
基于背书特征的电力行业联盟链账本篡改攻击检测方法
2023-11-01 01:13王栋杨珂李达周启惠张艳秋阮倩昀王瑜
电力建设 2023年11期
王栋,杨珂,李达,周启惠,张艳秋,阮倩昀,王瑜
(1.国网数字科技控股有限公司,北京市 100053; 2. 国网区块链科技(北京)有限公司,北京市 100053;3. 国网区块链应用技术实验室,北京市 100053;4. 中国科学院信息工程研究所,北京市 100093)
0 引 言
随着我国清洁能源的发展,绿电交易量大幅提升,传统电力交易模式面临绿电交易机制不完善、交易环节公开透明度不足、跨省区交易组织难[1-3]等一系列挑战。区块链因其多节点、防篡改、公开透明的特点与绿电交易的业务需求高度契合,能够很好解决清洁能源发展过程中的业务痛点。目前依托“区块链+电力交易”深度融合的关键技术[4-7],搭建起公开透明、高效可信的绿电交易系统。典型的绿电交易系统所依赖的区块链服务以联盟链为技术架构,为各类业务提供安全可信的底层区块链基础设施服务。
近年来,以比特币[8]和以太坊[9]等为代表的公链多次遭受51%算力攻击,即攻击者通过某种方式控制全网超50%的算力,达到了篡改全网区块链账本的效果[10-14]。与公链不同,电力行业联盟链中的共识不采用工作量证明机制,其账本篡改攻击不需要掌握超过全网一半的算力[15-16]。联盟链为了提高链中数据查询速度,采用数据库存储数据最新状态,数据库的存在为实现账本篡改攻击提供了可行性。因此,在电力联盟链中通过篡改电力企业节点的状态数据库中存储的电量值,会造成客户端查询数据不一致,若实施篡改电量值的恶意节点数量满足背书策略,这便达成了恶意节点在后续的电力交易中对链中所有节点账本中电量值的全局控制,对正常的电力交易活动造成恶劣影响。
面对上述攻击,学术界目前采取的解决措施包括防护和检测这两大类方法。针对攻击的防护方案能够减少攻击发生的概率,文献[17]提出了一种新共识方法,该方法使得掌握51%算力的攻击者篡改区块链数据的可能性较小。文献[18]提出了一种针对底层协议参数的补救措施,可阻止控制系统大部分资源的攻击者对区块链一致性攻击。文献[19]提出了一种基于历史权重信息的方法,分析历史区块中矿工出现频率并计算历史权重难度,使得攻击发生代价增加2个数量级。文献[20]提出了一种区块延迟发出的惩罚系统,基于攻击者向网络隐藏区块的时间对攻击者进行处罚。
防护方案不能完全杜绝攻击发生,因此对攻击的检测也至关重要,即及时发现在链中发生的账本篡改攻击并提供预警功能。机器学习方法由于其易用及有效性,已被广泛用于区块链的异常检测,文献[21]提出了一种基于自动编码器及时序模型算法的区块链异常检测方法,通过分析区块交易统计信息成功发现了ETC上发生的51%算力攻击。文献[22]提出了一种针对比特币交易的异常检测模型,利用支持向量机和K-Means算法可以检测出51%算力攻击。文献[23]使用智能软件代理监控区块链中异常行为,提出利用监督机器学习算法和博弈论算法以检测51%算力攻击的发生。
