
边缘计算中多服务器协同任务缓存策略
2023-10-30 08:58马世雄葛海波
计算机工程与应用 2023年20期
马世雄,葛海波,宋 兴
西安邮电大学 电子工程学院,西安 710121
随着超高清视频、虚拟现实、自动驾驶等新兴互联网业务的大量涌现,用户对于计算型服务的需求不断增多,仅靠云计算技术不能有效地响应越来越多的用户任务需求[1]。边缘计算被视为克服上述问题的有效方法之一[2]。其主要形式为将云服务器的计算和存储能力下降到网络边缘的服务器(例如基站),使其能够作为云服务器的替代品满足终端用户的大多数需求。
大多数边缘计算的相关研究都隐含地假设边缘服务器可以执行从用户卸载的所有类型的计算任务,却没有考虑到相应任务在边缘服务器上的可用性,即对应任务是否缓存在边缘服务器上[3]。因此,任务缓存(也称服务缓存)是目前边缘计算的研究的热点之一,其主要内容为:在边缘服务器(edge server,ES)中缓存应用服务程序及其相关的数据,从而使相应的计算任务能够被执行[4]。由于边缘服务器距离终端设备更近,其处理任务的时延相比云服务器会显著降低,也减少了传往云服务器的流量传输,减轻了传输网络的传输压力。但是由于边缘服务器内存容量和计算能力有限[5],它不能缓存所有用户的任务,将不合适的任务缓存到边缘服务器上,会浪费边缘服务器的内存资源和计算资源,并降低用户体验。因此,确定一个合理的任务缓存策略对于边缘服务器来说极为重要。
任务缓存决策的制定面临着一些挑战。首先,之前的研究一般假设任务请求是已知的[6],但这与现实情况有一些偏差。移动设备的任务请求绝不是一成不变的,用户的个性化的任务需求在空间和时间上都存在变化,边缘服务器需要根据环境实时调整缓存策略以最大化用户体验。其次,现有的研究大多忽略了动态任务缓存策略对长期服务成本和服务延迟的影响[7]。如何在没有预见未来系统动态的情况下做出缓存以最大化系统长期性能是很大的挑战。最后,由于边缘计算服务器覆盖范围远远小于云计算,相邻边缘服务器的用户更倾向于请求相似的任务[8],如何将相邻边缘服务器协同起来优化任务缓存策略是一个挑战。
针对以上挑战,本文考虑多个移动设备,多个边缘服务器和一个远程云服务器组成的网络系统,在Soft Actor-Critic(SAC)算法的基础上设计MSAC算法,通过经验共享机制使多个服务器协作训练,实现在线任务缓存决策。
1 相关工作
近年来,学术界对于任务缓存技术的研究越来越多[9]。首先考虑一个边缘服务器的情况。文献[10]考虑了边缘服务器计算和缓存能力的限制,通过设计一种交替迭代的方法来探索任务缓存和卸载的联合优化策略。文献[11]通过考虑用户的移动性,利用子模块优化的方法来最大化缓存命中率。文献[12]采用细粒度的任务模型,在边缘云缓存能力有限的情况下,利用遗传算法研究了边缘云上的任务缓存和迁移策略。虽然以上研究都考虑了边缘服务器缓存和计算能力的限制,但是都假设用户对任务的请求是固定的。而在实际中,用户的任务请求在空间上和时间上都是动态变化的,也就是先验未知的。
