
SMViT:用于新冠肺炎诊断的轻量化孪生网络模型
2023-10-29 04:21:08马自萍谭力刀马金林
计算机与生活 2023年10期
马自萍,谭力刀,马金林,陈 勇
1.北方民族大学 数学与信息科学学院,银川 750021
2.北方民族大学 计算机科学与工程学院,银川 750021
3.宁夏医科大学总医院 放射介入科,银川 750004
由于新冠病毒的传播速度极快,对全人类的生命健康带来了严重的危害。因此,快速精确地诊断出新冠肺炎对患者治疗与切断病毒传播链具有重要意义。研究表明,新冠肺炎患者在患病期间几乎都会出现肺部性状的改变[1-2]。手动标记影像数据不仅对检查人员的临床经验要求较高,而且费力耗时,而基于深度学习的智能影像诊断技术具有诊断速度快、灵敏度高的优点[3]。
用于新冠肺炎诊断的经典深度网络主要有[4-9]:VGGNet、ResNet、DenseNet、InceptionNet、CapsNet 和EfficientNet 等网络。VGGNet 使用小核卷积与小核池化来保证少量参数下获取更多细节特征,一些学者将VGGNet 作为主干网络用于新冠肺炎诊断取得了不错的效果[4]。ResNet 采用残差连接的结构将浅层特征与深层特征直接相连,有效地缓解了梯度消失、梯度弥散和网络退化的问题[5]。DenseNet中任意层之间都有直接的连接,利用所有层的特征来预测结果以提升网络的鲁棒性[6]。InceptionNet 采用多尺度的多分支卷积层来提取不同尺度的特征,使用1×1的卷积与全局平均池化来使网络参数减少的同时提高运算速度[7]。CapsNet通过将capsule嵌套在其他层中来减小网络深度,每个capsule 可以检测图像中的一类特定实体,通过动态路由机制向父层反馈检测到的实体。基于CapsNet架构的新冠肺炎诊断网络由于其深度较浅,对设备算力要求不高[8]。EfficientNet由B0~B7共8个不同尺度的子网络构成,通过交替使用3×3与5×5的卷积层来提取特征,并使用组合缩放系数来同时调整网络的宽度与深度,实现了较高的新冠肺炎诊断准确度[9]。
由于常规病毒性肺炎与新冠肺炎的影像特征差别很小,基础网络往往难以准确地进行分类。因此,研究者提出了一些多模型结合的方法。Ozkaya等[10]提出了一种多模型深层特征融合和排列的新冠肺炎检测方法(deep features fusion and ranking technique,DFFRT)。类似地,Rahimzadeh等[11]提出基于Xception[12]和ResNet的级联神经网络。这类网络虽然实现了精度的提升,但灵敏度不足。为此,Togacar 等[13]结合MobileNetV2[14]和SqueezeNet[15]构造级联网络,并且借助支持向量机(support vector machine,SVM)[16]对有效特征进行组合,提升了模型的灵敏度。
