
基于Transformer-VAE的ADS-B异常检测方法
2023-10-29 14:18丁建立张琪琪霍纬纲
系统工程与电子技术 2023年11期
丁建立, 张琪琪, 王 静, 霍纬纲
(1. 中国民航大学计算机科学与技术学院, 天津 300300; 2. 中国民航大学信息安全测评中心, 天津 300300; 3. 中国民航大学安全科学与工程学院, 天津 300300)
0 引 言
广播式自动相关监视(automatic dependent surveillance-broadcast, ADS-B)技术基于全球卫星导航系统和地空、空空数据链通信等技术向空中交通管制(air traffic control, ATC)中心以及其他相邻空域内飞机周期性广播飞机的经纬度、高度、速度等信息。ADS-B报文[1]被视为航空信息系统的重要数据源,其安全性对航班间隔管理、空中交通流量管理、空中交通防撞等功能子系统有着至关重要的影响。一旦ADS-B报文遭到攻击,整个航空信息系统的安全性将受到威胁,ADS-B报文的安全已成为航空安全的重要组成部分。然而,ADS-B报文以明文的形式广播并且协议缺乏基本的安全机制,攻击者可以利用无线射频传输技术轻易实现对ADS-B的欺骗干扰[2]。因此,研究有效的ADS-B安全解决方案具有重要意义。
传统的ADS-B安全解决方案主要包括3类,第1类为基于密码学[3-4]的方法,但此类方法需要修改协议的内部机制与硬件系统,因此在实际中应用难度较大。第2类为基于多点时差定位[5]的方法,该类方法利用ADS-B报文到达不同站点的时间差校验发送位置的正确性,但此类方法高度依赖大量地面站的参与,实施难度大、附加成本高,不易在大范围内推广。第3类为基于多阵列天线[6]的方法,该类方法利用多面阵列天线对ADS-B报文进行空间位置测量来验证目标的位置特征,此类方法实施成本较低,但仍需要在ADS-B系统上附加额外的设备。
为了避免硬件和协议更改带来的高昂成本,基于深度学习的异常检测方法逐渐受到关注。在此类方法中,无监督学习方法因为不需要标记数据进行模型训练且可以识别未知类型异常而得到了广泛的研究。ADS-B报文是具有多维特征的时间序列数据,Habler等[7]采用基于自动编码器(autoencoder, AE)结构的神经网络模型对ADS-B报文进行重构,使用长短时记忆(long short term memory, LSTM)网络作为编解码器来学习正常ADS-B报文的特征,通过滑动窗口来计算ADS-B报文序列的依赖关系并利用重构误差检测异常,有效地解决了传统机器学习方法无法捕捉时间依赖性的问题。丁建立等[8]在上述模型的基础上通过计算每个滑动窗口的统计特征来增加ADS-B序列特征维度,使模型能够更好地捕捉数据的时间依赖性,检测性能也有了较大提升。罗鹏等[9]采用双向门控循环单元神经网络预测ADS-B报文,并将预测值与真实值的差值放入支持向量数据描述(support vector data description, SVDD)中对样本进行二次训练,通过创建出的超球体分类器检测ADS-B异常报文,同时解决了ADS-B报文异常检测阈值的自适应问题。
飞机在飞行过程中,ADS-B报文在各个维度上的特征值会在正常范围内波动,表现出随机性。然而上述基于确定性模型的方法忽略了数据中随机性的影响,可能会发生误判问题[10]。对此,Fraccaro等[11]指出了在模型中引入随机变量来建模数据中的随机性能够改善并增强模型性能。Luo等[12]提出了基于变分AE(variational AE, VAE)的ADS-B异常检测算法,假设每个ADS-B报文除可见的特征外还有额外的潜在随机变量,并使用LSTM来计算该变量的分布,随后从计算出的分布中采样得到潜在随机变量的样本用于重构输入数据,随机性则可以通过采样过程融入建模过程。
