
基于深度确定性策略梯度的主动配电网有功-无功协调优化调度
2023-11-01 01:54孙国强殷岩岩卫志农臧海祥楚云飞
电力建设 2023年11期
孙国强,殷岩岩,卫志农,臧海祥,楚云飞
(河海大学能源与电气学院,南京市 211100)
0 引 言
随着分布式电源(distributed generation, DG)在配电层面的广泛接入,配电系统正从无源网络演变为有源配电网络,即主动配电网(active distribution network, ADN)。同时,光伏发电(photovoltaic, PV)、风电(wind turbines, WT)的随机性和波动性增加了ADN的不确定性,导致电压、潮流越限等问题变得更加严重[1-2]。
目前,为了实现ADN的协调优化控制,国内外学者已经提出诸多基于模型的优化方法。例如,文献[3]构建了ADN的混合整数非线性规划模型和等效混合整数二次约束模型,用于配电网中的电压管理。文献[4]将非线性潮流约束进行二阶锥松弛,从而将配电网经济运行优化模型转化为混合整数二阶锥规划问题,提高了求解精度。进一步,考虑到DG不确定性因素对配电网运行的影响,文献[5]中构建了基于随机规划的多阶段调度模型,验证了该模型能在随机状态下自适应调整储能装置、换流站及需求响应决策。然而,随机规划需获取不确定变量的概率分布参数[6],并采用大量场景刻画不确定信息,导致准确性和求解效率偏低[7-8]。为了消除ADN优化配置模型中DG相关的不确定性变量,文献[9]构建了鲁棒优化框架,并采用渐紧线切割算法和列和约束生成算法相结合的方法对转化模型求解,缩小了凸松弛间隙,提高了模型求解效率。文献[10]计及新能源的预测误差,基于离散不确定性域改进了现有鲁棒优化方法,从而获得了更广泛的“恶劣场景集”。上述鲁棒优化方法无需获取不确定性量的概率分布,而是通过不确定性集来描述DG出力的不确定性,形式简洁。但由于其在不确定性集的最恶劣实现情况下做出决策,因此可能导致优化结果过于保守[11-13]。
基于模型的方法在ADN协调优化控制方面取得了广泛的成效。然而,此方法依赖于完整且明确的配电网物理模型,需要获取详细的网络拓扑、线路参数、负荷功率等信息[14-15]。然而这些信息在现实获得过程中经常有所缺失、准确性低。如果参数和物理模型不准确,将会导致不经济甚至不切实际的调度决策[16]。此外,基于模型的方法计算复杂度高、存在维度灾等问题,这使得模型计算十分耗时,难以实现在ADN中进行实时优化控制[17]。
