
机器学习下网络平台文本的中文情感分析
2023-10-31 08:29孙昊男
黄河水利职业技术学院学报 2023年4期
孙昊男
(香港应用科技研究院,中国 香港 999077)
0 引言
网络平台里存在着大量带有情感态度的用户评论及其意见文本, 这些情感的发展会影响社会和谐与稳定。因此,分析网络平台文本中用户或博主的情感状态,判断其情感倾向与趋势已成为研究热点。情感分析是指对文本表达的情绪状态进行分析, 是一种利用自然语言处理技术来识别主观信息的任务实践。 它结合文本挖掘、信息提取、机器学习和自然语言处理等文本处理技术来分析、 处理和总结主观文本, 通过对网络文本数据进行量化来识别文本数据中隐含的情感态度和观点、探索用户的情感倾向。笔者主要应用朴素贝叶斯分类算法, 对中文情感分析的实现方法及流程进行研究。
1 机器学习下的关键技术
1.1 朴素贝叶斯分类算法
朴素贝叶斯分类算法(Naive Bayes)是一种统计概率模型算法。 该算法是基于统计学的一种分类算法,利用概率统计知识进行分类,其基本思想是使用单词和所属类别的联合概率估计给定评论所属类别的概率。
假设事件A 和事件B 是独立的,根据贝叶斯定理可以得出公式(1)。
式中:P(B|A)为在事件A 发生的情况下,事件B 发生的概率。
对于文本D,用一个n 维特征向量表示,则其联合概率计算公式为式(2)[1]。
式中:P(Cj|D)表示D 属于Cj的概率;P(D|Cj)表示Cj包含D 的概率。
选取P(Cj|D)的最大值,其对应的Cj即为D 的分类结果。 由于文本词之间具有独立性,P(Cj|D)可由式(3)~式(5)计算[2]。
式中:ti是文本D 中的单句;n 为训练数据量;N 为训练总量;a 为特征的出现次数;X 为固定平滑参数。
1.2 word2vec 转换向量法
Word2vec 是在神经网络语言模型(Neural Network Language Model,简称NNLM)基础上对神经网络结构进行的简化,包括连续词袋(Continue Bag Of Words,简称CBOW)模型和跳字(Skip-gram)模型这2 个重要模型。 