
基于深度学习的MRI重建方法综述
2023-10-30 08:57邓戈文魏国辉马志庆
计算机工程与应用 2023年20期
邓戈文,魏国辉,马志庆
山东中医药大学 智能与信息工程学院,济南 250355
医学影像技术在疾病诊断中发挥着重要作用,目前大部分疾病都是通过影像技术进行辅助诊断的,包括计算机断层扫描成像(CT)、磁共振成像(MRI)、超声波成像和X 射线成像、正电子发射计算机断层扫描(PET)等。其中,不同于CT 等成像会对人体造成辐射伤害,MRI是一种非侵入性、多参数对比、高分辨率的成像方式,是较为理想的临床医学检查手段。但是与其他的成像方法相比,MRI扫描时间过长,成像缓慢,通常需要15 分钟到1 小时,会给患者带来不适。此外,MRI对患者扫描过程中的生理和身体运动非常敏感,如心跳、呼吸、咳嗽、吞咽都会导致图像出现不同程度的伪影,这些都限制了MRI的推广与发展。
在过去的几十年里,许多研究者致力于加速MRI的重建,并行成像(parallel imaging)和压缩感知(compressed sensing)是其中应用最为广泛的两项技术。并行成像技术使用多个线圈同时对某一部位进行采样,利用敏感度信息辅助空间定位,常用的并行成像方法有SENSE(sensitivity encoding)[1]、SMASH(simultaneous acquisition of spatial harmonics)[2]、GRAPPA[3]、SPIRiT[4]等。压缩感知通过利用图像在总变换(total variation,TV)[5]或小波变换(wavelet transform,WT)[6]中的稀疏性,从欠采样k空间恢复原始数据。
深度学习(deep learning,DL)是20 世纪80 年代以来人工智能(artificial intelligence,AI)领域研究热点之一,它使用多层神经网络来学习大量数据中的复杂特征,并且在各种医学成像任务中显示出巨大的潜力[7-12],它的普及是随着计算能力的进步和训练技术的提高而推动的。Wang等人[13]于2016年首次用深度学习的方法帮助完成MRI重建,引起了研究者们的关注。基于深度学习的重建方法可以避免传统方法手动调参这一复杂的过程,并且能大量缩短MRI扫描与重建时间,具有较高的临床应用价值。
目前,基于深度学习的MRI重建综述类文章较少。从分类方式上来看,有按照监督学习、无监督学习分类的[14],还有按照输入/输出数据处在图像域/k空间域分类的[15],以上的分类方式仅从学习方法或数据类型入手,未能考虑到MRI重建领域成像的物理模型特性,针对方法设计的驱动方式进行归纳。已有的按照驱动方式分类的文献[16]缺少近三年模型的最新应用和各模型的区别及优缺点,对模型驱动的展开优化重建总结不够系统。本文更新了Transformer、Diffusion 等模型在MRI重建领域的最新应用,讨论了它们与其他模型的区别与优劣,并更系统地总结了模型驱动的重建方法。
1 重建问题
一般来说,MR图像重建可以被表述为以下逆问题:
其中,x是待重建的图像,y是测量的k空间数据,ε为测量过程中的噪声,A代表编码矩阵,对于单通道采集A=MF,对于多通道采集的情况A=MFS,M是采样掩码,F代表傅里叶变换,S是灵敏度编码。在实际重建过程中,测量数据y和编码矩阵A中的成像模型都是已知的,MRI重建的任务就是要从k空间数据y中恢复出目标图像x。
如果采样数据y满足奈奎斯特采样定理,可以直接求最小二乘法解来重建图像。例如,如果数据在笛卡尔网格中被完全采样,可以直接使用逆傅里叶变换。而如果采样低于奈奎斯特采样标准(即欠采样),理论上重建问题会有无穷多个解,此时需要引入额外的先验信息来约束这一欠定问题,欠采样图像重建问题通常被描述为如下最优化问题:
2 重建方法