近年来,深度强化学习(deep reinforcement learning, DRL)以其在线响应快、无需对DG的随机性分布建模的独特优势[18-19],在电力系统领域获得了广泛关注。文献[20]将能量储存系统(energy storage systems, ESS)考虑到配电网的电压控制中,并采用Q深度神经网络来逼近ESS的最佳动作价值。文献[21]提出了一种基于深度Q网络的有功安全校正策略,在消除线路过载和调节机组出力上具有良好的效果,但需要对连续动作空间离散化,可能会带来维度灾难问题[22]。为了使DRL智能体学习连续状态和动作空间之间的映射关系,文献[23]将深度确定性策略梯度(deep deterministic policy gradient, DDPG)方法应用到综合能源经济调度中。针对电压控制问题,文献[24]基于多智能体的DDPG算法协调优化光伏逆变器的无功功率输出,但未考虑无功-电压控制设备,如可投切电容器组(switchable capacitor banks, SCB)、有载调压变压器(on-load tap-changers, OLTC)等。针对配电系统优化控制问题,上述文献侧重于关注单一有功或无功资源控制,这在保证配电系统供电安全和降低运行成本方面存在一定局限性。此外,传统DDPG方法中的经验回放机制忽略了不同经验的重要程度,可能存在训练效率低、过度学习等问题[25]。另一方面,优先经验回放(priority experience replay, PER)机制在机器人控制和游戏任务中的应用取得了巨大成功,提高了学习效率和策略稳定性[26]。
基于此,本文将PER机制结合到DDPG方法中,构建了一种基于PER-DDPG的ADN在线调度框架。首先,以ADN日运行成本最小为目标,在计及节点电压偏移和潮流越限约束的基础上,协调SCB、OLTC、微型燃气轮机(micro-gas turbines, MT)和ESS等有功/无功资源,构建了ADN有功-无功协调调度模型。其次,将此模型转化为马尔科夫决策过程(Markov decision process, MDP),并基于PER-DDPG框架进行离线训练及在线测试。仿真结果表明,相较于传统的DDPG方法,本文所提出的基于优先经验重放的DPPG方法可以实现对连续动作空间的精确控制,并通过高效的经验学习以获得安全、经济的动作策略。本文研究有望为基于深度确定性策略梯度的有功-无功协调优化调度提供技术参考。
1 ADN有功-无功协调调度强化学习建模
本节首先构建了基于ADN的有功-无功协调调度数学模型。在计及潮流约束和配电网安全约束的基础上,该模型旨在以ADN日运行成本最小为目标,在不同时段协调各有功/无功资源的出力。然后,本节将此数学模型转化成基于MDP的调度模型,以充分利用DRL自适应源荷不确定性的优势进行求解。