它将词用固定维数的向量表示,实现词语相似性判断[3]。 Word2vec 转换向量法是一种将语句转为向量的方法, 其中包含Skip-gram 算法和CBOW 算法。 Skip-gram 算法是通过中心词来预测周围的词,而CBOW 算法则相反,它通过周围的词去预测中心词[4]。在处理自然语言时,使用向量表示词语,以向量空间表示语句,在将词语转化为向量之后,语句便会形成一个数字矩阵,通过这种方式将自然语言转化为数字。
1.3 Jieba 库分词
Jieba 是一个用于中文分词的第三方词库,包括精确模式、完整模式和搜索引擎模式3 种分词模式,能够对繁体中文进行分词,并支持自定义词典。它只需一个lcut()函数,即可掌握大部分分词功能[5]。
1.4 主观性文本识别
对原始材料信息进行分析和识别, 提取带有情感色彩的主观句子是汉语情感分析的前提。 文本中出现的情感词是主观文本识别的主要依据。 从目前的研究环境来看, 建立情绪词典和进行情绪词统计是主观性文本识别和提取的主要方法。
情感词典处理需要使用人工注释或机器统计来构建一个好的情感词典, 并将分割处理后的文本与词典进行比对,以识别原文的主客观性。在情感词典实验的基础上, 通过HowNet 知网构建一个更具自适应性的文本处理词典。 情绪词统计处理是指通过机器学习方法训练大量数据,生成可靠的数据模型,然后根据数据模型识别出需要处理的文本。
2 中文情感倾向性分析的整体流程
为实现中文文本的情感分析, 首先要对文本中各主观句的情感倾向进行分析,进而整合出整个文本的情感倾向。在实现对主观语句进行较为精准的分类基础上,先对单句情感倾向进行分析,评估影响因子,把倾向值累加起来,再对文本的情感值进行整合[6]。中文情感倾向性分析整体流程如图1 所示。
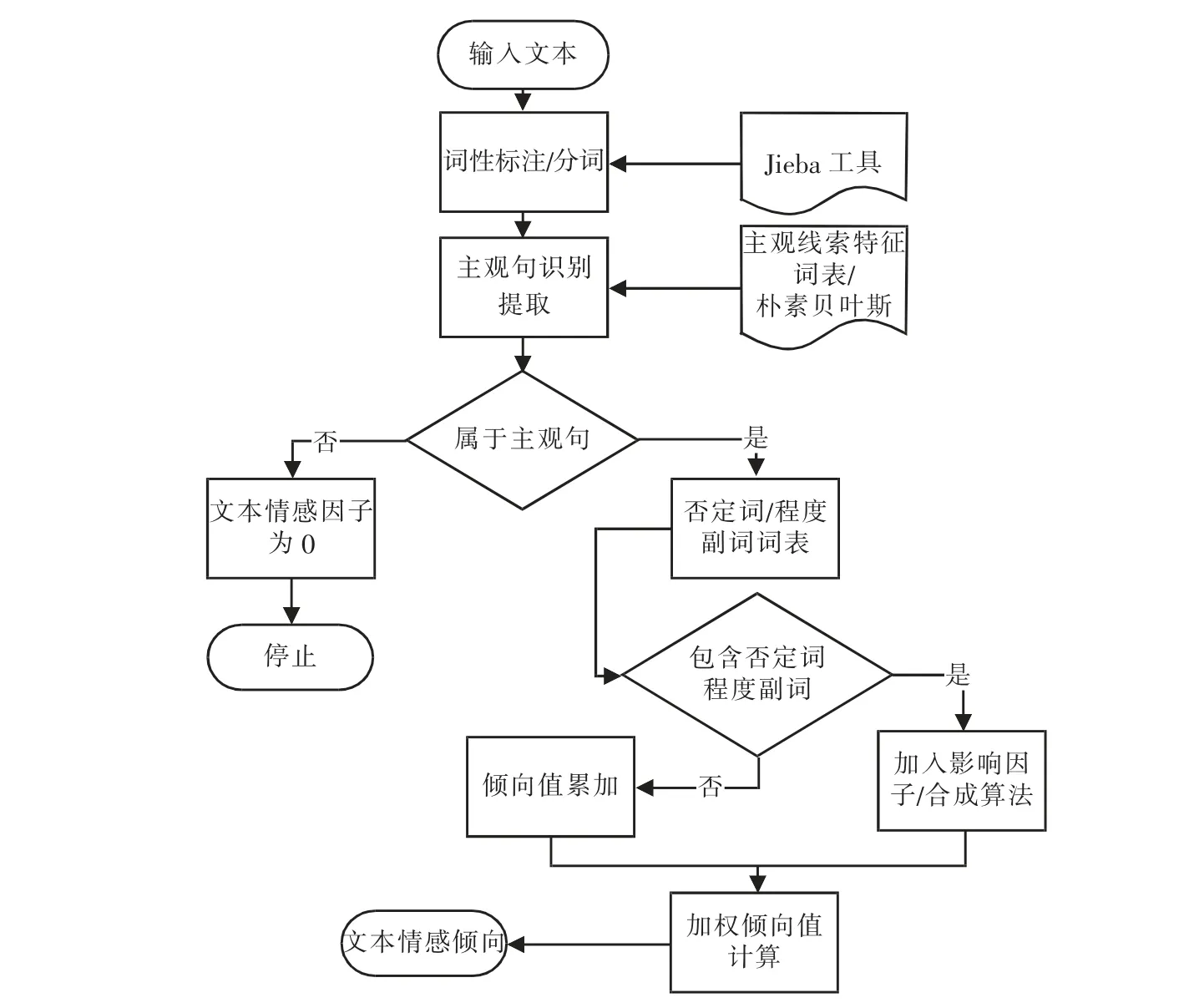
图1 中文情感倾向性分析流程图Fig.1 Flow chart of Chinese emotional tendency analysis
由图1 可知, 情感倾向性分析分为抽取情感信息、检索情感信息以及对情感信息分类3 个步骤。先将输入文本通过Jieba 分词工具进行分句、 分词及词性标注预处理,再根据主观线索特征词表,应用朴素贝叶斯分类器进行主观语句的识别和提取。
