
改进YOLOv4的野生菌视觉检测方法
2023-10-30 08:58张泽冰张冬妍娄蕴祎崔明迪王克奇
计算机工程与应用 2023年20期
张泽冰,张冬妍,娄蕴祎,崔明迪,王克奇
东北林业大学 机电工程学院,哈尔滨 150040
野生香菇作为食用菌中的珍品,营养、药用价值异常丰富,是一种养生保健的绿色健康食品[1]。野生香菇多生长在野外,存在采摘视线遮挡的情况,环境复杂,需要人工深入丛林仔细搜寻,采摘难度大,存在一定危险性。基于视觉检测的无人捡拾设备不仅可以提高采摘效率,还能解决人工采摘的危险性问题,因此设计一种快速视觉检测算法具有良好的应用价值。
目前,农林业目标检测研究已取得一些成果。卢军等[2]针对变化光照下柑橘的遮挡问题,利用R-B 色差图和归一化RGB 颜色空间方法对目标进行初分割,使用自适应直线拟合角点检测和边界跟踪算法进行轮廓标记,最后用椭圆拟合方法生成柑橘形状与位置信息。Pérez-Zavala等[3]针对林间葡萄检测使用HOG和LBP获取形状和纹理信息,SVM-RBF 分类器获得葡萄位置信息,检测精度和召回率分别达88.61%和80.34%。Kanwal等[4]利用HS 模型分割生成苹果斑点,通过细化去噪和Hough 变换精确定位苹果位置。这些对农林产品检测的方法主要是基于颜色、形状以及纹理特征的传统方法,由于目标背景特征不同,不同目标间特征差异较大,此类方法只适用特定场景,泛化能力弱。
深度学习算法克服传统特征提取方法中的特征主观性,提高模型场景应用的泛化能力。其中以Faster R-CNN[5]和Mask-RCNN[6]为代表的双阶段算法首先兴起。Stein等[7]使用Faster R-CNN 算法对522 树的芒果图像进行三维立体定位和产量估计,误差率仅为1.36%。熊俊涛等[8]使用Faster R-CNN 对树上绿色柑橘进行视觉检测研究,平均精度为85.49%,结果优于Otsu 分割法。Yu等[9]针对非结构环境下草莓的检测,使用Mask-RCNN,结合特征金字塔网络(FPN)结构进行特征提取,具有更好的通用性和鲁棒性。双阶段算法虽然检测精度高,通用性与鲁棒性好,但训练需要大量标记样本,模型参数量和计算量庞大,检测耗时过长,不利于工程化应用[10],由此诞生了以YOLO系列算法为代表的单阶段检测算法,相比于双阶段检测算法,具有步骤简单、计算效率高的优点。为了检测果园场景下未成熟芒果,薛月菊等[11]根据YOLOv2[12],提出以Tiny-yolo-dense 为基础网络的Ⅰ-YOLOv2,检测速度明显优于Faster RCNN 方法。虽然YOLOv2 检测速度有明显优势,但由于只有一个检测分支,特征提取能力与检测能力不足,所以Zhou等[13]针对无人机罂粟图像检测,使用FPN结构的YOLOv3[14],并引入MobileNetv2[15]轻量化网络、空间金字塔池化(SPP)和GIoU损失,生成SPP-GIOU-YOLOV3-MN 模型,在不降低速度的前提下,精度明显提升。