多模型结合的方法虽然在一定程度上提升了模型的诊断性能,但是大多数新冠肺炎数据集的样本数量十分有限,而常规架构下的深度学习网络会由于训练数据不足导致网络泛化能力较弱,难以在小样本数据集上取得良好的效果。因此,Zheng等提出了DeCoVNet[17]模型,该模型通过与弱监督方法[18]结合,采用数据增强技术有效缓解了数据集过小带来的过拟合问题,但是该模型容易导致较高的假阴性率。为此,Narin 等[19]巧妙地使用结合迁移学习的二进制Resnet模型(binary classification of transfer learning Resnet,BTLResnet)来解决数据量少和训练时间不足的问题,改善了假阴性问题。与BTLResnet模型不同,Wang 等[20]提出了基于DenseNet121 的新冠肺炎分类和预后分析方法,该方法使用双步迁移策略来解决新冠肺炎数据集样本数量不足的问题,在数据集较小的情况下取得了较高的诊断准确率。与此类似的是,Chowdhury等[21]提出基于EfficientNet的集成网络(efficient COVID-19 detection network,ECOVNet)。该网络使用在ImageNet 上预训练的权重进行迁移,通过集成预测的方法来降低模型的泛化误差,提高了在新冠肺炎X-ray图像小数据集的诊断准确率。
综上所述,基于迁移学习的方法解决了数据集样本不足的问题,然而,简单的迁移学习技术对源域数据与目标域数据的相似度要求较高,复杂的迁移学习技术在不同任务上需要使用不同的迁移策略,可移植性差。为此,He 等提出一种自监督预训练框架(masked autoencoder,MAE)[22],通过在原图像上随机掩盖一定比例的像素块作为模型的输入数据,使用原图像作为标签来训练模型。受此启发,本文构建了MAE 策略下的ViT(vision transformer)模型以缓解复杂的迁移学习技术的可移植性差问题。
目前,在许多视觉任务中ViT模型展现了其全局的优越性,与卷积神经网络(convolutional neural network,CNN)相比,性能有了显著的提升[23]。但是,ViT 模型的多头自注意力机制会对全局的特征表示进行学习,这导致其参数量显著增加。为此,本文采用循环子结构的方法对模型进行轻量化,通过在单个子网络上循环更新梯度来避免训练时产生过大的计算图。对由多个结构相同的编码器块构成的ViT模型,该方法可明显降低其参数量。
1 本文方法
1.1 轻量化策略
本文提出了循环子结构轻量化策略,其网络训练流程如图1 所示。设一个神经网络A由结构相同的子网络A1,A2,…,An构成,子网络Ak的输出为子网络Ak+1的输入,网络A的总参数量为子网络A1参数量的n倍。设神经网络B仅由子网络B1构成,B1与A1结构相同,因此网络B的总参数量为子网络A1参数量。通过公式推导证明,在网络A与网络B有相同输入、标签、网络参数的情况下,将子网络B1复用n次后,每一轮训练将会得到相同的结果。该策略对由多个具有相同结构的子网络构成的复杂网络具有轻量化效果。