假设该文本情感倾向值为0,如果是主观句子,且其中不包含否定词或程度副词, 可以直接累积计算文本中每句话的情感倾向值。 如果主观句中包含否定词或程度副词, 则有必要根据否定词和程度副词的词表为句子分配相应的影响因子, 并使用自定义合成算法计算句子的加权情绪倾向值, 最后判断出文本的情绪倾向。
3 基于主观线索的主观性文本识别
主观线索特征本文主要采用情感词、 指示性动词、语气词、富有情感的字符、关联词等作为特征词。
3.1 情感词
情感词对语句的情感作用极为关键。 本文采用HowNet 知网情感词集,如表1 所示。
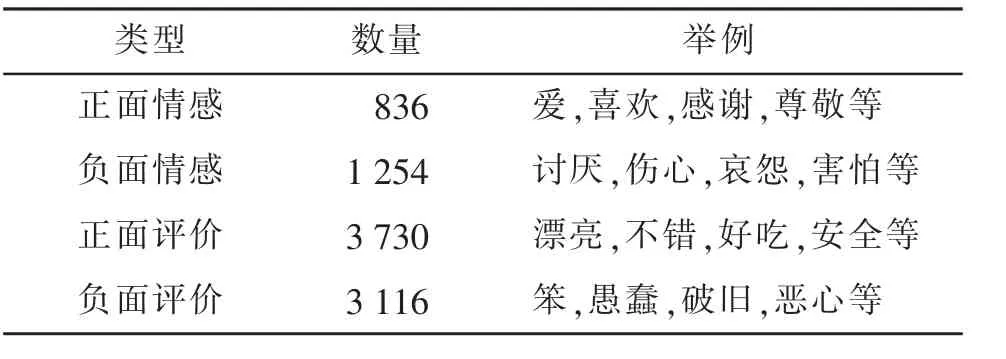
表1 情感词分布Tab.1 Distribution of emotion words
3.2 指示性动词
本文采用HowNet 知网指示性动词集, 如表2所示。

表2 指示性动词分布Tab.2 Distribution of indicative verbs
3.3 语气词
语气词主要协助输出情感,一般呈现出来的为主观句,如表3 所示。

表3 语气分布Tab.3 Distribution of mood
3.4 网络文化带有感情色彩特征词
具有情感特征的字符类似于程度副词, 在句子中具有强调情感的作用。 网络平台的文本存在着表情符号、颜文字和表情包等新兴网络语言。这些表情符号也会对句子的分类产生一定的影响[7],如表4所示。

表4 带有情感色彩的字符分布Tab.4 Distribution of character with emotional color
3.5 关联词
关联词是组合成复句的中间词, 具有一定的主观性,因此可将其划入文本识别特征词内,如表5 所示。

表5 常用关联词分布Tab.5 Distribution of common associatedd words
3.6 主观性判别实验及结果分析
3.6.1 实验数据