Zheng 等[16]为准确检测自然环境中的绿色柑橘,使用精度更高、模型更复杂的YOLOv4[17]作为基础网络,并通过修剪CSPDarknet53 骨干网络和提出双向特征金字塔结构(Bi-PANet),使模型参数量与速度都有所提升。以上研究均使用YOLO系列算法,发展至今已进化到YOLOv4 版本。YOLOv4 相比于其他YOLO算法,具有检测精度高、泛化能力强的优点,但也有参数量和计算量更复杂,检测效率较低的缺点。对于林地环境下的野生香菇检测,YOLOv4 满足精确度要求,但模型复杂度高,实时性差。
以YOLOv4 为框架。为实现野生菌视觉在线检测,为采摘提供实时指导,需提升网络搜索速度,对网络进行轻量化优化。选择高效的ShuffleNetv2 替代CSPDarknet53,在精度与实时性方面取得平衡;采用ASFF 结构代替PANet 结构进行特征融合;在预测分支中,采用金字塔卷积和深度可分离卷积替代普通卷积,降低计算复杂度;模型尾部引入SA 注意力模块,以少量计算提高检测精度;最后采用Weight DIoU NMS 代替NMS(non maximum suppression),优化预测框选取,由此实现模型轻量化与检测精度优化。
1 野生香菇检测模型
1.1 YOLOv4检测模型
YOLOv4 结构框图如图1 所示,网络组成模块如图2 所示。在数据处理中,引入Mosaic 数据增强操作,提升模型训练速度和网络泛化能力。主干网络使用CSPDarknet53[18],采用CSP 结构,将特征映射分为两部分,然后通过跨层次融合结构将之合并,促进底层信息融合,特征提取效果更佳,如图2(e)所示。CSPDarknet53保留经典的残差结构,能提取更深层的特征信息,如图2(c)所示;引入Mish 激活函数,提高网络对非线性特征的提取能力,如图2(a)所示。在颈部网络中,引入SPP模块[19],将不同尺寸的特征图转化为特征相同的特征向量,解决输入特征尺寸不统一的问题,如图2(b)所示;并将双向PANet特征融合结构代替单向FPN结构,提升网络的特征提取能力。颈部网络中存在三层、五层卷积块,起特征通道变换作用,如图2(d)所示。在网络训练中,使用CIoU Loss[20]代替原始MSE Loss。在预测输出端,使用DIoU NMS[20],选择更合理的预测框,提升检测精度。
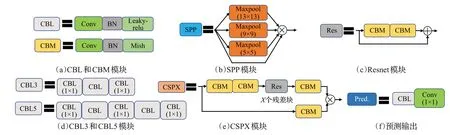
图2 YOLOv4模块组成Fig.2 Compositions of YOLOv4 module
1.2 改进YOLOv4野生香菇检测模型
