
基于注意力机制与画像的旅游路线推荐研究
2023-10-31 11:39:38李晓芳顾亦然
软件导刊 2023年10期
李晓芳,顾亦然,2
(1.南京邮电大学 自动化学院、人工智能学院;2.南京邮电大学 智慧校园研究中心,江苏 南京 210023)
0 引言
近年来,我国旅游消费趋势大幅上升。目前国内旅游业提供的基础设施、公共服务,特别是个性化旅游产品和旅游服务无法满足游客日益增长的多样化需求,且随着大数据技术的兴起,游客旅游需求的大数据化以及情境化趋势日益显著[1-3]。旅游路线推荐离不开用户旅游需求的驱动,如何从海量旅游大数据中挖掘出与用户需求精准匹配的景点资源[4],从而规划出科学合理的旅游路线成为大数据时代亟待解决的新课题。
1 相关研究
1.1 推荐算法
传统推荐算法中,协同过滤算法应用广泛。例如,Hwang 等[5]构建了用户—景点评分矩阵,使用协同过滤算法预测景点得分实现了个性化推荐,但在旅游推荐领域,用户旅游信息比一般产品的数据信息更为稀疏,因此推荐效果不甚理想;艾静超[6]提出基于地理位置的旅游路线推荐改进协同过滤算法,为游客推荐满足其旅游偏好的景点,所推荐路线不存在交叉重复现象,使游客时间花费降低1h 以上;郑淞尹等[7]结合景点热度、用户相似度以及时间上下文等信息提出景点推荐模型;Liu 等[8]通过构建“用户—区域—季节”隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型来捕捉游客之间的潜在关系,以解决协同过滤算法常见的数据稀疏问题;Qian 等[9]基于概率矩阵分解算法构建了景点推荐模型,该模型可以增强潜在空间中各项特征之间的内在联系,实现了对冷启动用户的个性化推荐。然而,上述研究仅考虑了单一维度的用户-景点交互行为,忽略了其他交互行为所包含的信息,以及不同交互行为之间的联系,降低了推荐系统的准确性,且并未考虑用户情境信息,因此也无法满足用户的情境化需求。
情境化推荐在图书馆领域应用广泛。例如,刘晓艳等[10]从上下文信息中充分提取读者偏好,提出一种矩阵分解推荐算法,有效提高了图书推荐的准确性;习海旭等[11]采用德尔菲法确定移动图书馆服务的情境因素,搭建了移动图书馆传统服务拓展原型系统,提升了图书馆资源推送的服务质量和整体效率;张潇璐等[12]通过融入情境因素,基于改进受限玻尔兹曼机的协同过滤算法实现了移动情境下的用户所需知识资源推荐。目前对游客情境化需求的研究还很少,例如郭斌等[13]运用卷积—循环神经网络联合嵌入游客旅游记录中的图像与文本,按照景点进行分类识别,然后筛选出具有多样性、代表性的图片,基于关联规则挖掘得到针对游客不同情境需求的推荐路线。
1.2 用户画像