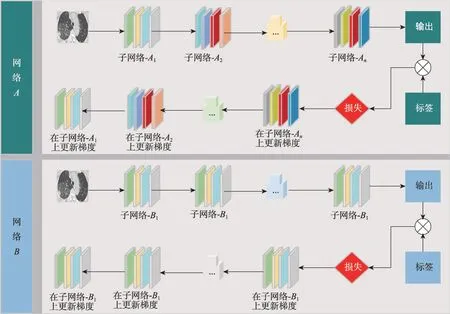
图1 网络A 与网络B 的训练流程Fig.1 Training process of network A and network B
理论证明如下:将神经网络表示为函数的形式,设子网络A1为函数output=f1(input),子网络A2为函数output=f2(input),子网络Ak为函数output=fk(input),子网络B1为函数output=g(input),其中input为网络的输入,output为网络的输出。设神经网络中采用sigmoid作为激活函数,并将一个子网络分为输入层、隐含层与输出层。由神经网络的定义可知,f1(input),f2(input),…,fn(input),g(input)的形式均可表示为:
其中,W为神经网络中输出层与前一层各连接的权重,b为偏置项,X为隐含层的输出。由式(1)易知,表示神经网络的函数在定义域内无穷次可导。因此,任意表示神经网络的函数均可利用泰勒公式将其表示为一个多项式函数。若将所有的子网络函数均按泰勒公式展开到固定的阶数,则函数f1(input),f2(input),…,fn(input),g(input)均可表示为同阶的多项式函数:
网络A可表示为:
网络B可表示为:
其中,函数g()复合了n次。设多项式函数g()的第m阶为omxm,多项式函数fn()的第m阶为pnmxm。
通过归纳假设法可以证明,当n=1时:
若令om=p1m,则式(3)与式(4)相等。当n=k时:
若令om(k-1)m+(k-1)=pkm p(k-1)m...p2m p1m,则式(3)与式(4)相等。当n=k+1时:
若令om km+k=p(k+1)m pkm...p2m p1m,则式(3)与式(4)相等,即可以通过将单个子网络复用n次来达到与由n个子网络构成的复杂网络相等的效果。
1.2 轻量化的孪生架构网络
本文提出轻量化的SMViT(siamese masked vision transformer)网络模型,其结构如图2所示。从图2可以看出,轻量化SMViT 模型的编码器通过将一个编码器子块循环使用来取得与原本由多个编码器子块堆叠构成的编码器相同的效果,有效减少了网络参数量与训练模型所需显存。在SMViT的预训练网络中,编码器负责提取高维特征表示,解码器则通过与未掩码图像计算MSE(mean square error)损失来细粒度地还原图像,从而有效地增强了模型的潜在特征表示能力。MSE损失公式为:

图2 SMViT网络结构图Fig.2 Structure of SMViT
最后,搭建一个孪生网络头用于新冠肺炎的诊断。
1.3 孪生网络头