在YOLOv4基础上,从模型轻量化和精度优化两方面进行结构优化设计。首先特征提取网络采用轻量级的ShuffleNetv2 以精简网络参数,减少计算量。其次在网络特征融合和输出部分,采用ASFF特征融合结构替代原始的PANet 结构以减少网络计算量,检测分支1 中普通3×3 卷积替换为金字塔卷积PyConv,检测分支3中普通3×3 卷积替换为深度可分离卷积DWConv 以简化检测分支。最后进行精确度优化操作,在网络模型末端引入SA 轻量级注意力模块提高检测精度,使用WeightDIoUNMS替代原始NMS选取更合理预测框,如图3所示。
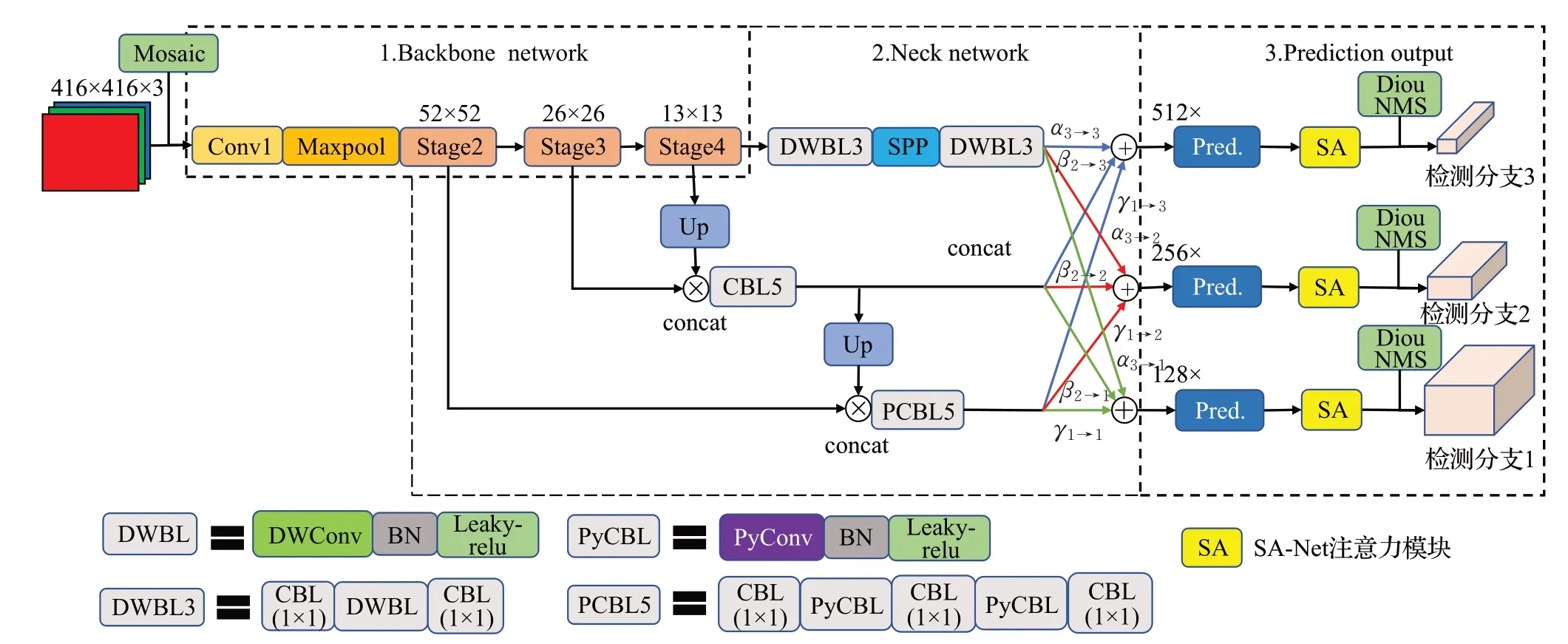
图3 改进YOLOv4网络结构图Fig.3 Improved YOLOv4 network structure
1.2.1 ShuffleNetv2
ShuffleNetv2[21]在ShuffleNetv1[22]基础上,引入通道“分流-重组合”的概念,重新设计基本结构模块,分为基本单元与下采样单元两种,如图4所示。其中,ChannelSplit实现通道分流,使网络参数量和计算量大大减少;基本单元需分别经过同等映射和3 个连续卷积组成倒残差结构进行特征提取,下采样单元与基本单元结构相似,不同的是其在两条通道路径中都引入参数stride=2 的DWConv,实现下采样操作;Channel Shuffle 进行特征重组融合,提高特征提取能力。一言概之,ShuffleNetv2结合通道分流重组思想和深度可分离卷积,在模型效率上提升明显。ShuffleNetv2 1×网络结构如表1 所示,其中每个Stage层都是由多个单元模块堆叠而成。
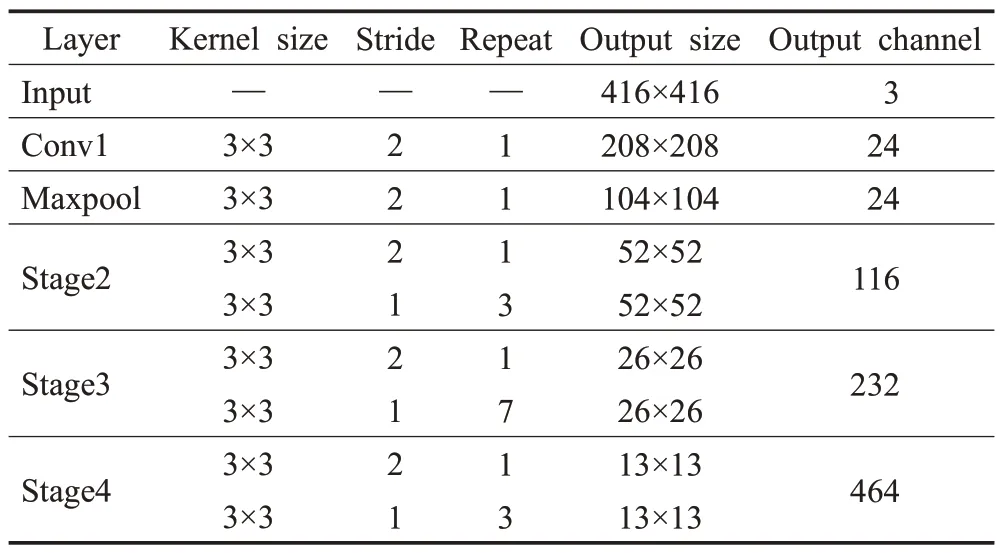
表1 ShuffleNetv2结构Table 1 Shufflenetv2 structure
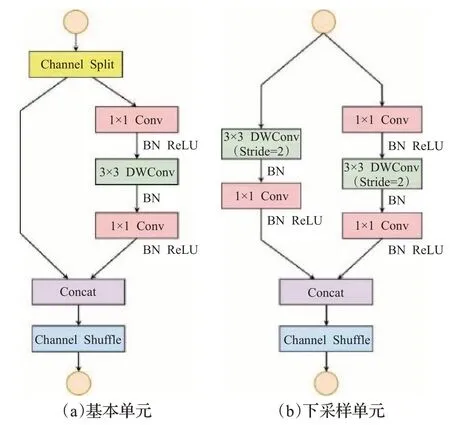
图4 ShuffleNetv2模块组成Fig.4 Shufflenetv2 module composition
1.2.2 特征融合结构和检测分支轻量化
对特征融合模块和检测输出部分进行轻量化设计,即引入ASFF 特征融合模块,并在检测分支中将深度可分离卷积和金字塔卷积替代普通Conv。
PANet结构检测效果好,但过量运算会拖累效率,而FPN特征提取效果较差,因此引入ASFF模块。ASFF[23]是在FPN 基础上,通过权重参数的方式,将不同层的特征图进行融合,以充分利用高层特征的语义信息和底层特征的细粒度信息。图5 即为PANet 与ASFF 的对比,两者前部分操作一致,均需要2次Concat操作;ASFF后部分只需要各通道之间进行求和(Add)操作,特征层数不变,设特征层数为Q,而PANet后部分进行拼接(Concat)操作,特征层数加倍,则为2Q,后续计算量远远大于前者。所以ASFF计算量明显小于PANet。
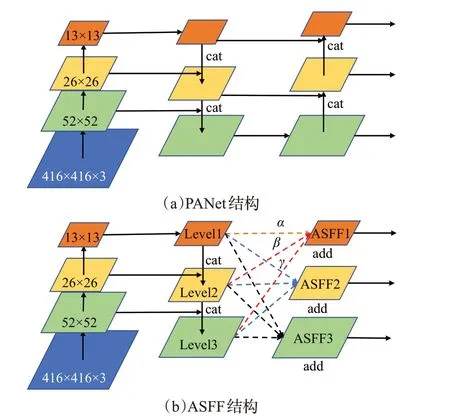
图5 不同特征融合模块示意图Fig.5 Schematic diagrams of different feature fusion modules