本次主、 客观句子分类实验中使用的语料集均来源于在线数据抓取。 通过Python 爬虫技术,爬取京东产品评价信息、微博娱乐数据、微博日常数据、热点时事数据等3 万条主观性网络评论, 爬取或搜集时政新闻、热播文章、新闻文案等3 万条客观性文本,共计6 万条可用数据,并手动标注,根据其主观或客观性质进行分类。 本次实验分传统朴素贝叶斯分类器实验组、 朴素贝叶斯分类器加泛用特征词实验组(不含关联词及感情字符)、朴素贝叶斯加本文整合的主观线索特征词实验组(下文统称为“本文方法”)3 个实验组,每个实验组共进行6 轮实验,实验设置如表6 所示。
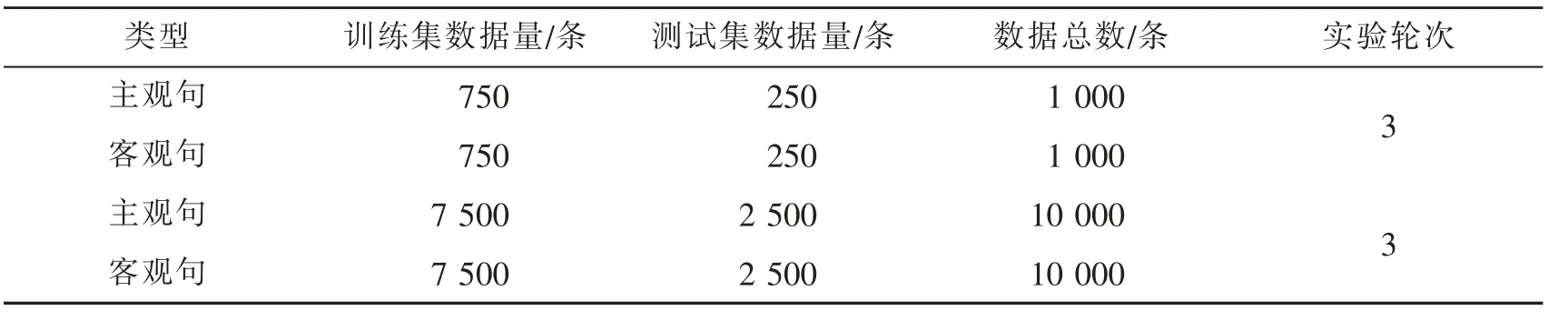
表6 训练和测试数据分布Tab.6 Distribution of training and test data
3.6.2 实验步骤
(1) 数据预处理。 本文采用中文分词第三方库Jieba 的精确模式进行分词,再借助哈尔滨工业大学提供的停用词表,从而准确去除停用词,完成实验数据的预处理工作,并赋予数据预处理代码。
(2)分词向量化处理。该步骤需要对处理后的数据进行向量化表示, 通过处理过程中存放的词典对向量的长度进行初始化, 最后使用Python 中的Sklearn 库的切分函数, 将X、Y 划分为训练集与测试集。以X 作为输入项向量,以Y 作为输出项向量。
(3)构建并训练模型。在该实验中,公式(1)所示的朴素贝叶斯算法概率公式可表示为式(6)。 所以,求解P(类别|特征)的问题便转换为求解P(特征|类别)、P(类别)、P(特征)。 由于各特征间具有相互独立性,P(特征|类别)采用式(7)计算。 式(7)中,各特征对应的P 值可采用式(8)求解。 P(类别)的计算式为式(9)。 通过全概率公式可知,本次实验仅主观和客观2 种类别,所以P(特征)的计算式为式(10)。
由于不论是求主观或是客观的概率, 都需要除以,因此,其对2 种概率都是无变化的,这里可直接忽略再进行比较[7]。
模型训练完后, 即可通过算法获取各类别对应的概率向量。为了解决零概率的问题,使用拉普拉斯平滑,贝叶斯公式分子项则可表示为式(11)。
以此通过朴素贝叶斯算法计算, 得到训练后的主客观句的模型向量。