1.1 基于ADN的有功-无功协调调度数学模型
1.1.1 目标函数
本文的目标函数包括变电站的能源交易成本和MT的燃料成本:
(1)
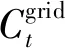
1.1.2 约束条件
1.1.2.1 潮流约束
(2)
(3)
(4)
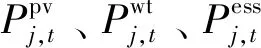
1.1.2.2 配电网安全约束
(5)
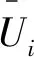
1.1.2.3 可控设备运行约束
1)SCB运行约束:
(6)
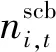
2)OLTC运行约束:
(7)
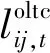
3)MT运行约束:
(8)
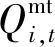
4)ESS运行约束:
(9)
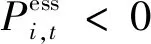
1.2 基于MDP的调度模型
本节将ADN有功-无功协调优化调度问题建模为MDP。MDP通常由学习环境E、状态空间S、动作空间A和奖励空间R组成。在每个时段t,DRL智能体通过观察ADN当前的状态st∈S,执行动作at∈A,并从环境E中获得奖励值rt∈R,然后ADN的当前状态st将根据状态转移概率函数p(st+1|st,at)转换到下一状态st+1。直至t达到总调度时段T时,此过程终止。t时段MDP的详细制定描述如下。
1.2.1 状态空间
(10)
状态空间包括当前时段、ESS的荷电状态、过去T个时段内的电价、过去T个时段内PV、WT的有功功率和过去T个时段内负荷的有功无功功率;状态空间中的各个变量都是连续性变量;为充分利用新能源,本文假设PV和WT是不可调度资源,并以固定单位功率因数运行[27],故在状态空间中不考虑新能源无功功率。
1.2.2 动作空间
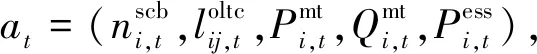
(11)
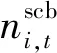
1.2.3 奖励函数
1.2.3.1 日运营成本项
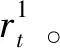
(12)