为了解决用户请求是先验未知的这一问题,文献[13]站在应用服务提供商的角度,让基站通过观察用户上下文信息来了解用户的需求模式,从而选择缓存内容并进行合理的基站租赁决策,但是此方法需要在基站内部维护较大的上下文信息空间。文献[14]中以未知的用户请求为前提并考虑任务计算量和缓存需求的异构性,提出一种基于强化学习的多臂强盗算法来实现智能的任务缓存策略,通过利用上置信约束来实现探索与开发之间的平衡。文献[15]提出了一个新的任务缓存框架,该框架通过使用马尔可夫链和Q 学习算法寻找最优的缓存策略。首先利用马尔可夫决策过程对用户请求建模,然后基于Q学习方法设计线性逼近函数,实现了在线任务缓存决策。文献[16]将深度学习与强化学习相结合,通过利深度强化学习算法来综合优化任务缓存和卸载策略。然而这些研究都是在单个服务器上进行的,没有考虑相邻服务器联合决策的情况。
随着研究的深入,多边缘服务器的情况被越来越多地研究。文献[17]利用李雅普诺夫优化技术建立一个能量不足队列(energy defificit queue)来指导任务缓存和卸载决策,通过吉布斯抽样算法实现基站之间的分散协调。文献[18]将多服务器任务缓存优化问题进行分解以降低计算复杂度,然后利用广义弯曲度分解(generalized benders decomposition)的方法得到系统决策。但是这些方法并没有摆脱任务请求已知的假设,也仅仅是单个时隙的最优决策,忽略了系统的长期性能。
与以上的研究不同,本文将用户请求未知的假设,系统长期性能和多服务器协同任务缓存问题联合起来,通过设计深度强化学习(deep reinforcement learning,DRL)算法来最大限度减少系统平均任务执行时延。本文的主要贡献可以概括如下:
(1)建立多服务器协同任务缓存模型。边缘服务器上可以缓存移动设备请求的任务,当任务不在边缘设备上缓存时,移动设备只能在云服务上执行。边缘服务器之间可以进行通信来协同优化任务缓存决策。
(2)将任务缓存问题形式化。以最小化用户总任务平均执行时延为目标,综合考虑边缘服务器的计算能力和缓存空间大小。
(3)设计基于改进Soft Actor-Critic 的任务缓存算法MSAC。该算法通过与环境的不断交互,可以适应用户请求任务的改变并不断更新任务缓存策略。通过引入最大熵鼓励探索更多策略,设计经验共享机制优化任务缓存决策,从而降低用户平均任务执行时延。
2 系统模型
2.1 网络建模
如图1 所示,在一个区域中,多个边缘服务器和一个云服务器组成边缘计算系统。边缘服务器通过无线链路与移动设备进行通信,云服务器通过核心网与边缘服务器通信,边缘服务器之间可以通过本地局域网进行通信。云服务器和边缘服务器均可以为移动设备提供任务计算服务,前提是先缓存要计算的任务。假设云服务器具有充足的计算能力和缓存容量,可以缓存所有的任务。相比于云服务器,边缘服务器的计算能力和缓存容量都是有限的,因此不能缓存所有的任务,只能缓存部分任务。每个移动设备都有需要执行的计算任务,例如移动游戏或者视频流。考虑到移动设备的计算能力和电池容量有限,不适于一些计算需求大且耗能的任务,因此,与文献[14]中的工作类似,假设移动设备本身不处理任务,只考虑边缘服务器或远程云上的任务缓存和处理。
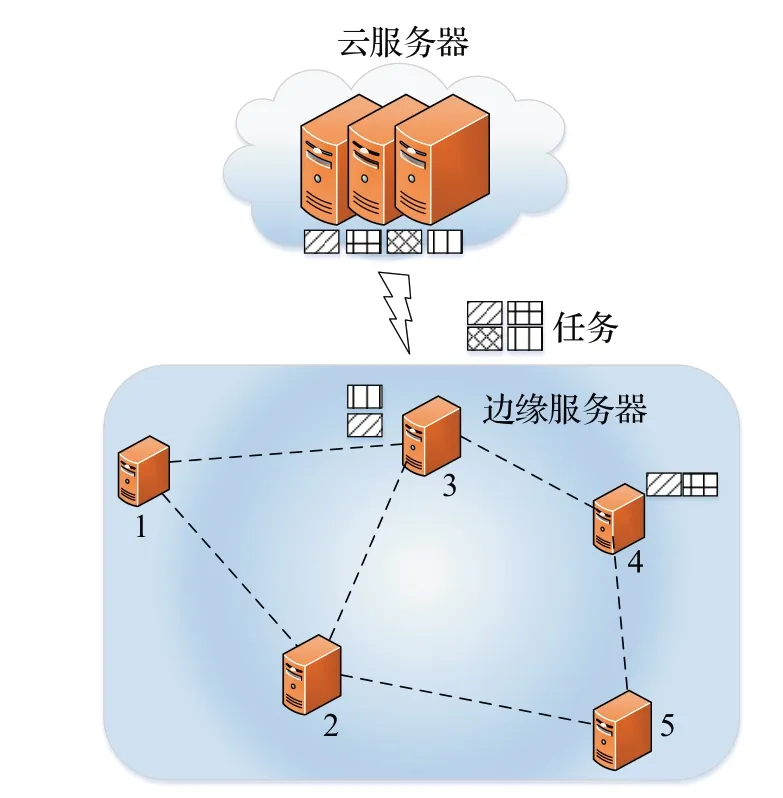
图1 系统模型Fig.1 System model
令N={1,2,…,n}表示边缘服务器的集合。边缘服务器的最大计算能力为fES(以cpu周期数为单位),内存容量为C。云服务器的最大计算能力为fCS,fCS>fES。令K={1,2,…,k}表示k个任务的集合,其中1,2,…,k表示任务的编号。每个任务之间是独立的,且具有四个固定参数:{wk,ck,pk,qk},wk指完成任务k所需的cpu周期总数,ck指缓存任务k所需的代码和环境所占用的内存空间大小,pk指任务计算所需的初始数据的大小,qk指任务计算完成后的数据结果大小。