上述检测方法仅面向公链和联盟链在共识以及交易流程等方面存在巨大差异性,用机器学习方法做攻击检测时,需要收集的数据特征也不一样,公链中的数据集以及数据集的攻击特征无法适用于联盟链。目前针对联盟链账本篡改攻击的检测方案较少,文献[24]提出了一种基于规则的检测方法,将数据库中存储的状态数据与无法篡改的区块数据进行比对,但这种方式会对区块链系统本身造成很大性能负担。恶意实用拜占庭容错(practical Byzantine fault tolerance,PBFT)共识会导致账本篡改攻击,文献[25]提出了一种利用机器学习对联盟链上PBFT共识异常的检测方案,验证了机器学习方法对联盟链上异常共识行为检测的有效性。文献[26]也采用机器学习方法对仅基于PBFT单一共识的联盟链恶意节点进行检测。文献[27]利用联盟链构建健康关怀系统,并使用图卷积神经网络检测恶意节点。文献[28]提出了一种基于K近邻算法(k-nearest neighbor,KNN)联盟链异常交易检测方法,虽然此方法是针对联盟链设计的,但在实验验证阶段却采用比特币交易数据进行验证,缺乏基于联盟链上攻击数据特征进行数据集构建,无法应对联盟链的异常检测需求。
针对上述问题,本文首先在电力联盟链绿电交易仿真环境中实现账本篡改攻击,然后提取攻击相关的多个背书特征进行数据集构建,并基于随机森林算法设计账本篡改攻击在线检测方法。本文的主要贡献为:
1)在电力联盟链绿电交易仿真环境中,基于状态数据库更改实现针对绿电交易场景的账本篡改攻击,研究并提取与攻击有关的背书读写集相似度、背书时间方差、验证时间均值和背书率4类背书特征。
2)基于背书特征构建攻击检测所需的数据集,采用Boosting随机森林算法进行检测模型训练,并将模型非侵入式部署,在线检测账本篡改攻击行为,通过闭环反馈机制的增强学习不断提升模型的精度和健壮性。
3)通过实施多组对比实验,与已有方法相比,本文所提方法具有耗能低、检测精度高、不局限于单一共识算法等优点。
1 区块链绿电交易平台概述
基于能源互联网的区块链绿电交易平台依托联盟链搭建。在绿电交易业务场景中,主要由发电机构、电网企业和售电企业这三大类主体组成,以完成绿电的发电、输送配送和售电业务。其中,发电机构生产的电能由电网企业输送并根据用电需求向用户分配电能,售电企业则负责电能的批发和零售等以实现电力产品价值的工作[29]。
为了提高链中数据查询速度,电力联盟链除了使用文件账本外,还采用数据库存储区块链中数据最新状态,数据均为键-值(key-value)形式。交易首先被模拟执行得到读写集并被签名背书,读集代表交易模拟执行时读到存储在状态数据库中key以及key的version,version的形式是(区块号,交易号),其代表了被更改后key值对应着的最新已完成交易所在区块号以及交易号。写集代表模拟执行后产生的状态更新,即被更改key以及key对应的新value。
读写集示例如表1所示。假定链中存在发电机构、电网企业和售电企业,这3类的代表节点分别为P0、P1、P2,三个节点产生各自背书读写集。比如在节点P0上,keyA的version是(1, 0),代表这笔交易对keyA进行操作,并且更改了keyA值的最新已完成交易是1号区块的0号交易,所以keyA的version为(1, 0)。在节点P0上模拟执行完当前交易后,keyA的值会变为98, 所以写集中value为98。
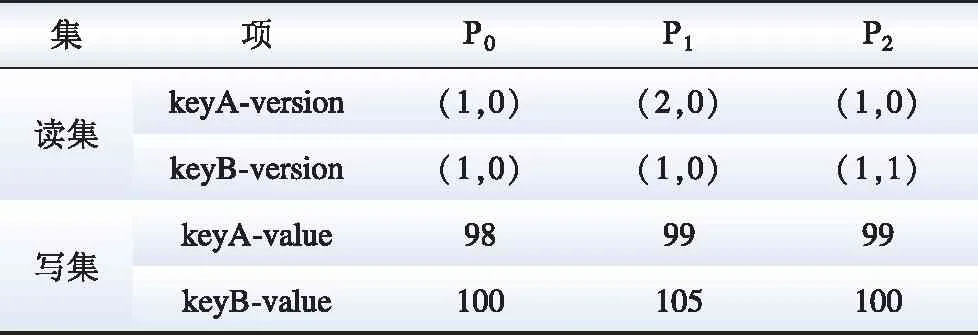
表1 读写集示例