其次,求和操作的特征提取能力劣于拼接操作,为解决此问题,ASFF 引入空间权重系数,通过Softmax 限定幅值范围,由网络自适应学习得到,以加强重要特征的权重,提高特征提取能力。
如图5(b),X1、X2、X3分别是来自经过FPN结构3个特征层的特征,分别通过直连、上采样和下采样获得特征向量X1→l、X2→l、X3→l(l=1,2,3),此时,三个特征向量大小完全一致,后与空间权重系数αl、βl、γl相乘,得到融合特征ASFFl(l=1,2,3),如公式(1)所示:
其中,参数αl、βl、γl满足下列条件:
总的来说,ASFF 是将加权思想与求和操作相融合的特征融合结构,在保证精度的前提下,检测效率优势明显。
传统Conv 采用固定尺度卷积核,参数量和计算量明显大于深度卷积和分组卷积,而深度可分离卷积[15]由深度卷积和逐点卷积组合而成。设输入特征尺寸为H×W×M,卷积核尺寸为K×K×M,输出特征尺寸为H′×H′×N,标准卷积计算量为K×K×M×N,而深度可分离卷积计算量只有K×K×M+M×N,仅为标准卷积的,计算量明显减少,如图6所示。
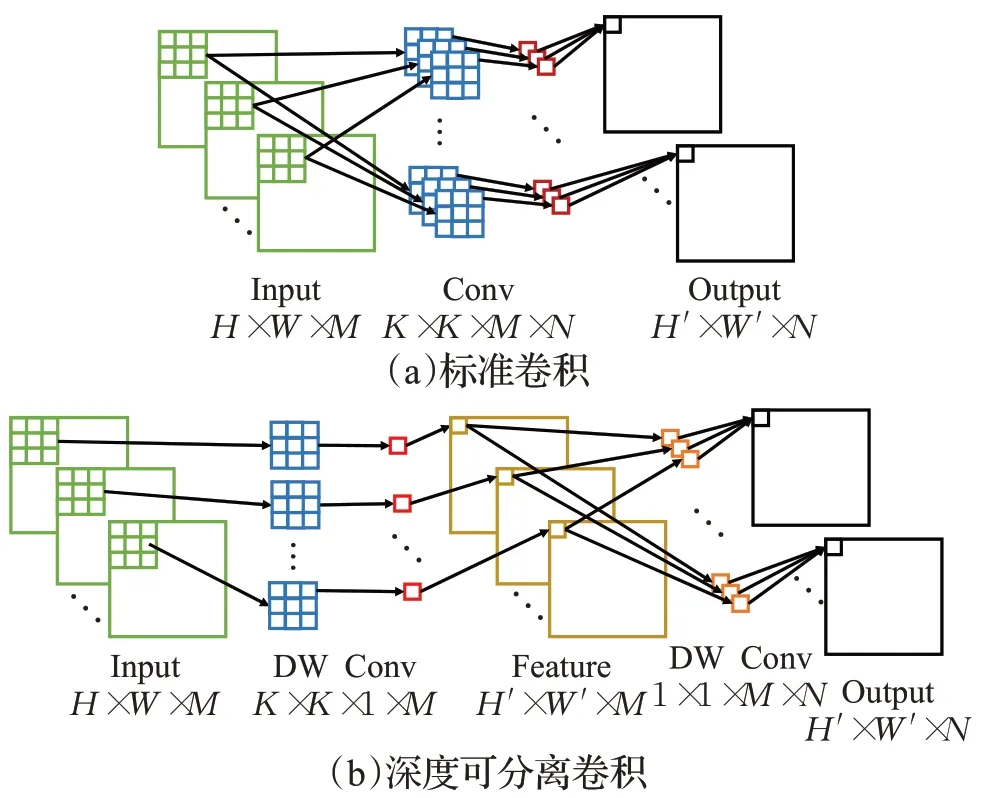
图6 普通卷积与深度可分离卷积示意图Fig.6 Schematic diagrams of normal convolution and depthwise separable convolution
金字塔卷积[24]采用多尺度、多深度的卷积核以提取多尺度特征;其中,大尺寸卷积核捕捉更细节的空间信息,特征检测能力更强,且深度较浅,以避免计算量激增;同时以组卷积的形式对输入特征进行并行卷积运算,计算量和参数量明显减少,计算效率明显提高,结构如图7所示。因此引入深度可分离卷积和金字塔卷积。

图7 标准卷积与金字塔卷积Fig.7 Standard convolution and pyramid convolution
标准卷积检测精度最优,而计算量大,检测效率较低。对于深度可分离卷积和金字塔卷积,前者在实时性方面提升更明显,后者则在模型参数量和检测精度两方面取得平衡,但卷积单元增多,步骤增加,计算效率有所下降。三种卷积各有优劣,可应用于不同检测分支。
对于三个检测分支,由于其特征图尺寸与特征层数的差别,在目标检测网络中的作用也不一致。检测分支1,特征尺寸最大,通道最少,是香菇小目标检测的主要部分。金字塔卷积会减少参数量,且能保证精确度,综合效能好。故检测分支1 中“PCBL5”模块引入了金字塔卷积,为避免过大卷积核对计算效率的不利影响,只引入由3×3卷积和5×5卷积组成的金字塔卷积。检测分支2,特征尺寸与通道数均为中等,也同样在目标检测任务中作用明显,采用标准卷积最大程度上保证较高水平的精确度,如图3 中“CBL5”所示。检测分支3,特征图最小,通道最多,在目标检测任务中作用最小,故采用计算效率最高的深度可分离卷积,有效减少参数量和计算量,对检测精度影响程度最小。故检测分支3 中2 个“DWBL”引入深度可分离卷积。