为了简化计算和实现,假设该模型运行在离散的时隙t=1,2,…,T,其中T表示有限的时间范围。每个时隙内任务均计算完成后转移到下一时隙。边缘服务器每个时隙中所关联的移动设备个数为Mt,且移动设备在每个时隙内位置固定,每个时隙结束后有一定的几率移动到相邻的服务器。
2.2 任务请求模型
每个时隙t开始时移动设备会在K个任务中选择一个请求至与其相关联的边缘服务器。由于每个用户可能请求相同的任务,且边缘服务器相关联的用户个数可能不同,如果将所有用户请求的任务依次表示,则总任务请求集合的元素个数将会不断改变。为了保持系统状态维度不变,便于模型求解,因此使用记录任务k的请求次数,则时隙t中用户总的任务请求表示为。例如,Bt={5,4,3,2,1}表示在任务种类为5 的系统中,时隙t内1 号任务请求个数为5,2号任务请求个数为4,以此类推即可。
2.3 任务缓存模型
边缘服务器在为移动设备提供服务时首先要把对应任务相关环境和数据缓存在内存中,定义每个边缘服务器上在时隙t的任务k的缓存决策:
则边缘服务器在时隙t的总缓存决策为at={…}。例如,at={0,1,0,0,1}表示2号任务和5号任务需要缓存在边缘服务器上。考虑到边缘服务器内存容量限制,每个边缘服务器进行任务缓存时需要满足的约束条件为:
每个时隙边缘服务器都会做出新的任务缓存决策at,由于at不会一直完全相同,因此需要对新的任务进行缓存替换,即删除不需要缓存的旧任务,给新任务分配其所需的内存资源并从磁盘中缓存该任务。
2.4 任务执行时延模型
该模型中任务执行的时延可以分为三部分:通信时延,计算时延,缓存替换时延。
(1)通信时延
通信时延指移动设备发送任务初始数据和接受计算结果过程中所产生的延迟。
当任务在边缘服务器上执行,即1 时。由于模型中移动设备和边缘服务器之间采用正交频分多址的方式进行通信,即边缘服务器为每个关联的移动设备分配一个正交信道用以传输数据,因此不用考虑传输信道之间可能产生的干扰问题。移动设备与边缘服务器之间的上行传输速率可由香农公式得出:
其中,Bk表示无线传输带宽,Ps和Pn分别表示边缘服务器的传输功率和噪声功率。则移动设备将任务k的初始数据通过无线链路发送到边缘服务器的上行传输时延为:
由于从边缘服务器到移动设备的下行链路速率远大于上行链路速率,因此只考虑上行链路,忽略从边缘服务器将任务结果传回移动设备的时延开销。则1时的通信时延为。
当任务在云服务器上执行,即0 时,输入数据通过边缘服务器转发到云服务器,计算结果通过边缘服务器转发到移动设备。由于与云服务器距离较远,假设核心网中的数据传输时间为tc,则可以得到任务k在0 时的通信时延:
则时隙t内任务总通信时延为:
(2)计算时延
计算时延表示为任务在边缘服务器或云服务器上计算所需的时间。边缘服务器会计算所有已缓存任务的请求,为每个任务平均分配计算能力:
每个任务计算时延为:
则该时隙内边缘服务器上任务总计算时延为:
由于云服务器计算能力充足,每个任务分配到的计算能力均为fCS,其计算时延为:
云服务器上任务总计算时延为:
由于边缘服务器的计算能力不如云服务器,若在边缘服务器上执行过多的任务,每个任务分配到的计算能力太少,其任务计算时延就会大大增加。因此,边缘服务器和云服务器的协同计算是必要的。
(3)缓存替换时延
缓存替换时延指边缘服务器做出缓存决策后,删除不再缓存的任务并从磁盘中加载新任务所需的时延。因为删除任务所需的时间极短,因此忽略删除任务的时延。任务k的缓存替换时延表示为:
其中,ck表示缓存任务k所需的内存大小,v代表任务从磁盘加载到内存的速度。由于缓存替换时任务不能执行,所以任务的总等待时间为:
综上所述,在一个边缘服务器上,时隙t的平均任务执行时延可以表示为:
2.5 问题表述
本文的研究目标是最小化多服务器任务缓存模型的平均任务执行时延,考虑到边缘服务器的计算能力和内存空间限制,对于图1 所示每个边缘计算服务器,任务时延问题表述为:
其中,目标函数为计算每个时隙的任务平均执行时延,第一个约束是任务总的缓存容量不能超过边缘服务器的内存空间限制,第二个约束表示任务k是否缓存在边缘服务器上。
3 MSAC算法设计
深度强化学习是近年来研究的一个热点,智能体通过与环境进行交互(做出动作决策并产生相应的奖励)来不断调整行为以最大化长期系统收益。相比于传统优化算法,DRL方法可以针对不同边缘计算环境中不同的任务请求做出对应的缓存决策,能够适应环境且决策用时短,更适用于边缘计算环境。目前已有许多DRL算法应用于边缘计算相关研究[19-22]。
在上文的模型中,由于任务替换时延需要考虑上一时隙的缓存决策,因此边缘服务器的缓存决策不仅影响当前时隙的任务平均执行时延,也会对下一时隙产生影响。如果仅考虑令当前时隙的任务平均时延最小,则可能会频繁地进行缓存替换,任务的执行时延可能会大大增加。因此边缘服务器做出缓存决策时不仅需要让当前时隙任务平均执行时延尽可能小,也要为未来考虑,最大化系统长期收益,这与强化学习的特点不谋而同。虽然进化算法也能够找到较优的决策,但是其决策用时过长,且仅能考虑当前时隙,没有“长远眼光”。
因此,为了解决任务缓存模型中用户请求未知和系统长期性能的挑战,本章基于Soft-Actor-Critic深度强化学习算法设计基于分布式决策的在线任务缓存算法,每个边缘服务器均通过与环境交互进行缓存决策以最小化移动设备任务平均执行时延,最大化系统长期性能。同时,为了解决边缘服务器协同的挑战,本章在SAC算法的基础上设计经验共享机制,使相邻边缘服务器共享经验以优化任务缓存决策。
3.1 构建MDP
马尔可夫决策过程(Markovian decision process,MDP)是强化学习中利用交互式学习来实现最大化系统收益的理论模型,其主要包含状态、动作、奖励这三个关键要素。在本模型中,对于每个边缘服务器,其三要素的定义如下:
系统奖励:系统奖励指在状态st下采取动作at后系统的收益。本文优化的目标是边缘服务器的平均任务执行时延,目的是令任务时延尽可能地减小,而强化学习的目标是最大化系统奖励。因此系统奖励应与平均任务执行时延呈负相关,将系统奖励设置为:
其中Qt的计算方式由式(14)给出。
3.2 动作优化
由于边缘服务器缓存容量有限,其缓存决策受到式(2)的限制。若边缘服务器做出非法动作,即任务缓存决策at不满足式(2)时,需要对该动作进行优化以满足式(2)。
本文通过任务优先级优化缓存动作。定义每个任务的优先级dk:
在等式右侧,前者表示任务请求数量占总数量的比值,后者表示任务大小和边缘服务器内存大小的比值。优先级越高,则表示该任务请求数量越多或所占缓存资源越少。当服务器做出的缓存决策at不满足式(2)时,服务器会根据at中要缓存任务的优先级进行排序,从优先级最高的任务开始缓存,直至服务器存储资源用完,从而得到优化后的动作。这个优化目标是要求服务器尽可能多地执行任务和缓存任务。同时,因为at是非法动作,该动作对应的系统奖励应为-r1。r1为惩罚因子,可以令服务器在更新策略时减少对该动作的选取。因此系统奖励应改为:
3.3 MSAC算法
标准强化学习的目标是最大化智能体的回报,而SAC算法在传统AC算法的基础上增加了最大熵模型,通过最大化熵值来让动作的分布更加均匀,鼓励智能体探索更多策略,从而避免反复选择同一动作而收敛于局部最优,同时通过最大化奖赏,放弃较低奖赏的策略以寻找最优策略。因此本文在SAC 算法的基础上设计MSAC 算法。由于本文的任务缓存模型中智能体输出的缓存决策为离散动作,因此本文采用SAC 算法的离散形式。
MSAC算法的结构如图2所示。该算法遵循Actor-Critic 框架。Actor 部分为一个参数为ϕ的策略网络πϕ(at|st),作用是通过与环境交互采集每个时隙的任务请求和上一时隙的缓存决策作为系统的输入st,通过策略网络输出任务缓存决策at。应用于离散情况时,策略网络不输出动作分布的均值和协方差,而是直接输出动作分布。具体操作是参数化π将状态映射到一个有2 |A|个元素的实数向量,其中 |A|是动作空间的维度。在该网络最后一层应用softmax 函数,以确保其输出的每个动作的概率分布是有效的。Critic部分为参数为θ的Q值网络Qθ(st,at),它通过输出每个动作的Q值来评估当前策略的好坏。
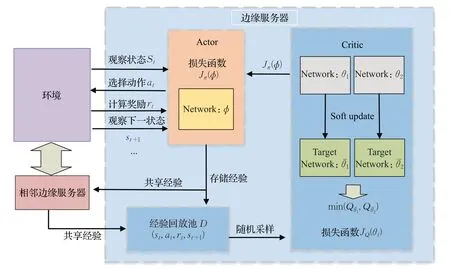
图2 MSAC算法框架Fig.2 Framework of MSAC
SAC算法目标是寻找最优策略π*:
其中,E表示均值,T是时间步数,r(st,at)为智能体在状态st下执行动作at获得的奖励,γ∈[0,1]是折扣因子,st,at分别为智能体在t时刻的状态和动作。τπ为策略π下的(st,at)的轨迹分布。α决定了熵项相对于奖励的重要性,称为温度系数。考虑到用户任务请求的时变性,为了维持算法的探索性,α设为定值。
H(π(·|st)表示策略在状态st处的熵,计算公式为:
Actor 部分通过观察环境状态st后输出最优动作at,执行动作at后,收集奖励rt并观察得到下一个状态st+1。四元组(st,at,rt,st+1)将被收集并存入经验回放池D中。
Critic 部分从经验回放池中采样,目标是通过训练Q值网络参数使贝尔曼误差JQ(θ)最小:
其中,E表示期望,状态值函数Vθ(st)表示为:
其中,π(st)表示离散化后的策略在st状态下每个动作的概率的集合,Q(st)表示st状态下每个动作Q 值的集合,因此可以直接计算得到Vθ(st)的值。通过随机梯度优化即可更新Q值网络参数θ:
其中,β表示学习率。
Critic部分有两个独立的Q值网络Qθ1、Qθ2,每个Q值网络还对应一个目标Q 值网络Qθˉ1、Qθˉ2,其作用是稳定Q值网络的学习效果。Q值网络参数更新后,需要对目标Q值网络参数进行软更新:
其中,λ为调节目标Q值网络软更新的超参数。为了避免对值函数的高估,使用两个Q值网络输出的最小值作为Critic部分的Q值网络输出:
得到Critic 网络输出后,可以计算Actor 网络的损失函数:
进而更新Actor网络参数以改进缓存策略:
该算法在策略评估和策略改进之间交替进行,从而不断优化服务器的缓存策略。
3.4 经验共享机制
通过在每个边缘服务器上部署上文的MSAC算法,每个边缘服务器均可以与本地环境进行交互来学习缓存决策。但是深度强化学习算法需要足够且多样的经验数据,以确保其学习性能。仅靠单个边缘服务器与本地环境交互来获取数据,会导致时间消耗和数据多样性不足。此外,在真实边缘计算环境中,DRL算法的学习时间与用户体验相关联,仅从单个环境中获取经验数据的学习成本太高[23]。
考虑到邻近地区的用户任务请求大多相似,相邻的边缘服务器所处环境较为相似,因此边缘服务器在收集四元组(st,at,rt,st+1)时不仅可以放入自己的经验回放池D 中,也可以发送给相邻的边缘服务器,自己也可以接受相邻的服务器传来的经验四元组来训练本地SAC算法。此时经验回放池D为:
其中,Dl为本地经验回放池,Dn为相邻服务器传来的经验四元组的集合。两者均为相同长度的双端队列,按照先进先出的原则,始终维护较新的经验回放池来训练SAC网络,以保持缓存决策的及时更新。
相邻服务器的定义为:两服务器之间的距离小于服务器最大接受范围的2 倍。不满足该条件的边缘服务器之间不共享经验。
MSAC算法流程描述如下:
输入:移动设备集合I,计算任务集合K,边缘服务器集合N,以及边缘服务器缓存容量C和计算频率fES,云服务器计算频率fCS。
4 仿真实验与结果分析
4.1 实验设置
由于无法实现真实的边缘计算环境,因此,为尽可能模拟真实环境,本文参考文献[24]的环境设置,在其基础上适当修改进行实验仿真。使用python3.7 和pytorch1.5.0 模拟了具有5 个边缘服务器和一个云服务器组成的小区边缘计算系统。边缘服务器的位置如图1所示摆放,每个时隙每个用户可以在现有任务中选择一个任务请求至边缘服务器,任务的请求概率服从齐夫分布[25]。由于边缘服务器所覆盖范围较小,因此假设每个用户与边缘服务器之间的数据传输带宽相同,以简化系统模型。该系统的主要参数设置由表1给出。
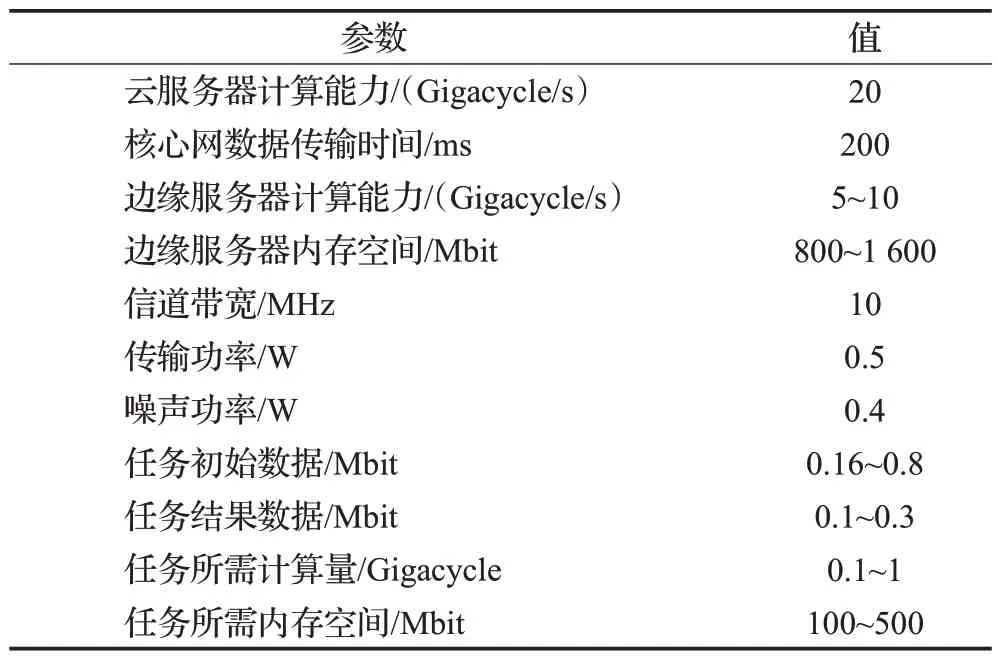
表1 系统主要参数设置Table 1 Main parameters setting of system
边缘计算系统采用分布式决策,在每个边缘服务器上部署MSAC算法,Actor部分和Critic部分均使用全连接神经网络来训练模型,学习率分别为0.001和0.000 5,并使用adam 优化器进行优化。Critic 部分中温度系数为0.2,折扣因子为0.9,软更新参数为0.001。设置经验回放池的大小为5 000,每次采样32组经验进行训练。
在实验中,默认设置每个边缘服务器计算能力为5 Gigacycle/s,内存空间为1 000 Mbit,初始关联用户数量为10,任务数量为6。
4.2 收敛性分析
为了研究所提算法的收敛性和经验共享机制的有效性,图3 展示了默认设置下图1 中3 号边缘服务器上MSAC算法的收敛性能,其中SAC算法为不采用经验共享机制的独立SAC算法。由于用户请求的随机性和RL的探索性,每个训练回合的任务平均时延不可能完全相同,因此,在任务平均执行时延较低且在一个较小范围内波动时,可视为算法达到收敛。从图3 可以看出,随着训练回合的增加,MSAC算法吸收更多的经验进行学习,能够较快收敛,大约在75 回合训练后达到收敛,而SAC算法由于经验多样性不足,在大约100回合训练后才达到收敛。MSAC算法收敛更快且性能更好,任务平均执行时延在225 ms左右,优于SAC算法,验证了经验共享机制的有效性。