孪生网络的核心思想是利用神经网络将两个输入样本映射到新的空间中进行表示,通过对两个样本在新空间的表示计算损失,来评价两个输入的相似度[24]。由于孪生网络具有权值共享的特性,这样可以保证两个不同样本的输出在同一域内[25]。近年来,孪生网络已成为各种视觉表示学习模型中的常见结构,它将最大化两幅同一类别图像之间的相似性,并最小化两幅不同类别图像之间的相似性。孪生神经网络可以将分类问题转化为模板匹配的问题,进而具备较强的小样本学习能力,且不易被错误样本干扰[26]。
因此,在ViT的编码器上添加一个由全连接层与MSE损失构成的孪生网络头,其结构如图2所示。其中,编码器与解码器负责掩码自监督预训练,预训练完成后再训练由编码器与孪生网络头组成的诊断网络,此时,编码器梯度将不再更新。由于肺部图像中不同区域对是否被判定为新冠肺炎的贡献度不同,在孪生网络头中,全连接层将对输入样本的特征图进行加权。然后计算两个样本加权后的MSE损失来判定两个样本是否属于同一类别。嵌入了孪生网络头后,轻量化的SMViT 能更好地分辨出新冠肺炎患者的肺部图像,进而在小样本数据集上具备良好的泛化能力。
1.4 算法流程
SMViT模型的训练流程图如图3所示,具体流程如下:
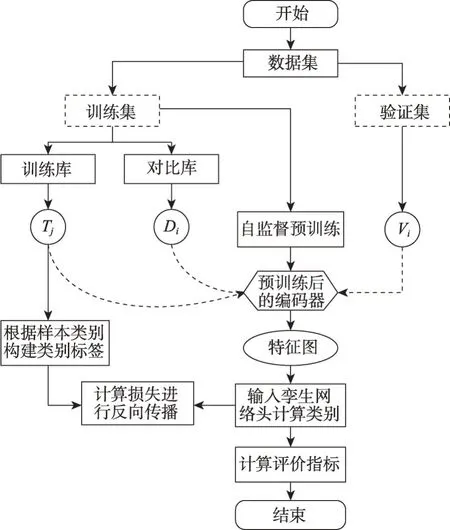
图3 SMViT训练流程图Fig.3 Flow chart of SMViT
(1)把所有样本分为训练集与验证集后,将所有训练集中的数据输入ViT 中进行掩码自监督预训练。预训练完成后随机从训练集中选取部分样本作为对比库。
(2)分别遍历对比库与训练集中剩余的所有样本,每次从对比库中选出一个样本Di,从训练集中挑选出一个样本Tj;将Di与Tj分别输入编码器中计算特征图。
(3)然后将特征图输入孪生网络头计算差异,并根据样本所属类别构建的标签进行损失计算,最终使得同类样本差异最小,异类样本差异最大。
(4)利用模型进行验证时,首先分别遍历验证集与对比库中所有样本,每次从验证集中选出一个样本Vi,从对比库中挑选出一个已知类别的样本Di,计算Vi与Di的特征图;其次输入孪生网络头进行判断,若两个样本属于同一类别,则该类别得分加1,反之,则不加分;最后计算所有类别的得分率,得分率最大者作为该输入样本的类别。
1.5 数据集与评价指标
现有的新冠肺炎数据集有X-ray图像与CT图像两类。本文使用的X-ray图像数据集包括COVID-19 radiography database 数据集[27]与Pranavraikokte 数据集[28],CT 图像数据集包括COVID19-CT 数据集[29]与SARS-CoV-2 CT-scan 数据集[30]。COVID-19 radiography database 数据集包含3 616 例新冠肺炎阳性、6 012 例肺部阴影(非COVID 肺部感染)和10 192 例正常的X-ray 图像。Pranavraikokte 数据集包含137例新冠肺炎阳性病例、90 例正常和90 例病毒性肺炎病例的X-ray图像。COVID19-CT数据集包含216名新冠肺炎患者的349 幅和397 幅正常的CT 图像。SARS-CoV-2 CT-scan数据集包括1 262例COVID-19阳性患者的CT 图像和1 230 例COVID-19 阴性患者的CT图像。本文实验中对所有数据集均按7∶3的比例划分训练集与验证集。