基于深度学习的MRI重建方法可以分为两类:数据驱动的端到端重建和模型驱动的展开优化重建。数据驱动的端到端重建借助常用的神经网络来学习输入(欠采样的k空间数据或伪影图像)和输出(目标图像)之间的非线性映射,并通过不断向神经网络引入MRI先验知识来提高重建模型的性能。该方法可供选择的神经网络多,但对于数据量的要求大,可解释性较差。模型驱动的展开优化重建继承自传统的重建算法(如压缩感知),从建立的物理模型出发,将传统的优化算法展开后嵌入到一个神经网络中,并通过多个网络模块的连接来模拟迭代计算的过程,保留了传统算法可解释性强的特点,同时具有深度学习的强大学习能力。
2.1 数据驱动的端到端重建
根据选择的神经网络结构的不同,以下介绍了6类常见的神经网络在MRI重建中的应用,分别是CNN、RNN、Transformer、GAN、VAE 和Diffusion,其中CNN、RNN、Transformer属于非生成模型,而GAN、VAE、Diffusion属于生成模型,6类模型重建的简要示意图见图1。
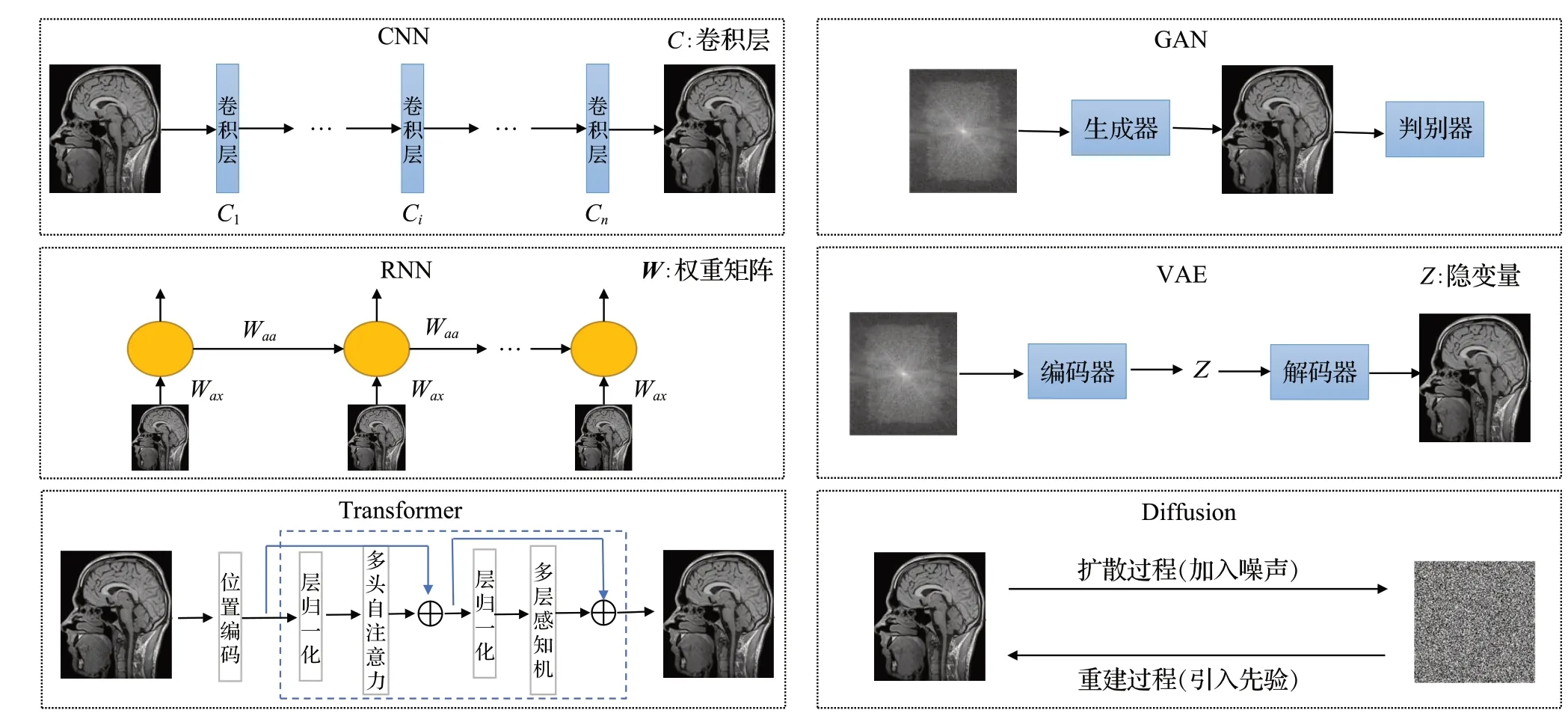
图1 6类用于MRI重建的深度学习模型Fig.1 6 Deep learning models for MRIreconstruction
2.1.1 基于CNN的重建模型
卷积神经网络(convolutional neural network,CNN)可以自动从大量数据中学习不同的特征表达,识别出复杂的数据结构,不再依赖于手动提取特征,被广泛地应用在MRI重建领域。Zhu 等人[17]提出了一种结合流形学习的重建模型AUTOMAP,网络的输入是k空间原始数据,输出是重建的图像,全连接层穿插在模型结构中,可以有效地重建MR图像。此外,AUTOMAP不仅可以重建直角坐标采样的k空间数据,还可以直接重建非直角坐标采样的数据。Cole 等人[18]使用复数卷积网络代替实数神经网络来针对处理MRI这类复数数据,以加快扫描的时间,经对比实验发现具有复数卷积与具有相同数量可训练参数的实数卷积相比,提供了更好的重建效果。Gan等人[19]提出了一种即插即用(plug-and-play,PnP)的MRI重建方法MSMRI-PnP,它可以很好地保证MRI的数据一致性,同时可以在没有任何无伪影的Ground Truth的情况下利用CNN先验训练,能够从高度欠采样的k 空间测量值中重建4D MR 图像,其重建的结果优于传统的TV正则化。
U 型神经网络(U-Net)是CNN 的众多变体模型之一,最初被用于医学图像的分割,它由编码器和解码器组成,并通过跳跃连接的方式实现多维度的特征融合。目前,许多重建研究都采用了U-Net结构或作为子结构改进,并取得了有效的成果。Hauptmann 等人[20]提出一个三维(二维加时间)U-Net结构重建了实时心脏图像序列。实验结果表明,U-Net的重建时间比传统的压缩感知重建方法快5倍以上,并且测得的双心室容积的图像质量和准确性都优于压缩感知重建。Han等人[21]提出了一种基于U-Net 的k 空间插值的深度学习算法,其中输入和输出都在k 空间域,并且是完全数据驱动的,所提出的k 空间插值网络在各种采样轨迹上的表现优于图像域深度学习方法。Dhengre等人[22]提出了一种端到端的基于U-Net 的可训练模型,他们在U-Net 的每个编码器和解码器中都引入了一个多核卷积模块,可以提取不同感受野的特征。此外,为了有效地利用不同尺度的解码器特征,使用了一种特征融合机制,以融合不同尺度的解码器特征。