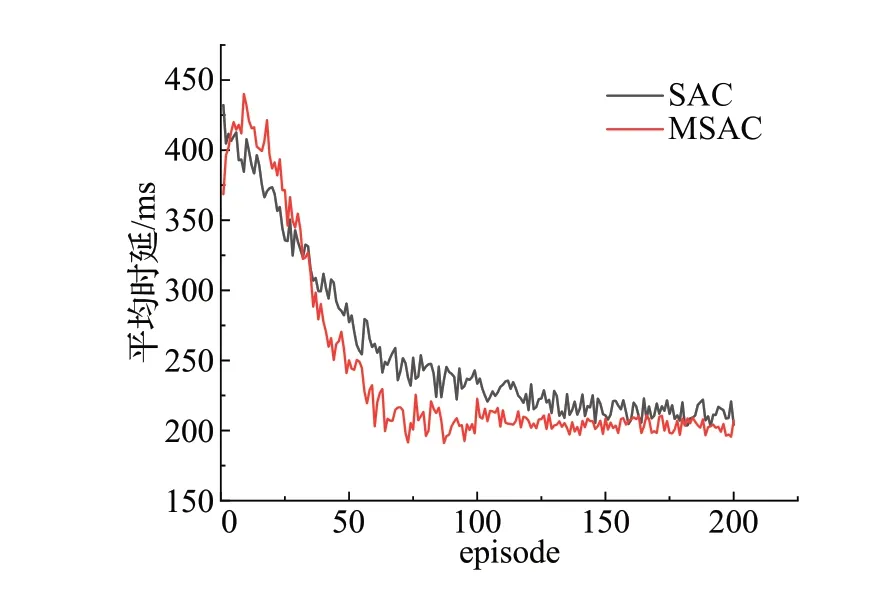
图3 MSAC与SAC算法收敛性能Fig.3 Convergence performance of MSAC and SAC
4.3 不同算法之间性能对比
为了验证所提算法的性能,将MSAC 算法和SAC算法训练200 回合时的性能分别与以下三种方案进行比较,具体描述如下:
基于DQN 算法[26]的缓存方案(DQN):每个边缘服务器部署用DQN 算法进行缓存决策,通过输出状态st下动作at的Q值判断该动作的优劣并改进缓存决策。
基于遗传算法[12]的缓存方案(GEN):使用遗传算法不断迭代得到较优缓存方案,取迭代100次的结果进行对比。
基于流行度的缓存方案(POP):边缘服务器统计任务的请求个数,按照个数从高到低缓存任务。
图4为5种算法在改变任务种类个数时任务平均执行时延的变化情况。随着任务种类的增加,系统任务平均执行时延呈上升趋势。由于边缘服务器内存空间的限制,边缘服务器不能缓存更多的任务,导致更多用户任务转发到云端执行,从而增加执行时延。与SAC 算法、DQN 算法、GEN 算法和POP 算法相比,本文提出的MSAC 算法性能最好,任务平均执行时延分别降低约3.8%、15.5%、8.4%、31.4%。
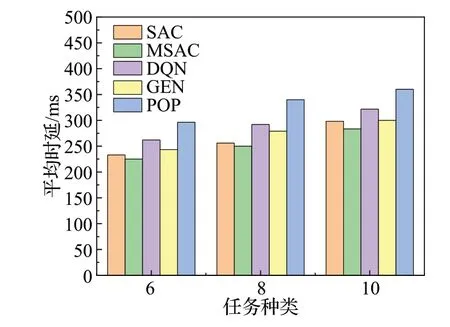
图4 任务种类个数与平均时延Fig.4 Number of task types and average latency
任务种类改变时各个算法每个时隙做出缓存决策的用时由表2列出,由于POP算法根据边缘服务器统计的各任务次数从高到低依次缓存,因此做出决策时间几乎为0 ms。随着任务种类的增加,其余算法决策用时均增加。SAC 算法、MSAC 算法和DQN 算法的决策因由神经网络计算得出,所以用时极短,仅需1~2 ms。相比于神经网络,GEN 算法由于需要不断迭代来寻找最优决策,需要耗费大量时间。在任务种类为6,8,10时,GEN算法迭代100 次的用时大约为其他三种算法的203 倍,200倍,135倍。
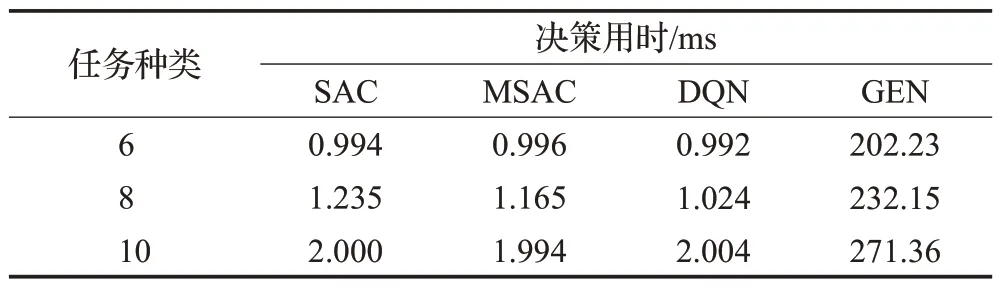
表2 任务种类与决策用时Table 2 Task type and decision-making
图5展示了5种算法在边缘服务器计算能力分别为5,6,7,8,9,10 Gigacycle/s 时的性能表现。随着边缘服务器计算能力的增加,系统平均任务执行时延不断降低。MSAC 算法在不同计算能力下均有着最好的性能表现,SAC 算法次之。由于DQN 算法容易过拟合且收敛速度慢,其性能不如GEN 算法。POP 算法由于不能动态适应用户的请求,其性能最差。相比于SAC算法、DQN算法、GEN算法和POP算法,MSAC算法的任务平均执行时延分别降低3.6%、16.5%、6.4%、26.3%。从曲线斜率来看,平均时延降低的速度逐渐变缓。这是由于边缘服务器缓存容量有限,已缓存任务的计算时延逐渐变小,而未缓存的任务只能在云服务器上执行,其时延与边缘服务器的计算能力无关,限制了系统的性能。