(4)评估模型。 利用测试集构建评估模型,进行性能测试,代码实现如图2 所示。

图2 代码评估模型测试Fig.2 Test of code evaluation model
3.6.3 实验结果分析
实验统计结果如表7 所示,3 组实验结果对比分析图如图3 所示。
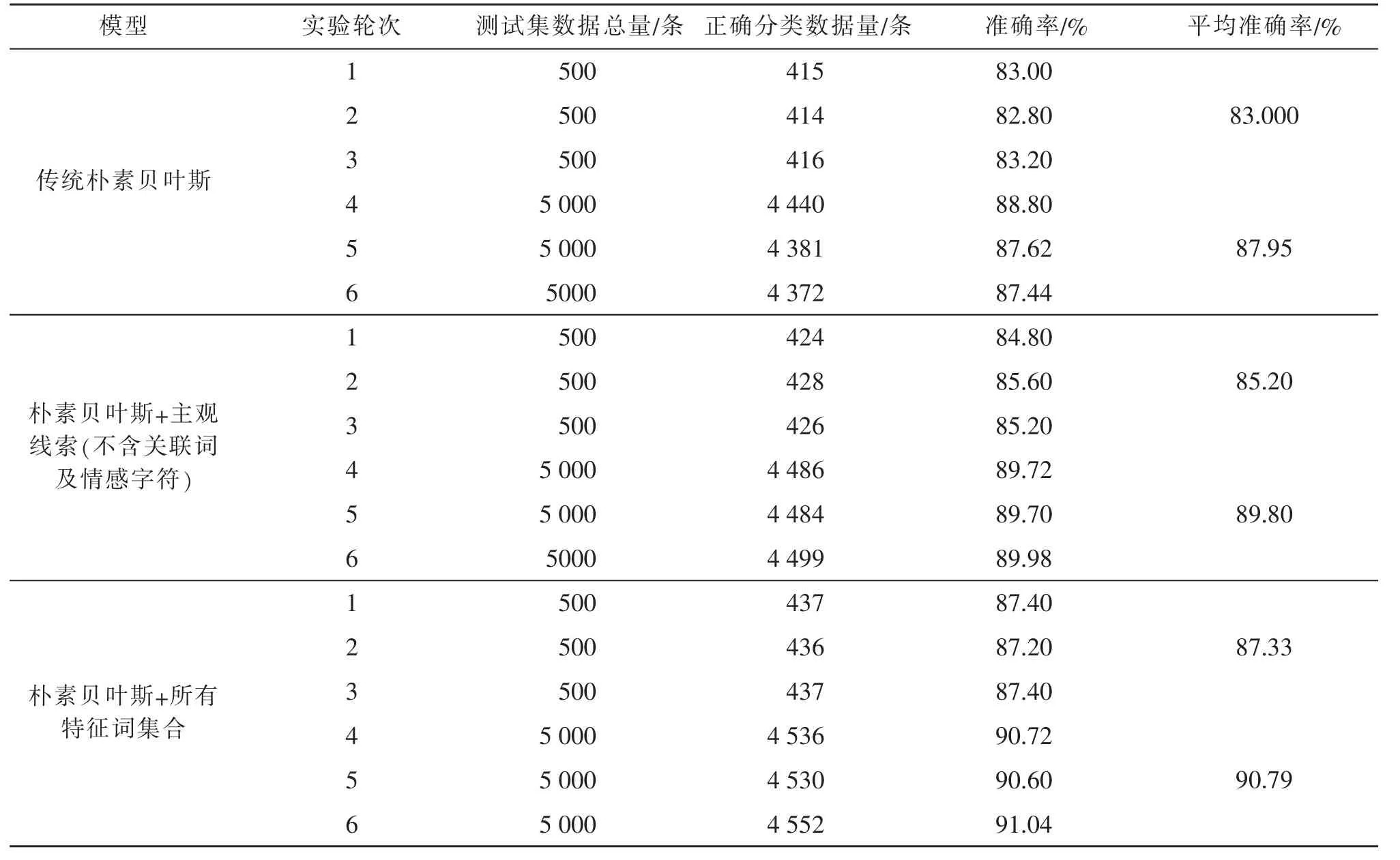
表7 实验结果统计Tab.7 Statistics of experimental results
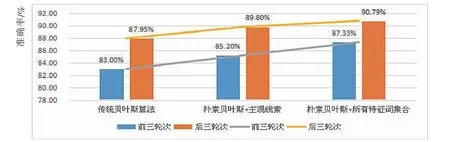
图3 3 组实验结果对比图Fig.3 Comparison diagram of experiment results of three groups
由表7 和图3 可知,对于同一种算法,数据量越大, 分析结果的准确率就越高; 在同等数据量条件下, 有主观线索特征选择过程的算法分析结果比传统的朴素贝叶斯算法的准确率表现更为优秀, 而添加了关联词和具有情感特色的字符作为特征选择的条件特征时,分析结果的准确率能够更高。
从实验结果可知, 在用贝叶斯算法针对某一事物进行判别时, 该事物可提供用于判断的特征线索越多,贝叶斯分类模型的准确率就越高,即模型向量更具有代表性。 本文提出采用更贴近网络新时代的新兴特征参与算法的训练过程, 不论是带有感情色彩的字符还是关联词,应用在不同类型网络文本中,都能影响语句的主客观性。 为了将这些新增的主观线索特征从句子中精确地提取出来, 还需要对停用词表的版本做出更适配当前分类方法的改进。 本文采用统计分析的方法不仅大胆地将固有停用词移除停用词表,还将其作为主观性判断特征利用起来。这种尝试具有一定的可行性及有效性。
4 整个文本的中文情感倾向分析
通过累加情感词的倾向值来计算文本整体的倾向值,再根据否定词和程度副词倾向值进行调整,得到一个相对准确的阈值。 当主观句的倾向性值高于阈值时,则为褒义;反之,则为贬义。当主观句的倾向性值等于阈值时,该句判为中性[8]。
4.1 倾向值累加