残差网络(ResNet)自提出以来,在自然图像分类方面取得了突出的成就。在医学图像重建领域,ResNet也被广泛使用。Cai等人[23]直接使用ResNet重建重叠回波分离(overlapping-echo detachment,OLED)序列的T2映射,在单射OLED 序列的模拟MR 图像上,取得了有效的重建效果。Bao等人[24]提出了一种基于递归残差网络的增强型递归残差网络(enhanced recursive residual network,ERRN),用于欠采样的MR 图像重建,提高图像重建质量。Du等人[25]在研究中提出了一种基于残差学习的残差CNN,用于单幅各向异性的三维MR图像的超分辨率重建,所提出的具有跳跃连接的残差CNN 可以有效地恢复MR图像的高频细节。Pawar等人[26]设计了一种数据驱动的运动校正技术,用来抑制由运动产生的MR 图像伪影。他们利用一个Inception-ResNet 作为编码器,并通过卷积层和上采样层的叠加来形成一个编码器-解码器网络。通过在模拟的运动损坏的大脑图像上进行训练,可以成功识别和抑制那些真实运动所产生的伪影。
2.1.2 基于RNN的重建模型
循环神经网络(recurrent neural network,RNN)使用序列信息来处理一系列的输入,RNN 与其他神经网络的区别在于,隐藏层之间的节点是相连的。每个时刻的输入不仅有当前时刻的输入,而且还有隐藏层在前一时刻的输出值。这种结构使网络具有记忆功能,所以它被广泛用于与时间序列有关的数据中。在快速MRI研究领域,也有一些研究使用RNN进行MRI重建。Zhang等人[27]使用自监督的RNN 进行4D 腹部和胎儿MR 成像,它首先使用自监督的RNN进行呼吸运动估计,然后使用三维去卷积网络进行超分辨率重建。Qin等人[28]共同探讨了时间序列的依赖性和传统算法的迭代特性,使用跨时间序列的双向RNN 来学习空间-时间依赖关系。Oh等人[29]提出基于RNN的端到端网络可以直接从笛卡尔和非笛卡尔轨迹和多通道线圈获得的k 空间数据中重建MR 图像。在该重建网络中,域变换网络将k空间数据转换为粗略的图像,然后在下游的网络中进行细化,以重建最终图像。
2.1.3 基于Transformer的重建模型
Transformer[30]是一种基于自注意力机制的深度神经网络,最初应用于自然语言处理领域。受Transformer强大表示能力的启发,研究人员提出将Transformer 扩展到计算机视觉任务。ViT[31(]vision Transformer)是Transformer 在计算机视觉图片分类任务中第一次成功的应用。此后也有一些研究者使用ViT来帮助完成MRI重建的工作。
Feng等人[32]提出了基于Transformer的结构MTrans,用于加速多模态MR 成像。MTrans 的主要组成部分是交叉注意力模块。在fastMRI和uiMRI数据集上进行的重建和超分辨率任务的实验表明,MTrans 比以前的方法取得了良好的性能。然而,MTrans 需要对MRI重建和超分辨率任务进行单独训练。为了联合重建和超分辨率MRI图像,Feng等人[33]提出了Task-Transformer,利用多任务学习的力量来融合重建分支和超分辨率分支之间的互补信息,在公共IXI和私人MRI大脑数据集上进行了实验。同样,Mahapatra 等人[34]提出了一个混合架构,通过利用CNN 和ViTs 的互补优势来重建MRI图像。他们还提出了新的损失函数[35]来保留超分辨率图像的语义和结构信息。
上述方法的一个缺点是需要大量配对数据集来训练ViT模型。为了缓解数据要求问题,Korkmaz等人[36-37]提出了一个框架SLATER 进行无监督的MRI重建。具体来说,SLATER通过迭代优化网络权重来最小化网络输出和欠采样多线圈MRI采集之间的误差,同时满足MRI前向模型的约束。与其他基于无监督学习的方法相比,SLATER 在单线圈和多线圈MRI大脑数据集上都得到了不同程度的改进。同样,Lin 等人[38]表明,在ImageNet 上预训练的ViT 模型,当只对100 张fastMRI图像进行微调时,与CNN 相比,不仅能产生清晰的重建,而且对偏移的解析更具鲁棒性。此外,他们的实验表明,ViT 相比U-Net 结构有更高的吞吐量和更少的内存消耗。