用户画像是一种刻画用户特征、反映用户需求、描述用户兴趣的重要手段[14-15],能够为个性化服务提供数据支撑和理论支持,其由交互设计之父Alan Cooper[16]提出,目的是尽可能全面细致地获取用户信息。用户画像应用广泛,例如王斐等[17]引入用户画像进行二次推荐,有效改善了推荐效果;李宝[18]构建了多维度用户画像,提出高校图书馆个性化推荐服务策略;魏玲等[19]为提升工作效率与服务水平,构建了集用户画像与协同过滤于一体的知识付费平台推荐模型;崔春生等[20]根据用户基本信息和行为信息构建用户画像,根据用户相似度和使用情境进行高质量推荐;Husain 等[21]根据用户偏好建立用户画像,同时结合其当前位置提供适宜的旅游信息;Ravi 等[22]从用户社交网络数据中挖掘其兴趣点进而生成用户画像,基于此推荐的旅游路线及快速又准确;刘海鸥等[23-24]将用户画像与资源画像融合起来对馆藏资源进行高效利用,提高了移动图书馆推荐系统的服务质量。
为提升旅游路线推荐服务中的用户体验,本文全面考虑用户情境信息及其旅游需求偏好,充分挖掘用户与景点之间不同类型的交互行为以及不同交互行为之间的相关性,提出一种基于注意力机制与画像技术的旅游路线情境化推荐方法AMPT(Attention Mechanism and Profile Technology)。该模型首先引入情境信息构建饱满的用户画像,同时提出景点画像的概念以深度刻画景点属性;然后设计两种注意力机制:①画像注意力机制综合考虑用户与景点之间不同类型的交互以及不同交互行为之间的相关性,弥补用户—景点交互数据稀疏的缺陷;②文本注意力机制加强局部特征与整个文本序列的相关性,学习文本信息中最有价值的语义信息;最后将带有注意权重的交互行为特征向量和文本特征向量作为深度因子分解机(Deep Factorizations Machine,Deep FM)模型的输入,进行评分预测。在去哪儿网真实数据集上的实验结果表明,AMPT 模型的推荐性能优于其他比较模型。
2 模型构建
本文提出的AMPT 模型结构如图1 所示。首先将数据集中的所有特征作为输入,通过Embedding 嵌入层转换为稠密特征向量;然后使用画像注意力机制学习用户与景点之间不同交互行为的相关性,进而得到用户和景点的隐向量,同时使用文本注意力机制对用户和景点文本进行特征学习,获得景点与目标用户关联度最高的部分;随后在Fusion 层将交互行为特征向量与文本特征向量进行融合;最后使用Deep FM 模型进行评分,其中因子分解机(Factorization Machine,FM)和深度神经网络(Deep Neural Network,DNN)分别用于处理低阶特征和非线性高阶特征,通过线性变换分别得到两个部分的输出结果,对结果进行加权求和,通过Sigmoid 函数得到AMPT 模型最终的预测得分。
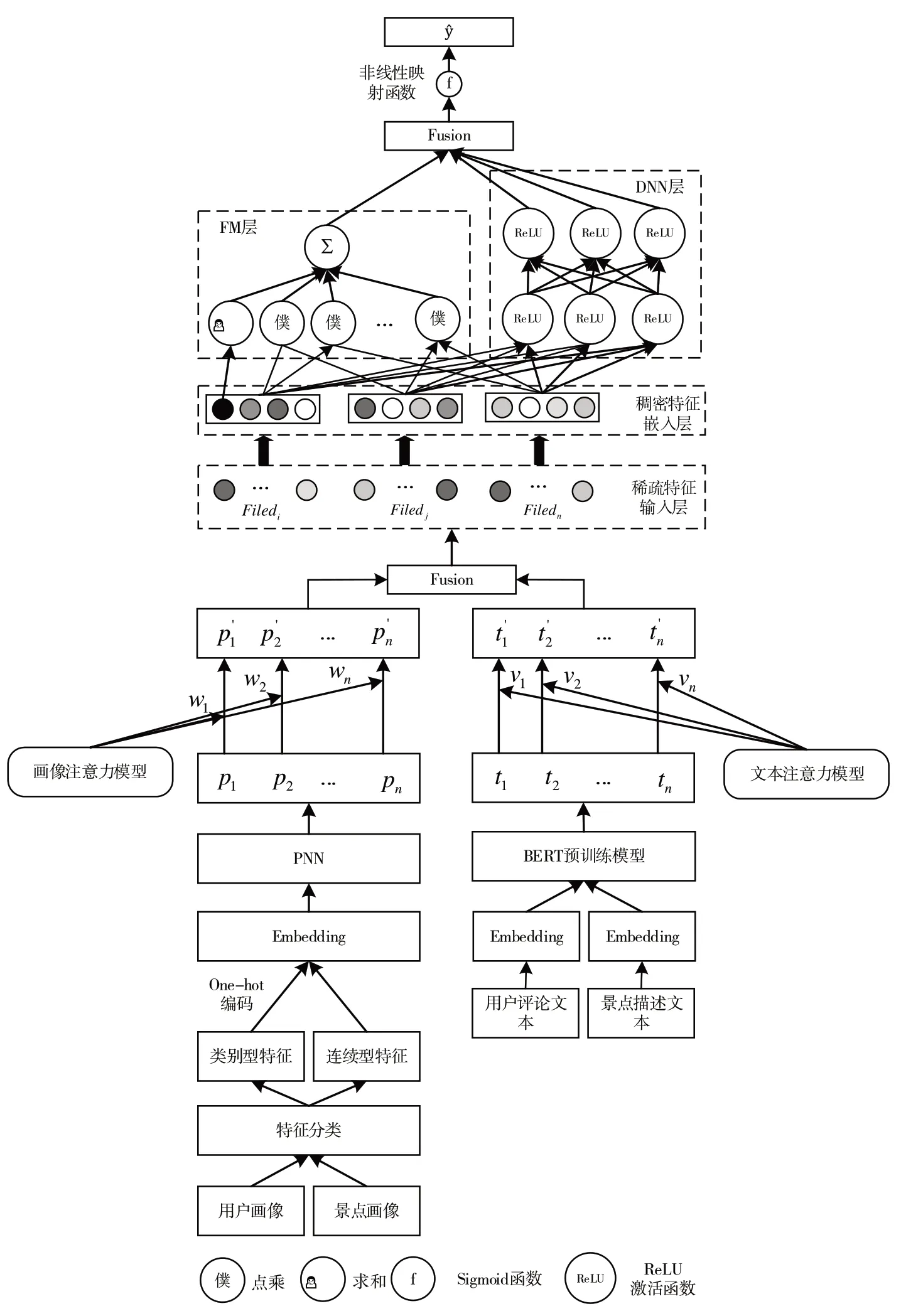
Fig.1 Architecture of AMPT model图1 AMPT模型结构
2.1 画像构建