电力联盟链交易流程如图1所示,链中交易遵循“模拟执行—排序成区块—验证提交”3个阶段。客户端发送交易给背书策略指定的背书节点。背书策略在交易过程中极为重要,用于在交易验证阶段验证交易的有效性,并且执行电力交易智能合约需指定交易的背书节点,例如“在一共5个背书节点中要求满足至少3个节点背书”。在绿电交易过程中,背书节点可为发电机构节点、电网企业节点和售电企业节点这3类角色。每个交易都被背书节点模拟执行得到读写集,背书节点会对交易的读写集进行签名,这一步称为背书。接下来,交易进入排序环节,客户端收集背书结果,把背书后的交易发送给排序服务,由排序服务采用共识算法把交易排序打包成区块。之后区块被广播给所有节点。每个节点在验证阶段依据背书策略验证交易的有效性。如果交易有效,则把交易有效标志位设置为是,同时把交易的写集更新到本地状态数据库中;如果交易无效,则把交易有效标志位设置为否,同时放弃交易的写集,不更新本地的状态数据库。
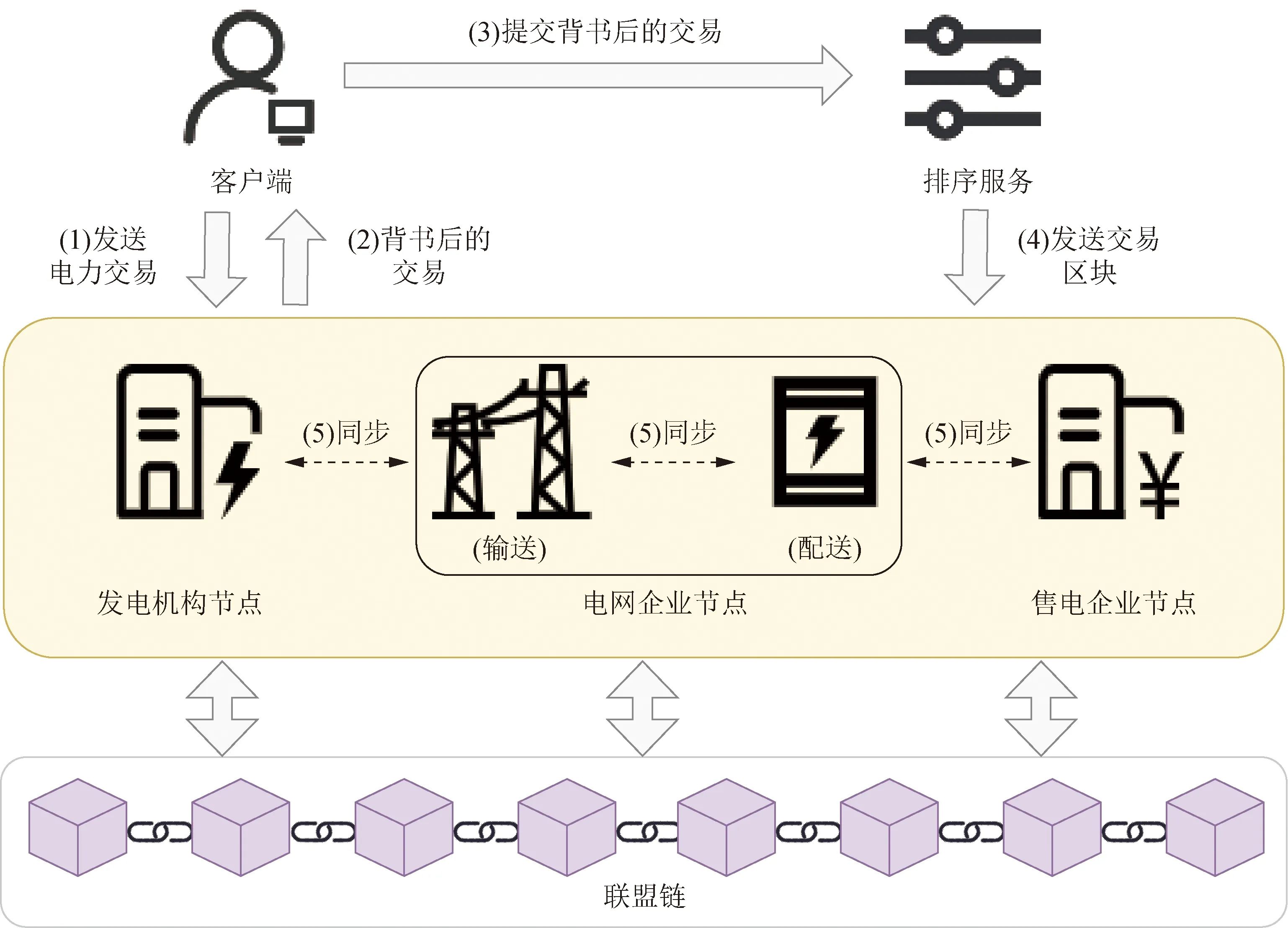
图1 电力联盟链中的交易流程
2 账本篡改攻击与攻击特征提取
本节在电力联盟链绿电交易仿真环境下,实现针对绿电交易场景的账本篡改攻击,并分析攻击的实现原理及攻击造成的后果。研究并提取与攻击紧密相关的多个背书特征,为后续攻击检测提供数据支撑。
2.1 账本篡改攻击
本节搭建了电力联盟链绿电交易仿真环境,模拟完成了由发电机构、电网企业和售电企业参与的发电、输电、配电和售电的基本绿电交易活动,并且基于此交易场景实现了账本篡改攻击。在电力联盟链中,账本篡改攻击主要是通过修改状态数据库中数据来实现的,具体过程如下:
在正常情况下,状态数据是由客户端通过调用智能合约发起交易来改变,比如状态数据库中存储了电网企业节点待输送电量的key(Pe)和售电企业节点待售电量的key(Se),对应value值分别是100和200,当客户端通过调用输电智能合约发起一笔电网企业节点传输10个单位电量到售电企业节点的交易,若这笔交易有效,交易首先会打包到区块并存储到文件账本中,同时状态数据库中Pe和Se的value值变为90和210。
由于节点状态数据库会挂载到节点所在主机的文件系统中,通过定位主机节点的数据库,读取数据库状态数据并对其进行修改,能够实现篡改节点数据库的目的。图2中电网企业用户篡改了其状态数据库中存储待售电量Se对应值,由210→230,客户端查询发电机构节点和售电企业节点数据库中Se的值为210,但客户端查询电网企业节点数据库中Se的值为230,即从电网企业节点上查到了不一致的数据。

图2 客户端查询数据不一致
更进一步地,如果篡改状态数据的组织数量满足了背书策略,那么全局账本数据都将被篡改。例如,设置背书策略为至少满足电力企业的2个代表节点的背书结果一致,在该背书策略下,若电网企业节点和发电机构节点合谋,篡改数据库中待售电量Se值由210→230,而售电企业中Se值仍为210。账本篡改攻击如图3所示,现在客户端发起一笔由待输送电量Pe转10个单位电量到Se交易,在背书阶段执行交易后返回的读写集中,电网企业节点和发电机构节点中Se的值均为240,由于这2个节点的背书结果一致,符合了背书策略,因此该笔交易有效,所有的节点都会用读写集中Se值为240来更新状态数据库。在这种情况下,虽然售电企业节点并没有篡改状态数据库,但最终仍“被动”与其他篡改过数据库节点账本数据一致,从而达到全局账本篡改的效果。而一旦链中Se值被恶意篡改,将严重影响到正常的绿电交易过程,上述攻击不仅使得售电企业节点待售电量虚高,更恶劣的是将无法保障最终用户收到所约定好一定量的电能产品,从而影响最终用户的用电,会造成巨大的经济损失。