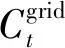
1.2.3.2 约束违反项
鉴于ADN安全运行的重要性,奖励函数中还应当考虑电压违反和潮流越限的风险。因此,本文采用惩罚机制,对电压违反和潮流越限进行惩罚。
1)电压违反惩罚项:
(13)
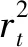
2)潮流越限惩罚项:
(14)
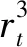
综上,奖励函数定义如下:
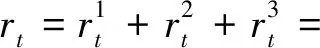
(15)
式(15)表明,当潮流计算收敛时,奖励函数的主要目标是使ADN的日运营成本最小,同时避免电压违反。当潮流计算发散时,智能体将会受到一个较大的惩罚值。
1.2.4 状态动作价值函数
为了在不同状态下获得最优动作,需要使用状态-动作价值函数Qπ(st,at;θ)来描述在当前状态st下执行动作at,并遵循策略π后所能带来的预期奖励,该策略由一组网络参数θ来控制。状态-动作价值函数如下式所示:
(16)
式中:π为从综合状态映射到调度计划的策略,智能体在状态st选择何种动作at由策略π(st)=at决定;γ为折扣因子,用来平衡未来奖励和即时奖励,γ∈[0,1];E(·)为数学期望。
在ADN调度问题中,DRL智能体的目标是在与环境的不断交互过程中找到最优策略π*,使ADN日运行成本最低。这个最优策略可以通过最大化状态-动作价值函数来实现:
(17)
式中:Qπ*(st,at;θ)为最优状态-动作价值函数。
2 基于DDPG的ADN有功-无功协调调度
2.1 PER-DDPG学习框架
为有效解决ADN有功-无功协调优化中存在的连续动作空间问题,本文构建了基于PER-DDPG算法的ADN在线调度框架,如图1所示,该框架中的DDPG智能体由Actor网络和Critic网络组成,每个网络都有自己的目标网络以提高算法的稳定性。为了提高智能体的采样效率,该框架引入了优先级经验缓冲区B。在训练过程中,智能体与ADN环境交互并收集若干组经验单元et={st,at,rt,st+1},然后根据优先级pt对经验单元进行重要性采样。pt值越大,相应经验单元的重要性越高,智能体从中学到经验越多。
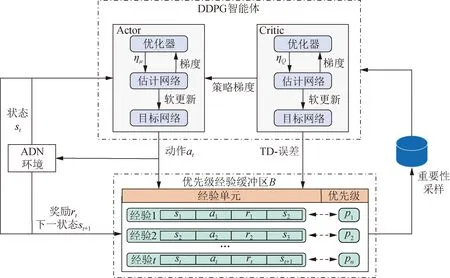
图1 PER-DDPG算法学习框架
本文在文献[25]的基础上,对pt计算公式进行改进:
pt=|δt|+ε
(18)
式中:δt为时间差分(temporal difference, TD)误差;