用户画像可以体现用户特征。本文选取自然属性、行为特征与情境信息3 个维度构建用户画像,选取基本信息、旅游类型、聚类标签3 个维度构建景点画像[25-26],并通过提取不同粒度的标签建立“标签—类别—关键词”三层次旅游类型标签体系,用于构建景点旅游类型模型。三层次旅游类型标签体系结构如图2所示。
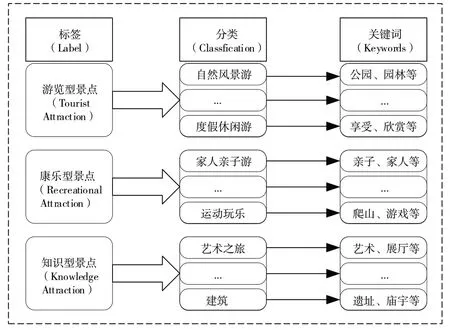
Fig.2 Three-level tourism type labeling system structure图2 三层次旅游类型标签体系结构
2.2 特征提取
本文设计的画像具有类别型和连续型两种类型的特征,为便于对两种类型的特征进行交叉,需要将其同时映射至相同低维特征空间中。类别型特征需要进行One-Hot编码(One-Hot Encoding),将其转化为数值向量;而连续型特征可直接映射至低维嵌入空间中,每一个连续型特征在嵌入空间中都对应一个特征向量。用户与景点的交互记录具有高维且稀疏的特点,基于乘积的神经网络(Productbased Neural Network,PNN)模型在Embedding 嵌入层之后引入显式二阶交互层,可以很好地对高维稀疏矩阵进行特征学习,因此本文使用PNN 模型提取用户画像与景点画像的特征。首先将高维稀疏的特征映射至低维稠密特征空间中,将输入的特征映射为稠密向量;然后使用画像注意力机制学习用户与景点交互行为的相关性;最后使用PNN模型提取用户特征、景点特征以及带有注意力权重的交互特征,得到用户隐向量和景点隐向量。PNN 模型结构如图3所示,其损失函数表示为:

Fig.3 PNN model structure图3 PNN模型结构
文本特征提取模块首先通过Embedding 嵌入层得到用户文本和景点文本的向量表示,并将其映射至低维嵌入空间中得到对应的特征向量;然后引入文本注意力机制用于学习包含最多价值的语义信息;最后使用BERT((Bidirectional Encoder Representations from Transformers)预训练模型得到文本特征向量。
2.3 注意力机制
注意力机制的网络结构如图4 所示。上下文向量为编码器输出向量h1,h2,…hj的加权和;向量h1,h2,…hj由权重αij进行缩放,能够捕获输入向量与预测输出之间的相关程度,因此能够确保解码器在预测输出时专注于更具价值的部分。上下文向量的计算公式表示为:
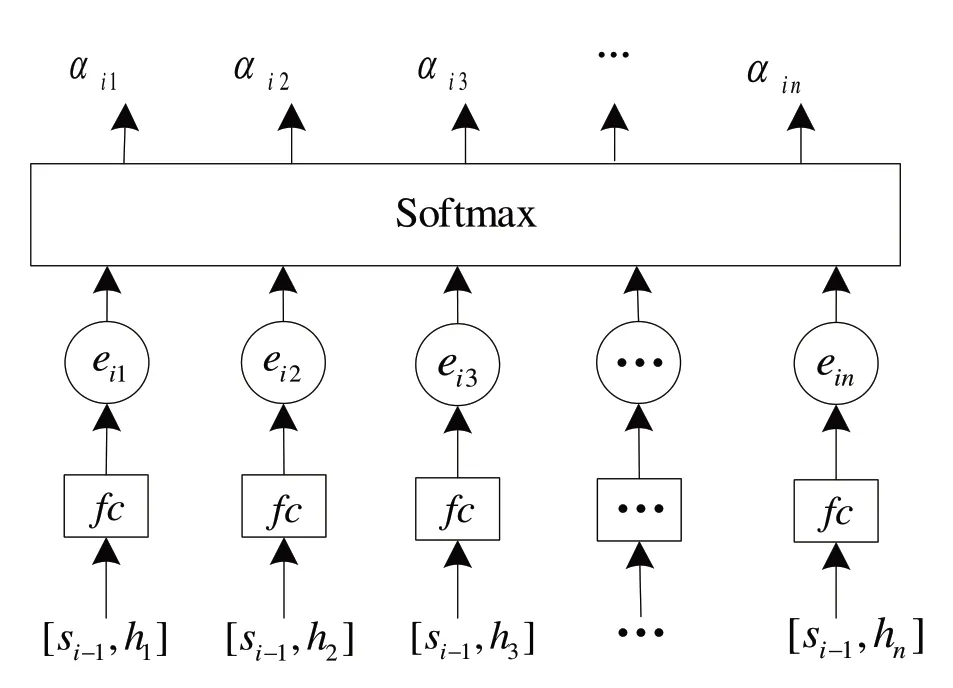
Fig.4 Attention mechanism network structure图4 注意力机制网络结构
为突出重点交互行为特征和文本特征的贡献,本文通过画像注意力机制和文本注意力机制计算每个特征的权值,为输入的向量序列更新权重。多层感知机具有多层神经网络结构,能有效提取高阶非线性特征,因此本文采用多层感知机计算交叉特征之间的相似度。计算公式为:
式中:pm表示交互行为特征矩阵P中第m个交互行为特征向量;p1…n表示所有交互行为特征向量;tm表示文本特征矩阵T中第m个文本特征向量;t1…n表示所有文本特征向量。
对计算得到的相似度进行归一化处理,可以得到每个特征向量的注意力权重。计算公式为:
式中:wm表示交互行为特征矩阵中第m个交互行为特征向量的注意力权重系数;vm表示文本特征矩阵中第m个文本特征向量的注意力权重系数。
分别使用wm和vm表示交互行为特征权重系数和文本特征权重系数,拼接所有特征向量的注意力权重系数得到交互行为注意力权重系数矩阵A(P)和文本注意力权重系数矩阵A(T)。表示为:
分别将注意力权重系数矩阵与交互行为特征矩阵和文本特征矩阵进行乘积操作,得到更新后带权重信息的交互行为特征矩阵P'和文本特征矩阵T',分别表示为:
将交互行为特征向量与带权重信息的交互行为特征矩阵P',以及文本特征向量与带权重信息的文本特征矩阵T'相乘,得到特征交叉的最终表现形式。表示为:
最终全连接层的输出表示为:
式中;W表示权重矩阵,b表示全连接层的偏置。
2.4 评分预测
Deep FM 模型并行集成了FM 层和DNN 层,其中FM 层能对一阶特征和二阶组合特征进行全建模,并且可以通过嵌入层得到每个特征对应的非零嵌入向量;而DNN 层的多层感知机可以很好地提取高阶非线性特征,弥补了FM层的缺陷。因此本文采用Deep FM 模型预测评分,其中FM 模型的输出表示为:
式中:w0表示常数项偏置,wi为第i个特征分量的权重,xi表示向量中第i个特征分量,xj表示向量中第j个特征分量,wij表示第i个特征分量与第j个特征分量的交互值,n表示样本的特征个数。前两项之和表示线性部分,第3项表示二阶特征交叉部分。FM 模型可以通过内积计算没有交互数据的两个特征之间的相似度,确保特征学习的完整性和连贯性。
DNN 模型的隐层输出表示为:
式中:wk表示第k层权重值,bk表示第k层偏置。
通过Fusion 层对FM 模型与DNN 模型的预测结果进行归一化,得到最后的预测结果。归一化公式为:
式中:非线性映射函数f(·)为Sigmoid 函数,β为折衷系数。
3 实验方法与结果分析
3.1 数据集
目前缺少包含用户景点交互记录的公共数据集。去哪儿网是国内最大的旅游分享网站之一,因此本文使用爬虫技术在去哪儿网上收集真实数据,以此自建数据集。本文数据集包含1 117 个景点信息、10 604 个用户信息、29 348 条景点描述文本以及43 569 条用户评论。景点信息包含名称、地理位置、等级、排名、门票价格、历史评分、建议游玩时长,附近路段拥堵系数,车均延误时长等;用户信息包含ID、性别、年龄、历史旅游记录、历史搜索记录、所处月份等。将80%的数据集作为训练集,20%的数据集作为测试集用于模型性能评估。