ADS-B报文序列是基于时间的一系列数据,ADS-B报文在过去的状态会对未来较长时期之后的状态产生影响,表现出长程依赖性。然而,现有异常检测算法却无法很好地捕捉ADS-B报文序列中的长程依赖关系。而Transformer[13]模型通过自注意力机制使得输入序列中每个时间点的数据都融合了之前以及之后时间点的所有特征,有效地提升了模型捕捉时间序列中长程依赖关系的能力。基于此,Meng和Duan等[14-15]利用Transformer模型来构建时间序列异常检测模型,显著地提升了模型的检测性能和鲁棒性。
此外,在一定的时间段内,ADS-B报文序列通常表现出整体性特征,例如飞机的飞行过程可以分为起飞、爬升、巡航、下降和着陆几个阶段,相应地,飞机的高度呈现出不同的变化趋势。ADS-B报文序列在不同阶段有不同的整体性特征,因而异常报文的判定标准也会发生变化,识别此类特征并加以利用对于提升模型的检测性能具有重要作用。然而,现有的ADS-B异常检测算法无法获得输入序列的整体性特征。在自然语言处理领域,Bowman等[16]通过基于LSTM的VAE模型引入随机变量,用于表示单个语句的整体性特征,证实了整体性特征在控制模型生成文本的语义连续性方面具有重要作用,因此本文参考该研究工作引入随机变量来表示序列的整体性特征。
综上所述,本文提出了基于Transformer-VAE的无监督异常检测算法,通过Transformer编码器的自注意力机制建模ADS-B报文序列中的长程依赖关系,基于VAE框架,在Transformer模型中引入随机变量来反映ADS-B报文序列的随机性和整体性特征。然后通过特殊的融合模块将该变量与Transformer解码器的输出进行融合,实现ADS-B报文的重构,最后利用重构误差来判定异常。在真实的数据集上的实验表明,本文提出的算法与其他基线算法相比在所设定的不同攻击场景下具有更高的准确率。
1 准备知识
1.1 Transformer
Transformer是深度学习中用于处理时间序列数据的神经网络模型,该模型完全基于自注意力机制来建模序列中的时序特性,通过将序列中的任意两个元素直接连接,有效地捕捉序列长程依赖关系。Transformer基于编码器-解码器结构,其中的编码器与解码器部分各自都是通过堆叠多层相同的模型构建而成,每一层模型主要包括多头注意力(MultiHead)和前馈神经网络(feedforword neural network, FFN)两个主要子模型。
多头注意力子模型主要基于缩放点积注意力机制,注意力权重矩阵运算过程如下:
(1)
式中:Q表示查询向量矩阵;K表示键向量矩阵;V表示值向量矩阵;dmodel表示模型隐状态的维度。
多头注意力机制则是使用不同的线性映射参数矩阵将输入数据矩阵映射为多个不同的查询向量矩阵、键向量矩阵和值向量矩阵,作为缩放点积注意力机制的输入,此过程可定义为
(2)

FFN由两次线性映射以及一个ReLU[17]激活函数构成,该网络的运算过程如下:
FFN(x)=W2max(0,W1x+b1)+b2
(3)
式中:W1,W2∈Rdmodel×dmodel是线性映射的参数矩阵;b1,b2∈Rdmodel是偏置项参数;x表示特征维度为dmodel的输入数据。
1.2 VAE

logp(x)=DKL(qφ(z|x)‖p(z|x))+LVAE(φ,θ;x)
(4)
式中:DKL(·)表示变分后验分布qφ(z|x)与真实后验分布p(z|x)之间的KL(Kullback-Leibler)散度;φ和θ分别表示编码器和解码器中的参数;LVAE(·)表示边缘对数似然函数的下界,也是变分自编码器所使用的目标函数,VAE通过优化这一下界来优化模型中的参数,其定义如下:
LVAE=-DKL(qφ(z|x)‖pθ(z))+Eqφ(z|x)[logpθ(x|z)]
(5)
式中:第一项通过最小化变分后验分布与先验分布之间的KL散度来正则化潜在变量的分布;而第二项则是通过最大化对数似然函数logpθ(x|z)来实现对原始数据的重构。
2 ADS-B异常检测方法
2.1 问题定义