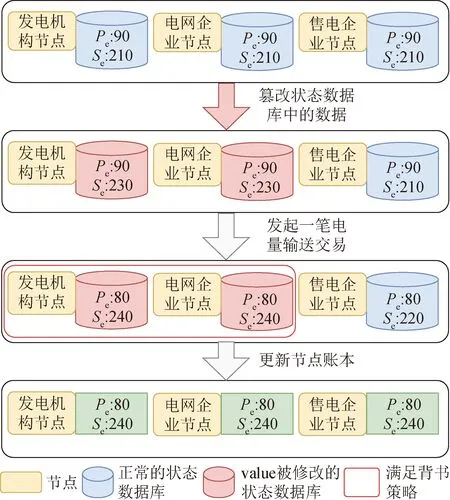
图3 账本篡改攻击
在绿电交易业务场景中,当需要从链上读取数据时,链是直接从节点本地数据库中读取状态数据。在交易背书阶段对于每个键值对最新状态查询仅访问状态数据库。因此通过攻击某个节点状态数据库,之后有可能读到篡改后的数据。本文所实现账本篡改攻击的原理并不与联盟链的不可篡改性矛盾,这是因为联盟链是以链式结构来存储区块的,但这种不可篡改性只存在于文件账本中,而存储状态数据数据库是可被篡改的。
2.2 攻击特征提取
根据上述分析的账本篡改攻击原理,电力联盟链易受攻击点在于交易流程背书阶段中对于key-value最新状态的查询仅访问状态数据库,通过篡改状态数据库中的值,从而造成客户端查询数据不一致甚至是链中所有账本数据都被篡改的情况。与背书紧密相关的且受攻击影响的特征将会有利于表征账本篡改攻击对背书阶段的影响。在本节中,通过对电力联盟链交易流程和攻击特征的分析,提取背书读写集相似度、背书时间方差、验证时间均值和背书率这4类背书特征,并基于提取的特征构建检测数据集。
2.2.1 背书读写集相似度
在交易流程背书阶段,发电机构、电网企业和售电企业节点都会生成一个读写集,读写集的值依赖于节点本地状态数据库中存储的值。状态数据篡改可能会更改状态数据库中存储key的value值以及version,从而导致不同节点产生背书读写集有差异,因此,可将节点上背书读写集相似度作为一类特征。为了计算背书读写集相似度,首先需要将所有节点背书读写集统一编码,然后提取距离参考系,最后计算背书节点读写集编码与参考系的平均距离。
1)读写集统一编码。
读写集中key所对应的version、value一般都以字符串形式表示,无法直接计算相似度,在计算相似度之前需要将其转换为数字形式表示。因此,本方案对每个节点读写集中version和value进行统一One-Hot编码从而方便计算,得到编码集合为Opi。One-Hot编码,又称为一位有效编码,主要是采用位状态寄存器来对状态进行编码,在任意时候只有一位有效。使用One-Hot编码,可将离散特征的取值扩展到欧氏空间,使特征之间的距离计算更加合理。
为了实现对读写集编码,首先对所有读写集中version值和value值做统计,得到不同version值和不同value值的总数,表1读写集示例的总类别数为7,然后每个version值或者value值会转换为一个长度为7的二进制向量,向量中只有一位为1,其余位为0。举例来说,P0节点的读集中的keyA-version,经过编码后变为[0, 0, 0, 0, 0, 0, 1],总类别数为7,且它属于第一类。表1的示例进行统一One-Hot编码后的结果如表2所示。
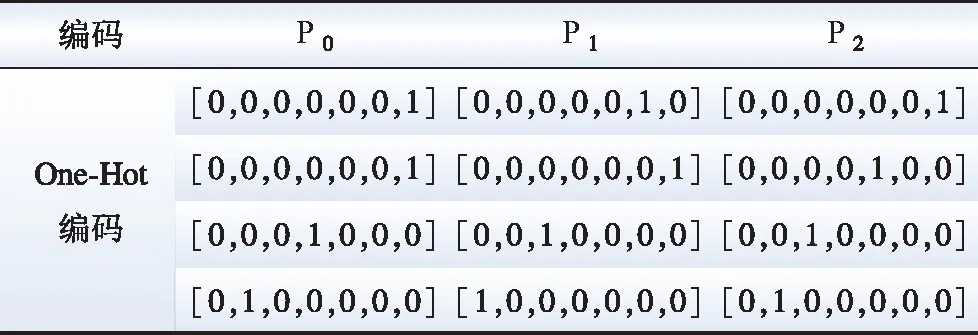
表2 读写集统一编码示例
2)距离参考系Oc。
计算背书读写集相似度D之前,需要得到链中大多数节点所共有的背书读写集,该读写集称为距离参考系Oc,如果没有发生数据库中数据被篡改的情况,那么链中所有节点背书读写集是一致的,Oc就为当前读写集,当发生篡改情况时,就会出现节点背书读写集不一致情况,Oc计算方式定义为:
(1)
式中:k从0到Ls-1取值,Ls为所有key在读集和写集中出现的总次数,即表2的行数;j从0到Ln-1取值,Ln代表链中所有节点的个数;OPj(k)为对于k代表的行(如keyA-version为第1行,对应的k为0),第j个节点对应的二进制向量。如表1,当取k=0,j=0时,OP0(0)=[0, 0, 0, 0, 0, 0, 1],即P0节点生成的读集keyA-version的值。定义函数count[OPj(k)]的含义为当k取值确定时,OPj(k)在所有节点出现的次数,如表1所示,当取k=0,j=0时,count[OP0(0)]=2,因为对于keyA-version,P0和P2节点对应的二进制向量是一致的,在所有节点中出现了2次。定义函数argmax()作用为当count[OPj(k)]的取值最大时,返回对应的OPj(k),如表1所示。
(2)
利用式(1),分别计算出当k取不同值时,Oc(k)的值,计算结果如表3所示。
3)计算相似度D。
定义dist(x,y)为向量x、y的欧氏距离:
(3)
根据式(1)和式(3),则平均相似度即背书读写集相似度D定义为:
(4)
首先固定k,对表2中的第k行,计算每一列的元素OPj(k)与Oc(k)的距离,然后k递增,继续计算第k行中每一列的元素OPj(k)与Oc(k)的距离,最后计算Ln*Ls个距离值的平均值即为D。
2.2.2 背书时间方差TE
背书时需要进行交易的模拟执行,而模拟执行输入来自于状态数据库,在智能合约的函数中对不同类别输入会选择不同的代码分支执行,当数据被篡改后,被篡改数据节点与正常节点在模拟执行交易时,会选择不同的代码分支执行,从而导致背书时间的不一致。
本文定义第i个节点背书时间为Ei,那么n个节点背书时间方差定义为:
(5)
2.2.3 验证时间均值TV
验证阶段为交易的第3个阶段,节点收到排序服务打包的区块后,对其中每笔交易读写集进行验证。篡改状态数据库中数据后,被篡改节点与其他正常节点产生背书读写集不同,由于交易的读写集是所有背书节点读写集的集合,因此攻击发生时待验证交易读写集与未受到攻击时待验证交易读写集有差别,从而导致交易验证时间有差异。并且验证阶段,节点需要验证本地状态数据version与被验证交易读写集中version是否一致。如果节点本地version被篡改过,也会导致验证过程与未受到攻击时验证过程有差别。
本文定义第i个节点的验证时间为Vi,那么n个节点的验证时间均值定义为:
(6)
2.2.4 背书策略背书率TP
电力联盟链的智能合约都有背书策略,假如链中有3类机构分别为发电机构、电网企业和售电企业,背书策略指定机构中至少2个节点对交易执行结果进行签名。背书策略指定链中的节点执行合约后对执行结果进行背书,在交易验证过程中,节点需要确保交易拥有合适数量的背书结果,即验证此交易满足背书策略。背书率表示实际参加背书的节点数量与背书策略指定的背书节点数量的比值,用TP表示,该比值越大,则受到攻击的概率越小,反之,则越大。
3 账本篡改攻击检测方法
3.1 攻击检测任务概述
基于背书特征的账本篡改攻击检测工作流如图4所示,主要包括数据收集、特征提取、模型训练、在线检测以及增量更新。