由于数据集样本内部存在类别不均衡的问题,为了对模型性能进行更客观的评价,本文采用准确率(accuracy,ACC)、特异度(specificity,SPE)、灵敏度(sensitivity,SEN)和F1分数来评价模型性能。其中,SPE的计算公式为:
其中,TP、TN、FP、FN分别表示真正例、真反例、假正例、假反例。F1-Measure的计算公式为:
其中,P与R分别表示查准率和查全率,其计算公式分别为:
1.6 实验环境
本文的实验环境均基于Pytorch 框架,使用Titan V 12 GB 显卡。初始学习率为0.000 3,batchsize 为32,epoch为100,使用Adam优化策略。
2 实验结果与分析
2.1 新冠肺炎诊断结果与分析
本实验验证了SMViT 模型在新冠肺炎X-ray 图像、CT 图像数据集上的诊断性能,并给出了实验分析。测试集一共包含4个数据集,本文方法在各数据集上的“损失-轮次”与“准确率-轮次”折线图如图4所示。从图4可以看出,损失值随轮次增加逐渐趋于稳定,准确率上升趋势在训练后期仍然增长平稳,表明本文方法具有较稳定的收敛性能。
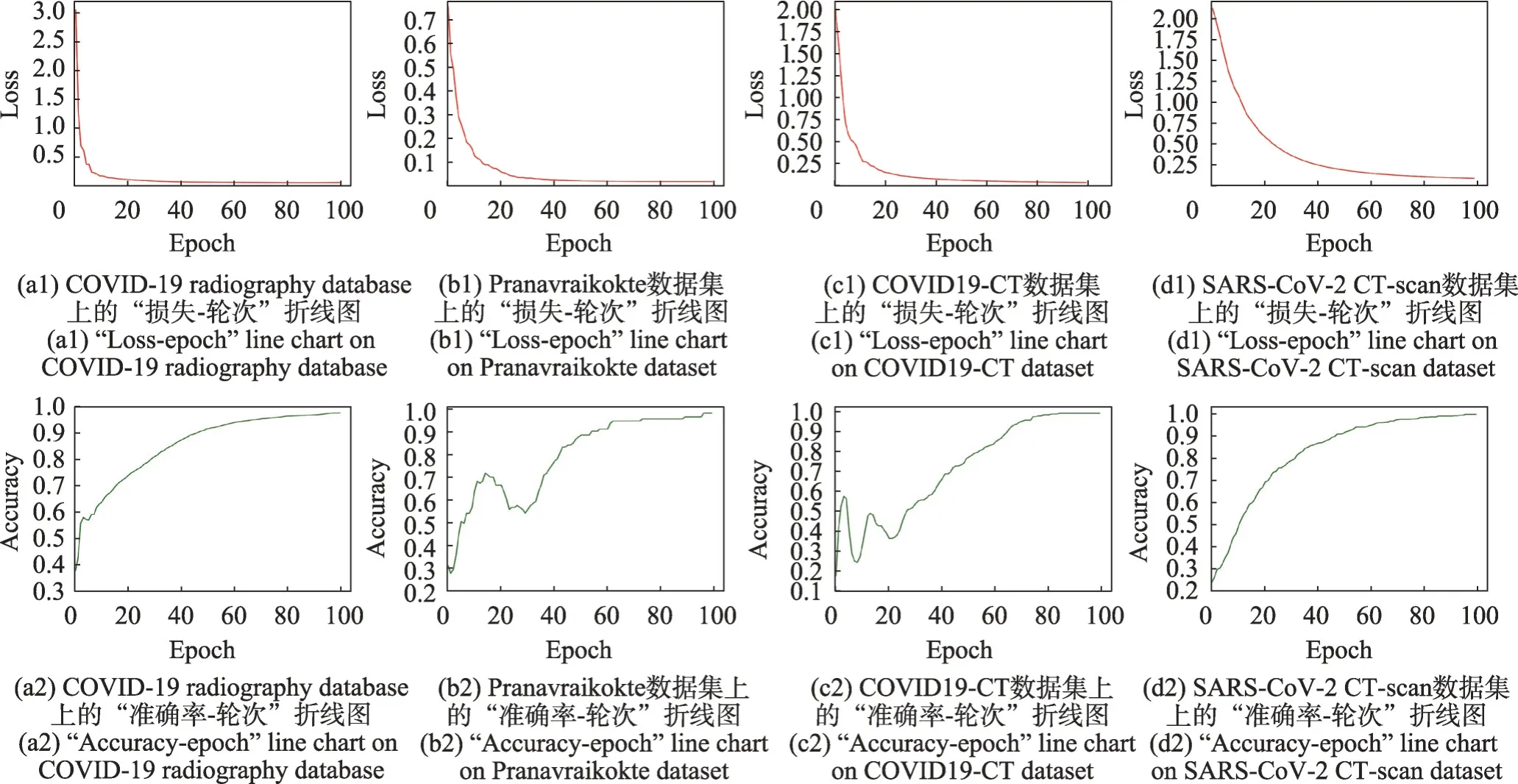
图4 不同数据集下轮次对精度和损失的影响Fig.4 Effect of epoch on accuracy and loss under different datasets
在两个X-ray 图像数据集上比较了SMViT 与对比模型的诊断性能,实验结果如表1 所示。可以看出,在两个数据集上,对于ACC、SPE、SEN和F1 分数而言,SMViT模型取得了最好的诊断性能,与对比模型相比,最多提高了7.0%、6.7%、7.3%和6.0%,与MFViT 相比,分别提高了0.9%~1.4%、0.8%~4.6%、0.4%~0.8%和0.8%~2.8%,表明SMViT 在X-ray 图像上的诊断性能具有明显的优势。此外,为了比较模型在推断时的计算效率,在两个X-ray图像数据集上计算了单幅图像的平均推断耗时。SMViT的推断耗时略高于MobileNetV2+SqueezeNet,但是明显低于其他对比模型。因此,本文模型在推断速度上仍然具有一定的优势。

表1 不同方法在X-ray图像上的性能对比Table 1 Performance comparison of different methods on X-ray images