定义X={x1,x2,…,xL}表示原始ADS-B报文序列,其中L为原始ADS-B报文序列的长度。定义xt=[t,lon,lat,alt,id,s1,s2,…,sn]表示ADS-B报文特征向量,代表在t时刻具有唯一识别码(id)的飞机所在位置的经度(lon)、纬度(lat)以及气压高度(alt)等,s1,s2,…,sn代表飞机附加特征,本文分配一个字段代表飞机的航行方向,即航向(s1)。
由于原始ADS-B报文序列长度过长,故采用步长为1的滑动窗口机制处理原始报文序列,将其分割为若干段长度为k的子序列作为模型的输入,其中任意一段ADS-B子序列表示为{xt-k+1,xt-k+2,…,xt-1,xt}。
2.2 模型设计
本文提出了基于Transformer-VAE的ADS-B异常检测模型,该模型是一个端到端的无监督深度学习模型,其结构如图1所示。

图1 模型结构图
Transformer-VAE模型主要由编码器、解码器和估计网络3个模块组成。整体上采用VAE框架通过引入潜在随机变量z捕捉ADS-B报文序列的随机性。编码器模块用于建模ADS-B报文序列中的长程依赖关系,将ADS-B报文的特征向量编码到低维潜在空间中,得到包含上下文特征的潜在表示。估计网络用于计算潜在随机变量z的概率密度的参数,建模子序列的整体性特征。在解码器模块中,将Transformer解码器的输出与代表整体性特征的潜在随机变量的样本融合以进行样本特征的重构。
2.2.1 Transformer-VAE编码器
Transformer-VAE的编码器模块具有与原始的Transformer模型类似的结构,由Ne个相同的编码器层构成。编码器使用滑动窗口生成的ADS-B报文子序列{xt-k+1,xt-k+2,…,xt-1,xt}作为输入,完全基于自注意力机制将报文的特征向量映射到低维潜在空间中,从而得到报文子序列的上下文表示。
以第t个时间点处的ADS-B报文的特征向量xt为例,首先通过输入数据向量与位置编码向量相加,将位置特征引入计算过程:
(6)
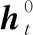

(7)
式中:MultiHead(·)表示多头注意力机制;LayerNorm(·)表示层归一化机制[17]。随后计算结果Bi被进一步输入前馈神经网络模块:
(8)
式中:FFN(·)表示前馈神经网络。经过Ne层的迭代后,最后一编码器层的输出HNe将被输入到估计网络和解码器,以分别用于估计潜在随机变量后验分布的参数以及进行多头注意力机制的计算。
2.2.2 基于神经网络的后验分布估计网络
Transformer-VAE通过引入潜在随机变量来显式地建模输入ADS-B序列的整体性表示。包含潜在随机变量的模型所面临的一大挑战是建模相关的后验分布,在Transformer-VAE模型中,假设其服从协方差矩阵为对角矩阵的多元高斯分布,并采用神经网络来估计分布的相关参数。
首先使用平均池化操作来得到滑动窗口中ADS-B报文序列的确定性整体特征表示h:
(9)

(10)
式中:fμ(·)和fσ(·)分别为全连接神经网络;diag(·)表示以输入向量为对角元素的对角矩阵。在得到随机隐变量的后验分布的参数后,输入ADS-B报文子序列的随机性整体性特征可通过在该分布中采样得到。
由于该采样过程无法微分,为了使得整个模型可以通过梯度下降算法端到端地训练出来,采用重参数化方法[13],通过在标准高斯分布中进行采样来得到服从特定分布的随机性整体性特征z,计算过程表示为
(11)
式中:ε表示从标准高斯分布中的采样结果;z可以表示ADS-B报文子序列的整体性特征。
2.2.3 融入注意力机制的解码器
解码器的主要任务是根据已生成的当前时刻t以及之前的ADS-B报文序列和随机隐变量z重构出下一时间点处的ADS-B报文的特征向量。与编码器类似,解码器使用融合了位置特征的ADS-B报文特征向量作为输入,并且由Nd个相同的解码器层堆叠而成。每一个解码器层主要包括掩码多头注意力机制、交叉多头注意力机制以及前馈神经网络3个模块。