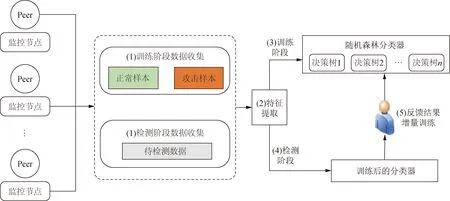
图4 攻击检测工作流
1)数据收集:收集发电机构、电网企业和售电企业等多节点运行时数据。为每个节点启动一个非侵入式监控节点获取数据,采集的监控数据包括:一次交易的背书读写集、完成一次交易所需的背书时间、完成一次交易所需的验证时间和背书节点数量。数据按照单次交易触发一次的频率收集,即当新交易发生时,在所有相关的节点上进行一次数据采集。
2)特征提取:汇总收集的数据,利用本文特征计算方法提取数据特征,包括读写集相似度、背书时间方差、验证时间均值和背书率,为样本生成4维特征向量。
3)模型训练:训练阶段,通过学习正常和攻击样本进行基于随机森林攻击检测模型的训练。
4)在线检测:检测阶段,实时收集正在运行的链上数据并提取特征,利用上一步训练的模型,对实时采集的数据特征进行在线攻击检测,并将检测结果发送给用户。
5)增量更新:模型训练数据不能覆盖所有的攻击,因此提供闭环反馈机制的增强学习更新模型,在线检测过程中会将判断有误的数据传给分类器,分类器依托回传数据增量训练提高模型精度。
3.2 攻击模型检测
本文采用分类与回归树(classification and regression tree,CART)算法生成决策树,多棵决策树形成随机森林,有效避免单棵决策树的过拟合问题[30],并采用基于Boosting的方法避免冗余树的生成,降低内存消耗。
3.2.1 基于随机森林的检测模型
随机森林检测模型如图5所示,训练决策树过程对训练集中的样本有放回随机采样,对背书读写集相似度、背书时间方差、验证时间均值以及背书率4类特征随机采样,抑制模型的过拟合、提高分类器的健壮性。
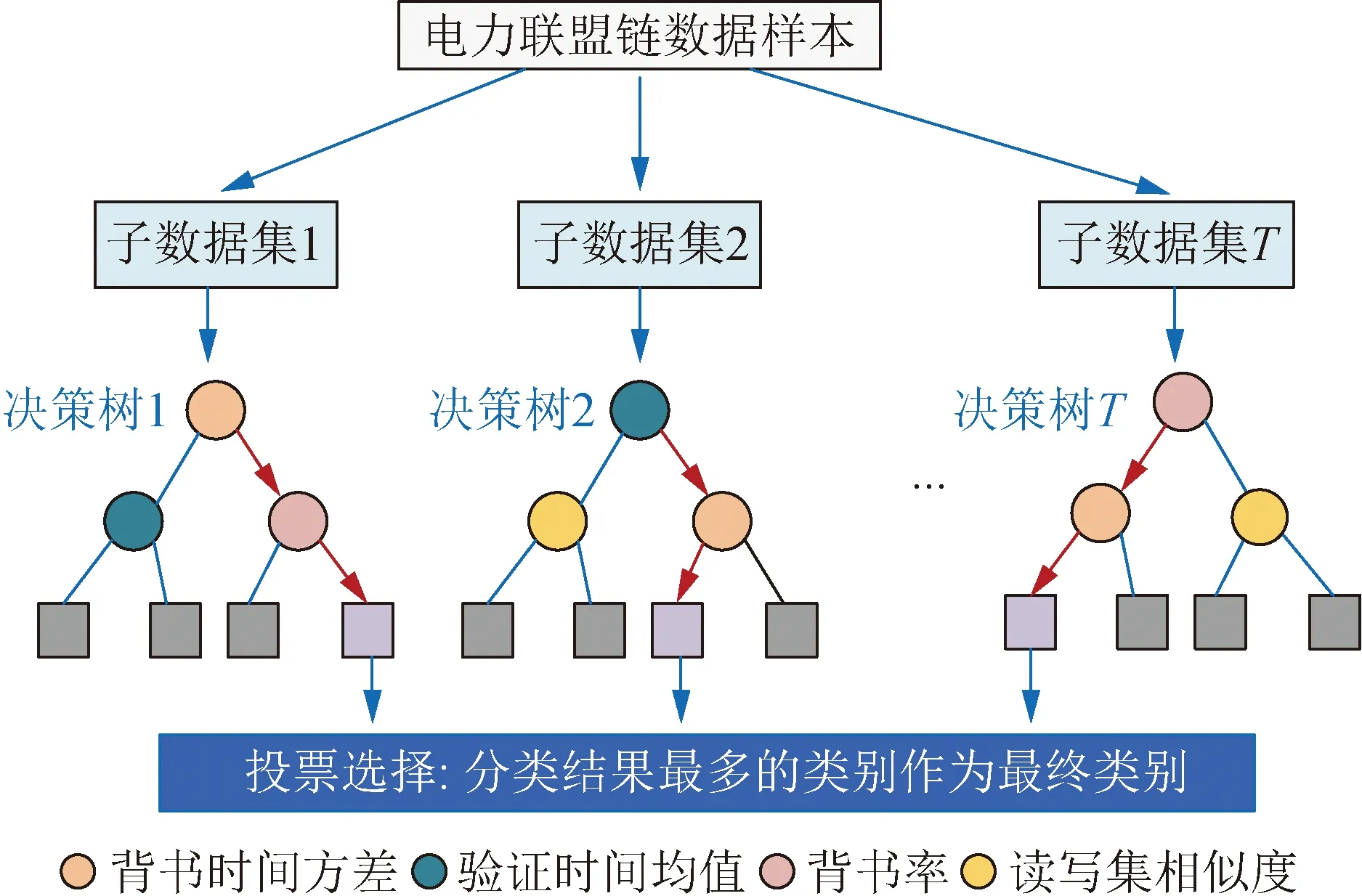
图5 检测模型的训练过程
随机森林的训练过程如下:
1)样本随机采样。给定包含正常和攻击样本的训练集X={x1,x2,…,xn}和带有正常/异常的样本目标值Y={y1,y2,…,yn},使用有放回背书特征样本采样方法。多次采样中没有用到样本作为验证集。
2)特征随机采样。每个决策树训练过程中随机采样背书特征,不使用全部的背书特征,如Tree1的特征是背书读写集相似度和验证时间均值,Tree2的特征是背书时间方差、验证时间均值和背书率。对于每棵树而言,样本和特征都是不同的。
3)训练结果计算。决策树的预测结果包括正常和异常,在分类任务中预测结果的类别通过投票方式选择,将得票最高的结果作为最终输出。由于该过程使用大量决策树训练,有效避免了过拟合问题,但产生冗余决策树会大量消耗内存。
3.2.2 基于Boosting的训练模型权重更新
Boosting使用序列训练方法加速模型权重更新,为决策树构建信息互补对象,保证每棵树信息都是高可用的,避免冗余树的生成,降低内存消耗。算法关键部分如下:
1)节点划分。
给定{x1,y1,w1},…,{xN,yN,wN},依据随机选取的背书特征和信息增益划分决策树节点。在计算信息增益过程中,样本按最大权重进行排序。信息增益计算过程为:
(7)
式中:ΔG为信息增益;Sn为节点n的样本集合;Sl为样本集合的左子节点;Sr为样本集合的右子节点;E(·)为交叉熵计算。
当递归划分将决策树扩展到一定的深度或者当前到达节点的样本信息增益为0时,会创建新的叶节点。
2)决策树权重。