3.2 评价指标
采用准确率(Accuracy,A)、精确率(Precision,P)、召回率(Recall,R)、AUC值作为评价指标,并采用平均绝对误差(Mean Absolute Error,MAE)衡量本文预测结果与真实得分之间的误差[27]。分类矩阵如表1所示。表中TP表示正向样本预测为正向样本的个数,TN表示负向样本预测为负向样本的个数,FP表示负向样本预测为正向样本的个数,FN表示正向样本预测为负向样本的个数。

Table 1 Classification matrix表1 分类矩阵
根据TP、TN、FP和FN计算准确率A、精确率P、召回率R,具体计算公式分别表示为:
AUC值的计算公式为:
式中:pNum表示正样本数量,nNum表示负样本数量;pi表示正样本预测得分,nj表示负样本预测得分。
平均绝对误差MAE的计算公式为:
式中:ru,i表示用户u对路线i的实际评分;表示用户u对路线i的预测分数;n表示测试数量。
3.3 实验结果分析
为验证本文提出的AMPT 模型的优越性,选择逻辑回归(Logistic Regression,LR)、DNN、FM、卷积神经网络(Convolutional Neural Network,CNN)、PNN、Deep FM 等主流推荐模型作为对照,在自建数据集上进行性能比较,结果如表2所示。可以看出,本文模型表现最佳。

Table 2 Experimental results表2 实验结果 (%)
4 结语
为使游客旅游体验度更佳、花费代价更小,本文提出一种基于注意力机制与画像的旅游路线情境化推荐模型,使用画像技术充分建模用户与景点之间的相关性,同时使用两种注意力机制分别学习文本内容的语义信息以及用户和景点交互的非线性特征,弥补了传统推荐算法依赖单一维度信息的缺陷,增强了推荐性能。在自建真实数据集上的比较实验结果表明,本文模型性能优于其他6 个常用推荐模型。今后拟在模型中增加多模态信息,如用户和景点视频、图片、用户社交信息等,以进一步提升推荐效果。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
小哥白尼(神奇星球)(2022年3期)2022-06-06 07:39:34
保定学院学报(2022年2期)2022-04-07 02:26:50
新世纪智能(高一语文)(2020年9期)2021-01-04 00:42:42
非公有制企业党建(2020年10期)2020-10-27 06:30:14
意林·全彩Color(2018年7期)2018-08-13 09:35:24
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
海外星云(2016年7期)2016-12-01 04:18:07
Coco薇(2015年11期)2015-11-09 13:19:52