通常, 文本的情感倾向与各句中情感词的褒贬有直接联系。 通过使用HowNet 知网情感词集、评价词集作为词典对语句进行识别[9],情感词和文本Si情感倾向的贡献值θsi的函数关系如式(12)所示。
式中:Si为单个语句;Wsi是Si语句分词后的所有词的集合;ωj为集合Wsi中某一个词。
将α(ωj)的值设定为式(13)。
计算出文本内各句的α(ωj)值。 确定Si单个语句的θsi值后,再对所有语句累加,从而确定整体的情感。
4.2 否定词特征值
否定词可导致语句的情感极性逆转。 本文通过统计分析大量主观性文本,构建了包括非、别、不、没、无、别动、没有、不能、不足以等1 516 个否定词的否定词特征词集。
依据“双重否定表肯定”的自然语言规则,判定情感倾向性极性。若否定词出现奇数次,则情感倾向性的极性逆转;若否定词出现偶数次,极性不变。 因此, 得出否定词与情感倾向性极性的影响因子的函数关系,如式(14)所示。
4.3 程度副词特征值
程度副词作为语句中的修饰词, 能使词语的情感倾向强度发生变化,如非常、很、特别等词。本文采用HowNet 中的中文程度级别词集, 构建如表8 所示的副词表。

表8 程度副词分布Tab.8 Distribution of adverb of degree
中文程度级别词语表包含6 个程度等级, 对程度副词分别赋予因子值,范围0~4。 0~1 为减弱型,1~4 为增强型。 将程度副词与分词处理后的序列集进行匹配,赋予它相应的因子值,并将其与情感词相乘,以反映程度副词的强弱效果。程度副词的影响因子定义为式(15)。
在特征选择后,从句子中提取程度副词。 然后,根据程度词与影响因子的关系, 改进程度副词的编码,并通过代码中的级别level_num 控制影响因子,在倾向值累积之前对其进行影响。
综合倾向累加值、 程度副词及否定词与主观句情感倾向值的函数关系为式(16)。
式中:β(ωj)和γ(Si)分别表示程度副词、否定词的影响因子值;WSi是Si语句分词后的所有词的集合;ωj为词集合WSi中的某个词;α(ωj)为情感词置信度,褒义为1,贬义为-1,中性为0。
4.4 文本情感倾向合成算法
依据倾向值累加、否定词及程度副词3 种影响文本情感倾向性的因素,基于文本中各个句子的情感权重,构建合成算法,确定整个文本的情感倾向值。
