
人工智能在自然语言处理中的应用
2023-10-31 06:58房伟伟
信息记录材料 2023年9期
房伟伟,韩 猛
(聊城职业技术学院 山东 聊城 252000)
0 引言
自然语言处理(natural language processing,NLP)是人工智能领域中的一个重要方向,致力于使计算机能够理解和处理人类语言[1-2]。随着社交媒体和在线论坛的广泛应用,大量用户生成并分享了海量的文本数据,使得暴力言论、仇恨言论等不良信息的传播成了一个日益严重的问题[3-4]。在此情况下,发展有效的自然语言处理技术来自动检测或过滤暴力言论变得尤为重要。长短期记忆网络(long short-term memory,LSTM)作为一种重要的深度学习模型,具有良好的序列建模能力,特别适用于处理文本数据[5-6]。其能够捕捉文本中的长期依赖关系,并具有一定的记忆能力,这使它在自然语言处理任务中表现出色。
本文旨在研究基于LSTM模型的暴力言论检测系统,提出了一种基于LSTM的架构。通过在网络文本数据上进行测试,验证了该架构的有效性和可行性。本文首先对LSTM网络进行了详细的介绍,解释了其结构和工作原理;其次提出了一种基于LSTM的暴力言论检测架构,该架构利用LSTM网络对输入的文本进行建模,并通过训练从中学习到暴力言论的特征表示;最后,使用网络爬虫抓取了大规模的网络数据,并构建了一个相应的数据集,以评估所提出的架构在实际环境中的性能。
本文的研究成果对于社交媒体平台、在线论坛以及其他涉及用户生成文本的应用领域具有重要的实际意义。通过自动化检测和过滤暴力言论,可以维护网络空间的安全和健康发展,减少恶意行为对用户的伤害。同时,本文还为基于深度学习的自然语言处理研究提供了一种新的思路和方法。
1 基于LSTM模型的暴力言论检测
1.1 LSTM网络
LSTM是一种具有记忆能力的递归神经网络,被广泛应用于序列建模任务中。其独特的结构使其能够有效地捕捉长期依赖关系,对于处理自然语言处理等序列数据具有重要意义。该网络包含输入层、隐藏状态和输出层三个基本结构,如图1所示。

图1 LSTM的基本结构
LSTM的输入层接收序列数据,通常是文本、语音或时间序列数据,在每个时间步中,输入均被表示为向量形式。假设在时间步t时,输入向量为x(t)∈Rn,其中,n是输入向量的维度。
LSTM中的隐藏状态由两个部分组成,分别是细胞状态和隐藏状态。细胞状态负责存储和传递长期记忆信息,而隐藏状态负责在网络中传递和共享信息。细胞状态的更新通过遗忘门、输入门和输出门的控制来实现,遗忘门决定了细胞状态在当前时间步保留多少以前的信息,输入门决定了当前时间步的输入信息对细胞状态的更新程度,输出门决定了细胞状态的输出到隐藏状态的程度。细胞状态C(t)的更新方式为式(1)所示:
C(t)=f(t)⊙C(t-1)+i(t)⊙g(t)
(1)
式(1)中,⊙表示逐元素相乘操作,f(t)是遗忘门的输出,i(t)是输入门的输出,g(t)是候选细胞状态,通过当前输入和先前隐藏状态计算得到。隐藏状态h(t)的计算通过输出门对细胞状态进行调整为式(2)所示:
h(t)=o(t)⊙tanh(C(t))
(2)
式(2)中,o(t)是输出门的输出,tanh是双曲正切函数,用于引入非线性变换。
LSTM的输出层根据具体任务的需求而定。对于分类任务,通常使用softmax激活函数将隐藏状态映射到预测类别的概率分布。假设有K个类别,LSTM的输出向量h(t)∈Rm,其中m是隐藏状态的维度。通过线性变换和softmax激活函数,可以将隐藏状态映射到K维的预测概率向量y(t)∈RK:
y(t)=softmax(W(h(t))+b)
(3)
式(3)中,W和b分别是可学习的权重和偏差。
1.2 系统架构
基于LSTM的暴力言论检测架构旨在利用LSTM来自动识别和过滤暴力言论。该架构基于文本输入,通过LSTM网络对输入文本进行建模,并学习到暴力言论的特征表示,如图2所示。
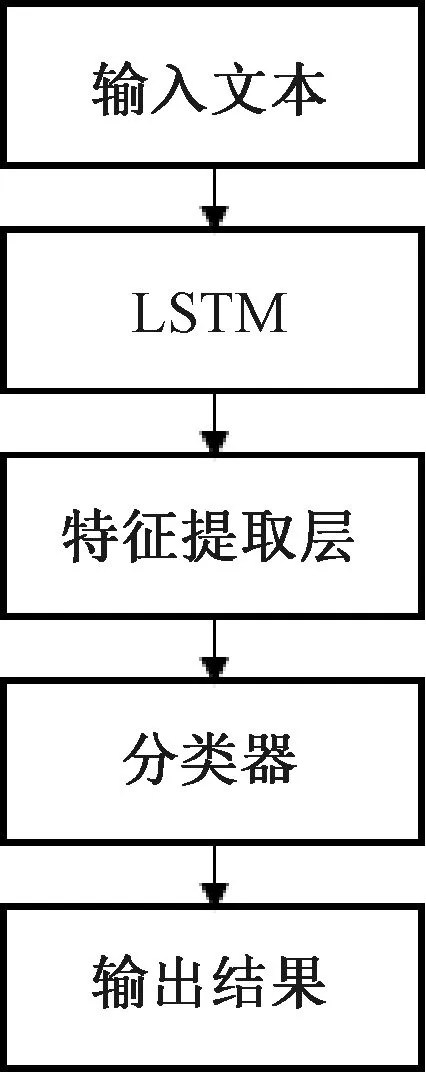
图2 基于LSTM的暴力言论检测架构
(1)输入层:该架构接收文本作为输入,通常是用户生成的文本数据,如社交媒体帖子、评论或论坛发言等。输入文本经过预处理,转化为向量表示。
(2)LSTM层:输入文本的向量表示被馈送到LSTM网络中。LSTM网络由多个LSTM单元组成,每个单元负责处理一个时间步的输入。通过将输入文本序列逐步输入LSTM单元,网络能够对文本中的上下文信息进行建模,并捕捉长期依赖关系。LSTM单元中的遗忘门、输入门和输出门机制对细胞状态进行更新和调整,从而提供丰富的文本表示。
(3)特征提取:LSTM网络的隐藏状态可以看作是对输入文本的编码表示。为了从中提取有关暴力言论的特征,可以在LSTM层之后添加一些附加的全连接层或卷积层。这些层可以进一步处理LSTM的隐藏状态,以捕捉更高级的语义和结构信息。通过特征提取的过程,网络能够学习到更具区分性的暴力言论特征表示。
(4)分类器:在特征提取之后,得到的特征向量被输入到分类器中进行最终的分类判别。分类器可以采用多种算法,例如支持向量机[7-8]或多层感知器[9-10]。本架构采用支持向量机对特征进行分类。
给定一个训练数据集{xi,yi},其中xi是输入的特征向量,yi∈{-1,1}表示样本的类别标签。支持向量机通过最大化间隔的思想来进行分类,其中间隔定义为超平面到最近的样本点的距离。支持向量机的分类决策函数可以表示为式(4)所示:
f(x)=sign(wTx+d)
(4)
式(4)中,w是超平面的法向量,d是偏置(偏移)项,sign是符号函数,用于根据函数值的正负来判定样本的类别。
支持向量机的目标是找到最优的w和d,使得分类决策函数能够正确地将样本分为不同的类别,并且间隔最大化。这可以转化为一个优化问题,即最小化目标函数,同时满足约束条件。通常使用凸优化方法来求解这个问题。支持向量机的优化问题可以表达为式(5)、式(6)、式(7)所示:
(5)
subject:yi(wTxi+d)≥1-ξi,i=1,2,…,n
(6)
ξi≥0,i=1,2,…,n
(7)
式(5)、式(6)、式(7)中,||w||2是权重向量||w||2的L2范数的平方,C是正则化参数,用于平衡间隔和分类误差的权衡,ξi是松弛变量,用于处理样本的不可分性。通过求解上述优化问题,可以得到最优的超平面参数w和d,从而构建支持向量机分类器。
2 实验与分析
2.1 数据获取
本研究用网络爬虫对微博评论进行爬取,并将部分文本界定为暴力言论。在此过程中,首先选择Scrapy网络爬虫工具[11-12]对微博平台上的评论进行抓取,通过设置爬虫的初始链接和抓取规则,可以遍历微博的相关页面,提取评论数据;在爬取评论数据后,对数据进行预处理和文本清洗,包括去除HTML标签、特殊字符和表情符号,并进行分词和去除停用词等操作,以获得干净的文本数据。其次通过将评论数据与相应的标签关联,可以建立一个训练集,这些数据集包含正面样本(暴力言论)和负面样本(非暴力言论)。
2.2 模型训练和测试
