
基于深度学习的行为识别系统及关键技术
2023-10-31 06:57韩培珊吴滢滢熊茂华通信作者
信息记录材料 2023年9期
韩培珊,吴滢滢,熊茂华(通信作者)
(1 广东外语外贸大学南国商学院 广东 广州 510545) (2 广州商学院信息技术与工程学院 广东 广州 511363)
0 引言
近年来,国内外众多学者在深度学习(deep learning,DL)、人群异常行为检测、目标跟踪、视觉认知分析与神经机理、多视角步态识别、群体分析等领域均取得了非常多的研究成果。
对于DL早期采用低级视觉特征描述方法,如:轨迹、方向梯度直方图(histogram of oriented gradient,HOG)、光流直方图(histogram of flow,HOF)、混合动态纹理(mixtures of dynamic textures,MDT)和光流场等。主要研究视频行为描述、行为建模、行为分类和智能视频检测方法,如:轨迹特征分析法、单阶段的视频行为检测、动态混合纹理模型、光流场模型等,还有基于对数似然比(log-likelihood ratio,LLR)算法、子空间聚类算法、基于三维方向梯度算法和稀疏重构算法;深度神经网络(deep neural networks,DNN)、多任务卷积神经网络(multi-task convolutional neural network,MTCNN)、循环神经网络(recurrent neural network,RNN)等算法。
目前,行为检测中广泛采用的方法有[1]:①局部特征提取的方法;②基于三维时空的特征角点的检测方法,即以子空间聚类的算法和分类器结合进行姿态识别;③新型的智能马尔科夫逻辑网络,即基于时空的动作关联网络,其作用是提高体姿态动态识别效果;④消除摄像机抖动或运行而影响视频行为特征提取的改进增强型特征提取方法与算法;⑤对光流图像进行优化的增强改进型密集轨迹算法等。
1 系统的结构
1.1 系统的拓扑结构与主要功能
系统的拓扑结构如图1所示。系统的主要功能包括:

图1 系统拓扑结构
(1)基于迁移学习的目标检测。首先从标准数据集中学习检测子,再根据实际监控数据特性将检测子从标准数据集中迁移过来。
(2)基于多任务深度学习的行为识别与分析。采用硬参数共享方式,在网络的卷积层采用共享的参数。
(3)基于多视点多尺度的行为摘要与检索。采用多视点的行为摘要分析有助于从多个角度分析描述行为,且多个摄像头下的协同操作能够应对复杂环境下的遮挡等干扰。在后端的检索过程中,借助多维度多尺度的信息作为特征,从而实现快速精准的检索。
(4)行为智能分析的应用。嵌入新的行为分析模块,其中包括:可疑行为检测,如徘徊、遗留物品等;违规行为检测,如绊线、逆行等;行为检索,如设立不同的标注,检索出满足标注行为的目标片段等。
1.2 智能视频行为分析算法的框架与流程
智能视频行为分析算法流程如图2所示。分为行为检测、目标识别和行为分析3个层次[2]。
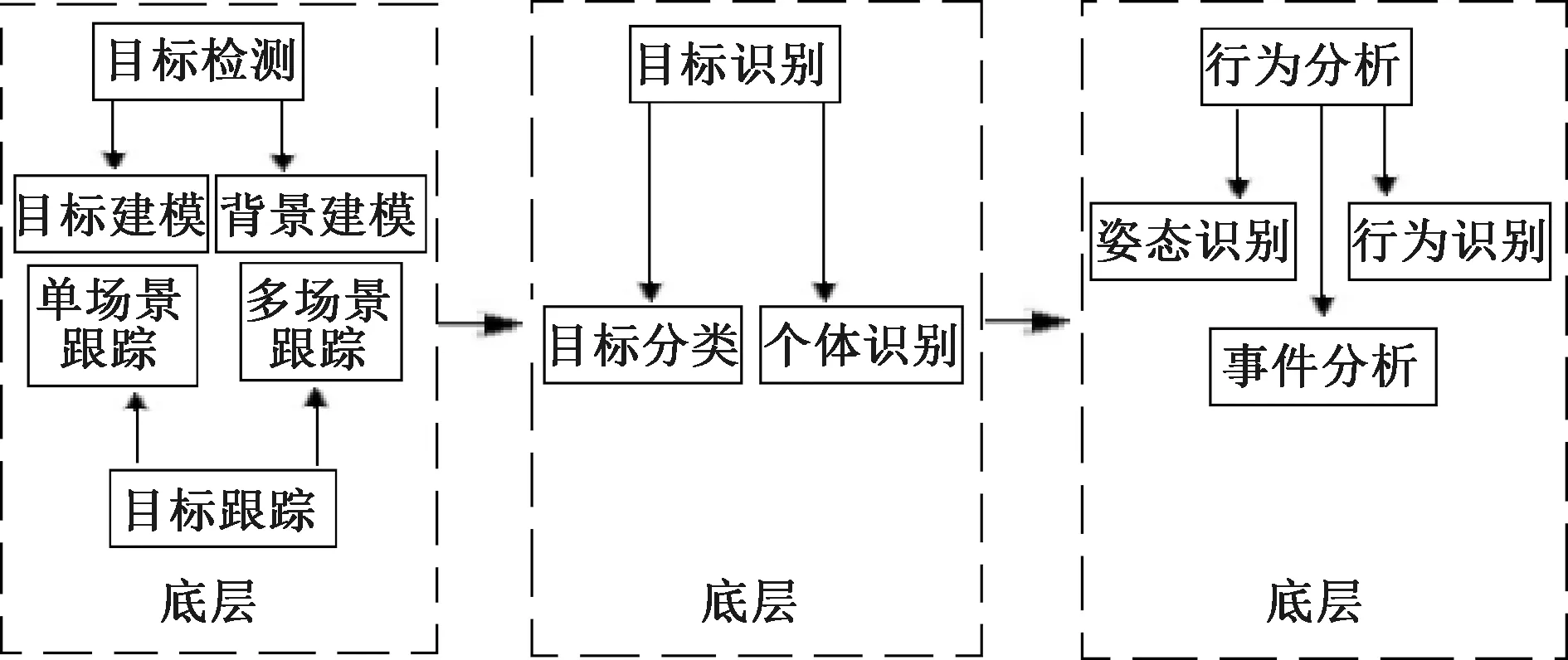
图2 智能视频行为分析算法流程
(1)行为检测是属于行为分析系统算法流程的最底层,行为分析系统在前端是用行为图像获取装置来采集实时动态的图像帧,过滤、去噪后对目标和背景进行建模、分析,完成目标检测。目标跟踪是通过视频图像的场景来选择采用单场跟踪还是多场景跟踪,最终可获得运动目标的运动时间、活动位置、运动方向、运动速度、目标大小和外表属性等相关信息。
(2)目标识别是属于智能行为分析系统算法流程的中间层,对所获取的运动目标信息进行分析、推测,再用智能分类算法和智能目标识别算法进行目标识别。
(3)行为分析是属于智能行为分析系统算法流程的高层,借助智能行为分析算法,依据目标场景、语义场景、应用场景和背景场景等复杂场景,对行为姿态识别、异常行为识别和行为事件分析。