和多类Boosting[31-32]相似,决策树权重的计算公式为:
(8)
式中:αt为决策树权重;M为类别数量;εt为决策树的分类错误率。
3)训练样本权重更新。
通过使错误分类样本权重变大,在下一步操作中构建容易纠正错误分类样本的决策树。
(9)
式中:wi为决策树的迭代更新权重,更新权重后权重被归一化,重复训练过程,直到获得最终权重。
4 实验测评
本节介绍实验环境以及数据集的构成,从识别耗时、区块链性能损耗、识别准确率等方面将本文提出的方案与已有检测方案进行对比。
4.1 实验环境
电力联盟链绿电交易仿真场景包括发电机构节点、电网企业节点和售电企业节点3类节点,每类的节点个数设置具有随机性,为每个节点启动一个非侵入式监控节点收集信息,使用Kafka、Raft(一种崩溃容错共识算法)、拜占庭容错(robust Byzantine fault tolerance,RBFT)等多种共识算法,每个节点都在一个独立OpenStack虚拟机上运行,每个虚拟机使用相同硬件配置:vCPU(e3-1220 v5@ 3.00 GHz),内存8 GB。所有虚拟机运行在同一个局域网中,局域网交换机的速度为1.0 Gbit/s。
4.2 数据集
数据基于仿真环境采集,组建不同大小(节点数不同)以及不同应用下的电力联盟链绿电交易场景以提高数据丰富度:链中节点总数从2到24不等,多应用场景智能合约包括配电合约、电力资产管理合约和电力实体身份认证合约等,使用脚本模拟用户随机发起交易的行为。
每条样本包含一次交易的背书读写集相似度、完成一次交易所需背书时间方差、验证时间均值和背书率。对于负(异常)样本的收集,随机选择上述节点,对其进行账本篡改攻击。数据集如表4所示,共16 800个样本,正样本8 505个,负样本8 295个,训练集和测试集的占比为80%和20%。

表4 数据集数量
4.3 对比实验
本节针对已有的基于规则检测方法和其他机器学习方法进行复现,并与本文方法进行多评估指标对比。
4.3.1 基于规则的检测方法
将文献[24]提出的基于规则检测方法称为RULE方法,本文提出的检测方法称为ML方法。RULE方法是每次交易执行之前,把节点状态数据库与文件账本区块中的数据作对比,若对比结果相同,则未受到攻击,反之亦然。主要从识别耗时、对区块链的性能损耗、识别准确率方面进行比较,其结果对比如图6所示。
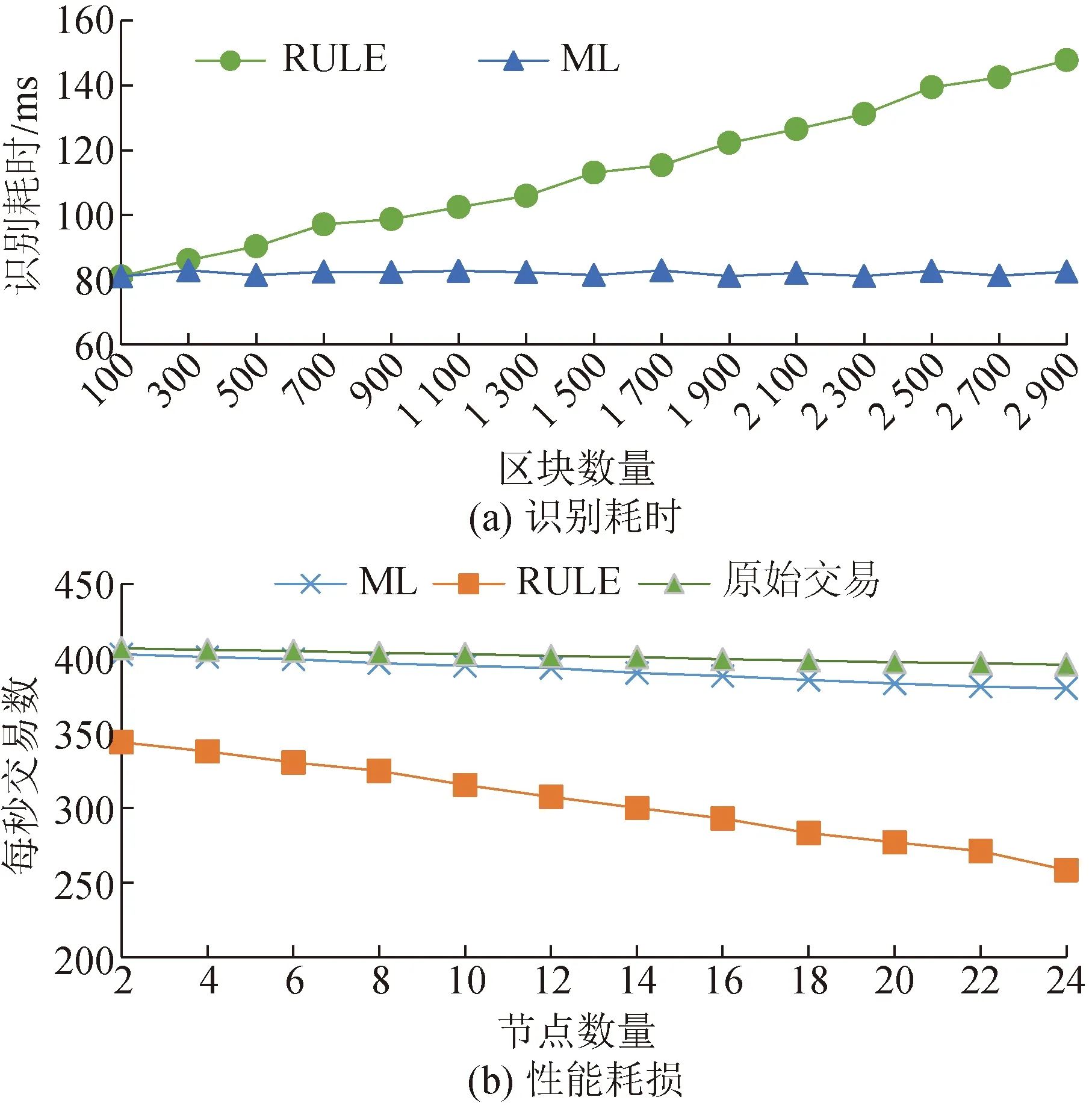
图6 本文方法与基于规则的检测方法对比
识别耗时表示从交易结束到检测出攻击所消耗的时间,如图6(a)所示,随着区块数量增加,RULE方法识别耗时急剧增长,而ML方法的识别耗时保持稳定且远小于RULE方法。ML方法使用样本数据特征作为输入,数据特征在交易过程中通过非侵入式监控节点采集,不需要访问区块数据,因此即使区块数量增加,模型计算时间也不会变化;RULE方法在判断是否发生攻击时需要比对状态数据库与本地区块账本是否一致,随着本地区块数量的增加,每次逆序遍历区块账本,寻找状态数据库中key所对应的交易在区块账本中位置的时间也会增长。