在使用数据集对基于LSTM的暴力言论检测架构进行训练和测试的阶段:
(1)数据集划分:将准备好的数据集划分为训练集和测试集。采用交叉验证的方法,将数据集分为80%训练模型,剩下的20%用于评估模型的性能,并确保训练集和测试集的样本分布和类别平衡。
(2)构建LSTM模型:基于LSTM的暴力言论检测架构需要构建一个包含LSTM层、特征提取层和分类器的模型。通过定义合适的网络结构、层数和节点数,以及选择合适的激活函数、优化算法和损失函数,建立一个有效的模型。在训练过程中,需要设置合适的超参数,如学习率、批次大小和迭代次数等。
(3)模型训练:使用训练集对LSTM模型进行训练。将清洗和预处理后的评论文本数据输入到LSTM模型中,通过反向传播算法和梯度下降优化算法,更新模型的权重和偏置,以最小化损失函数。训练过程中,监控模型在训练集上的损失和性能指标,确保模型能够逐渐收敛并学习到评论文本的特征表示。
(4)模型评估:在训练过程完成后,使用测试集对训练好的模型进行评估。将测试集的评论文本输入到模型中,通过前向传播算法获得预测结果,并将其与真实标签进行比较。使用评估指标,包括准确率、召回率、F1分数等,来评估模型在暴力言论检测任务上的性能。
2.3 分析与讨论
本研究用准确率、召回率和F1分数对该架构的评估结果如表1所示。

表1 模型评估
对于暴力言论类别,模型正确预测了85个样本,错误预测了15个样本,总共有100个正样本。对于非暴力言论类别,模型正确预测了180个样本,错误预测了20个样本,总共有200个正样本。通过计算准确率、召回率和F1分数,可以进行数据分析。
准确率表示模型正确预测的样本占所有预测结果的比例。在该实验中,暴力言论和非暴力言论类别的准确率分别为0.85和0.9,这意味着模型在预测暴力言论和非暴力言论时分别有85%和90%的准确性;召回率衡量模型对正样本的识别能力,即模型能够正确预测多少个正样本,暴力言论和非暴力言论类别的召回率分别达到了0.85和0.9;暴力言论和非暴力言论类别的F1分数分别达到了0.85和0.9。这表明模型在暴力言论和非暴力言论的预测中有较好的平衡性能。
3 结论
综上所述,本文开发了一种基于LSTM的暴力言论检测系统,并对其在自然语言处理中的应用进行了验证。实验结果表明,该系统在检测暴力言论方面具有良好的性能和准确性。通过合理设计和训练LSTM模型,能够准确地识别和分类暴力言论,为社交媒体平台和在线社区提供一种有效的工具来过滤和管理不当言论。然而在进一步研究和应用中仍存在一些挑战和改进空间:(1)数据集的构建和标定需要更加精细和全面,以提高模型的鲁棒性和泛化能力;(2)优化模型的超参数选择和调整,以进一步提升性能指标的表现。此外,还可以考虑引入更多的特征工程和深度学习模型优化方法,以提高暴力言论检测的精度和效率。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
环球时报(2022-03-09)2022-03-09
湘潮(上半月)(2021年4期)2021-07-20
湘潮(上半月)(2021年3期)2021-07-20
汽车工程(2021年12期)2021-03-08
作文成功之路·小学版(2020年3期)2020-04-21
智族GQ(2019年12期)2019-01-07
电信科学(2017年6期)2017-07-01
小学生必读(低年级版)(2017年11期)2017-03-15
电测与仪表(2015年22期)2015-04-09