2 系统的技术实现方案
2.1 基于迁移学习的目标检测技术
系统中目标检测技术的应用场景为视频监控系统,不同的应用场景和视点视角所采集的真实目标检测数据与现有常用的人体检测数据集不同,且规模更大,包含的目标姿态信息更丰富,目标背景也更复杂和更具多样性。系统采用基于迁移学习的目标检测算法,将已有的人体数据集作为源域,实际监控视频中所得到的视频数据作为目标领域,从原始领域向目标领域进行迁移学习。即使在现有实际场景标注样本较少的情况下,依然能够从源域数据(已有标注数据集)得到有效迁移信息,从而得到准确的分类器和检测器。基于迁移学习的目标检测算法,如图3所示。

图3 基于迁移学习的目标检测算法
首先,通过目标检测获取原始领域样本,采用相应的样本选择策略对样本进行二值分类,由样本分类器分析、判断检测窗口中是否包含有运动目标,并进行样本标记。然后,从包含运动目标的窗口中获取目标领域内样本和图像;目标领域样本经样本筛选智能算法分析推测,获取检测的目标。其次,采用基于迁移学习的目标检测算法先对原始领域样本训练、分类、标记,以获得目标领域样本;再对目标领域未标记的样本进行检测、分类、标记。最后,对目标领域样本训练、进行权重、学习和计算,训练出更加适合目标领域的目标检测器,以获得更理想的检测结果。
2.2 基于多任务深度学习的行为识别与分析技术
主流的异常行为识别技术有基于图像异常行为识别和基于视频异常行为识别。基于单幅图像的行为识别缺乏了运动信息,不能使用传统的时空特征编码静态图像中的行为,而基于视频的行为识别则可以从时空块中提取低层特征,如视频时空兴趣点(spatio-temporal interest point,STIP),对不同行为进行分类。单看一张图像可能难以对其中的某一动作进行区分,而对视频联系前后关联,则可以轻松地对目标行为进行识别与分析[3]。
在行为识别的过程中,由于可标记的样本数量少,因此更需要多任务学习方式来避免目标任务的过度拟合。基于多任务深度学习的异常行为识别技术是一种机器学习方法,若多个任务之间有关联且并行学习或对于学习结果存在互相影响,则可采用联合学习方法。
2.3 基于多视点多尺度的行为摘要与行为检索技术
2.3.1 多视点的行为摘要技术
在多视点行为分析过程中,多摄像头网络之间的时间拓扑结构能够对视频数据中的目标进行相应的时空约束,从而可实现基于多摄像机网络拓扑结构的多视点摘要分析。根据多摄像头提供的相关冗余信息,可融合多摄像头重叠视域的行为摘要模型,对多视角下的目标动作与行为进行协同表达与摘要分析。融合多时空尺度下的目标运动信息,实现对视频数据的层次化摘要分析与描述。
在构建过程中需考虑多视点视频之间不同的属性关系,如时间邻近性、内容相似性和高层语义特征联系等。具体的构建方法:超图中的每个节点代表从视频中提取的画面,而超边则对应画面之间的一种类型的属性关系,最后将超图转换成一个有权重的时空镜头图,图上的边权值就可以定量的衡量多视点视频之间的联系。这样复杂而庞大的多视点视频数据可以转化为图问题的求解了。在此基础上,可以结合前期行为分析中所计算的指标计算与视频的低级视觉特征,如色彩、运动向量等进行视频画面的重要性评价,从而更有针对性的提取特征。
2.3.2 多尺度的行为检索技术
当前的视频检索多是通过从原始数据中挖掘各种特征作为线索,然而单一的基于内容的视频检索模型难以充分挖掘视频本身所蕴含的丰富语义信息,从而难以得到精准的检索结果。系统将侧重研究多维度的视觉信息之间融合,从各维度数据的相关性出发,获取更具丰富语义信息的高层次特征,从而实现精准有效的检索。此外,在检索过程中,从之前视频行为分析的多任务学习过程中,视频行为被打上了不同的语义标签,不同的语义标签可以整合成独立的检索模块,形成子检索模块,采用随机森林策略,将不同的子检索模块看成是一个个弱分类器,根据不同的深度决策树原则进行模型设计与优化求解[4]。