轻量化设计在一定程度上会造成检测精度下降,引入SA注意力模块和Weight DIoU NMS后处理算法,以少量计算代价提高检测准确率。
轻量化注意力SA[25]结合SGE-Net[26]中的特征通道分组理念和ShuffleNetv2中用于保证通道信息高效交互的Channel Shuffle模块,实现空间注意力与通道注意力的轻量化融合,以少量计算量提升检测精度,结构如图8所示。由图8得,SA分三个部分,分别为特征分组、混合注意力、特征聚合。特征分组将输入特征图X∈ℝC×H×W分为g组子特征(sub feature)(k=1,2,…,g)。混合注意力将子特征Xk依据通道维度分为两个子特征Xk1,(k=1,2,…,g);Xk1进行通道注意力操作,Xk2进行空间注意力操作。特征聚合先利用Concat对经过注意力特征强化的进行拼接操作得到,再利用Channel Shuffle 保证各子特征之间的信息交互,得到最终的注意力特征图X′。
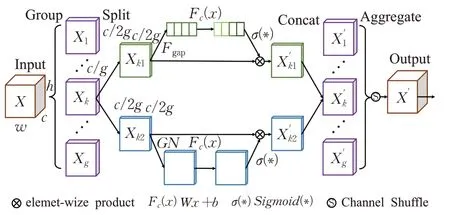
图8 SA模块Fig.8 SA module
SA通过分组操作与Split操作实现特征流的并行传递,参数少,计算效率高。同时SA 属于复合注意力机制,比单一的空间或通道注意力效果更好。
在检测算法生成预测框之后,通常使用非极大值抑制算法(non maximum suppression,NMS)消除多余检测框,但由于作用机制较为简单,易出现目标漏检情况,尤其针对密集的小目标检测,因此,YOLOv4采用DIoUNMS。DIoU-NMS 在NMS 基础上,将DIoU 替代IoU,加入距离影响因子,对漏检问题有所改善,如公式(3)所示:
其中,Si为预测框存在性得分,M为当前预测得分最高的预测框,bi为待处理的预测框,Ni为设定的阈值。DIoU-NMS 虽能缓解NMS 的漏检问题,但其得分最高框M仍沿用传统NMS的定义,精度提升有限。
引入Weight NMS[27],冗余框也可能定位准确,舍弃冗余框剔除机制,提出坐标加权平均概念,对得分最大框M重新定义,如公式(4)所示:
其中,权重wi=Si×IoU(M,bi),表示得分与IoU的乘积。
3.5.2饲料配方小鸡阶段:玉米58%、豆粕30%、鱼粉5%、酵母3%、油脂1%、骨粉1.5%、食盐0.5%、预混合饲料1%。中鸡阶段:玉米62%、豆粕27%、鱼粉3%、酵母3%、油脂2%、骨粉1.5%、食盐0.5%、预混合饲料1%。大鸡阶段:玉米65%、豆粕23%、鱼粉2%、酵母4%、油脂3%、骨粉1.5%、食盐0.5%、预混合饲料1%。
Weight NMS 解决最优框M的问题,但并未解决漏检问题。原始公式中用到IoU 损失,已说明其缺点,引入DIoU损失函数,加入距离损失因子,减少漏检情况发生,如公式(5)所示:
其中,权重wi=Si×DIoU(M,bi)。
2 实验设置
2.1 实验平台
实验硬件平台为Intel®CoreTMi9-10885@2.40 GHz处理器,内存16 GB,NVIDIA Quadro RTX 5000 显卡,显存16 GB。软件平台为Win 10 系统,Pytorch 框架,Pycharm环境。
2.2 实验数据
为保证野生香菇环境的多样性,使用在线下载的野生香菇图片数据,主要是在东北、华北野外丛林里拍摄得到的,包含小尺寸与大尺寸、阴暗光照和正常光照等多种场景,部分图像如图9所示。图片372张,数据量较少,为提高图片数据丰富度,增强模型泛化能力,对图片数量进行扩增。首先将原始数据集分为原始训练集和原始测试集,再使用随机颜色(锐度、亮度、对比度)、随机噪声(高斯、椒盐)方法分别处理原始训练集和原始测试集,扩增数据,得到数量为880 的总训练集和数量为232的总测试集,共1 112张数据图片,流程如图10所示。

图9 野生香菇示例图片Fig.9 Sample picture of wild shiitake mushrooms
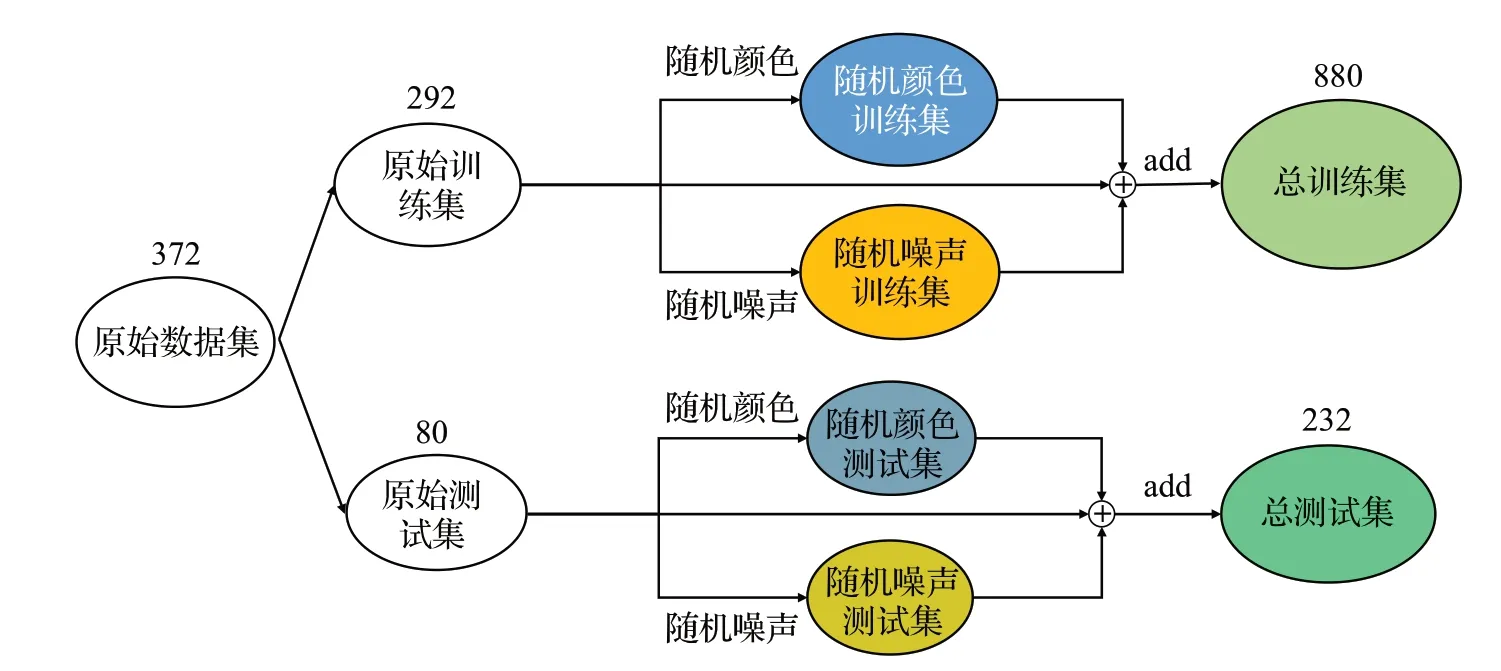
图10 数据扩增示意图Fig.10 Schematic diagram of data amplification
利用LabelImg 进行数据标注,利用K-means++对锚框进行聚类分析,以获取更符合蘑菇图像大小的初始锚框。
2.3 模型训练与评价
1 112 张图片按照8∶2 的比例划分训练集和测试集。使用Adam优化器训练模型,启动mosaic数据增强操作,标签平滑参数ls=0.005,图片输入尺寸为416×416×3,Batch Size=8,总训练次数140 Epoch,采用“冻结-解冻”策略,其中冻结训练70 Epoch,初始学习率lr0=1×10-3;解冻训练70 Epoch,初始学习率lr1=5×10-5。考虑到训练过程采用“冻结-解冻”策略,若采用余弦退火学习率会导致冻结训练与解冻训练的过渡阶段的不稳定,故采用随机衰减学习率。
IoU 指标为0.5,选用检测精度AP、F1 系数指标、每分钟检测图片数FPS 以及模型权重尺寸4 个指标评价模型,计算如公式(6)~(9)所示。其中P、R 分别是准确率和召回率,AP为P-R曲线面积,F1表示P和R的均衡性;FPS反映检测速度。
其中,NTP是正确地检测为正样本数量,NFP是错误地检测为正样本数量,NFN是错误地检测为负样本的数量。Ci为检测种类数,此处只有香菇一类,Ci=1。
3 实验结果分析
3.1 消融实验
如表2 所示设计消融实验,组别1 表示YOLOv4 模型,组别2表示主干网络使用ShuffleNetv2的网络模型,组别3 表示在组别2 的基础上引入ASFF特征融合结构的网络模型,组别4 表示在组别3 的基础上进行分支轻量化改进的检测网络,组别5 表示在组别4 的基础上引入轻量化注意力模块SA的改进网络,最后,组别6表示在组别5的基础上使用Weight DIoU NMS的检测模型。