ε为较小正常数,用以确保每个经验单元即使TD-误差为零时仍有一定概率被抽样。
在常规方法中,智能体往往更倾向于重放pt值较高的经验单元,这可能会改变状态访问频率,导致神经网络的训练过程出现振荡或发散。针对上述问题,本文使用了重要性采样权重来计算每个经验单元对于权重变化的贡献:
(19)
式中:wi为第i个经验单元所占权重;pi为第i个经验单元的优先级;Bsize为经验缓冲区的大小;κ∈[0,1]。
接下来详细介绍Critic网络和Actor网络在离线训练阶段的更新过程:
1)Critic网络。
在训练过程中,Critic网络使用具有参数θQ的深度神经网络来估计状态-动作价值函数。智能体根据经验优先级对一小批经验单元进行抽样,在每次抽样中,Critic网络试图最小化以下损失函数:
(20)
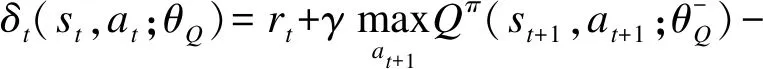
(21)
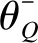

(22)
2)Actor网络。
在训练过程中,Actor网络用于学习动作策略和执行动作。Actor网络中的参数化函数μ(st;θμ)可以确定性地将状态映射到特定动作来指定当前策略。动作策略定义的目标如下:
J(θμ)=Est~B[Qπ(st,μ(st;θμ);θQ]
(23)
(24)
其次,基于动作参数θμ更新:
(25)
式中:ημ为Actor网络的学习率。
2.2 离线训练过程
本文所提PER-DDPG方法的离线训练过程如图2所示。在每一轮训练中:首先,DDPG智能体的Actor网络根据参数化函数μ(st;θμ)+Δμt制定SCB、OLTC、MT和ESS有功/无功资源的调度策略,Δμt为随机噪声。然后,智能体在当前状态st下执行动作at,经潮流计算后获得奖励rt,并观察到新的状态st+1,历史样本通过上述交互被收集存储在经验缓冲区中的经验单元et。最后,智能体根据优先经验回放机制对经验单元进行小批量采样,并更新Actor和Critic估计网络和目标网络参数。当t达到T时,一个训练集结束。重复以上步骤,直到训练集数达到最大训练集umax,离线训练过程结束,保存此时最优的神经网络模型。
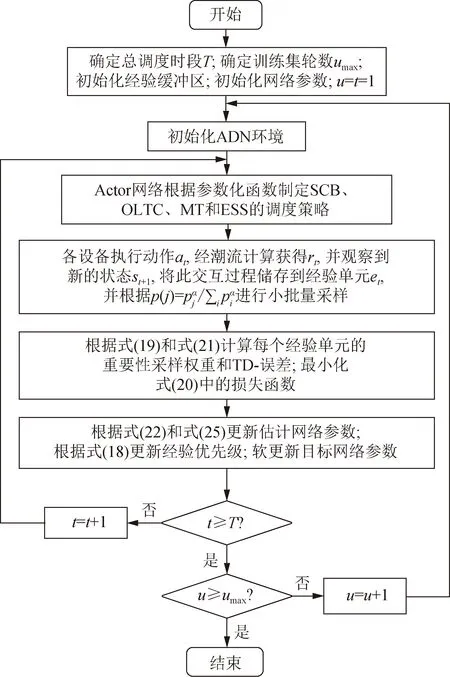
图2 PER-DDPG算法流程
3 算例分析
3.1 算例设置