4.4.1 确定文本情感倾向权重
整个文本的情感倾向值由构成文本的所有的主观句决定。 对这些语句的情感倾向值加权累加并取平均值,即为文本的情感倾向值。 其计算公式为式(17)。
式中:V(Si)为文本中第i 个主观句对应的情感倾向值。
由于互联网生成的数据信息的灵活性和可变性,源文本的个人用户在语言表达方面也存在差异。因此, 不同位置的主观句子对整个文本的影响都必然是不相同的。如,来源于网络的电影评论,“这部电影的女主角很丑。剧情也不优秀。但我还是喜欢男主啊! ”3 句话尽管都是主观句,前2 句有消极情绪倾向,只有最后1 句是积极的,但评论的最后1 句话情感倾向最强烈,因此给最后一句赋予最大的权重。
4.4.2 用合成算法计算情感倾向值
采用式(18)计算情感倾向值V(para)[10]。
式中:V(Si)代表各句在进行初步情感分析后所给予的情感倾向值;γ(Si)代表否定词对语句的影响因子;α(ωj)代表程度副词为语句带来的影响因子。
4.5 加权倾向值计算实验与实验结果分析
4.5.1 实验数据
实验采用weibo_senti_100k 数据集, 该文件数据来源于新浪微博,搜集了12 万条评论数据,其中正负向评论各6 万条,且均经过标注分类。
本次实验每个实验组共进行6 轮, 前3 轮每轮取不同的2 000 条数据, 其中褒义文本和贬义文本各1 000 条,750 条用于构成训练数据集,250条用于构成测试数据集; 后三轮每轮取不同的2万条数据, 其中褒义文本和贬义文本各10 000条,7 500 条用于构成训练数据集,2 500 条用于构成测试数据集。
4.5.2 实验步骤与实验评价指标
(1)实验步骤同3.6.2。
(2)实验评价指标。 采用式(19)计算准确率P。
4.6 实验结果分析
4.6.1 实验环境
本次实验设置4 组,分别为:无权值影响的倾向值累加实验组、 仅包含否定词影响因子的加权实验组、仅包含程度副词的影响因子的加权实验组,以及合成算法实验组。每个实验组共进行6 轮实验,其中前3 轮与后3 轮数据量不同。实验结束后,计算每一轮实验的准确率, 并将前后3 轮准确率的平均值进行对比,结果如表9 和图4 所示[11]。