表2 消融实验设计Table 2 Design of ablation experiments
由表3 得,组别2 相较于组别1,AP、F1 值有轻微下降,FPS和模型权重尺寸大幅度改善,说明ShuffleNetv2主干网络对精确度影响较小,而检测速度与模型权重尺寸改善明显。组别3 相比于组别2,AP、F1 略有波动,FPS 由60.06 提升至67.82,说明ASFF 轻量化提升效果也较为明显。组别4相比于组别3,AP和F1下降幅度为0.01~0.02,FPS变化幅度小,模型权重尺寸由100.93 MB缩减为52.27 MB,说明第一检测分支引入金字塔卷积,第三检测分支引入深度可分离卷积的操作对模型权重尺寸的改善效果明显。组别5相比于组别4,AP和F1大约都提高0.02,FPS 和模型权重尺寸几乎不变,说明SA注意力模块在保持模型检测速率和尺寸的前提下,能有效提升检测精度。组别6相比于组别5,AP和F1大约都提高0.01,FPS 和模型权重尺寸同样变化幅度较小,说明Weight DIoU NMS也对精度有一定的提升效果。最终组别6相比于组别1,检测精度下降幅度小,检测速度和模型权重尺寸改善明显:AP仅下降2.74个百分点,F1下降0.032,FPS 提升幅度达82.9%,模型权重尺寸下降78.6%。为方便表达,将组别6命名为改进YOLOv4。
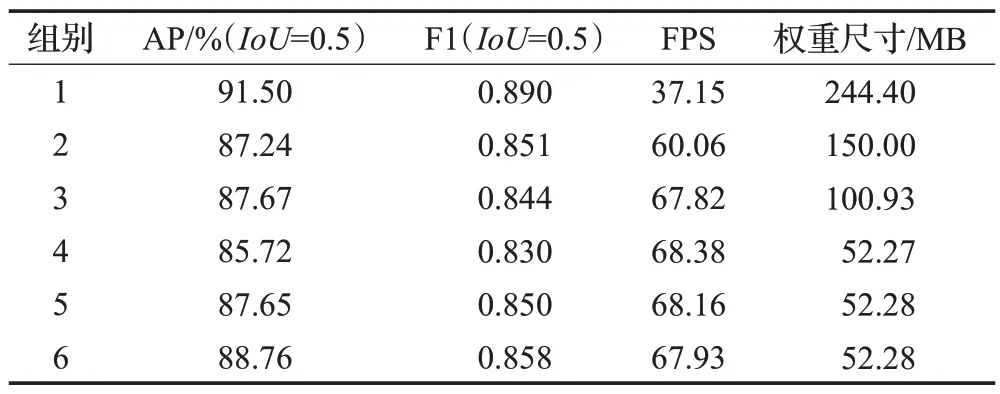
表3 消融实验结果Table 3 Results of ablation experiments
为直观比较改进YOLOv4 相比于YOLOv4 精度的变化以及数据扩增对检测精度的影响,统计训练过程中损失函数Loss和精度指标AP的变化,如图11所示。由图11 得,改进YOLOv4 相比于YOLOv4,Loss 较高,AP较低,但差距较小,与上文统计数据相互印证,分析原因可能是引入深度可分离卷积和减小模型深度的操作不利于特征提取,进而影响检测精度,但影响程度小。
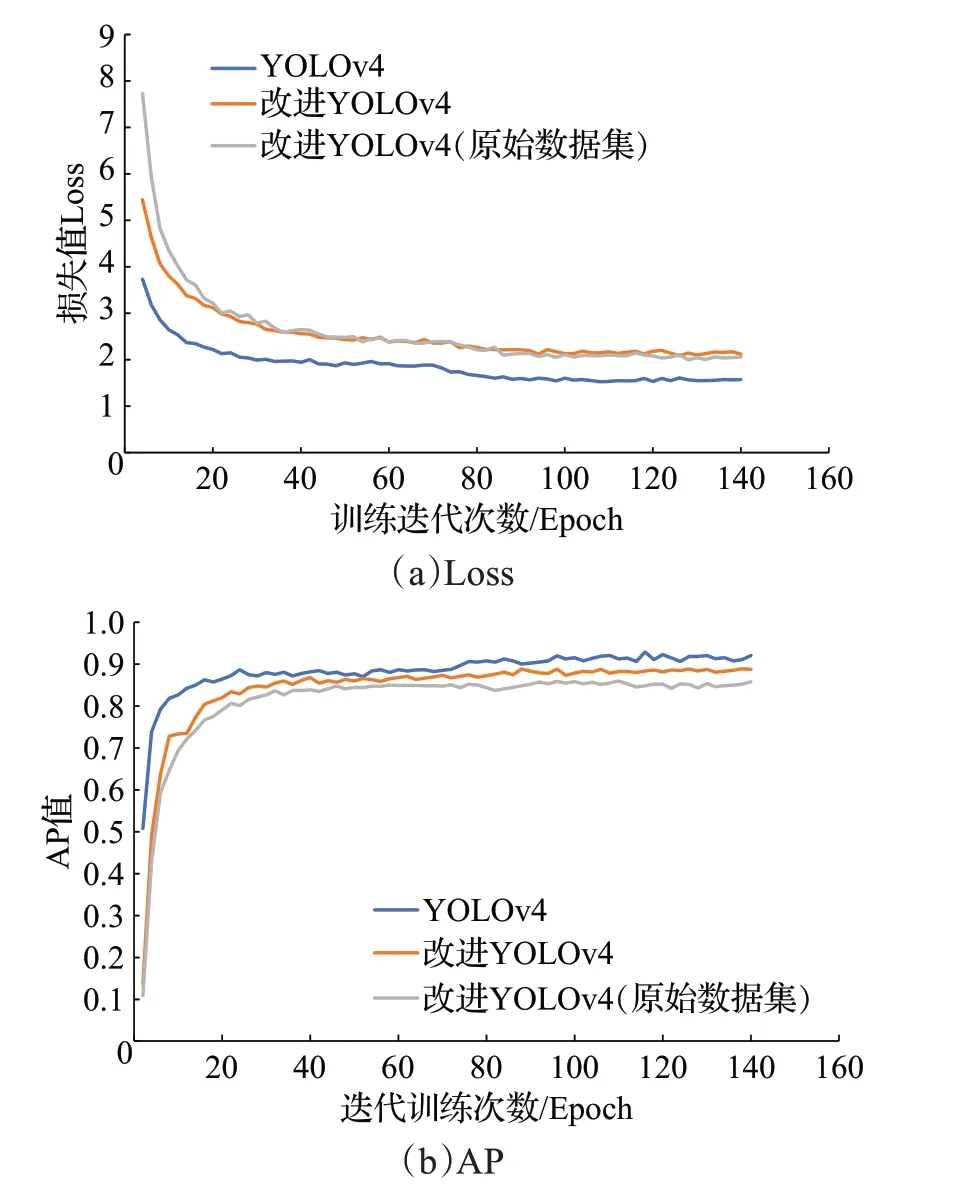
图11 训练过程中的Loss和APFig.11 Loss and AP during training
在训练前期,数据扩增后的模型Loss 值更低,模型拟合度更高;在训练后期,尽管两者Loss几近相等,但数据扩增后,模型在测试集中检测精度更高,泛化性更好。由此可见,数据扩增对模型性能提升有积极作用。
3.2 比较实验
为检验改进YOLOv4 的性能,将其与主流算法EfficientDet、YOLOv4-tiny、EN0-YOLOv3和MN3-YOLOv4-lite 网络进行比较,图12 是5 种方法部分测试图像的检测结果,表4是进一步对5种方法各性能参数的结果统计。