为了验证所提PER-DDPG方法在ADN有功-无功协调优化调度的有效性,本文采用如图3所示修改的IEEE-34节点配电算例[27]进行仿真验证。该配电系统接入了2个MT、1个ESS、3组PV和3台WT,各设备参数详见表1。在节点7、8之间以及节点19、20之间分别接入2个OLTC,均具有33档调节位置,调节范围在-10%~10%之间。2个SCB分别安装在节点24和节点34,每个SCB共有4组运行单元,每组运行单元的无功功率为120 kvar。变电站的容量为2 500 kVA。配电网节点电压的限制范围为0.95~1.05 pu。为了获取配电网电价、各节点负荷需求和新能源有功及无功功率数据,本文基于加州ISO开放存取同步信息系统时间序列数据[28]进行分析,并以1 h为时间段提取2018—2020三年的数据信息。其中,将2018—2019年的数据作为训练集,2020年的数据作为测试集,用以验证所提方法在ADN有功-无功协调优化调度问题上的有效性。总调度时段T为24 h。
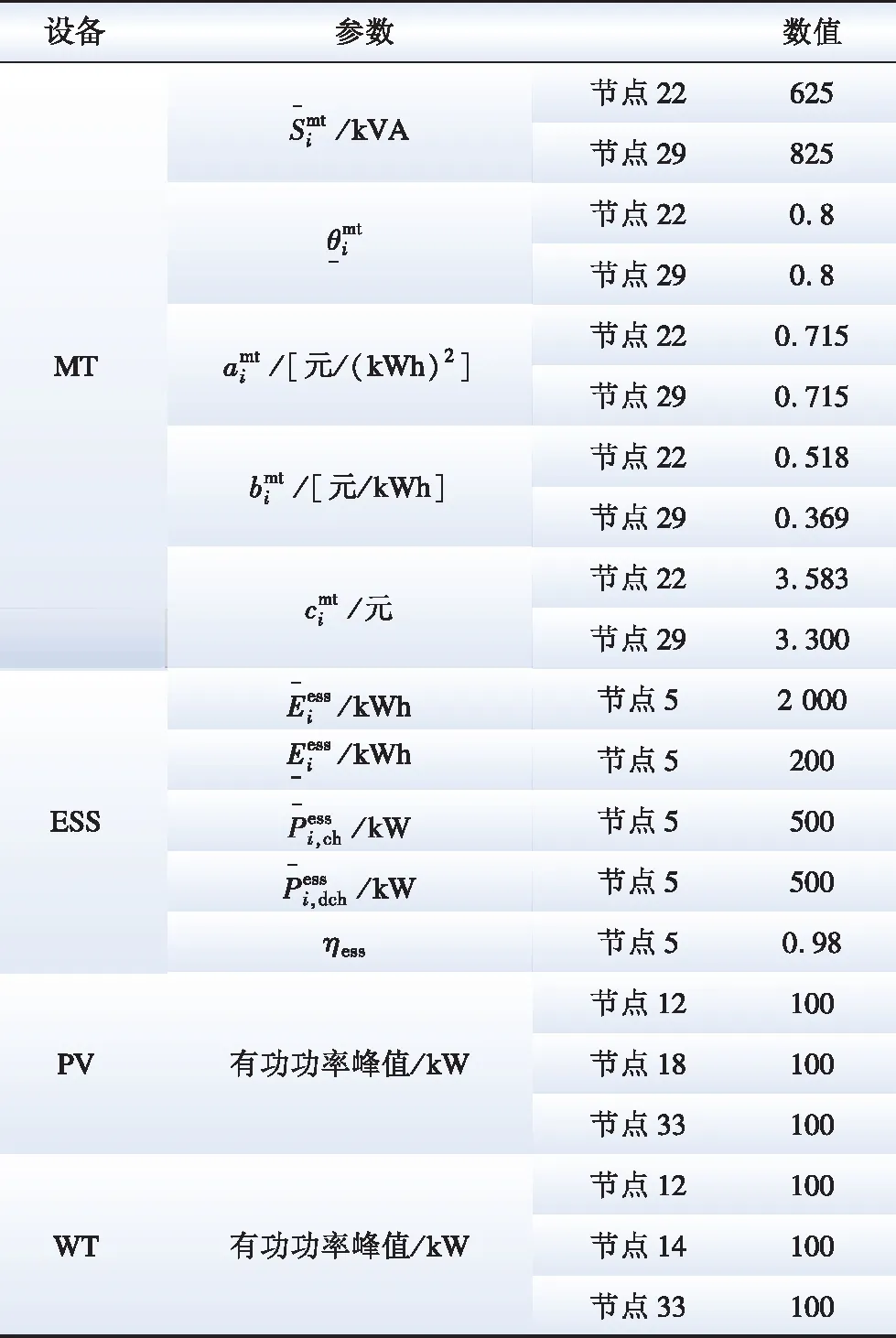
表1 各设备参数
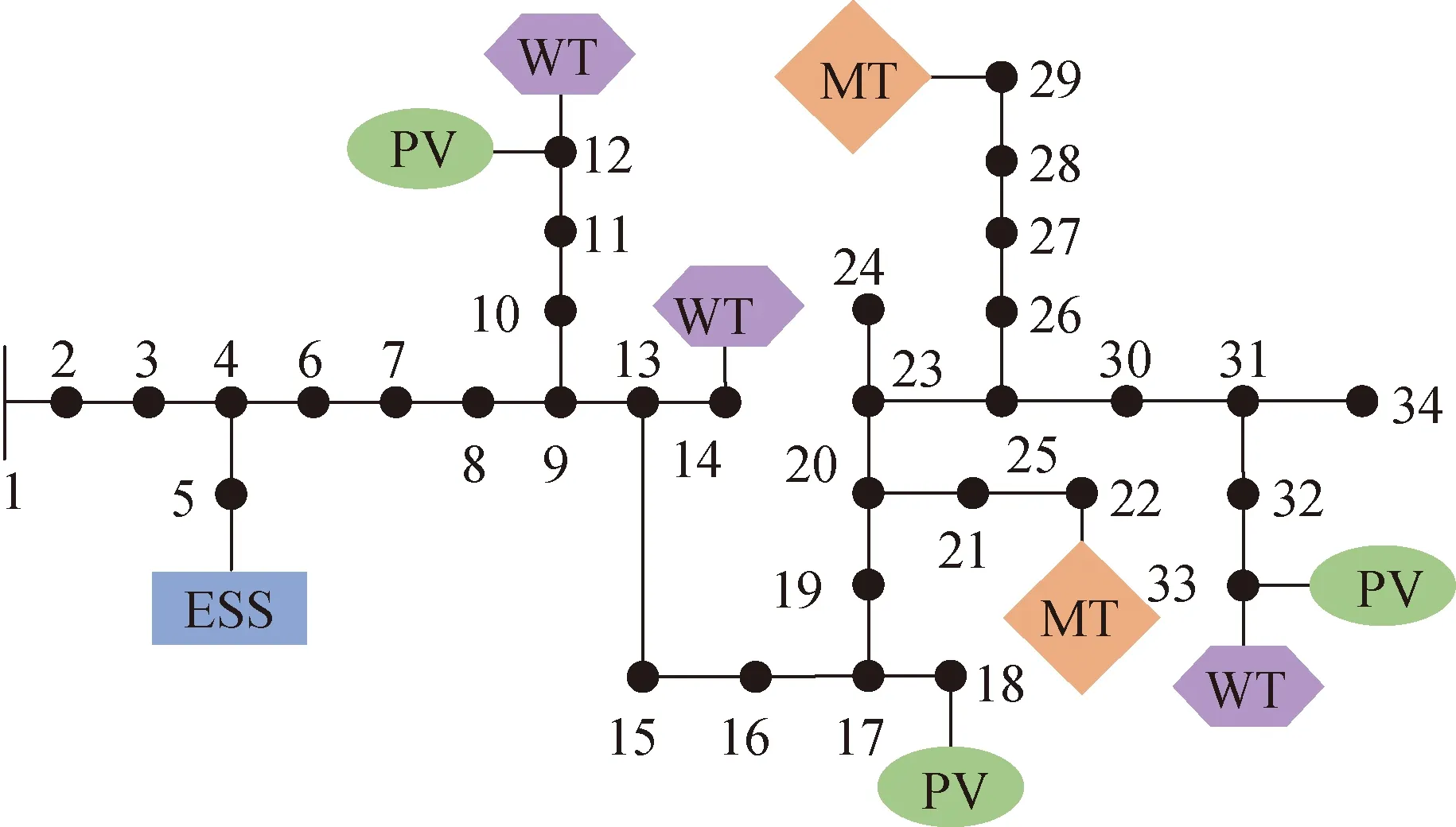
图3 修改后的IEEE-34节点标准配电系统
本文采用Python中Tensorflow 2.2.0实现所提算法,并基于OpenAI Gym标准搭建了ADN有功-无功协调优化调度学习环境。同时,为了进行潮流计算判断收敛性,本文依赖电力系统分析包Pandapower。所有的算例仿真都在Intel(R) Core(TM) i7-11800H处理器2.30 GHz的工作站上进行。
3.2 离线训练
本文所提PER-DDPG方法的详细参数设置如表2所示。在本文所建立的MDP中,动作空间同时存在连续和离散动作。然而PER-DDPG方法只能处理连续动作空间。因此在智能体离线训练之前,本文对离散动作进行了连续化处理,将离散-连续混合动作空间转化成连续动作空间。在使用PER-DDPG方法进行训练后,本文再将OLTC和SCB的连续动作值舍入到最近的整数值。
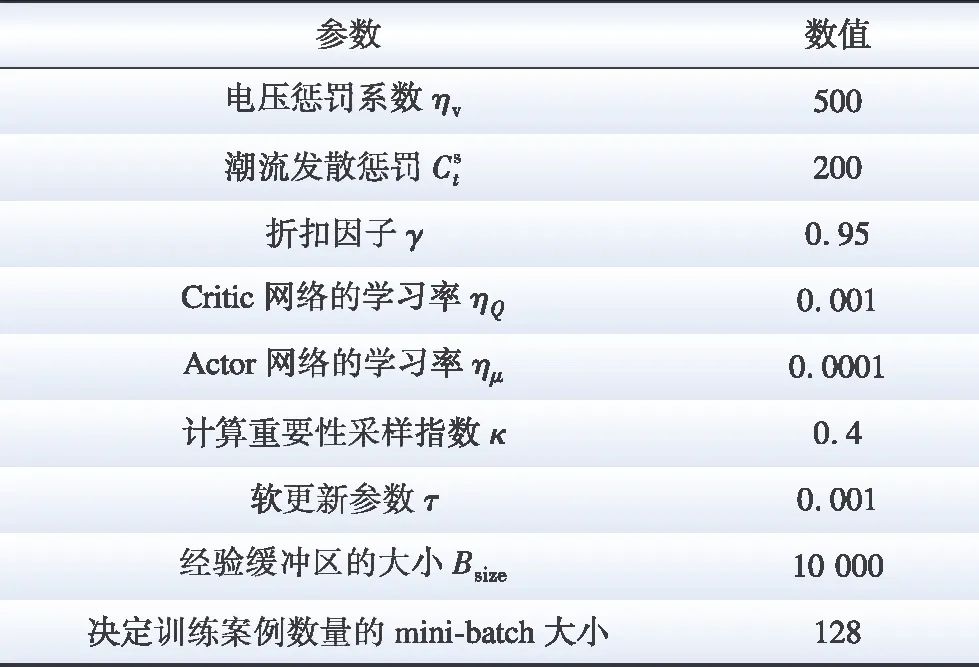
表2 所提方法参数设置
由于PER机制可以从本文提出的方法中单独分离,因此本文将所提PER-DDPG方法与DDPG方法进行比较。表3展示了不同方法在离线训练和在线测试(迭代一次)上的平均耗时对比。本文对每种方法使用不同的随机种子运行5次,每次离线训练的最大迭代次数为106。结果表明,两种DRL方法均能实现秒级在线求解,实现ADN有功-无功协调优化在线调度策略。与DDPG方法相比,本文所提PER-DDPG方法的离线训练时间和在线测试时间更短,计算资源损耗更小。