其中,掩码多头注意力机制是指在多头注意力机制中引入掩码以确保在当前时刻t的注意力权重计算以及预测仅依赖于当前时刻之前的ADS-B报文数据,掩码多头注意力模块用于建模已解码出的部分ADS-B报文序列中的时序关系。第i个解码器层中掩码多头注意力模块的计算过程定义如下:
(12)

(13)
最后,前馈神经网络模块被用来进一步提升解码器的表示能力:
(14)
(15)

(16)

2.3 Transformer-VAE模型训练
作为基于VAE的模型,使用变分下界作为模型最终的优化目标,目标函数初步表示为
L=Eqφ(z|X)[logpθ(X|z)]-KL(qφ(z|X)‖p(z)
(17)
式中:第1项通过最大化对数似然函数来实现对原始数据的重构;第2项通过最小化变分后验分布与先验分布之间的KL散度来正则化来正则化潜在变量的分布。式(17)中的对数似然分布logpθ(X|z)[20]可以进一步分解为
(18)
假设每个ADS-B报文所服从的似然分布logpθ(xt|x (19) 式中:为了平衡目标函数中目的不同的两项,引入超参数λ来控制两者的作用;M为蒙特卡罗方法中的采样次数,通常设定M=1。 异常检测的总体流程图如图2所示。 图2 异常检测流程图 图2(a)表示在训练阶段,输入原始的ADS-B报文序列并对其进行特征筛选及归一化处理,将预处理后的时间序列输入到基于Transformer-VAE的深度异常检测模型当中进行重构训练,通过调整Transformer-VAE模型参数以缩小重构序列与真实序列的重构误差,当在验证集上的重构误差达到最小值时停止训练。 图2(b)表示在测试阶段,输入含有异常的ADS-B报文序列并进行数据预处理,利用模型重构出来的序列同原序列之间的重构误差来检测输入序列中的异常,若输入序列为正常的ADS-B报文序列,重构误差将被控制在一定范围内,若输入序列包含异常,重构误差将大于异常分数阈值,从而判定异常。 假设模型对正常数据的重构误差服从高斯分布N(μe,σe),定义异常分数函数fs(xt)为模型重构误差的负对数似然函数,具体表示如下: (20) 式中:et表示t时刻的重构误差,参数μe和σe由验证集中正常数据的重构误差通过极大似然估计法计算得到。 若当前时刻数据的异常分数高于分数阈值η时,则判定此时间点的数据为异常数据,即 (21) 其中,异常分数的阈值选定方式如下:首先计算全部测试集数据的异常分数,随后在异常分数分布的区间内等距离采样100个点,选定其中使得判定结果的F1分数最大的异常分数点作为阈值。 Flightradar24网站可以访问从数千个地面站收集的数据,为了验证模型性能,以在Flightadar24网站采集到的40趟航班完整飞行过程中的ADS-B报文序列作为分析基础,其中每趟航班的飞行过程中约包含6 000个采样点,收集到共计约24万条ADS-B报文序列,将ADS-B报文序列按8∶1∶1比例划分为训练集、验证集和测试集。训练集中全部都为正常序列,用于学习基于Transformer-VAE的重构模型;验证集中也全部都为正常序列,参考提前停止策略,在训练过程中模型在验证集上重构误差达到最低点时停止训练;在正常序列中注入异常序列构成测试集,用于测试模型性能。 在训练过程中,设定滑动窗口的大小为50,设定滑动步长为1。采用Adam[21]作为模型的优化算法,设定其中的参数Batch size为64,并设定初始学习率为0.001,采用Noam[13]学习率衰减算法更新训练过程中的学习率,设定其中的参数Warm step为16 000。经过超参数搜索后,设定Transformer-VAE模型中多头注意力机制中的头数为4,Transformer编解码器中的前馈神经网络尺寸为100,编码器与解码器的层数分别为4和1,模型隐状态及随机隐变量z的维度为84。 为了提取ADS-B报文序列中有意义的特征,选择经度、纬度、高度、速度和航向作为特征,而诸如循环冗余校验码、国际民航组织标识符等字段由于不随时间发生变化,在任务中毫无意义,故而在特征筛选环节被剔除掉。