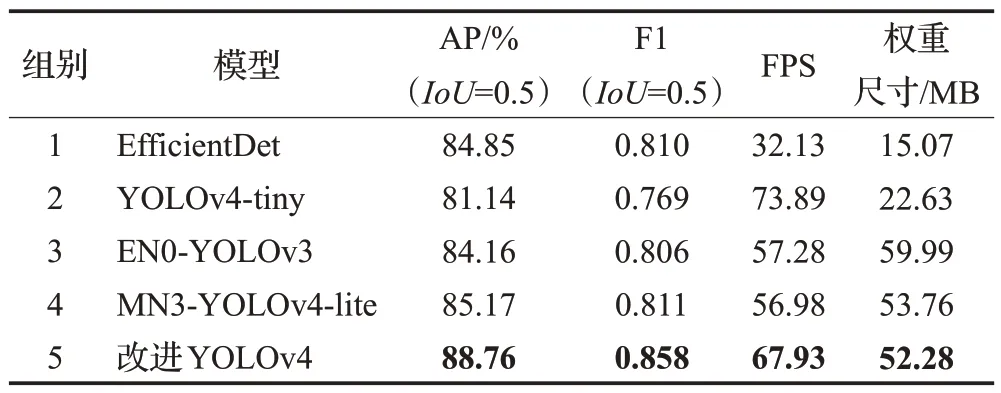
表4 比较实验结果Table 4 Results of compared experiments

图12 不同网络模型检测结果Fig.12 Detection results of different network models
由图12 得,5 种模型误检率都很低,但漏检率差距较大。对于近距离的蘑菇目标而言,5种检测方法都有较高的检测准确率与召回率,其中,改进YOLOv4 漏检更少,检测精度略占优势。而对于远距离蘑菇目标而言,5 种方法检测精度差距较大,YOLOv4-tiny 与MN3-YOLOv4-lite 检测效果漏检率最高,检测精度最低,EfficientDet 与EN-YOLOv3 漏检更少,检测精度相对较高,改进YOLOv4 误检率最少,检测精度最高。总体而言,改进YOLOv4检测效果占优。
由表4 得,EfficientDet 检测精度较低,FPS 指标较低,而模型权重尺寸小,分析原因可能是EfficientDet调用的BIFPN 结构有5 层特征层,特征流为串行传递方式,相比于常用的3层特征结构计算效率更低。由此可见,检测速率不仅仅与模型参数有关,还受多方面因素的影响。YOLOv4-tiny同样参数量较少,且检测速度最快,但检测精度最差,不符合实际要求。剩余的3 个模型权重尺寸位于50~60 MB,且EN0-YOLOv3 与MN3-YOLOv4 的FPS 都约为57,而改进YOLOv4 速度指标FPS 约为68,明显优于前两者;EN0-YOLOv3 与MN3-YOLOv4-lite检测精度明显劣于改进YOLOv4。综上所述,本文的改进YOLOv4 模型实现了在检测精度、运算速率与参数尺寸三方面的平衡,满足实际应用的要求。
4 结束语
为满足野生蘑菇检测的实时性和准确度要求,提出改进YOLOv4 检测模型。在YOLOv4 基础上进行轻量化改进:引入高效ShuffleNetv2作为主干网络,将PANet替换为高效的ASFF 进行特征融合,并使用深度可分离卷积DWConv 和金字塔卷积PyConv 分别替换第三、第一检测分支中普通卷积。在轻量化改进基础上进行检测精度的优化:引入SA注意力模块,以少量计算代价提高检测准确率;使用改进的WeightDIoU NMS替代原始NMS,预测框选择更加合理。
改进YOLOv4 模型AP 为88.76%,F1 为0.858,FPS为67.93,模型权重尺寸为52.28 MB,相较于YOLOv4,检测精度基本不变,实时性得到大幅度提升,模型权重尺寸急剧减小,且相较于其他主流模型,综合性能更优,有利于无人捡拾设备的部署运行。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
专用汽车(2016年1期)2016-03-01
专用汽车(2015年4期)2015-03-01