在两个CT 图像数据集上比较了SMViT 与对比模型的诊断性能,实验结果如表2 所示。可以看出,SMViT的ACC、SPE、SEN和F1分数具有最高的取值,与最具竞争力的Trans-CNN Net相比,分别提高了0.9%~2.1%、1.2%~2.1%、0.7%~2.0%和1.0%~2.1%,表明SMViT 在CT 图像上的诊断性能具有明显优势。从推断耗时来看,SMViT的推断耗时与DeCoVNet2D相当,略高于COVID-FACT,但低于其他对比模型。其原因是COVID-FACT也采用了轻量化策略。与其他非轻量化的模型相比,SMViT在CT图像上的推断速度仍然具有显著的优势。

表2 不同方法在CT图像上的性能对比Table 2 Performance comparison of different methods on CT images
2.2 消融实验
为了验证孪生网络与ViT结合的有效性,分别设计了四组消融实验,在包含X-ray 图像与CT 图像的四个数据集上的实验结果如表3所示。
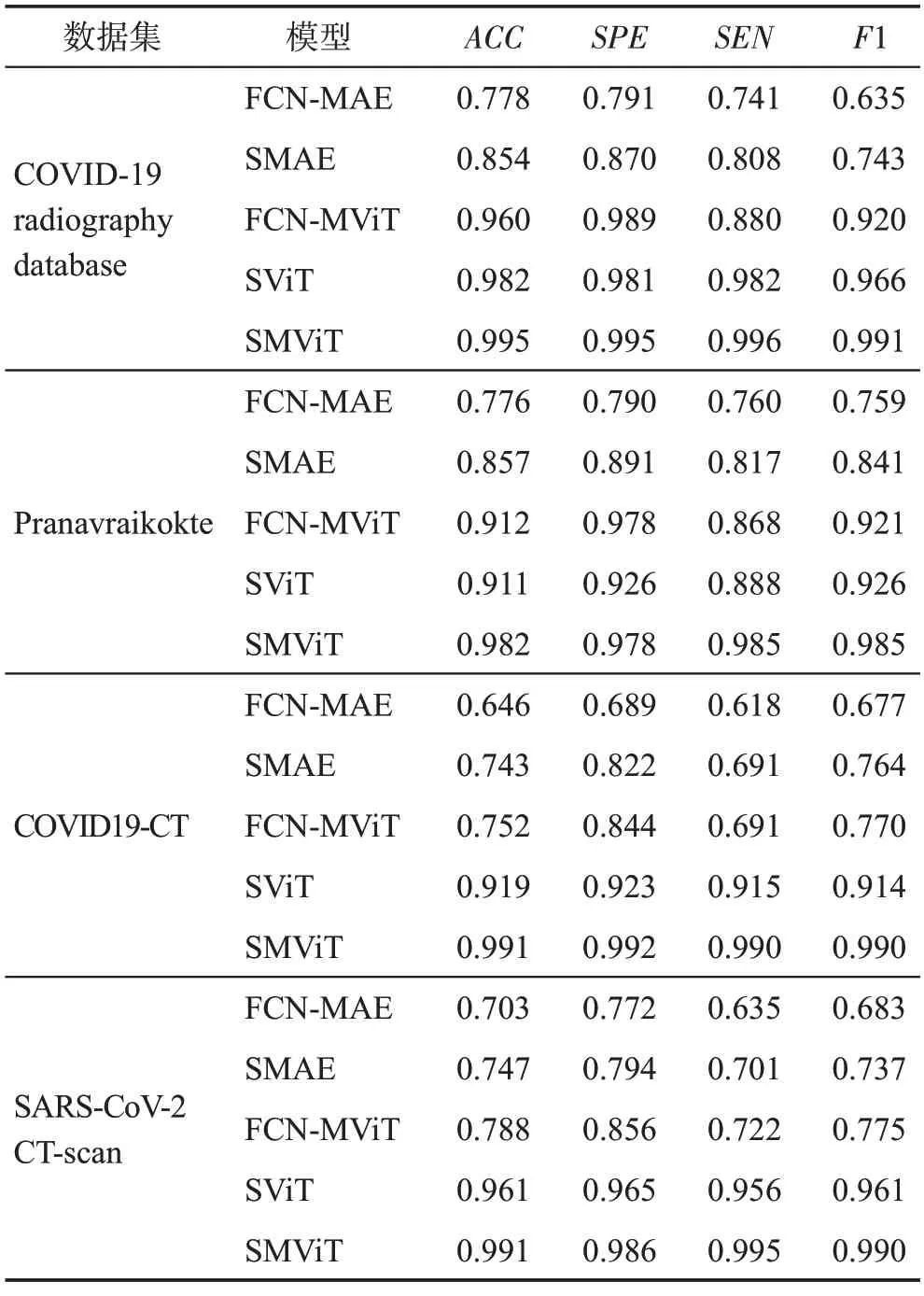
表3 消融实验结果Table 3 Ablation experimental results
第一组实验验证孪生网络架构是否比全连接网络架构更有效。将ViT 与主流的用于分类的全连接网络进行组合(fully connected network-masked vision transformer,FCN-MViT),其训练流程与SMViT 保持一致。对比表3 中COVID19-CT 数据集与Pranavraikokte数据集上的实验结果可以看出,FCN-MViT的性能不如SMViT,对于相对复杂的CT图像病例的诊断效果较差。这表明FCN-MViT 在小数据集上的分辨能力不足,而基于孪生网络与ViT 结合的SMViT,在小数据集上表现出了优越的性能。因此,采用孪生网络架构比采用全连接网络架构性能更好。
第二组实验检验基于ViT 的自监督预训练模型是否比基于卷积自编码器的自监督预训练模型更有效。使用图像处理领域非常流行的卷积自编码器来代替ViT 进行掩码自监督预训练(siamese masked autoencoder,SMAE)。对比表3 中SMAE 与SMViT的实验结果,可以看出SMAE的性能明显不如SMViT,这表明SMAE在图像特征提取能力上略逊一筹。因此,虽然SMViT与SMAE模型均采用孪生网络架构,但基于ViT 的自监督预训练模型比基于卷积自编码器的自监督预训练模型更有效。
第三组实验验证卷积自编码器与全连接网络架构是否会是更有效的结合方式:使用卷积自编码器进行掩码自监督预训练,采用全连接网络架构进行分类(fully connected network-masked autoencoder,FCNMAE)。从表3 可以看出,FCN-MAE 不仅不能在小数据集上取得良好的结果,而且其总体性能远低于SMViT。这进一步验证了采用孪生网络架构的模型在小数据集上能取得更好的效果,而采用卷积自编码器与全连接网络架构相结合的架构则会带来更糟糕的结果。
