url:’http://localhost:3306/api/sjkData’,
type:’get’,
dataType:’json’,
success:function(data){
_this.sjkOption=data.sjkOption;
_this.sjkOption.series[0].data=data.geoDataSwl
[years];
_this.sjkChart.setOption(_this.sjkOption);
}
});
}
}
平台依照设计原则,根据传染病数据类型、特点,选取相应的ECharts可视化图表进行数据展示。
在传染病病原体信息简介面板,传染病的整体分类采用ECharts树图,基于TagCanvas用词云设计发病症状等关键词滚动效果,如图5所示。
相关传染病的发病人数及死亡人数采用柱形图展示,两者数据分别选用色差较大的颜色形成直观对比,也可以移动鼠标至相应传染病查看具体数据,能够进行纵向和横向比较。同样的色彩对比还运用于第二个模块——国内部分传染病的发病率及死亡率状况,此处采用ECharts雷达图,可完整、清晰、直观地对比二者数据差距,如图6所示。
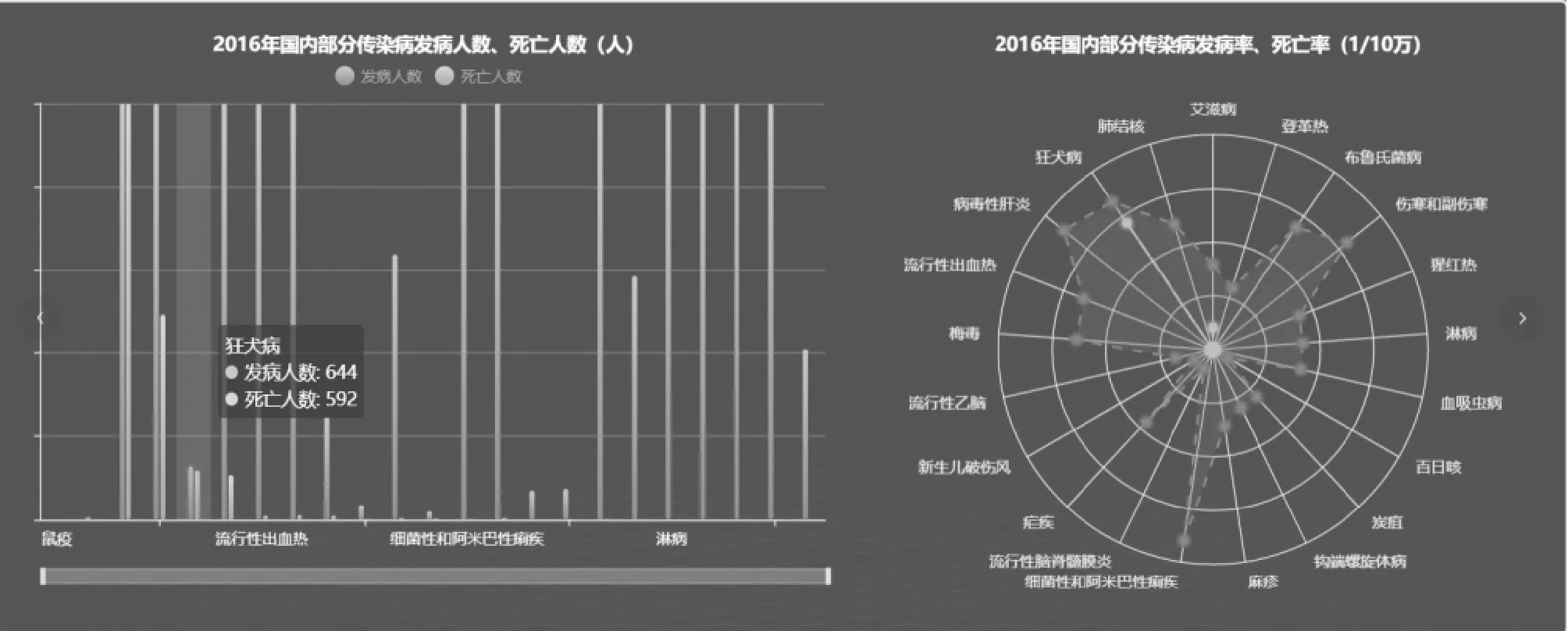
图6 ECharts渲染后传染病数据柱状图与雷达图视图
国内当年甲乙类传染病的发病率及死亡率使用饼图显示,如图7所示。当年各地区甲乙类传染病的死亡率用ECharts行政地图展示,其颜色深浅即表示死亡率数据的高低,同时可筛选色彩范围来查看地区状况。每四个模块组成一年的数据展示,更换年份只需拖动页面下方的时间轴即可,操作简洁,数据翔实。

图7 ECharts渲染后传染病数据饼图与地图视图
各类传染病的层级分类关系利用旭日图展示,如图8所示。查看具体传染病信息时,鼠标点击将会发生色彩变化及图标浮动效果,旭日图最外围添加了国内各类传染病2018年的发病人数及死亡人数的数据信息。当点击具体传染病时,右侧文字信息上浮至页面当中,细化可视化信息。
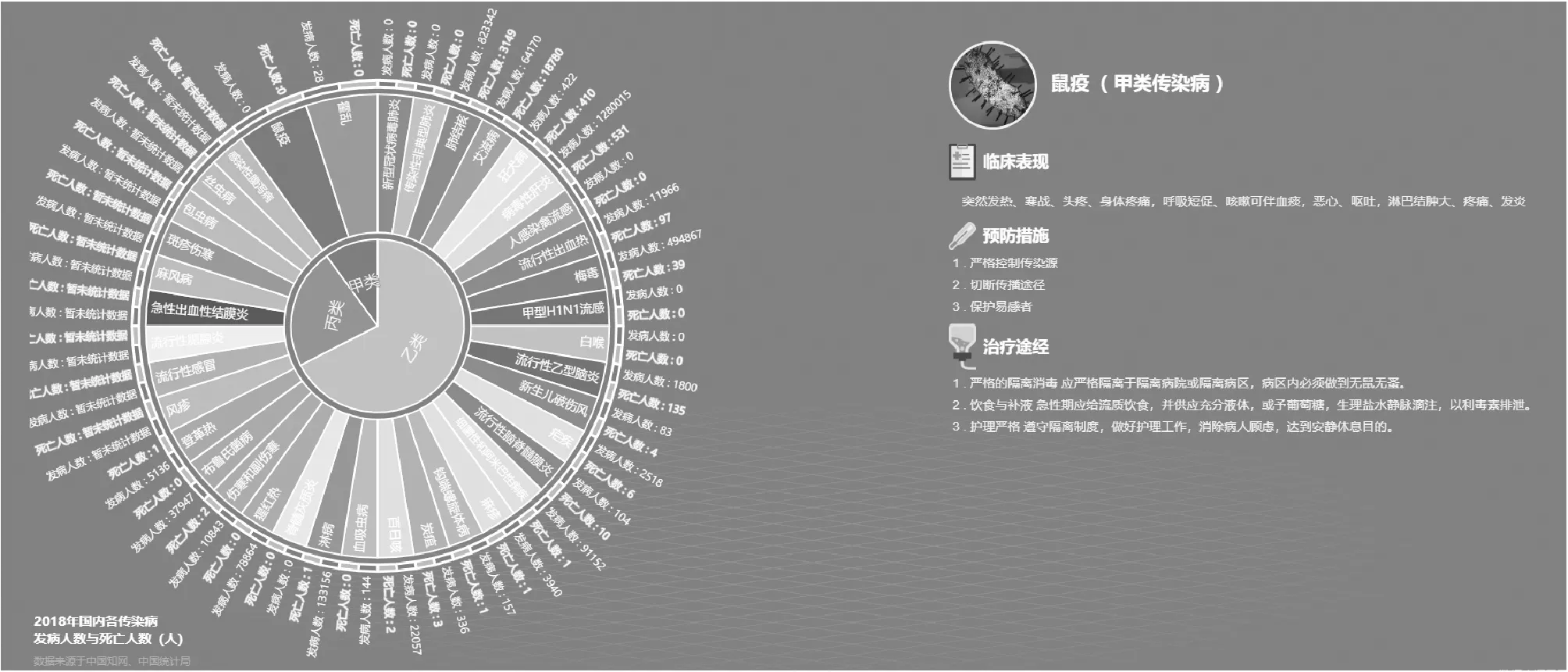
图8 ECharts渲染后传染病数据旭日图视图
(3) 通过Three.js框架的OBJLoader与MTLLoader加载器导入病原体的三维obj模型文件以及其mtl材质文件,通过OrbitControls轨道控制器实现模型的360度自动旋转以及通过拖拽事件实现模型的720度交互展示,如图9所示。部分关键代码如下:

图9 Three.js渲染后新型冠状病毒的三维视图
var that=this;