对于一些时间点上的飞行状态缺失,通过用相邻状态来填充缺失状态。若是某条航班数据有多于一半的属性值缺失,将此条数据直接从数据集中剔除。针对少于一半属性值缺失的某条航班数据,采用线性插值法补齐。 为了避免某些ADS-B数据特征差异过大影响到数据分析的结果,同时为了提高模型的收敛速度和精度,采用离差标准化的方法对ADS-B数据进行处理,将每个特征的取值映射到[0,1]之间,转换公式如下: (22) 通过计算精确率P(Precision)、召回率R(Recall)、F1分数(F1-score)来评估异常检测算法,以上指标计算公式如下: (23) 式中:TP表示正常样本被模型正确识别为正常样本的样本数量;TN表示异常样本被模型正确识别为异常样本的样本数量;FP表示异常样本被模型错误识别为正常样本的样本数量;FN表示正常样本被模型错误识别为异常样本的样本数量;P是指被模型正确识别为异常样本的数量占被检测出来的所有异常样本的比例;R是指被模型正确识别为异常样本的数量占数据集中所有异常样本的比例;F1分数为精确率和召回率的加权平均调和值。 考虑到真实飞行状态,模拟了以下5种详细的攻击模式并将构建的ADS-B异常报文混合到正常飞行的数据集中建立测试集评估模型性能,选取包含2 000条ADS-B数据的示例航班,异常报文生成如下: (1) 随机噪声异常通过将第1 000~1 500条ADS-B报文序列任意一个特征的原始值乘以0到2之间随机生成的浮点数而产生,其余报文不做修改。 (2) 幽灵飞机异常通过将来自不同但合法航线的ADS-B报文序列注入测试航班的报文序列而产生,替换报文范围为0~800,长度为800,其余报文不做修改。 (3) 航向偏移异常通过修改第900~1 400条ADS-B报文序列中的航向字段而产生。以100条为一组,每组通过连续增加5度的航向字段(即,对于异常段中的第一条消息,航向将被增加5度,第二条消息被增加10度,依此类推)不断增加,产生异常,每组均从初始位置开始构建异常,其余报文不做修改。 (4) 速度偏移异常通过修改第450~950条ADS-B报文序列中的速度字段而产生。以100条为一组,每组通过连续增加10节的速度字段(即,对于异常段中的第一条消息,速度将被加速10节,第二条消息被加速20节,依此类推)不断增加速度,产生异常,每组均从初始位置开始构建异常,其余报文不做修改。 (5) 拒绝服务(denial of service, DOS)攻击异常通过在第977~1 377条和第1 692~2 000条两组连续ADS-B报文序列中,每组只保留第一条报文并删除其余报文(将报文的特征值全部置零)而产生。即只有间隔足够大的消息才能到达目的地,从而模拟拒绝服务攻击或网络延迟模式,其余报文不做修改。 3.5.1 实验结果 图3~图7为Transformer-VAE模型异常检测实验结果图,横坐标为ADS-B报文序列号,纵坐标为异常分数值,红色虚线为异常分数阈值,红色长方形阴影区域为异常注入的范围。从图中异常点的异常分数明显高于非异常点这一现象可以看出,该模型异常检测效果十分显著。 图3 随机噪声检测 图3为随机噪声异常检测结果图,如图所示,在注入攻击范围内报文的异常分数明显高于阈值;图4为幽灵飞机异常检测结果图,使用正常的ADS-B报文序列替换掉测试航班的0~799条报文序列,第800条报文为两段报文序列的衔接处,故异常分数在此处达到峰值,这表明Transformer-VAE模型对报文序列中的数据变化十分敏感。 图4 幽灵飞机检测 图5为航向偏移异常检测结果图,注入攻击范围为第900~1 400条报文,第900~1 000条报文由于航向与正常报文偏移程度的不断增加导致异常分数逐渐增大并在第1 000条报文处达到此段异常分数峰值,由于每组异常报文的偏移程度均从0开始增加,故在第1 000条报文之后,异常分数呈急速下降的趋势,其余各组异常报文的异常分数变化趋势同理;图6表示速度偏移检测结果图,其原理与图5相似,故不详细展开论述。 