本文进一步比较了所提PER-DDPG方法和DDPG方法在不同随机种子情况下的训练过程性能,如图4所示。实线代表各DRL智能体的平均奖励值,阴影部分代表奖励值的波动范围。通过图4可以看出,在智能体与ADN环境的交互学习过程中,PER-DDPG方法和DDPG方法的奖励值逐步增加,并最终均可收敛到一个稳定值,表明两种方法均可通过学习获得使ADN日运行成本最小的经济调度策略。其中,PER-DDPG方法迭代到约2×105次时出现了一定振荡,这属于训练早期智能体探索ADN环境的正常行为,并不影响其总体收敛性。值得注意的是,PER-DDPG方法迭代到约5.7×104次时获得奖励值-19 500,而DDPG方法需要迭代到约17.1×104次时才能得到相同的奖励值。因此,本文所提PER-DDPG方法的智能体能够快速学习到成功样本,积累得到一定的成功经验,从而更迅速学到ADN有功-无功协调调度策略。此外,基于PER-DDPG方法的最终收敛稳定奖励值为-9 500,而DDPG方法的最终稳定奖励值相对较低,为-10 500。因此,本文所提出的PER-DDPG方法具有更快的收敛速度,未来折扣奖励回报相较DDPG方法提升了9.52%。
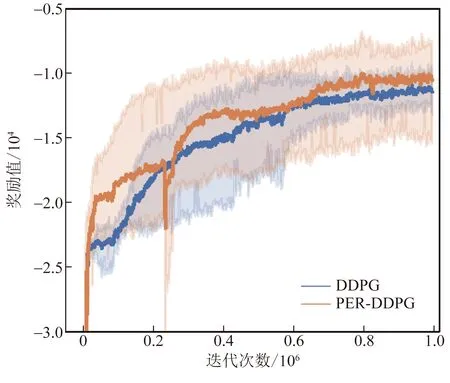
图4 不同算法下的训练过程
3.3 在线测试表现
在实验交互过程达到所设置的最大迭代次数后,离线训练过程完成,本文保存此时训练完成的最优神经网络模型,并在测试集上进行测试。如图5所示,测试集中PER-DDPG方法和DDPG方法的累积运行成本分别为243.07万元和396.27万元。结果表明,PER-DDPG方法在一年内能够降低38.66%的ADN运行成本,相比之下,DDPG方法效果较为有限。
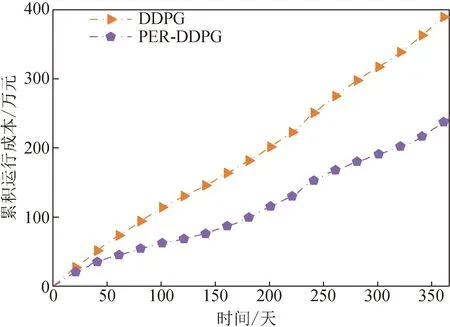
图5 不同算法下测试过程的累计成本
本文所提PER-DDPG智能体在测试集中某天的调度决策结果如图6所示。
图6(a)展示了当天WT和PV的有功功率输出变化。图6(b)展示了负荷有功无功功率需求以及电价变化情况。由图6(c)可知,智能体在低电价时段调度ESS进行充电以储存能量;而在高电价时段,智能体调度ESS进行放电以满足负荷运行需求,从而降低配变功率峰谷差。由图6(d)—(e)可知,两个MT的功率因数被限制在0.8以上,智能体根据当前电价和ADN负荷需求动态地调整MT的发电量。当负荷需求减少或电价下降时,智能体调度MT减小发电量以避免过剩的电力浪费;而当负荷需求增多或电价上涨时,智能体调度MT增大发电量以缓解ADN的运行压力。在08:00—16:00之间,风电和光伏的总有功功率较大,ESS进行充电且MT减少输出功率,以就地消纳新能源,减少功率倒送。通过上述调度方式,一定程度上减小了新能源随机性对配电系统的干扰。