从模型的结构来说,得益于CNN 有效的特征提取能力,目前大多数重建模型都是以CNN 为基础进行设计的,这些应用里有针对图像进行后处理也有对k空间数据进行逆映射的。但CNN 有两个不可避免的局限性,首先,CNN 的归纳偏置不适合处理k 空间数据,例如,CNN中的卷积核通常在所有空间位置上共享,即等价特性,然而,在k空间数据里,空间位置代表正弦和余弦函数的频段,不同位置出现的相同图案可能指的是完全不同的信息;其次,CNN由于缺乏长距离依赖和空间关系建模能力,感受野有限,导致其模型扩展能力不足。尽管一些工作尝试级联更多的层或者使用更大的卷积核来缓解这一问题,但在模型的精度上与最先进的视觉模型还有一定的距离。RNN以其捕获全局时-空特征关系的能力在MRI重建有少量的应用,这些模型基本都是针对k空间数据进行逆映射的,但RNN不能有效地并行处理每一帧的数据,而且计算成本高。Transformer作为一种包含自注意力机制的先进结构,可以很好地弥补上述CNN与RNN的缺点。相比于CNN,Transformer具有更大的感受野,可以捕获长距离依赖信息,更容易扩展模型的规模,Swin Transformer[39]模型更是首次达到了30 亿参数级别,更大的模型参数量使其能从规模庞大、类型复杂的数据中学习更强大和鲁棒的特征。而相比于RNN,Transformer 能够实现并行运算。但是由于Transformer 相比CNN 有更小的归纳偏置,所以往往需要大规模的数据集训练来获得更好的性能,这同时也意味着更高的内存与计算要求。
2.1.4 基于GAN的重建模型
Goodfellow 等人[40]首次提出了用于生成自然图像的GAN。GAN由两个网络组成,一个是生成器,另一个是判别器,这两个网络相互对抗以达到最佳的生成效果,随后经过GAN的不断发展,已经衍生出不同类型的版本,在不同领域也得到了应用[41]。而GAN 也被用于加速MRI的重建,Yang等人[42]用DAGAN中的U-Net网络取代了生成器中的CNN 模块,结合图像损失和频率损失,在重建过程中保留图像细节。Mardani 等人[43]提出了一个整合压缩感知与GAN的框架,使用GAN将欠采样的零填充MR图像映射为完全采样的高质量MR图像。Quan等人[44]在GAN中引入了一个残差的U型网络,它由两个连续的框架组成,一个用于重建(RecoGAN),另一个用于细化结果(RefineGAN)。Jiang 等人[45]在GAN 中加入了Wasserstein 距离,以减少重建图像与真实值之间的距离,使训练过程更加稳定,缓解了梯度消失的问题。Shaul 等人[46]提出了一个两阶段的GAN 网络,即KIGAN,用于估计缺失的k 空间数据并恢复图像空间的混叠伪影。Lv[47]等人提出了一个将并行成像与GAN 架构相结合的模型PIC-GAN,用于加速多通道MRI重建。Huang 等人[48]提出了一个具有双判别器的PIDD-GAN,一个用于增强边缘信息,另一个用于整体图像的重建。
2.1.5 基于VAE的重建模型
变分自编码器(variational autoencoder network,VAE)是自动编码器(autoencoder,AE)网络的一个变种,它包含一个编码器和解码器。编码器将输入图像投射到一个低维向量中,然后由解码器将特征恢复到原始形状。VAE 从完全采样的数据中得出潜在向量的条件概率,具有良好的可解释性和图像重建质量。Makhzani等人[49]提出了对抗性自动编码器(adversarial autoencoders,AAE),将对抗性引入AE 以增强生成效果。Tezcan 等人[50]利用VAE来学习欠采样k空间的非确定性信息,通过使用VAE 的先验信息产生了高质量的重建图像。Zou等人[51]提出了用于动态成像中的Gen-SToRM模型,它使用高斯先验概率来推导基于证据的下限(evidencebased lower bound,ELBO)潜在变量,可用于心脏电影成像的重建,而它对潜在变量没有任何约束条件,导致了切片排列和重建的图像质量不佳。为了解决这个问题,Higgins等人[52]提出了约束变量框架(cVAE),用一个超参数β扩展了原来的VAE 框架,用来调节通道的容量,驱动模型学习更有效的数据潜在表示。随后,Ahmed等人[53]用潜在变量取代了平滑度先验信息,其参数是通过反向传播从欠采样数据中直接学习的,这进一步提高了重建性能。