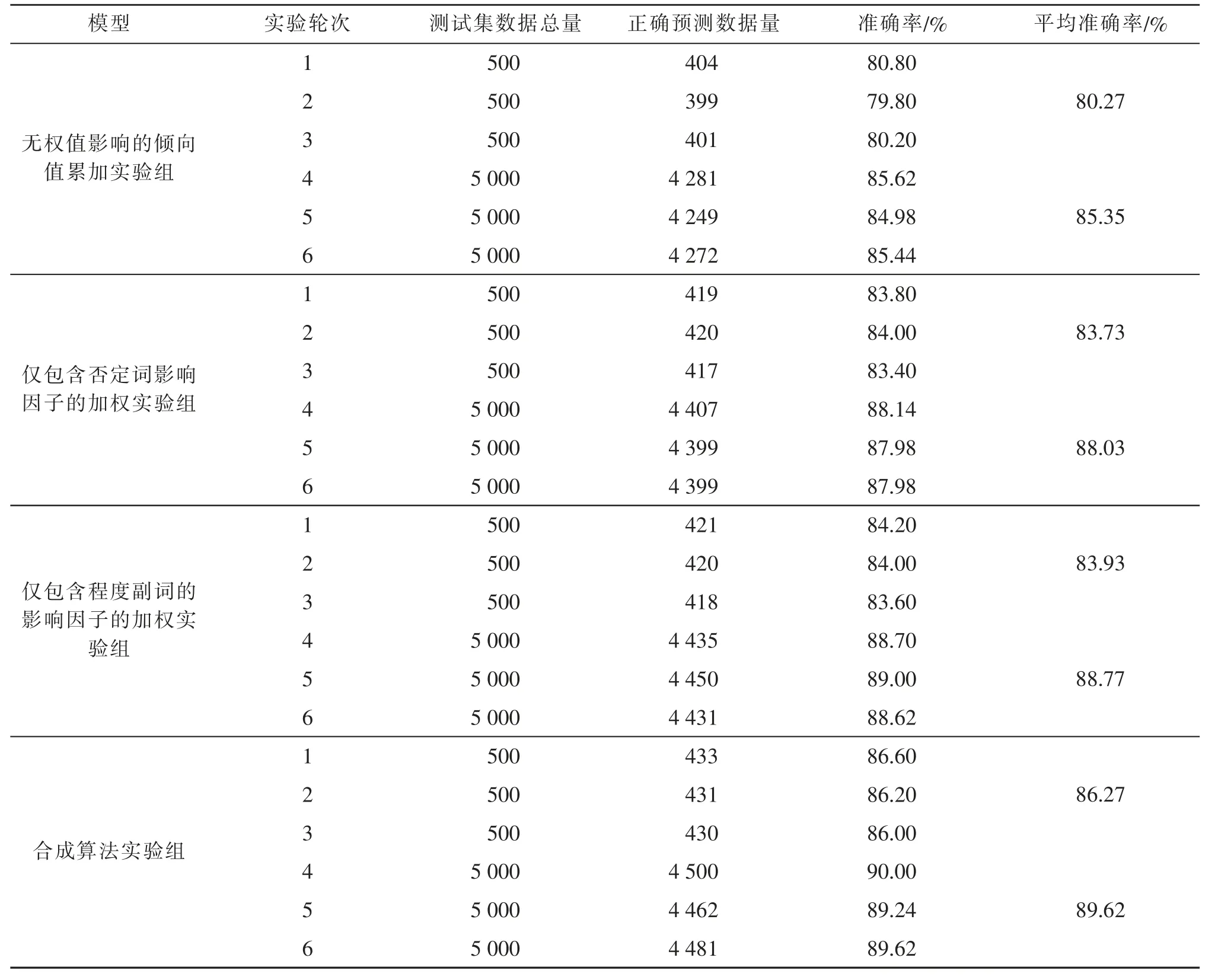
表9 实验统计结果Tab.9 Experiment statistical results
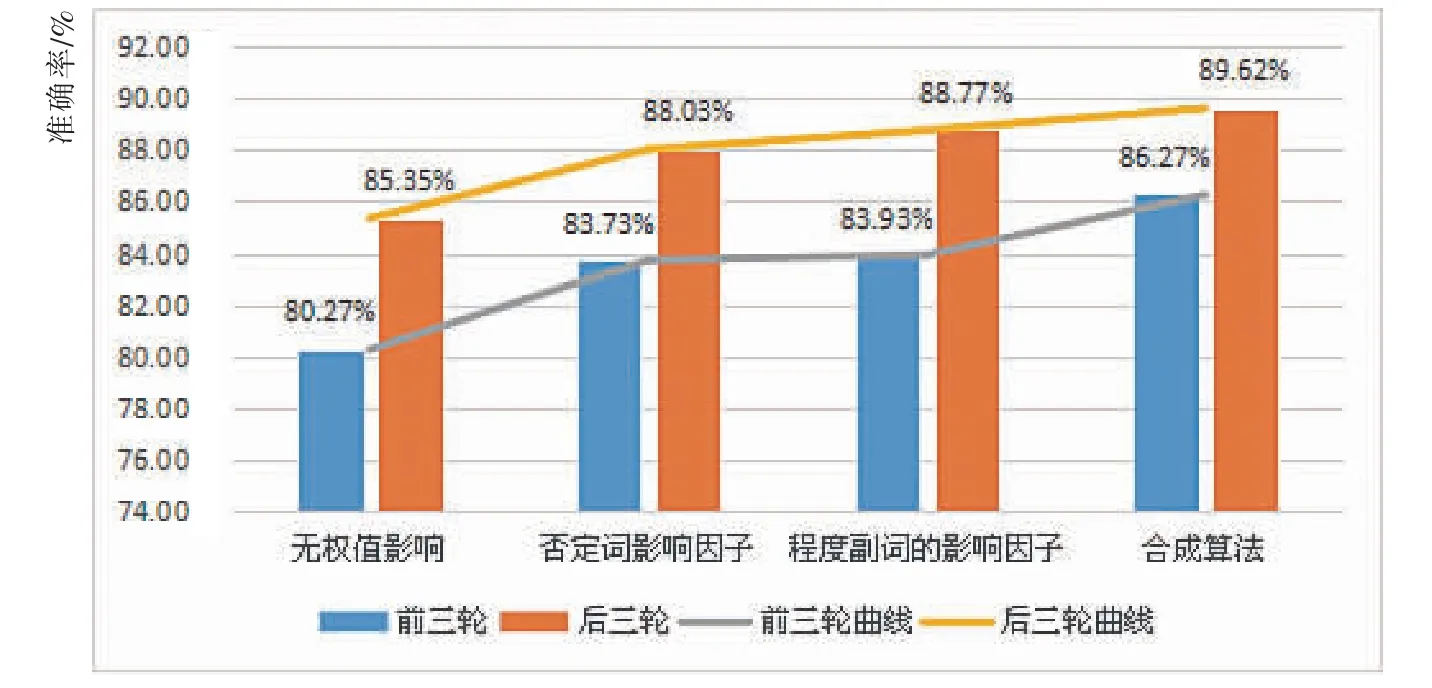
图4 三组实验对比分析图Fig.4 Comparison analysis diagram of experiment results of three groups
4.6.2 实验数据分析及结论
由表9 及图4 可知,对于同1 种算法,数据量越大,计算结果的精度就越高;在数据量相同时,影响因子在衡量文本中每一句话的权重方面起着至关重要的作用。在否定词和程度副词的影响下,与传统的朴素贝叶斯算法相比, 有主观线索特征选择过程的算法计算结果更准确。 合成算法将两者的影响因素结合起来,精确率也得到了提高。 这说明,当给予分类模型提供更多的数据特征时, 可以更好地训练出精度更高的模型向量。
从否定词和程度副词对分类准确性的个体影响来看,两者差异不显著。程度副词的影响略好于否定词, 但这并不证明程度副词比否定词具有更好的分类特征。
5 结语
实验结果表明, 要准确计算出整段文本的情感倾向值,需对单个语句进行加权处理。即采取将主观句分为总结性主观句和一般主观句的方式实现加权操作, 并通过自定义合成算法计算出文本的情感倾向值。通过实验,验证了根据不同语句在文本内的权重不同赋予相应权值的方法切实可行, 并且该方法将计算准确率维持在相对较高的水平。 本文结合语句的权重分析提出了自定义合成算法的雏形, 为后续探索基于单个语句权重的文本情感倾向分析的方法提供了参考。
猜你喜欢
阅读(快乐英语中年级)(2023年6期)2023-05-24
三门峡职业技术学院学报(2021年4期)2021-04-19
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
高中生学习·高三版(2014年3期)2014-04-29
郑州大学学报(理学版)(2014年2期)2014-03-01