第四组实验验证掩码自监督预训练策略能否比非掩码自监督预训练策略提取到更有效的特征表示,进而提升诊断精度。实验中,使用与SMViT结构完全相同的网络,采用非掩码自监督预训练策略(siamese vision transformer,SViT)。从表3 可以看出,在不同的数据集上SViT 的诊断准确率比SMViT低1.3%~7.2%。这表明与非掩码自监督预训练策略相比,掩码自监督预训练策略能提取到更有效的特征表示。
综上所述,采用非孪生网络架构的神经网络在小数据集上的性能不佳;采用卷积自编码器进行预训练会导致模型特征提取能力不足,与采用ViT进行预训练的模型相比其性能略显不足;采用卷积自编码器与全连接网络架构的模型会带来更糟糕的结果;而采用孪生网络架构的ViT模型能够在数据集样本不足的情况下取得最好的效果。因此,孪生网络对ViT模型在新冠肺炎诊断中具有重要的提升效果,进而验证了此种架构的有效性。此外,与非掩码自监督预训练策略相比,掩码自监督预训练策略能提取到更有效的特征表示,对模型诊断性能的贡献更高。
2.3 单类网络下的轻量化可行性分析
在1.1 节已经证明由多个具有相同结构的子网络构成的复合网络,可以通过在单个子网络上循环更新梯度来取得完全相同的结果。但为了进一步验证该方法的可行性,设计了一个采用全连接层构建的具有多个相同结构子网络的复合网络,其结构如图5所示。
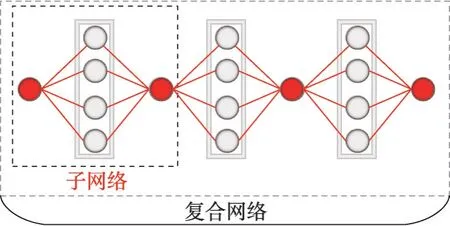
图5 全连接构建的复合网络Fig.5 Composite network constructed by full connection
设定相同输入、标签、初始参数,在单个子网络复用三次与三个子网络使用一次的模式下,验证输出与损失是否一致来判断该策略的可行性,实验结果如图6所示。从图6可以看出,两种模式下每个轮次的输出与损失完全一致,这表明该策略是可行的。

图6 单类网络下两种方法的损失与输出结果曲线Fig.6 Loss and result curves of two methods under simple network
2.4 复合网络下的轻量化可行性分析
在保证相同输入、标签、初始参数的情况下,仍然通过检查单个子网络复用三次与三个子网络使用一次两种模式下,每个轮次的输出与损失是否一致来检验该方法在复合网络下的可行性,实验结果如图7 所示。从图7 可以看出,两种模式下,每个轮次的输出与损失仍然完全一致,这表明该方法在复合网络下仍然可行。

图7 多类网络下两种方法的损失与输出结果曲线Fig.7 Loss and result curves of two methods under multiple networks
设计了一个由全连接层、卷积层共同构建的具有多个相同结构子网络的复合网络,其结构如图8所示。从图8可以看出,该复合网络具有三个结构完全相同的子网络,每个子网络的数据由全连接层输入,通过reshape改变张量形状,再输入卷积层,然后通过reshape 再次改变张量形状后输入到全连接层,最后将全连接层的输出作为下一个子网络的输入。