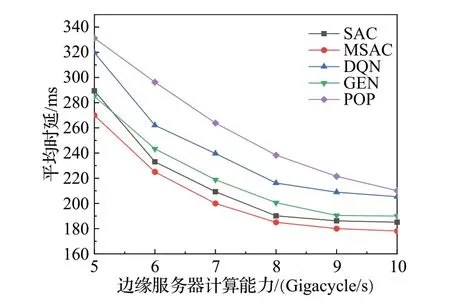
图5 边缘服务器计算能力与平均时延Fig.5 Computing power of edge server and average latency
内存空间大小的改变对算法性能的影响由图6 给出,通过曲线可以看到内存空间是影响系统性能的因素之一,除POP 算法外,其他四种算法的平均任务执行时延随着内存容量的提高而降低。随着内存容量的增加,POP算法缓存了越来越多的任务,但由于边缘服务器计算能力的限制,每个任务需要更长的时间去计算,从而导致任务执行时延的增加。而MSAC 算法,SAC 算法,DQN 算法和GEN 算法经过不断训练或迭代,能够智能地做出缓存决策,而不是地缓存任务,从而降低任务执行时延。与SAC 算法、DQN 算法、GEN 算法和POP 算法对比,MSAC 算法的性能最好,其任务平均执行时延分别降低4.7%、17.2%、10.9%、37.8%。
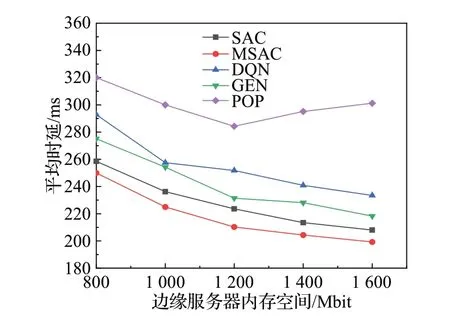
图6 边缘服务器内存空间与平均时延Fig.6 Memory space of edge server and average latency
图7 为边缘服务器初始关联用户数量的改变对任务平均执行时延的影响。随着用户数量的增多,边缘服务器分给每个已缓存任务的计算能力变少,导致任务计算时延不断增加。从图7可以看出,本文所提MSAC算法性能最好,相比于SAC 算法、DQN 算法、GEN 算法、POP算法,其任务平均执行时延分别降低约2.3%、11.5%、9.4%、37.6%。
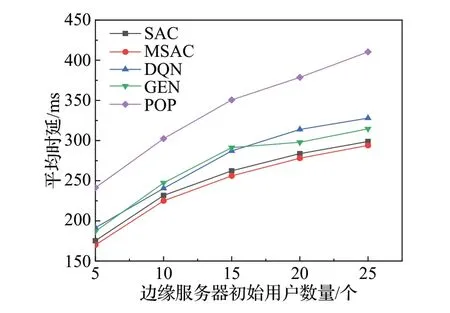
图7 初始用户数量与平均时延的关系Fig.7 Computing power and memory space of edge server
5 结束语
本文研究了边缘计算中多用户多服务器系统中的任务缓存策略。首先建立了任务缓存模型,把平均任务执行延迟作为评价系统性能的指标,并给出了一种等效的强化学习形式。提出了一种有效的在线任务缓存算法MSAC,该算法考虑了边缘服务器缓存能力和计算能力的限制以及相邻服务器用户任务请求相似的特点,令相邻边缘服务器之间通过共享经验优化缓存决策,以适应用户任务请求的变化。多次仿真实验表明,通过在边缘服务器上部署MSAC算法,可以显著降低任务执行时延,且MSAC 算法在不同条件下均有较好的性能表现。下一步工作将把任务缓存与任务卸载技术相结合,联合考虑能耗与时延的约束,进一步优化边缘计算系统性能。
猜你喜欢
理科爱好者(教育教学版)(2022年2期)2022-05-05
甘肃教育(2021年10期)2021-11-02
甘肃教育(2020年21期)2020-04-13
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
铁道通信信号(2018年9期)2018-11-10
数学大世界(2018年1期)2018-04-12
舰船电子对抗(2016年3期)2016-12-13
广西大学学报(自然科学版)(2016年5期)2016-11-12
系统工程与电子技术(2016年7期)2016-08-21