性能损耗表示攻击检测方法对电力联盟链造成的影响,性能指标为每秒处理的交易数(transaction per second,TPS)。使用RULE方法需要在每次交易执行前暂停整体联盟链网络,并且需要等待所有节点的检测结果,对区块链系统本身交易性能影响较大,随着联盟链网络节点数量的增加,TPS迅速下降,如图6(b)所示,在节点数量从2增加到24的过程中,RULE方法的TPS从344减小到258。本文提出的ML方法无需停止正常交易流程,对区块链交易性能的影响很小,几乎与原始交易性能一致,即使节点数量增加到24,TPS依然大于344,优于RULE方法的最佳性能。以原始交易模式下的交易性能作为基准,RULE方法会造成34.75%的性能损耗,ML方法造成4.03%的性能损耗,ML方法的性能损耗远低于RULE方法。
在准确率方面,ML方法在相同95.75%准确率下,比RULE方法,具有检测耗时和性能损耗比较低的优势,在不影响实际业务运行条件下,更满足对电力联盟链进行账本篡改攻击的在线检测需求。
4.3.2 其他机器学习方法
在联盟链的攻击检测研究领域,基于机器学习研究方法相对较少,本节选取了2个准确率较高且较相关的方法进行对比实验,分别为文献[25](记为文献MLCA)以及文献[27](记为文献GHAD)进行实验对比。
采用准确率作为评价指标,由于本文方法与对比方法都是基于机器学习的方法,三者在识别耗时和对区块链的性能损耗是接近的,不再进行比对展示。三者的准确率对比如图7所示。与另外2种检测方法相比,本文方法的检测准确率是最高的,从而说明了本文方案在电力联盟链账本篡改攻击检测上十分有效,包括数据集的设计和机器学习算法的选取。
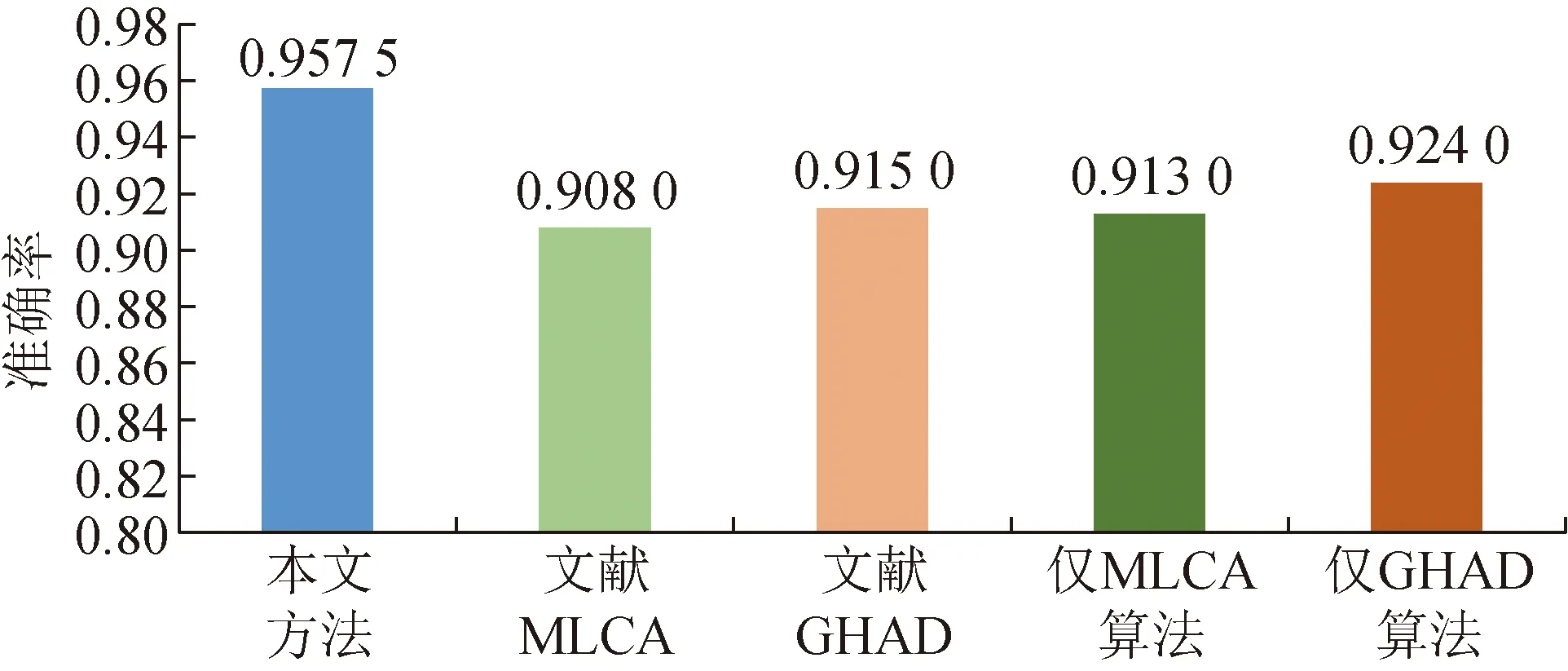
图7 本文方法与其他基于机器学习的检测方法对比
由于对比方法所采用的数据集与本文采用的数据集存在不一致性,为了进一步验证本文方法有效性,设置了另外一组对比实验,分别将对比方法中所采用机器学习算法用于本文设计的数据集,得到的测试结果标注为“仅MLCA算法”和“仅GHAD算法”。测试结果如图7所示,可看到将对比方法中的机器学习算法用于本文的数据集,所得到测试结果的准确率仍低于本文方法,模型的准确率均小于92.50%,远低于本文方法得到的95.75%准确值,从而说明在相同的数据集上,本文所采用的随机森林算法效果更好。另外,由于本文提取的背书特征与共识算法类型无关,检测方法不局限于单一共识算法,可以适配多种共识算法。
5 结束语
针对电力联盟链中的账本篡改攻击,本文提出了基于背书特征的检测方法,进行了试验验证,相比于现有检测方法在识别耗时、区块链性能损耗、检测准确率有较大优势,并能满足电力联盟链在线检测的业务需求。目前本文用于攻击检测的特征仅包含背书读写集相似度、背书时间方差、验证时间均值和背书率4类,后续工作会增加特征种类及优化特征提取方法,进一步提高本文方法的识别准确率。
猜你喜欢
快乐语文(2021年34期)2022-01-18
汉字汉语研究(2021年4期)2021-03-09
科学(2020年5期)2020-11-26
科学(2020年6期)2020-02-06
当代党员(2019年19期)2019-11-13
学生天地·小学中高年级(2018年10期)2018-12-13
小学生导刊(2018年31期)2018-12-06
传媒评论(2018年4期)2018-06-27
现代企业文化(2018年13期)2018-06-09
小学科学(学生版)(2018年1期)2018-01-31