图6(f)—(g)分别展现了OLTC的挡位及SCB的运行数量变化情况,均满足调度周期内动作次数不宜过多的规定。在12:00—17:00时,风电和光伏发电出力较大,SCB减少运行数量,防止因新能源功率倒送引起电压越限。
不同时段各节点的电压分布情况如图7所示。由图7可知,在无功电压调节设备SCB和OLTC的共同作用下,ADN的各节点电压都被限制在安全范围0.95~1.05 pu内。其中,在14:00时节点22上的电压最低,为0.970 7 pu;在15:00时节点5上的电压最高,为1.001 3 pu。
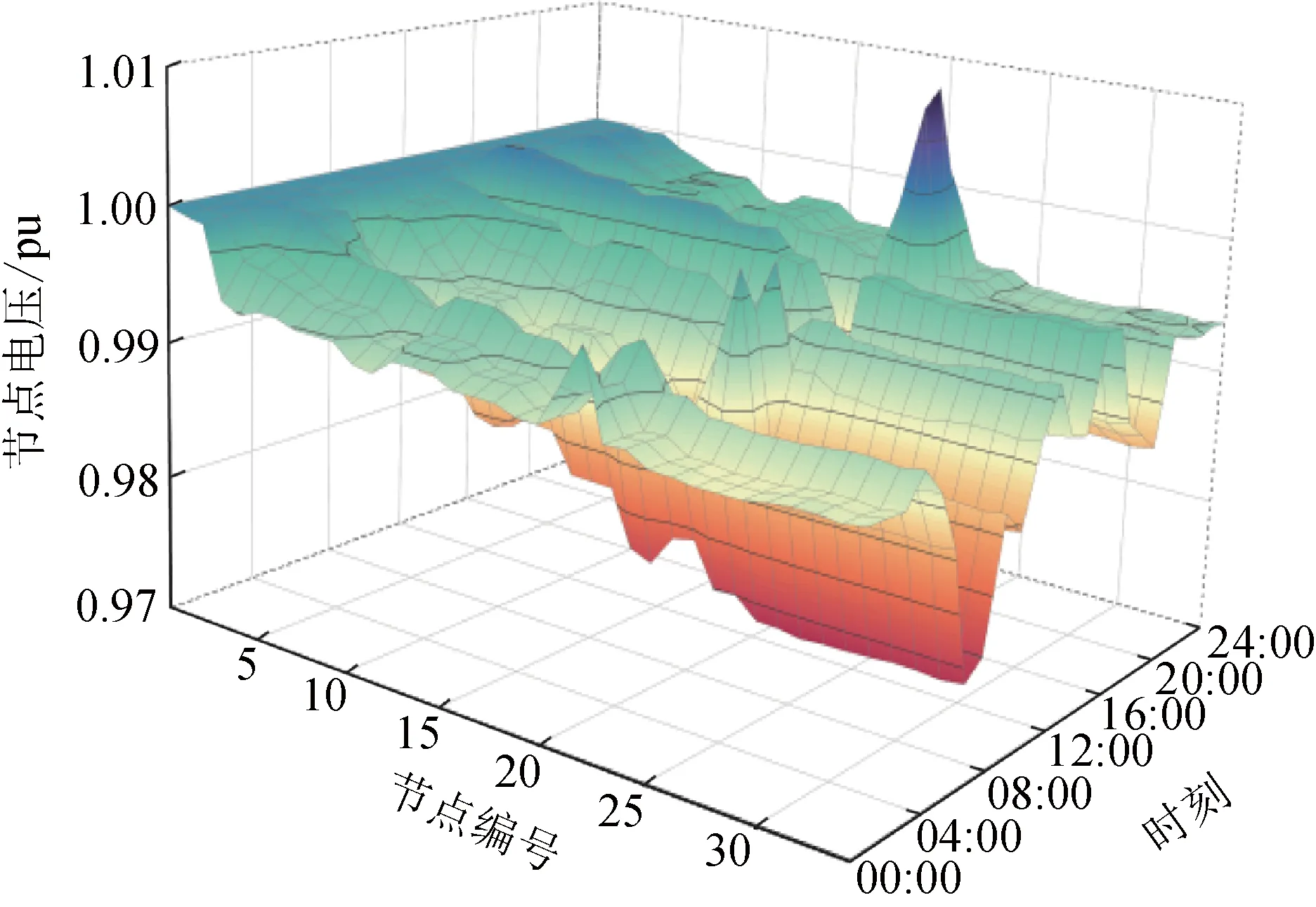
图7 不同节点的电压分布
从算例结果可以看出,经本文提出的PER-DDPG方法离线训练后,智能体能够在线调度ESS、MT、OLTC和SCB有功/无功资源动作,并与PV及WT协同作用,以具有成本效益的方式响应ADN电力负荷需求。该方法在新能源消纳、削峰填谷和需求响应等方面具有良好的效果。
4 结 论
本文针对ADN的有功-无功协调优化调度问题,在DDPG方法的基础上添加了PER机制,提出一种基于深度确定性策略梯度的主动配电网有功-无功协调优化调度策略。基于算例分析,得到如下结论:
1)本文所设计的MDP模型最大程度地模拟了ADN实际环境,不依赖于任何物理模型,避免了对新能源、负荷及电价的不确定性建模,具有实际应用价值。
2)采用本文所提出的PER-DDPG框架进行离线训练得到的最优神经网络模型可以在线生成ADN调度策略,能够有效解决电压和潮流越限的问题,并同时最小化日常运行成本。
3)在离线训练过程中,本文所提PER-DDPG方法相较于DDPG方法具有更高的未来折扣奖励和更快的收敛速度。
猜你喜欢
防爆电机(2021年4期)2021-07-28
中国特种设备安全(2021年11期)2021-05-05
铁道通信信号(2020年6期)2020-09-21
铁道通信信号(2020年10期)2020-02-07
成都信息工程大学学报(2019年3期)2019-09-25
小学生作文(低年级适用)(2019年5期)2019-07-26
三门峡职业技术学院学报(2019年1期)2019-06-27
中成药(2018年2期)2018-05-09
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