2.1.6 基于Diffusion的重建模型
扩散模型(Diffusion)是最近兴起的一类生成模型的范式,其目的是将先验数据分布转换为随机噪声,然后逐步修正变换,从而重建一个以相同分布为先验的全新样本。最近,Diffusion 模型凭借其强大的生成能力,成为生成模型的一大热门,而将其应用于医学图像也是一个自然的选择。Chung等人[54]提出一个基于分数的扩散模型(score-based diffusion model)来加速MRI重建,用去噪分数匹配来训练一个连续的随时间变化的分数函数,然后在数字随机微分方程求解器和数据一致性步骤之间进行迭代,以实现重建。类似地,Song等人[55],但提供了一个更灵活的框架,且是完全无监督的,不需要配对数据的训练,这项工作利用了物理测量过程,并专注于采样算法,以创建与观察到的测量结果和估计数据先验一致的图像样本。Chung 等人[56]提出的R2D2+将基于扩散模型的MRI重建和超分辨率结合到同一个网络中,用于生成端到端的高质量医学图像。
同样作为生成模型,GAN、VAE、Diffusion的生成原理有所不同,重建的效果各有优劣。基于GAN 的MRI重建模型使用生成对抗性训练策略,生成器生成尽可能真实的图像,判别器区分真实图像和虚假图像,两者在博弈中不断精进,最终生成理想的重建图像。VAE则使用变分推断来近似数据分布,其编码器用于接近隐层空间中的后验分布,而解码器则用于根据概率分布对原始信息进行建模。Diffusion在扩散阶段从真实图像采样,然后对样本逐步添加随机噪声,在重建阶段从噪声图像采样,通过引入先验知识学习一个模型来估计真实的图像。从重建的结果上来看,基于GAN 的方法重建图像的纹理细节丰富、轮廓清晰,但是它存在着训练过程的不稳定性和梯度消失的现象。而基于VAE的方法直接模拟隐变量,生成的图像分布与真实图像相似,梯度下降在训练过程中得以稳定,但由于它是基于像素的,不能更多地关注全局信息,从而导致生成的图像模糊不清。基于Diffusion的方法不需要训练额外的判别器,也不需要指定一个后验分布,训练过程更加稳定,具有相对明确统一的损失函数设计,高度简单,重建图像质量高。但是与GAN、VAE相比,它的一个固有的缺点是大量的采样步骤和较长的采样时间,这是因为Diffusion利用马尔科夫过程通过微小的扰动来转换数据分布,在训练和推理阶段都需要大量的扩散步骤。
2.1.7 混合结构模型
除了上述标准的网络模型之外,一些方法结合了多个网络来处理MRI重建,这样设计的初衷是为了融合不同网络在重建中特定方面的优点。Chen 等人[57]提出了一种金字塔卷积RNN(PC-RNN)模型,三个卷积RNN模块用于迭代学习多尺度的特征,重建的图像最后由CNN 模块以金字塔的方式组合,与常见的并行成像重建方法不同,PC-RNN直接将多个线圈建模为多通道输入。为了降低Transformer网络的复杂性,Huang等人[58]提出了一个Swin Transformer 与U-Net 结合起来的模型,并通过设计可变形注意力(deformable attention)来揭示模型的可解释性。实验结果表明,U-Net结构的加入可以极大地减少网络参数量,而可变形注意力可以在计算成本增长有限的情况下加强MRI重建。Zhao 等人[59]提出了一种Swin Transformer 与GAN 结合的模型SwinGAN,它由两个生成器组成:一个频域生成器和一个图像域生成器,能够同时利用k 空间与图像信息,使网络能够捕获更多的有效信息,并且两个生成器都基于Swin Transformer,可以有效地捕捉长距离的依赖关系。