3 智能视频行为分析的部分算法实验对比
3.1 异常行为检测常用数据集
异常行为检测数据集包括个体异常行为检测数据集和群体异常行为检测数据集2大类[5]。异常行为检测数据集非常多,主要有UCSD、UCF、RWC、UCF-Crime、UMN、VIF、PETS和MALL等。
(1)个体异常行为检测的数据集
① UCSD像素级数据集,异常种类包括骑自行车、滑冰、小推车、行人横穿人行道、侵入草地等。
② UCF视频级数据集,包含的人群和其他高密度移动物体的视频。
③ RWC视频级数据集,是运动的个人轨迹。
④ UCF-Crime视频级数据集,异常种类包括打斗、抢劫、纵火、逮捕、爆炸、事故等。
(2)群体异常行为检测数据集
① UMN帧级数据集,异常种类包括人群四处逃散、人群单方向跑动、聚集等。
② VIF帧级数据集,包括人群暴力行为,为检验暴力/非暴力分类和暴力标准提供测试依据等。
③ PETS视频级数据集,包含了多传感器的不同人群的活动序列。
④ MALL帧级数据集,MALL数据库有密集十字路口交通流视频和购物中心的视频2个子集。
异常行为检测数据集大多数都可用于低密度人群或单人行为的检测与识别,但部分只能用于群体异常行为检测。
3.2 不同场景下的目标跟踪对比
异常行为检测的场景和目标对象对其目标跟踪的特性起关键作用。不同的场景与不同的目标其跟踪特点不同,同一场景下的不同目标,其跟踪特性也不尽相同。
表1列出了单场景目标跟踪、重叠场景、非重叠场景等目标跟踪算法的特点。

表1 目标跟踪算法与特点
(1)对于单场景目标跟踪要求时空连续,这种单场景目标跟踪算法特别适应于对单个目标的持续跟踪。对前景目标建模,可将跟踪看作是前景和背景的二分类,通过学习分类器,在当前帧搜索得到与背景最具区分度的前景区域,即判别式跟踪。可按目标跟踪策略精准定位跟踪,目标跟踪与目标检测可同步进行。
(2)在重叠场景目标跟踪中,采用多摄像头从多视角对目标检测,若出现重叠目标场景,目标就会从一个场景进入另一个场景,可用连续的空间关系确定进入新场景的目标身份;也可用单应性矩阵关联不同场景下的目标,精准推演计算目标在对应场景下的位置。
(3)在非重叠场景目标跟踪中,场景之间盲区可能导致同一目标在不同摄像机获取目标信息中的时空信息缺失,从而造成目标跟踪的难度,可采用摄像机网络拓扑估计和跨摄像机目标再识别算法解决此问题。
4 结语
综上所述,行为分析系统中主要是以传统机器学习算法进行视频行为识别与分析、以手工特征描述行人外观和运动特征,构建特征空间。系统采用的技术方案,即基于迁移学习的目标检测技术、基于多任务深度学习的行为识别与分析技术、基于多视点多尺度的行为摘要与检索技术等,能较好地实现视频行为的检测、识别与分析,尤其在三维时空的多视角点的检测、姿态动态识别效果良好。克服了单一的视频行为识别与分析方法易产生盲区、单视点等弱点,具有较高的实用价值。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
意林图解作文(小学版)(2019年6期)2019-07-16
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
专利代理(2016年1期)2016-05-17
中国老区建设(2016年1期)2016-02-28
河南电力(2016年5期)2016-02-06
新闻前哨(2015年2期)2015-03-11
中国水利(2015年5期)2015-02-28
质量与标准化(2010年5期)2010-05-03