图5 航向偏移检测 图6 速度偏移检测 图7表示DOS攻击异常检测结果图,注入攻击范围为第977~1 377条和第1 692~2 000条报文序列,由于每组除第一条报文剩余序列被全部置零,因此异常分数均相同,同时异常分数在被置零的报文序列与原始报文的拼接处的报文数据点达到峰值。 图7 DOS攻击检测 另外,为了客观验证模型性能,选取了具有代表性的5种异常检测方法进行对比实验,这5种方法分别为一类支持向量机(one class-support vector machine, OC-SVM)[22]、局部异常因子(local outlier factor, LOF)算法[23]、孤立森林(isolation forest, IF)[24]、基于深度学习的LSTM-AE[8]和LSTM-VAE[12]异常检测算法。 (1) OC-SVM:基于核函数的异常检测算法,通过学习正常样本与异常样本的决策边界来识别异常,适用与小样本,低维度的数据集。 (2) LOF:基于密度的异常检测算法,通过比较每个数据点和其邻域点的密度偏差识别异常,适用于小样本的数据集。 (3) IF:基于集群的异常检测算法,通过判断数据空间内某些区域数据点分布的稀疏程度识别异常,适用于异常样本占比很少的数据集。 (4) LSTM-AE: 基于AE的异常检测算法,由LSTM神经网络作为模型的编解码器,通过重构误差和预先设定的阈值进行异常检测,适用于大规模数据集,但模型需要质量较高的训练集进行训练。 (5) LSTM-VAE:基于VAE的异常检测算法,在LSTM-AE的基础上引入了随机变量来捕捉数据中的随机性,适用于大规模数据集,对训练集质量要求不高。 实验结果如表1所示,表1显示了各个异常方法的精确率、召回率和F1分数。由于基于机器学习的方法没有考虑到数据的时序关系导致其检测性能较差,无法检测出DOS攻击。其中,LOF模型的召回率较高但其精确率较低,说明此方法仅仅是将大量的点标记为异常来尽可能多地检测出异常样本。对比OC-SVW、IF、LOF这3种机器学习方法,Transformer-VAE的各项指标比OC-SVW均高于21.95%以上,Transformer-VAE的各项指标比LOF均高于21.35%以上,Transformer-VAE的各项指标比IF均高于22.57%以上。对比LSTM-AE、LSTM-VAE这两种深度学习方法,LSTM-VAE的各项指标LSTM-AE均高于1.75%以上,Transformer-VAE的各项指标比LSTM-AE均高于6.92%以上,Transformer-VAE的各项指标比LSTM-VAE均高于3.02%以上。 表1 各个异常方法的精确率、召回率和F1分数 综上所述,基于深度学习的模型由于考虑到了ADS-B报文序列的时序性,相较基于传统的机器学习方法表现出了更高的F1分数,Transformer通过自注意力机制有效地提升了模型捕捉ADS-B报文序列中长程依赖关系的能力,相较LSTM具有优越性。 而VAE通过引入随机变量来捕捉ADS-B报文序列中的随机性,显著地提升了模型性能,相较AE具有优越性。实验结果表明,针对不同类型的异常,Transformer-VAE算法精确率、召回率及F1分数均优于相关基线算法,表现出良好的性能。 3.5.2 消融实验 为了验证模型各部分的有效性,本组实验测试了不同模型框架对于算法性能的影响,实验参数的设定同第3.2节。具体的模型框架如下: (1) Transformer-AE:未引入VAE结构,即消除图1中的估计网络模块以及解码器模块中的融合机制,消除了潜在随机变量 在模型中的作用,仅使用AE的重构误差作为损失函数,其他同本文。 (2) Transformer-VAE(无融合):未引入融合机制,仅将从估计网络和编码器中计算并采样到的潜在变量z作为解码过程的开始标志向量,即图1中的S0,通过解码器中的自注意力机制将z融入解码过程,其余同本文。 (3) Transformer-VAE:本文所提出的模型。 实验结果如表2所示。Transformer-VAE的各项指标要优于Transformer-AE,其中F1分数比Transformer-AE高3.85%, Transformer-VAE的各项指标要优于Transformer-VAE(无融合),F1分数比Transformer-VAE(无融合)高1.79%,这表明Transformer-VAE模型中的估计网络模块和融合机制对模型检测性能的提升均有正面作用。 表2 Transformer-VAE消融实验 3.5.3 滑动窗口长度的影响 为了验证Transformer的长程依赖性,本组实验测试了改变滑动窗口的长度k对于算法性能的影响,选取循环神经网络(recurrent neural networks, RNN)系列中效果最好的LSTM-VAE算法作为对照实验。由表3可知,在不同的滑动窗口长度下,Transformer-VAE的各项指标要明显优于LSTM-VAE,F1分数最高相差达到6.95%。其中,在滑动窗口长度为500的情况下,Trans-former-VAE的F1分数比LSTM-VAE高5.14%。另外,Transformer-VAE在滑动窗口长度为300的情况下达到下述长度区间内检测性能的峰值,而LSTM-VAE则是在滑动窗口长度为200的情况下达到下述长度区间内检测性能的峰值。实验结果表明,Transformer-VAE能够更好的捕捉ADS-B报文序列的长程依赖关系。 表3 滑动窗口长度对算法性能的影响 3.5.4 潜在空间可视化 为了验证Transformer-VAE模型能够捕捉ADS-B报文的整体性特征,首先从验证集中随机采样2 000条正常的ADS-B报文数据,随后使用已训练完成的模型计算出这些报文数据隐含随机变量的分布并从中采样得到这些报文对应的向量表示z。使用K-Means算法对z进行聚类,并使用不同颜色标出聚类结果,随后使用T-SNE算法对z进行可视化,聚类及可视化结果如图8所示(其中,横坐标与纵坐标代表降维后用于可视化的两个维度)。从图中可以看出,在潜在空间中,采样到的报文数据可以明显地被K-Means算法分成5类,表明本文提出的模型能够捕捉到一定的整体性特征。 图8 可视化结果 ADS-B异常检测算法应考虑到报文序列中的随机性、长程依赖关系以及整体性特征对此,本文从以上3个角度出发,构建了基于VAE和Transformer的ADS-B异常检测算法。利用Transformer编码器的自注意力机制建模ADS-B报文序列中的长程依赖关系并通过改变滑动窗口的长度验证了Transformer的长程依赖性。同时,基于VAE框架,在Transformer模型中引入随机变量来反映ADS-B报文序列的随机性和整体性特征,并通过消融实验与潜在空间可视化实验验证了估计网络模块和融合机制对模型检测性能提升的正面作用以及报文序列的整体性特征。为评估模型性能,针对ADS-B潜在的攻击行为模拟生成5类异常报文,异常检测实验结果表明,所提出的方法在设定的不同攻击场景下,检测性能优于OC-SVM、LOF、IF、LSTM-AE、LSTM-VAE算法。2.4 基于Transformer-VAE的异常检测流程

2.5 阈值确定与异常判定
3 实 验
3.1 实验设定
3.2 数据缺失插值与映射转换

3.3 评估指标
3.4 攻击构建
3.5 实验结果与分析









4 结 论
猜你喜欢
汽车电器(2022年9期)2022-11-07
摄影世界(2022年1期)2022-01-21
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
铁道通信信号(2020年4期)2020-09-21
家庭影院技术(2019年8期)2019-12-04
中国外汇(2019年11期)2019-08-27
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