2.2 模型驱动的展开优化重建
模型驱动的展开优化重建来源于压缩感知MRI中使用的迭代优化算法。其思想是将这种算法的迭代展开为端到端的神经网络,将测量的k空间映射到相应的重建图像。然后对图像变换、稀疏促进函数、正则化参数和更新率进行训练,并使用反向传播拟合到训练数据集。与经典优化相比,它学习的参数可能比手工设计的参数更适合图像特征,且避免了手动调参这一复杂的过程,重建速度也更快。
如今,一些优化算法已经成功地应用到神经网络中。其中包括GD(gradient descent)[60]、PGD(proximal gradient descent)[61-63]、ISTA(iterative shrinkage-thresholding algorithm)[64]、AMA(alternating minimization algorithm)[65-66]、ADMM(alternating direction method of multipliers)[67-68]和PDHG(primal dual hybrid gradient method)[69]。
重建模型、算法和网络的不同选择构成了不同的展开优化方法,具体方法总结见表1。以下根据重建模型的不同设计将模型驱动的展开优化方法分为类压缩感知模型、去噪模型和广义优化模型三类进行介绍。

表1 模型驱动的展开优化方法Table 1 Model-driven unrolled optimization methods
2.2.1 类压缩感知模型
2.2.2 去噪模型
2.2.3 广义优化模型
此外,有些方法并不限制正则化项的形态,他们设计一个通用项R(x),并使用一个CNN来直接估计其近似映射。R-GANCS[63]、CRNN-MRI(convolutional recurrent neural network)[28]、VS-Net(variable splittingnetwork)[66]、HC-PGD(history cognizant-PGD)[62]和PDHG-CSNe(tprimal dual hybrid gradient-compressive sensing)[71]都是这种情况。
3 MRI重建评价指标和常用数据集
3.1 评价指标
(1)均方误差(MSE)
均方误差(mean square error,MSE)是指标准图像与重建后图像对应像素点灰度值的均方误差,它能反映两张图像全图的逐像素点的差异。均方误差越小在一定程度上能说明重建效果越好。给定图像尺寸为m×n,标准图像I和重建后的图像K的均方误差计算公式为:
(2)峰值信噪比(PSNR)
由于均方误差实质上是用全图的逐像素点取平均,无法衡量图像物体边缘这样的局部差异,所以以均方误差为评价指标的算法结果往往与人眼主观的视觉效果不一致。而峰值信噪比(peek signal-to-noise ratio,PSNR)是MR图像重建结果的另一个重要评价指标,它表示信号最大可能功率与均方误差表示的噪声功率的相对大小,峰值信噪比的计算公式如下:
其中,n表示图像像素点灰度值位数,峰值信噪比的单位是分贝(dB),通常来说更高的PSNR就显示了更高的图像质量。
(3)结构相似度(SSIM)
结构相似度(structural similarity,SSIM)是对两个图像之间的亮度、对比度和结构三个参数的综合考量,通过三者之间的关系度量两个图像之间的相似度。对于两张图像I与K,SSIM的计算公式如下:
其中,μI、μK分别代表I、K的平均值,σI、σK为I、K的标准差,σIK为I和K的协方差,而c1、c2为常数,避免分母为0带来的系统错误。
3.2 数据集