that.controls=new
OrbitControls(that.camera,that.renderer.domElement);
that.controls.target.set(0, 0, 0);
that.controls.autoRotate=true;
var loader=new OBJLoader();
var mloader=new MTLLoader();
that.$nextTick(()=>{
mloader.setPath(′./static/models/′).load(that.model.modelID+′.mtl′,function(mlt){
mlt.preload();
loader.setMaterials( mlt );
loader.setPath(′./static/models/′).load(that.model.modelID+′.obj′, function(object) {
that.loadingFlag=false;
console.log(′加载完毕!′);
object.traverse(function(child) {
if (child.isMesh) {
child.castShadow=true;
child.receiveShadow=true;
}
});
object.scale.set(that.model.mscale,
that.model.mscale,that.model.mscale);
object.children[0].geometry.computeBoundingBox();
object.children[0].geometry.center();
that.scene.add(object);
animate();
});
});
})
function animate() {
that.rafId=requestAnimationFrame(animate);
var delta=clock.getDelta();
if (mixer) mixer.update(delta);
controls.update(delta);
that.renderer.render(that.scene, that.camera);
}
(4) 在Pom.xml文件中导入相关sparkCore与sparkSql的依赖,部分关键代码如下:
(5) 数据分为本地数据与Hive中的数据,本地数据用于测试,实际运行时使用Spark接口从Hive中获取数据,将传染病数据的年限与名称作为关键字进行二次排序,再通过各种算法模型进行聚合与分析,实现对各种年限的传染病相关数据的计算。进行二次排序关键代码如下:
var primitiveRdd: RDD[(String, (String, String, String))]=primitiveDataSet.rdd.map(arr=>{
val id=arr.getString(0)
val time=arr.getString(1)
(SecondSortKey(imsi.toLong,time.toLong),arr)}).
sortByKey().map(arr=>{
val pathogene=arr._2.getString(0)
val introduce=arr._2.getString(1)
val death_num=arr._2.getString(2)
val deathrate=arr._2.getString(3)
val contagion=arr._2.getString(4)
(imsi,(time,pathogene,introduce+"-"+death_num,contagion))
})
4 结 语
本文旨在利用数据可视化技术将传染病的各项相关信息,包括其爆发历史、临床症状、传播途径、预防措施、治疗途径、相关热点词云、病原体3D模型等非数字数据以及历年来各地区、时段的传染病情况等数字数据以图文结合的方式进行展现。通过对数据图表的交叉对比,帮助用户对比任意省份、传染病之间的相似程度,检测其相关性。同时,基于不同数据视图之间丰富的交互使用户直观地感受到不同地区时段传染病的分布情况,有效地挖掘出传染病传播的时空模式,快速寻找出传染病暴发的典型地区时段以及传播趋势,从而更好地预防、把控和分析传染病。该技术为数据可视化在具体的学科领域应用提供一定的实践价值参考,同时也能够在一定程度上促进数据可视化技术的发展。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
传染病信息(2022年3期)2022-07-15
肝博士(2022年3期)2022-06-30
云南化工(2021年8期)2021-12-21
今日农业(2021年8期)2021-07-28
海洋信息技术与应用(2020年1期)2020-06-11
基层中医药(2020年3期)2020-02-13
传媒评论(2019年4期)2019-07-13
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