图8 多类网络构建的复合网络Fig.8 Composite network constructed by multiple networks
2.5 轻量化结果与分析
由于ViT 的编码器是由多个结构相同编码器块组合而成,属于由多个相同结构的子网络构成的复杂网络,可以通过循环单个编码器块来达到与使用多个编码器块一样的效果,并减小ViT的参数量。为了验证SMViT 的轻量化效果,在不同编码器块数量下进行了对比。不同编码器块所占显存与参数量如表4所示。在batchsize相同的情况下,循环单个编码器块的SMViT与拥有9个编码器块的ViT相比,所占显存可减少74.07%,网络参数量可减少88.88%。因此,基于循环子结构的SMViT 能明显减少其参数量与显存占用。

表4 不同方法的资源使用量Table 4 Resource usage of different methods
3 结束语
本文提出了一种轻量化的孪生ViT模型SMViT,并应用于新冠肺炎诊断。首先,使用非对称的轻量级ViT 进行掩码自监督预训练来使模型学到更有效的潜在特征表示;其次,在ViT 的基础上添加孪生网络架构来搭建SMViT;最后,通过循环子结构的方法对模型进行轻量化。实验结果表明:在X-ray数据集上,本文模型的ACC、SPE、SEN与F1 分数,比最具竞争力的ViT 架构模型提高了1.42%、4.62%、0.40%和2.80%;在CT图像数据集上,相应指标最大可提高2.16%、2.17%、2.05%和2.06%。在X-ray 图像与CT图像上的实验结果均表明SMViT的诊断性能明显优于对比模型,表现出了优越的性能。此外,在数据集样本量不足的情况下,SMViT 仍然具有良好的泛化能力。在基于循环子结构的轻量化策略下,SMViT能明显减少参数量与显存占用。
由于SMViT 采用了孪生网络架构,在解决多分类问题时训练耗时较高,未来的研究将对此进行优化。另外,对不具有结构相同子网络的复合网络如何进行轻量化仍然有待进一步研究。
猜你喜欢
精密成形工程(2022年2期)2022-02-22 05:44:14
今日农业(2021年2期)2021-11-27 19:19:53
今日农业(2021年1期)2021-03-19 08:35:38
疯狂英语·初中天地(2020年5期)2020-06-22 08:47:54
恋爱婚姻家庭·养生版(2020年3期)2020-04-13 10:01:57
智富时代(2019年2期)2019-04-18 07:44:42
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
专用汽车(2016年1期)2016-03-01 04:13:19
电子器件(2015年5期)2015-12-29 08:42:24