MRI重建常用的数据集有HCP、fastMRI和IXI等,数据集及具体的描述见表2。关于成像区域,主要是脑部和膝部,其次还有一些心脏成像的应用。关于MR图像的对比度,T1加权图像和T2加权图像是最常见的。

表2 常见MRI重建数据集Table 2 Common MRIreconstruction datasets
4 总结与展望
本文介绍了MRI重建问题,然后分别从数据驱动的端到端重建和模型驱动的展开优化重建两方面对基于深度学习的MRI重建方法进行了综述,最后提供了常见评价指标和数据集。当前基于深度学习的MRI重建技术发展迅速,但仍面临着许多挑战,同时有一些值得关注的方向。
(1)数据集问题
深度学习需要大量的数据集进行训练才能获得好的结果。对于医学图像处理来说,深度学习方法面临的最大挑战之一是数据集与标签的稀缺。为了增加训练样本的数量,一些研究采用了数据增强的方法。最主流的数据增强技术是翻转和旋转。其他的技术包括添加随机噪声、清晰度、对比度,以及使用不同加速比的图像。除此以外,数据集的分布也是不均衡的,大部分医疗数据是正常病例,少数是异常病例。
(2)模型通用性
基于深度学习的MRI重建模型的另一个问题是它们缺乏对不同数据集的通用性。只有少数研究显示了其模型在不同数据集和噪声水平下的通用性能。然而,一项研究显示,T1 加权图像的性能比FLAIR 图像性能更好[78],另一项研究显示在含脂肪区域的重建误差更高[79]。此外,如果没有迁移学习,在自然或T1加权图像上训练的深度学习模型不能在T2加权图像上保持同等的性能。这些结果表明,相同的基于深度学习的MRI重建模型在不同的MR 扫描序列或解剖区域可能无法达到相同的性能。这与一些基于深度学习的方法,如VN、DAGAN 和DC-CNN 在输入图像的扰动下的不稳定性相关。
(3)新模型范式
近来,Transformer在各项计算机视觉任务中展现出先进的性能,在MRI重建方面,也有很多工作利用Transformer或者将Transformer与CNN相结合取得了较之前以CNN 为基础的模型更好的表现。这显示出Transformer 成为MRI重建任务中新范式的潜力,同时这些工作也提到了当前Transformer在面临重建任务时的问题,主要是模型参数量大以及依赖大量数据集训练,未来的工作也将从这两方面进行改进。在更适合无监督学习的生成模型方面,Diffusion作为近来兴起的一类生成模型,在自然语言处理[80]、计算机视觉[81]、时间数据建模[82]、多模态建模[83]等领域都有丰富的应用,并展现出与GAN、VAE 等生成模型相当的竞争力,具体在MRI重建任务中,繁琐的采样步骤和较长的扩散过程是限制Diffusion广泛应用的主要原因。因此,在加速采样的情况下保证高质量的样本是未来Diffusion 用于重建时追求的目标。
(4)两类模型统一
当前基于深度学习的MRI重建方法主要分为数据驱动的端到端重建和模型驱动的展开优化重建,两类模型遵循的思路不同,各有优劣。数据驱动方法利用神经网络学习大量的数据,通过不断引入先验知识提高模型的性能。模型驱动方法将传统的优化算法展开后嵌入到一个神经网络中,并通过多个网络模块的连接来模拟迭代计算的过程,在数据量小的时候也能得到不错的效果。两类方法不断地得到完善,互为补充,在未来可能可以相互结合或达到统一。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
汽车实用技术(2022年7期)2022-04-20
房地产导刊(2020年11期)2020-12-28
作文小学中年级(2020年6期)2020-07-24
电子制作(2019年19期)2019-11-23
铁道通信信号(2019年4期)2019-10-10
通信电源技术(2016年1期)2016-04-16
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
